【C++】unordered系列容器的封装

unordered系列的封装
- 1 unordered_map 和 unordered_set
- 2 改造哈希桶
- 2.1 模版参数
- 2.2 加入迭代器
- 3 上层封装
- 3.1 unordered_set
- 3.2 unordered_map
- 4 面试题分析
- Thanks♪(・ω・)ノ谢谢阅读!!!
- 下一篇文章见!!!
1 unordered_map 和 unordered_set
unordered系列的库是以哈希桶为底层的容器,其是用来快速寻找指定数据。这里主要介绍unordered_map和unordered_set。
- unordered_map是用来储存
<key , value>键值对的容器,可以通过Key快速寻找到其对应的value,注意Key和value的类型可以不一样。并且key不可更改,value可以更改! - unordered_map内部并不是按照特定顺序储存的,而是按照key转换得到的数组下标来进行存储,因此内部是无序的!
- unordered_map通过key查找元素比map快非常多!!!但对应迭代的速度比较慢。
- unordered_map允许
[ ]下标访问! - unordered_map只有正向迭代器!没有反向迭代器!
- unordered_set是只储存key值的容器!和set相似,用来去重或者判断是否存在!
- unordered_set内部并不是按照特定顺序储存的,而是按照key转换得到的数组下标来进行存储,因此内部是无序的!
-
- unordered_set通过key查找元素比set快非常多!!!但对应迭代的速度比较慢。
- unordered_set不提供
[ ]下标访问! - unordered_set只有正向迭代器!没有反向迭代器!
他们都提供以下接口:
| 函数 | 功能介绍 |
|---|---|
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
| 函数 | 功能介绍 |
|---|---|
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为key的键值对的个数 |
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器中的元素 |
| 函数 | 功能介绍 |
|---|---|
| size_t bucket_count()const | 返回哈希桶中桶的总个数 |
| size_t bucket_size(size_t n)const | 返回n号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素key所在的桶号 |
接下来我们就来实现这些功能!
2 改造哈希桶
2.1 模版参数
unordered_map 和 unordered_set的底层是开散列版本的哈希表(哈希桶),但是他们两个储存的数据却不一样:一个是键值对pair<k , v> , 一个是键值key。所以为了可以让哈希桶适配,就要进行泛型编程的改造,增加模版参数。由上层的unordered_map 和 unordered_set控制底层的哈希桶存储什么数据,因此我们需要添加一个class T模版参数,供上层决定储存什么数据。与之对应的,从数据中获取key的仿函数。
这样加上将转换key为size_t的仿函数,共用四个模版参数:
class k: 表明键值key的类型,这是最基本的。class T: 储存的数据类型:pair<k , v>或key。class KeyOfT: 如何从T中获取key,这是很关键的,是我感觉最巧妙的一环,通过仿函数来适配不同类型,太妙了!class HashFunc:将key值转换为size_t的数组下标。
通过这四个模版参数,就可以通过传入对应的参数来保证适配!(迭代器我们后续来实现)
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
public:typedef HashNode<T> Node;iterator begin(){}iterator end(){}const_iterator begin() const {}const_iterator end() const {}HashTable():hs(),kot(){_table.resize(10, nullptr);_n = 0;}//插入数据pair<iterator, bool> insert(const T kv){}//删除bool erase(const K& key){}//查找iterator find(const K& key){}
private://底层是一个指针数组vector<Node*> _table;//有效数量size_t _n;//仿函数Hash hs;KeyOfT kot;
};
我们的模版参数修改之后,我们的函数体也要进行改造,不能直接写死,要符合泛型编程:
函数基本都是修改了原本的cur->_kv。first 变为 kot(cur->_kv),通过仿函数来获取key值,并且返回值设置为迭代器。这样无论我们传入的是pair<k , v> 或 key,都可以通过仿函数获取对应的key值!下面给出插入函数的代码,其余函数的改造类似!
//插入数据
pair<iterator, bool> insert(const T kv)
{iterator it = find(kot(kv));if (it != end())return make_pair(it, false);//扩容if (_n == _table.size() * 0.7){//直接把原本的节点移动到新的table中即可vector<Node*> newtable(2 * _table.size());//遍历整个数组for (int i = 0; i < _table.size(); i++){if (_table[i]){Node* cur = _table[i];while (cur){//获取数据Node* next = cur->_next;//计算新的映射//kot(cur->_kv) 来获取 T 中的keysize_t hashi = hs(kot(cur->_kv)) % newtable.size();//进行头插cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}}}_table.swap(newtable);}//首先寻找到合适下标size_t hashi = hs(kot(kv)) % _table.size();//进行头插Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return make_pair(iterator(newnode , this), true);
}
2.2 加入迭代器
实现封装一定少不了迭代器!!!迭代器可是强大的武器,有了迭代器就可以使用基于范围的for循环,还可以通过迭代器来访问修改数据。
那么我们就要来写一个迭代器,来供我们使用。
哈希表的迭代器和之前写过的迭代器有所不同,我们来看奥:我们搭建一个基本框架:
- 首先我们需要一个节点指针,这是迭代器中的关键元素,用来访问数据
- 然后我们的迭代器其要支持
++运算,可以移动到下一个节点。移动规则:当前桶没走完就移动到下一个元素, 当前桶走完了就移动到下一个桶的第一个元素,而移动到下一个桶需要哈希表表,所以内部需要有一个哈希表 - 还要提供基本的
!= == * ->运算。 - 注意构造函数要使用
const HashTable* ht低权限,因为我们不会对其修改,还要避免上层传入``const HashTable* `,所以要做好预防!
template<class Ref , class Ptr>
struct _HTIterator
{typedef _HTIterator<Ref, Ptr> Self;//成员Node* _node;//哈希表const HashTable* _pht;//构造函数_HTIterator(Node* node, const HashTable* ht):_node(node),_pht(ht){}//++Self& operator++(){}//判断很好写bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}Ref operator*() const{return _node->_kv;}Ptr operator->() const{return &_node->_kv;}
};
如果我们将迭代器正常放在哈希表的外面,会发现报错:编译器不认识 HashTable,很正常,因为HashTable在其后面才进行定义,所以我们可以在迭代器之前加一个HashTable前置声明!或者使用内部类,把迭代器放HashTable内部就好了!
然后我们就来解决这个++的问题:
- 如果当前桶还没有走到最后,就要移动到下一个节点,使用
cur = cur ->next即可! - 如果走完当前桶了(next指针是nullptr时),就要向后寻找下一个桶了。
- 如果找到了就继续进行,没有找到,说明走完了
//++
Self& operator++()
{Hash hs;KeyOfT kot;//++//当前桶没走完就移动到下一个 桶走完了就移动到下一个桶 if (_node->_next) _node = _node->_next;else{//桶走完了就移动到下一个桶size_t i = hs(kot(_node->_kv)) % _pht->_table.size();i++;for (; i < _pht->_table.size(); i++){if (_pht->_table[i])break;}//走完循环有两种可能,要进行判断if (i == _pht->_table.size())_node = nullptr;else{_node = _pht->_table[i];}}return *this;
}
这样我们的迭代器就完成了,再在hashtable中实例化普通迭代器和const迭代器:
//迭代器
typedef _HTIterator<T&, T*> iterator;
//const 迭代器
typedef _HTIterator<const T&, const T*> const_iterator;
然后加入我们begin()和end()函数
- begin():从哈希表的第一个桶开始寻找,找到桶中的第一个元素
- end() : 设置为空就可以
iterator begin()
{for (size_t i = 0; i < _table.size(); i++){if (_table[i])return iterator(_table[i], this);}return iterator(nullptr, this);
}iterator end()
{return iterator(nullptr, this);
}const_iterator begin() const
{for (size_t i = 0; i < _table.size(); i++){if (_table[i])return const_iterator(_table[i], this);}return const_iterator(nullptr, this);
}const_iterator end() const
{return const_iterator(nullptr, this);
}
这样底层就实现好了,接下来我们开始在上层做动作!
3 上层封装
底层的哈希桶我们已经改造完毕了,接下来就是在上层来调用:
3.1 unordered_set
先来看unordered_set,其底层要注意:
- unordered_set储存是key值,注意不可修改!要设置为const变量
- 使用仿函数SetKeyOfT来从T中获取Key值
- 上层要通过给对应的哈希函数
- 大部分函数直接调用底层
Hashtable中的函数就可以! - 在实例化迭代器时,需要使用typename关键字来明确指出iterator是一个类型,而不是一个变量或者别的什么。
这样我们可以搭建起一个框架
//仿函数
template<class K>
struct SetKeyOfT
{const K operator()(const K& k){return k;}
};template<class K ,class Hash = HashFunc<K>>
class my_unoerder_set
{
public://迭代器typedef typename HashTable<K, const K, SetKeyOfT<K>, Hash >::iterator iterator;typedef typename HashTable<K, const K, SetKeyOfT<K>, Hash >::const_iterator const_iterator;pair<iterator , bool> insert(const K& k){return _table.insert(k);}iterator find(const K& k){return _table.find(k);}bool erase(const K& k){return _table.erase(k);}iterator begin(){return _table.begin();}iterator end(){return _table.end();}const_iterator begin() const{return _table.begin();}const_iterator end() const {return _table.end();}
private:HashTable<K,const K, SetKeyOfT<K> , Hash > _table;
};这样就设置好了,我们来测试一下:
void test_set1()
{my_unoerder_set<string> S;vector<string> arr = { "sort" , "hello" , "JLX" , "Hi" };for (auto e : arr){S.insert(e);}my_unoerder_set<string>::iterator it = S.begin();cout << "-------while循环遍历--------" << endl;while (it != S.end()){//(*it)++;std::cout << *it << endl;++it;}cout << "-------基于范围的for循环--------" << endl;for (auto e : S){//e++;cout << e << endl;}cout << "-------查找\"hello\"--------" << endl;cout << *(S.find("hello")) << endl;
}
测试结果:

完美,这样unordered_set就完成了,当然还可以继续完善功能函数,其他的函数比较简单就不加赘述。
3.2 unordered_map
继续来看unordered_map:
- 与unordered_set不同,unordered_map里面储存的是
pair<k , v>,而且注意k值不能修改所以要传入pair<const k , v>! - 使用仿函数MapKeyOfT来从T中获取Key值
- 上层要通过给对应的哈希函数
- 大部分函数直接调用底层
Hashtable中的函数就可以! - 在实例化迭代器时,需要使用typename关键字来明确指出iterator是一个类型,而不是一个变量或者别的什么。
- 另外要额外实现
[ ]操作:非常简单,[ ]的运算规则是:如果对应key已经存在,就返回其value值。不存在就进行插入,value设置为初始值,所以直接调用Insert函数就可以,因为Insert函数不会插入重复的数据并且会返回对应的迭代器!
//仿函数
template<class K , class V>
struct MapKeyOfT
{const K& operator()(const pair<K , V>& kv){return kv.first;}
};template<class K , class V, class Hash = HashFunc<K>>
class my_unoerder_map
{
public://迭代器typedef typename HashTable< K, pair<const K, V>, MapKeyOfT<K, V> , Hash>::iterator iterator;typedef typename HashTable< K, pair<const K, V>, MapKeyOfT<K, V> , Hash>::const_iterator const_iterator;pair<iterator, bool> insert(pair<const K, V> kv){return _table.insert(kv);}iterator find(const K& k){return _table.find(k);}bool erase(const K& k){return _table.erase(k);}iterator begin(){return _table.begin();}iterator end(){return _table.end();}//[]操作V& operator[](const K& k){pair<iterator, bool> it = insert(make_pair( k , V() ));return it.first->second;}private:HashTable<K, pair<const K , V>, MapKeyOfT<K , V> , Hash> _table;
};我们来进行一下测试奥:
void test_unordered_map()
{my_unoerder_map<string, int> countMap;string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉","苹果","草莓", "苹果","草莓" };for (auto& e : arr){countMap[e]++;}my_unoerder_map<string, int>::iterator it = countMap.begin();while (it != countMap.end()){//(*it).first += 2;cout << (*it).first << ':' << (*it).second << endl;++it;}
}
运行结果:

完美!!!
4 面试题分析
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
错误回答:通过哈希表,遍历一遍该文件,获取到每个IP地址出现的次数,再遍历一遍哈希表,得到出现次数的IP地址。
…
这样的回答是对哈希理解的不够深导致的,我们看题目条件:超过100G大小的log file!哈希中负载因子一般为0.5 ~ 0.7,所以会有很多空间是浪费的,文件本身已经100G了,可想而知这个哈希表会有多大了!
我们可以使用
- 分治法:将大文件分割成多个小文件,每个文件分别统计IP出现次数,然后再合并结果。
- 哈希分区:根据IP地址的哈希值将日志分布到多个小文件中,每个小文件分别处理,最后合并结果。
- 外部排序:如果内存有限,可以使用外部排序算法来处理大量数据。布隆过滤器:如果内存非常有限,可以使
- 用布隆过滤器来估算IP地址的出现频率,但可能会有误报。
…
正确回答(分治 + 哈希):
- 预处理:如果日志文件格式允许,可以使用命令行工具(如awk,grep,sort等)对日志进行预处理,提取IP地址并排序。
- 分治:将大文件分割成多个小文件,每个文件大小可以基于内存限制来决定。
- 计数:对于每个小文件,使用哈希表统计IP出现次数。合并:将所有小文件的统计结果合并起来。这里可以使
- 用外部排序或者分布式系统来进行合并。
- 找到最频繁的IP:在合并结果中找到出现次数最多的IP。
与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?
正确答案:
- 提取IP地址:使用awk或grep等工具从日志文件中提取IP地址。
- 排序:使用sort命令对提取出的IP地址进行排序(文件过大可以分成若干个文件进行排序)。
- 计数:使用uniq -c命令来计数每个IP地址出现的次数。
- 排序并获取Top K:再次使用sort命令,这次是根据计数进行排序,并使用head -n K来获取前K个结果。
- 对应指令:
awk '{print $1}' log_file | sort | uniq -c | sort -nr | head -n K
给定100亿个整数,设计算法找到只出现一次的整数?
正确回答:可以使用位图(Bitmap)数据结构来有效地解决问题。位图是一种数据结构,用于存储与处理布尔值,其中每个值只占用一个位(bit)的空间。位图中是一个整型数组,每个整型可以储存32个比特位
- 初始化位图:创建一个位图,其大小足以表示所有可能出现的整数。需要一个大小为10亿位的位图。
- 标记出现次数:遍历所有的整数,对于每个整数,将其在位图中对应的位设置为
1。如果整数再次出现,则将其在位图中对应的位设置为-1,在出现就不进行处理。这样,最终位图中为1的位对应的整数就是只出现一次的整数。 - 收集结果:遍历位图,找到所有为
1的位,这些位对应的整数就是只出现一次的整数。
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
正确回答:
- 方法一:分治法 + 哈希分桶
- 分治法:将每个文件分割成多个小文件,每个小文件的大小可以基于内存限制来决定。
- 哈希分桶:使用哈希函数将文件中的整数分布到多个桶中。对于每个桶,可以在内存中处理两个文件中的整数,找到交集。
- 合并结果:将所有小文件的交集结果合并起来,得到最终的交集
- 方法二:外部排序
- 排序:分别对两个文件进行外部排序。由于内存限制,每次只处理一部分数据。
- 合并:使用外部归并排序的思想,逐步合并两个文件中的数据(取整数出现次数少的那部分),找到交集。
位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
正确回答:
- 方法一:分治法 + 哈希表
- 分治法:将大文件分割成多个小文件,每个小文件的大小可以基于内存限制来决定。
- 计数:对于每个小文件,使用哈希表(如std::unordered_map)来计数每个整数出现的次数。
- 过滤:遍历哈希表,将出现次数不超过2次的整数输出到结果文件中。
- 合并结果:将所有小文件的结果合并起来,得到最终的输出。
- 方法二:哈希分桶
- 哈希分桶:使用哈希函数将文件中的整数分布到多个桶中。
- 计数:对于每个桶,可以在内存中使用哈希表来计数每个整数出现的次数。
- 过滤:遍历哈希表,将出现次数不超过2次的整数输出到结果文件中。
- 合并结果:将所有桶的结果合并起来,得到最终的输出
Thanks♪(・ω・)ノ谢谢阅读!!!
下一篇文章见!!!
相关文章:
【C++】unordered系列容器的封装
你很自由 充满了无限可能 这是很棒的事 我衷心祈祷你可以相信自己 无悔地燃烧自己的人生 -- 东野圭吾 《解忧杂货店》 unordered系列的封装 1 unordered_map 和 unordered_set2 改造哈希桶2.1 模版参数2.2 加入迭代器 3 上层封装3.1 unordered_set3.2 unordered_map 4 面…...

matlab 超越椭圆函数图像绘制
matlab 超越椭圆函数图像绘制 超越椭圆函数图像绘制xy交叉项引入斜线负向斜线成分正向斜线成分 x^2 y^2 xy 1 (负向)绘制结果 x^2 y^2 - xy 1 (正向)绘制结果 超越椭圆函数图像绘制 xy交叉项引入斜线 相对于标准圆…...

本地文件同步上传到Gitee远程仓库
1、打开我们的项目所在文件夹 2、在项目文件夹【鼠标右击】弹出菜单,在【鼠标右击】弹出的菜单中,点击【Git Bash Here】,弹出运行窗口(前提条件是已装好git环境) 3、在命令窗口中输入:git init 4、在 Gite…...

RESTful Web 服务详解
RESTful Web 服务是一种基于 Representational State Transfer (REST) 架构风格的 Web 服务,它利用 HTTP 协议来传输数据,支持多种数据格式如 JSON 和 XML。在 Spring 框架中,通过简单配置和注解可以轻松实现 RESTful Web 服务。在本文中&…...

【ARMv8/v9 GIC 系列 5.3 -- 系统寄存器对中断的处理】
请阅读【ARM GICv3/v4 实战学习 】 文章目录 ARMv8/v9系统寄存器对中断的控制Group 0中断的寄存器Group 1中断的寄存器安全状态与中断分组中断处理过程中断确认处理代码中断完成处理代码ARMv8/v9系统寄存器对中断的控制 在ARM GIC 体系结构中,中断分组通过一系列系统寄存器进…...

MUNIK解读ISO26262--系统架构
功能安全之系统阶段-系统架构 我们来浅析下功能安全系统阶段重要话题——“系统架构” 目录概览: 系统架构的作用系统架构类型系统架构层级的相关安全机制梳理 1.系统架构的作用 架构的思维包括抽象思维、分层思维、结构化思维和演化思维。通过将复杂系统分解…...
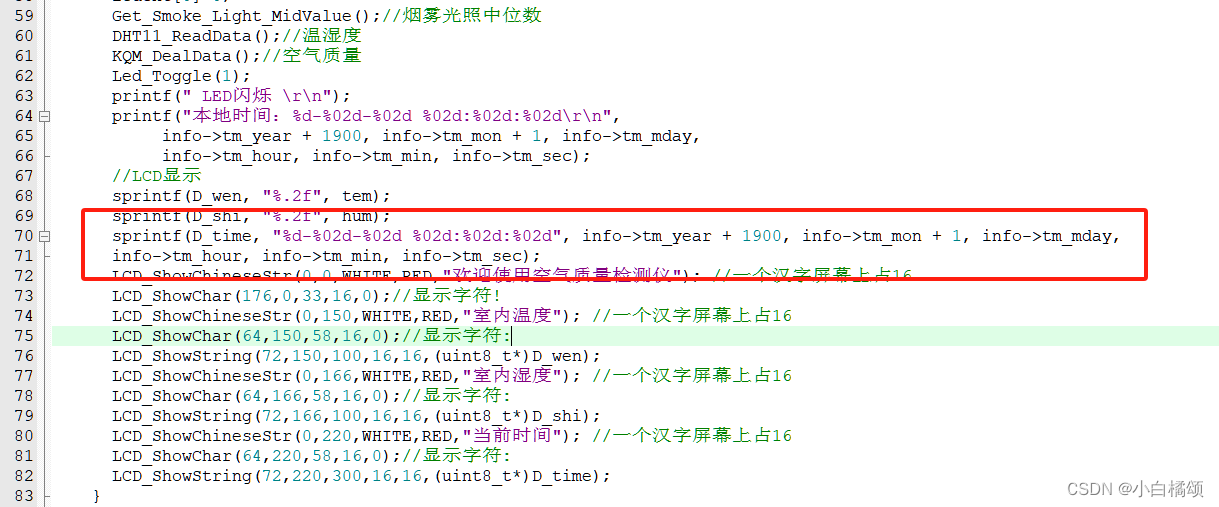
STM32第十五课:LCD屏幕及应用
文章目录 需求一、LCD显示屏二、全屏图片三、数据显示1.显示欢迎词2.显示温湿度3.显示当前时间 四、需求实现代码 需求 1.在LCD屏上显示一张全屏图片。 2.在LCD屏上显示当前时间,温度,湿度。 一、LCD显示屏 液晶显示器,简称 LCD(Liquid Cry…...

Java--继承
1.继承的本质是对某一批类的抽象,从而实现对世界更好的建模 2.extends的意思是“扩展”,子类是父亲的扩展 3.Java中只有单继承,没有多继承 4.继承关系的两个类,一个为子类(派生类),一个为父类…...

Github与本地仓库建立链接、Git命令(或使用Github桌面应用)
一、Git命令(不嫌麻烦可以使用Github桌面应用) git clone [] cd [] git branch -vv #查看本地对应远程的分支对应关系 git branch -a #查看本地和远程所有分支 git checkout -b [hongyuan] #以当前的本地分支作为基础新建一个【】分支,命名为h…...

c++之旅第十一弹——顺序表
大家好啊,这里是c之旅第十一弹,跟随我的步伐来开始这一篇的学习吧! 如果有知识性错误,欢迎各位指正!!一起加油!! 创作不易,希望大家多多支持哦! 一,数据结构…...

深入了解 PXE:定义、架构、原理、应用场景及常见命令体系
引言 PXE(Preboot Execution Environment,预启动执行环境)是一种允许计算机通过网络启动操作系统而无需本地存储设备的技术。本文将详细介绍 PXE 的定义、架构、原理、应用场景及常见命令体系,特别是以 CentOS 为例,展…...

《每天5分钟用Flask搭建一个管理系统》第9章:API设计
第9章:API设计 9.1 RESTful API的概念 RESTful API是一种基于HTTP协议的网络服务接口设计方法,它使用标准的HTTP方法,如GET、POST、PUT、DELETE等,来执行资源的操作。 9.2 Flask-RESTful扩展的使用 Flask-RESTful是一个Flask扩…...

CCM的作用及原理
CCM调试的理论依据_ccm矩阵sat调试-CSDN博客 CCM是在WB之后,就是当AWB将白色校正之后其他颜色也会跟着有明显变化,CCM的作用就是要保持白色不变,把其他色彩校正到非常精准的地步。 校正后的颜色(target值是一个固定的值)CCM矩阵*原始的颜色…...
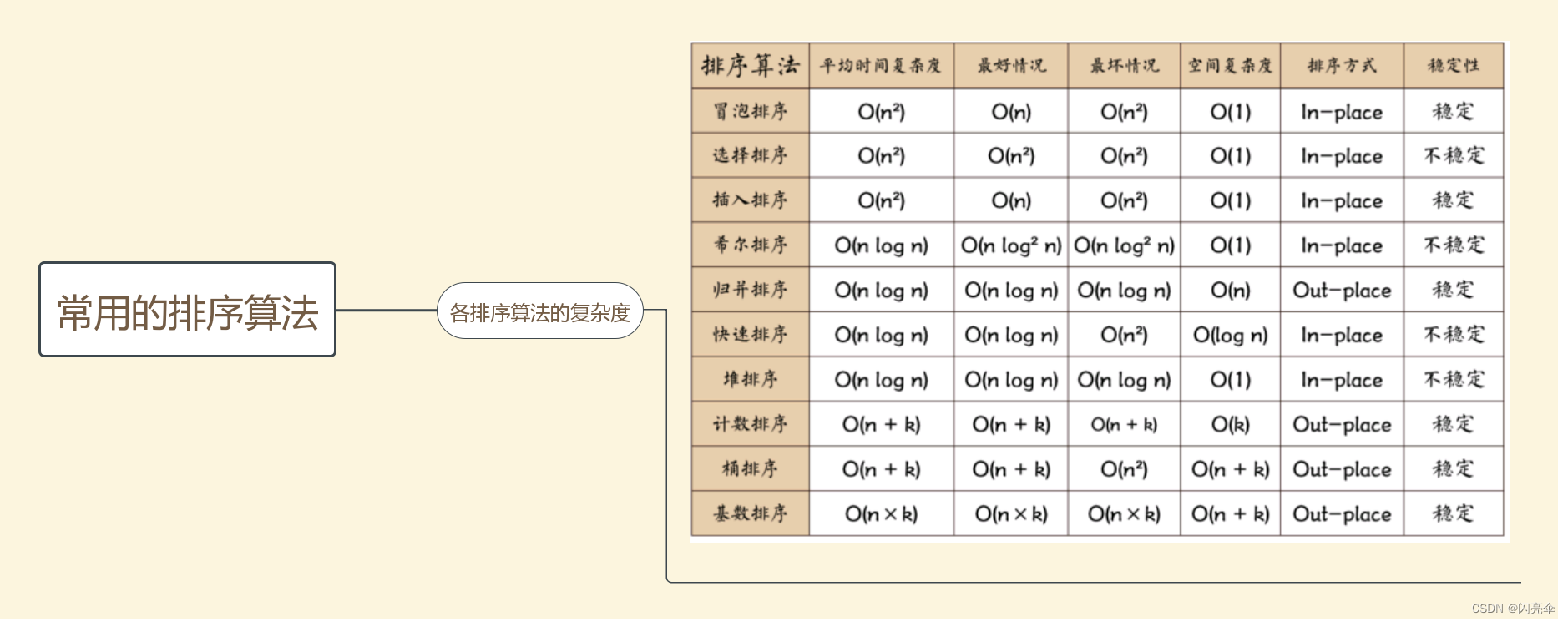
10.09面试题目记录
艾融软件 - 线上面试题 排序算法的时间复杂度 O(n^2):冒泡,选择,插入 O(logn):折半插入排序 O(nlogn):希尔,归并,快速,堆 O(nk):桶,…...
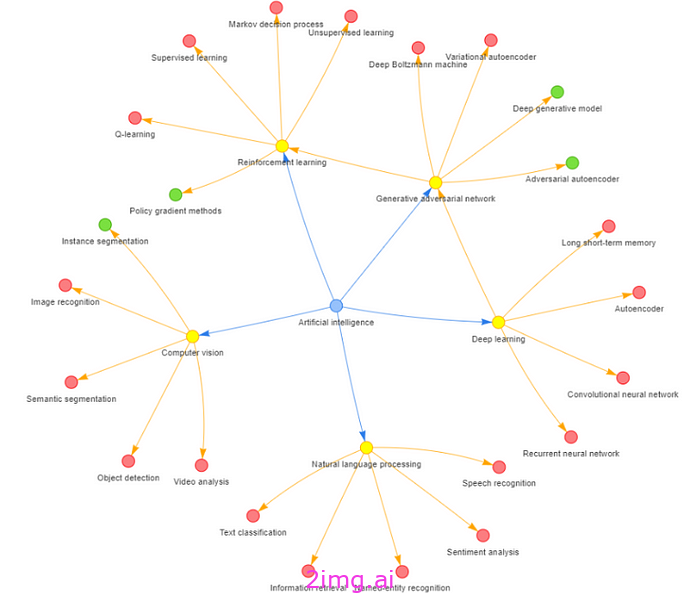
14-29 剑和诗人3 – 利用知识图谱增强 LLM 推理能力
知识图谱提供了一种结构化的方式来表示现实世界的事实及其关系。通过将知识图谱整合到大型语言模型中,我们可以增强它们的事实知识和推理能力。让我们探索如何实现这一点。 知识图谱构建 在利用知识图谱进行语言模型增强之前,我们需要从可靠的来源构建…...

【代码大全2 选读】看看骨灰级高手消灭 if-else 逻辑的瑞士军刀长啥样
文章目录 1 【写在前面】2 【心法】这把瑞士军刀长啥样3 【示例1】确定某个月份的天数(Days-in-Month Example)4 【示例2】确定保险费率(Insurance Rates Example)5 【示例3】灵活的消息格式(Flexible-Message-Format …...

深度学习 --- stanford cs231学习笔记八(训练神经网络之dropout)
6,dropout 6,1 线性分类器中的正则化 在线性分类器中,我们提到过正则化,其目的就是为了防止过度拟合。例如,当我们要用一条curve去拟合一些散点的数据时,常常是不希望训练出来的curve过所有的点,…...

【C++】 解决 C++ 语言报错:Undefined Reference
文章目录 引言 未定义引用(Undefined Reference)是 C 编程中常见的错误之一,通常在链接阶段出现。当编译器无法找到函数或变量的定义时,就会引发未定义引用错误。这种错误会阻止生成可执行文件,影响程序的正常构建。本…...
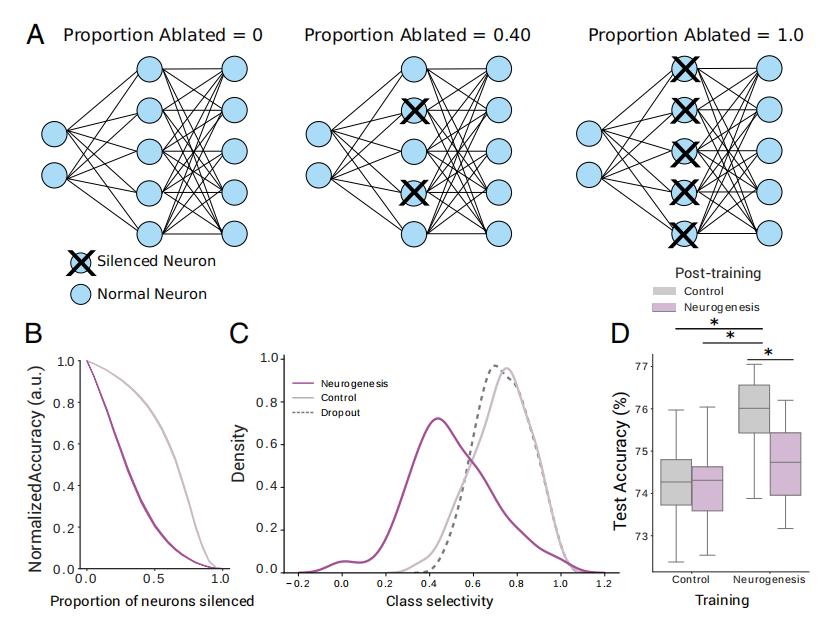
【博士每天一篇文献-算法】Adult neurogenesis acts as a neural regularizer
阅读时间:2023-12-20 1 介绍 年份:2022 作者:Lina M. Tran,Adam Santoro,谷歌DeepMind 期刊: Proceedings of the National Academy of Sciences 引用量:13 代码:https://github.c…...

在Spring Boot项目中引入本地JAR包的步骤和配置
在Spring Boot项目中,有时需要引入本地JAR包以便重用已有的代码库或者第三方库。本文将详细介绍如何在Spring Boot项目中引入本地JAR包的步骤和配置,并提供相应的代码示例。 1. 为什么需要本地JAR包 在开发过程中,可能会遇到以下情况需要使…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

JWT弱密钥爆破实战:从HS256签名原理到CTF权限提升
1. 这不是密码学考试,而是一场“密钥猜谜”实战JWT(JSON Web Token)在现代Web系统中早已不是可选项,而是默认配置。登录成功后返回一串形如eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsIm5hbWUiOiLnlKjliYkiLCJpYX…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

3分钟终极指南:用ncmdump轻松解密网易云音乐NCM格式文件
3分钟终极指南:用ncmdump轻松解密网易云音乐NCM格式文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM格式文件无法在其他播放器播放而烦恼吗?ncmdump正是解决这个问题的神器&…...