Python脚本:将Word文档转换为Excel文件

引言
在文档处理中,我们经常需要将Word文档中的内容转换成其他格式,如Excel,以便更好地进行数据分析和报告。针对这一需求,我编写了一个Python脚本,能够批量处理指定目录下的Word文档,将其内容结构化并转换为Excel文件。
功能概述
这个脚本的主要功能包括:
- 批量读取Word文档:自动检索指定目录下的所有Word文档(.docx格式)。
- 内容抽取和组织:根据Word文档中的标题层级(Heading),抽取和组织内容。
- 关键信息提取:自动从Word文档的文件名中提取关键信息,作为Excel表格中的一级节点名称。
- 结构化DataFrame创建:将抽取的信息转化为DataFrame,包含一级至四级节点及其对应内容。
- Excel文件保存:将每个Word文档转换得到的DataFrame保存为同名的Excel文件,位于原始Word文档所在的同一目录。
使用方法
- 准备文档:确保所有待处理的Word文档位于同一目录下,并且每个文档中要有定义好的标题样式(一级标题、二级标题等)。
- 指定目录:修改脚本中的
batch_process_word_to_excel函数中的directory参数,指定Word文档所在目录。 - 运行脚本:执行脚本,等待处理完成。脚本将在指定目录下生成对应的Excel文件,文件名与原Word文档一致,但扩展名为’.xlsx’。
代码解析
以下是脚本的完整代码,包含了所需的库和函数定义:
# -*- coding: utf-8 -*-
"""
此Python脚本旨在自动化处理目录下所有的Word文档(.docx),将其内容结构化并转换为Excel文件(.xlsx)。主要功能:
1. 批量读取指定目录下的所有Word文档。
2. 对每个Word文档,根据文档内的标题层级(Heading)结构,抽取和组织内容。
3. 自动从Word文档的文件名中提取关键信息作为Excel表格中的一级节点名称,特别关注“分册”和“细则”之间的文本。
4. 将抽取的信息转化为结构化的DataFrame,其中包含一级至四级节点及其对应内容。具体转换规则如下:填充说明:1.word文件名为一级标题,作为Excel中的一级节点;2.word中的一级标题作为Excel中的二级节点,一级标题和当前一级标题下的第一个二级标题之间的正文内容作为Excel的二级内容;3.word中的二级标题作为Excel中的三级节点,二级标题和当前二级标题下的第一个三级标题之间的正文内容作为Excel的三级内容;4.word中的三级标题作为Excel中的四级节点,三级标题和当前三级标题下的第一个四级标题之间的正文内容作为Excel的四级内容;
5. 将每个Word文档转换得到的DataFrame保存为同名的Excel文件,位于原始Word文档所在的同一目录。使用方法:
- 确保所有待处理的Word文档位于同一目录下。并且,每个word中要有样式:一级标题、二级标题、三级标题等
- 修改'batch_process_word_to_excel'函数中的'directory'参数,指定Word文档所在目录。
- 运行脚本,脚本将在指定目录下生成对应的Excel文件,文件名与原Word文档一致,但扩展名为'.xlsx'。依赖库:
- os: 提供与操作系统交互的功能,如文件和目录操作。
- docx: 用于读取Word文档的库。
- pandas: 用于数据处理和分析的库,创建DataFrame和保存Excel文件。注意事项:
- 代码假设Word文档中的标题层级不超过四级。
- 一级节点名称的提取逻辑基于文件名中包含“分册”和“细则”的特定格式。
- 如需处理不同层级或文件命名规则,需相应调整代码逻辑。"""
import os
import docx
import pandas as pddef extract_title_from_filename(filename):# 分割文件名找到"分册"和"细则"parts = filename.split('分册')if len(parts) > 1:title_part = parts[1].split('细则')[0]return title_part.strip() # 去除前后空格else:return filename # 如果没有找到"分册"或"细则",返回原文件名def process_word_to_excel(file_path):doc = docx.Document(file_path)columns = ['一级节点', '二级节点', '二级内容', '三级节点', '三级内容', '四级节点', '四级内容']df = pd.DataFrame(columns=columns)# 获取Word文档的文件名,并从中提取一级节点名称filename = os.path.basename(file_path)word_file_name = extract_title_from_filename(filename)current_level2 = ""current_level3 = ""current_level4 = ""current_content = ""last_level = 0for paragraph in doc.paragraphs:if paragraph.style.name.startswith('Heading'):heading_level = int(paragraph.style.name[-1])if heading_level <= last_level:if current_level4:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'三级节点': [current_level3],'四级节点': [current_level4],'四级内容': [current_content]})elif current_level3:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'三级节点': [current_level3],'三级内容': [current_content]})elif current_level2:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'二级内容': [current_content]})df = pd.concat([df, new_row], ignore_index=True)current_content = ""if heading_level == 1:current_level2 = paragraph.textcurrent_level3 = ""current_level4 = ""last_level = 1elif heading_level == 2:current_level3 = paragraph.textcurrent_level4 = ""last_level = 2elif heading_level == 3:current_level4 = paragraph.textlast_level = 3else:current_content += paragraph.text + '\n'if current_content:if current_level4:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'三级节点': [current_level3],'四级节点': [current_level4],'四级内容': [current_content]})elif current_level3:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'三级节点': [current_level3],'三级内容': [current_content]})elif current_level2:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'二级内容': [current_content]})df = pd.concat([df, new_row], ignore_index=True)return dfdef batch_process_word_to_excel(directory):for filename in os.listdir(directory):if filename.endswith('.docx'):file_path = os.path.join(directory, filename)df = process_word_to_excel(file_path)excel_filename = os.path.splitext(filename)[0] + '.xlsx'excel_path = os.path.join(directory, excel_filename)df.to_excel(excel_path, index=False)print(f'Processed {filename} to {excel_filename}')# 调用函数,指定目录
batch_process_word_to_excel('D:\\test')
相关文章:
Python脚本:将Word文档转换为Excel文件
引言 在文档处理中,我们经常需要将Word文档中的内容转换成其他格式,如Excel,以便更好地进行数据分析和报告。针对这一需求,我编写了一个Python脚本,能够批量处理指定目录下的Word文档,将其内容结构化并转换…...

【单链表】03 设L为带头结点的单链表,编写算法实现从尾到头反向输出每个结点的值。
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux算法题上机准备 😘欢迎 ❤️关注 👍点赞 🙌收藏 ✍️留言 题目 设L为带头结点的单链表,编写算法实现从尾到头反向输出每个结点的值。 算法…...
鸿蒙开发设备管理:【@ohos.vibrator (振动)】
振动 说明: 开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复制转到。 本模块首批接口从API version 8开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 imp…...

【信息学奥赛】CSP-J/S初赛07 排序算法及其他算法在初赛中的考察
本专栏👉CSP-J/S初赛内容主要讲解信息学奥赛的初赛内容,包含计算机基础、初赛常考的C程序和算法以及数据结构,并收集了近年真题以作参考。 如果你想参加信息学奥赛,但之前没有太多C基础,请点击👉专栏&#…...

第N7周:seq2seq翻译实战-pytorch复现-小白版
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 理论基础 seq2seq(Sequence-to-Sequence)模型是一种用于机器翻译、文本摘要等序列转换任务的框架。它由两个主要的递归神经网络&#…...

java集合(1)
目录 一.集合概述 二. 集合体系概述 1. Collection接口 1.1 List接口 1.2 Set接口 2. Map接口 三. ArrayList 1.ArrayList常用方法 2.ArrayList遍历 2.1 for循环 2.2 增强for循环 2.3 迭代器遍历 一.集合概述 我们经常需要存储一些数据类型相同的元素,之前我们学过…...
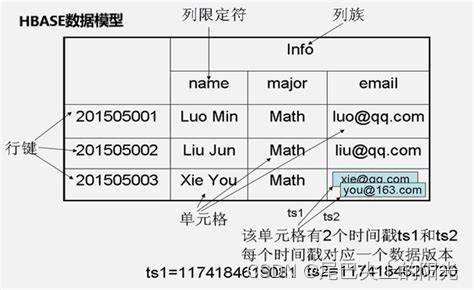
分布式数据库HBase:从零开始了解列式存储
在接触过大量的传统关系型数据库后你可能会有一些新的问题: 无法整理成表格的海量数据该如何储存? 在数据非常稀疏的情况下也必须将数据存储成关系型数据库吗? 除了关系型数据库我们是否还有别的选择以应对Web2.0时代的海量数据? 如果你也曾经想到过这些问题, 那么HBase将是…...

接口测试流程及测试点!
一、什么时候开展接口测试 1.项目处于开发阶段,前后端联调接口是否请求的通?(对应数据库增删改查)--开发自测 2.有接口需求文档,开发已完成联调(可以转测),功能测试展开之前 3.专…...
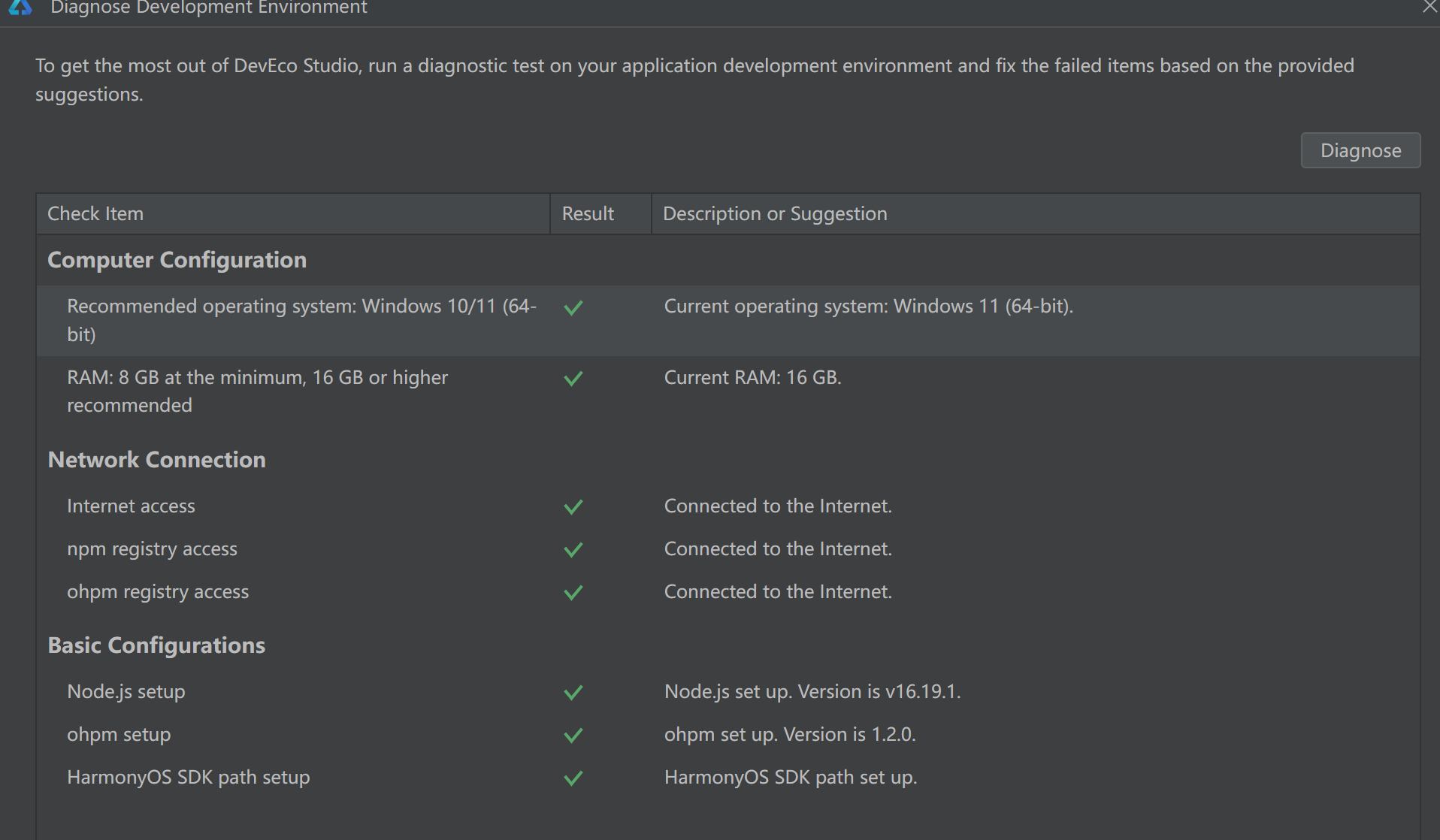
已经安装deveco-studio-4.1.3.500的基础上安装deveco-studio-3.1.0.501
目录标题 1、执行exe文件后安装即可2、双击devecostudio64_3.1.0.501.exe2.1、安装Note (注意和4.1的Note放不同目录)2.2、安装ohpm (注意和4.1版本的ohpm放不同目录)2.3、安装SDK (注意和4.1版本的SDK放不同目录) 1、执行exe文件后安装即可 2、双击devecostudio64_3.1.0.501.e…...

【C++】 解决 C++ 语言报错:Use of Uninitialized Variable
文章目录 引言 使用未初始化的变量(Use of Uninitialized Variable)是 C 编程中常见且危险的错误之一。它通常在程序试图使用尚未赋值的变量时发生,导致程序行为不可预测,可能引发运行时错误、数据损坏,甚至安全漏洞。…...

2024年7月6日 十二生肖 今日运势
小运播报:2024年7月6日,星期六,农历六月初一 (甲辰年庚午月辛未日),法定节假日。 红榜生肖:猪、马、兔 需要注意:狗、鼠、牛 喜神方位:西南方 财神方位:正…...
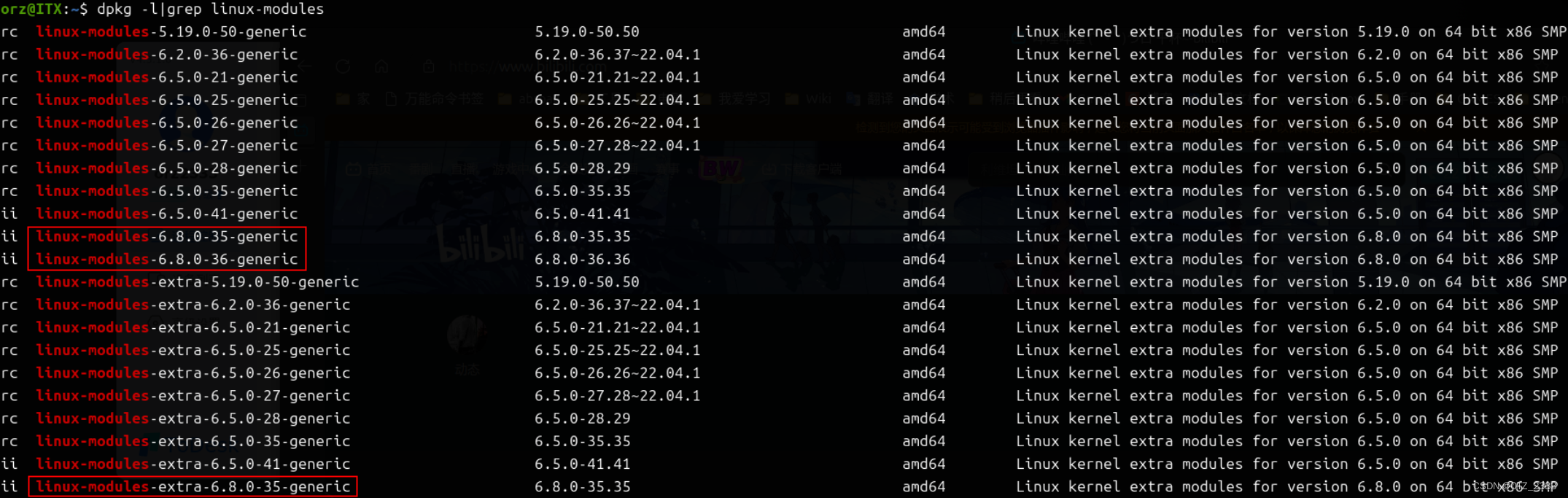
ubuntu丢失网络/网卡的一种原因解决方案
现象 开机进入ubuntu后发现没有网络,无论是在桌面顶部状态栏的快捷键 还是 系统设置中,都没有”有线网“和”无线网“的选项,”代理“的选项是有的使用数据线连接电脑和手机,手机开启”通过usb共享网络“,还是没有任何…...

第6篇 共识机制深度解析:PoW、PoS、DPoS和PBFT
在区块链的世界里,有一个非常重要的概念叫做“共识机制”。它就像是区块链的心脏,保证大家在这条链上的信息是可靠的、不可篡改的。今天,我们就来通俗易懂地聊聊区块链里的四大共识机制:工作量证明(PoW)、权益证明(PoS)、委托权益证明(DPoS)和拜占庭容错(PBFT)。为…...
Windows环境使用SpringBoot整合Minio平替OSS
目录 配置Minio环境 一、下载minio.exe mc.exe 二、设置用户名和密码 用管理员模式打开cmd 三、启动Minio服务器 四、访问WebUI给的地址 SpringBoot整合Minio 一、配置依赖,application.yml 二、代码部分 FileVO MinioConfig MinioUploadService MinioController 三…...

LeetCode 196, 73, 105
目录 196. 删除重复的电子邮箱题目链接表要求知识点思路代码 73. 矩阵置零题目链接标签简单版思路代码 优化版思路代码 105. 从前序与中序遍历序列构造二叉树题目链接标签思路代码 196. 删除重复的电子邮箱 题目链接 196. 删除重复的电子邮箱 表 表Person的字段为id和email…...

在Apache HTTP服务器上配置 TLS加密
安装mod_ssl软件包 [rootlocalhost conf.d]# dnf install mod_ssl -y此时查看监听端口多了一个443端口 自己构造证书 [rootlocalhost conf.d]# cd /etc/pki/tls/certs/ [rootlocalhost certs]# openssl genrsa > jiami.key [rootlocalhost certs]# openssl req -utf8 -n…...

C语言力扣刷题11——打家劫舍1——[线性动态规划]
力扣刷题11——打家劫舍1和2——[线性动态规划] 一、博客声明二、题目描述三、解题思路1、线性动态规划 a、什么是动态规划 2、思路说明 四、解题代码(附注释) 一、博客声明 找工作逃不过刷题,为了更好的督促自己学习以及理解力扣大佬们的解…...
房屋租赁管理小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,中介管理,房屋信息管理,房屋类型管理,租房订单管理,租房信息管理 微信端账号功能包括:系统首页,房屋信息&am…...

oracle sql语句 排序 fjd = ‘0101‘ 排在 fjd = ‘0103‘ 的前面
要实现这个排序需求,你可以使用 CASE 表达式来自定义排序逻辑。假设你有一个表格名为 your_table,并且有一个字段 fjd 存储类似 ‘0101’, ‘0103’ 这样的值,你可以这样编写 SQL 查询: SELECT * FROM your_table ORDER BY CASE …...
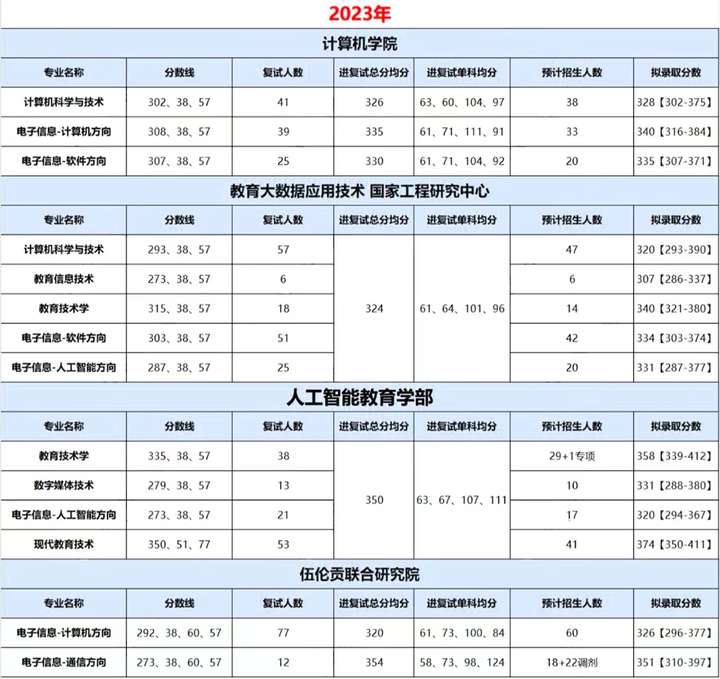
初试成绩占比百分之70!计算机专硕均分340+!华中师范大学计算机考研考情分析!
华中师范大学(Central China Normal University)简称“华中师大”或“华大”,位于湖北省会武汉,是中华人民共和国教育部直属重点综合性师范大学,国家“211工程”、“985工程优势学科创新平台”重点建设院校,…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...
函数的计算原理(附绘图代码))
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码)
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码) 在数学和工程领域,复数不仅是抽象的概念,更是解决实际问题的有力工具。当我们谈论复数68j时,它不仅仅是一个符号组合——在…...