从0开始学习pyspark--Spark DataFrame数据的选取与访问[第5节]
在PySpark中,选择和访问数据是处理Spark DataFrame的基本操作。以下是一些常用的方法来选择和访问DataFrame中的数据。
- 选择列(Selecting Columns):
select: 用于选择DataFrame中的特定列。selectExpr: 用于通过SQL表达式选择列。
df.select('name', 'age') # 选择'name'和'age'列 df.select(df.name, df.age + 10) # 选择'name'列和'age'列加10 df.selectExpr('name', 'age + 10 as age_plus_10') # 使用SQL表达式选择列 - 筛选行(Filtering Rows):
filter: 用于根据指定条件筛选DataFrame中的行。
df.filter(df.age > 30) # 筛选年龄大于30的行 df.filter((df.age > 30) & (df.gender == 'male')) # 筛选年龄大于30且性别为男的行 - 排序数据(Sorting Data):
orderBy: 用于根据指定列排序DataFrame。sort: 与orderBy类似,用于排序DataFrame。
df.orderBy('age', ascending=False) # 按年龄降序排序 df.sort(df.age.desc()) # 按年龄降序排序 - 抽样数据(Sampling Data):
sample: 用于对DataFrame进行随机抽样。
df.sample(0.5, seed=42) # 抽取50%的数据,随机种子为42 - distinct 数据(Distinct Data):
distinct: 用于去除DataFrame中的重复行。
df.distinct() # 去除重复行 - 随机分割数据(Randomly Splitting Data):
randomSplit: 用于将DataFrame随机分割成多个DataFrame。
df.randomSplit([0.7, 0.3], seed=42) # 将数据随机分割为70%和30% - 列操作(Column Operations):
withColumn: 用于添加或替换DataFrame中的列。withColumnRenamed: 用于重命名DataFrame中的列。
df.withColumn('age_plus_10', df.age + 10) # 添加新列'age_plus_10' df.withColumnRenamed('old_name', 'new_name') # 重命名列 - 聚合数据(Aggregating Data):
groupBy: 用于对DataFrame进行分组。agg: 用于对分组后的DataFrame进行聚合操作。
df.groupBy('gender').agg({'age': 'mean'}) # 按性别分组并计算平均年龄 - 窗口函数(Window Functions):
window: 用于创建一个窗口 specification,用于窗口函数的计算。over: 用于指定窗口函数的应用范围。
from pyspark.sql.window import Window windowSpec = Window.partitionBy('gender').orderBy('age') df.withColumn('row_number', row_number().over(windowSpec)) # 计算行号 - 集合操作(Set Operations):
union: 合并两个DataFrame,去除重复行。unionAll: 合并两个DataFrame,不去除重复行。intersect: 获取两个DataFrame的交集。except: 获取两个DataFrame的差集。
df1.union(df2) # 合并df1和df2,去除重复行 df1.unionAll(df2) # 合并df1和df2,不去除重复行 - 访问数据(Accessing Data):
collect: 将DataFrame的数据作为一个Python列表返回。take: 返回DataFrame中的前几行。show: 显示DataFrame的内容。
df.collect() # 返回DataFrame的所有数据 df.take(5) # 返回DataFrame的前5行 df.show() # 显示DataFrame的内容
这些是PySpark中选择和访问数据的一些基本操作。你可以根据需要组合使用这些操作来处理和分析数据。
相关文章:

从0开始学习pyspark--Spark DataFrame数据的选取与访问[第5节]
在PySpark中,选择和访问数据是处理Spark DataFrame的基本操作。以下是一些常用的方法来选择和访问DataFrame中的数据。 选择列(Selecting Columns): select: 用于选择DataFrame中的特定列。selectExpr: 用于通过SQL表达式选择列。 df.select…...

Fastjson首字母大小写问题
1、问题 使用Fastjson转json之后发现首字母小写。实体类如下: Data public class DataIdentity {private String BYDBSM;private String SNWRSSJSJ;private Integer CJFS 20; } 测试代码如下: public static void main(String[] args) {DataIdentit…...

GuLi商城-商品服务-API-品牌管理-效果优化与快速显示开关
<template><div class"mod-config"><el-form :inline"true" :model"dataForm" keyup.enter.native"getDataList()"><el-form-item><el-input v-model"dataForm.key" placeholder"参数名&qu…...

如何成为C#编程高手?
成为C#编程高手需要时间、实践和持续的学习。以下是一些建议,可以帮助你提升C#编程技能: 深入理解基础知识: 确保你对C#的基本语法、数据类型、控制结构、面向对象编程(OOP)原则有深刻的理解。学习如何使用Visual Stud…...
SpringBoot学习06-[SpringBoot与AOP、SpringBoot自定义starter]
SpringBoot自定义starter SpringBoot与AOPSpringBoot集成Mybatis-整合druid在不使用启动器的情况下,手动写配置类进行整合使用启动器的情况下,进行整合 SpringBoot启动原理源码解析创建SpringApplication初始化SpringApplication总结 启动 SpringBoot自定义Starter定…...

Maven - 在没有网络的情况下强制使用本地jar包
文章目录 问题解决思路解决办法删除 _remote.repositories 文件代码手动操作步骤验证 问题 非互联网环境,无法从中央仓库or镜像里拉取jar包。 服务器上搭建了一套Nexus私服。 Nexus私服故障,无法连接。 工程里新增了一个Jar的依赖, 本地仓…...
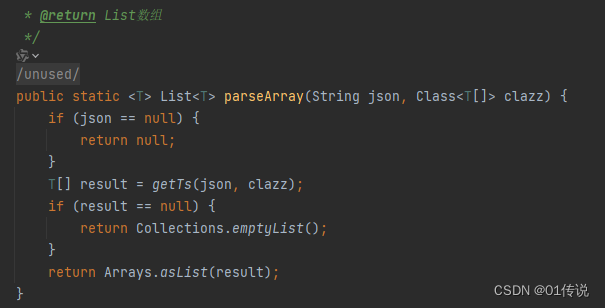
JAVA--JSON转换工具类
JSON转换工具类 import com.alibaba.fastjson.JSONObject; import com.fasterxml.jackson.annotation.JsonInclude; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.DeserializationFeature; import com.fasterxml.jackso…...

每日复盘-20240705
今日关注: 20240705 六日涨幅最大: ------1--------300391--------- 长药控股 五日涨幅最大: ------1--------300391--------- 长药控股 四日涨幅最大: ------1--------300391--------- 长药控股 三日涨幅最大: ------1--------300391--------- 长药控股 二日涨幅最…...

MySQL 一些用来做比较的函数
目录 IF:根据不同条件返回不同的值 CASE:多条件判断,类似于Switch函数 IFNULL:用于检查一个值是否为NULL,如果是,则用指定值代替 NULLIF:比较两个值,如果相等则返回NULLÿ…...

一个使用率超高的大数据实验室是如何练成的?
厦门大学嘉庚学院“大数据应用实训中心”(以下简称“实训中心”)自2022年建成以来,已经成为支撑“大数据专业”复合型人才培养的重要支撑,目前实训中心在专业课程实验教学、项目实训、数据分析类双创比赛、毕业设计等方面都有深入…...
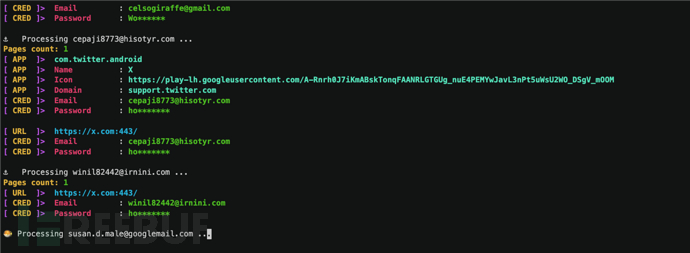
Chiasmodon:一款针对域名安全的公开资源情报OSINT工具
关于Chiasmodon Chiasmodon是一款针对域名安全的公开资源情报OSINT工具,该工具可以帮助广大研究人员从各种来源收集目标域名的相关信息,并根据域名、Google Play应用程序、电子邮件地址、IP地址、组织和URL等信息进行有针对性的数据收集。 该工具可以提…...

如何在Java中实现PDF生成
如何在Java中实现PDF生成 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在软件开发和企业应用中,生成PDF文档是一项常见的需求。Java作为一种强大…...

Redis 的缓存淘汰策略
Redis 作为一个高性能的内存数据库,提供了多种缓存淘汰策略(也称为过期策略或驱逐策略),用于管理内存使用。当 Redis 达到其内存限制时,系统会根据配置的策略删除一些数据,以释放内存空间。以下是 Redis 支…...

音乐播放器
目录 一、设计目标二、实现流程1. 数据库操作2. 后端功能实现3. 前端UI界面实现4. 程序入口 三、项目收获 一、设计目标 1. 模拟网易云音乐,实现本地音乐盒。 2. 功能分析: 登录功能窗口显示加载本地音乐建立播放列表播放音乐删除播放列表音乐 3.设计思…...

三星组件新的HBM开发团队加速HBM研发
为应对人工智能(AI)市场扩张带来的对高性能存储解决方案需求的增长,三星电子在其设备解决方案(DS)部门内部成立了全新的“HBM开发团队”,旨在提升其在高带宽存储器(HBM)领域的竞争力。根据Business Korea的最新报告,该团队将专注于推进HBM3、…...

图书馆数据仓库
目录 1.数据仓库的数据来源为业务数据库(mysql) 初始化脚本 init_book_result.sql 2.通过sqoop将mysql中的业务数据导入到大数据平台(hive) 导入mysql数据到hive中 3.通过hive进行数据计算和数据分析 形成数据报表 4.再通过sq…...
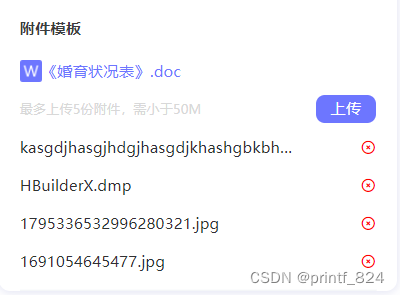
基于uniapp(vue3)H5附件上传组件,可限制文件大小
代码: <template><view class"upload-file"><text>最多上传5份附件,需小于50M</text><view class"" click"selectFile">上传</view></view><view class"list" v…...

Phoenix Omid Timestamp Oracle 组件实现原理
Omid Timestamp Oracle 组件实现原理 作用 生成全局单调递增的时间戳,支持获取操作和崩溃恢复。 功能 1.生成全局单调递增的时间戳(支持崩溃恢复)apinext返回下一个时间戳getLast返回最后一个分配的时间戳(当前时间戳)实现方式TimestampOracleImpl单调递增的时间…...

Lex Fridman Podcast with Andrej Karpathy
我不太喜欢Lex Fridman的声音,总觉得那让人昏昏欲睡, 但无奈他采访的人都太大牌了,只能去听。但是听着听着,就会觉得有深度的采访这些人,似乎也只有他这种由研究员背景的人能干, 另,他提的问题确…...

力扣1895.最大的幻方
力扣1895.最大的幻方 求前缀和暴力枚举幻方边长 求行列前缀和 class Solution {public:int largestMagicSquare(vector<vector<int>>& grid) {int n grid.size() , m grid[0].size();vector<vector<int>> rowsum(n,vector<int>(m));for…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

JavaScript对象创建:告别繁琐,四种灵活写法一学就会
在JavaScript里,创建对象的这般方法常把刚开始学习的新手弄得困惑不已,好像无论走哪条道都行得通,可又不清楚该挑哪一条才好。我编写JavaScript都有十几年功夫了,对象创建这事差不多每天都会碰到可谓基础技能。它不像变量声明那般…...

鸿蒙HarmonyOS 5与Unity跨运行时通信实战指南
1. 这不是“调个API”那么简单:为什么鸿蒙Unity通信总在临门一脚卡住我第一次把Unity打包的AR模块塞进HarmonyOS 5 App里时,信心满满——毕竟文档里写着“支持JS/ArkTS调用Native能力”,Unity也标榜“跨平台通用”。结果呢?App一启…...

Qri入门教程:如何在5分钟内开始使用分布式数据集版本控制
Qri入门教程:如何在5分钟内开始使用分布式数据集版本控制 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一款强大的分布式数据集版本控制工具,它比电子表格更强大,比数…...