G9 - ACGAN理论与实战
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目录
- 环境
- 步骤
- 环境设置
- 数据准备
- 工具方法
- 模型设计
- 模型训练
- 模型效果展示
- 总结与心得体会
上周已经简单的了解了ACGAN的原理,并且不经实践的编写了部分代码,这周复现一下真正的ACGAN
环境
Pytorch: 2.3.1+cu121
Nvidia GTX 4090
步骤
环境设置
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torchvision.utils import save_imagefrom torch.utils.data import DataLoader
from torch.autograd import Variable
import numpy as npdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 全局参数
n_epochs = 200
batch_size = 64
lr = 0.0002
b1 = 0.5
b2 = 0.999
n_cpu = 8
latent_dim = 100
n_classes = 10
img_size = 32
channels = 1
sample_interval = 400
数据准备
# 创建中间采样图片的文件夹
import os
os.makedirs('images', exist_ok=True)
# 配置数据集
os.makedirs('data/mnist', exist_ok=True)
dataloader = DataLoader(datasets.MNIST('data/mnist',train=True,download=True,transform=transforms.Compose([transforms.Resize(img_size),transforms.ToTensor(),transforms.Normalize([0.5], [0.5])]),),batch_size=batch_size,shuffle=True,
)工具方法
# 权重初始化函数
def weights_init_normal(m):classname = m.__class__.__name__if classname.find('Conv') != -1:torch.nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find('BatchNorm2d') != -1:torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.constant_(m.bias.data, 0.0)# 日志函数 因为使用了jupyter notebook环境,长时间的任务日志无法直接查看,于是需要打印到文件
import logging
import sys
import datetimedef init_logger(filename, logger_name):'''@brief:initialize logger that redirect info to a file just in case we lost connection to the notebook@params:filename: to which file should we log all the infologger_name: an alias to the logger'''# get current timestamptimestamp = datetime.datetime.utcnow().strftime('%Y%m%d_%H-%M-%S')logging.basicConfig(level=logging.INFO, format='[%(asctime)s] %(name)s {%(filename)s:%(lineno)d} %(levelname)s - %(message)s',handlers=[logging.FileHandler(filename=filename),logging.StreamHandler(sys.stdout)])# Testlogger = logging.getLogger(logger_name)logger.info('### Init. Logger {} ###'.format(logger_name))return logger# Initialize
my_logger = init_logger("./ml_notebook.log", "ml_logger")# 生成函数的结果保存
def sample_image(n_row, batches_done):"""保存从0到n_classes的生成数字的图像风格"""# 采样噪声z = torch.randn((n_row**2, latent_dim), device=device)# 为n行生成标签从0到n_classeslabels = torch.tensor([num for _ in range(n_row) for num in range(n_row)], device=device)gen_imgs = generator(z, labels)save_image(gen_imgs.data.cpu(), 'images/%d.png' % batches_done, nrow=n_row, normalize=True)
模型设计
# 生成器
class Generator(nn.Module):def __init__(self):super().__init__()# 标签嵌入self.label_emb = nn.Embedding(n_classes, latent_dim)# 计算上采样前的初始大小self.init_size = img_size // 4# 第一层线性层self.l1 = nn.Sequential(nn.Linear(latent_dim, 128*self.init_size**2))# 卷积层self.conv_blocks = nn.Sequential(nn.BatchNorm2d(128),nn.Upsample(scale_factor=2),nn.Conv2d(128, 128, 3, stride=1, padding=1),nn.BatchNorm2d(128, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, stride=1, padding=1),nn.BatchNorm2d(64, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, channels, 3, stride=1, padding=1),nn.Tanh(),)def forward(self, noise, labels):# 标签嵌入到噪声中gen_input = torch.mul(self.label_emb(labels), noise)# 通过第一层线性层out = self.l1(gen_input)# 整形out = out.view(out.shape[0], 128, self.init_size, self.init_size)# 卷积生成图像img = self.conv_blocks(out)return img
# 判别器
class Discriminator(nn.Module):def __init__(self):super().__init__()# 判别器块生成函数def discriminator_block(in_filters, out_filters, bn=True):"""返回每个判别器层"""block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))return block# 卷积层self.conv_blocks = nn.Sequential(*discriminator_block(channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)# 下采样后,图像的宽高ds_size = img_size // 2 ** 4# 输出层self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, n_classes), nn.Softmax())def forward(self, img):out = self.conv_blocks(img)out = out.view(out.shape[0], -1)validity = self.adv_layer(out)label = self.aux_layer(out)return validity, label# 模型初始化# 损失函数
adversarial_loss = nn.BCELoss()
auxiliary_loss = nn.CrossEntropyLoss()# 初始化生成器和判别器
generator = Generator().to(device)
discriminator = Discriminator().to(device)# 初始化权重
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
模型训练
# 训练# 优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))for epoch in range(n_epochs):for i, (imgs, labels) in enumerate(dataloader):batch_size = imgs.shape[0]# 图像是 真实的 标签valid = torch.ones((batch_size, 1), requires_grad=False, device=device)# 图像是 生成的 标签fake = torch.zeros((batch_size, 1), requires_grad=False, device=device)real_imgs = imgs.to(device)labels = labels.to(device)# 训练生成器optimizer_G.zero_grad()# 采样噪声和标签作为生成器的输入z = torch.randn((batch_size, latent_dim), device=device)gen_labels = torch.randint(0, 1, (batch_size,), device=device)# 生成一批图像gen_imgs = generator(z, gen_labels)# 损失度量 生成器欺骗判别器的能力validity, pred_label = discriminator(gen_imgs)g_loss = 0.5 * (adversarial_loss(validity, valid) + auxiliary_loss(pred_label, gen_labels))g_loss.backward()optimizer_G.step()# 训练判别器optimizer_D.zero_grad()# 真实图像的损失real_pred, real_aux = discriminator(real_imgs)d_real_loss = 0.5 * (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels))# 生成图像的损失fake_pred, fake_aux = discriminator(gen_imgs.detach())d_fake_loss = 0.5 * (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, gen_labels))# 判别器的总损失d_loss = 0.5 * (d_real_loss + d_fake_loss)# 计算判别器的准确率pred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)gt = np.concatenate([labels.data.cpu().numpy(), gen_labels.data.cpu().numpy()], axis=0)d_acc = np.mean(np.argmax(pred, axis=1) == gt)d_loss.backward()optimizer_D.step()if i % 100 == 0:my_logger.info("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]" % (epoch, n_epochs, i, len(dataloader), d_loss.item(), 100 * d_acc, g_loss.item()))batches_done = epoch * len(dataloader) + iif batches_done % sample_interval == 0:sample_image(n_row=10, batches_done=batches_done)

模型效果展示


总结与心得体会
通过对模型的复现,发现我之前对判别器的理解有偏差,如果在判别器的输入中插入分类信息,等于是将答案直接给了判别器,生成的结果反而不会太好。还有一个和我预想的不一样的地方,在生成器中,将标签嵌入到特征向量使用了矩阵乘法,而没有直接使用concatenate操作。
相关文章:
G9 - ACGAN理论与实战
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目录 环境步骤环境设置数据准备工具方法模型设计模型训练模型效果展示 总结与心得体会 上周已经简单的了解了ACGAN的原理,并且不经实践的编写了部分…...
合合信息大模型“加速器”亮相2024世界人工智能大会,助力大模型学好“专业课”
7月4日至7日,2024世界人工智能大会在上海拉开帷幕。现阶段,“百模大战”现象背后的中国大模型发展前景与堵点仍然是各界关注的焦点。如何帮助大模型在信息的海洋中快速找准航向,在数据的荒漠中找到高质量的“水源”?合合信息在本次…...

bond网络配置文件中 interface-name 与 id 的区别
在bond网络配置文件中,interface-name和id是两个不同的参数,它们有如下区别: interface-name:该参数用于指定bond设备所使用的物理网卡接口的名称。可以设置一个或多个接口名称,多个接口名称之间使用逗号分隔。例如&am…...
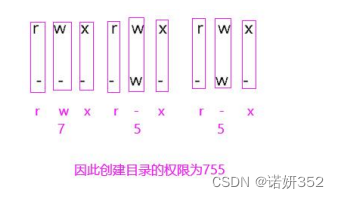
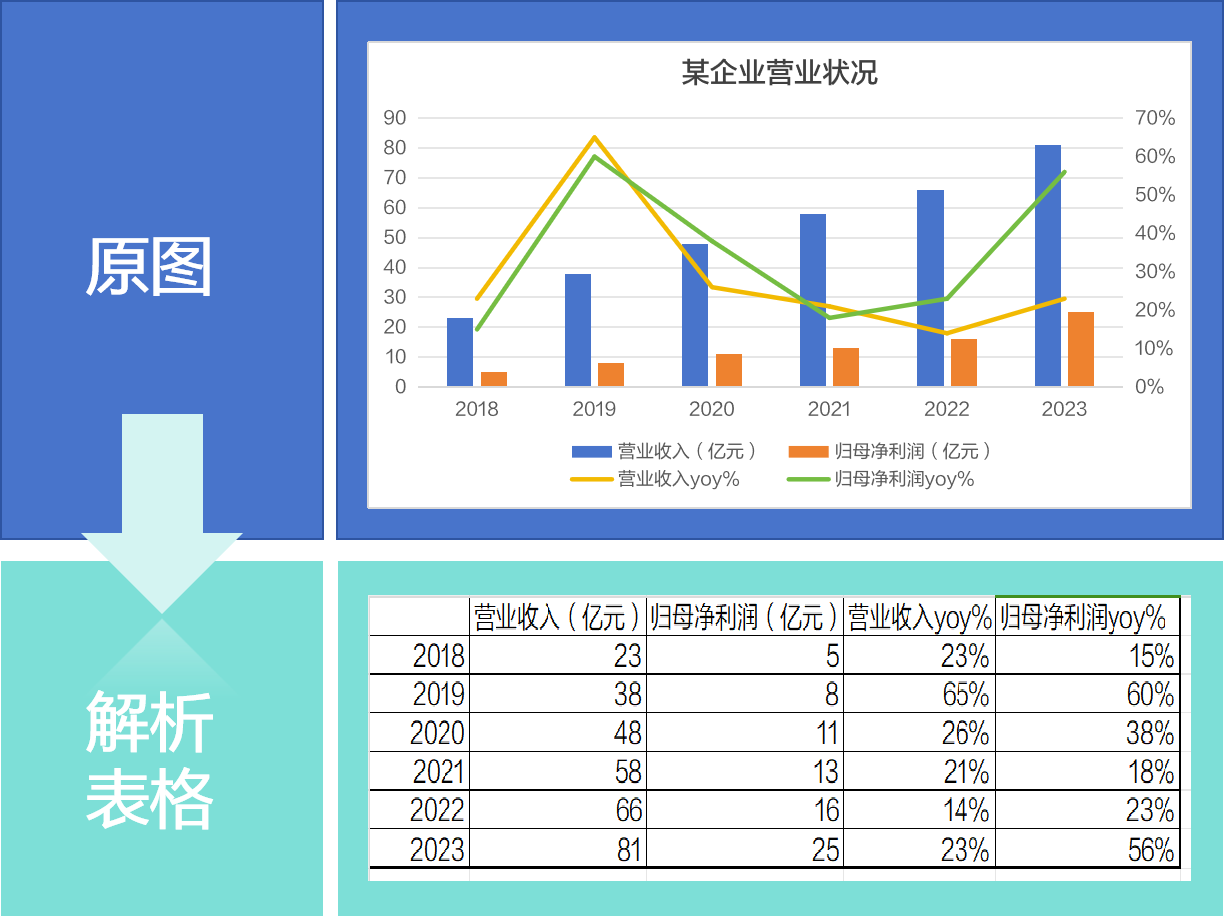
Linux权限概述
一、权限概述 1.权限的基本概念 2.为什么要设置权限 3.linux用户的身份类别 4.user文件的拥有者 5.group文件所属组内用户 6.other其他用户 7.特殊用户root 二、普通权限管理 1.ls -l查看文件权限 2.文件类型以及权限解析 3.文件或文件夹的权限设置 4.通过数字给文件…...

谷粒商城学习-09-配置Docker阿里云镜像加速及各种docker问题记录
文章目录 一,配置Docker阿里云镜像加速二,Docker安装过程中的几个问题1,安装报错:Could not resolve host: mirrorlist.centos.org; Unknown error1.1 检测虚拟机网络1.2 重设yum源 2,报错:Could not fetch…...

基于GWO灰狼优化的多目标优化算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 4.1灰狼优化算法原理 4.2 多目标优化问题(MOP)的帕累托最优解 4.3 基于GWO的多目标优化算法 5.完整程序 1.程序功能描述 基于GWO灰狼优化的多目标优化算法matlab仿真,目标函数…...

排序算法-java版本
冒泡排序 原理:相邻的数据两两比较,小的放前面,大的放后面 int[] arr{3,5,2,1,4} for(int i0;i<arr.length-1;i){for(int j0;j<arr.length-1-i;j){if(arr[j]>arr[j1]){int temparr[j];arr[j]arr[j1];arr[j1]temp;}}}选择排序 升序…...

Java+前后端分离架构+ MySQL8.0.36产科信息管理系统 产科电子病历系统源码
Java前后端分离架构 MySQL8.0.36产科信息管理系统 产科电子病历系统源码 产科信息管理系统—住院管理 数字化产科住院管理是现代医院管理中的重要组成部分,它利用数字化技术优化住院流程,提升医疗服务质量和效率。以下是对数字化产科住院管理的详细阐述…...

js使用websocket,vue使用websocket,copy即用
新建一个文件 websocket.js // 定义websocket 地址 let socketurlDev "ws://192.000.0.0:8085/websocket/admin/"; //开发环境 let socketurlProd "wss://123456789.cn/prod-api/websocket/admin/"; //正式环境// 重连锁, 防止过多重连 let reconnectLo…...
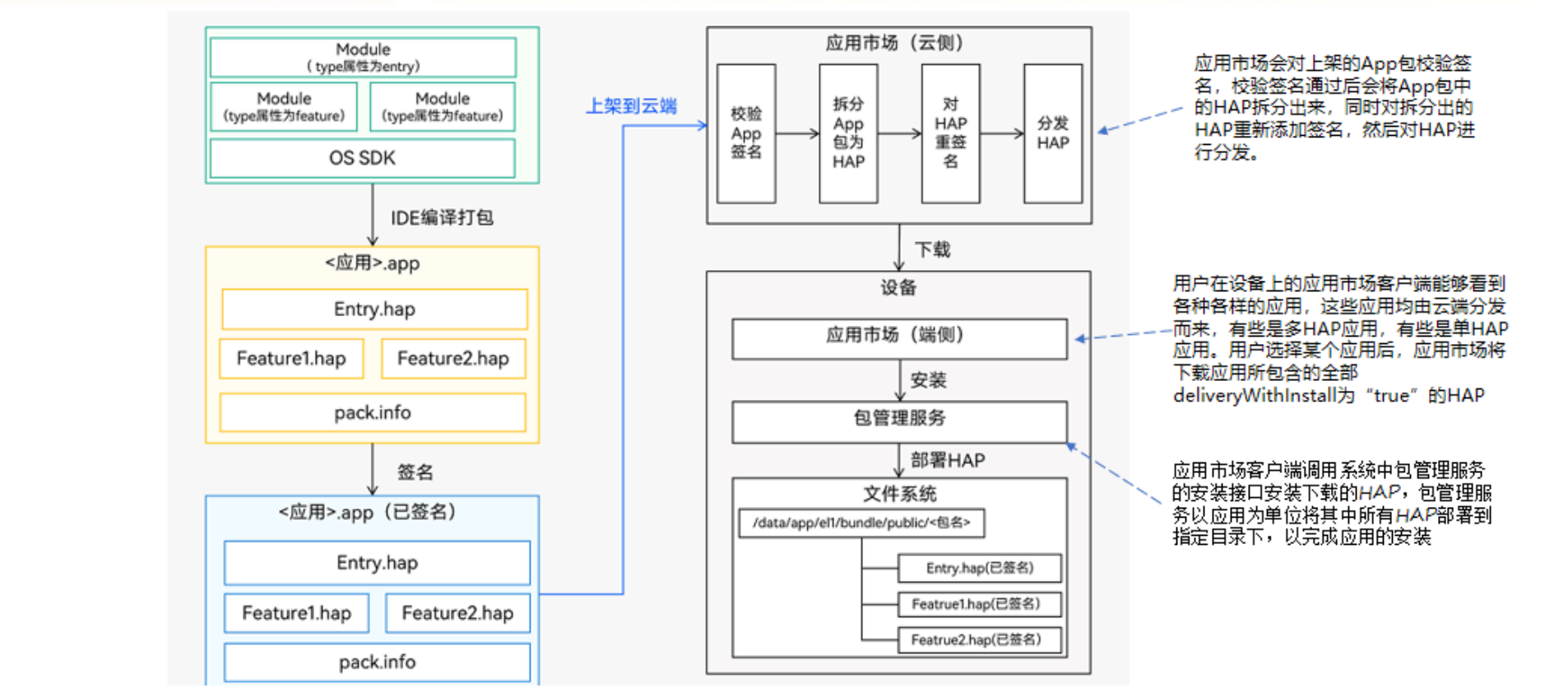
【鸿蒙学习笔记】Stage模型工程目录
官方文档:应用配置文件概述(Stage模型) 目录标题 FA模型和Stage模型工程级目录模块级目录app.json5module.json5程序执行流程程序基本结构开发调试与发布流程 FA模型和Stage模型 工程级目录 模块级目录 app.json5 官方文档:app.j…...

算法基础-----【动态规划】
动态规划(待完善) 动规五部曲分别为: 确定dp数组(dp table)以及下标的含义确定递推公式(状态转移公式)dp数组如何初始化确定遍历顺序举例推导dp数组、 动态规划的核心就是递归剪枝(存储键值,…...

Java中的响应式编程与Reactor框架
Java中的响应式编程与Reactor框架 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 响应式编程(Reactive Programming)是一种面向数据流…...
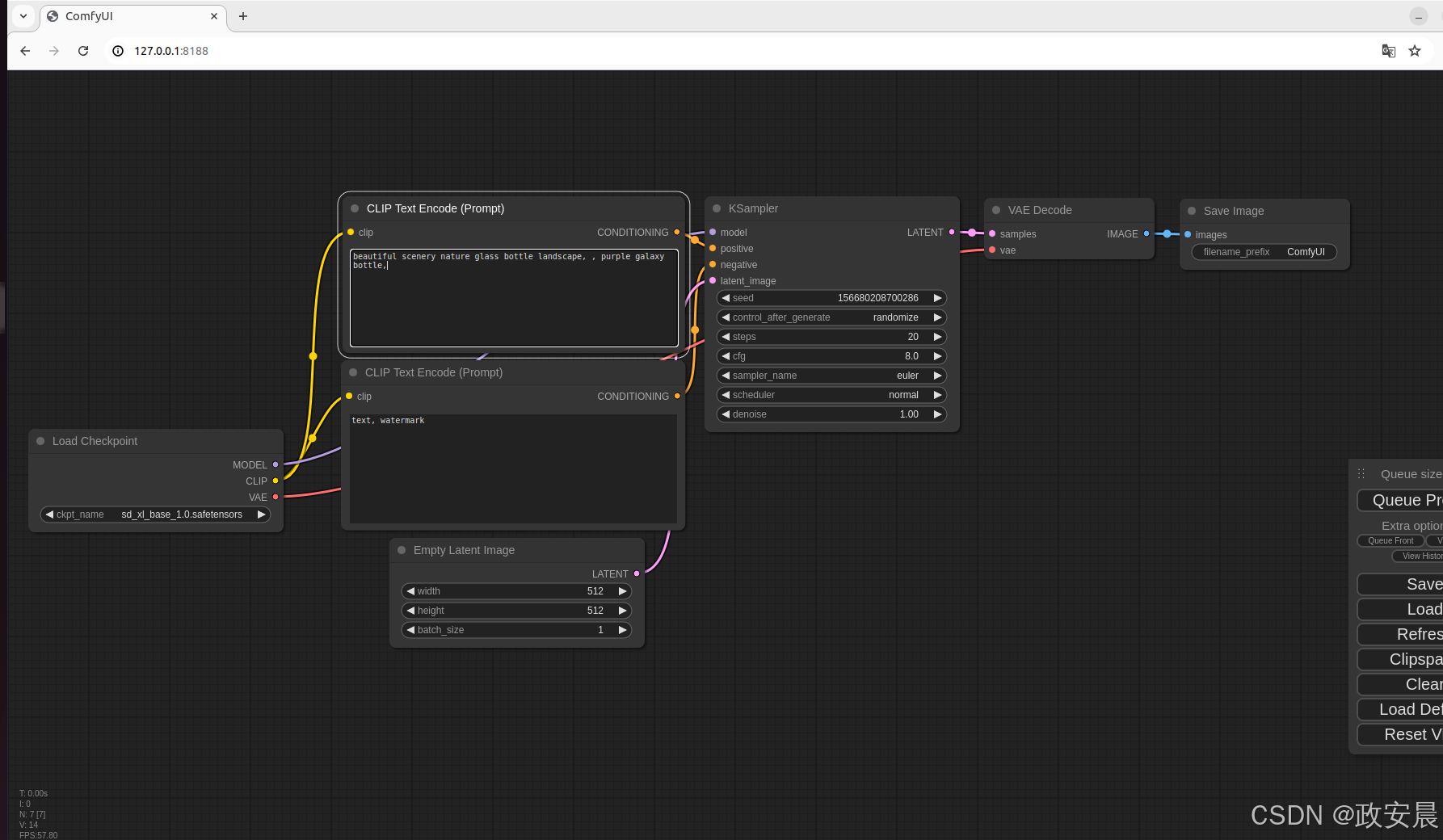
政安晨【零基础玩转各类开源AI项目】基于Ubuntu系统部署ComfyUI:功能最强大、模块化程度最高的Stable Diffusion图形用户界面和后台
目录 ComfyUI的特性介绍 开始安装 做点准备工作 在Conda虚拟环境中进行 依赖项的安装 运行 政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: 零基础玩转各类开源AI项目 希望政安晨的博客能够对您有所裨益,如有不足之处&…...

匿名内部类
下面代码中,Person24 是一个抽象类,这意味着它不能被直接实例化,只能通过继承它的子类来实现其抽象方法。代码片段中展示了如何使用匿名内部类来实现一个抽象类的实例。 package chapter04;public class Java24_Object_匿名内部类 {public s…...

react_web自定义组件_多类型Modal_搜索栏Search
目录 一、带输入框的Modal 二、提示框Modal 三、搜索栏Search 在做项目时引入一些现成的UI组件,但是如果和设计图冲突太大,更改时很麻烦,如果自己写一个通用组件其实也就几十分钟或者几个小时,而且更具UI设计更改也比较好更改&…...

Apache Flink架构介绍
目录 一、Apache Flink架构组件栈 1.1 概述 1.2 架构图 1.3 架构分层组件说明 1.3.1 物理部署层 1.3.2 Runtime 核心层 1.3.3 API & Libraries层 二、Flink运行时架构 2.1 概述 2.2 架构图 2.3 架构角色和组件 2.3.1 Flink Clients客户端 2.3.2 JobManager 2.…...

华为HCIP Datacom H12-821 卷28
1.单选题 下面是一台路由器的部分配置,关于该部分配置描述正确的是,[HUAWEI]ip ip-prefx pl permit 10.0.192.0 8greater-equal17 less-equal 18 A、10.0.192.0/8网段内,掩码长度为18的路由会匹配到该前缀列表,匹配规则为允许 B、10.0.192.0/8网段内掩码长度为21的路…...

安装Nginx以及简单使用 —— windows系统
一、背景 Nginx是一个很强大的高性能Web和反向代理服务,也是一种轻量级的Web服务器,可以作为独立的服务器部署网站,应用非常广泛,特别是现在前后端分离的情况下。而在开发过程中,我们常常需要在window系统下使用Nginx作…...

【UE5.3】笔记8 添加碰撞,检测碰撞
添加碰撞 打开BP_Food,添加Box Collision组件,与unity类似: 调整Box Collision的大小到刚好包裹物体,通过调整缩放和盒体范围来控制大小,一般先调整缩放找个大概大小,然后调整盒体范围进行微调。 碰撞检测 添加好碰撞…...

丝滑流畅!使用kimi快速完成论文仿写
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 今天的分享,我们将带大家探索一种新的学术写作技巧——使用Kimi进行论文仿写。本文将深入解析如何利用Kimi的智能辅助功能,提高论文写作的效率和质量,…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...