动手学深度学习(Pytorch版)代码实践 -循环神经网络-54~55循环神经网络的从零开始实现和简洁实现
54循环神经网络的从零开始实现

import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import matplotlib.pyplot as plt
import liliPytorch as lp# 读取H.G.Wells的时光机器数据集
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)# 查看数据集
# for X, Y in train_iter:
# print('X:', X.shape)
# print('Y:', Y.shape)
# print(vocab.token_freqs)
# print(vocab.idx_to_token)
# print(vocab.token_to_idx)# 独热编码
# 将每个索引映射为相互不同的单位向量: 假设词表中不同词元的数目为N(即len(vocab)), 词元索引的范围为0
# 到N-1。 如果词元的索引是整数i, 那么我们将创建一个长度为N的全0向量, 并将第i处的元素设置为1。
# 此向量是原始词元的一个独热向量。
# print(F.one_hot(torch.tensor([0,3,6]), len(vocab)))
"""
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0],[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
"""# 每次采样的小批量数据形状是二维张量: (批量大小,时间步数)。
# one_hot函数将这样一个小批量数据转换成三维张量, 张量的最后一个维度等于词表大小(len(vocab))。
# 我们经常转换输入的维度,以便获得形状为 (时间步数,批量大小,词表大小)的输出。
# 这将使我们能够更方便地通过最外层的维度, 一步一步地更新小批量数据的隐状态。# X = torch.arange(10).reshape((2, 5))
# print(X)
# tensor([[0, 1, 2, 3, 4],
# [5, 6, 7, 8, 9]])
# print(X.T)
# tensor([[0, 5],
# [1, 6],
# [2, 7],
# [3, 8],
# [4, 9]])
# print(F.one_hot(X.T, 28).shape) # torch.Size([5, 2, 28])
# print(F.one_hot(X.T, 28))
"""
tensor([[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0]],[[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0]],[[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0]],[[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0]],[[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0]]])
"""# 初始化模型参数
def get_params(vocab_size, num_hiddens, device):# 设置输入和输出的数量为词汇表的大小num_inputs = num_outputs = vocab_size# 定义一个函数,用于以正态分布初始化权重def normal(shape):return torch.randn(size=shape, device=device) * 0.01# 初始化隐藏层参数W_xh = normal((num_inputs, num_hiddens)) # 输入到隐藏层的权重W_hh = normal((num_hiddens, num_hiddens)) # 隐藏层到隐藏层的权重(循环权重)b_h = torch.zeros(num_hiddens, device=device) # 隐藏层的偏置# 初始化输出层参数W_hq = normal((num_hiddens, num_outputs)) # 隐藏层到输出层的权重b_q = torch.zeros(num_outputs, device=device) # 输出层的偏置# 将所有参数收集到一个列表中params = [W_xh, W_hh, b_h, W_hq, b_q]# 设置每个参数的requires_grad属性为True,以便在反向传播期间计算梯度for param in params:param.requires_grad_(True)return params # 返回参数列表# 循环神经网络模型
# 初始化时返回隐状态
def init_rnn_state(batch_size, num_hiddens, device):# batch_size:批量的大小,即每次输入到RNN的序列数量。# num_hiddens:隐藏层单元的数量,即隐藏状态的维度。return (torch.zeros((batch_size, num_hiddens), device=device), ) # 返回一个包含一个张量的元组def rnn(inputs, state, params):# inputs的形状:(时间步数量,批量大小,词表大小)# state:初始隐藏状态,通常是一个元组,包含隐藏层的状态。# params:RNN的参数,包含权重和偏置。W_xh, W_hh, b_h, W_hq, b_q = paramsH, = state # 当前的隐藏状态。outputs = []# X的形状:(批量大小,词表大小)for X in inputs:H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)# 存储从零开始实现的循环神经网络模型的参数
class RNNModelScratch: #@save"""从零开始实现的循环神经网络模型"""def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state): # 前向传播方法X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device): # 初始化隐藏状态return self.init_state(batch_size, self.num_hiddens, device)# X = torch.arange(10).reshape((2, 5))
num_hiddens = 512
# net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
# init_rnn_state, rnn)
# state = net.begin_state(X.shape[0], d2l.try_gpu()) # 初始化隐藏状态
# 调用模型实例的 __call__ 方法执行前向传播。
# Y, new_state = net(X.to(d2l.try_gpu()), state)
# Y:模型输出。
# new_state:更新后的隐藏状态。# print(Y.shape, len(new_state), new_state[0].shape)
# torch.Size([10, 28]) 1 torch.Size([2, 512])
# 输出形状是(时间步数 X 批量大小,词表大小), 而隐状态形状保持不变,即(批量大小,隐藏单元数)def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符prefix:生成文本的前缀,即初始输入字符序列。num_preds:要预测的字符数。net:训练好的循环神经网络模型。vocab:词汇表,包含字符到索引和索引到字符的映射。"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]] # outputs:用于存储生成字符的索引列表。get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))for y in prefix[1:]: # 预热期,遍历前缀中的剩余字符(从第二个字符开始)。_, state = net(get_input(), state) # 调用 net 进行前向传播,更新隐藏状态 state。outputs.append(vocab[y]) # 将当前字符的索引添加到 outputs 中。for _ in range(num_preds): # 预测num_preds步# 调用 net 进行前向传播,获取预测结果 y 和更新后的隐藏状态 state。y, state = net(get_input(), state)# 使用 y.argmax(dim=1) 获取预测的字符索引,并将其添加到 outputs 中。outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])# print(predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu()))
# time traveller cfjwsthaqc# 梯度裁剪
"""
在训练深层神经网络(特别是循环神经网络)时,梯度爆炸(gradients exploding)问题会导致梯度值变得非常大,
从而导致模型不稳定甚至训练失败。为了防止梯度爆炸,可以对梯度进行裁剪,使得梯度的范数不超过某个预设的阈值。
"""
def grad_clipping(net, theta): #@save"""裁剪梯度net:神经网络模型。theta:梯度裁剪的阈值。"""if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad]else:params = net.params# 计算梯度范数, L2 范数norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta:for param in params:param.grad[:] *= theta / norm# 将每个参数的梯度按比例缩放,使得新的梯度范数等于 theta。# 训练
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):"""训练网络一个迭代周期(定义见第8章)"""state, timer = None, d2l.Timer()metric = lp.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * y.numel(), y.numel())return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):"""训练模型(定义见第8章)"""loss = nn.CrossEntropyLoss()animator = lp.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller '))print(predict('traveller '))# 顺序抽样方法
num_epochs, lr = 500, 1
# train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
# plt.show()
"""
困惑度 1.0, 95138.3 词元/秒 cuda:0
time traveller you can show black is white by argument said filby
traveller you can show black is white by argument said filby
"""# 随机抽样方法
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),use_random_iter=True)
plt.show()
"""
困惑度 1.3, 109268.9 词元/秒 cuda:0
time traveller held in his hand was a glitteringmetallic framewor
traveller held in his hand was a glitteringmetallic framewor
"""
顺序抽样:

随机抽样:

55循环神经网络的简洁实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import matplotlib.pyplot as plt# 加载时光机器数据集并设置批量大小和序列长度
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)# 定义RNN模型
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)# 用零张量初始化隐藏状态
state = torch.zeros((1, batch_size, num_hiddens))
# print(state.shape) # torch.Size([1, 32, 256])# X = torch.rand(size=(num_steps, batch_size, len(vocab)))
# Y, state_new = rnn_layer(X, state)
# print(Y.shape, state_new.shape, X.shape)
# torch.Size([35, 32, 256]) torch.Size([1, 32, 256]) torch.Size([35, 32, 28])# 完整的循环神经网络模型定义了一个RNNModel类
#@save
class RNNModel(nn.Module):"""循环神经网络模型"""def __init__(self, rnn_layer, vocab_size, **kwargs):super(RNNModel, self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_size# 如果RNN是双向的,num_directions应该是2,否则应该是1if not self.rnn.bidirectional:self.num_directions = 1self.linear = nn.Linear(self.num_hiddens, self.vocab_size)else:self.num_directions = 2self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)def forward(self, inputs, state):X = F.one_hot(inputs.T.long(), self.vocab_size)X = X.to(torch.float32)Y, state = self.rnn(X, state)# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)# 它的输出形状是(时间步数*批量大小,词表大小)。output = self.linear(Y.reshape((-1, Y.shape[-1])))return output, statedef begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens),device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))# 训练与预测device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
"""
perplexity 1.3, 236379.1 tokens/sec on cuda:0
time traveller held in his hand was a glitteringmetallic framewo
traveller fith a slan but move anotle bothe thon st stagee
"""
plt.show()
print(d2l.predict_ch8('time traveller', 10, net, vocab, device))
# time traveller held in h

相关文章:
动手学深度学习(Pytorch版)代码实践 -循环神经网络-54~55循环神经网络的从零开始实现和简洁实现
54循环神经网络的从零开始实现 import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l import matplotlib.pyplot as plt import liliPytorch as lp# 读取H.G.Wells的时光机器数据集 batch_size, num_steps 32, …...

Python酷库之旅-第三方库Pandas(006)
目录 一、用法精讲 10、pandas.DataFrame.to_excel函数 10-1、语法 10-2、参数 10-3、功能 10-4、返回值 10-5、说明 10-6、用法 10-6-1、数据准备 10-6-2、代码示例 10-6-3、结果输出 11、pandas.ExcelFile类 11-1、语法 11-2、参数 11-3、功能 11-4、返回值 …...

智慧矿山:EasyCVR助力矿井视频多业务融合及视频转发服务建设
一、方案背景 随着矿井安全生产要求的不断提高,视频监控、数据传输、通讯联络等业务的需求日益增长。为满足矿井生产管理的多元化需求,提高矿井作业的安全性和效率,TSINGSEE青犀EasyCVR视频汇聚/安防监控综合管理平台,旨在构建一…...

Unix/Linux shell实用小程序1:生字本
前言 在日常工作学习中,我们会经常遇到一些不认识的英语单词,于时我们会打开翻译网站或者翻译软件进行查询,但是大部分工具没有生词本的功能,而有生字本的软件又需要注册登陆,免不了很麻烦,而且自己的数据…...

springboot2.7.6 集成swagger
在 Spring Boot 2.7.6 版本中集成 Swagger 的步骤相对直接,主要涉及添加依赖、编写配置以及在控制器中添加文档注解几个环节。 下面是集成 Swagger 的基本步骤: 1. 添加依赖 首先,在pom.xml文件中添加 Swagger 相关依赖。 对于 Spring Boot…...
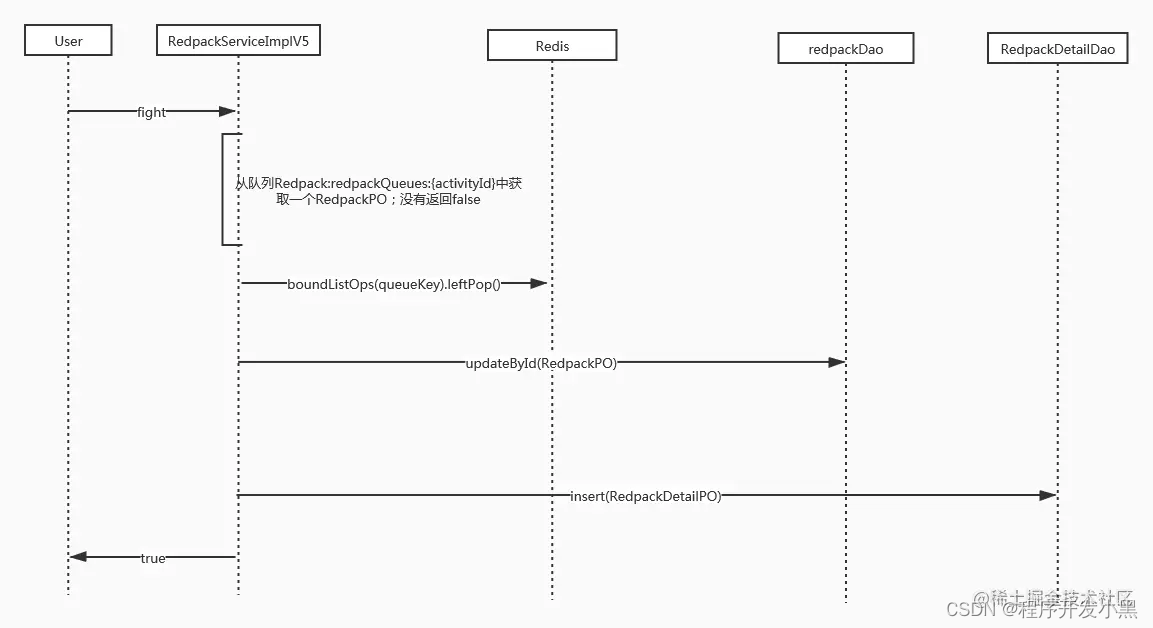
面试篇-系统设计题总结
文章目录 1、设计一个抢红包系统1.1 高可用的解决方案:1.2 抢红包系统的设计1.3 其他 2、秒杀系统设计 这里记录一些有趣的系统设计类的题目,一般大家比较喜欢出的设计类面试题目会和高可用系统相关比如秒杀和抢红包等。欢迎大家在评论中评论自己遇到的题…...
如何摆脱反爬虫机制?
在网站设计时,为了保证服务器的稳定运行,防止非法数据访问,通常会引入反爬虫机制。一般来说,网站的反爬虫机制包括以下几种: 1. CAPTCHA:网站可能会向用户显示CAPTCHA,要求他们在访问网站或执行…...

68745
877454...
github仓库的基本使用-创建、上传文件、删除
1.第一步 先点击左侧菜单栏的远程仓库 2.点击NEW 3.创建仓库 然后点击右下角的 CREATE 4.点击code 点击SSH,然后我出现了You don’t have any public SSH keys in your GitHub account. You can add a new public key, or try cloning this repository via HTTPS. 1ÿ…...

[课程][原创]opencv图像在C#与C++之间交互传递
opencv图像在C#与C之间交互传递 课程地址:https://edu.csdn.net/course/detail/39689 无限期视频有效期 课程介绍课程目录讨论留言 你将收获 学会如何封装C的DLL 学会如何用C#调用C的DLL 掌握opencv在C#和C传递思路 学会如何配置C的opencv 适用人群 拥有C#…...
)
科研绘图系列:R语言双侧条形图(bar Plot)
介绍 双侧条形图上的每个条形代表一个特定的细菌属,条形的高度表示该属的LDA得分的对数值,颜色用来区分不同的分类群或组别,它具有以下优点: 可视化差异:条形图可以直观地展示不同细菌属在得分上的差异。强调重要性:较高的条形表示某些特征在区分不同组别中具有重要作用…...

计算机未来大方向的选择
选专业要了解自己的兴趣所在。 即想要学习什么样的专业,如果有明确的专业意向,就可以有针对性地选择那些专业实力较强的院校。 2.如果没有明确的专业意向,可以优先考虑一下院校。 确定一下自己想要选择综合性院校还是理工类院校或是像财经或者…...
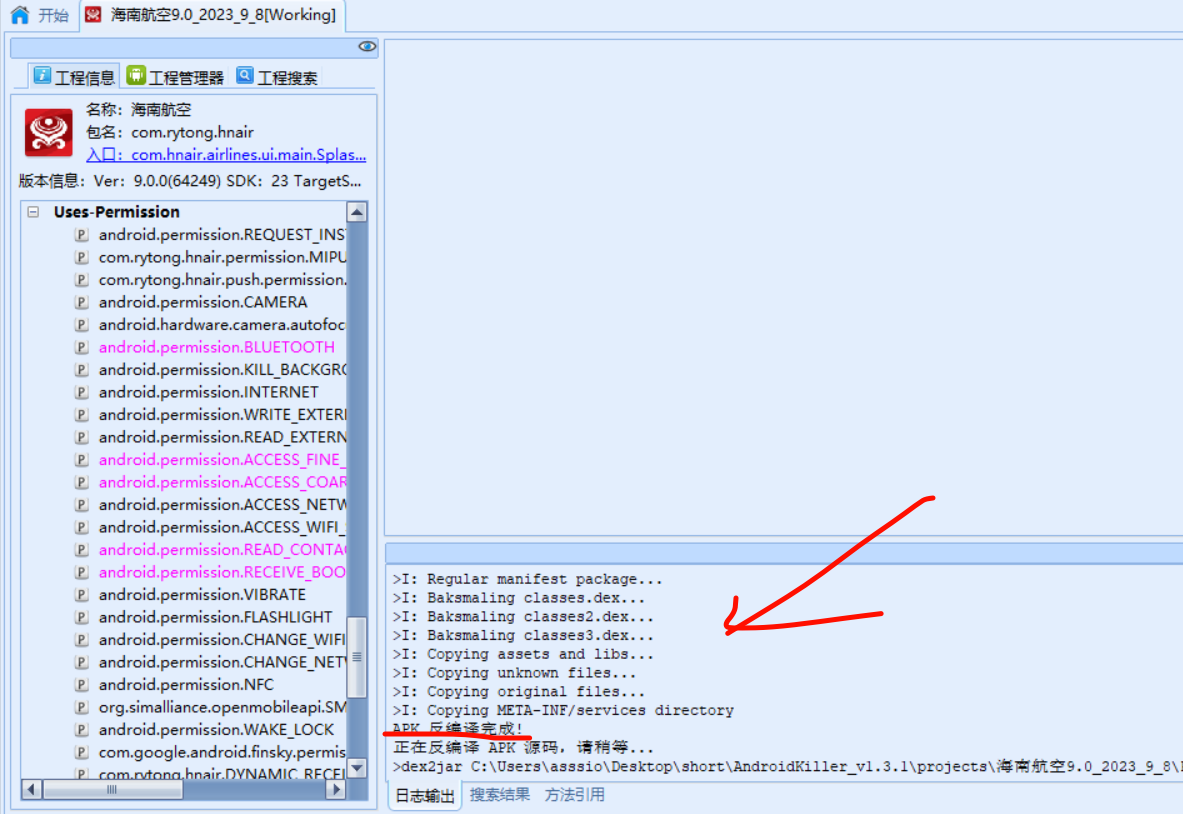
AndroidKille不能用?更新apktool插件-cnblog
AndroidKiller不更新插件容易报错 找到apktool管理器 填入apktool位置,并输入apktool名字 选择默认的apktool版本 x掉,退出重启 可以看到反编译完成了...

非参数检测2——定义
定义:若研究二判定问题(即判断有无信号)的检测问题, 检测器的虚警概率可以由对输入数据统计特性提出微弱假设确定假设中不包含输入噪声的统计特性 则称该检测器为非参数检测器。 设计目标 在未知或时变环境下,有最…...

iOS多target时怎么对InfoPlist进行国际化
由于不同target要显示不同的App名称、不同的权限提示语,国际化InfoPlist文件必须创建名称为InfoPlist.strings的文件,那么多个target时怎么进行国际化呢?步骤如下: 一、首先我们在项目根目录创建不同的文件夹对应多个不同的targe…...
TZDYM001矩阵系统源码 矩阵营销系统多平台多账号一站式管理
外面稀有的TZDYM001矩阵系统源码,矩阵营销系统多平台多账号一站式管理,一键发布作品。智能标题,关键词优化,排名查询,混剪生成原创视频,账号分组,意向客户自动采集,智能回复…...
你的 Mac 废纸篓都生苍蝇啦
今天给大家推荐个免费且有趣的小工具 BananaBin,它可以在你的废纸篓上“长”一些可爱的苍蝇🪰。 软件介绍 BananaBin 是 macOS 上的一款有趣实用工具,当你的垃圾桶满了时,它会提醒你清理。这个软件通过在垃圾桶上添加互动的苍蝇…...

推出新的C2000™ F28P65x 实时微控制器,专为高效控制电力电子产品而构建(F28P650DH、F28P650DK、F28P650SH)
C2000™ F28P65x 实时微控制器是集中级性能、PWM 和模拟创新与系统成本优化等优势于一身。 F28P65x 系列是 C2000™ 实时微控制器 (MCU) 系列的中级性能系列产品,专为高效控制电力电子产品而构建。凭借超低延迟,F28P65x 通过更多的模拟功能和新的 PWM 功…...

使用Java实现分布式日志系统
使用Java实现分布式日志系统 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在分布式系统中,日志记录是一项至关重要的任务。它不仅用于故障排查和…...

Java 基础查漏补缺
1.深入解读:JDK与JRE的区别 JDK提供了完整的Java开发工具和资源,包括编译器、调试器和其他开发工具,满足开发人员的各种需求。 JRE则相对更为基础,它只提供了Java程序运行所需的环境,包含了Java虚拟机(JVM&…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...