使用Java实现分布式日志系统
使用Java实现分布式日志系统
大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!
在分布式系统中,日志记录是一项至关重要的任务。它不仅用于故障排查和系统监控,还可以支持系统的性能优化、安全审计以及业务数据分析。传统的单机日志系统往往无法满足分布式环境下大规模、高并发的日志记录需求,因此需要构建分布式日志系统来解决这些挑战。
1. 设计分布式日志系统的基本架构
分布式日志系统的基本架构通常包括日志收集、存储、检索和分析等核心组件。其中,日志收集器负责从各个节点收集日志数据;存储组件用于持久化存储日志;检索模块支持快速的日志查询和分析。
package cn.juwatech.distributedlog;import java.util.logging.Logger;public class DistributedLogSystem {private static final Logger logger = Logger.getLogger(DistributedLogSystem.class.getName());public static void main(String[] args) {// Implementation of distributed log system componentslogger.info("Initializing distributed log system...");// Initialization code}
}
在上述示例中,我们展示了一个简单的Java类,用于演示分布式日志系统的初始化过程。
2. 日志收集器的实现
日志收集器负责从分布式系统的各个节点收集日志数据,并将其发送到中心化的存储组件。常见的实现方式包括基于消息队列或者分布式文件系统的日志收集方案。
package cn.juwatech.logcollector;import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Properties;public class LogCollector {private Consumer<String, String> kafkaConsumer;public LogCollector() {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ConsumerConfig.GROUP_ID_CONFIG, "log-group");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");kafkaConsumer = new KafkaConsumer<>(props);}public void start() {kafkaConsumer.subscribe(Collections.singletonList("logs-topic"));while (true) {// Consume logs from Kafka topic}}public static void main(String[] args) {LogCollector collector = new LogCollector();collector.start();}
}
在上述示例中,我们展示了如何使用Apache Kafka作为消息队列,实现日志收集器的基本功能。
3. 分布式日志存储的选择与优化
分布式日志存储通常需要考虑数据的持久性、高可用性和水平扩展性等特性。常见的存储方案包括基于分布式文件系统(如HDFS)、NoSQL数据库(如Elasticsearch)或者基于云服务的存储解决方案(如AWS S3)。
package cn.juwatech.logstorage;import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestClients;public class LogStorage {private RestHighLevelClient client;public LogStorage() {RestClientBuilder builder = RestClients.createDefault();client = new RestHighLevelClient(builder);}public void storeLog(String log) {// Store log in Elasticsearch or other storage systems}public static void main(String[] args) {LogStorage storage = new LogStorage();storage.storeLog("Example log message");}
}
在上述示例中,我们展示了如何使用Elasticsearch作为分布式日志存储,通过Elasticsearch的Java高级客户端实现日志数据的存储。
4. 日志检索与分析
分布式日志系统需要提供快速的日志查询和分析能力,以便开发人员和运维人员能够快速定位和解决问题。常见的实现方式包括基于文本索引和查询语言的日志检索服务。
package cn.juwatech.logsearch;import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;public class LogSearch {private RestHighLevelClient client;public LogSearch() {// Initialization of Elasticsearch client}public void searchLogs(String query) throws IOException {SearchRequest searchRequest = new SearchRequest("logs-index");SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(QueryBuilders.queryStringQuery(query));sourceBuilder.timeout(TimeValue.timeValueSeconds(10));searchRequest.source(sourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// Process search response}public static void main(String[] args) throws IOException {LogSearch searcher = new LogSearch();searcher.searchLogs("error");}
}
在上述示例中,我们展示了如何使用Elasticsearch的Java高级客户端实现基本的日志搜索功能,通过查询字符串查询日志中包含"error"关键字的日志条目。
结语
通过本文的介绍,我们深入探讨了如何使用Java实现分布式日志系统。从架构设计到具体实现,我们讨论了日志收集、存储、检索和分析等关键组件的实现方式和技术选择。分布式日志系统不仅帮助开发团队更好地管理和监控系统运行状态,还能够提升系统的稳定性和可靠性,是大规模分布式系统中不可或缺的重要组成部分。
微赚淘客系统3.0小编出品,必属精品!
相关文章:

使用Java实现分布式日志系统
使用Java实现分布式日志系统 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在分布式系统中,日志记录是一项至关重要的任务。它不仅用于故障排查和…...

Java 基础查漏补缺
1.深入解读:JDK与JRE的区别 JDK提供了完整的Java开发工具和资源,包括编译器、调试器和其他开发工具,满足开发人员的各种需求。 JRE则相对更为基础,它只提供了Java程序运行所需的环境,包含了Java虚拟机(JVM&…...
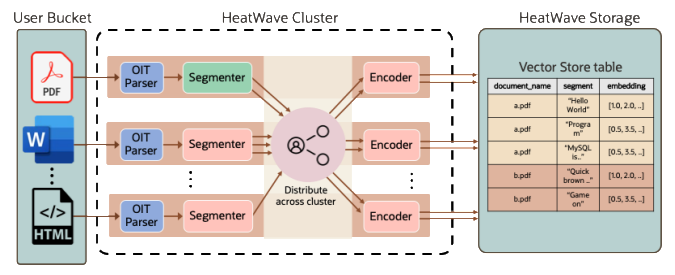
甲骨文首次将LLMs引入数据库,集成Llama 3和Mistral,和数据库高效对话
信息时代,数据为王。数据库作为数据存储&管理的一种方式,正在以势不可挡的趋势与AI结合。 前有OpenAI 收购了数据库初创公司 Rockset,引发广泛关注;Oracle公司(甲骨文)作为全球最大的信息管理软件及服…...

HumbleBundle7月虚幻捆绑包30件军事题材美术模型沙漠自然环境大逃杀模块化建筑可定制武器包二战现代坦克飞机道具丧尸士兵角色模型20240705
HumbleBundle7月虚幻捆绑包30件军事题材美术模型沙漠自然环境大逃杀模块化建筑可定制武器包二战现代坦克飞机道具丧尸士兵角色模型202407051607 这次HumbleBundle捆绑包是UE虚幻军事题材的,内容非常多。 有军事基地、赛博朋克街区、灌木丛景观环境等 HB捆绑包虚幻…...

SQL 别名
SQL 别名 在SQL(Structured Query Language)中,别名是一种常用的技术,用于给表或列指定一个临时的名称,以便在查询中使用。这种技术可以提高查询的可读性,使查询更加清晰和易于理解。本文将详细介绍SQL别名的概念、用途、语法以及在不同场景下的应用示例。 1. 什么是SQ…...
浅谈反射机制
1. 何为反射? 反射(Reflection)机制指的是程序在运行的时候能够获取自身的信息。具体来说,反射允许程序在运行时获取关于自己代码的各种信息。如果知道一个类的名称或者它的一个实例对象, 就能把这个类的所有方法和变…...

解决obsidian加粗中文字体显示不突出的问题
加粗字体显示不突出的原因:默认字体的加粗版本本来就不突出 解决方法:改成显示突出的类型Microsoft YaHei UI 【效果】 修改前:修改后: 其他方法: 修改css(很麻烦,改半天也不一定奏效&#…...

Shell echo命令
Shell echo命令 在Shell编程中,echo命令是一个常用的内置命令,用于在终端或控制台上显示文本或变量的值。它是与用户交互的一种基本方式,经常用于输出信息、创建文件内容或与脚本的其他部分进行通信。本文将详细介绍echo命令的用法、选项和实际应用示例。 基本用法 echo命…...

级联目标检测:构建高效目标识别的多阶段策略
标题:级联目标检测:构建高效目标识别的多阶段策略 级联目标检测(Cascade Object Detection)是一种多阶段的目标检测方法,它通过一系列逐渐细化的分类器来提高检测的准确性和效率。这种技术通常用于处理计算资源受限的…...

this指向问题以及如何改变指向
当在Vue.js中讨论"this"的指向问题时,有几个重要的方面需要考虑,特别是在组件化开发和异步操作中: 1. 普通函数 vs 箭头函数 在JavaScript中,普通函数和箭头函数对于"this"的处理方式有显著区别:…...
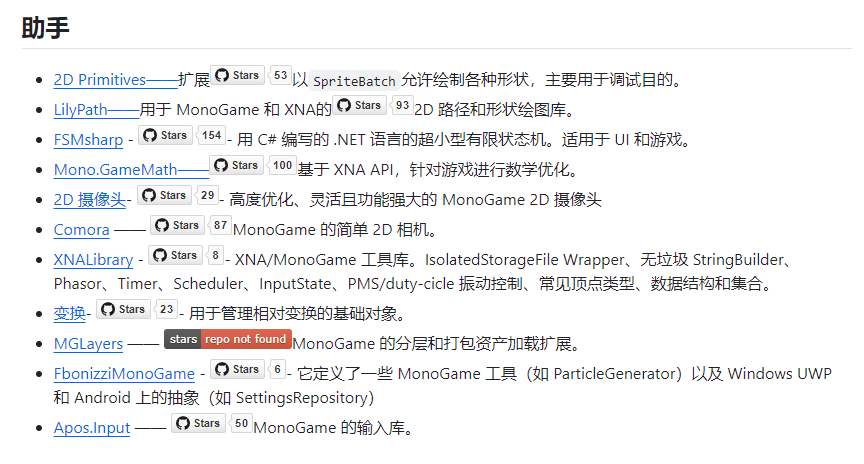
基于.NET开源游戏框架MonoGame实现的开源项目合集
前言 今天分享一些基于.NET开源游戏框架MonoGame实现的开源项目合集。 MonoGame项目介绍 MonoGame是一个简单而强大的.NET框架,使用C#编程语言可以创建桌面PC、视频游戏机和移动设备游戏。它已成功用于创建《怒之铁拳4》、《食肉者》、《超凡蜘蛛侠》、《星露谷物…...

spring boot + vue3+element plus 项目搭建
一、vue 项目搭建 1、创建 vue 项目 vue create vue-element说明:创建过程中可以选择路由,也可也可以不选择,可以通过 npm install 安装 vue 项目目录结构 说明:api 为自己创建的文件夹,router 选择路由模块会自动…...
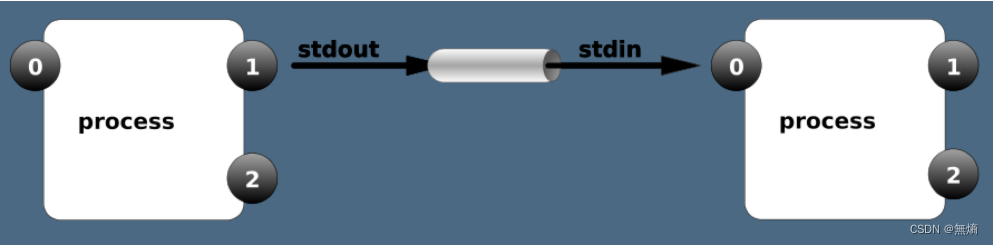
linux之管道重定向
管道与重定向 一、重定向 将原输出结果存储到其他位置的过程 标准输入、标准正确输出、标准错误输出 进程在运行的过程中根据需要会打开多个文件,每打开一个文件会有一个数字标识。这个标识叫文件描述符。 进程使用文件描述符来管理打开的文件(FD--…...

to_json 出现乱码的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

Java接口和类
package chapter04;public class Java22_Object_接口 {public static void main(String[] args) {// TODO 面向对象 - 接口// 所谓的接口,可以简单理解为规则、规范// 基本语法:interface 接口名称 { 规则属性,规则的行为 }// 接口其实是抽象…...

前端文件预览汇总
一、vue中预览word、excel、pdf: vue-office vue-office支持多种文件(docx、excel、pdf)预览的vue组件库,支持vue2/3,也支持非Vue框架的预览。 特点: 一站式:提供word(.docx)、pdf、excel(.xlsx, .xls)多种文档在线…...

银河麒麟V10 安装tigervncserver
银河麒麟V10 安装tigervncserver 银河麒麟V10安装tigervnc-server步骤: 提示,本安装环境:arm飞腾2000,主机开机进入root用户模式。 1、安装server安装包 #rpm -i tigervnc-server-1.10.1-5.p05.ky10.aarch64.rpm 2、控制台输入 …...

SKM Power*Tools 10.0
SKM Power*Tools 10.0是功能强大的电气电力系统分析设计解决方案!综合软件提供强大的功能和领先的技术,在检查、计算、负载分配、流量、瞬态稳定性等多个方面提供领先的支持,可对不同的安全设备、系统进行评估分析和比较,使用 Pow…...

查看视频时间基 time_base
时间基、codec, 分辨率,音频和视频的都一样,才可以直接使用ffmpeg -f concat -i file.txt 方式合并。 On Thu, Dec 03, 2015 at 21:54:53 0200, redneb8888 wrote: I am looking for a way to find the time base of a stream (video or audio), $ ffpr…...

数据结构 —— 最小生成树
数据结构 —— 最小生成树 什么是最小生成树Kruskal算法Prim算法 今天我们来看一下最小生成树: 我们之前学习的遍历算法并没有考虑权值,仅仅就是遍历结点: 今天的最小生成树要满足几个条件: 考虑权值所有结点联通权值之和最小无环…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

CPU架构启发的智能仓储布局优化实践
1. 仓库布局优化的核心挑战与创新机遇在物流仓储领域,拣货环节通常占据运营成本的55%-65%,而其中约50%的时间消耗在无效行走路径上。传统矩形仓库布局虽然易于规划和施工,但其正交的通道设计导致拣货员需要频繁进行90度转向,这种&…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...