MySQL复合查询
文章目录
- 基本查询回顾
- 多表查询
- 自连接
- 子查询
- 单行子查询
- 多行子查询
- 多列子查询
- 在from子句中使用子查询
- 合并查询
- union
- union all
基本查询回顾
查询的员工部门表结构:
mysql> show tables;
+-----------------+
| Tables_in_scott |
+-----------------+
| dept |
| emp |
| salgrade |
+-----------------+
3 rows in set (0.00 sec)mysql> desc dept;
+--------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------------------+------+-----+---------+-------+
| deptno | int(2) unsigned zerofill | NO | | NULL | |
| dname | varchar(14) | YES | | NULL | |
| loc | varchar(13) | YES | | NULL | |
+--------+--------------------------+------+-----+---------+-------+
3 rows in set (0.00 sec)mysql> desc emp;
+----------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------------------+------+-----+---------+-------+
| empno | int(6) unsigned zerofill | NO | | NULL | |
| ename | varchar(10) | YES | | NULL | |
| job | varchar(9) | YES | | NULL | |
| mgr | int(4) unsigned zerofill | YES | | NULL | |
| hiredate | datetime | YES | | NULL | |
| sal | decimal(7,2) | YES | | NULL | |
| comm | decimal(7,2) | YES | | NULL | |
| deptno | int(2) unsigned zerofill | YES | | NULL | |
+----------+--------------------------+------+-----+---------+-------+
8 rows in set (0.00 sec)mysql> desc salgrade;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| grade | int(11) | YES | | NULL | |
| losal | int(11) | YES | | NULL | |
| hisal | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
3 rows in set (0.00 sec)
查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J:
mysql> select job, ename, sal from emp where (sal>500 or job='MANAGER') and ename like 'J%';
+---------+-------+---------+
| job | ename | sal |
+---------+-------+---------+
| MANAGER | JONES | 2975.00 |
| CLERK | JAMES | 950.00 |
+---------+-------+---------+
2 rows in set (0.00 sec)
按照部门号升序而雇员的工资降序排序:
mysql> select ename, sal, deptno from emp order by deptno asc, sal desc;
+--------+---------+--------+
| ename | sal | deptno |
+--------+---------+--------+
| KING | 5000.00 | 10 |
| CLARK | 2450.00 | 10 |
| MILLER | 1300.00 | 10 |
| SCOTT | 3000.00 | 20 |
| FORD | 3000.00 | 20 |
| JONES | 2975.00 | 20 |
| ADAMS | 1100.00 | 20 |
| SMITH | 800.00 | 20 |
| BLAKE | 2850.00 | 30 |
| ALLEN | 1600.00 | 30 |
| TURNER | 1500.00 | 30 |
| WARD | 1250.00 | 30 |
| MARTIN | 1250.00 | 30 |
| JAMES | 950.00 | 30 |
+--------+---------+--------+
14 rows in set (0.00 sec)
使用年薪进行降序排序:
mysql> select ename, sal*12+ifnull(comm,0) year_sal from emp order by year_sal desc;
+--------+----------+
| ename | year_sal |
+--------+----------+
| KING | 60000.00 |
| SCOTT | 36000.00 |
| FORD | 36000.00 |
| JONES | 35700.00 |
| BLAKE | 34200.00 |
| CLARK | 29400.00 |
| ALLEN | 19500.00 |
| TURNER | 18000.00 |
| MARTIN | 16400.00 |
| MILLER | 15600.00 |
| WARD | 15500.00 |
| ADAMS | 13200.00 |
| JAMES | 11400.00 |
| SMITH | 9600.00 |
+--------+----------+
14 rows in set (0.00 sec)
显示工资最高的员工的名字和工作岗位:
mysql> select ename, job from emp where sal=(select max(sal) from emp);
+-------+-----------+
| ename | job |
+-------+-----------+
| KING | PRESIDENT |
+-------+-----------+
1 row in set (0.00 sec)
显示工资高于平均工资的员工信息:
mysql> select ename, sal from emp where sal>(select avg(sal) from emp);
+-------+---------+
| ename | sal |
+-------+---------+
| JONES | 2975.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| FORD | 3000.00 |
+-------+---------+
6 rows in set (0.00 sec)
显示每个部门的平均工资和最高工资:
mysql> select deptno, max(sal), avg(sal) from emp group by deptno;
+--------+----------+-------------+
| deptno | max(sal) | avg(sal) |
+--------+----------+-------------+
| 10 | 5000.00 | 2916.666667 |
| 20 | 3000.00 | 2175.000000 |
| 30 | 2850.00 | 1566.666667 |
+--------+----------+-------------+
3 rows in set (0.00 sec)
显示平均工资低于2000的部门号和它的平均工资:
mysql> select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal<2000;
+--------+-------------+
| deptno | avg_sal |
+--------+-------------+
| 30 | 1566.666667 |
+--------+-------------+
1 row in set (0.00 sec)
显示每种岗位的雇员总数,平均工资:
mysql> select job, count(*) '雇员总数', avg(sal) '平均工资' from emp group by job;
+-----------+--------------+--------------+
| job | 雇员总数 | 平均工资 |
+-----------+--------------+--------------+
| ANALYST | 2 | 3000.000000 |
| CLERK | 4 | 1037.500000 |
| MANAGER | 3 | 2758.333333 |
| PRESIDENT | 1 | 5000.000000 |
| SALESMAN | 4 | 1400.000000 |
+-----------+--------------+--------------+
5 rows in set (0.00 sec)
多表查询
在实际中往往数据来自不同的表,所以需要多表查询。本节我们用一个简单的公司管理系统,有三张表EMP,DEPT,SALGRADE来演示如何进行多表查询:
案例:
显示雇员名、雇员工资以及所在部门的名字:
因为上面的数据来自EMP和DEPT表,因此要联合查询

mysql> select * from emp, dept limit 12;
+--------+-------+----------+------+---------------------+---------+--------+--------+--------+------------+----------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno | deptno | dname | loc |
+--------+-------+----------+------+---------------------+---------+--------+--------+--------+------------+----------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 | 10 | ACCOUNTING | NEW YORK |
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 | 20 | RESEARCH | DALLAS |
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 | 30 | SALES | CHICAGO |
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 | 40 | OPERATIONS | BOSTON |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 | 10 | ACCOUNTING | NEW YORK |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 | 20 | RESEARCH | DALLAS |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 | 30 | SALES | CHICAGO |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 | 40 | OPERATIONS | BOSTON |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 | 10 | ACCOUNTING | NEW YORK |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 | 20 | RESEARCH | DALLAS |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 | 30 | SALES | CHICAGO |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 | 40 | OPERATIONS | BOSTON |
+--------+-------+----------+------+---------------------+---------+--------+--------+--------+------------+----------+
12 rows in set (0.00 sec)
此时就需要对表的数据进行筛选,只要emp表中的deptno = dept表中的deptno字段的记录:
mysql> select ename, sal, dname from emp, dept where emp.deptno=dept.deptno;
+--------+---------+------------+
| ename | sal | dname |
+--------+---------+------------+
| SMITH | 800.00 | RESEARCH |
| ALLEN | 1600.00 | SALES |
| WARD | 1250.00 | SALES |
| JONES | 2975.00 | RESEARCH |
| MARTIN | 1250.00 | SALES |
| BLAKE | 2850.00 | SALES |
| CLARK | 2450.00 | ACCOUNTING |
| SCOTT | 3000.00 | RESEARCH |
| KING | 5000.00 | ACCOUNTING |
| TURNER | 1500.00 | SALES |
| ADAMS | 1100.00 | RESEARCH |
| JAMES | 950.00 | SALES |
| FORD | 3000.00 | RESEARCH |
| MILLER | 1300.00 | ACCOUNTING |
+--------+---------+------------+
14 rows in set (0.00 sec)
显示部门号为10的部门名,员工名和工资:
mysql> select emp.deptno, dname, ename, sal from emp, dept where emp.deptno=dept.deptno and emp.deptno=10;
+--------+------------+--------+---------+
| deptno | dname | ename | sal |
+--------+------------+--------+---------+
| 10 | ACCOUNTING | CLARK | 2450.00 |
| 10 | ACCOUNTING | KING | 5000.00 |
| 10 | ACCOUNTING | MILLER | 1300.00 |
+--------+------------+--------+---------+
3 rows in set (0.00 sec)
显示各个员工的姓名,工资,及工资级别:
mysql> select ename, sal, grade from emp,salgrade where sal between losal and hisal;
+--------+---------+-------+
| ename | sal | grade |
+--------+---------+-------+
| SMITH | 800.00 | 1 |
| ALLEN | 1600.00 | 3 |
| WARD | 1250.00 | 2 |
| JONES | 2975.00 | 4 |
| MARTIN | 1250.00 | 2 |
| BLAKE | 2850.00 | 4 |
| CLARK | 2450.00 | 4 |
| SCOTT | 3000.00 | 4 |
| KING | 5000.00 | 5 |
| TURNER | 1500.00 | 3 |
| ADAMS | 1100.00 | 1 |
| JAMES | 950.00 | 1 |
| FORD | 3000.00 | 4 |
| MILLER | 1300.00 | 2 |
+--------+---------+-------+
14 rows in set (0.00 sec)
自连接
自连接是指在同一张表连接查询
案例:
显示员工FORD的上级领导的编号和姓名:
- 子查询
mysql> select empno, ename from emp where empno=(select mgr from emp where ename='FORD');
+--------+-------+
| empno | ename |
+--------+-------+
| 007566 | JONES |
+--------+-------+
1 row in set (0.00 sec)
- 使用多表查询(自查询)
mysql> select leader.empno, leader.ename from emp leader,emp worker where worker.mgr=leader.empno and worker.ename='FORD';
+--------+-------+
| empno | ename |
+--------+-------+
| 007566 | JONES |
+--------+-------+
1 row in set (0.00 sec)
子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询
返回一行记录的子查询
显示SMITH同一部门的员工:
mysql> select ename, job from emp where job=(select job from emp where ename='SMITH');
+--------+-------+
| ename | job |
+--------+-------+
| SMITH | CLERK |
| ADAMS | CLERK |
| JAMES | CLERK |
| MILLER | CLERK |
+--------+-------+
4 rows in set (0.00 sec)
多行子查询
返回多行记录的子查询
- in关键字:查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10号部门:
mysql> select ename, job, sal, deptno from emp where job in(select job from emp where deptno=10);
+--------+-----------+---------+--------+
| ename | job | sal | deptno |
+--------+-----------+---------+--------+
| JONES | MANAGER | 2975.00 | 20 |
| BLAKE | MANAGER | 2850.00 | 30 |
| CLARK | MANAGER | 2450.00 | 10 |
| KING | PRESIDENT | 5000.00 | 10 |
| SMITH | CLERK | 800.00 | 20 |
| ADAMS | CLERK | 1100.00 | 20 |
| JAMES | CLERK | 950.00 | 30 |
| MILLER | CLERK | 1300.00 | 10 |
+--------+-----------+---------+--------+
8 rows in set (0.00 sec)
- all关键字:显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
mysql> select ename, sal, deptno from emp where sal > all(select sal from emp where deptno=30);
+-------+---------+--------+
| ename | sal | deptno |
+-------+---------+--------+
| JONES | 2975.00 | 20 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| FORD | 3000.00 | 20 |
+-------+---------+--------+
4 rows in set (0.00 sec)
- any关键字:显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号
mysql> select ename, sal, deptno from emp where sal > any(select sal from emp where deptno=30);
+--------+---------+--------+
| ename | sal | deptno |
+--------+---------+--------+
| ALLEN | 1600.00 | 30 |
| WARD | 1250.00 | 30 |
| JONES | 2975.00 | 20 |
| MARTIN | 1250.00 | 30 |
| BLAKE | 2850.00 | 30 |
| CLARK | 2450.00 | 10 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| TURNER | 1500.00 | 30 |
| ADAMS | 1100.00 | 20 |
| FORD | 3000.00 | 20 |
| MILLER | 1300.00 | 10 |
+--------+---------+--------+
12 rows in set (0.01 sec)
多列子查询
单行子查询是指子查询只返回单列,单行数据。多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句。
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人:
mysql> select ename from emp where (deptno, job) = (select deptno, job from emp where ename='SMITH') and ename!='SMITH';
+-------+
| ename |
+-------+
| ADAMS |
+-------+
1 row in set (0.00 sec)
在from子句中使用子查询
子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资:
mysql> select ename, emp.deptno, sal, avg_tb.avg_sal from emp, > (select deptno, avg(sal) avg_sal from emp group by deptno) avg_tb> where emp.deptno=avg_tb.deptno and emp.sal>avg_tb.avg_sal;
+-------+--------+---------+-------------+
| ename | deptno | sal | avg_sal |
+-------+--------+---------+-------------+
| ALLEN | 30 | 1600.00 | 1566.666667 |
| JONES | 20 | 2975.00 | 2175.000000 |
| BLAKE | 30 | 2850.00 | 1566.666667 |
| SCOTT | 20 | 3000.00 | 2175.000000 |
| KING | 10 | 5000.00 | 2916.666667 |
| FORD | 20 | 3000.00 | 2175.000000 |
+-------+--------+---------+-------------+
6 rows in set (0.00 sec)
查找每个部门工资最高的人的姓名、工资、部门、最高工资:
mysql> select ename, sal, emp.deptno, max_tb.max_sal from emp, >(select deptno, max(sal) max_sal from emp group by deptno) max_tb > where emp.deptno=max_tb.deptno and emp.sal=max_tb.max_sal;
+-------+---------+--------+---------+
| ename | sal | deptno | max_sal |
+-------+---------+--------+---------+
| BLAKE | 2850.00 | 30 | 2850.00 |
| SCOTT | 3000.00 | 20 | 3000.00 |
| KING | 5000.00 | 10 | 5000.00 |
| FORD | 3000.00 | 20 | 3000.00 |
+-------+---------+--------+---------+
4 rows in set (0.00 sec)
显示每个部门的信息(部门名,编号,地址)和人员数量:
- 方法一:使用多表查询
mysql> select dept.dname, emp.deptno, dept.loc, count(*) cnt from emp, dept > where emp.deptno=dept.deptno group by dept.deptno, dept.loc, dept.dname;
+------------+--------+----------+-----+
| dname | deptno | loc | cnt |
+------------+--------+----------+-----+
| ACCOUNTING | 10 | NEW YORK | 3 |
| RESEARCH | 20 | DALLAS | 5 |
| SALES | 30 | CHICAGO | 6 |
+------------+--------+----------+-----+
3 rows in set (0.00 sec)
- 方法二:使用子查询
mysql> select dname, dept.deptno, loc, cnt_tb.cnt from dept, > (select emp.deptno, count(*) cnt from emp group by deptno) cnt_tb > where deept.deptno=cnt_tb.deptno;
+------------+--------+----------+-----+
| dname | deptno | loc | cnt |
+------------+--------+----------+-----+
| ACCOUNTING | 10 | NEW YORK | 3 |
| RESEARCH | 20 | DALLAS | 5 |
| SALES | 30 | CHICAGO | 6 |
+------------+--------+----------+-----+
3 rows in set (0.00 sec)
合并查询
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
将工资大于2500或职位是MANAGER的人找出来:
mysql> select ename, job, sal from emp where sal>2500 union select ename, job, sal from emp where job='MANAGER';
+-------+-----------+---------+
| ename | job | sal |
+-------+-----------+---------+
| JONES | MANAGER | 2975.00 |
| BLAKE | MANAGER | 2850.00 |
| SCOTT | ANALYST | 3000.00 |
| KING | PRESIDENT | 5000.00 |
| FORD | ANALYST | 3000.00 |
| CLARK | MANAGER | 2450.00 |
+-------+-----------+---------+
6 rows in set (0.00 sec)
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
将工资大于2500或职位是MANAGER的人找出来:
mysql> select ename, job, sal from emp where sal>2500 union all select ename, job, sal from emp where job='MANAGER';
+-------+-----------+---------+
| ename | job | sal |
+-------+-----------+---------+
| JONES | MANAGER | 2975.00 |
| BLAKE | MANAGER | 2850.00 |
| SCOTT | ANALYST | 3000.00 |
| KING | PRESIDENT | 5000.00 |
| FORD | ANALYST | 3000.00 |
| JONES | MANAGER | 2975.00 |
| BLAKE | MANAGER | 2850.00 |
| CLARK | MANAGER | 2450.00 |
+-------+-----------+---------+
8 rows in set (0.00 sec)
相关文章:
MySQL复合查询
文章目录基本查询回顾多表查询自连接子查询单行子查询多行子查询多列子查询在from子句中使用子查询合并查询unionunion all基本查询回顾 查询的员工部门表结构: mysql> show tables; ----------------- | Tables_in_scott | ----------------- | dept …...

PCIe 资料收集2
文章目录感官认识PCIe的存储空间PCIe 在 linux 下的驱动PCIe 验证1.PCIe 传递裸数据2.PCIe 转其他设备PCIe转其他总线RS232USB从用户空间理解PCIe感官认识 总线协议接口 视频介绍PCIe 视频介绍及PCIe文字介绍 PCIe上可以接各种控制器硬盘控制器硬盘声卡控制器音响咪头/耳机显…...
)
Linux网络编程(使用VScode远程登录ubuntu)
文章目录 前言一、SSH插件的安装1.SSH简单介绍2.SSH插件安装和配置步骤二、安装C/C++插件总结前言 本篇文章将带大家进行网络编程的准备工作,使用vscode进行远程登录ubuntu。为什么要使用vscode进行远程登录ubantu呢?因为有些小伙伴的电脑可能性能不够开启虚拟机后会导致电脑…...

如何提高项目估算精准度?关键看5大影响因子
如何让项目估算工作更加精准,我们需要重点关注5大调整因子。 1、功能点调整因子 首先需要对功能点因子进行调整,区分不同类型的系统特征值。 因为不同的系统,对项目开发的影响程度不同,一般我们把系统特征值分为14种类型ÿ…...

论文阅读笔记《Nctr: Neighborhood Consensus Transformer for Feature Matching》
核心思想 本文提出一种融合邻域一致性的Transfomer结构来实现特征点的匹配(NCTR)。整个的实现流程和思想与SuperGlue相似,改进点在于考虑到了邻域一致性。邻域一致性在许多的传统图像匹配和图匹配任务中都有应用,他基于一个很重要…...

上位机系统Ubuntu 20.04与下位机arduino UNO通讯
目录一、安装arduino IDE1.1安装方法1.1.1终端里命令下载(不推荐)1.1.2官网下载(不推荐)1.1.3论坛下载(不推荐)1.1.4系统应用商店(推荐!)1.2配置项目文件位置1.3测试IDE功…...

hive面试题
1、什么是Hive Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL) 2、Hive的意义(最初研发的原因) 避免了去写MapReduce,提供快速开发的…...

【CUDA】《CUDA编程:基础与实践》CUDA加速的关键因素
CUDA事件计时 CUDA提供了一种基于CUDA事件(CUDA event)的计时方式,可用来给一段CUDA代码(可能包含主机代码和设备代码)计时。 对计时器的封装: class CUDATimeCost { public:void start() {elapsed_time_ 0.0;// 初始化cudaEventcheckCudaRuntime(cud…...
——双向循环链表)
数据结构【Golang实现】(四)——双向循环链表
目录0. 定义节点1. IsEmpty()2. Length()3. AddFromHead()4. AddFromTail()5. Insert()6. DeleteHead()7. DeleteTail()8. Remove()9. RemoveByValue()10. Contain()11. Traverse()0. 定义节点 type DLNode struct {Data anyPrev, Next *DLNode }// DoublyLoopLinkedLis…...
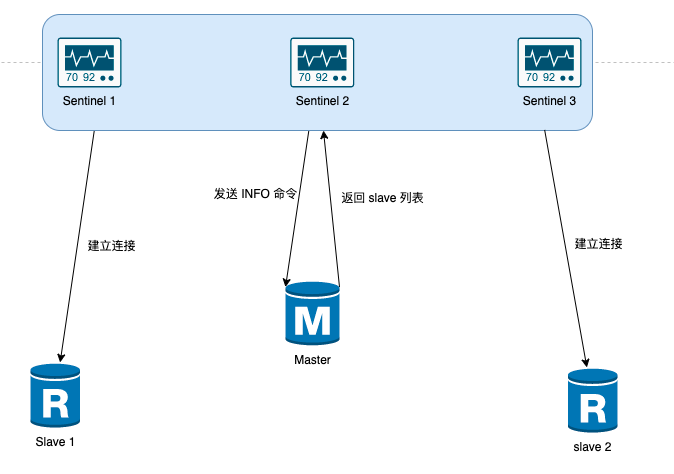
【Redis】高可用架构之哨兵模式 - Sentinel
Redis 高可用架构之哨兵模式 - Sentinel1. 前言2. Redis Sentinel 哨兵集群搭建2.1 一主两从2.2 三个哨兵3. Redis Sentinel 原理剖析3.1 什么哨兵模式3.2 哨兵机制的主要任务3.2.1 监控(1)每1s发送一次 PING 命令(2)PING 命令的回…...

图片的美白与美化
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…...
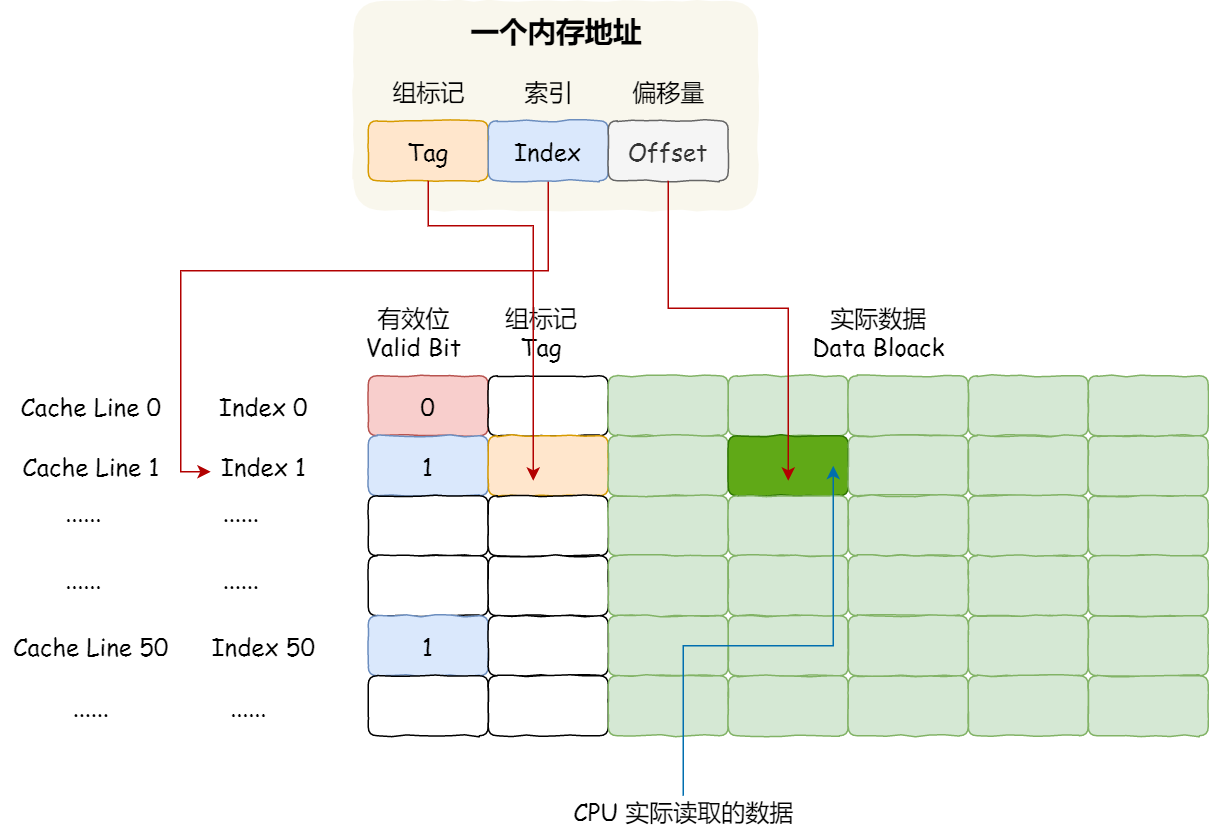
面试官:关于CPU你了解多少?
CPU是如何执行程序的? 程序执行的基本过程 第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准…...

UI自动化测试-Selenium的使用
文章目录 1. 环境搭建1.1 入门示例1.2 元素操作常用方法1.3 浏览器操作常用方法1.4 获取元素信息常用方法1.5 鼠标操作常用方法1.6 键盘操作常用方法1.7 下拉选择框操作2. 元素定位2.1 id定位2.2 name定位2.3 class_name定位2.4 tag_name定位2.5 link_text定位2.6 partail_link…...
嵌入式学习笔记——STM32的USART相关寄存器介绍及其配置
文章目录前言USART的相关寄存器介绍状态寄存器:USARTX->SR具体位代表的含义实际代码数据寄存器 USARTX->DR波特率寄存器 USARTX->BRR控制寄存器 (USART_CR)控制寄存器1(USART_CR1)控制寄存器2(USART_CR2)GPIO…...
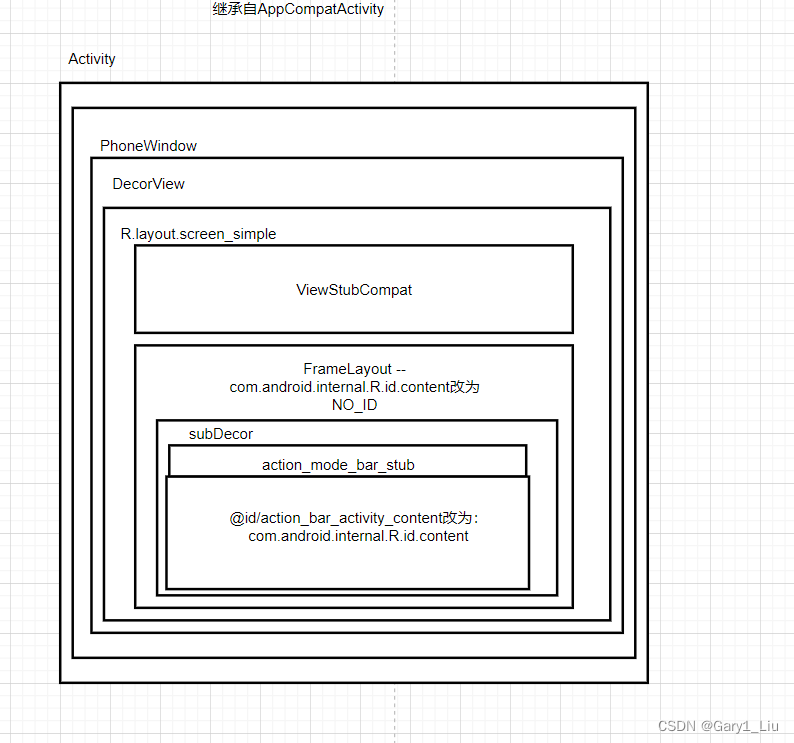
Android setContentView流程分析(一)
对于做Android App的小伙伴来说setContentView这个方法再熟悉不过了,那么有多少小伙伴知道它的调用到底做了多少事情呢?下面就让我们来看看它背后的故事吧? setContentView()方法将分为两节来讲: 第一节:如何获取De…...

doris数据库操作数字遇到的问题
关于doris数据库Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。…...

3.13文件的IO操作
一.文件1.定义文件一般指的是存储在硬盘上的普通文件形如:txt.jpg.mp4,rar等这些文件在计算机中,文件可能是一个广义的概念,不仅可以包含普通文件,还可以包含目录(也就是文件夹.把目录称为目录文件)在操作系统中,还会用文件来描述一些其他的硬件设备或者软件资源比如网卡,显示器…...
ffmpeg使用
1 下载FFmpeg安装 官网地址:https://www.ffmpeg.org/download.html#build-windows 进入网址,点击下面红框部分 点击下面范围进行下载,下载速度有点慢,等等吧! 下载成功后,解压后,复制bin的路…...
/分区器如何确定)
spark中的并行度(分区数)/分区器如何确定
源头RDD有自己的分区计算逻辑,一般没有分区器,并行度是根据分区算法自动计算的,RDD的compute函数中记录了数据如何而来,如何分区的hadoopRDD,根据XxxinputFormat.getInputSplits()来决定,比如默认的TextInputFormat将文…...

00后女生“云摆摊”两周赚1.5万,实体店转战线上真的能赚钱吗?
最近,山东临沂的00后女生利用小程序在线上“云摆摊”卖水果,两周赚1.5万,引发网友热议。不少人发出质疑的声音:年轻人不要有稳定的工作不做,去摆摊;网上开店成本低,开实体店结果就难说了&#x…...

你的串口通信稳定吗?STM32CubeMX配置USART1的避坑指南与稳定性测试
STM32串口通信稳定性实战:从配置陷阱到压力测试全解析 当你的嵌入式设备在实验室运行良好,却在现场频繁出现数据丢失或乱码时,问题往往出在那些容易被忽视的细节上。串口通信作为嵌入式系统中最基础的调试与数据交互接口,其稳定性…...

终极指南:5分钟快速解密网易云音乐NCM文件,实现音乐自由
终极指南:5分钟快速解密网易云音乐NCM文件,实现音乐自由 【免费下载链接】ncmdump ncmdump - 网易云音乐NCM转换 项目地址: https://gitcode.com/gh_mirrors/ncmdu/ncmdump 还在为网易云音乐下载的NCM格式文件无法在其他播放器播放而烦恼吗&#…...

AI架构绘图副驾驶:用自然语言生成专业Excalidraw架构图
1. 项目概述与核心价值 如果你和我一样,每天都要面对陌生的、动辄几十个微服务的复杂代码库,或者需要向团队解释一个新系统的设计,那你一定理解那种“认知过载”的痛苦。在脑海里构建整个系统的架构图,试图理清服务间的调用关系和…...

BlueArchive-Cursors:为你的Windows桌面注入二次元灵魂
BlueArchive-Cursors:为你的Windows桌面注入二次元灵魂 【免费下载链接】BlueArchive-Cursors Custom mouse cursor theme based on the school RPG Blue Archive. 项目地址: https://gitcode.com/gh_mirrors/bl/BlueArchive-Cursors 还在使用Windows默认的单…...

英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南
英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否厌倦了在英雄联盟排位赛中手忙脚乱地查询对手战绩?是否希望有一个智能助…...

模拟芯片巨头Maxim 2010技术日深度解读:从工艺到应用的创新启示
1. 一场迟到的“技术盛宴”:深入解读Maxim 2010年编辑分析师日 在半导体行业,尤其是模拟芯片这个领域,巨头们的一举一动都牵动着整个产业链的神经。2010年9月底,模拟与混合信号半导体领域的“安静巨人”——Maxim Integrated&…...

3个步骤掌握Sketch MeaXure:设计师与开发者的终极协作桥梁
3个步骤掌握Sketch MeaXure:设计师与开发者的终极协作桥梁 【免费下载链接】sketch-meaxure 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-meaxure 你是否厌倦了在Sketch中手动测量每个元素、反复截图标注的日子?Sketch MeaXure正是为解…...

光子计算如何突破LLM推理中的KV缓存瓶颈
1. 光子计算在KV缓存管理中的突破性应用在当今大语言模型(LLM)推理领域,一个令人惊讶的事实正在发生:计算能力已不再是主要瓶颈。随着上下文窗口从最初的几千token扩展到如今的百万级(如Qwen2.5)࿰…...

Godot 4中构建真实水体渲染:从PBR原理到性能优化实践
1. 项目概述:从像素到波光,在Godot中构建真实水体如果你正在用Godot引擎开发一款开放世界游戏、一个宁静的模拟场景,或者任何需要水体表现的项目,那么“水”的质量几乎直接决定了场景的沉浸感上限。静态的、像果冻一样的平面贴图早…...

从绕接到焊接:硬件连接技术的演进与工程思维启示
1. 从“绕接”到“焊接”:一个硬件工程师的认知进化史十几年前,我刚踏入硬件设计这行,第一次在实验室的角落里看到前辈们用一把像笔一样的工具,将一根细细的导线在方形的金属柱上绕出紧密的螺旋。那是我与“绕接”技术的初次相遇。…...