优化:遍历List循环查找数据库导致接口过慢问题
前提:
我们在写查询的时候,有时候会遇到多表联查,一遇到多表联查大家就会直接写sql语句,不会使用较为方便的LambdaQueryWrapper去查询了。作为一个2024新进入码农世界的小白,我喜欢使用LambdaQueryWrapper,虽然他会有很多缺点,但是能跑就行嘛。
背景:
我在公司写了一套查询,遍历一个list,在遍历的时候每次都会查询一次数据库,该list极有可能是十万级的,我的好师兄这时候给我说为什么我的接口调的那么慢,我说我也不知道啊,然后他给我看了一下我的代码,咬牙切齿到,你一个查询要跟数据库交互10万次啊,查一次就算是10ms,你这也得超过10m了。随后我就一边被他吐槽一边听他说解决方案。
解决方案:
不要循环查找数据库,和数据库交互是很慢的,我们选择的应该是先直接把这一大把数据全部查出来,然后交给内存处理这些数据就好了,内存处理数据是非常快的。
举个栗子:
现在我们有一个类目(类目名称:金属),该类目有一些属性(金属颜色,金属材料),属性会有属性值(颜色:黄绿蓝;材料:金银铁)。类目,属性,都是单独一张表来记录,属性值单表中记录属性的id,类目和属性之间存在一张关联表。我们根据此关联关系需要做一个属性的分页,分页需要展示的数据为属性的基本数据+属性的类目+属性值。
思路:
OK!!!!!我们来理一下思路。基本数据就不在多说了,主要关注一下我们的分类info和属性值info。首先是属性值:我们查到属性分页(只含有基本数据)数据后,需要根据属性ids到属性值表中查询到属性值然后塞进返回值中返回。一下我想到的就是遍历ids,然后每一次遍历的时候拿着属性id在属性值表中查到这个属性值List然后添加到结果集合中,最后返回出去。很好想对吧,但是这就触及到了我们的这篇文章的问题了,假如有10万的属性,那我们就会10万次交互数据库,最后造成接口查询十分缓慢。
这个方法我就是用了这个循环遍历查询数据库的方式,导致接口反应速度极慢
public List<ItemAttributePoInfo> processCategoryAndValues(List<ItemAttributePo> itemAttributePos) {List<ItemAttributePoInfo> results = AbstractModelConverter.convertListByBeanCopier(itemAttributePos, ItemAttributePoInfo.class);//最终需要被返回的结果集List<Long> attributeIds = results.stream().map(e -> e.getId()).collect(Collectors.toList());for (ItemAttributePoInfo result : results) {Long attributeId = result.getId();//属性idLambdaQueryWrapper<ItemAttributeValue> attributeValueWrapper = new LambdaQueryWrapper<>();attributeValueWrapper.eq(ItemAttributeValue::getAttributeId, attributeId);List<ItemAttributeValue> itemAttributeValueList = itemAttributeValueReadService.list(attributeValueWrapper);List<ItemAttributeValueInfo> itemAttributeValueInfos = AbstractModelConverter.convertList(itemAttributeValueList, ItemAttributeValueInfo.class);result.setItemAttributeValueInfos(itemAttributeValueInfos);}return results;}
}正确做法:
那么正确的做法是什么呢,就是我上文所说的我们应该根据属性ids一次性把所有的数据都查出来,然后我们根据属性id分组。分组成为一个Map<Long, List<属性值>>。这样我们最后直接循环结果集,将对应属性id作为map的key,从map中查到对应属性值的list塞入即可。下面的代码为正确做法。
public List<ItemAttributePoInfo> processCategoryAndValues(List<ItemAttributePo> itemAttributePos) {List<ItemAttributePoInfo> results = AbstractModelConverter.convertListByBeanCopier(itemAttributePos, ItemAttributePoInfo.class);List<Long> attributeIds = results.stream().map(e -> e.getId()).collect(Collectors.toList());//封装属性值信息LambdaQueryWrapper<ItemAttributeValue> attributeValueWrapper = new LambdaQueryWrapper<>();attributeValueWrapper.in(ItemAttributeValue::getAttributeId, attributeIds);List<ItemAttributeValue> itemAttributeValueList = itemAttributeValueReadService.list(attributeValueWrapper);Map<Long, List<ItemAttributeValue>> attributeValueMaps = itemAttributeValueList.stream().collect(Collectors.groupingBy(ItemAttributeValue::getAttributeId));if (CollectionUtils.isNotEmpty(itemAttributeValueList)) {for (ItemAttributePoInfo result : results) {List<ItemAttributeValue> attributeValueResult = attributeValueMaps.get(result.getId());if (CollectionUtils.isEmpty(attributeValueResult)) {result.setItemAttributeValueInfos(new ArrayList<>());} else {result.setItemAttributeValueInfos(AbstractModelConverter.convertList(attributeValueResult, ItemAttributeValueInfo.class));}}}return results;}注:
该方法可能对刚刚使用这个方法的同学不太友好,理解起来相对比较费力,大家要多看两遍,代码也很重要,理解其中的意思,该例子中的类目由于设计到关联表,使用起来可能理解难度会更大一些,先把属性值理解了再来看类目更容易一些。
附:
类目info:
public List<ItemAttributePoInfo> processCategoryAndValues(List<ItemAttributePo> itemAttributePos) {List<ItemAttributePoInfo> results = AbstractModelConverter.convertListByBeanCopier(itemAttributePos, ItemAttributePoInfo.class);//最终需要被返回的结果集List<Long> attributeIds = results.stream().map(e -> e.getId()).collect(Collectors.toList());//封装类目信息LambdaQueryWrapper<ItemCategoryAttributeRel> categoryAttributeRelWrapper = new LambdaQueryWrapper<>();categoryAttributeRelWrapper.in(ItemCategoryAttributeRel::getAttributeId, attributeIds);List<ItemCategoryAttributeRel> itemCategoryAttributeRelList = itemCategoryAttributeRelReadService.list(categoryAttributeRelWrapper);if (CollectionUtils.isNotEmpty(itemCategoryAttributeRelList)) {List<Long> categoryIds = itemCategoryAttributeRelList.stream().map(e -> e.getCategoryId()).collect(Collectors.toList());Map<Long, List<ItemCategoryAttributeRel>> categoryAttributeMaps = itemCategoryAttributeRelList.stream().collect(Collectors.groupingBy(ItemCategoryAttributeRel::getAttributeId));List<ItemCategoryPo> categorise = itemCategoryPoReadService.findByIds(categoryIds);if (CollectionUtils.isNotEmpty(categorise)) {Map<Long, ItemCategoryPo> categoryMap = categorise.stream().collect(Collectors.toMap(e -> e.getId(), e -> e));for (ItemAttributePoInfo result : results) {List<ItemCategoryAttributeRel> itemCategoryAttributeRels = categoryAttributeMaps.get(result.getId());if (CollectionUtils.isNotEmpty(itemCategoryAttributeRels)) {List<ItemCategoryPo> categoryResult = itemCategoryAttributeRels.stream().map(ItemCategoryAttributeRel::getCategoryId).map(categoryMap::get).collect(Collectors.toList());if (CollectionUtils.isEmpty(categoryResult)) {result.setItemCategoryPoInfo(new ItemCategoryPoInfo());} else {result.setItemCategoryPoInfo(AbstractModelConverter.convertModelByBeanCopier(categoryResult.get(0), ItemCategoryPoInfo.class));}}}}}
}相关文章:

优化:遍历List循环查找数据库导致接口过慢问题
前提: 我们在写查询的时候,有时候会遇到多表联查,一遇到多表联查大家就会直接写sql语句,不会使用较为方便的LambdaQueryWrapper去查询了。作为一个2024新进入码农世界的小白,我喜欢使用LambdaQueryWrapper,…...

NoSQL 之 Redis 配置与常用命令
一、关系型数据库与非关系型数据库 1、数据库概述 (1)关系型数据库 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记 录。 SQL 语句(标准数据查询语言&am…...

用SpringBoot打造坚固防线:轻松实现XSS攻击防御
在这篇博客中,我们将深入探讨如何使用SpringBoot有效防御XSS攻击。通过结合注解和过滤器的方式,我们可以为应用程序构建一个强大的安全屏障,确保用户数据不被恶意脚本所侵害。 目录 什么是XSS攻击?SpringBoot中的XSS防御策略使用…...

2024机器人科研/研发领域最新研究方向岗位职责与要求
具身智能工程师 从事具身智能领域的技术研究或产品开发,制定具身智能技术标准,利用大模型技术来提高机器人的智能化水平,研究端云协同的机器人系统框架,并赋能人形/复合等各类形态的机器人。具体内容包括不限于: 1、负…...

笔记:Newtonsoft.Json 序列化接口集合
在使用 Newtonsoft.Json 序列化接口集合时,一个常见的挑战是如何处理接口的具体实现,因为接口本身并不包含关于要实例化哪个具体类的信息。为了正确序列化和反序列化接口集合,你需要提供一些额外的信息或使用自定义的转换器来指导 Newtonsoft…...
【Unity设计模式】✨使用 MVC 和 MVP 编程模式
前言 最近在学习Unity游戏设计模式,看到两本比较适合入门的书,一本是unity官方的 《Level up your programming with game programming patterns》 ,另一本是 《游戏编程模式》 这两本书介绍了大部分会使用到的设计模式,因此很值得学习 本…...

CDH安装和配置流程
这份文件是一份关于CDH(Clouderas Distribution Including Apache Hadoop)安装的详细手册,主要内容包括以下几个部分: 1. **前言**: - CDH是基于Apache Hadoop的发行版,由Cloudera公司开发。 - 相比…...
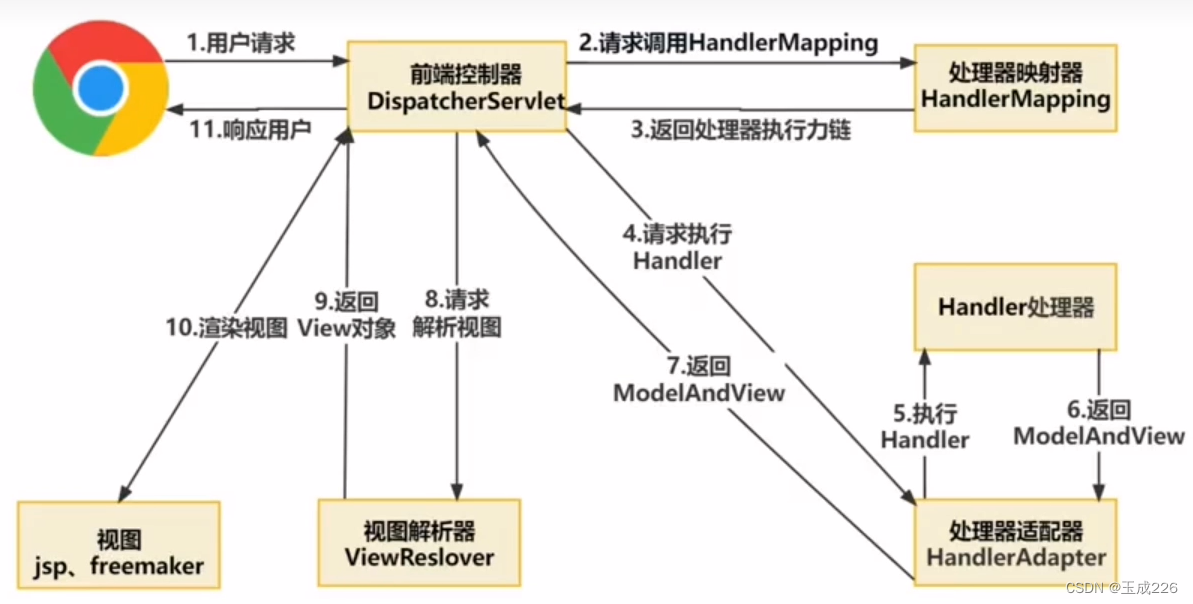
SpringMVC:SpringMVC执行流程
文章目录 一、介绍二、什么是MVC 一、介绍 Spring MVC 是一种基于Java的Web框架,它采用了MVC(Model - View - Controller)设计模式,通过吧Model、View和Controller分离,将Web层进行职责解耦,把复杂的Web应…...
如何在前端网页实现live2d的动态效果
React如何在前端网页实现live2d的动态效果 业务需求: 因为公司需要做机器人相关的业务,主要是聊天形式的内容,所以需要一个虚拟的卡通形象。而且为了更直观的展示用户和机器人对话的状态,该live2d动画的嘴型需要根据播放的内容来…...

昇思25天学习打卡营第15天|linchenfengxue
Pix2Pix实现图像转换 Pix2Pix概述 Pix2Pix是基于条件生成对抗网络(cGAN, Condition Generative Adversarial Networks )实现的一种深度学习图像转换模型,该模型是由Phillip Isola等作者在2017年CVPR上提出的,可以实现语义/标签到…...

软考中级数据库系统工程师备考经验分享
前几天软考成绩出了,赶紧查询了一下发现自己顺利通过啦(上午63,下午67,开心),因此本文记录一下我的备考经验分享给大家。因为工作中项目管理类的知识没有系统学习过,本来想直接报名软考高级证书…...

Centos7删除MariaDB
在 CentOS 7 上删除 MariaDB 可以通过 yum 包管理器来完成。以下是一步一步的指导: 打开终端:首先,你需要打开你的 CentOS 7 系统的终端。 停止 MariaDB 服务(如果正在运行):在卸载 MariaDB 之前ÿ…...

【Docker系列】Docker 镜像构建中的跨设备移动问题及解决方案
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

C++友元函数和友元类的使用
1.友元介绍 在C++中,友元(friend)是一种机制,允许某个类或函数访问其他类的私有成员。通过友元,可以授予其他类或函数对该类的私有成员的访问权限。友元关系在一些特定的情况下很有用,例如在类之间共享数据或实现特定的功能。 友元可以分为两种类型:类友元和函数友元。…...

黑马苍穹外卖技术亮点 详情
1.使用工厂模式和策略模式实现布隆过滤器解决缓存穿透问题 Bitmap Bitmap是一种数据结构,它使用位图来表示数据。在处理大量数据时,Bitmap可以通过将每个数据元素映射到一个位,然后使用位运算来对数据进行操作。 通过使用Bitmap,…...

Python酷库之旅-第三方库Pandas(005)
目录 一、用法精讲 7、pandas.read_clipboard函数 7-1、语法 7-2、参数 7-3、功能 7-4、返回值 7-5、说明 7-6、用法 7-6-1、代码示例 7-6-2、结果输出 8、pandas.DataFrame.to_clipboard函数 8-1、语法 8-2、参数 8-3、功能 8-4、返回值 8-5、说明 8-6、用法…...

javascripr如何设计弹出输入框并在网页内输出输入内容
javascript如何设计弹出输入对话框 这里就需要用到prompt语言 它的语法格式是 prompt(对话框内容) 如何把在对话框里输入内容输出到网页里,需要先定义一个变量,用var或let都可以。 假定变量名为a,代码是 let aprompt(请输入…...

gitee代码初次上传步骤
ps. 前提是已经下载安装gitee 一、在本地项目目录下空白处右击,选择“Git Bash Here” 二、初始化 git init 三、添加、提交代码(注意add与点之间的空格) git add . git commit -m 添加注释 四、连接、推送到gitee仓库 git remote add …...

android调用openssl库
android 调用openssl库 一、openssl安装编译 下载openssl-1.1.1w.tar.gz和android-ndk-r21e-linux-x86_64.zip解压android-ndk-r21e-linux-x86_64.zip到/opt/pj_ssl目录下,然后配置环境 vim ~/.bashrc增加如下内容 export NDK_HOME/opt/pj_ssl/android-ndk-r21e…...
Hugging face Transformers(3)—— Tokenizer
Hugging Face 是一家在 NLP 和 AI 领域具有重要影响力的科技公司,他们的开源工具和社区建设为NLP研究和开发提供了强大的支持。它们拥有当前最活跃、最受关注、影响力最大的 NLP 社区,最新最强的 NLP 模型大多在这里发布和开源。该社区也提供了丰富的教程…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能
BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否觉得网易云音乐PC版功能有限,界面单调?…...