【机器学习】机器学习重塑广告营销:精准触达,高效转化的未来之路

📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


❀目录
- 📒1. 引言
- 📙2. 机器学习基础与广告营销的结合
- 🧩机器学习在广告营销中的核心应用领域
- 🌹用户画像构建
- 🌺广告内容个性化推荐
- 🌼广告投放时机与渠道优化
- 🌸广告效果预测与评估
- 📕3. 精准触达:机器学习如何提升广告定位的准确性
- 🌞数据收集与预处理:构建全面用户画像的基石
- 🌙特征工程:挖掘数据背后的价值,定义关键指标
- ⭐模型训练与优化:从海量数据中学习用户偏好
- ⛰️实时反馈与动态调整:确保广告触达的持续精准
- 🌈案例分享:精准触达在实际广告营销中的应用
- 📚4. 高效转化:机器学习驱动的广告效果优化
- 🏞️转化路径分析:理解用户从点击到购买的每一步
- 🌄跨渠道协同营销:机器学习助力全渠道转化
- 📜5. 机器学习在广告营销中的挑战与应对策略
- 🍁数据隐私与安全:保障用户信息不被滥用
- 🍂算法偏见与公平性:确保广告触达的公正性
- 📝6. 未来展望:机器学习在广告营销中的发展趋势
- 🎩跨领域合作与创新:广告营销与其他行业的联动
- 🎈可持续发展与社会责任:绿色广告营销的探索
- 📖7. 总结
- 💧机器学习对广告营销行业的深远影响
- 🔥对未来广告营销行业的展望与期待
📒1. 引言
在过往,广告营销往往依赖于经验判断、市场调研和广泛的媒体投放,试图以量取胜,覆盖尽可能多的潜在消费者。然而,这种方式不仅成本高昂,而且效率低下,大量广告资源被浪费在对产品不感兴趣或无需求的受众身上。随着消费者行为日益多元化、个性化,以及信息获取渠道的碎片化,传统的广告营销策略显得愈发力不从心。

正是在这样的背景下,机器学习技术如同一股清新的风,为广告营销行业带来了颠覆性的改变。通过深度挖掘和分析海量用户数据,包括浏览历史、搜索记录、购买行为、社交媒体互动等多维度信息,机器学习模型能够构建出每个用户的精准画像,理解其兴趣偏好、消费习惯乃至潜在需求。这种能力使得广告营销能够实现从“广而告之”到“精准推送”的跨越,让每一条广告都能精准触达真正有需求的用户,大大提升了广告的有效性和转化率。
更进一步,机器学习还赋予了广告营销动态调整与优化的能力。基于实时反馈和数据分析,系统能够自动调整广告内容、投放时间、渠道策略等,确保广告活动始终保持在最佳状态,实现资源的最优配置。这种智能化的管理方式,不仅降低了人为干预的复杂性和不确定性,还极大地提升了广告营销的效率与效果。
📙2. 机器学习基础与广告营销的结合
🧩机器学习在广告营销中的核心应用领域
机器学习在广告营销中的核心应用领域包括精准用户画像构建、个性化广告推荐、广告投放优化、广告效果评估与反馈以及跨渠道整合营销等方面。这些应用不仅提高了广告营销的效率和效果,还为广告主提供了更加科学、智能的决策支持。

🌹用户画像构建
概念: 机器学习通过分析用户的行为数据(如浏览历史、购买记录、搜索关键词等),结合社交媒体信息、地理位置等多维度数据,构建出精准的用户画像。这些画像不仅包含用户的基本属性,还深入揭示了用户的兴趣偏好、消费习惯、心理特征等,为个性化广告推送提供了坚实的基础。
应用实例:
- 电商平台利用机器学习算法分析用户的购买历史和浏览行为,预测用户可能感兴趣的商品,实现精准推荐。
- 社交媒体平台通过用户发布的内容和互动行为,构建用户兴趣图谱,为广告主提供精准的目标用户群体。
🌺广告内容个性化推荐
概念: 基于用户画像,机器学习能够实现广告的个性化推荐。通过分析用户的兴趣偏好和实时行为数据,机器学习算法能够实时调整广告内容、形式和投放策略,确保每个用户都能接收到与其最相关的广告信息。
应用实例:
- 视频流媒体平台利用机器学习算法分析用户的观看历史和兴趣标签,为其推荐个性化的广告内容。
- 新闻资讯类应用通过机器学习分析用户的阅读习惯和兴趣点,推送定制化的广告信息。
🌼广告投放时机与渠道优化
概念: 机器学习在广告投放优化中发挥着重要作用。通过对广告活动效果的实时监测和数据分析,机器学习算法能够自动调整广告投放的时间、渠道、预算等参数,以实现广告效果的最大化。此外,机器学习还能帮助广告主预测广告活动的潜在回报,为广告预算的分配提供科学依据。
应用实例:
- 程序化广告平台利用机器学习算法进行实时竞价和智能投放,确保广告能够精准触达目标用户群体。
- 广告主通过机器学习模型预测广告的点击率、转化率等关键指标,优化广告创意和投放策略。
🌸广告效果预测与评估
概念: 机器学习还能够对广告效果进行全面、客观的评估,为广告主提供有价值的反馈。通过分析广告活动的曝光量、点击率、转化率等数据指标,机器学习算法能够评估广告的效果和ROI(投资回报率),帮助广告主了解广告活动的表现,并据此调整投放策略。
应用实例:
- 广告公司利用机器学习模型对广告活动的数据进行深入分析,评估广告创意的吸引力和目标受众的接受度。
- 品牌主通过机器学习反馈的数据,了解产品在市场中的表现和消费者需求,为产品改进和营销策略调整提供依据。
📕3. 精准触达:机器学习如何提升广告定位的准确性
机器学习在提升广告定位的准确性方面发挥着至关重要的作用。它通过分析大量用户数据,识别用户的行为模式、兴趣偏好以及潜在需求,从而能够更精准地将广告推送给目标受众。

🌞数据收集与预处理:构建全面用户画像的基石
数据收集与预处理是构建全面用户画像的基石,它们为后续的特征工程、模型训练等环节提供了必要的数据基础。
数据收集
数据收集通常涉及从多个来源获取用户数据,包括但不限于网站行为、APP使用记录、社交媒体互动、交易历史等。在实际操作中,你可能需要使用API调用、数据库查询、日志文件分析等技术手段来收集数据。
数据收集代码示例(伪代码)
# 假设有几个数据源需要收集
data_sources = ['website_logs', 'app_usage', 'social_media', 'transaction_history'] # 定义一个函数来收集数据(这里只是概念性表示)
def collect_data(sources): collected_data = [] for source in sources: if source == 'website_logs': # 假设有一个函数可以读取网站日志文件 website_logs = read_website_logs() collected_data.append(website_logs) elif source == 'app_usage': # 假设有一个API可以获取APP使用数据 app_usage = fetch_app_usage_api() collected_data.append(app_usage) # ... 其他数据源类似处理 # 合并数据(这里需要处理数据格式统一、去重等问题) # merged_data = merge_and_clean_data(collected_data) # 注意:合并和清洗数据通常在预处理阶段进行 return collected_data # 这里仅作为示例,实际应返回合并清洗后的数据 # 调用函数收集数据(此处省略了合并和清洗步骤)
collected_data = collect_data(data_sources)
数据预处理
数据预处理是数据收集之后的关键步骤,它涉及数据清洗、格式转换、缺失值处理、异常值检测与处理、特征选择与提取等多个方面。
数据预处理代码示例(伪代码)
# 假设已经有一个包含原始数据的DataFrame
import pandas as pd # 原始数据示例(实际中会是更复杂的数据结构)
raw_data = pd.DataFrame({ 'user_id': [1, 2, 3, 4], 'age': [25, 30, None, 40], # 包含缺失值 'gender': ['M', 'F', 'M', 'Unknown'], # 包含非标准值 'page_views': [100, 200, 300, 400], 'purchase_amount': [100.0, None, 150.0, 200.0] # 包含缺失值和浮点数
}) # 数据清洗示例
def preprocess_data(data): # 处理缺失值 data['age'].fillna(data['age'].mean(), inplace=True) # 用平均值填充年龄缺失值 data['purchase_amount'].fillna(0, inplace=True) # 假设未购买则金额为0 # 处理异常值或非标准值(这里仅做简单示例) data['gender'].replace({'Unknown': 'Other'}, inplace=True) # 将'Unknown'替换为'Other' # 特征选择(此处仅保留部分列作为示例) selected_features = ['user_id', 'age', 'gender', 'page_views', 'purchase_amount'] processed_data = data[selected_features] # 可能还需要进行其他预处理步骤,如编码分类变量、标准化数值变量等 # ... return processed_data # 调用函数进行预处理
processed_data = preprocess_data(raw_data) # 查看预处理后的数据
print(processed_data)
🌙特征工程:挖掘数据背后的价值,定义关键指标
特征工程是机器学习项目中至关重要的一步,它涉及从原始数据中提取、选择和构造特征,以便更好地训练模型。特征工程的目标是挖掘数据背后的价值,定义出对预测目标有重要影响的关键指标(或称为特征)。
特征工程代码示例(伪代码)
import pandas as pd
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split # 假设df是已经加载好的DataFrame
# 这里我们仅使用部分列作为示例
columns = ['user_id', 'product_id', 'price', 'category', 'rating', 'view_count', 'search_keyword', 'purchase']
data = { 'user_id': [1, 2, 3, 4], 'product_id': [101, 102, 103, 104], 'price': [100, 200, 150, 300], 'category': ['Electronics', 'Books', 'Electronics', 'Clothing'], 'rating': [4.5, 5.0, 4.0, 3.5], 'view_count': [5, 10, 3, 8], 'search_keyword': ['smartphone', 'python', 'headphones', 'shirt'], 'purchase': [1, 0, 1, 0] # 1表示购买,0表示未购买
}
df = pd.DataFrame(data) # 特征提取(示例:从搜索关键词中提取关键词长度)
df['keyword_length'] = df['search_keyword'].apply(len) # 特征选择(此处直接选择所有特征,实际中可能需要筛选)
features = df.drop(['user_id', 'product_id', 'purchase'], axis=1)
labels = df['purchase'] # 特征构造(示例:构造价格区间特征)
def price_bucket(price): if price <= 100: return 'Low' elif price <= 250: return 'Medium' else: return 'High'
df['price_bucket'] = df['price'].apply(price_bucket)
features = pd.concat([features, pd.get_dummies(df['price_bucket'], prefix='price_bucket')], axis=1) # 特征转换(编码和标准化)
# 对类别特征进行编码
le = LabelEncoder()
for col in ['category', 'search_keyword']: features[col] = le.fit_transform(features[col]) # 对数值特征进行标准化(这里仅对price进行示例)
scaler = StandardScaler()
features['price'] = scaler.fit_transform(features[['price']]) # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42) # 现在X_train和X_test包含了处理后的特征,可以用于模型训练
⭐模型训练与优化:从海量数据中学习用户偏好
模型训练与优化是一个复杂且迭代的过程,特别是在处理海量数据以学习用户偏好时。由于具体的实现细节会依赖于所使用的编程语言、机器学习库、数据集的特性以及目标任务的性质
模型评估代码示例(伪代码)
from sklearn.metrics import accuracy_score, roc_auc_score # 预测测试集
y_pred = model.predict(X_test) # 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}") # 如果问题适合,也可以计算AUC-ROC分数
y_pred_proba = model.predict_proba(X_test)[:, 1]
auc_roc = roc_auc_score(y_test, y_pred_proba)
print(f"AUC-ROC: {auc_roc}")
模型优化代码示例(伪代码)
# 使用网格搜索进行参数调优(这里只是示例,实际中需要导入GridSearchCV)
# from sklearn.model_selection import GridSearchCV # param_grid = {
# 'C': [0.1, 1, 10, 100], # 正则化强度的倒数
# 'max_iter': [100, 500, 1000]
# } # grid_search = GridSearchCV(model, param_grid, cv=5, scoring='roc_auc')
# grid_search.fit(X_train, y_train) # print("Best parameters found: ", grid_search.best_params_)
# print("Best AUC-ROC: ", grid_search.best_score_)
注意:上述只是提供了一个从数据准备到模型训练、评估和优化的基本框架
⛰️实时反馈与动态调整:确保广告触达的持续精准
实时反馈与动态调整是确保广告触达持续精准的关键。这通常涉及监控广告的表现,并根据实时数据(如点击率、转化率、用户行为等)自动或手动调整广告策略。在实现这一功能时,可能会使用到多种技术,包括但不限于数据分析、机器学习、API调用以及自动化工具。
监控广告表现
import requests
from datetime import datetime, timedelta def fetch_ad_performance(ad_id, start_time, end_time): # 假设这是广告平台的API调用 api_url = f"https://api.adplatform.com/ads/{ad_id}/performance" params = { 'start_time': start_time.isoformat(), 'end_time': end_time.isoformat() } response = requests.get(api_url, params=params) if response.status_code == 200: return response.json() # 返回广告表现数据 else: return None # 示例用法
current_time = datetime.now()
start_time = current_time - timedelta(hours=1) # 过去1小时的数据
performance_data = fetch_ad_performance('ad_123', start_time, current_time)分析数据并决定调整策略
def analyze_and_adjust(performance_data, ad_id, ad_platform_client): if not performance_data: return # 假设我们关注的是点击率(CTR) clicks = performance_data.get('clicks', 0) impressions = performance_data.get('impressions', 0) ctr = clicks / impressions if impressions > 0 else 0 # 假设我们的目标是保持CTR在0.05以上 if ctr < 0.05: # 调整策略,例如增加预算、更换广告素材或定位更精准的目标受众 print(f"Adjusting ad {ad_id} due to low CTR ({ctr})") # 这里是伪代码,具体实现会依赖于广告平台的API # ad_platform_client.increase_budget(ad_id, 10) # 假设有这样一个方法来增加预算 # 或其他调整策略 # 假设我们有一个广告平台客户端的实例
ad_platform_client = AdPlatformClient() # 这是一个假设的类,你需要根据实际情况来实现
analyze_and_adjust(performance_data, 'ad_123', ad_platform_client)
🌈案例分享:精准触达在实际广告营销中的应用
肯德基可达鸭:多面触达引爆热潮
肯德基可达鸭的爆火是精准触达的一个经典案例。起初,可达鸭作为肯德基儿童节限定玩具,通过线下门店渠道吸引顾客。随后,肯德基利用短视频平台等线上渠道,发布可达鸭的魔性舞蹈视频,引发网友模仿和关注。这种从多个渠道(线上+线下)获得类似信息的策略,显著提升了可达鸭的曝光度和知名度。
精准触达策略:
- 多渠道传播:通过短视频平台、社交媒体、线下门店等多种渠道传播可达鸭的信息,形成全方位覆盖。
- 内容创新:制作具有趣味性和传播性的内容(如魔性舞蹈视频),激发用户的分享欲和购买欲。
- 用户互动:鼓励用户参与可达鸭的二创和分享,增加用户粘性和品牌忠诚度。
成效:
- 可达鸭在短时间内成为热门话题,引发大量关注和讨论。
- 肯德基门店销量激增,可达鸭成为热销商品。
- 品牌知名度和美誉度得到提升。
📚4. 高效转化:机器学习驱动的广告效果优化
机器学习在广告效果优化中发挥着至关重要的作用,它通过高效的数据处理和分析能力,帮助广告主实现广告的精准投放和高效转化

🏞️转化路径分析:理解用户从点击到购买的每一步
概述: 转化路径分析是指通过跟踪和分析用户在产品或服务中的行为,从而了解他们在不同阶段的决策和行为模式,以及最终完成转化的路径。这种分析有助于揭示用户在产品或服务中遇到的问题和挑战,为产品或服务的改进和用户体验优化提供数据支持。
转化路径的关键步骤:
- 广告点击或网站访问
- 浏览与搜索
- 产品对比与选择
- 加入购物车
- 填写订单信息
- 提交订单与支付
- 完成购买与后续服务
转化路径分析是理解和优化用户购买行为的重要手段。通过深入分析用户在不同阶段的决策和行为模式以及最终完成转化的路径,可以发现潜在问题和改进机会,并通过相应的优化措施提升购买转化率和用户体验。对于网站或应用的运营者来说,合理的数据收集、数据处理和数据分析方法至关重要。
🌄跨渠道协同营销:机器学习助力全渠道转化
概述: 跨渠道协同营销在当今数字化时代尤为重要,它要求企业在多个渠道上保持一致的品牌形象,同时实现各渠道间的无缝衔接,以最大化营销效果。机器学习作为人工智能的核心技术之一,正在为跨渠道协同营销提供强大的支持,助力企业实现全渠道转化。
关键步骤:
- 用户画像构建与精准定向
- 营销内容优化与动态调整
- 跨渠道协同与数据共享
📜5. 机器学习在广告营销中的挑战与应对策略
🍁数据隐私与安全:保障用户信息不被滥用
在广告营销中,机器学习技术的应用极大地提升了广告的精准度和效果,但同时也对数据隐私与安全提出了更高要求。为了保障用户信息不被滥用,需要采取一系列措施来加强数据隐私保护和安全防护。

数据隐私保护
遵守法律法规
- 严格遵守各国和地区的数据隐私法规,如欧盟的《通用数据保护条例》(GDPR)、美国的《加州消费者隐私法案》(CCPA)以及中国的《个人信息保护法》等。这些法规对数据处理、存储、传输和共享等方面提出了明确要求,企业应确保自身行为符合法规要求。
数据加密和匿名化处理
- 对敏感数据进行加密处理,确保数据在传输和存储过程中的安全性。同时,通过匿名化处理技术降低数据泄露的风险,保护用户隐私。
隐私保护技术应用
- 利用差分隐私、联邦学习等隐私保护技术,在保护用户隐私的同时进行数据分析。这些技术可以在不泄露原始数据的情况下,实现数据的共享和计算,提高数据的安全性。
数据安全防护
建立安全防御体系
- 构建完善的安全防御体系,包括防火墙、入侵检测系统、安全审计系统等,确保系统免受外部攻击和内部泄露的风险。
数据备份与恢复
- 定期对数据进行备份,并建立快速恢复机制。在数据丢失或损坏时,能够迅速恢复数据,减少损失。
异常检测与响应
- 利用机器学习算法对系统进行异常检测,及时发现潜在的安全威胁。同时,建立快速响应机制,对异常行为进行及时处置,防止事态扩大。
🍂算法偏见与公平性:确保广告触达的公正性
算法偏见是广告营销领域中一个不容忽视的问题,它直接关系到广告触达的公正性。为了确保广告触达的公正性,需要采取一系列措施来减少算法偏见的影响。这些措施包括确保数据多样性与质量控制、提高算法透明性与可解释性、建立公平性与伦理审查机制、采用隐私保护技术以及加强监管与执法力度等。通过这些措施的实施,可以推动广告营销领域向更加公平、公正的方向发展。
📝6. 未来展望:机器学习在广告营销中的发展趋势
未来机器学习在广告营销中的发展趋势将呈现深度个性化与超个性化、数据安全与隐私保护、跨渠道整合与自动化、智能化创意与内容生成以及预测分析与决策支持等关键方向。这些趋势将共同推动广告营销行业的数字化转型和智能化升级,为企业带来更加高效、精准和创新的营销解决方案

🎩跨领域合作与创新:广告营销与其他行业的联动
跨领域合作与创新在广告营销中扮演着越来越重要的角色,这种联动不仅打破了传统行业的界限,还为企业带来了全新的营销机遇和增长点。
电商平台与广告营销的联动
精准投放与销售转化
- 电商平台拥有大量的用户数据和购买行为记录,这些数据为广告营销提供了精准的投放依据。通过数据分析,广告主可以准确识别目标用户群体,实现广告的精准投放。
- 当用户在电商平台上浏览商品时,系统会根据用户的兴趣和购买历史推荐相关广告,提高广告的点击率和转化率。例如,在淘宝、京东等电商平台上,用户经常能看到基于其浏览历史和购买偏好的商品推荐广告。
游戏产业与广告营销的联动
游戏中嵌入广告
- 随着手机游戏产业的快速发展,广告主开始将目光投向这一新兴领域。通过在游戏中嵌入广告,广告主可以实现品牌推广和用户互动。
- 例如,在游戏中设置虚拟商品销售,用户可以通过互动购买虚拟商品,同时广告主也能通过这种方式增加品牌曝光和用户黏性。这种嵌入广告的方式既不会打断玩家的游戏体验,又能有效地传达品牌信息。
影视产业与广告营销的联动
植入广告与剧情融合
- 影视产业是广告投放的重要领域之一。广告主可以将广告植入到影视剧中,通过剧情的融合实现产品和品牌的无缝融入。
- 例如,在电视剧或电影中植入广告场景或产品特写镜头,使观众在观看剧情的同时接受到品牌信息。这种植入广告的方式既不会打断观众的观影体验,又能有效地提升品牌知名度和美誉度。
🎈可持续发展与社会责任:绿色广告营销的探索
绿色广告营销的定义与重要性
绿色广告营销是指企业在广告活动中融入环保、可持续发展和社会责任的理念,通过传播绿色、环保、低碳的信息,推广绿色产品和服务,以提升企业品牌形象和市场竞争力。这种营销方式不仅符合当前社会对环保和可持续发展的要求,也有助于企业塑造积极的社会形象,增强消费者对企业的信任和忠诚度。
绿色广告营销的探索与实践
绿色广告内容的创新
- 环保主题:广告内容应突出环保和可持续发展的主题,如使用可再生材料、节能减排、资源循环利用等。例如,美的生态冰箱的广告就强调了其净水系统、空气净化系统和智能运行系统的环保特点。
- 正面引导:通过广告向消费者传递积极的环保信息,引导消费者形成绿色消费观念。例如,可以展示使用绿色产品对环境和社会带来的好处,以及个人行为对环境的影响。
绿色广告营销的未来展望
绿色广告营销是企业在可持续发展和社会责任方面的重要探索和实践。通过创新广告内容、选择绿色传播渠道和实施绿色公关活动等方式,企业可以不断提升自身的品牌形象和市场竞争力,同时为社会和环境的可持续发展做出贡献。
📖7. 总结
💧机器学习对广告营销行业的深远影响
精准触达:从大众到个体的跨越
在机器学习技术的加持下,广告营销实现了从“大众传播”到“个体定制”的飞跃。通过深度挖掘和分析用户数据,机器学习模型能够精准构建用户画像,理解其独特的兴趣偏好、消费习惯乃至潜在需求。这使得广告内容能够更加贴近用户的个性化需求,实现一对一的精准推送。这种精准触达不仅提高了广告的相关性和吸引力,也大大增强了用户的参与度和满意度。
高效转化:数据驱动的决策优化
机器学习不仅在精准触达方面展现出巨大潜力,更在广告转化的效率提升上发挥了关键作用。基于实时反馈和数据分析,机器学习系统能够自动调整广告策略,包括内容创意、投放时间、渠道选择等,以确保广告活动始终保持在最佳状态。这种智能化的管理方式,使得广告营销更加灵活高效,能够迅速适应市场变化和用户需求的波动,从而实现广告资源的最优配置和转化效率的最大化。
🔥对未来广告营销行业的展望与期待
展望未来,机器学习将继续在广告营销领域发挥引领作用,推动行业向更加智能化、个性化的方向发展。一方面,随着技术的不断进步和数据的持续积累,机器学习模型将更加精准地理解用户需求,实现更加个性化的广告推送和服务。另一方面,机器学习也将与其他新兴技术如虚拟现实、增强现实、区块链等深度融合,为广告营销带来更多创新可能性和应用场景。
总之,机器学习已经并将继续深刻改变广告营销行业的格局和生态。通过精准触达和高效转化,机器学习为品牌与消费者之间创造了更加紧密、高效的互动关系,为广告营销行业注入了新的活力和动力。我们有理由相信,在未来的日子里,机器学习将引领广告营销行业走向一个更加智能化、个性化、融合创新的未来之路。
让我们携手共进,迎接精准触达,高效转化的未来之路的新时代,共同创造更加美好的未来!

相关文章:
【机器学习】机器学习重塑广告营销:精准触达,高效转化的未来之路
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀目录 📒1. 引言📙2. 机器学习基础与广告营销的结合🧩机器学习在广告营销中的核心应用领域🌹用…...

常见的Java运行时异常
常见的Java运行时异常 1、ArithmeticException(算术异常)2、ClassCastException (类转换异常)3、IllegalArgumentException (非法参数异常)4、IndexOutOfBoundsException (下标越界异常…...
CANoe的capl调用Qt制作的dll
闲谈 因为Qt封装了很多个人感觉很好用的库,所以一直想通过CAPL去调用Qt实现一些功能,但是一直没机会(网络上也没看到这方面的教程),这次自己用了两天,踩了很多坑,终于是做成了一个初步的调用方…...

论如何搭建属于自己的服务器?
在现如今的数字化时代中,为了能够搭建网站和运行应用程序,很多人选择搭建属于自己的服务器,下面我们就来了解一下如何搭建服务器吧! 搭建服务器我们首先需要选择适合自身需求的硬件设备,其中包含内存、CPU和存储等配置…...

【C++ OpenCV】机器视觉-二值图像和灰度图像的膨胀、腐蚀、开运算、闭运算
原图 结果图 //包含头文件 #include <opencv2/opencv.hpp>//命名空间 using namespace cv; using namespace std;//全局函数声明部分//我的腐蚀运算 Mat Erode(Mat src, Mat Mask, uint32_t x0, uint32_t y0) {uint32_t x 0, y 0;Mat dst(src.rows, src.cols, CV_8U…...

STMF4学习笔记RTC(天空星)
前言:本篇笔记参考嘉立创文档,连接放在最后 #RTC相关概念定义 Real-Time Clock 缩写 RTC 翻译 实时时钟,是单片机片内外设的一种,作用于提供准确的时间还有日期,这个外设有独立的电源,当单片机停止供电…...

vue数组变化的侦测***
数组变化的侦测 变更方法 vue能够侦听响应式数组的变更方法,并在他们被调用时触发相关更新。这些变更方法包括: push()pop()shift()unshift()splice()sort()reverse() 替换一个数组 变更方法,顾名思义,就是会对调用他们的原数组进…...

k8s-第十节-Ingress
Ingress 介绍 Ingress 为外部访问集群提供了一个 统一 入口,避免了对外暴露集群端口;功能类似 Nginx,可以根据域名、路径把请求转发到不同的 Service。可以配置 https 跟 LoadBalancer 有什么区别? LoadBalancer 需要对外暴露…...
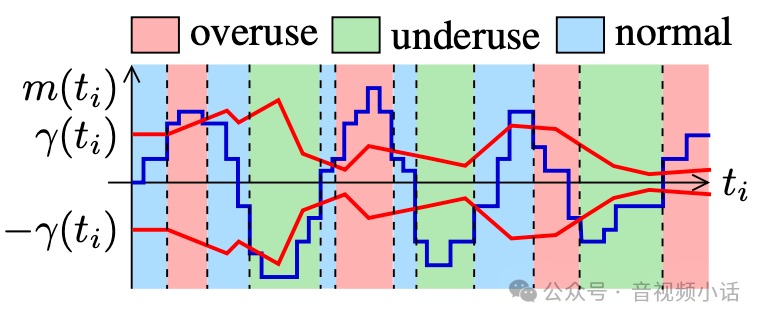
webrtc gcc详解
webrtc的gcc算法(Google Congestion Control),貌似国内很多文章都没有细讲,原理是怎么样的,具体怎么进行计算的。这里详解一下gcc。 gcc算法,主要涉及到: 拥塞控制的关键信息和公式 卡曼滤波算法 gcc如何使用卡曼滤…...

Linux多进程和多线程(七)进程间通信-信号量
进程间通信之信号量 资源竞争 多个进程竞争同一资源时,会发生资源竞争。 资源竞争会导致进程的执行出现不可预测的结果。 临界资源 不允许同时有多个进程访问的资源, 包括硬件资源 (CPU、内存、存储器以及其他外 围设备) 与软件资源(共享代码段、共享数据结构) …...
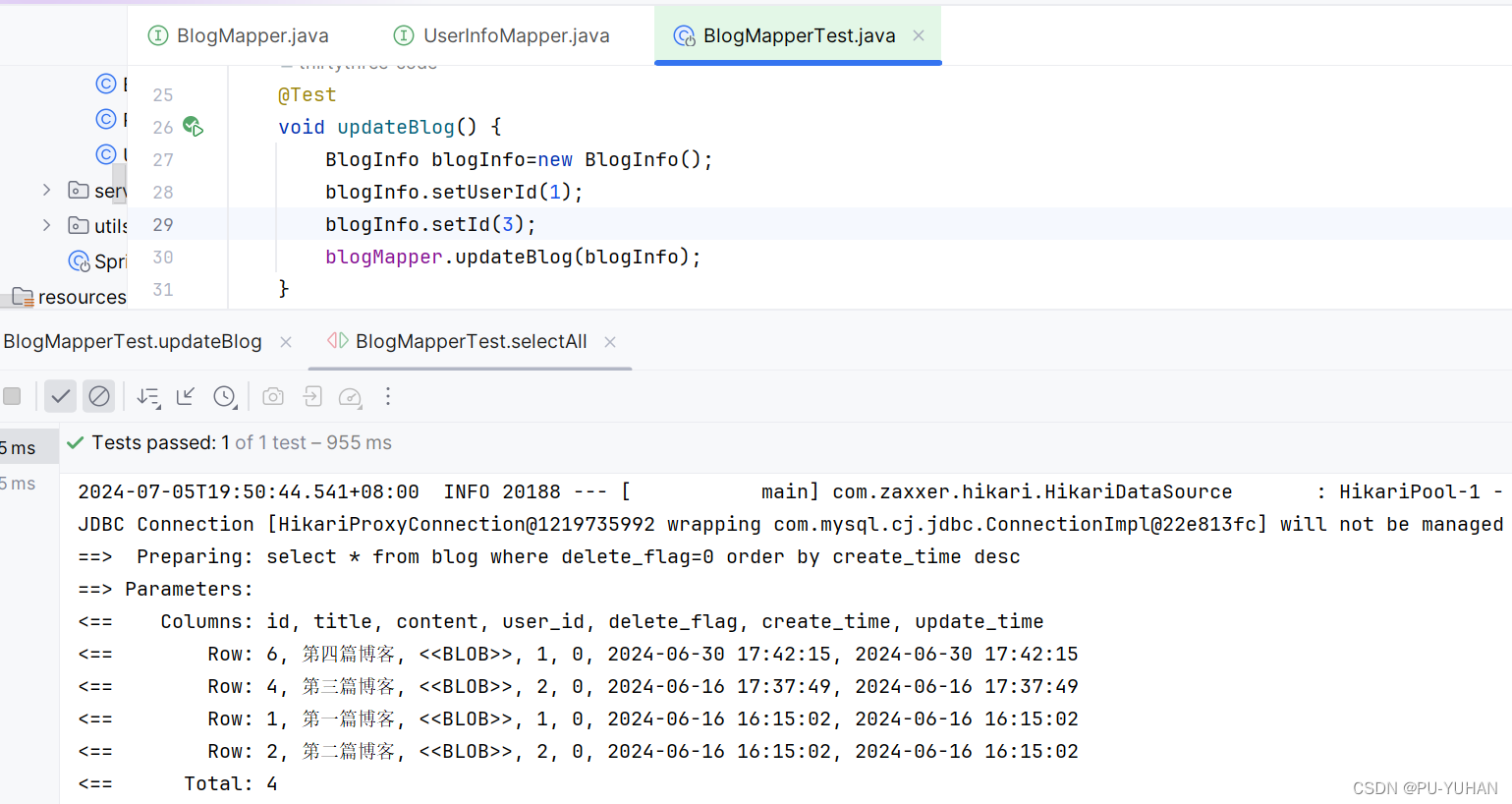
【项目日记(一)】梦幻笔耕-数据层实现
❣博主主页: 33的博客❣ ▶️文章专栏分类:项目日记◀️ 🚚我的代码仓库: 33的代码仓库🚚 🫵🫵🫵关注我带你了解更多项目内容 目录 1.前言2.后端模块3数据库设计4.mapper实现4.1UserInfoMapper4.2BlogMapper 5.总结 1.…...

ElementUI的中国省市区级联数据插件element-china-area-data
安装 npm install element-china-area-data -S import 使用 import {provinceAndCityData,pcTextArr,regionData,pcaTextArr,codeToText, } from "element-china-area-data"; provinceAndCityData省市二级联动数据,汉字+coderegionData省市区三级联动数据pcTextAr…...
Kotlin算法:把一个整数向上取值为最接近的2的幂指数值
Kotlin算法:把一个整数向上取值为最接近的2的幂指数值 import kotlin.math.ln import kotlin.math.powfun main(args: Array<String>) {val number intArrayOf(2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18)number.forEach {println("$…...

简单且循序渐进地查找软件中Bug的实用方法
“Bug”这个词常常让许多开发者感到头疼。即使是经验丰富、技术娴熟的开发人员在开发过程中也难以避免遭遇到 Bug。 软件中的故障会让程序员感到挫败。我相信在你的软件开发生涯中,也曾遇到过一些难以排查的问题。软件中的错误可能会导致项目无法按时交付。因此&…...

基于springboot+vue+uniapp的高校宿舍信息管理系统小程序
开发语言:Java框架:springbootuniappJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包&#…...

(完整音频)DockerHub、OpenAI、GitCode,脱钩时代,我们该如何自处?
本期主播 朱峰:「津津乐道播客网络」创始人,产品及技术专家。(微博:zhufengme)高春辉:「科技乱炖」主播。“中国互联网站长第一人”,科技、互联网领域的连续创业者。(微博࿱…...

macos 10.15系统下载包,macOS Catalina for mac
macOS Catalina 让你喜欢的种种 Mac 体验都更进一步。你可以领略音乐、播客这两款全新 Mac app 的表演;在 Mac 上畅享各款自己心爱的 iPad app;拿起 iPad 和 Apple Pencil,拓展工作空间,释放创意灵感;再打开那些平时常…...
 和 uni.showShareImageMenu({}) 的区别)
uni.showShareMenu({}) 和 uni.showShareImageMenu({}) 的区别
ChatGPT uni.showShareMenu({}) 和 uni.showShareImageMenu({}) 是 Uni-app 中两个不同的 API,它们的作用和用法有所不同: uni.showShareMenu({}) 作用:用于显示当前页面的分享菜单,通常显示在页面的右上角(类似于微…...

Spring Boot logback 日志文件配置
引入依赖 <dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency>logback-spring.xml 配置 <?xml version"1.0" encoding"UTF-8&quo…...
240705_昇思学习打卡-Day17-基于 MindSpore 实现 BERT 对话情绪识别
240705_昇思学习打卡-Day17-基于 MindSpore 实现 BERT对话情绪识别 近期确实太忙,此处仅作简单记录: 模型简介 BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

Taotoken的TokenPlan套餐如何实现更经济的模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的TokenPlan套餐如何实现更经济的模型调用 1. 理解TokenPlan的计费模式 在模型应用开发过程中,成本的可预测性…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...