Transformer自注意力机制(Self-Attention)模型
上一篇我们介绍了transform专题一:Seq2seq model,也知道了transfrom属于seq2seq模型,这一排篇咱们接着介绍另外几种seq2seq架构的模型。)RNN(循环神经网络)CNN(卷积神经网络),最后我们还会介绍一种transformer采用的self-attention模型
RNN(Recurrent Neural Network)和CNN(Convolutional Neural Network)是两种不同类型的神经网络架构,分别适用于不同类型的数据和任务。下面我们来详细介绍这两种网络的原理、特点和应用场景。
RNN(循环神经网络)
原理
RNN是一类用于处理序列数据的神经网络,其结构允许信息在序列的各个时间步之间传递。与传统的前馈神经网络不同,RNN具有循环连接,使其能够处理时间序列数据或其他顺序相关的数据。
RNN的基本单元是一个神经元,它在每个时间步都接收当前输入和前一时间步的隐藏状态,然后计算出当前的隐藏状态。这个隐藏状态不仅包含当前输入的信息,还包含前一时间步的信息。
数学表达
RNN的核心公式如下:
[ h_t = \sigma(W_h \cdot h_{t-1} + W_x \cdot x_t + b) ]
其中:
- ( h_t ) 是当前时间步的隐藏状态
- ( h_{t-1} ) 是前一时间步的隐藏状态
- ( x_t ) 是当前时间步的输入
- ( W_h ) 和 ( W_x ) 是权重矩阵
- ( b ) 是偏置向量
- ( \sigma ) 是激活函数(如tanh或ReLU)
特点
- 处理序列数据:RNN擅长处理和预测序列数据,能够捕捉时间步之间的依赖关系。
- 记忆能力:通过循环连接,RNN能够记忆序列中的信息,适用于需要上下文信息的任务。
- 梯度消失和爆炸:RNN在处理长序列时可能会遇到梯度消失或梯度爆炸问题,影响训练效果。
变种
为了克服RNN的缺点,研究人员提出了多种RNN的变种:
- LSTM(长短期记忆网络):通过引入门机制(输入门、遗忘门和输出门),LSTM能够更好地捕捉长距离依赖关系。
- GRU(门控循环单元):GRU是LSTM的简化版,通过减少门的数量,保留了LSTM的优势,同时提高了计算效率。
应用场景
- 自然语言处理(NLP):如机器翻译、文本生成、语音识别等。
- 时间序列预测:如股票价格预测、天气预报等。
- 语音和视频处理:如语音识别、视频分析等。
CNN(卷积神经网络)
原理
CNN是一类专门用于处理图像数据的神经网络,通过卷积操作提取图像的空间特征。CNN利用局部连接和共享权重的机制,能够有效地处理高维图像数据。
CNN的基本组成部分包括卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)。
卷积层
卷积层通过卷积核(也称为滤波器)在输入图像上进行滑动窗口操作,提取局部特征。每个卷积核可以检测不同的特征,如边缘、角点等。
卷积操作的公式如下:
[ (I * K)(i, j) = \sum_m \sum_n I(i+m, j+n) \cdot K(m, n) ]
其中:
- ( I ) 是输入图像
- ( K ) 是卷积核
- ( (i, j) ) 是卷积操作的位置
池化层
池化层通过对卷积层的输出进行下采样,减少数据量和计算量,同时保留重要的特征。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。
全连接层
全连接层将前面的特征图展平,并进行分类或回归任务。全连接层与传统的前馈神经网络类似,所有的输入节点与输出节点相连。
特点
- 局部连接:卷积操作只在局部区域内进行,有效减少了参数数量。
- 共享权重:同一卷积核在整个图像上共享参数,减少了过拟合的风险。
- 平移不变性:卷积操作能够有效识别图像中的特征位置,使模型对图像的平移具有鲁棒性。
应用场景
- 图像分类:如手写数字识别(MNIST)、物体识别(ImageNet)等。
- 目标检测:如人脸检测、车辆检测等。
- 图像分割:如语义分割、实例分割等。
- 医学影像分析:如病灶检测、图像重建等。
RNN与CNN的对比
| 特点 | RNN | CNN |
|---|---|---|
| 主要应用领域 | 序列数据处理,如NLP、时间序列预测 | 图像数据处理,如图像分类、目标检测 |
| 数据类型 | 时间序列、文本、语音等 | 图像、视频等 |
| 核心操作 | 循环连接 | 卷积操作 |
| 处理长序列的能力 | 可能遇到梯度消失或爆炸问题 | 不适用于处理长序列 |
| 参数量 | 参数量较多,尤其是长序列 | 通过局部连接和共享权重减少参数量 |
| 平移不变性 | 不具备平移不变性 | 具有平移不变性 |
| 记忆能力 | 能够记忆和处理序列中的上下文信息 | 主要用于捕捉图像中的局部特征 |
| 变种 | LSTM、GRU | 卷积神经网络变种,如ResNet、DenseNet |
总之,RNN和CNN是两种重要的神经网络架构,分别擅长处理不同类型的数据。RNN适用于处理序列数据,能够捕捉时间步之间的依赖关系,而CNN则适用于处理图像数据,能够有效提取图像的空间特征。在实际应用中,选择哪种网络架构取决于具体的任务和数据类型。
自注意力机制(Self-Attention)是Transformer模型的核心部分,它在自然语言处理(NLP)任务中取得了显著的成功。与传统的RNN和CNN不同,自注意力机制能够在序列的所有位置之间直接建立联系,使模型能够捕捉长距离的依赖关系。以下是对自注意力机制的详细介绍。
自注意力机制的基本原理
自注意力机制通过对输入序列中的每个元素计算其与其他元素的相关性(注意力分数),从而生成新的表示。这个过程可以分为以下几个步骤:
1. 计算查询(Query)、键(Key)和值(Value)
对于输入序列中的每个元素,我们首先计算三个向量:查询向量 (Q)、键向量 (K) 和值向量 (V)。这些向量通过与可训练的权重矩阵进行线性变换得到:
[ Q = XW_Q ]
[ K = XW_K ]
[ V = XW_V ]
其中,(X) 是输入序列,(W_Q)、(W_K) 和 (W_V) 是可训练的权重矩阵。
2. 计算注意力分数
接下来,我们计算查询向量 (Q) 与键向量 (K) 的点积,并进行缩放(除以 (\sqrt{d_k})),然后通过Softmax函数得到注意力分数:
[ \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V ]
其中,(\sqrt{d_k}) 是缩放因子, (d_k) 是键向量的维度。
3. 计算加权和
使用注意力分数对值向量 (V) 进行加权求和,得到最终的输出向量。
4. 多头注意力机制
为了使模型能够捕捉更多的特征,自注意力机制通常会使用多头注意力(Multi-Head Attention)。多头注意力机制将查询、键和值向量分为多个子空间,并在每个子空间上独立计算注意力,最后将这些结果拼接在一起:
[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_h)W_O ]
其中,每个头的计算方式为:
[ \text{head}i = \text{Attention}(QW{Q_i}, KW_{K_i}, VW_{V_i}) ]
自注意力机制的优势
- 并行化:与RNN不同,自注意力机制可以在计算时并行处理输入序列中的所有位置,提高了训练效率。
- 长距离依赖:自注意力机制能够直接在序列的所有位置之间建立联系,更好地捕捉长距离依赖关系。
- 灵活性:自注意力机制可以用于各种类型的输入数据,不仅限于时间序列。
Transformer模型
自注意力机制是Transformer模型的核心组件。Transformer模型由编码器和解码器组成,每个编码器和解码器包含多个堆叠的自注意力层和前馈神经网络(Feed-Forward Neural Network)层。
编码器(Encoder)
每个编码器层包含两个主要部分:
- 多头自注意力层(Multi-Head Self-Attention Layer):计算输入序列中每个元素之间的注意力分数。
- 前馈神经网络层(Feed-Forward Neural Network Layer):对自注意力层的输出进行进一步处理。通常包含两个全连接层和一个ReLU激活函数。
此外,每个层还有残差连接(Residual Connection)和层归一化(Layer Normalization),以提高训练稳定性和模型性能。
解码器(Decoder)
解码器的结构与编码器类似,但包含额外的注意力层,用于计算解码器输入与编码器输出之间的注意力分数。每个解码器层包含三个主要部分:
- 掩码多头自注意力层(Masked Multi-Head Self-Attention Layer):类似于编码器的自注意力层,但对未来的时间步进行掩码,以防止信息泄露。
- 多头注意力层(Multi-Head Attention Layer):计算解码器输入与编码器输出之间的注意力分数。
- 前馈神经网络层(Feed-Forward Neural Network Layer):与编码器中的前馈神经网络层类似。
Transformer模型的应用
Transformer模型在各种NLP任务中取得了显著的成功,包括:
- 机器翻译:如Google的翻译服务,使用Transformer模型实现高质量的翻译。
- 文本生成:如OpenAI的GPT系列模型,可以生成连贯且有意义的文本。
- 文本分类:如BERT模型,通过预训练和微调,实现了各种文本分类任务的高性能。
- 问答系统:如BERT和GPT,可以用于构建智能问答系统,回答用户的问题。
代码示例
以下是使用PyTorch实现自注意力机制的简化示例:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embedding size needs to be divisible by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split the embedding into self.heads different piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) / (self.embed_size ** (1 / 2))if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy, dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)out = self.fc_out(out)return out# 示例输入
embed_size = 256
heads = 8
seq_length = 10
batch_size = 32values = torch.randn(batch_size, seq_length, embed_size)
keys = torch.randn(batch_size, seq_length, embed_size)
query = torch.randn(batch_size, seq_length, embed_size)
mask = Noneattention = SelfAttention(embed_size, heads)
out = attention(values, keys, query, mask)
print(out.shape) # 输出的形状应该是 (batch_size, seq_length, embed_size)
总结
自注意力机制是现代自然语言处理模型(如Transformer)的核心,具有处理并行化、捕捉长距离依赖和灵活性强等优点。通过多头注意力机制,自注意力模型能够有效地捕捉序列中的多种特征,广泛应用于机器翻译、文本生成、文本分类和问答系统等任务。
相关文章:
Transformer自注意力机制(Self-Attention)模型
上一篇我们介绍了transform专题一:Seq2seq model,也知道了transfrom属于seq2seq模型,这一排篇咱们接着介绍另外几种seq2seq架构的模型。)RNN(循环神经网络)CNN(卷积神经网络)&…...
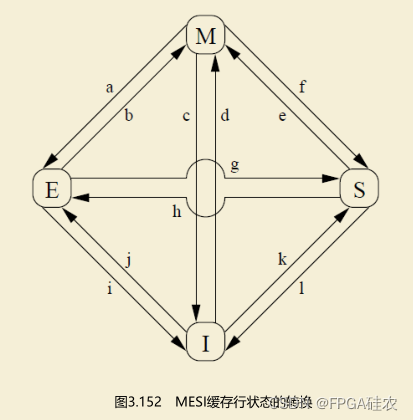
【计算机体系结构】缓存的false sharing
在介绍缓存的false sharing之前,本文先介绍一下多核系统中缓存一致性是如何维护的。 目前主流的多核系统中的缓存一致性协议是MESI协议及其衍生协议。 MESI协议 MESI协议的4种状态 MESI协议有4种状态。MESI是4种状态的首字母缩写,缓存行的4种状态分别…...
Ubuntu24.04 Isaacgym的安装
官方论坛 rl-接口 教程1 教程2 教程3 1.下载压缩包 link 2. 解压 tar -xvf IsaacGym_Preview_4_Package.tar.gz核心教程在 isaacgym/docs/install.html下 3. 从源码安装 Ubuntu24.04还需首先进入虚拟环境 python -m venv myenv # 创建虚拟环境,已有可跳过…...

docker 设置代理,通过代理服务器拉取镜像
docker 拉取目标镜像需要通过代理服务器进行时,可以通过为 docker 配置全局代理来实现。 注:Linux 上通过临时命令 export HTTP_PROXY 设置的代理,对 curl 这些有用,但是对 docker pull 不起作用。 示例 假设您的代理服务器地址是…...

OpenCV教程02:图像处理系统1.0(翻转+形态学+滤波+缩放+旋转)
-------------OpenCV教程集合------------- Python教程99:一起来初识OpenCV(一个跨平台的计算机视觉库) OpenCV教程01:图像的操作(读取显示保存属性获取和修改像素值) OpenCV教程02:图像处理…...

人工智能在招投标领域的运用---监控视频连续性检测
作者:舒城县公共交易中心 zhu_min726126.com 原创,转载请注明出处。 摘要 随着人工智能(AI)技术的飞速发展,其在各个领域的应用日益广泛。本文旨在探讨人工智能在招投标领域的运营,重点介绍AI对视频完整…...

加装德国进口高精度主轴 智能手机壳「高质量高效率」钻孔铣槽
在当前高度智能化的社会背景下,智能手机早已成为人们生活、工作的必备品,智能手机壳作市场需求量巨大。智能手机壳的加工过程涉及多个环节,包括钻孔和铣槽等。钻孔要求精度高、孔位准确,而铣槽则需要保证槽位规整、深度适宜。这些…...

Java Stream API 常用操作技巧
Java 8 引入的 Stream API 为集合操作提供了一种声明式编程模型,极大地简化了数据处理的复杂性。本文将介绍 Java Stream API 的几种常用操作方式,帮助开发者更高效地处理集合数据。 1. 过滤(Filtering) 过滤是选择集合中满足特…...

SwiftData 模型对象的多个实例在 SwiftUI 中不能及时同步的解决
概览 我们已经知道,用 CoreData 在背后默默支持的 SwiftUI 视图在使用 @FetchRequest 来查询托管对象集合时,若查询结果中的托管对象在别处被改变将不会在 FetchedResults 中得到及时的刷新。 那么这一“囧境”在 SwiftData 里是否也会“卷土重来”呢?空说无益,就让我们在…...

Android 系统网络、时间服务器配置修改
1.修改wifi 是否可用的检测地址: 由于编译的源码用的是谷歌的检测url,国内访问不了,系统会认为wifi网络受限,所以改成国内的地址 adb shell settings delete global captive_portal_https_urladb shell settings delete global captive_por…...

类和对象深入理解
目录 static成员概念静态成员变量面试题补充代码1代码2代码3如何访问private中的成员变量 静态成员函数静态成员函数没有this指针 特性 友元友元函数友元类 内部类特性1特性2 匿名对象拷贝对象时的一些编译器优化 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接…...

在postgres数据库中的几个简单用法
1、例如表中coord_str的字段数据是121.12334 31.3435这样的字符串,如何将对应的数据转换成geometry数据,实现如下 UPDATE coordinates SET geom ST_GeomFromText(POINT( || split_part(coord_str, , 1) || || split_part(coord_str, , 2) || ), 43…...

SQLServer Manager Studio扩展开发从入门到弃坑
Visualstudio的已经开发好了,可这个就是不行,直接运行点这些按钮加载失败,而我直接不调试模式,则直接什么都没有,调试 发现是根本没触发逻辑的。 文档资料太少, 我换了几个ssms.exe都不行,18-20…...

ComfyUI预处理器ControlNet简单介绍与使用(附件工作流)
简介 ControlNet 是一个很强的插件,提供了很多种图片的控制方式,有的可以控制画面的结构,有的可以控制人物的姿势,还有的可以控制图片的画风,这对于提高AI绘画的质量特别有用。接下来就演示几种热门常用的控制方式 1…...

【篇三】在vue3上实现阿里云oss文件直传
之前写了两篇关于文件上传的文章 【篇一】使用springbootvue实现阿里云oss上传 【篇二】使用springbootvue实现阿里云oss文件直传,解决大文件分片上传问题 今天介绍一下在vue3中实现阿里云oss文件直传,主要是基于篇二中的源码进行修改,看具体…...

OceanBase v4.2 特性解析:对Json与Xml的扩展支持
1. 背景 OceanBase的Oracle模式当前已实现对XMLType类型的支持,不仅包含了基本的构造、查询、更新以及格式转换功能,还支持使用Xpath查询从XML数据中提取特定值。在V 4.2.2 版本中,我们进一步扩展了Oracle模式下对XMLType的支持,…...

《框架封装 · 统一异常处理和返回值包装》
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗 🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数…...

深入WebKit:揭秘复杂文档的高效渲染之道
深入WebKit:揭秘复杂文档的高效渲染之道 在当今信息爆炸的时代,网页不再仅仅是简单的文本和图片的集合,而是充满了复杂布局和丰富媒体内容的交互式平台。WebKit 作为众多流行浏览器的心脏,其布局引擎承担着将 HTML、CSS 代码转换…...

进程的控制-孤儿进程和僵尸进程
孤儿进程 : 一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被 init 进程( 进程号为 1) 所收养,并由 init 进程对它们完成状态收集工作 为了释放子进程的占用的系统资源: …...

【Unity navigation面板】
【Unity navigation面板】 Unity的Navigation面板是一个集成在Unity编辑器中的界面,它允许开发者对导航网格(NavMesh)进行配置和管理。 Unity Navigation面板的一些关键特性和功能: 导航网格代理(NavMesh Agent&…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

【DeepSeek测试用例生成实战指南】:20年QA专家亲授5大高覆盖率生成模式与3个避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的核心价值与适用边界 DeepSeek系列大模型在代码理解与生成任务中展现出显著的上下文建模能力,其测试用例生成功能并非通用“黑盒测试器”,而是聚焦于**单元级、函…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...

揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式
更多请点击: https://intelliparadigm.com 第一章:揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式 Midjourney V6 在启用云雾(mist/fog/haze)类视觉效果时,…...

2026上海GEO生成式引擎优化服务商综合实力测评:谁在真正帮品牌进入AI答案
当企业在讨论“上海生成式引擎优化公司哪家好”时,这个问题本身就反映了市场一个关键的转折。两三年前,企业营销的主战场还是搜索引擎排名和官网访问量。现在,决策者开始频繁向DeepSeek、豆包、通义千问等AI工具提问,而这些生成式…...