从一次 SQL 查询的全过程了解 DolphinDB 线程模型
1. 前言
DolphinDB 的线程模型较为复杂,写入与查询分布式表都可能需要多个类型的线程。通过了解 SQL 查询的全过程,可以帮助我们了解 DolphinDB 的线程模型,掌握 DolpinDB 的配置,以及优化系统性能的方法。
本教程以一个分布式 SQL 查询为例,介绍 DolphinDB 分布式数据库查询过程的数据流,以及其经历的各类线程池。
2. DolphinDB 的主要节点类型
- agent(代理节点)
负责执行控制节点发出的启动和关闭数据节点或计算节点的命令。在一个集群中,每台物理服务器有且仅有一个代理节点。
- controller(控制节点)
负责收集代理节点、数据节点和计算节点的心跳,监控每个节点的工作状态,管理分布式文件系统的元数据和事务。
- data node(数据节点)
既可以存储数据,也可以用于数据的查询和计算。
- compute node(计算节点)
只用于数据的查询和计算。计算节点应用于计算密集型的操作,包括流计算、分布式关联和机器学习等场景。计算节点不存储数据,但可以通过 loadTable 加载数据进行计算。通过在集群中配置计算节点,可以将写入任务提交到数据节点、所有计算任务提交到计算节点,实现存储和计算的分离。
1.30.14/2.00.1 版本开始支持计算节点。
3. DolphinDB 线程类型
3.1 worker 线程
- 常规交互作业的工作线程。
- 每个节点都存在 worker 线程,可以分为以下几类:
- ZeroWorker
- FirstWorker
- SecondWorker
- ThirdWorker
- ForthWorker
- FifthWorker
- SixthWorker
- 客户端提交至节点的作业为 0 级,由 ZeroWorker 处理。
- 根据作业所涉及到的分区,ZeroWorker 将其分解为多个子任务。
- 其中本地节点上的子任务由 ZeroWorker 与 FirstWorker 并行执行。
- 需要由远程节点执行的子任务则降低为 1 级,并通过 remoteExecutor 发送到对应节点上的 FirstWorker 处理。
- 以此类推,若某个级别的子任务需要进一步拆解,则拆分出来的由远程节点执行的子任务降低一级,发送至远程节点上对应层级的 worker 处理。
- ZeroWorker, FirstWorker, SecondWorker 的线程数量由配置参数 workerNum 决定,分别为 workerNum, workerNum-1, workerNum*0.75。
- 其余层级的 work 线程数量为上级的 1/2 ,向上取整,最小个数为 1。
- 配置参数 workerNum 默认值为机器上的 CPU 核数,最大值不超过 license 中的最大核数。
3.2 remote executor 线程
- 将远程任务发送到远程节点的线程。
- 在非 single 模式的节点上可以通过配置参数 remoteExecutors 配置线程个数。
- 默认值为集群中节点个数和本地 worker 的较小值。
3.3 asynchronous remote executor 线程
- 接收对其他节点发起的远程调用(Remote Procedure Call, RPC)任务的线程。
- 将收到的远程调用任务放到 remote executor 的任务队列中。
- 每个非 single 模式的节点上有且仅有 1 个该线程。
3.4 remote task dispatcher 线程
- 在远程调用出错需要重试时,或者一个被关闭的连接上仍有未完成的任务时,这些任务会先放到一个队列里,由 remote task dispatcher 线程从这个队列取任务并重新交由 asynchronous remote executor 线程去发起远程调用。
3.5 batch job worker 线程
- 执行批处理作业任务的工作线程,批处理作业是指通过函数
submitJob、submitJobEx、submitJobEx2提交的作业。 - 其上限通过配置参数 maxBatchJobWorker 设置。
- 如果 maxBatchJobWorker 未设置,其默认值是配置参数 workerNum 的值。
- 该线程在任务执行完后若闲置 60 秒会被系统自动回收,不再占用系统资源。
3.6 web worker 线程
- 处理 HTTP 请求的工作线程。
- 由配置参数 webWorkerNum 配置,默认为 1,最大值为 CPU 内核数。
3.7 dynamic worker manager 线程和 dynamic worker 线程
- dynamic worker 是动态工作线程,是 worker 线程的补充。
- dynamic worker manager 是创建 dynamic worker 的线程,每个节点有且仅有 1 个该线程。
- 当所有的 worker 线程被占满时,再有新任务到来时,通过 dynamic worker manager 线程创建 dynamic worker 线程来执行新任务。
- 根据系统并发任务的繁忙程度,总共可以创建三组动态工作线程,每一个级别可以创建 maxDynamicWorker 个动态工作线程。
- maxDynamicWorker 的默认值为配置参数 workerNum 的值。
- 动态工作线程在任务执行完后若闲置 60 秒则会被系统自动回收,不再占用系统资源。
3.8 infra worker 线程
- 基础设施处理线程。
- 开启高可用后,用于接收 raft 心跳汇报的线程,防止集群负载大时,心跳信息无法及时汇报。
- 默认自动创建 2 个该线程,。
3.9 urgent worker 线程
- 处理紧急任务。
- 只接收一些特殊的系统级任务,譬如登录、取消作业等。
- 由配置参数 urgentWorkerNum 配置,默认值为 1,最大值为 CPU 内核数。
3.10 block IO worker 线程
- 执行对硬盘读写任务的线程。
- 由配置参数 diskIOConcurrencyLevel 配置,默认值为 1。
4. 一次 SQL 查询的线程经历
SQL 查询可提交到集群中任一计算节点或数据节点。获得请求的节点作为该查询的协调节点。
下面以 API 向协调节点发起一次 SQL 查询为例,讲述整个过程中所调度的所有线程。

step1:DolphinDB 客户端向协调节点(数据节点或计算节点)发起数据查询请求
以协调节点为数据节点为例,发起一次聚合查询,查询语句如下:
select avg(price)
from loadTable("dfs://database", "table")
where date between 2021.01.01 : 2021.12.31
group by date假设上述聚合查询语句总共涉及 300 个分区的数据,且正好平均分配在三个数据节点(即每个数据节点包含了 100 个查询的分区数据)。
DolphinDB 客户端将查询请求进行二进制序列化后通过 TCP 协议传输给 datanode1。
step2:datanode1 收到查询请求
datanode1 收到客户端的查询请求后,将分配 1 个 ZeroWorker 线程对内容进行反序列化和解析。当发现内容是 SQL 查询时,会向 controller 发起请求,获取跟这个查询相关的所有分区的信息。整个 SQL 查询执行完毕前,这个 ZeroWorker 线程会被一直占用。
step3:controller 收到 datanode1 的请求
controller 收到 datanode1 的请求后,将分配 1 个 FirstWorker 线程对内容进行反序列化和解析,准备好本次 SQL 查询涉及的数据分区信息后,由该 FirstWorker 线程序列化后通过 TCP 协议传输给 datanode1。controller 的该 FirstWorker 线程完成该工作后将从请求队列中获取下一个请求。
step4:datanode1 收到 controller 返回的信息
datanode1 的 ZeroWorker 收到 controller 返回的信息后,由本节点下的 1 个 FirstWorker 线程对内容进行反序列化和解析。
得知本次 SQL 查询涉及的数据分区信息后,将位于本节点的分区数据计算任务添加到本地任务队列,此时本地任务队列会产生 100 个子任务。
同时,把需要使用远程节点 datanode2 与 datanode3 的分区数据的计算任务,以任务包的方式发送到远程任务队列。远程任务队列会被添加 2 个远程任务,分别打上 datanode2 和 datanode3 的标志。
step5 (1):本地 worker 消费本地任务队列
此时,datanode1 中的 ZeroWorker 线程和 FirstWorker 线程会同时并行消费本地任务队列的子任务。
step5 (2)、(3):本地 remote executor 发送远程任务至远程节点
同时,remote executor 线程将远程任务队列的内容序列化后,通过 TCP 协议分别发送到 datanode2 和 datanode3。
step6 (1)、(2):远程节点收到远程任务
datanode2 和 datanode3 收到远程任务后,将分配 1 个 FirstWorker 线程对内容进行反序列化和解析,并将计算任务发送到本地任务队列,此时 datanode2 和 datanode3 的本地任务队列各会产生 100 个子任务。
step7 (1)、(2):远程节点 FirstWorker 消费本地任务队列
此时,datanode2 和 datanode3 上的 FirstWorker 线程会并行消费本地任务队列的子任务。
step8 (1)、(2):远程节点返回中间计算结果至 datanode1
当 datanode2 和 datanode3 涉及的计算任务完成后,分别得到了本次 SQL 查询的中间计算结果,由一直占用的 FirstWorker 线程对内容进行序列化后,通过 TCP 协议传输给 datanode1。
step9:datanode1 计算最终结果并返回给客户端
datanode1 接收到 datanode2 和 datanode3 返回的中间计算结果后,由一直占用的 ZeroWorker 线程对内容进行反序列化,然后在该线程上计算出最终结果,并在序列化后通过 TCP 协议传输给客户端。
DolphinDB 客户端接收到 datanode1 返回的信息后,经过反序列化显示本次 SQL 查询的结果。
协调节点为数据节点和计算节点的区别:
- 数据节点可以存储数据,计算节点不能存储数据。但计算节点解析客户端的 SQL 查询后,从 controller 拿到本次 SQL 查询涉及的数据分区信息,会将所有数据查询任务都分配到数据节点执行,得到每个数据节点返回的中间结果,最后调度计算节点的 ZeroWorker 线程计算最终结果并返回给客户端。
- 当实时写入的数据量非常大时,建议配置计算节点,将所有 SQL 查询都提交到计算节点,实现存储和计算的分离,减轻数据节点的计算工作负担。
5. 优化建议
通过分析上述的线程经历,可以发现,本次 SQL 查询一共发生了 8 次 TCP 传输,其中 2 次是 DolphinDB server 和 DolphinDB client 之间的传输。如果查询结果的数据量比较大,同时又对查询结果的延时性比较敏感,可以选择如下 6 个优化方向:
- 集群节点之间,以及节点和客户端之间的通信推荐使用万兆以太网。
- 优化线程配置参数。(详见本文后续章节)
- 增加每个节点的物理磁盘的数量。更多的磁盘可以更快速地并行读取多个分区的数据。
- SQL 语句优化:where 条件添加分区字段的信息过滤,起到分区剪枝的目的,避免全表扫描。
- 在查询数据量较大时,可对 API 查询结果进行数据压缩,提高传输效率。开启压缩后从 server 下载的数据即为压缩后的数据。Java 代码示例如下。
//API 建立 connection 的时候将第三个参数 compress 设置为 true 即可开启压缩
DBConnection connection = new DBConnection(false, false, true);
connection.connect(HOST, PORT, "admin", "123456");
BasicTable basicTable = (BasicTable) connection.run("select * from loadTable(\"dfs://database\", \"table\")");- 增加 license 限制的 CPU 核心数和内存大小,提升系统的并发处理能力。
6. 不同类型线程与配置参数的关系
| 线程类型 | 参数配置 | 默认配置 | 配置优化建议 |
|---|---|---|---|
| worker | workerNum | CPU的内核数 | license 限制的 CPU 核心数与物理机 CPU 核心数两者的最小值 |
| remote executor | remoteExecutors | 1 | 集群的节点数-1 |
| batch job worker | maxBatchJobWorker | workerNum | license 限制的 CPU 核心数与物理机 CPU 核心数两者的最小值 |
| web worker | webWorkerNum | 1 | 推荐 webWorkerNum 配置为 4大多情况下很少通过 web 与 DolphinDB 节点交互的方式提交查询任务 |
| dynamic worker | maxDynamicWorker | workerNum | 采用默认值 |
| infra worker | infraWorkerNum | 2 | 采用默认值 |
| urgent worker | urgentWorkerNum | 1 | 采用默认值 |
| block IO worker | diskIOConcurrencyLevel | 1 | 对于 hdd 磁盘,推荐 diskIOConcurrencyLevel 设为对应节点下通过 volumes 参数配置的磁盘个数对于 ssd 磁盘,推荐 diskIOConcurrencyLevel = 0 |
备注:
- 如果是单节点 single 模式或者是单数据节点集群,不需要配置 remoteExecutors 的值。
7. 总结
通过本文介绍,可以看出,DolphinDB的线程模型主要由 worker、remote executor、batch job worker、web worker、dynamic worker、infra worker、urgent worker、block IO worker 组成。在一次 SQL 查询会发生多次 TCP 传输,用户可以根据服务器的具体情况进行合理配置线程参数,从而降低查询延时。
相关文章:
从一次 SQL 查询的全过程了解 DolphinDB 线程模型
1. 前言 DolphinDB 的线程模型较为复杂,写入与查询分布式表都可能需要多个类型的线程。通过了解 SQL 查询的全过程,可以帮助我们了解 DolphinDB 的线程模型,掌握 DolpinDB 的配置,以及优化系统性能的方法。 本教程以一个分布式 …...

Vue3.js“非原始值”响应式实现基本原理笔记(二)
如果您觉得这篇文章有帮助的话!给个点赞和评论支持下吧,感谢~ 作者:前端小王hs 阿里云社区博客专家/清华大学出版社签约作者/csdn百万访问前端博主/B站千粉前端up主 此篇文章是博主于2022年学习《Vue.js设计与实现》时的笔记整理而来 书籍&a…...
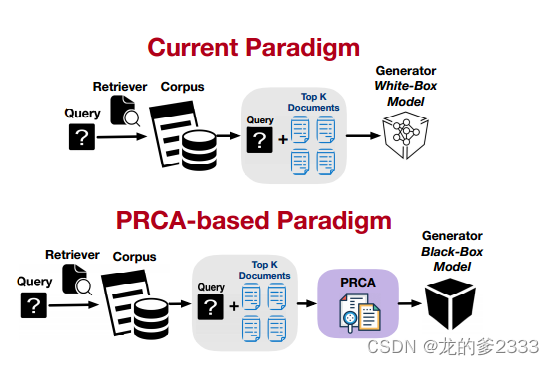
论文 | PRCA: 通过可插拔奖励驱动的上下文适配器拟合用于检索问答的黑盒大语言模型
论文全称:PRCA: Fitting Black-Box Large Language Models for Retrieval Question Answering via Pluggable Reward-Driven Contextual Adapter 核心问题:如何在检索增强式问答(ReQA)任务中,利用大型语言模型…...

网络状态的智能感知:WebKit 支持 Network Information API 深度解析
网络状态的智能感知:WebKit 支持 Network Information API 深度解析 在现代 Web 应用中,理解用户的网络连接状态对于提供适应性体验至关重要。Network Information API,一个新兴的 Web API,允许 Web 应用访问设备的网络信息&…...

Vue3基础知识:组合式API中的provide和inject,他们作用是什么?如何使用?以及案例演示
1.provide和inject相较于父子传递的不同在于provide,inject可以用于跨层级通信(通俗易懂的讲就是可以实现爷孙之间的直接信息传递)。 1.跨层级传递数据 1.在顶层组件通过provide函数提供数据 2.底层组件通过inject函数获取数据 演示一:跨…...
Transformer自注意力机制(Self-Attention)模型
上一篇我们介绍了transform专题一:Seq2seq model,也知道了transfrom属于seq2seq模型,这一排篇咱们接着介绍另外几种seq2seq架构的模型。)RNN(循环神经网络)CNN(卷积神经网络)&…...
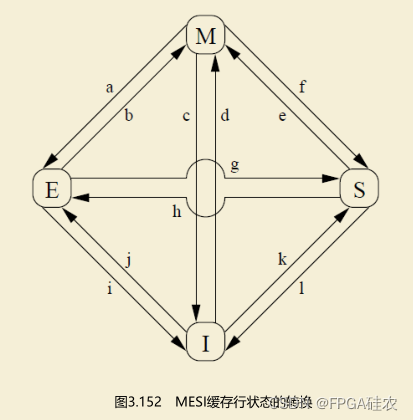
【计算机体系结构】缓存的false sharing
在介绍缓存的false sharing之前,本文先介绍一下多核系统中缓存一致性是如何维护的。 目前主流的多核系统中的缓存一致性协议是MESI协议及其衍生协议。 MESI协议 MESI协议的4种状态 MESI协议有4种状态。MESI是4种状态的首字母缩写,缓存行的4种状态分别…...
Ubuntu24.04 Isaacgym的安装
官方论坛 rl-接口 教程1 教程2 教程3 1.下载压缩包 link 2. 解压 tar -xvf IsaacGym_Preview_4_Package.tar.gz核心教程在 isaacgym/docs/install.html下 3. 从源码安装 Ubuntu24.04还需首先进入虚拟环境 python -m venv myenv # 创建虚拟环境,已有可跳过…...

docker 设置代理,通过代理服务器拉取镜像
docker 拉取目标镜像需要通过代理服务器进行时,可以通过为 docker 配置全局代理来实现。 注:Linux 上通过临时命令 export HTTP_PROXY 设置的代理,对 curl 这些有用,但是对 docker pull 不起作用。 示例 假设您的代理服务器地址是…...

OpenCV教程02:图像处理系统1.0(翻转+形态学+滤波+缩放+旋转)
-------------OpenCV教程集合------------- Python教程99:一起来初识OpenCV(一个跨平台的计算机视觉库) OpenCV教程01:图像的操作(读取显示保存属性获取和修改像素值) OpenCV教程02:图像处理…...

人工智能在招投标领域的运用---监控视频连续性检测
作者:舒城县公共交易中心 zhu_min726126.com 原创,转载请注明出处。 摘要 随着人工智能(AI)技术的飞速发展,其在各个领域的应用日益广泛。本文旨在探讨人工智能在招投标领域的运营,重点介绍AI对视频完整…...

加装德国进口高精度主轴 智能手机壳「高质量高效率」钻孔铣槽
在当前高度智能化的社会背景下,智能手机早已成为人们生活、工作的必备品,智能手机壳作市场需求量巨大。智能手机壳的加工过程涉及多个环节,包括钻孔和铣槽等。钻孔要求精度高、孔位准确,而铣槽则需要保证槽位规整、深度适宜。这些…...

Java Stream API 常用操作技巧
Java 8 引入的 Stream API 为集合操作提供了一种声明式编程模型,极大地简化了数据处理的复杂性。本文将介绍 Java Stream API 的几种常用操作方式,帮助开发者更高效地处理集合数据。 1. 过滤(Filtering) 过滤是选择集合中满足特…...

SwiftData 模型对象的多个实例在 SwiftUI 中不能及时同步的解决
概览 我们已经知道,用 CoreData 在背后默默支持的 SwiftUI 视图在使用 @FetchRequest 来查询托管对象集合时,若查询结果中的托管对象在别处被改变将不会在 FetchedResults 中得到及时的刷新。 那么这一“囧境”在 SwiftData 里是否也会“卷土重来”呢?空说无益,就让我们在…...

Android 系统网络、时间服务器配置修改
1.修改wifi 是否可用的检测地址: 由于编译的源码用的是谷歌的检测url,国内访问不了,系统会认为wifi网络受限,所以改成国内的地址 adb shell settings delete global captive_portal_https_urladb shell settings delete global captive_por…...

类和对象深入理解
目录 static成员概念静态成员变量面试题补充代码1代码2代码3如何访问private中的成员变量 静态成员函数静态成员函数没有this指针 特性 友元友元函数友元类 内部类特性1特性2 匿名对象拷贝对象时的一些编译器优化 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接…...

在postgres数据库中的几个简单用法
1、例如表中coord_str的字段数据是121.12334 31.3435这样的字符串,如何将对应的数据转换成geometry数据,实现如下 UPDATE coordinates SET geom ST_GeomFromText(POINT( || split_part(coord_str, , 1) || || split_part(coord_str, , 2) || ), 43…...

SQLServer Manager Studio扩展开发从入门到弃坑
Visualstudio的已经开发好了,可这个就是不行,直接运行点这些按钮加载失败,而我直接不调试模式,则直接什么都没有,调试 发现是根本没触发逻辑的。 文档资料太少, 我换了几个ssms.exe都不行,18-20…...

ComfyUI预处理器ControlNet简单介绍与使用(附件工作流)
简介 ControlNet 是一个很强的插件,提供了很多种图片的控制方式,有的可以控制画面的结构,有的可以控制人物的姿势,还有的可以控制图片的画风,这对于提高AI绘画的质量特别有用。接下来就演示几种热门常用的控制方式 1…...

【篇三】在vue3上实现阿里云oss文件直传
之前写了两篇关于文件上传的文章 【篇一】使用springbootvue实现阿里云oss上传 【篇二】使用springbootvue实现阿里云oss文件直传,解决大文件分片上传问题 今天介绍一下在vue3中实现阿里云oss文件直传,主要是基于篇二中的源码进行修改,看具体…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

实战解锁:在Blender中掌握专业级MMD动画制作全流程
实战解锁:在Blender中掌握专业级MMD动画制作全流程 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools MMD …...

利用 Taotoken 多模型能力为智能客服场景提供备份路由
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型能力为智能客服场景提供备份路由 智能客服系统是许多企业与用户交互的关键入口,其响应能力和服务…...

基于ISDN信令的来电语音播报系统:从原理到树莓派实现
1. 项目概述:一个基于ISDN的来电语音播报系统如果你家里或办公室里还有一台老式的ISDN路由器,别急着把它当电子垃圾处理掉。我最近就利用手头一台闲置的ISDN路由器,折腾出了一个挺有意思的小玩意儿:一个能自动识别来电号码&#x…...

地理空间机器学习库全解析:从TorchGeo到Raster Vision的实战指南
1. 项目概述:为什么我们需要专门的地理空间机器学习库?如果你尝试过用标准的PyTorch或TensorFlow去处理一张卫星影像,大概率会在第一步就卡住。不是模型写不出来,而是数据根本读不进去,或者读进去了却对不上位置。一张…...

三分钟快速上手:FanControl让你的电脑风扇从此安静又高效
三分钟快速上手:FanControl让你的电脑风扇从此安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...