Kafka第四篇——生产数据总体概括,源码解析分区策略,数据收集器,Sender发送线程,key值
目录
流程图以及总体概述
拦截器
分区器以及分区计算策略
为啥进行分区计算?
producer生产者怎么知道有哪些分区?
分区计算
如何自定义实现分区器?
想说的在图里啦!宝宝!💡 编辑
如果key值忘记传递了呢!?
数据校验
数据收集器
注意
Sender发送线程
流程图以及总体概述
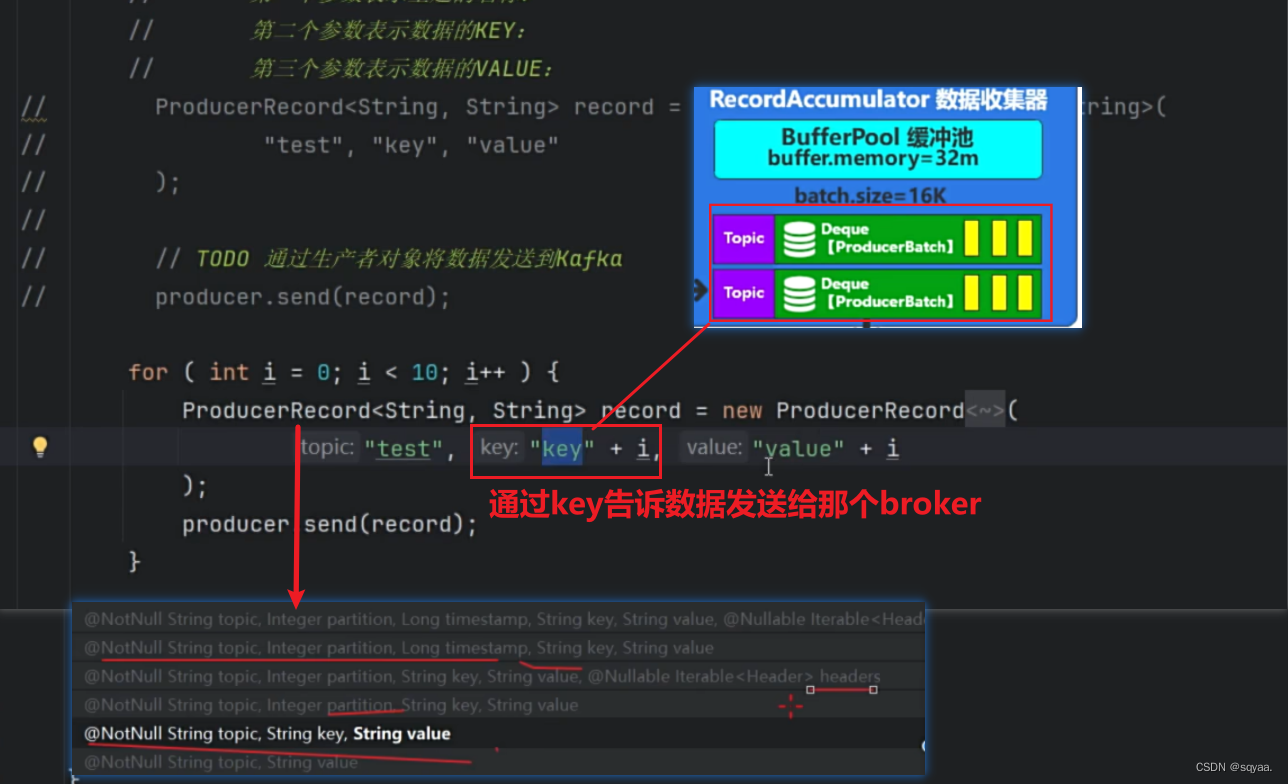
producer进行发送record,record对象包含topic,key,value,partition,时间戳,通过拦截器,将数据信息发送给broker,但是咱们也不知道把数据信息发送给哪个broker,而我们的Metadata就可以获取出来这个,如下面代码就是获取到9092.获取到缓存,放在底层。然后经过key对象的序列化,value对象的序列化,对应在代码中就是,configMap.put()那两行,并且这个是必须写的。然后经过分区器,partition,每个数据需要发送到broker中,每个消息发送到特定的主题,主题分为多个分区。kafka在发送数据时候,可以将数据发送到指定主题的指定分区,kafka会自动决定将消息发送到那个分区。分区器有那种判断发送给那个broker。然后进行数据校验。在数据收集器当中,相当于一个缓冲池,将同一个主题的数据可以存放在一个队列中,按“批”为单位进行发送,提高效率,并且指定了每批的大小是16K,
数据已经缓存到数据收集器后,就可以进行发送数据喽!此时就不会按topic为单位进行发送了,就可以重新整合,以节点为主!(why??因为不同的topic可以发送给同一个节点呀傻瓜!也就是说,在缓冲区以topic为单位,在发送线程中以节点为单位)封装请求,然后放在缓冲区中。再由网络通信从缓冲区中取出,发送给socket。在缓冲区,需要注意概念,在途请求缓冲区为5,表示同一个节点同一时间处理的请求数量。


拦截器
数据的规范化处理。可以有多个,可以按顺序执行数据的被拦截。和框架那块的一样。
onsend方法就是主要进行执行拦截规则的,for(ProducerInterceptor<K,V> interceptor:this.intercept)就可以循环执行多个拦截器,并且,看try,catch内容,无论当前拦截器发生什么异常,都不会影响到下一个拦截器的执行,更不会影响整个数据的发送。



自定义实现拦截器,帮助自己更好地了解拦截器。
java import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata;import java.util.Map;public class ValueInterceptorTest implements ProducerInterceptor<String, String> {/*** 实现拦截器规则**/@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {}/*** 当记录被Broker确认接收时调用** */@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {// 这个方法在记录被Broker确认接收时被调用// 根据确认情况实现自定义的处理逻辑}/*** 关闭拦截器时调用*/@Overridepublic void close() {}/*** 配置拦截器时调用**configs 配置信息*/@Overridepublic void configure(Map<String, ?> configs) {} }

分区器以及分区计算策略
为啥进行分区计算?
数据发送给某个主题,主题会有很多分区,会在不同的broker当中,所以要算分区编号,不然连数据要发送给主题哪个节点都不知道。但是分区标号也得有范围呀!
producer生产者怎么知道有哪些分区?

从元数据缓存中获取到producer需要的主题相关信息
意味着只要元数据信息缓存了,主题的相关信息我们就可以拿到。



分区器通过Matadata获取到分区,副本id,leadid之类的,
分区计算
 ¹²³⁴ 如果参数中指定了分区编号就直接返回
¹²³⁴ 如果参数中指定了分区编号就直接返回

如何自定义实现分区器?
1.实现partitioner接口, 重写相关方法。感觉主要就是实现partition方法。
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;import java.util.List;
import java.util.Map;public class CustomPartitioner implements Partitioner {/*** 配置分区器** @param configs 配置信息*/@Overridepublic void configure(Map<String, ?> configs) {}/*** 计算分区** @param topic 主题名称* @param key 消息键,可以为null* @param keyBytes 消息键的字节数组表示,可以为null* @param value 消息值* @param valueBytes 消息值的字节数组表示* @param cluster Kafka集群信息* @return 分配的分区ID*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes,Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();// 如果键为null,则使用轮询分区策略if (keyBytes == null) {return Utils.toPositive(Utils.murmur2(valueBytes)) % numPartitions;}// 使用键的hashCode来计算分区return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}/*** 关闭分区器*/@Overridepublic void close() {// 可以在这里进行资源的清理操作,通常分区器不需要进行额外的关闭操作}
}
想说的在图里啦!宝宝!💡
嘿嘿,这里解决了之前的问题,key并不像之前学到的hashmap中消费者用来消费的key,它的核心作用就是用来进行分区计算!
这个点就可以从:没有指定特定的分区标号,并且分区标号没有超过范围!序列化key以及分区器不忽略key的情况下看出来。partitionForKey()方法中就用不加密的hash算法并且对分区数量进行取余处理计算。
如果key值忘记传递了呢!?
return RecordMetadata.UNKNOWN_PARTITION;(这是一个表示未知分区的常量)。表明当前生产者无法确定消息发送到哪个分区,可能需要进一步处理或记录错误信息。那感觉也不太对啊,不知道把key发送到哪一个分区!
其实他是在数据收集器那一步追加了,看这个accumulator.append方法!
点进去哦!分区标号计算:粘性分区策略
如果没有进行传递key参数,也就是当前分区是未知分区,就会根据当前主题的分区负载情况来动态获取分区标号。这就是一种优化后的粘性分区策略!如图1.1

🤔图1.1 当前分区是未知分区,就会根据当前主题的分区负载因子来动态获取分区标号。 会根据当前分区负载情况判断去那个分区!如图1.2
✅当分区负载情况为空,就动态去随机选择分区,然后就尽可能的给这个分区追加数据(粘性分区策略),并且也不能超过数值batch.size=16K。如果超过这个阈值就会切换到下一个分区。并且更新分区负载情况。
✅当前主题分区负载情况不为空,那就不用随机生成了。会根据分区负载使用频率随机生成一个随机权重,然后利用二分查找算法找与权重相近的值,根据这个值获取到相应的分区,就可以得到我们的分区标号啦!

图1.2




数据校验
当数据校验成功,数据就到达了数据收集器当中。数据收集器,生产的数据作为一个临时的存储。

数据收集器
如果直接生产一条数据就通过网络通信来发送,这样做效率很低哦!像javaio流读取文件一样,读一个字节写一个字节,性能很低呀!
所以就有了ProducerBatch双端队列,从很减少频繁的网络交互,提高传输效率!
在神魔时候真正进行网络交互呢??
嘿嘿,看最大范围,batch.size=16K。在前面分区计算中,有一个粘性分区策略(一旦确定了一个分区,就尽可能往这个分区中追加数据,追加数据就是往producebatch中追加数据,当到达16K,就会被sender检测到),里面就有“没有传递key,如果没有分区负载情况,就会随机生成分区,不能超过最大

注意
🤔而且这里的16k意思是超过16k就不再接收数据了,不意味着数据不能超过16k!比如数据是20k,kafka要保证数据的完整性,发现这个数据值大于16k,就立马关闭,不再接收!
Sender发送线程
kafka底层就采用了很多生产者消费者模型,一个放一个取。数据收集器是按照主题分区来放数据,而Sender发送线程会按照broker重新整合。(主题的不同分区会放在不同的节点当中,所以有可能存在不同主题的分区在同一个节点当中)。
当整合好之后,就会封装成produceRequest,进而发送给网络客户端。
默认发送时间0,也就是消息取过来就可以直接发送了!
注意这个在途请求缓冲区数量:5


- Broker 和 Topic:每个 broker 可以存储一个或多个 topic 的数据分片,Kafka 集群的每个 broker 都可以服务于多个 topic。
- Topic 和 分区:每个 topic 可以被分为多个分区,分区内的消息顺序是有序的,而不同分区之间的消息顺序则不保证,分区允许 Kafka 横向扩展和提高并行处理能力。
- Broker 和 分区:每个 broker 可能会存储多个 topic 的多个分区数据,这样在整个 Kafka 集群中就形成了数据的分布式存储和处理能力。
相关文章:

Kafka第四篇——生产数据总体概括,源码解析分区策略,数据收集器,Sender发送线程,key值
目录 流程图以及总体概述 拦截器 分区器以及分区计算策略 为啥进行分区计算? producer生产者怎么知道有哪些分区? 分区计算 如何自定义实现分区器? 想说的在图里啦!宝宝!💡 编辑 如果key值忘记传递了呢&a…...

二叉树的链式结构
前言 Hello,友友们,小编将继续重新开始数据结构的学习,前面讲解了堆的部分知识,今天将讲解二叉树的链式结构的部分内容。 1.概念回顾与新增 二叉树是一种数据结构,其中每个节点最多有两个子节点,分别是左子节点和右子…...

【STM32】在标准库中使用DMA
1.MDA简介 DMA全称Direct Memory Access,直接存储区访问。 DMA传输将数据从一个地址空间复制到另一个地址空间。当CPU初始化这个传输动作,传输动作本身是由DMA控制器来实现和完成的。DMA传输方式无需CPU直接控制传输,也没有中断处理方式那样保留现场和…...
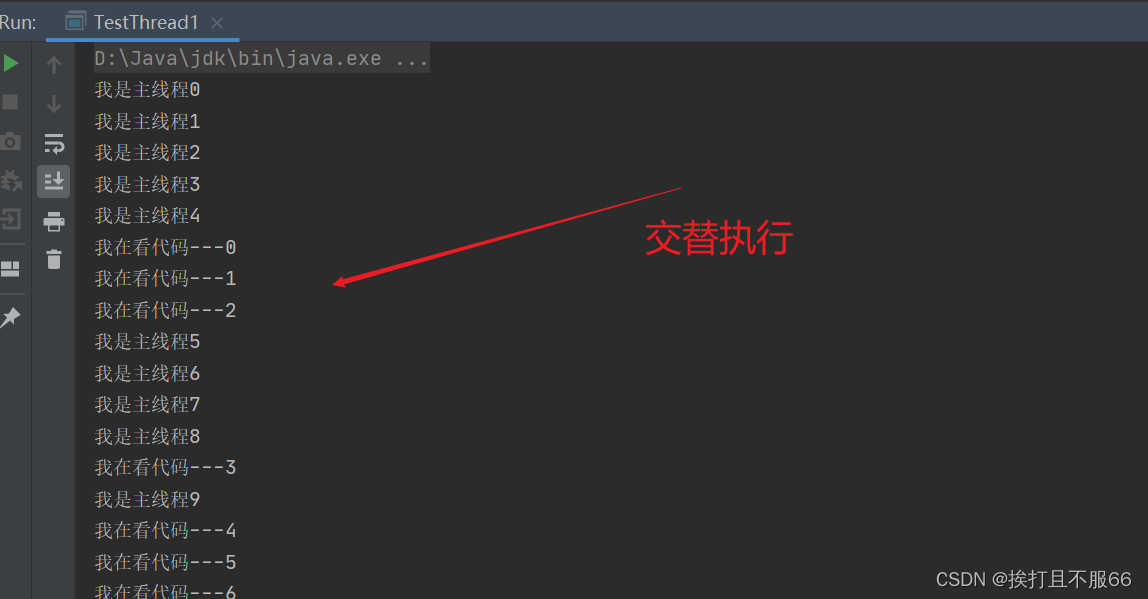
多线程详解
文章目录 多线程创建方式p3一些教程 狂神说 多线程创建方式p3 代码: package com.demo1;//创建线程方式一:继承Thread类,重写run()方法,调用start开启线程/*** 总结:注意,线程开启不一定立即执行,dCPU调度执行*/public class TestThread1 extends Thre…...

软件工程需求之:业务需求与用户需求
在软件开发项目中,"业务需求"和"用户需求"是两个核心概念,它们分别从不同的角度描述了软件应该具备的功能和特性。理解这两个概念的区别对于成功地规划和开发软件至关重要。 业务需求 业务需求主要关注于软件项目如何帮助实现企业…...

Nettyの源码分析
本篇为Netty系列的最后一篇,按照惯例会简单介绍一些Netty相关核心源码。 1、Netty启动源码分析 代码就使用最初的Netty服务器案例,在bind这一行打上断点,观察启动的全过程: 由于某些方法的调用链过深,节约篇幅…...

MySQL远程登录
root是超级管理员,默认情况下,root不能作为远程登录的用户名,远程登录前,需要将登录的数据库在本地登录,修改权限,输入: update user set host % where user root ; 回车键,再输…...

html的作业
目录 作业题目 1.用户注册 A图 B代码 2.工商银行电子汇款单 A图 B代码 3.李白诗词 A图 B代码 4.豆瓣电影 A图 B代码 学习产出: 作业题目 1.用户注册 A图 B代码 <!DOCTYPE html> <html lang"zh"> <head><meta charset&qu…...

【TORCH】查看dataloader里的数据,通过dataloader.dataset或enumerate
文章目录 dataloader.dataset示例代码使用自定义数据集使用 MNIST 数据集 说明 enumerate示例代码说明使用 MNIST 数据集的例子 dataloader.dataset 是的,您可以直接访问 train_loader 的数据集来查看数据,而不必通过 enumerate 遍历数据加载器。可以通…...

KDTree 简单原理与实现
介绍 K-D树是一种二叉树的数据结构,其中每个节点代表一个k维点,可用于组织K维空间中的点,其中K通常是一个非常大的数字。二叉树结构允许对多维空间中的点进行非常有效的搜索,包括最近邻搜索和范围搜索,树中的每个非叶…...

[c++] 可变参数模版
前言 可变参数模板是C11及之后才开始使用,学校的老古董编译器不一定能用 相信大家在刚入门c/c时都接触过printf函数 int printf ( const char * format, ... ); printf用于将数据格式化输出到屏幕上,它的参数非常有意思,可以支持任意数量,任意类型的多参数.而如果我们想实现类…...

QWidget窗口抗锯齿圆角的一个实现方案(支持子控件)2
QWidget窗口抗锯齿圆角的一个实现方案(支持子控件)2 本方案使用了QGraphicsEffect,由于QGraphicsEffect对一些控件会有渲染问题,比如列表、表格等,所以暂时仅作为研究,优先其他方案 在之前的文章中&#…...

数据结构之“队列”(全方位认识)
🌹个人主页🌹:喜欢草莓熊的bear 🌹专栏🌹:数据结构 前言 上期博客介绍了” 栈 “这个数据结构,他具有先进后出的特点。本期介绍“ 队列 ”这个数据结构,他具有先进先出的特点。 目录…...
密码学复习
目录 基础 欧拉函数 欧拉函数φ(n)定义 计算方法的技巧 当a=a_1*a_2*……*a_n时 欧拉定理 剩余系 一些超简单密码 维吉尼亚 密钥fox 凯撒(直接偏移) 凯特巴氏(颠倒字母表) 摩斯密码(字母对应电荷线) 希尔(hill)密码 一些攻击 RSA 求uf+vg=1 快速幂模m^…...
【文献解析】一种像素级的激光雷达相机配准方法
大家好呀,我是一个SLAM方向的在读博士,深知SLAM学习过程一路走来的坎坷,也十分感谢各位大佬的优质文章和源码。随着知识的越来越多,越来越细,我准备整理一个自己的激光SLAM学习笔记专栏,从0带大家快速上手激…...

Http 实现请求body体和响应body体的双向压缩方案
目录 一、前言 二、方案一(和http header不进行关联) 二、方案二(和http header进行关联) 三、 客户端支持Accept-Encoding压缩方式,服务器就一定会进行压缩吗? 四、参考 一、前言 有时请求和响应的body体比较大,需要进行压缩,以减少传输的带宽。 二、方案一(和…...

C++(Qt)-GIS开发-简易瓦片地图下载器
Qt-GIS开发-简易瓦片地图下载器 文章目录 Qt-GIS开发-简易瓦片地图下载器1、概述2、安装openssl3、实现效果4、主要代码4.1 算法函数4.2 瓦片地图下载url拼接4.3 多线程下载 5、源码地址6、参考 更多精彩内容👉个人内容分类汇总 👈👉GIS开发 …...

誉天教育7月开班计划:为梦想插上腾飞的翅膀!
随着夏日的脚步渐近,誉天教育也迎来了新一轮的学习热潮。在这个充满活力和希望的季节里,我们精心策划了7月的开班计划,旨在为广大学子提供一个优质、高效的学习平台,助力他们追逐梦想,实现自我价值。 本月 Linux云计算…...

STM32基础篇:GPIO
GPIO简介 GPIO:即General Purpose Input/Output,通用目的输入/输出。就是一种片上外设(内部模块)。 对于STM32的芯片来说,周围有一圈引脚,有时需要对引脚进行读写(读:从外部输入一…...

HTTPS 发送请求出现TLS握手失败
最近在工作中,调外部接口,发现在clientHello步骤报错,服务端没有返回serverHello。 从网上找了写方法,都没有解决; 在idea的vm options加上参数: -Djavax.net.debugSSL,handshake 把SSL和handshake的日…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

服务器日志分析实战:用Python追踪HTTP 404错误并可视化异常频率
作为一名爬虫开发者或网站运维人员,服务器日志就像飞机的“黑匣子”——它记录了每个请求的来龙去脉。而404错误(页面未找到)尤其值得关注:它可能是用户输错了网址,可能是你爬虫的URL构造逻辑有漏洞,也可能是网站改版后旧的链接失效了。更严重的是,大量突然涌出的404请求…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...

Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量 Hermes Agent 是一个流行的 AI 代理开发框架࿰…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...