[机器学习]-4 Transformer介绍和ChatGPT本质
Transformer
Transformer是由Vaswani等人在2017年提出的一种深度学习模型架构,最初用于自然语言处理(NLP)任务,特别是机器翻译。Transformer通过自注意机制和完全基于注意力的架构,核心思想是通过注意力来捕捉输入序列中元素之间的关系,从而在并行计算的情况下更有效地处理长序列数据,克服了传统RNN和CNN的一些局限性,在许多任务上实现了显著的性能提升。
1 自注意机制
自注意机制通过三个矩阵(Query, Key, Value)计算输入序列中每个元素与其他元素的相关性,从而生成新的表示,这三个矩阵是通过输入序列的线性变换得到的。
给定输入序列 X ,自注意机制计算如下:
Q = XW_Q,K = XW_K,V = XW_V,其中, W_Q, W_K, W_V是可学习的权重矩阵。
注意力分数通过点积计算并归一化:
Attention(Q, K, V) = softmax({QK^T}/{})V,这里dk是K的维度,用于缩放点积的结果。
2 多头注意力机制
多头注意力机制通过并行计算多个自注意机制来捕捉不同的子空间信息,然后将这些子空间的信息进行拼接和线性变换。
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W_O,其中每个头head_i =Attention(QW_Qi, KW_Ki, VW_Vi),W_Qi, W_Ki, W_Vi, W_O是可学习的权重矩阵。
3 组成结构
Transformer由编码器和解码器两个部分组成,每个部分都是由多个堆叠的层组成的。
1)编码器
编码器由多个相同的层堆叠而成,每层包含以下两个子层:多头自注意子层、前馈神经网络子层,每个子层后都有一个残差连接和层归一化。
编码器的输入是一个序列X,通过嵌入层和位置编码(Positional Encoding)进行处理,然后输入到编码器的每一层。
EncoderLayer(X) = LayerNorm(X +MultiHead(X, X, X))
EncoderLayer(X) = LayerNorm(X + FFN(X))
2)解码器
解码器与编码器结构类似,但每层包含以下三个子层:多头自注意子层、多头注意力子层(接收编码器的输出)、前馈神经网络子层。
解码器的输入是目标序列的前一部分,通过嵌入层和位置编码进行处理,然后输入到解码器的每一层。
DecoderLayer(Y) =LayerNorm(Y +MultiHead(Y, Y, Y))
DecoderLayer(Y) =LayerNorm(Y + MultiHead(Y, EncoderOutput, EncoderOutput))
DecoderLayer(Y) = LayerNorm(Y +FFN(Y))
4 训练过程
Transformer的训练过程类似于其他深度学习模型,通过最小化损失函数来优化模型参数,常用的损失函数是交叉熵损失。
具体步骤如下:
1)数据预处理:将输入序列和目标序列进行标记化、嵌入和位置编码。
2)前向传播:将输入序列通过编码器生成编码器输出,将目标序列通过解码器生成预测输出。
3)计算损失:使用预测输出和实际目标序列计算交叉熵损失。
4)反向传播:计算损失相对于模型参数的梯度。
5)参数更新:使用优化算法(如Adam)更新模型参数。
6)重复步骤2-5,直到模型收敛。
5 典型应用
Transformer在多个领域都有广泛的应用,尤其在自然语言处理和计算机视觉领域。
自然语言处理(NLP)
1)机器翻译:Transformer最初用于机器翻译任务,如Google的翻译系统。
2)文本生成:GPT(Generative Pre-trained Transformer)系列模型在文本生成任务中表现优异。
3)文本分类:BERT(Bidirectional Encoder Representations from Transformer)模型用于各种NLP任务,如情感分析、问答系统等。
计算机视觉
1)图像分类:Vision Transformer(ViT)模型用于图像分类任务,取得了与卷积神经网络相媲美的性能。
2)目标检测:DETR(Detection Transformer)模型用于目标检测任务,通过自注意机制实现了端到端的目标检测。
6 实现示例
以下是一个使用Python和TensorFlow实现的简单Transformer模型,用于序列到序列任务(如机器翻译):
import tensorflow as tf
from tensorflow.keras.layers import Dense, Embedding, LayerNormalization, Dropout
from tensorflow.keras.models import Model
# 定义多头自注意力机制
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = Dense(d_model)
self.wk = Dense(d_model)
self.wv = Dense(d_model)
self.dense = Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q)
k = self.wk(k)
v = self.wv(v)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
scaled_attention, attention_weights = self.scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
output = self.dense(concat_attention)
return output, attention_weights
def scaled_dot_product_attention(self, q, k, v, mask):
matmul_qk = tf.matmul(q, k, transpose_b=True)
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, v)
return output, attention_weights
# 定义前馈神经网络
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
Dense(dff, activation='relu'),
Dense(d_model)
])
# 定义编码器层
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(rate)
self.dropout2 = Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output)
return out2
# 定义编码器
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = Embedding(input_vocab_size, d_model)
self.pos_encoding = self.positional_encoding(input_vocab_size, d_model)
self.enc_layers = [EncoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]
self.dropout = Dropout(rate)
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(np.arange(position)[:, np.newaxis], np.arange(d_model)[np.newaxis, :], d_model)
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
def get_angles(self, pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
return pos * angle_rates
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x
# 定义解码器层
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.layernorm3 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(rate)
self.dropout2 = Dropout(rate)
self.dropout3 = Dropout(rate)
def call(self, x, enc_output, training, look_ahead_mask, padding_mask):
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(x + attn1)
attn2, attn_weights_block2 = self.mha2(enc_output, enc_output, out1, padding_mask)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(out1 + attn2)
ffn_output = self.ffn(out2)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(out2 + ffn_output)
return out3, attn_weights_block1, attn_weights_block2
# 定义解码器
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = Embedding(target_vocab_size, d_model)
self.pos_encoding = self.positional_encoding(target_vocab_size, d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]
self.dropout = Dropout(rate)
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(np.arange(position)[:, np.newaxis], np.arange(d_model)[np.newaxis, :], d_model)
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
def get_angles(self, pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
return pos * angle_rates
def call(self, x, enc_output, training, look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, training, look_ahead_mask, padding_mask)
attention_weights['decoder_layer{}_block1'.format(i+1)] = block1
attention_weights['decoder_layer{}_block2'.format(i+1)] = block2
return x, attention_weights
# 定义Transformer模型
class Transformer(Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff, input_vocab_size, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff, target_vocab_size, rate)
self.final_layer = Dense(target_vocab_size)
def call(self, inp, tar, training, enc_padding_mask, look_ahead_mask, dec_padding_mask):
enc_output = self.encoder(inp, training, enc_padding_mask)
dec_output, attention_weights = self.decoder(tar, enc_output, training, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output)
return final_output, attention_weights
ChatGpt
ChatGPT是一种基于Transformer架构的生成式预训练语言模型,它是由OpenAI开发的,旨在通过自然语言处理(NLP)技术进行人机对话。ChatGPT的核心技术基于GPT系列模型,特别是GPT-3和后续版本,这些模型通过大量的互联网文本进行预训练,然后通过特定任务进行微调,从而在生成和理解自然语言方面表现出色。GPT模型的初始版本是GPT-1,随后是GPT-2和GPT-3,GPT-3是一个具有1750亿参数的模型,代表了当时最先进的语言模型之一。
1 GPT模型架构
GPT模型是一种自回归语言模型,使用Transformer的解码器部分,通过预测下一个词来生成文本,依赖于上下文信息。
1)预训练阶段: ChatGPT首先通过大量的互联网文本进行预训练,学习词汇、语法、知识和常识。这一阶段主要关注语言建模任务,即给定前文条件下预测下一个词的概率。
2)微调阶段: 在预训练的基础上,ChatGPT通过特定任务或数据集进行微调,以提高在特定任务上的表现。比如为了提高对话系统的性能,模型可以通过大量对话数据进行微调。
3)生成响应: 用户输入文本后,ChatGPT通过前向传播计算每个可能的下一个词的概率分布,模型根据这些概率进行采样,逐步生成响应。具体步骤如下:
- 输入处理: 用户输入的文本被分词、编码成词嵌入。
- 上下文建模: 通过多层Transformer对输入进行处理,捕捉上下文信息和语义关系。
- 词预测与采样: 在每一步预测下一个词的概率分布,根据这些概率进行采样生成词语,直到生成完整的响应。
2 嵌入原理
嵌入是一种将是将符号数据(如单词、句子或文档)转换为实数向量的技术,这些实数向量称为嵌入向量,即将高维数据转换为低维向量空间的方法,使得数据在该向量空间中具有某种结构或几何意义。嵌入在自然语言处理领域尤为重要,因为它们能将文本数据转换为机器学习模型能够处理的数值形式。
- 相似性表示:在嵌入空间中,相似的词或句子会被映射到彼此相近的位置。
- 维度缩减:嵌入将高维的稀疏表示(如独热编码)转化为低维的稠密表示,从而减少计算复杂度。
- 捕捉语义:嵌入能够捕捉词语或句子之间的语义关系。例如“国王”(king)和“王后”(queen)之间的关系在嵌入空间中也会有所体现。
1)ChatGPT中的嵌入
在ChatGPT中,嵌入用于多个层面,包括单词、短语和句子层面,模型通过嵌入来理解和生成自然语言。
- 词嵌入:最基本的嵌入是词嵌入,将每个词转换为固定长度的向量。常见的词嵌入技术有Word2Vec、GloVe等。在Transformer架构中,初始的词嵌入是通过查找嵌入矩阵实现的。
- 位置嵌入:Transformer模型没有内置的序列信息,因此需要添加位置嵌入来捕捉词语在句子中的位置。
- 上下文嵌入:与静态词嵌入不同,ChatGPT使用Transformer架构生成上下文相关的嵌入,这意味着同一个词在不同上下文中会有不同的向量表示。
2)嵌入的生成和使用
在训练和推理过程中,嵌入起到了至关重要的作用。
训练阶段:
- 模型首先将输入文本转化为词嵌入向量。
- 位置嵌入向量与词嵌入向量相加,形成包含位置信息的输入嵌入。
- 这些嵌入作为输入传递给Transformer的多层自注意力机制,生成更高层次的上下文嵌入。
推理阶段:
- 在生成回复时,模型根据输入的上下文嵌入,预测下一个词的概率分布。
- 基于概率分布,选取最可能的词作为输出,然后更新嵌入,继续生成下一个词,直到生成完整的回复。
3)嵌入的优势
嵌入在ChatGPT中的应用带来了很多好处:
- 提高理解能力:通过嵌入,模型能够捕捉词与词之间的复杂语义关系,从而更好地理解输入文本。
- 增强生成能力:上下文嵌入帮助模型生成连贯且符合语义的回复。
- 减少计算复杂度:稠密的向量表示减少了计算所需的资源,提高了模型的效率。
4)典型示例
假设我们有一句话“ChatGPT is a powerful language model”。在这句话中:
- 每个词(如“ChatGPT”、“is”等)会被映射到一个固定维度的嵌入向量。
- 这些词嵌入向量将与位置嵌入向量相加,形成输入嵌入。
- 输入嵌入被传递到Transformer的自注意力机制,生成包含上下文信息的嵌入。
- 最终模型利用这些上下文嵌入,生成针对用户输入的自然语言回复。
3 工作原理
总体目标:根据所接受的训练(来自互联网数十亿文本),以合理的方式续写文本,对于任意给定的上下文,它会预测并生成下一个适当的标记(即单词或符号)。
1)阶段一获取输入嵌入
1.1)获取标记序列:
输入文本被分解成一系列标记(tokens),标记可以是单词、子词或字符,取决于具体的分词方法。例如输入句子“ChatGPT is amazing”可能会被分成如下标记序列:["ChatGPT", "is", "amazing"]。
1.2)嵌入表示:
- 每个标记被映射到一个高维向量(嵌入向量),这一步通常使用预训练的嵌入矩阵,该矩阵将每个标记转换为固定长度的向量。
- 嵌入向量是一个数组,表示标记的特征,这些嵌入向量捕捉了词汇之间的语义关系。例如标记“ChatGPT”可能对应一个300维的向量:[0.12, 0.34, ..., 0.56]。
1.3)位置嵌入:
为了捕捉序列中的位置信息,位置嵌入被添加到标记嵌入上,这样模型能够理解标记在序列中的相对位置。
2)阶段二神经网络处理
2.1)输入嵌入传递到Transformer模型:
- 嵌入向量被传递到Transformer模型中。(Transformer由多层堆叠的自注意力机制和前馈神经网络组成)
- 自注意力机制允许模型在处理每个标记时关注输入序列中的所有其他标记,从而捕捉上下文信息。(备注:GPT-2共有12个注意力块,GPT-3种共有96个,每个注意力块都有自己特定的注意力模式和全链接权重)
2.2)层层传递和变换:
输入嵌入依次通过Transformer的各层。在每一层,自注意力和前馈网络都会对输入进行变换,生成新的嵌入向量。这些变换捕捉了输入序列中的复杂模式和关系。
2.3)生成新的嵌入:
通过多层的传递和变换,生成一个新的嵌入向量,这个向量包含了输入序列的上下文信息。
3)阶段三生成输出标记
3.1)输出层生成概率分布:
经过Transformer处理后的最终嵌入向量被传递到输出层,输出层通常是一个全连接层,它将嵌入向量映射到一个包含所有可能标记的向量(词汇表大小)。例如词汇表大小为50000,那么输出将是一个50000维的向量。
3.2)计算每个标记的概率:
- 输出向量中的每个值表示生成相应标记的未归一化得分(logits)。
- 使用softmax函数将这些得分转换为概率分布。softmax函数会对所有值进行指数运算,并归一化使得这些值之和为1。
3.3)选择下一个标记:
基于生成的概率分布,选择下一个标记,选择方法可以是直接选择概率最高的标记(贪心搜索),也可以是按概率进行随机选择(采样)。
(备注:Transformer本质上将标记序列的原始嵌入集合转换到最终集合,chatgpt选择其中最后一个嵌入并解码得到下一个标记的概率列表。chatgpt最长的路径,大约400个核心层,数百万神经元,总共1750亿个连接,所以有1750亿个权重;它每生成一个新的标记,都必须进行一次包括所有权重在内的计算。在实现上,这些计算可按层进行高度并行计算,但对于每个标记生成,仍需1750亿次计算。)
相关文章:
[机器学习]-4 Transformer介绍和ChatGPT本质
Transformer Transformer是由Vaswani等人在2017年提出的一种深度学习模型架构,最初用于自然语言处理(NLP)任务,特别是机器翻译。Transformer通过自注意机制和完全基于注意力的架构,核心思想是通过注意力来捕捉输入序列…...

基于深度学习的电力分配
基于深度学习的电力分配是一项利用深度学习算法优化电力系统中的电力资源分配、负荷预测、故障检测和系统管理的技术。该技术旨在提高电力系统的运行效率、稳定性和可靠性。以下是关于这一领域的系统介绍: 1. 任务和目标 电力分配的主要任务是优化电力系统中的电力…...
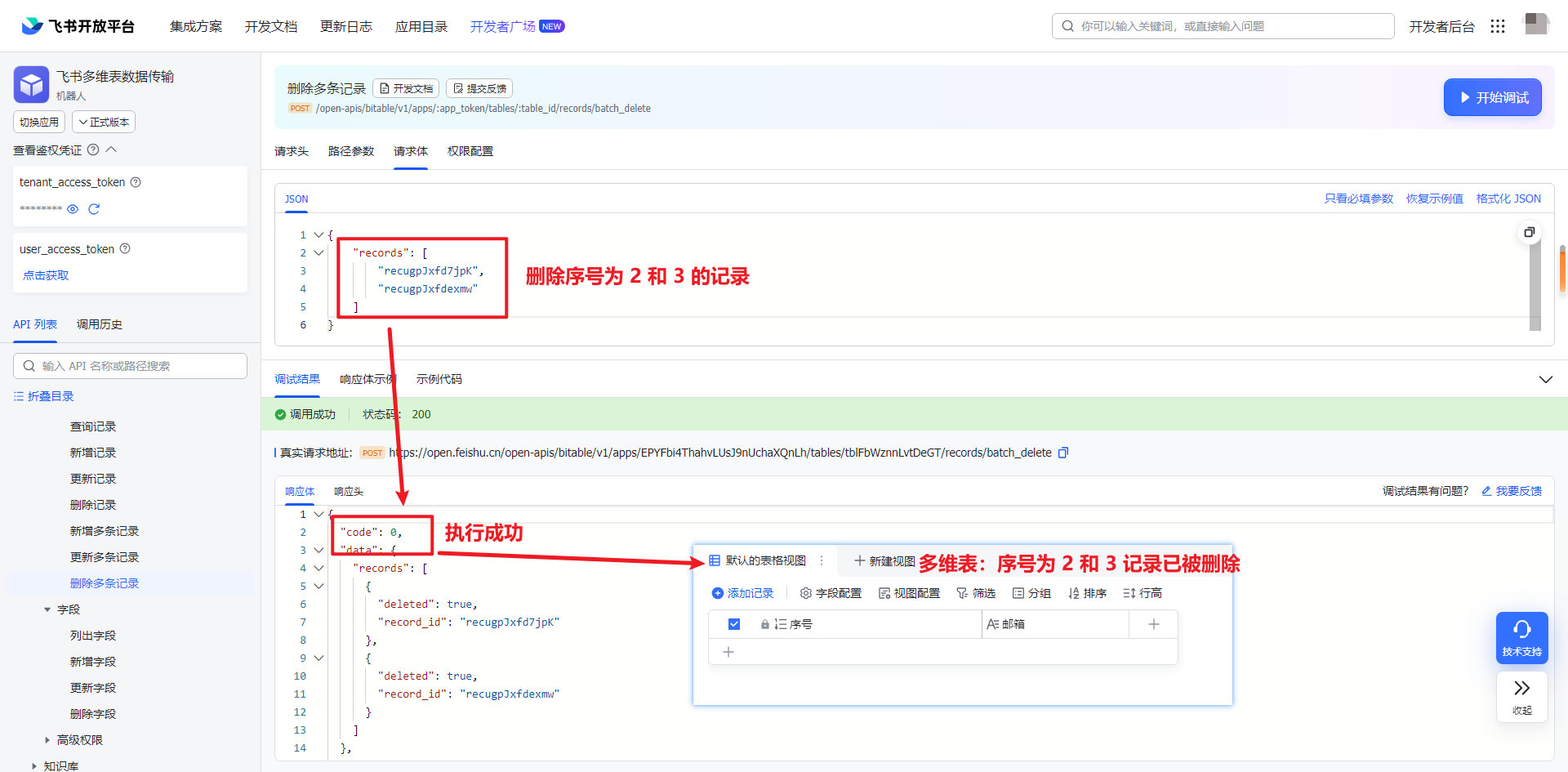
飞书 API 2-4:如何使用 API 将数据写入数据表
一、引入 上一篇创建好数据表之后,接下来就是写入数据和对数据的处理。 本文主要探讨数据的插入、更新和删除操作。所有的操作都是基于上一篇(飞书 API 2-4)创建的数据表进行操作。上面最终的数据表只有 2 个字段:序号和邮箱。序…...

系统设计题-日活月活统计
一、题目描述 根据访问日志统计接口的日活和月活。日志格式为 yyyy-mm-dd|clientIP|url|result 其中yyyy-mm-dd代表年月日,一个日志文件中时间跨度保证都在同一个月内,但不保证每行是按照日期顺序。 clientIP为合法的点分十进制ipv4地址(1.1.1.1和1.01.…...

在CentOS7云服务器下搭建MySQL网络服务详细教程
目录 0.说明 1.卸载不要的环境 1.1查看当前环境存在的服务mysql或者mariadb 1.2卸载不要的环境 1.2.1先关闭相关的服务 1.2.2查询曾经下载的安装包 1.2.3卸载安装包 1.2.4检查是否卸载干净 2.配置MySQLyum源 2.1获取mysql关外yum源 2.2 查看当前系统结合系统配置yum…...

【数据结构与算法】快速排序霍尔版
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法》 期待您的关注 ...

无人机5公里WiFi低延迟图传模组,抗干扰、长距离、低延迟,飞睿智能无线通信新标杆
在科技日新月异的今天,我们见证了无数通信技术的飞跃。从开始的电报、电话,到如今的4G、5G网络,再到WiFi的广泛应用,每一次技术的革新都极大地改变了人们的生活方式。飞睿智能5公里WiFi低延迟图传模组,它以其独特的优势…...

Kappa架构
1.Kappa架构介绍 Kappa架构由Jay Kreps提出,不同于Lambda同时计算和批计算并合并视图,Kappa只会通过流计算一条的数据链路计算并产生视图。Kappa同样采用了重新处理事件的原则,对于历史数据分析类的需求,Kappa要求数据的长期存储能…...

护网在即,助力安服仔漏洞扫描~
整合了个漏扫系统,安服仔必备~ 使用场景 网前布防,漏洞扫描,资产梳理 使用方法: 启动虚拟机后运行命令: ./StartSystemScript.sh 输入密码attack 启动完成后浏览器打开网站: http://IP:5000 相关账户…...
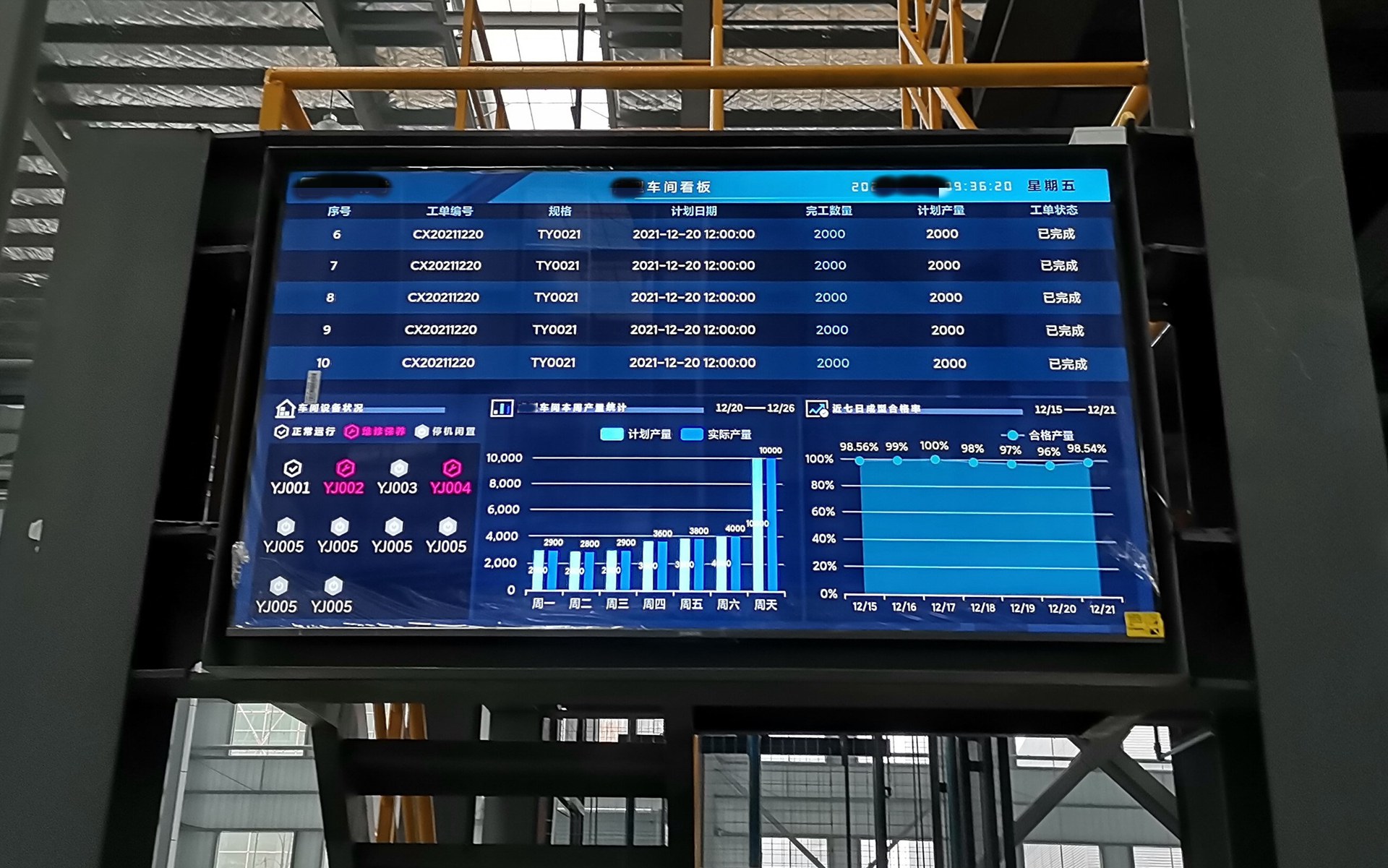
3C电子制造行业MES系统,提高企业生产效率
随着科技的不断进步,3C电子制造行业正迎来传统工厂向数字化工厂转型的阶段。在这场变革中,MES系统发挥着重要的作用,成为了企业变革的“智慧大脑”,引领着生产流程的优化和升级。 那么,MES系统究竟有哪些功能…...

C++ 多态和虚函数
参考C:多态 详解_c多态-CSDN博客 C多态——虚函数_c的a* a new b()是什么意思-CSDN博客 一.多态的概念 多态是在不同继承关系的类对象,去调用同一函数,产生了不同的行为。比如 Student 继承了 Person。 Person 对象买票全价,…...

七月记录上半
7.5 运行mysql脚本 mysql -u root -p 数据库名 < 脚本名 7.6 使用screen在服务器后台长期运行一个程序: screen -S 窗口名:创建窗口 执行程序脚本 ctrlad:退出窗口 screen -ls :查看所有窗口 screen -r 窗口号 &#…...
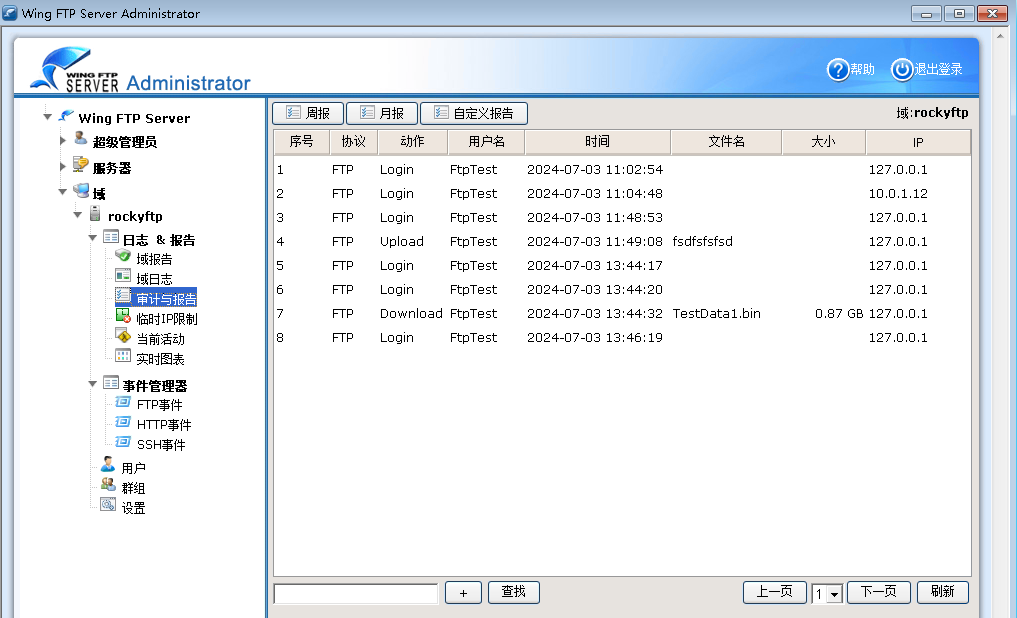
Wing FTP Server
文章目录 1.Wing FTP Server简介1.1主要特点1.2使用教程 2.高级用法2.1Lua脚本,案例1 1.Wing FTP Server简介 Wing FTP Server,是一个专业的跨平台FTP服务器端,它拥有不错的速度、可靠性和一个友好的配置界面。它除了能提供FTP的基本服务功能以外&#…...
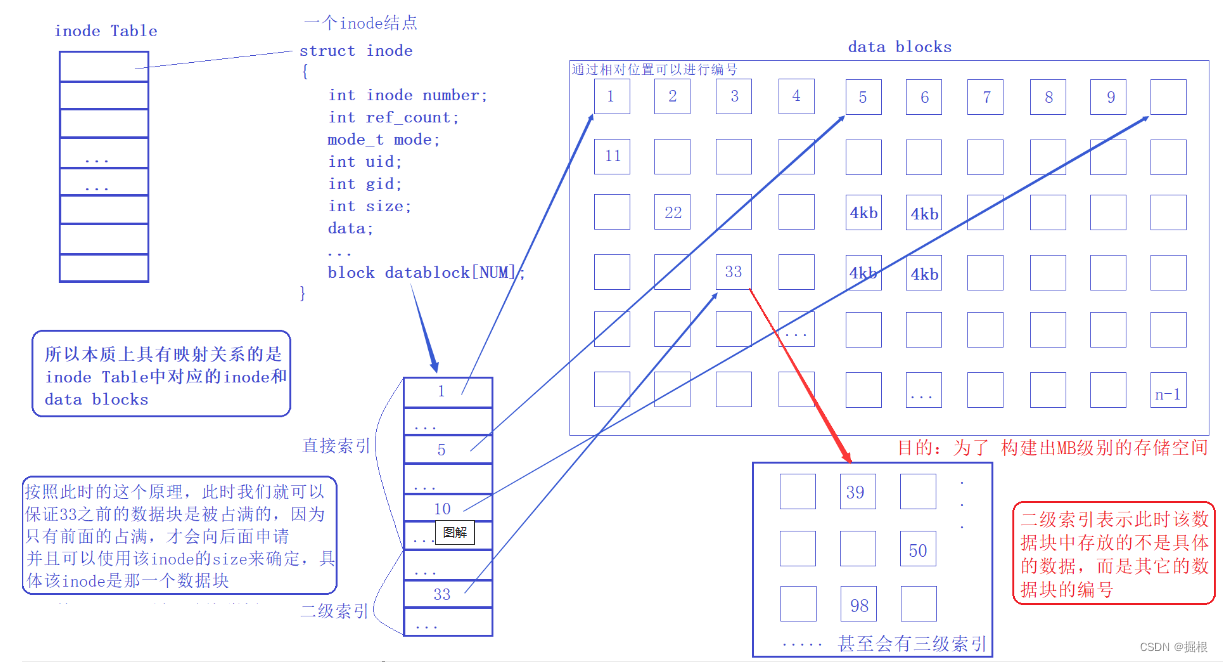
【Linux进阶】文件系统6——理解文件操作
目录 1.文件的读取 1.1.目录 1.2.文件 1.3.目录树读取 1.4.文件系统大小与磁盘读取性能 2.增添文件 2.1.数据的不一致(Inconsistent)状态 2.2.日志式文件系统(Journaling filesystem) 3.Linux文件系统的运行 4、文件的删…...

Python编译器的选择
了解如何使用一个集成开发环境(IDE)对于 Python 编程是非常重要的。IDE 提供了代码编辑、运行、调试、版本控制等多种功能,可以极大地提升开发效率。以下是一些流行的 Python IDE 和代码编辑器的介绍,以及如何开始使用它们&#x…...

Java | Leetcode Java题解之第217题存在重复元素
题目: 题解: class Solution {public boolean containsDuplicate(int[] nums) {Set<Integer> set new HashSet<Integer>();for (int x : nums) {if (!set.add(x)) {return true;}}return false;} }...

python基础语法 006 内置函数
1 内置函数 材料参考:内置函数 — Python 3.12.4 文档 Python 解释器内置了很多函数和类型,任何时候都能直接使用 内置函数有无返回值,是python自己定义,不能以偏概全说都有返回值 以下为较为常用的内置函数,欢迎补充…...

ABAP中BAPI_CURRENCY_CONV_TO_EXTERNAL函数详细的使用方法
在ABAP(SAP的应用程序开发语言)中,BAPI_CURRENCY_CONV_TO_EXTERNAL函数用于将SAP系统内部存储的货币金额转换为外部显示的格式。这个函数在处理财务报告、用户界面显示或与其他系统集成时非常有用。以下是该函数的详细使用方法: …...

Mac本地部署大模型-单机运行
前些天在一台linux服务器(8核,32G内存,无显卡)使用ollama运行阿里通义千问Qwen1.5和Qwen2.0低参数版本大模型,Qwen2-1.5B可以运行,但是推理速度有些慢。 一直还没有尝试在macbook上运行测试大模型…...
Qt:8.QWidget属性介绍(focuspolicy属性-控件焦点、stylesheet属性-为控件设置样式)
目录 一、focuspolicy属性-控件焦点: 1.1focuspolicy属性介绍: 1.2设置焦点策略——setFocusPolicy(): 1.3获取控件的焦点策略——focusPolicy(): 二、stylesheet属性——为控件设置样式: 2.1 stylesheet属性介绍…...

ECAPA-TDNN:通道注意力驱动的说话人验证技术革新
ECAPA-TDNN:通道注意力驱动的说话人验证技术革新 【免费下载链接】ECAPA-TDNN Unofficial reimplementation of ECAPA-TDNN for speaker recognition (EER0.86 for Vox1_O when train only in Vox2) 项目地址: https://gitcode.com/gh_mirrors/ec/ECAPA-TDNN …...

granite-4.0-h-350m部署案例:Ollama在科研团队内部知识引擎中的应用
granite-4.0-h-350m部署案例:Ollama在科研团队内部知识引擎中的应用 如果你在一个科研团队工作,每天面对海量的论文、实验报告和内部文档,是不是经常感觉信息过载,想找点资料就像大海捞针?或者,当新成员加…...
)
建筑行业老司机揭秘:中级职称挂靠的那些门道(附避坑指南)
建筑行业职称挂靠的深层逻辑与风险规避策略 在建筑行业摸爬滚打多年的从业者都清楚,职称证书不仅是个人专业能力的证明,更是一张可以兑换经济价值的"隐形支票"。当项目经理老张第一次听说朋友通过职称挂靠每月多赚5000元时,他的第一…...

2026年海南公司注册与合规服务行业评估报告
行业背景与评估维度2026年,随着海南自贸港全岛封关运作的正式实施,“零关税、低税率、简税制”的政策红利全面释放,海南已成为企业布局跨境业务与享受税收优惠的战略高地。然而,政策环境的快速迭代也带来了显著的痛点:…...

OpCore-Simplify终极指南:3分钟打造完美黑苹果EFI配置
OpCore-Simplify终极指南:3分钟打造完美黑苹果EFI配置 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 想要体验macOS的强大功能࿰…...

新手福音,用快马平台可视化学习apifox接口调用与测试
作为一个刚接触API开发的新手,第一次看到各种接口文档时完全摸不着头脑。直到发现了Apifox这个工具,配合InsCode(快马)平台的智能生成功能,终于找到了最适合新手的可视化学习路径。下面分享我的学习心得: 为什么选择Apifox作为入门…...

如何用Hearthstone-Script解放炉石传说玩家双手?开源自动化工具全解析
如何用Hearthstone-Script解放炉石传说玩家双手?开源自动化工具全解析 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 你是否也曾为炉石传说…...

角谷猜想/考拉兹猜想:3N+1
角谷猜想的转化:一切自然数转化为形如3^n-1的自然数???作者: 3n1/3^n-1/GrainShell/谷壳(加壳/脱壳) 2026-04-02 角谷猜想,又叫3N1猜想,又叫collatz,谐…...

Nunchaku FLUX.1-dev 开发环境配置:Anaconda虚拟环境创建与管理指南
Nunchaku FLUX.1-dev 开发环境配置:Anaconda虚拟环境创建与管理指南 想玩转Nunchaku FLUX.1-dev这类前沿的AI模型,第一步也是最关键的一步,就是把它的“家”给搭好。这个“家”就是Python虚拟环境。你可能听过不少因为环境依赖冲突ÿ…...

Janus-Pro-7B文生图作品展:中国风角色、科幻机甲、自然生态高清图集
Janus-Pro-7B文生图作品展:中国风角色、科幻机甲、自然生态高清图集 1. 模型能力概览 Janus-Pro-7B是DeepSeek推出的统一多模态模型,它在一个框架内同时实现了图像理解和文本生成图像两大核心功能。这个设计思路很巧妙——传统上,理解图像和…...