昇思25天学习打卡营第12天|FCN图像语义分割
文章目录
- 昇思MindSpore应用实践
- 基于MindSpore的FCN图像语义分割
- 1、FCN 图像分割简介
- 2、构建 FCN 模型
- 3、数据预处理
- 4、模型训练
- 自定义评价指标 Metrics
- 5、模型推理结果
- Reference
昇思MindSpore应用实践
本系列文章主要用于记录昇思25天学习打卡营的学习心得。
基于MindSpore的FCN图像语义分割
1、FCN 图像分割简介
全卷积网络(Fully Convolutional Networks,FCN)是UC Berkeley的Jonathan Long等人于2015年在Fully Convolutional Networks for Semantic Segmentation[1]一文中提出的用于图像语义分割的一种框架。
FCN是首个端到端(end to end)进行像素级(pixel level)预测分类(即语义分割的工作原理)的全卷积网络。
语义分割(Semantic Segmentation)的定义:每个像素对应一个类标签。同一类会被定义成一个区域块,不区分其中单个物体。
•任务:将图像中的每个像素分配到预定义的类别中,从而实现对图像的像素级别理解和分类。
•特点:不区分不同物体的实例,只关注像素所属的语义类别,例如人、车、树等。
•应用:自动驾驶、医学图像分析、视频分析等领域。
输入一张图片,经过前向传播和反向传播训练学习网络中的参数,可以实现端到端地输出语义分割的推理结果,像一个黑盒一样无需额外预处理。

2、构建 FCN 模型
FCN主要用于图像分割领域,是一种端到端的分割方法,是深度学习应用在图像语义分割的开山之作。通过进行像素级的预测直接得出与原图大小相等的label map。因FCN丢弃全连接层替换为全卷积层,网络所有层均为卷积层,故称为全卷积网络。
全卷积神经网络主要使用以下三种技术:
-
卷积化(Convolutional)
使用
VGG-16作为FCN的骨干网络(backbone)。VGG-16的输入为224*224的RGB图像,输出为1000个预测值。
VGG-16只能接受固定大小的输入,丢弃了空间坐标,产生非空间输出。VGG-16中共有三个全连接层,全连接层也可视为带有覆盖整个区域的卷积。将全连接层转换为卷积层能使网络输出由一维非空间输出变为二维矩阵,利用输出能生成输入图片映射的heatmap。
-
上采样(Upsample)
在卷积过程的卷积操作和池化操作会使得特征图的尺寸变小,为得到原图的大小的稠密图像预测,需要对得到的特征图进行上采样操作。使用双线性插值的参数来初始化上采样逆卷积的参数,后通过反向传播来学习非线性上采样。在网络中执行上采样,以通过像素损失的反向传播进行端到端的学习。

-
跳跃结构(Skip Layer)
利用上采样技巧对最后一层的特征图进行上采样得到原图大小的分割是步长为32像素的预测,称之为FCN-32s。
由于最后一层的特征图太小,损失过多细节,采用skips结构将更具有全局信息的最后一层预测和更浅层的预测结合,使预测结果获取更多的局部细节。将底层(stride 32)的预测(FCN-32s)进行2倍的上采样得到原尺寸的图像,并与从pool4层(stride 16)进行的预测融合起来(相加),这一部分的网络被称为FCN-16s。随后将这一部分的预测再进行一次2倍的上采样并与从pool3层得到的预测融合起来,这一部分的网络被称为FCN-8s。 Skips结构将深层的全局信息与浅层的局部信息相结合。

FCN 网络特点:
- 不含全连接层(fc)的全卷积(fully conv)网络,可适应任意尺寸输入。
- 增大数据尺寸的反卷积(deconv)层,能够输出精细的结果。
- 结合不同深度层结果的跳跃连接(skip)结构,同时确保鲁棒性和精确性。
基于MindSpore的FCN网络构建代码如下:
import mindspore.nn as nnclass FCN8s(nn.Cell):def __init__(self, n_class):super().__init__()self.n_class = n_class# conv1,输入通道数=输入图像通道数,输出通道数为64,卷积核为3*3,默认滑动步长为1self.conv1 = nn.SequentialCell( nn.Conv2d(in_channels=3, out_channels=64,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(in_channels=64, out_channels=64,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(64),nn.ReLU())# pool1,采用最大池化,池化不改变通道数,卷积核为2*2,滑动步长为2self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)# conv2,输入通道数为64,输出通道数128,卷积核3*3self.conv2 = nn.SequentialCell(nn.Conv2d(in_channels=64, out_channels=128,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(in_channels=128, out_channels=128,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(128),nn.ReLU())# pool2,采用最大池化,池化不改变通道数,卷积核为2*2,滑动步长为2self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)# conv3,输入通道数为128,输出通道数256,卷积核3*3self.conv3 = nn.SequentialCell(nn.Conv2d(in_channels=128, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(in_channels=256, out_channels=256,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(256),nn.ReLU())# pool3,采用最大池化,池化不改变通道数,卷积核为2*2,滑动步长为2self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)# conv4,输入通道数为256,输出通道数512,卷积核3*3self.conv4 = nn.SequentialCell(nn.Conv2d(in_channels=256, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU())# pool4,采用最大池化,池化不改变通道数,卷积核为2*2,滑动步长为2self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)# conv5,输入通道数为512,输出通道数1024,卷积核3*3self.conv5 = nn.SequentialCell(nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(in_channels=512, out_channels=512,kernel_size=3, weight_init='xavier_uniform'),# pool5,采用最大池化,池化不改变通道数,卷积核为2*2,滑动步长为2self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)# conv6,输入通道数为512,输出通道数4096,卷积核为7*7self.conv6 = nn.SequentialCell(nn.Conv2d(in_channels=512, out_channels=4096,kernel_size=7, weight_init='xavier_uniform'),nn.BatchNorm2d(4096),nn.ReLU(),)# conv7,输入通道数为4096,输出通道数4096,卷积核为1*1(像素级)self.conv7 = nn.SequentialCell(nn.Conv2d(in_channels=4096, out_channels=4096,kernel_size=1, weight_init='xavier_uniform'),nn.BatchNorm2d(4096),nn.ReLU(),)# 将特征图从较高的通道数(4096,通常接在一个CNN网络末端的特征维度)减少到分类的类别数(self.n_class)self.score_fr = nn.Conv2d(in_channels=4096, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')# 转置卷积层(反卷积,将特征图的尺寸从较小的尺寸增加到较大的尺寸),用来将特征图的尺寸上采样两倍(stride=2)# 将低分辨率的输出映射回较高分辨率,为最终恢复到原始输入图像的尺寸做准备self.upscore2 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=4, stride=2, weight_init='xavier_uniform')# 将通道数为512的特征图转换为类别数维度的输出self.score_pool4 = nn.Conv2d(in_channels=512, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')# 转置卷积层,用于将通过score_pool4层处理后的特征图再次上采样两倍self.upscore_pool4 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=4, stride=2, weight_init='xavier_uniform')# 将通道数为256的特征图转换为类别数维度的输出self.score_pool3 = nn.Conv2d(in_channels=256, out_channels=self.n_class,kernel_size=1, weight_init='xavier_uniform')# 最后一个转置卷积层,使用16x16的卷积核和8倍上采样,将特征图从较低分辨率放大到与原始输入图像相同的尺寸self.upscore8 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,kernel_size=16, stride=8, weight_init='xavier_uniform')def construct(self, x):x1 = self.conv1(x)p1 = self.pool1(x1)x2 = self.conv2(p1)p2 = self.pool2(x2)x3 = self.conv3(p2)p3 = self.pool3(x3)x4 = self.conv4(p3)p4 = self.pool4(x4)x5 = self.conv5(p4)p5 = self.pool5(x5)x6 = self.conv6(p5)x7 = self.conv7(x6)sf = self.score_fr(x7)u2 = self.upscore2(sf)s4 = self.score_pool4(p4)f4 = s4 + u2u4 = self.upscore_pool4(f4)s3 = self.score_pool3(p3)f3 = s3 + u4out = self.upscore8(f3)return out
3、数据预处理
由于PASCAL VOC 2012数据集中图像的分辨率大多不一致,无法放在一个tensor中,故输入前需做标准化处理。
将PASCAL VOC 2012数据集与SDB数据集进行混合:
import numpy as np
import cv2
import mindspore.dataset as dsclass SegDataset:def __init__(self,image_mean,image_std,data_file='',batch_size=32,crop_size=512,max_scale=2.0,min_scale=0.5,ignore_label=255,num_classes=21,num_readers=2,num_parallel_calls=4):self.data_file = data_fileself.batch_size = batch_sizeself.crop_size = crop_sizeself.image_mean = np.array(image_mean, dtype=np.float32)self.image_std = np.array(image_std, dtype=np.float32)self.max_scale = max_scaleself.min_scale = min_scaleself.ignore_label = ignore_labelself.num_classes = num_classesself.num_readers = num_readersself.num_parallel_calls = num_parallel_callsmax_scale > min_scaledef preprocess_dataset(self, image, label):image_out = cv2.imdecode(np.frombuffer(image, dtype=np.uint8), cv2.IMREAD_COLOR)label_out = cv2.imdecode(np.frombuffer(label, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)sc = np.random.uniform(self.min_scale, self.max_scale)new_h, new_w = int(sc * image_out.shape[0]), int(sc * image_out.shape[1])image_out = cv2.resize(image_out, (new_w, new_h), interpolation=cv2.INTER_CUBIC)label_out = cv2.resize(label_out, (new_w, new_h), interpolation=cv2.INTER_NEAREST)image_out = (image_out - self.image_mean) / self.image_stdout_h, out_w = max(new_h, self.crop_size), max(new_w, self.crop_size)pad_h, pad_w = out_h - new_h, out_w - new_wif pad_h > 0 or pad_w > 0:image_out = cv2.copyMakeBorder(image_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=0)label_out = cv2.copyMakeBorder(label_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=self.ignore_label)offset_h = np.random.randint(0, out_h - self.crop_size + 1)offset_w = np.random.randint(0, out_w - self.crop_size + 1)image_out = image_out[offset_h: offset_h + self.crop_size, offset_w: offset_w + self.crop_size, :]label_out = label_out[offset_h: offset_h + self.crop_size, offset_w: offset_w+self.crop_size]if np.random.uniform(0.0, 1.0) > 0.5:image_out = image_out[:, ::-1, :]label_out = label_out[:, ::-1]image_out = image_out.transpose((2, 0, 1))image_out = image_out.copy()label_out = label_out.copy()label_out = label_out.astype("int32")return image_out, label_outdef get_dataset(self):ds.config.set_numa_enable(True)dataset = ds.MindDataset(self.data_file, columns_list=["data", "label"],shuffle=True, num_parallel_workers=self.num_readers)transforms_list = self.preprocess_datasetdataset = dataset.map(operations=transforms_list, input_columns=["data", "label"],output_columns=["data", "label"],num_parallel_workers=self.num_parallel_calls)dataset = dataset.shuffle(buffer_size=self.batch_size * 10)dataset = dataset.batch(self.batch_size, drop_remainder=True)return dataset# 定义创建数据集的参数
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"# 定义模型训练参数
train_batch_size = 4
crop_size = 512
min_scale = 0.5
max_scale = 2.0
ignore_label = 255
num_classes = 21# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,image_std=IMAGE_STD,data_file=DATA_FILE,batch_size=train_batch_size,crop_size=crop_size,max_scale=max_scale,min_scale=min_scale,ignore_label=ignore_label,num_classes=num_classes,num_readers=2,num_parallel_calls=4)dataset = dataset.get_dataset()
import numpy as np
import matplotlib.pyplot as pltplt.figure(figsize=(16, 8))# 对训练集中的数据进行展示
for i in range(1, 9):plt.subplot(2, 4, i)show_data = next(dataset.create_dict_iterator())show_images = show_data["data"].asnumpy()show_images = np.clip(show_images, 0, 1)
# 将图片转换HWC格式后进行展示plt.imshow(show_images[0].transpose(1, 2, 0))plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0)
plt.show()

4、模型训练
import mindspore
from mindspore import Tensor
import mindspore.nn as nn
from mindspore.train import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor, Modeldevice_target = "GPU"
mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target=device_target)train_batch_size = 4
num_classes = 21
# 初始化模型结构
net = FCN8s(n_class=21)
# 导入vgg16预训练参数
load_vgg16()
# 计算学习率
min_lr = 0.0005
base_lr = 0.05
train_epochs = 1
iters_per_epoch = dataset.get_dataset_size()
total_step = iters_per_epoch * train_epochslr_scheduler = mindspore.nn.cosine_decay_lr(min_lr,base_lr,total_step,iters_per_epoch,decay_epoch=2)
lr = Tensor(lr_scheduler[-1])# 定义损失函数
# 语义分割是对图像中每个像素点进行分类,仍是分类问题,故损失函数选择交叉熵损失函数来计算FCN网络输出与mask之间的交叉熵损失
# mindspore中使用mindspore.nn.CrossEntropyLoss()作为交叉熵损失函数。loss = nn.CrossEntropyLoss(ignore_index=255)
# 定义优化器
optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.0001)
# 定义loss_scale
scale_factor = 4
scale_window = 3000
loss_scale_manager = ms.amp.DynamicLossScaleManager(scale_factor, scale_window)
# 初始化模型
if device_target == "Ascend":model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})# 设置ckpt文件保存的参数
time_callback = TimeMonitor(data_size=iters_per_epoch)
loss_callback = LossMonitor()
callbacks = [time_callback, loss_callback]
save_steps = 330
keep_checkpoint_max = 5
config_ckpt = CheckpointConfig(save_checkpoint_steps=10,keep_checkpoint_max=keep_checkpoint_max)
ckpt_callback = ModelCheckpoint(prefix="FCN8s",directory="./ckpt",config=config_ckpt)
callbacks.append(ckpt_callback)
model.train(train_epochs, dataset, callbacks=callbacks)IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"# 下载已训练好的权重文件
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/FCN8s.ckpt"
download(url, "FCN8s.ckpt", replace=True)
net = FCN8s(n_class=num_classes)ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)if device_target == "Ascend":model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,image_std=IMAGE_STD,data_file=DATA_FILE,batch_size=train_batch_size,crop_size=crop_size,max_scale=max_scale,min_scale=min_scale,ignore_label=ignore_label,num_classes=num_classes,num_readers=2,num_parallel_calls=4)
dataset_eval = dataset.get_dataset()
model.eval(dataset_eval)
从训练过程可以看出,基于VGG作为Backbone的FCN网路运算量是比较大的,仅1个epoch还未训练出良好的收敛状态:


由于FCN网络在训练的过程中需要大量的训练数据和训练轮数,这里只提供了小数据单个epoch的训练来演示loss收敛的过程,下文中使用已训练好的权重文件进行模型评估和推理效果的展示。
自定义评价指标 Metrics
这一部分主要对训练出来的模型效果进行评估,为了便于解释,假设如下:共有 k + 1 k+1 k+1 个类(从 L 0 L_0 L0 到 L k L_k Lk, 其中包含一个空类或背景), p i j p_{i j} pij 表示本属于 i i i类但被预测为 j j j类的像素数量。即, p i i p_{i i} pii 表示真正的数量, 而 p i j p j i p_{i j} p_{j i} pijpji 则分别被解释为假正和假负, 尽管两者都是假正与假负之和。
- Pixel Accuracy(PA, 像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。
P A = ∑ i = 0 k p i i ∑ i = 0 k ∑ j = 0 k p i j P A=\frac{\sum_{i=0}^k p_{i i}}{\sum_{i=0}^k \sum_{j=0}^k p_{i j}} PA=∑i=0k∑j=0kpij∑i=0kpii
- Mean Pixel Accuracy(MPA, 均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
M P A = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j M P A=\frac{1}{k+1} \sum_{i=0}^k \frac{p_{i i}}{\sum_{j=0}^k p_{i j}} MPA=k+11i=0∑k∑j=0kpijpii
- Mean Intersection over Union(MloU, 均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之,在语义分割的问题中,这两个集合为真实值(ground truth) 和预测值(predicted segmentation)。这个比例可以变形为正真数 (intersection) 比上真正、假负、假正(并集)之和。在每个类上计算loU,之后平均。
M I o U = 1 k + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i M I o U=\frac{1}{k+1} \sum_{i=0}^k \frac{p_{i i}}{\sum_{j=0}^k p_{i j}+\sum_{j=0}^k p_{j i}-p_{i i}} MIoU=k+11i=0∑k∑j=0kpij+∑j=0kpji−piipii
- Frequency Weighted Intersection over Union(FWIoU, 频权交井比):为MloU的一种提升,这种方法根据每个类出现的频率为其设置权重。
F W I o U = 1 ∑ i = 0 k ∑ j = 0 k p i j ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i F W I o U=\frac{1}{\sum_{i=0}^k \sum_{j=0}^k p_{i j}} \sum_{i=0}^k \frac{p_{i i}}{\sum_{j=0}^k p_{i j}+\sum_{j=0}^k p_{j i}-p_{i i}} FWIoU=∑i=0k∑j=0kpij1i=0∑k∑j=0kpij+∑j=0kpji−piipii
import numpy as np
import mindspore as ms
import mindspore.nn as nn
import mindspore.train as trainclass PixelAccuracy(train.Metric):def __init__(self, num_class=21):super(PixelAccuracy, self).__init__()self.num_class = num_classdef _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrixdef clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)def update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)def eval(self):pixel_accuracy = np.diag(self.confusion_matrix).sum() / self.confusion_matrix.sum()return pixel_accuracyclass PixelAccuracyClass(train.Metric):def __init__(self, num_class=21):super(PixelAccuracyClass, self).__init__()self.num_class = num_classdef _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrixdef update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)def eval(self):mean_pixel_accuracy = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)mean_pixel_accuracy = np.nanmean(mean_pixel_accuracy)return mean_pixel_accuracyclass MeanIntersectionOverUnion(train.Metric):def __init__(self, num_class=21):super(MeanIntersectionOverUnion, self).__init__()self.num_class = num_classdef _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrixdef update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)def eval(self):mean_iou = np.diag(self.confusion_matrix) / (np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -np.diag(self.confusion_matrix))mean_iou = np.nanmean(mean_iou)return mean_iouclass FrequencyWeightedIntersectionOverUnion(train.Metric):def __init__(self, num_class=21):super(FrequencyWeightedIntersectionOverUnion, self).__init__()self.num_class = num_classdef _generate_matrix(self, gt_image, pre_image):mask = (gt_image >= 0) & (gt_image < self.num_class)label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]count = np.bincount(label, minlength=self.num_class**2)confusion_matrix = count.reshape(self.num_class, self.num_class)return confusion_matrixdef update(self, *inputs):y_pred = inputs[0].asnumpy().argmax(axis=1)y = inputs[1].asnumpy().reshape(4, 512, 512)self.confusion_matrix += self._generate_matrix(y, y_pred)def clear(self):self.confusion_matrix = np.zeros((self.num_class,) * 2)def eval(self):freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)iu = np.diag(self.confusion_matrix) / (np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -np.diag(self.confusion_matrix))frequency_weighted_iou = (freq[freq > 0] * iu[freq > 0]).sum()return frequency_weighted_iou
5、模型推理结果
import cv2
import matplotlib.pyplot as pltnet = FCN8s(n_class=num_classes)
# 设置超参
ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)
eval_batch_size = 4
img_lst = []
mask_lst = []
res_lst = []
# 推理效果展示(上方为输入图片,下方为推理效果图片)
plt.figure(figsize=(8, 5))
show_data = next(dataset_eval.create_dict_iterator())
show_images = show_data["data"].asnumpy() # 原始图像
mask_images = show_data["label"].reshape([4, 512, 512]) # 语义分割的掩码图像
show_images = np.clip(show_images, 0, 1) # 限制show_images数组中的像素值在归一化后的0和1之间
for i in range(eval_batch_size):img_lst.append(show_images[i])mask_lst.append(mask_images[i])
res = net(show_data["data"]).asnumpy().argmax(axis=1)
for i in range(eval_batch_size):plt.subplot(2, 4, i + 1)plt.imshow(img_lst[i].transpose(1, 2, 0))plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0.02)plt.subplot(2, 4, i + 5)plt.imshow(res[i])plt.axis("off")plt.subplots_adjust(wspace=0.05, hspace=0.02)
plt.show()

在推理时,训练好的FCN对输入图像进行前向传播,图像经过FCN网络中的多层卷积、激活和池化后,通过上采样层恢复到原始尺寸,每个像素的输出通常经过 softmax 函数转换成为概率,表明每个像素属于各个类别的概率。选择概率最高的类别作为该像素的类别标签,每个像素对应一个类标签。同一类会被定义成一个区域块,从而实现整个图像的语义分割。
因此,FCN通过这种结构能够有效地在像素级别上对图像进行分类,实现精确的语义分割。
Reference
[1] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for Semantic Segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
[2] 昇思大模型平台
[3] 昇思官方文档-FCN图像语义分割
[4] 图像分割概述 - 语义分割、实例分割、全景分割、一键抠图(FCN, U-Net,Mask R-CNN,UPSNet)
相关文章:
昇思25天学习打卡营第12天|FCN图像语义分割
文章目录 昇思MindSpore应用实践基于MindSpore的FCN图像语义分割1、FCN 图像分割简介2、构建 FCN 模型3、数据预处理4、模型训练自定义评价指标 Metrics 5、模型推理结果 Reference 昇思MindSpore应用实践 本系列文章主要用于记录昇思25天学习打卡营的学习心得。 基于MindSpo…...

昇思MindSpore学习笔记4-03生成式--Diffusion扩散模型
摘要: 记录昇思MindSpore AI框架使用DDPM模型给图像数据正向逐步添加噪声,反向逐步去除噪声的工作原理和实际使用方法、步骤。 一、概念 1. 扩散模型Diffusion Models DDPM(denoising diffusion probabilistic model) (无)条件…...

Go:hello world
开启转职->Go开发工程师 下面是我的第一个go的程序 在上面的程序介绍: 1、package main 第一行代码package main定义了包名。必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程…...

JVM专题之内存模型以及如何判定对象已死问题
体验与验证 2.4.5.1 使用visualvm **visualgc插件下载链接 :https://visualvm.github.io/pluginscenters.html https://visualvm.github.io/pluginscenters.html **选择对应JDK版本链接--->Tools--->Visual GC** 2.4.5.2 堆内存溢出 * **代码** java @RestCont…...

vscode使用Git的常用操作
主打一个实用 查看此篇之前请先保证电脑安装了Git,安装教程很多,可自行搜索 一.初始化本地仓库🔴 使用vscode打开项目文件夹如图所使初始化仓库,相当于命令行的git init 二.提交到暂存区🔴 二.提交到新版本…...

RPC与REST
RPC与REST 访问远程服务1远程服务调用(Remote Procedure Call,RPC):RPC 解决什么问题?如何解决的?为什么要那样解决?1.1 先解决两个进程间如何交换数据的问题,也就是进程间通信&…...

计数排序的实现
原理 对一个数组进行遍历,再创建一个count数组 每找到一个值则在count数组中对应的位置加一,再在count数组中找到数字上方的count值,count值为几,则打印几次数组中的值. 开空间 相对映射 排序的实现 void CountSort(int* a, i…...

【Qt】QTableWidget设置可以选择多行多列,并能复制选择的内容到剪贴板
比如有一个 QTableWidget*m_tbwQuery m_tbwQuery->installEventFilter(this); //进行事件过滤处理//设置可以选择多行多列 m_tbwQuery->setSelectionMode(QAbstractItemView::MultiSelection); m_tbwQuery->setSelectionBehavior(QAbstractItemView::SelectItems); …...

跨越界限的温柔坚守
跨越界限的温柔坚守 —— 郑乃馨与男友的甜蜜抉择在这个光怪陆离、瞬息万变的娱乐圈里,每一段恋情像是夜空中划过的流星,璀璨短暂。然而,当“郑乃馨与男友甜蜜约会”的消息再次跃入公众视野,它不仅仅是一段简单的爱情故事…...

Vue3 对于内嵌Iframe组件进行缓存
1:应用场景 对于系统内所有内嵌iframe 的页面均通过同一个路由/iframe, 在router.query内传入不同src 参数,在同一组件内显示iframe 内嵌页面,对这些页面分别进行缓存。主要是通过v-show 控制显示隐藏从而达到iframe 缓存逻辑 2:…...

L04_MySQL知识图谱
这些知识点你都掌握了吗?大家可以对着问题看下自己掌握程度如何?对于没掌握的知识点,大家自行网上搜索,都会有对应答案,本文不做知识点详细说明,只做简要文字或图示引导。 1 基础 1.1内部组件结构 1.2 数据…...

什么是CNN,它和传统机器学习有什么区别
CNN,全称为卷积神经网络(Convolutional Neural Networks),是一种专门用于处理具有网格结构数据(如图像、视频)的深度学习模型。它由多个卷积层、池化层、全连接层等组成,通过卷积运算和池化操作…...

游戏开发面试题3
unity如何判断子弹射击到敌人,如果子弹特别快怎么办 使用物理学碰撞检测。使用Unity的物理组件,如Rigidbody和Collider,将子弹和敌人都设置为有一定的物理碰撞属性,当子弹碰到敌人的时候,就会触发OnCollisionEnter()事…...
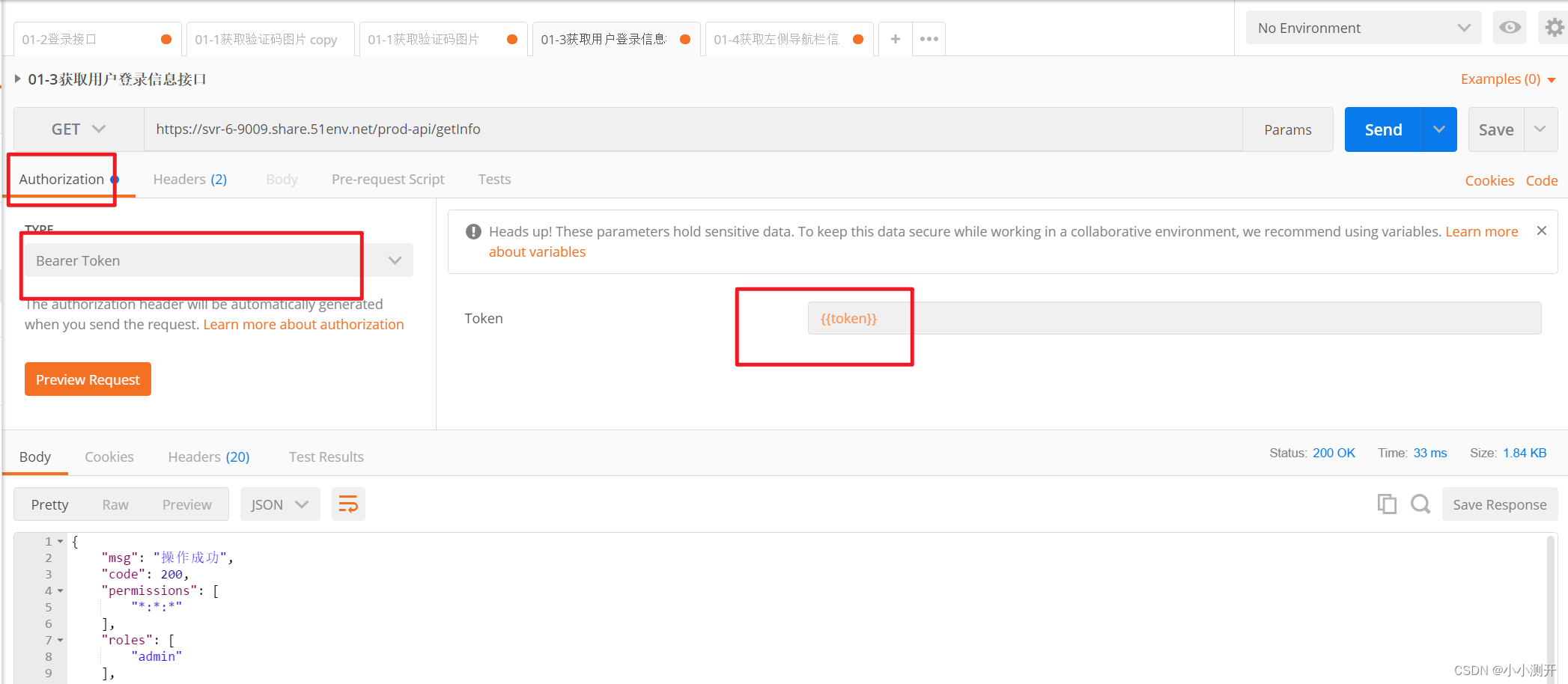
postman请求访问:认证失败,无法访问系统资源
1、使用postman时,没有传入相应的token,就会出现这种情况,此时需要把token放进去 发现问题: { "msg": "请求访问:/getInfo,认证失败,无法访问系统资源", "code": 401 } 1…...

Apache Seata新特性支持 -- undo_log压缩
本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 Apache Seata新特性支持 – undo_log压缩 Seata新特性支持 – undo_log压缩 现状 & 痛点…...

Java中的软件架构重构与升级策略
Java中的软件架构重构与升级策略 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 重构与升级的背景和意义 软件架构在应用开发中起着至关重要的作用。随着技术…...

设置Docker中时区不生效的问题
项目中使用docker-compose,并通过以下方式设置了时区 environment:- SET_CONTAINER_TIMEZONEtrue- CONTAINER_TIMEZONEAsia/Shanghai 但是并没有正确生效,网上有很多博客都在推荐这个做法,另外一种是使用标准环境标量 -TZAsia/Shangehai …...

LeetCode436:寻找右区间
题目链接:436. 寻找右区间 - 力扣(LeetCode) class Solution { public:vector<int> findRightInterval(vector<vector<int>>& intervals) {vector<pair<int, int>> startIntervals;int n intervals.size…...
前端JS特效第22集:html5音乐旋律自定义交互特效
html5音乐旋律自定义交互特效,先来看看效果: 部分核心的代码如下(全部代码在文章末尾): <!DOCTYPE html> <html lang"en" > <head> <meta charset"UTF-8"> <title>ChimeTime™</title…...

pyrender 离线渲染包安装教程
pyrender 离线渲染包安装教程 安装 安装 官方安装教程:https://pyrender.readthedocs.io/en/latest/install/index.html#installmesa 首先 pip install pyrenderclang6.0安装 下载地址:https://releases.llvm.org/download.html#6.0.0 注意下好是叫:clangllvm-6…...

DeOldify跨框架模型转换:从PyTorch到ONNX及TensorRT加速
DeOldify跨框架模型转换:从PyTorch到ONNX及TensorRT加速 最近在折腾一个挺有意思的项目,想把老照片上色的模型DeOldify部署到生产环境里。原版模型是用PyTorch写的,直接拿来用的话,推理速度总觉得差点意思,尤其是在处…...

终极指南:如何使用Consul实现HyperLPR车牌识别服务的微服务化改造
终极指南:如何使用Consul实现HyperLPR车牌识别服务的微服务化改造 【免费下载链接】HyperLPR High Performance Chinese License Plate Recognition Framework. 项目地址: https://gitcode.com/gh_mirrors/hy/HyperLPR HyperLPR作为高性能的中文车牌识别框架…...

探索R语言中的数据处理:序列统计
在数据分析中,我们经常需要处理复杂的顺序数据,例如测试的时间序列。在本篇博客中,我们将探讨如何使用R语言来处理一个特定的问题:统计四种测试(Test 1到Test 4)在不同顺序下的执行频率。 问题描述 假设我们有一个研究数据框,其中包含四种测试的日期,这些测试可以以任…...

OpenClaw技能市场探秘:Qwen3-32B-Chat镜像赋能10大自动化场景
OpenClaw技能市场探秘:Qwen3-32B-Chat镜像赋能10大自动化场景 1. 为什么需要技能市场? 第一次接触OpenClaw时,我误以为它只是个"高级版按键精灵"。直到在ClawHub技能市场看到wechat-publisher这个模块——它能直接将Markdown文章…...
✅)
计算机毕业设计:Python汽车销量数据挖掘与预测系统 Flask框架 scikit-learn 可视化 requests爬虫 AI 大模型(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...
)
基于单片机的心率及跌倒检测系统设计(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T4192205M设计简介:本设计是基于单片机的心率及跌倒检测系统,主要实现以下功能:1、可通过心率模块检测当前的心率 2、可…...

Three.js实战:打造交互式3D中国地图可视化
1. 从零开始搭建3D中国地图 第一次接触Three.js时,我被它强大的3D渲染能力震撼到了。作为一个长期从事数据可视化的开发者,我一直在寻找能够将地理数据以更生动方式呈现的工具。Three.js配合D3.js的组合,完美解决了这个问题。 1.1 数据准备与…...

OpenClaw学习助手:Qwen3.5-9B自动整理学术PDF笔记
OpenClaw学习助手:Qwen3.5-9B自动整理学术PDF笔记 1. 为什么需要自动化文献整理 作为一名每天需要阅读大量文献的研究者,我长期被两个问题困扰:一是PDF里的关键信息需要手动复制粘贴到笔记软件,二是不同文献的结论难以横向对比。…...

Python迭代器与生成器:从入门到精通的完全指南
本文将用最通俗易懂的方式讲解Python迭代器和生成器的核心概念,通过大量实例帮你彻底掌握这两个重要的Python特性。 1. 引言:为什么要学迭代器和生成器? 想象一下,你需要处理一个包含1000万条数据的文件,如果一次性把所有数据加载到内存,你的电脑可能就卡死了。这时,迭…...

别再死磕 SEO 了,2026 年是 GEO 的天下:如何让大模型在搜索结果里“翻你的牌子”?
1. 为什么 2026 年你的 SEO 流量断崖式下跌?如果你最近发现网站的 GA(Google Analytics)或百度统计里的自然流量在掉,别急着骂运营。看看现在的搜索习惯:用户不再去翻第二页的蓝色链接,而是直接在 Perplexi…...