强化学习中的Double DQN、Dueling DQN和PER DQN算法详解及实战
1. 深度Q网络(DQN)回顾
DQN通过神经网络近似状态-动作值函数(Q函数),在训练过程中使用经验回放(Experience Replay)和固定目标网络(Fixed Target Network)来稳定训练过程。DQN的更新公式为:
2. Double DQN算法
原理
DQN存在一个问题,即在更新Q值时,使用同一个Q网络选择和评估动作,容易导致过高估计(overestimation)问题。Double DQN(Double Deep Q-Network, DDQN)通过引入两个Q网络,分别用于选择动作和评估动作,来缓解这一问题。
公式推导
Double DQN的更新公式为:
其中:
是当前Q网络的参数。
是目标Q网络的参数。
代码实现
我们以经典的OpenAI Gym中的CartPole环境为例,展示Double DQN算法的实现。
import gym
import numpy as np
import tensorflow as tf
from tensorflow.keras import models, layers, optimizersclass DoubleDQNAgent:def __init__(self, state_size, action_size):self.state_size = state_sizeself.action_size = action_sizeself.memory = []self.gamma = 0.95self.epsilon = 1.0self.epsilon_decay = 0.995self.epsilon_min = 0.01self.learning_rate = 0.001self.model = self._build_model()self.target_model = self._build_model()self.update_target_model()def _build_model(self):model = models.Sequential()model.add(layers.Dense(24, input_dim=self.state_size, activation='relu'))model.add(layers.Dense(24, activation='relu'))model.add(layers.Dense(self.action_size, activation='linear'))model.compile(loss='mse', optimizer=optimizers.Adam(learning_rate=self.learning_rate))return modeldef update_target_model(self):self.target_model.set_weights(self.model.get_weights())def remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def act(self, state):if np.random.rand() <= self.epsilon:return np.random.choice(self.action_size)q_values = self.model.predict(state)return np.argmax(q_values[0])def replay(self, batch_size):minibatch = np.random.choice(self.memory, batch_size)for state, action, reward, next_state, done in minibatch:target = self.model.predict(state)if done:target[0][action] = rewardelse:t = self.model.predict(next_state)t_ = self.target_model.predict(next_state)target[0][action] = reward + self.gamma * t_[0][np.argmax(t[0])]self.model.fit(state, target, epochs=1, verbose=0)if self.epsilon > self.epsilon_min:self.epsilon *= self.epsilon_decayenv = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DoubleDQNAgent(state_size, action_size)
episodes = 1000for e in range(episodes):state = env.reset()state = np.reshape(state, [1, state_size])done = Falsetime = 0while not done:action = agent.act(state)next_state, reward, done, _ = env.step(action)next_state = np.reshape(next_state, [1, state_size])reward = reward if not done else -10agent.remember(state, action, reward, next_state, done)state = next_statetime += 1if done:agent.update_target_model()print(f"Episode: {e}/{episodes}, Score: {time}, Epsilon: {agent.epsilon:.2}")if len(agent.memory) > 32:agent.replay(32)env.close()
print("Double DQN训练完成")
3. Dueling DQN算法
原理
Dueling DQN通过将Q值函数拆分为状态价值(Value)和优势函数(Advantage),分别估计某一状态下所有动作的价值和某一动作相对于其他动作的优势。这样可以更好地评估状态的价值,从而提高算法性能。
公式推导
Dueling DQN的Q值函数定义为:
其中:
是状态价值函数。
是优势函数。
代码实现
以CartPole环境为例,展示Dueling DQN算法的实现。
import gym
import numpy as np
import tensorflow as tf
from tensorflow.keras import models, layers, optimizersclass DuelingDQNAgent:def __init__(self, state_size, action_size):self.state_size = state_sizeself.action_size = action_sizeself.memory = []self.gamma = 0.95self.epsilon = 1.0self.epsilon_decay = 0.995self.epsilon_min = 0.01self.learning_rate = 0.001self.model = self._build_model()self.target_model = self._build_model()self.update_target_model()def _build_model(self):input = layers.Input(shape=(self.state_size,))dense1 = layers.Dense(24, activation='relu')(input)dense2 = layers.Dense(24, activation='relu')(dense1)value_fc = layers.Dense(24, activation='relu')(dense2)value = layers.Dense(1, activation='linear')(value_fc)advantage_fc = layers.Dense(24, activation='relu')(dense2)advantage = layers.Dense(self.action_size, activation='linear')(advantage_fc)q_values = layers.Lambda(lambda x: x[0] + (x[1] - tf.reduce_mean(x[1], axis=1, keepdims=True)))([value, advantage])model = models.Model(inputs=input, outputs=q_values)model.compile(loss='mse', optimizer=optimizers.Adam(learning_rate=self.learning_rate))return modeldef update_target_model(self):self.target_model.set_weights(self.model.get_weights())def remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def act(self, state):if np.random.rand() <= self.epsilon:return np.random.choice(self.action_size)q_values = self.model.predict(state)return np.argmax(q_values[0])def replay(self, batch_size):minibatch = np.random.choice(self.memory, batch_size)for state, action, reward, next_state, done in minibatch:target = self.model.predict(state)if done:target[0][action] = rewardelse:t = self.target_model.predict(next_state)target[0][action] = reward + self.gamma * np.amax(t[0])self.model.fit(state, target, epochs=1, verbose=0)if self.epsilon > self.epsilon_min:self.epsilon *= self.epsilon_decayenv = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DuelingDQNAgent(state_size, action_size)episodes = 1000for e in range(episodes):state = env.reset()state = np.reshape(state, [1, state_size])done = Falsetime = 0while not done:action = agent.act(state)next_state, reward, done, _ = env.step(action)next_state = np.reshape(next_state, [1, state_size])reward = reward if not done else -10agent.remember(state, action, reward, next_state, done)state = next_statetime += 1if done:agent.update_target_model()print(f"Episode: {e}/{episodes}, Score: {time}, Epsilon: {agent.epsilon:.2}")if len(agent.memory) > 32:agent.replay(32)env.close()
print("Dueling DQN训练完成")4. 优先经验回放DQN(PER DQN)
原理
优先经验回放(Prioritized Experience Replay, PER)通过赋予不同经验样本不同的优先级来增强经验回放机制。优先级高的样本更有可能被再次抽取,从而加速学习过程。
公式推导
优先经验回放基于TD误差计算优先级,定义为:
其中:
是TD误差。
是一个小的正数,防止优先级为零。
然后根据优先级分布概率来采样,使用重要性采样权重来修正梯度更新,定义为:
代码实现
以CartPole环境为例,展示PER DQN算法的实现。
import gym
import numpy as np
import tensorflow as tf
from tensorflow.keras import models, layers, optimizers
import random
import collectionsclass PERDQNAgent:def __init__(self, state_size, action_size):self.state_size = state_sizeself.action_size = action_sizeself.memory = collections.deque(maxlen=2000)self.gamma = 0.95self.epsilon = 1.0self.epsilon_decay = 0.995self.epsilon_min = 0.01self.learning_rate = 0.001self.model = self._build_model()self.target_model = self._build_model()self.update_target_model()self.priority = []self.alpha = 0.6self.beta = 0.4self.beta_increment_per_sampling = 0.001def _build_model(self):model = models.Sequential()model.add(layers.Dense(24, input_dim=self.state_size, activation='relu'))model.add(layers.Dense(24, activation='relu'))model.add(layers.Dense(self.action_size, activation='linear'))model.compile(loss='mse', optimizer=optimizers.Adam(learning_rate=self.learning_rate))return modeldef update_target_model(self):self.target_model.set_weights(self.model.get_weights())def remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))self.priority.append(max(self.priority, default=1))def act(self, state):if np.random.rand() <= self.epsilon:return np.random.choice(self.action_size)q_values = self.model.predict(state)return np.argmax(q_values[0])def replay(self, batch_size):if len(self.memory) < batch_size:returnpriorities = np.array(self.priority)sampling_probabilities = priorities ** self.alphasampling_probabilities /= sampling_probabilities.sum()indices = np.random.choice(len(self.memory), batch_size, p=sampling_probabilities)minibatch = [self.memory[i] for i in indices]importance_sampling_weights = (len(self.memory) * sampling_probabilities[indices]) ** (-self.beta)importance_sampling_weights /= importance_sampling_weights.max()for i, (state, action, reward, next_state, done) in enumerate(minibatch):target = self.model.predict(state)if done:target[0][action] = rewardelse:t = self.target_model.predict(next_state)target[0][action] = reward + self.gamma * np.amax(t[0])self.model.fit(state, target, epochs=1, verbose=0, sample_weight=importance_sampling_weights[i])self.priority[indices[i]] = abs(target[0][action] - self.model.predict(state)[0][action]) + 1e-6if self.epsilon > self.epsilon_min:self.epsilon *= self.epsilon_decayself.beta = min(1.0, self.beta + self.beta_increment_per_sampling)env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = PERDQNAgent(state_size, action_size)
episodes = 1000for e in range(episodes):state = env.reset()state = np.reshape(state, [1, state_size])done = Falsetime = 0while not done:action = agent.act(state)next_state, reward, done, _ = env.step(action)next_state = np.reshape(next_state, [1, state_size])reward = reward if not done else -10agent.remember(state, action, reward, next_state, done)state = next_statetime += 1if done:agent.update_target_model()print(f"Episode: {e}/{episodes}, Score: {time}, Epsilon: {agent.epsilon:.2}")if len(agent.memory) > 32:agent.replay(32)env.close()
print("PER DQN训练完成")
5. 总结
Double DQN、Dueling DQN和优先经验回放DQN(PER DQN)都是对原始DQN的改进,各有其优点和适用场景。Double DQN通过减少过高估计提高了算法的稳定性;Dueling DQN通过分离状态价值和优势函数更好地评估状态;PER DQN通过优先采样重要经验加速了学习过程。这些改进算法在不同的应用场景下,可以选择合适的算法来提升强化学习的效果。
相关文章:
强化学习中的Double DQN、Dueling DQN和PER DQN算法详解及实战
1. 深度Q网络(DQN)回顾 DQN通过神经网络近似状态-动作值函数(Q函数),在训练过程中使用经验回放(Experience Replay)和固定目标网络(Fixed Target Network)来稳定训练过程…...

前端八股文 说一说样式优先级的规则是什么?
标准的回答 CSS样式的优先级应该分成四大类 第一类 !important: 😄无论引入方式是什么,选择器是什么,它的优先级都是最高的。 第二类 引入方式: 😄行内样式的优先级要高于嵌入和外链,嵌入和外链…...

洞察国内 AI 绘画行业的璀璨前景
在科技的浪潮中,AI 绘画如同一颗璀璨的新星,正在国内的艺术与技术领域绽放出耀眼的光芒。 近年来,国内 AI 绘画行业发展迅猛,展现出巨大的潜力。随着人工智能技术的不断突破,AI 绘画算法日益精进,能够生成…...

socket编程
文章目录 套接字网路字节序列TCP和UDP套接字 本文章主要介绍Linux下套接字的相关接口,和一些基础知识。 套接字 所有网络通信的行为本质都是进程间进行通信,网络通信也是进程间通信,只不过是不同主机上的两个进程之间的通信。网络通信对于双…...
)
python自动移除excel文件密码(升级v2版本)
欢迎查看第一版 https://blog.csdn.net/weixin_45631815/article/details/140013476?spm1001.2014.3001.5502 一功能改进 此版本主要改进功能有以下: 直接可以调用函数实现可以尝试多个密码没有加密的文件进行保存,可以按实际业务进行改进.思路来源:java 面向对象设计模式.…...

深入MOJO编程语言的单元测试世界
引言 在软件开发的历程中,单元测试扮演着至关重要的角色。单元测试不仅帮助开发者确保代码的每个部分都按预期工作,而且也是代码质量和维护性的关键保障。本文将引导读者了解如何在MOJO这一假想编程语言中编写单元测试,尽管MOJO并非真实存在…...

Canvas:掌握颜色线条与图像文字设置
想象一下,用几行代码就能创造出如此逼真的图像和动画,仿佛将艺术与科技完美融合,前端开发的Canvas技术正是这个数字化时代中最具魔力的一环,它不仅仅是网页的一部分,更是一个无限创意的画布,一个让你的想象…...

打包导入pyzbar的脚本时的注意事项
目录 前言问题问题的出现解决 总结 本文由Jzwalliser原创,发布在CSDN平台上,遵循CC 4.0 BY-SA协议。 因此,若需转载/引用本文,请注明作者并附原文链接,且禁止删除/修改本段文字。 违者必究,谢谢配合。 个人…...
02-android studio实现下拉列表+单选框+年月日功能
一、下拉列表功能 1.效果图 2.实现过程 1)添加组件 <LinearLayoutandroid:layout_width"match_parent"android:layout_height"wrap_content"android:layout_marginLeft"20dp"android:layout_marginRight"20dp"android…...
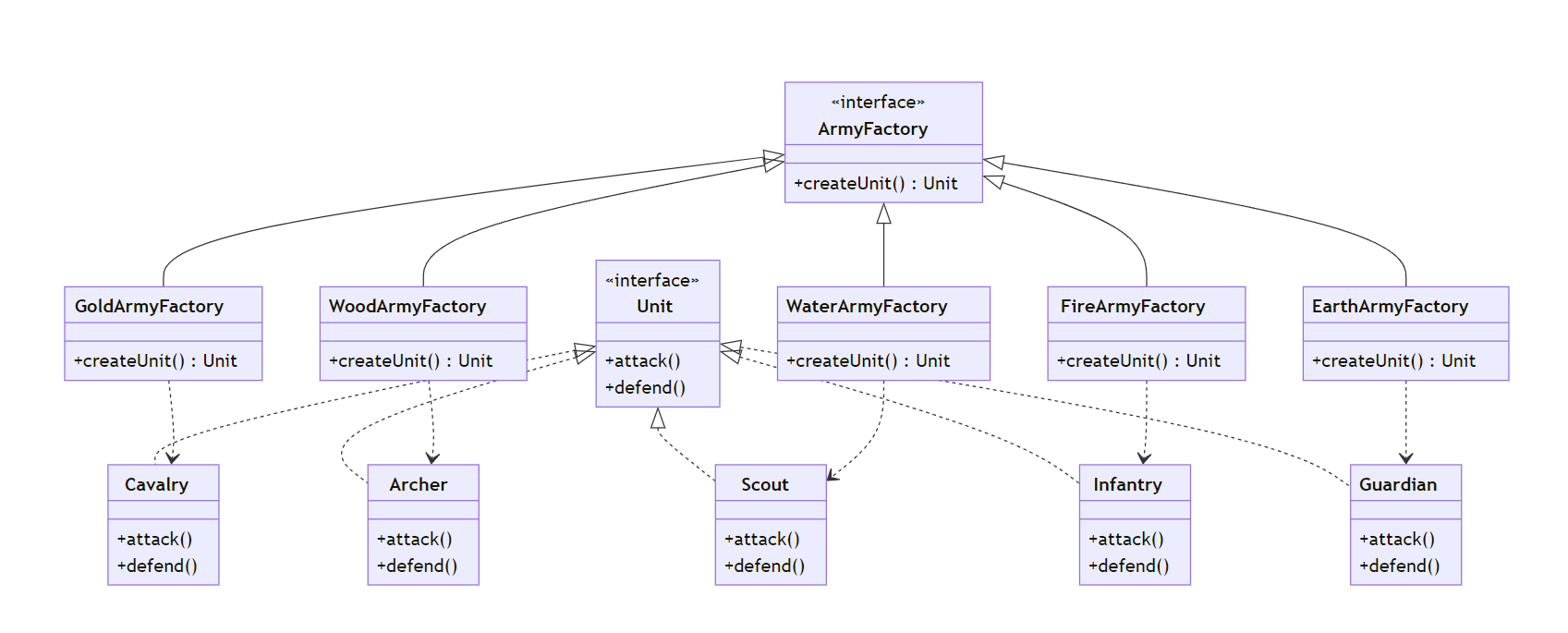
曹操的五色棋布阵 - 工厂方法模式
定场诗 “兵无常势,水无常形,能因敌变化而取胜者,谓之神。” 在三国的战场上,兵法如棋,布阵如画。曹操的五色棋布阵,不正是今日软件设计中工厂方法模式的绝妙写照吗?让我们从这个神奇的布阵之…...

谷粒商城学习笔记-逆向工程错误记录
文章目录 1,Since Maven 3.8.1 http repositories are blocked.1.1 在maven的settings.xml文件中,新增如下配置:1.2,执行clean命令刷新maven配置 2,internal java compiler error3,启动逆向工程报错&#x…...

FastAPI+SQLAlchemy数据库连接
FastAPISQLAlchemy数据库连接 目录 FastAPISQLAlchemy数据库连接配置数据库连接创建表模型创建alembic迁移文件安装初始化编辑env.py编辑alembic.ini迁移数据库 视图函数查询 配置数据库连接 # db.py from sqlalchemy import create_engine from sqlalchemy.orm import sessio…...

Android中的适配器,你知道是做什么的吗?
😄作者简介: 小曾同学.com,一个致力于测试开发的博主⛽️,主要职责:测试开发、CI/CD,日常还会涉及Android开发工作。 如果文章知识点有错误的地方,还请大家指正,让我们一起学习,一起…...

GitHub详解:代码托管与协作开发平台
文章目录 一、GitHub简介二、GitHub的核心功能2.1 仓库(Repository)2.2 版本控制与分支(Branch)2.3 Pull Request2.4 Issues与Projects2.5 GitHub Actions 三、GitHub的使用方法3.1 注册与登录3.2 创建和管理仓库3.3 使用Git进行代…...

【植物大战僵尸杂交版】获取+存档插件
文章目录 一、还记得《植物大战僵尸》吗?二、在哪下载,怎么安装?三、杂交版如何进行存档功能概述 一、还记得《植物大战僵尸》吗? 最近,一款曾经在15年前风靡一时的经典游戏《植物大战僵尸》似乎迎来了它的"文艺复…...

BP神经网络与反向传播算法在深度学习中的应用
BP神经网络与反向传播算法在深度学习中的应用 在神经网络的发展历史中,BP神经网络(Backpropagation Neural Network)占有重要地位。BP神经网络通过反向传播算法进行训练,这种算法在神经网络中引入了一种高效的学习方式。随着深度…...

【数据结构与算法】插入排序
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法》 期待您的关注 ...

MySQL如何实现数据排序
根据explain的执行计划来看,MySQL可以分为索引排序和filesort 索引排序 如果查询中的order by字句包含的字段已经在索引中,且索引的排列顺序和order by子句一致,则可直接利用索引进行排序,由于索引有序,所以排序效率…...

给我的 IM 系统加上监控两件套:【Prometheus + Grafana】
监控是一个系统必不可少的组成部分,实时,准确的监控,将会大大有助于我们排查问题。而当今微服务系统的话有一个监控组合很火那就是 Prometheus Grafana,嘿你别说 这俩兄弟配合的相当完美,Prometheus负责数据采集&…...

【Python】基于动态规划和K聚类的彩色图片压缩算法
引言 当想要压缩一张彩色图像时,彩色图像通常由数百万个颜色值组成,每个颜色值都由红、绿、蓝三个分量组成。因此,如果我们直接对图像的每个像素进行编码,会导致非常大的数据量。为了减少数据量,我们可以尝试减少颜色…...

4大技术方案解决WarcraftHelper工具的《魔兽争霸III》兼容性与性能优化问题
4大技术方案解决WarcraftHelper工具的《魔兽争霸III》兼容性与性能优化问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专注…...

H5动态公共导航栏
CommonNavBar.vue: <template><divclass"common-nav-bar":style"navBarStyle"><!-- 状态栏占位,可以按项目需要删除或调整高度 --><div class"status-bar-placeholder"></div><!-- 主导…...

汇编VS高级语言:从硬件操控到高效开发
汇编语言和Visual Studio(VS)的主要区别如下:核心区别对比维度汇编语言Visual Studio本质一种低级编程语言,直接操作硬件一种集成开发环境(IDE),支持多种高级语言使用场景嵌入式系统、驱动开发、…...

Linux网络诊断工具ping、traceroute等命令实战指南
在Linux系统的网络世界里,网络诊断工具就像是我们手中的“听诊器”,能够帮助我们精准地找出网络中存在的问题。今天,我们就来深入了解ping、traceroute等网络诊断命令的使用,通过实际操作和示例,让你轻松掌握使用这些工…...

别再把AI当聊天机器人了:Claude Code之父的“15倍速”工程化工作流全拆解
在这个AI编程工具层出不穷的时代,大多数人还在纠结“哪家大模型的代码补全更准”,或者在对话框里一行行地复制粘贴代码。然而,Anthropic工程师、Claude Code的缔造者Boris Cherny最近在X上公开的一套工作流,直接震碎了开发者社区的…...

用风水学重构代码:周易卦象优化系统架构
在软件工程领域,系统架构的优化与性能调优一直是技术专家们不懈探索的核心课题。传统的优化思路往往聚焦于算法效率、资源调度、中间件配置等技术维度。然而,一个更具颠覆性的视角正在悄然兴起:将源自古老东方智慧的《周易》卦象体系…...

告别重复输入:快马助你打造高效openclaw命令管理工具
最近在团队协作中频繁使用openclaw工具时,发现每次手动输入冗长的命令参数特别容易出错,尤其是当需要切换不同环境配置时,常常因为输错一个参数导致整个流程卡住。于是决定用Python开发一个小工具来提升操作效率,顺便把实现过程记…...

Qwen3.5-4B模型10分钟快速部署体验:开箱即用的推理服务
Qwen3.5-4B模型10分钟快速部署体验:开箱即用的推理服务 1. 惊艳的开箱即用体验 第一次在星图GPU平台上部署Qwen3.5-4B模型时,我有点不敢相信整个过程如此简单。从选择镜像到完成部署,再到开始第一次对话,全程只用了不到10分钟。…...

Apache DolphinScheduler 三月大动作,你知道几个?
嘿!2026 年 3 月 月报来啦!Apache DolphinScheduler 社区超给力~ 13 位小伙伴踊跃贡献代码,发布了 3.4.1 昕版本,调度增强、任务插件升级,还优化 API 与 UI,修复超 15 个 Bug。 与此同时,基础设…...

你的微信记忆银行:三分钟学会永久保存珍贵聊天记录
你的微信记忆银行:三分钟学会永久保存珍贵聊天记录 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMs…...