视觉语言模型:融合视觉与语言的未来
1. 概述
视觉语言模型(Vision-Language Models, VLMs)是能够同时处理和理解视觉(图像)和语言(文本)两种模态信息的人工智能模型。这种模型结合了计算机视觉和自然语言处理的技术,使得它们能够在视觉问答、图像描述生成、文本到图像搜索等复杂任务中表现出色。它是将transformer架构应用到计算机视觉领域的成功案例。具体来说就是将传统CNN中图像特征提取的全局替换为注意力机制。视觉语言模型在多个领域展示了巨大的潜力,包括图像检索、生成式AI、图像分割、医疗诊断和机器人技术。这些模型的出现不仅提升了AI系统的性能,还为开发更智能、更高效的应用程序提供了新的可能性。
2. 视觉Transformer
视觉Transformer(ViT)通过将图像分割成小块(patches),然后将这些小块嵌入到Transformer编码器中,以获取全局图像表示。每个图像块被视为一个独立的“词”,并通过自注意力机制进行处理。与传统的卷积神经网络(CNN)相比,视觉Transformer在处理大型数据集和高分辨率图像时表现出色。它们在图像分类任务中超越了许多先进的CNN架构。
下面是一个简单视觉Transformer的结构。

4. 视觉语言模型的架构
4.1 对比学习(Contrastive Learning)
对比学习是一种通过理解数据点差异来学习数据点的技术。该方法计算数据实例之间的相似性得分,旨在最大限度地减少对比损失。它在半监督学习中最有用,其中只有少数标记样本指导优化过程来标记看不见的数据点。
 例如,了解猫的外观的一种方法是将其与相似的猫图像和狗图像进行比较。对比学习模型通过识别面部结构、身体大小和皮毛等特征来学习区分猫和狗。这些模型可以确定哪张图像更接近原始图像(称为“锚点”),并预测其类别。其中CLIP模型就是典型的按照对比学习来训练的一种模型。CLIP模型通过计算文本和图像嵌入之间的相似度来实现零样本预测。它首先训练文本和图像编码器,然后将训练数据集的类别转换为标题,并为给定输入图像估计最佳标题。下面是CLIP模型的架构:
例如,了解猫的外观的一种方法是将其与相似的猫图像和狗图像进行比较。对比学习模型通过识别面部结构、身体大小和皮毛等特征来学习区分猫和狗。这些模型可以确定哪张图像更接近原始图像(称为“锚点”),并预测其类别。其中CLIP模型就是典型的按照对比学习来训练的一种模型。CLIP模型通过计算文本和图像嵌入之间的相似度来实现零样本预测。它首先训练文本和图像编码器,然后将训练数据集的类别转换为标题,并为给定输入图像估计最佳标题。下面是CLIP模型的架构:

4.2 前缀语言模型(PrefixLM)
前缀语言模型通过输入部分文本(前缀)并预测序列中的下一个词来进行预训练。在视觉语言模型中,PrefixLM 使模型能够根据图像及其各自的前缀文本预测下一个单词序列。它利用视觉变换器(ViT)将图像划分为一维补丁序列,每个序列代表一个局部图像区域。然后,该模型对处理后的补丁应用卷积或线性投影,以生成上下文化的视觉嵌入。对于文本模态,模型将相对于补丁的文本前缀转换为标记嵌入。转换器的编码器-解码器块接收视觉嵌入和令牌嵌入。SimVLM 是一种利用 PrefixLM 学习方法的流行架构。下面是它的架构:

4.3 冻结前缀语言模型(Frozen PrefixLM)
冻结前缀语言模型允许使用预训练网络,并仅更新图像编码器的参数。其中典型就有Frozen架构和Flamingo架构。Frozen架构使用预训练的语言模型和视觉编码器。通过微调图像编码器,使其图像表示与文本嵌入对齐。Flamingo架构结合了类似CLIP的视觉编码器和大型语言模型(LLM)。通过在文本之间插入图像,进行快速推理。下面是典型的一个Frozen PrefixLM的网络架构。

4.4 跨注意力融合(Cross-Attention)
Cross-Attention是一种通过跨模态注意力机制将不同模态(如文本、图像、音频等)信息进行融合的方法。跨注意力融合方法通过添加跨注意力层来学习视觉表示。具体来说,就是让一种数据类型的特征(比如文字)关注另一种数据类型的特征(比如图片),从而在理解和处理多种信息时表现更好。这种机制在许多需要同时处理多种数据类型的任务中都能显著提升效果。下面是Cross-Attention架构的原理图:

5. 视觉语言模型的数据集
5.1 LAION-5B
LAION-5B数据集包含超过50亿个由CLIP生成的图像-文本对,用于构建大型预训练模型。
https://laion.ai/blog/laion-5b/
5.2 PMD
PMD数据集由多个大型数据集组合而成,包含70亿个图像-文本对。
https://huggingface.co/datasets/facebook/pmd
5.3 VQA
VQA数据集用于视觉问答和视觉推理任务,包含超过20万张图像,每张图像有五个问题和对应的答案。
https://visualqa.org/
5.4 ImageNet
ImageNet数据集包含超过1400万张带注释的图像,适用于图像分类和目标识别任务。
https://www.image-net.org/
6. 视觉语言模型的应用
6.1 图像检索
通过视觉语言模型,用户可以使用语言查询找到相关的图像。

6.2 生成式AI
生成式AI允许用户通过文本描述生成图像,应用于设计和内容创作等领域。比如SD 等产品。

6.3 图像分割
VLMs可用于实例、全景和语义分割任务,通过理解用户提示进行图像标注。

相关文章:
视觉语言模型:融合视觉与语言的未来
1. 概述 视觉语言模型(Vision-Language Models, VLMs)是能够同时处理和理解视觉(图像)和语言(文本)两种模态信息的人工智能模型。这种模型结合了计算机视觉和自然语言处理的技术,使得它们能够在…...
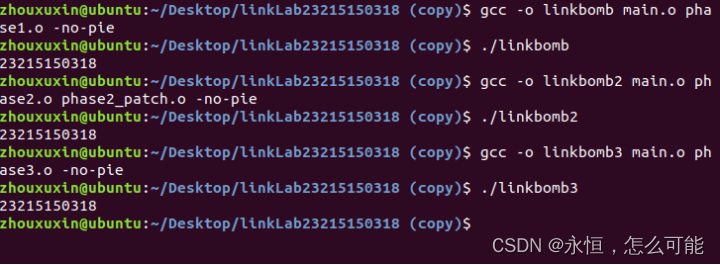
【CSAPP】-linklab实验
目录 实验目的与要求 实验原理与内容 实验步骤 实验设备与软件环境 实验过程与结果(可贴图) 实验总结 实验目的与要求 1.了解链接的基本概念和链接过程所要完成的任务。 2.理解ELF目标代码和目标代码文件的基本概念和基本构成 3.了解ELF可重定位目…...

UE C++ 多镜头设置缩放 平移
一.整体思路 首先需要在 想要控制的躯体Pawn上,生成不同相机对应的SpringArm组件。其次是在Controller上,拿到这个Pawn,并在其中设置输入响应,并定义响应事件。响应事件里有指向Pawn的指针,并把Pawn的缩放平移功能进行…...
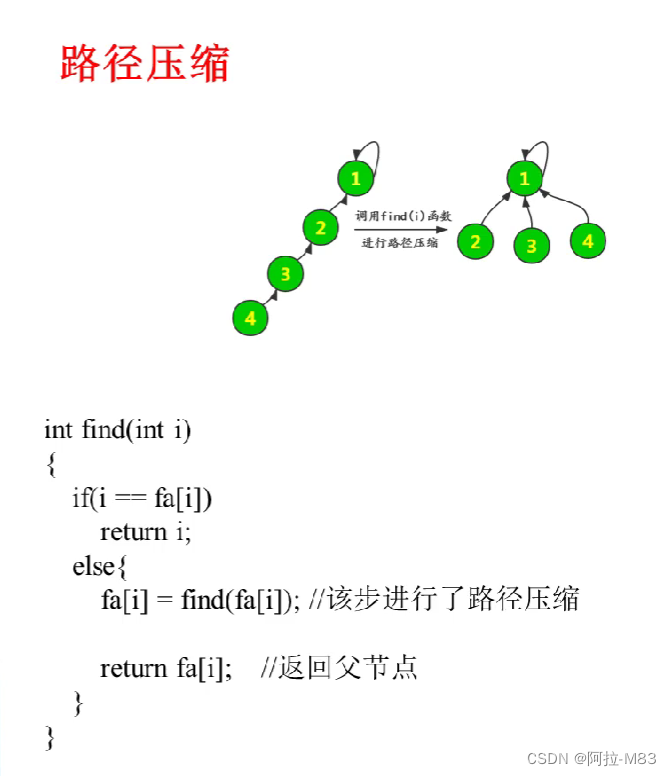
代码随想录Day69(图论Part05)
并查集 // 1.初始化 int fa[MAXN]; void init(int n) {for (int i1;i<n;i)fa[i]i; }// 2.查询 找到的祖先直接返回,未进行路径压缩 int.find(int i){if(fa[i] i)return i;// 递归出口,当到达了祖先位置,就返回祖先elsereturn find(fa[i])…...

53-1 内网代理3 - Netsh端口转发(推荐)
靶场还是用上一篇文章搭建的靶场 :52-5 内网代理2 - LCX端口转发(不推荐使用LCX)-CSDN博客 一、Netsh 实现端口转发 Netsh是Windows自带的命令行脚本工具,可用于配置端口转发。在一个典型的场景中,如果我们位于公网无法直接访问内网的Web服务器,可以利用中间的跳板机通过…...

四、(1)网络爬虫入门及准备工作(爬虫及数据可视化)
四、(1)网络爬虫入门及准备工作(爬虫及数据可视化) 1,网络爬虫入门1.1 百度指数1.2 天眼查1.3 爬虫原理1.4 搜索引擎原理 2,准备工作2.1 分析爬取页面2.2 爬虫拿到的不仅是网页还是网页的源代码2.3 爬虫就是…...
-C卷D卷-200分)
2024华为OD机试真题-分月饼-(C++/Python)-C卷D卷-200分
2024华为OD机试题库-(C卷+D卷)-(JAVA、Python、C++) 题目描述 中秋节,公司分月饼,m 个员工,买了 n 个月饼,m ≤ n,每个员工至少分 1 个月饼,但可以分多个,单人分到最多月饼的个数是 Max1 ,单人分到第二多月饼个数是 Max2 ,Max1 - Max2 ≤ 3 ,单人分到第 n - 1…...

Git 查看提交历史
Git 查看提交历史 Git 是一个强大的版本控制系统,它允许开发人员跟踪代码的变化,并与其他人协作。了解如何查看提交历史对于理解项目的发展和维护代码库至关重要。本文将详细介绍如何使用 Git 查看提交历史,包括不同的命令和选项,…...

力扣双指针算法题目:快乐数
目录 1.题目 2.思路解析 3.代码展示 1.题目 . - 力扣(LeetCode) 2.思路解析 题目意思是将一个正整数上面的每一位拿出来,然后分别求平方,最后将这些数字的平方求和得到一个数字,如此循环,如果在此循环中…...
:未来的智能体)
【Tools】了解人工通用智能 (AGI):未来的智能体
什么是人工通用智能 (AGI)? 人工通用智能(Artificial General Intelligence,AGI)是指一种能够理解、学习和应用知识,具有像人类一样广泛和通用的认知能力的智能系统。与专门处理特定任务的人工智能(AI&…...

华媒舍:8种网站构建推广方法全揭密!
网站构建成为了推广宣传和宣传品牌的关键一环。对于新手,搭建和营销推广网站有可能是一项全新的挑战。下面我们就为大家介绍8种网站搭建和营销推广技巧,帮助你在这些方面取得成功。 1.选择适合自己的网站构建平台选择合适的网站构建平台针对构建一个成功…...

【Scrapy】 深入了解 Scrapy 下载中间件的 process_exception 方法
准我快乐地重饰演某段美丽故事主人 饰演你旧年共寻梦的恋人 再去做没流着情泪的伊人 假装再有从前演过的戏份 重饰演某段美丽故事主人 饰演你旧年共寻梦的恋人 你纵是未明白仍夜深一人 穿起你那无言毛衣当跟你接近 🎵 陈慧娴《傻女》 Scrapy 是…...

DevEco Studio无法识别本地模拟器设备的解决方法
目录 场景 解决办法 方式1 方式2 场景 有很多小伙伴遇到过安装了手机模拟器, 但是开发工具设备栏不识别手机设备的问题, 如下图,明明模拟器都安装了,并启动, 但为什么设备栏不显示呢? 解决后的截图,应该是这样(其实跟 android 类似 )...

EN-SLAM:Implicit Event-RGBD Neural SLAM解读
论文路径:https://arxiv.org/pdf/2311.11013.pdf 目录 1 论文背景 2 论文概述 2.1 神经辐射场(NeRF) 2.2 事件相机(Event Camera) 2.3 事件时间聚合优化策略(ETA) 2.4 可微分的CRF渲染技术…...

2407C++,从构生成协议文件
原文 protobuf会根据proto文件生成c对象及其序化/反序化方法,而iguana的struct_pb则是以结构为核心,编译期反射来生成序化/反序化代码. 有人提出能不能按proto文件输出结构呢,这样就可给其它语言用了,很好建议,实现起来也比较简单. protobuf是从proto文件到c对象,而struct_p…...

遗传算法求解TSP
一、基本步骤 遗传算法求解旅行商问题(TSP)的一般步骤如下: 编码: 通常采用整数编码,将城市的访问顺序表示为一个染色体。例如,假设有 5 个城市,编码为[1, 3, 5, 2, 4],表示旅行商的…...

鸿蒙开发:Universal Keystore Kit(密钥管理服务)【明文导入密钥(C/C++)】
明文导入密钥(C/C) 以明文导入ECC密钥为例。具体的场景介绍及支持的算法规格 在CMake脚本中链接相关动态库 target_link_libraries(entry PUBLIC libhuks_ndk.z.so)开发步骤 指定密钥别名keyAlias。 密钥别名的最大长度为64字节。 封装密钥属性集和密钥材料。通过[OH_Huks_I…...

视频汇聚/安防监控/GB28181国标EasyCVR视频综合管理平台出现串流的原因排查及解决
安防视频监控系统/视频汇聚EasyCVR视频综合管理平台,采用了开放式的网络结构,能在复杂的网络环境中(专网、局域网、广域网、VPN、公网等)将前端海量的设备进行统一集中接入与视频汇聚管理,视频汇聚EasyCVR平台支持设备…...
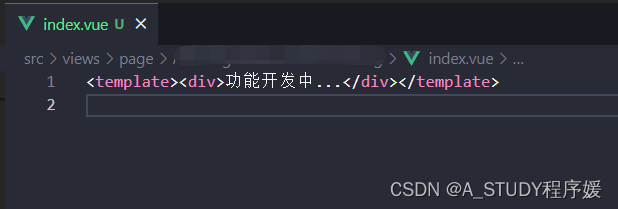
TypeError: Cannot read properties of null (reading ‘nextSibling‘)
做项目用的Vue3Vite, 在画静态页面时,点击菜单跳转之后总是出现如下报错,百思不得其解。看了网上很多回答,也没有解决问题,然后试了很多方法,最后竟然发现是template里边没有结构的原因。。。 原来我的index.vue是这样…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...

pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南
pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download pan-baidu-download是一款基于Python开发的百度网盘命令行下载…...