遗传算法求解TSP
一、基本步骤
遗传算法求解旅行商问题(TSP)的一般步骤如下:
-
编码:
- 通常采用整数编码,将城市的访问顺序表示为一个染色体。例如,假设有 5 个城市,编码为[1, 3, 5, 2, 4],表示旅行商的访问顺序为城市 1、城市 3、城市 5、城市 2、城市 4,最后回到出发城市 1。
-
初始化种群:
- 随机生成一定数量的染色体,作为初始种群。
-
适应度评估:
- 计算每个染色体所代表的路径长度,路径长度越短,适应度越高。适应度函数可以是路径长度的倒数或其他与路径长度相关的函数。
-
选择操作:
- 基于适应度,选择一定比例的染色体进入下一代种群。常见的选择方法有轮盘赌选择、锦标赛选择等。
-
交叉操作:
- 对选中的染色体进行交叉,生成新的染色体。例如,单点交叉,随机选择一个交叉点,交换两个染色体在交叉点之后的部分。
-
变异操作:
- 以一定的概率对染色体中的基因进行变异,例如随机交换两个城市的位置。
-
重复步骤 3 - 6 ,直到满足终止条件(如达到预定的迭代次数或找到满意的解)。
通过不断迭代,种群中的染色体逐渐优化,最终得到较优的 TSP 路径。需要注意的是,遗传算法的参数(如种群大小、交叉概率、变异概率等)需要根据具体问题进行调整和优化,以获得更好的求解效果。
二、代码
#!/usr/bin/env python
# coding: utf-8# In[32]:import numpy as np
import copy
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
import random# In[33]:#准备好距离矩阵
city_num = 5
city_dist_mat = np.zeros([city_num, city_num])
city_dist_mat[0][1] = city_dist_mat[1][0] = 1165
city_dist_mat[0][2] = city_dist_mat[2][0] = 1462
city_dist_mat[0][3] = city_dist_mat[3][0] = 3179
city_dist_mat[0][4] = city_dist_mat[4][0] = 1967
city_dist_mat[1][2] = city_dist_mat[2][1] = 1511
city_dist_mat[1][3] = city_dist_mat[3][1] = 1942
city_dist_mat[1][4] = city_dist_mat[4][1] = 2129
city_dist_mat[2][3] = city_dist_mat[3][2] = 2677
city_dist_mat[2][4] = city_dist_mat[4][2] = 1181
city_dist_mat[3][4] = city_dist_mat[4][3] = 2216
#标号说明
#list_city = ['0_北京', '1_西安', '2_上海', '3_昆明', '4_广州']# In[34]:#1.定义个体类,包括基因(城市路线)和适应度
num_person_idx = 0
num_person = 0
dis_list = []
class Individual:def __init__(self, genes = None):global num_personglobal dis_listglobal num_person_idxnum_person_idx += 1if num_person_idx % 20 == 0:num_person += 1self.genes = genesif self.genes == None:genes = [0]*5temp = [0]*4temp = [i for i in range(1,city_num)]########################################################################random.shuffle(temp)genes[1:] = tempgenes[0] = 0self.genes = genesself.fitness = self.evaluate_fitness()else:self.fitness = float(self.evaluate_fitness())#2. #计算个体的适应度def evaluate_fitness(self):dis = 0for i in range(city_num - 1):dis += city_dist_mat[self.genes[i]][self.genes[i+1]]if i == city_num - 2:dis += city_dist_mat[self.genes[i + 1]][0]#回到0if num_person_idx % 20 == 0:dis_list.append(dis)return 1/dis# In[35]:def copy_list(old):new = []for element in old:new.append(element)return new
def sort_win_num(group):for i in range(len(group)):for j in range(len(group) - i - 1):
# print('group[j].fitness_type', type(group[j].fitness))if group[j].fitness < group[j+1].fitness:temp = group[j]group[j] = group[j+1]group[j+1] = tempreturn group
#定义Ga类
#3~5,交叉、变异、更新种群,全部在Ga类中实现
class Ga:#input_为城市间的距离矩阵def __init__(self, input_):#声明一个全局变量global city_dist_matcity_dist_mat = input_#当代的最佳个体########################################此处做了更改#self.best = Noneself.best = Individual(None)
# print("BBBBBBbest.fitness",self.best.fitness)#种群self.individual_list = []#每一代的最佳个体self.result_list = []#每一代个体对应的最佳适应度self.fitness_list = []#交叉,这里采用交叉变异def cross(self):new_gen = []#随机选取一段,含有num_cross个数字(城市)num_cross = 3#后期可能需要调试的参数,考虑到实际问题里只有5个城市,所以认为3较为合适for i in range(0, len(self.individual_list) - 1, 2):parent_gen1 = copy_list(self.individual_list[i].genes)parent_gen2 = copy_list(self.individual_list[i+1].genes)
# print("parent_gen1",parent_gen1)
# print("parent_gen2",parent_gen2) index1_1 = 0index1_2 = 0index2_1 = 0index2_2 = 0#定义一个下表列表index_list = [0]*3for i in range(city_num - 3):#就是2,即0,1index_list[i] = i + 1index1_1 = random.choice(index_list)index1_2 = index1_1 + 2index2_1 = random.choice(index_list)index2_2 = index2_1 + 2choice_list1 = parent_gen1[index1_1:index1_2 + 1]choice_list2 = parent_gen2[index2_1:index2_2 + 1]
# print("choice_list1",choice_list1)
# print("choice_list2",choice_list2)#利用这一段生成两个子代,下面的赋值只是为了获取长度,所以用哪个父代能可以#也可以直接用city_num直接代替son_gen1 = [0]*city_numson_gen2 = [0]*city_num
# print('son_gen1_size = ',len(son_gen1))
# print('son_gen2_size = ',len(son_gen2))
# print("index1_1 == ",index1_1)
# print("index1_2 == ",index1_2)
# print("index2_1 == ",index2_1)
# print("index2_2 == ",index2_2)#找到之后进行交叉,分别得到son_gen1,son_gen2#先把选中的段复制进去son_gen1[index1_1: index1_2 + 1] = choice_list1son_gen2[index2_1: index2_2 + 1] = choice_list2
# print("now, son_gen1 = ", son_gen1)
# print("now, son_gen2 = ", son_gen2)#然后左、右“查漏补缺”temp1 = choice_list1temp2 = choice_list2if index1_1 == 0:passelse: for i in range(index1_1):for j in range(city_num):#如果父代2里面的这个当初没被选中,那就加入son_gene1if parent_gen2[j] not in choice_list1:son_gen1[i] = parent_gen2[j]#这个时候要扩增choice_list1, 这样parent_gen2里面未被选中的元素才会一个个被遍历到#1choice_list1.append(parent_gen2[j])#找到之后马上break,防止被覆盖breakchoice_list1 = temp1if index1_2 == city_num - 1:passelse:for i in range(index1_2 + 1, city_num):for j in range(city_num):if parent_gen2[j] not in choice_list1:son_gen1[i] = parent_gen2[j]#这个时候要扩增choice_list1, 这样parent_gen2里面未被选中的元素才会一个个被遍历到#2choice_list1.append(parent_gen2[j])#找到之后马上break,防止被覆盖break#son_gen2亦是如此if index2_1 == 0:passelse:for i in range(index2_1):for j in range(city_num):#如果父代1里面的这个当初没被选中,那就加入son_gen2if parent_gen1[j] not in choice_list2:son_gen2[i] = parent_gen1[j]#这个时候要扩增choice_list2, 这样parent_gen1里面未被选中的元素才会一个个被遍历到#3choice_list2.append(parent_gen1[j])#找到之后马上break,防止被覆盖breakchoice_list2 = temp2if index2_2 == city_num - 1:passelse:for i in range(index2_2 + 1, city_num):for j in range(city_num):if parent_gen1[j] not in choice_list2:
# print("i == ", i)son_gen2[i] = parent_gen1[j]#这个时候要扩增choice_list2, 这样parent_gen1里面未被选中的元素才会一个个被遍历到#4choice_list2.append(parent_gen1[j])#找到之后马上break,防止被覆盖break#新生成的子代基因加入new_gene列表
# print('son_gen1 = ',son_gen1)
# print('son_gen2 = ',son_gen2)new_gen.append(Individual(son_gen1))#print('new_gen[-1].genes', new_gen[-1].genes)new_gen.append(Individual(son_gen2))return new_gen#变异def mutate(self, new_gen):mutate_p = 0.02#待调参数index_list = [0]*(city_num-1)index_1 = 1index_2 = 1for i in range(city_num - 1):index_list[i] = i + 1for individual in new_gen:if random.random() < mutate_p:
# change += 1#如果变异,采用基于位置的变异,方便起见,直接使用上面定义的index列表index_l = random.choice(index_list)
# index_2 = (index_1 + 2) % city_num#这里让间隔为2的两个城市进行交换index_2 = random.choice(index_list)while index_1 == index_2:index_2 = random.choice(index_list)#交换temp = individual.genes[index_1]individual.genes[index_1] = individual.genes[index_2]individual.genes[index_2] = temp#变异结束,与老一代的进行合并self.individual_list += new_gen#选择def select(self):#在此选用轮盘赌算法#考虑到5的阶乘是120,所以可供选择的个体基数应该适当大一些,#在此每次从种群中选择6个,进行轮盘赌,初始化60个个体,同时适当调高变异的概率select_num = 6select_list = []for i in range(select_num):gambler = random.choice(self.individual_list)gambler = Individual(gambler.genes)select_list.append(gambler)#求出这些fitness之和sum = 0for i in range(select_num):sum += select_list[i].fitnesssum_m = [0]*select_num#实现概率累加for i in range(select_num):for j in range(i+1):sum_m[i] += select_list[j].fitnesssum_m[i] /= sumnew_select_list = []p_num = 0#随机数for i in range(select_num):p_num = random.uniform(0,1)if p_num>0 and p_num < sum_m[0]:new_select_list.append(select_list[0])elif p_num>= sum_m[0] and p_num < sum_m[1]:new_select_list.append(select_list[1])elif p_num >= sum_m[1] and p_num < sum_m[2]:new_select_list.append(select_list[2])elif p_num >= sum_m[2] and p_num < sum_m[3]:new_select_list.append(select_list[3])elif p_num >= sum_m[3] and p_num < sum_m[4]:new_select_list.append(select_list[4])elif p_num >= sum_m[4] and p_num < sum_m[5]:new_select_list.append(select_list[5])else:pass#将新生成的一代替代父代种群self.individual_list = new_select_list#更新种群def next_gen(self):#交叉new_gene = self.cross()#变异self.mutate(new_gene)#选择self.select()#获得这一代的最佳个体
# print("**************************************")
# print('self.best.fitness = ', self.best.fitness)
# print('now, best.fitness = ', self.best.fitness)for individual in self.individual_list:if individual.fitness > self.best.fitness:self.best = individual
# print("更换了最优路径")
# print('now, best.fitness = ', self.best.fitness)def train(self):#随机出初代种群#individual_num = 60self.individual_list = [Individual() for _ in range(individual_num)]#迭代gen_num = 100for i in range(gen_num):#从当代种群中交叉、变异、选择出适应度最佳的个体,获得子代产生新的种群self.next_gen()#连接首位
# print("i = ", i)result = copy.deepcopy(self.best.genes)result.append(result[0])self.result_list.append(result)self.fitness_list.append(self.best.fitness)print(self.result_list[-1])print('距离总和是:', 1/self.fitness_list[-1])
# return self.result_list, self.fitness_listdef draw(self):x_list = [i for i in range(num_person)]y_list = dis_listplt.rcParams['figure.figsize'] = (60, 45)plt.plot(x_list, y_list, color = 'g')plt.xlabel('Cycles',size = 50)plt.ylabel('Route',size = 50)x = np.arange(0, 910, 20)y = np.arange(7800, 12000, 100)plt.xticks(x)plt.yticks(y)plt.title('Trends in distance changes', size = 50)plt.tick_params(labelsize=30)
# plt.savefig("D:\AI_pictures\遗传算法求解TSP问题_1_轮盘赌算法")plt.show()
route = Ga(city_dist_mat)
route.train()
route.draw()相关文章:

遗传算法求解TSP
一、基本步骤 遗传算法求解旅行商问题(TSP)的一般步骤如下: 编码: 通常采用整数编码,将城市的访问顺序表示为一个染色体。例如,假设有 5 个城市,编码为[1, 3, 5, 2, 4],表示旅行商的…...

鸿蒙开发:Universal Keystore Kit(密钥管理服务)【明文导入密钥(C/C++)】
明文导入密钥(C/C) 以明文导入ECC密钥为例。具体的场景介绍及支持的算法规格 在CMake脚本中链接相关动态库 target_link_libraries(entry PUBLIC libhuks_ndk.z.so)开发步骤 指定密钥别名keyAlias。 密钥别名的最大长度为64字节。 封装密钥属性集和密钥材料。通过[OH_Huks_I…...

视频汇聚/安防监控/GB28181国标EasyCVR视频综合管理平台出现串流的原因排查及解决
安防视频监控系统/视频汇聚EasyCVR视频综合管理平台,采用了开放式的网络结构,能在复杂的网络环境中(专网、局域网、广域网、VPN、公网等)将前端海量的设备进行统一集中接入与视频汇聚管理,视频汇聚EasyCVR平台支持设备…...
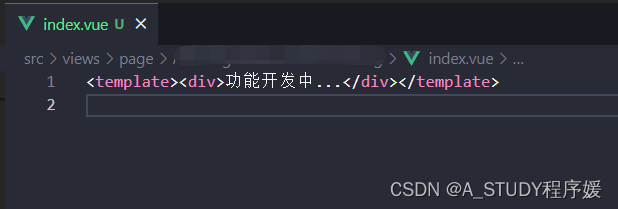
TypeError: Cannot read properties of null (reading ‘nextSibling‘)
做项目用的Vue3Vite, 在画静态页面时,点击菜单跳转之后总是出现如下报错,百思不得其解。看了网上很多回答,也没有解决问题,然后试了很多方法,最后竟然发现是template里边没有结构的原因。。。 原来我的index.vue是这样…...
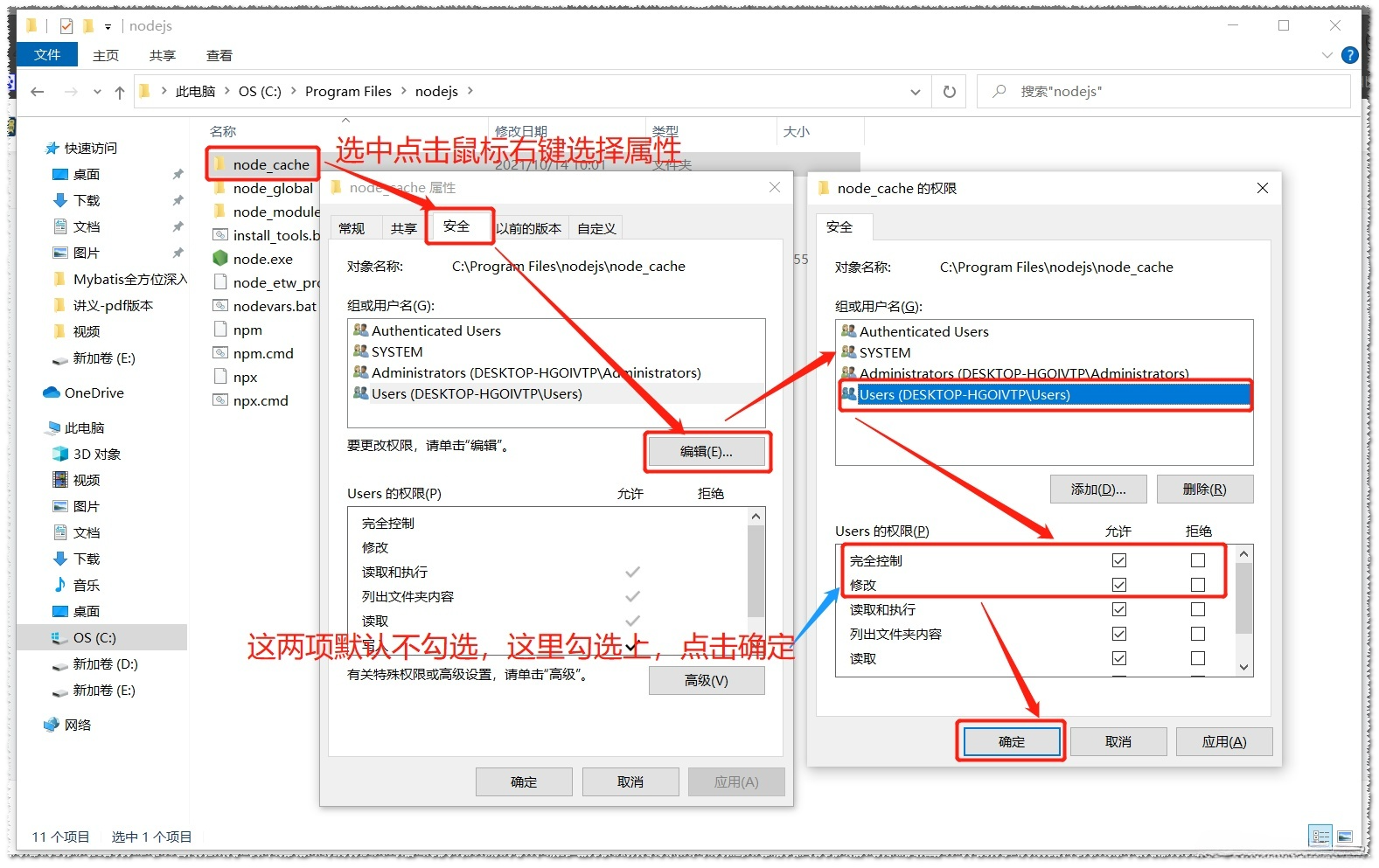
解决 npm intasll 安装报错 Error: EPERM: operation not permitted
Node.js安装及环境配置完成之后 npm install express -g 安装全局的模块报错提示没有权限operation not permitted mkdir 错误编号4048: 其原因是当前用户操作该目录权限不足,当以管理员身份运行cmd,再执行npm install express -g 是不会报权…...

redis实用技能
为什么要使用redis及其使用场景 大部分场景是应对高并发高性能场景才会使用,就是访问量已经超过mysql所能承受的,需要做缓存,帮助mysql分流。或者一些复杂查询,mysql执行很慢没法优化,可以做缓存提速(做缓存)做认证服务的时候需要存储用户的session信息,使用redis数据有…...

AcWing 1260:二叉树输出
【题目来源】https://www.acwing.com/problem/content/1262/【题目描述】 树的凹入表示法主要用于树的屏幕或打印输出,其表示的基本思想是兄弟间等长,一个结点的长度要不小于其子结点的长度。 二叉树也可以这样表示,假设叶结点的长度为 1&…...

刷爆leetcode第十期
题目一 相同的树 给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。 如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。 首先我们要来判断下它们的根是否相等 根相等的话是否它们的左子树相等 是否…...
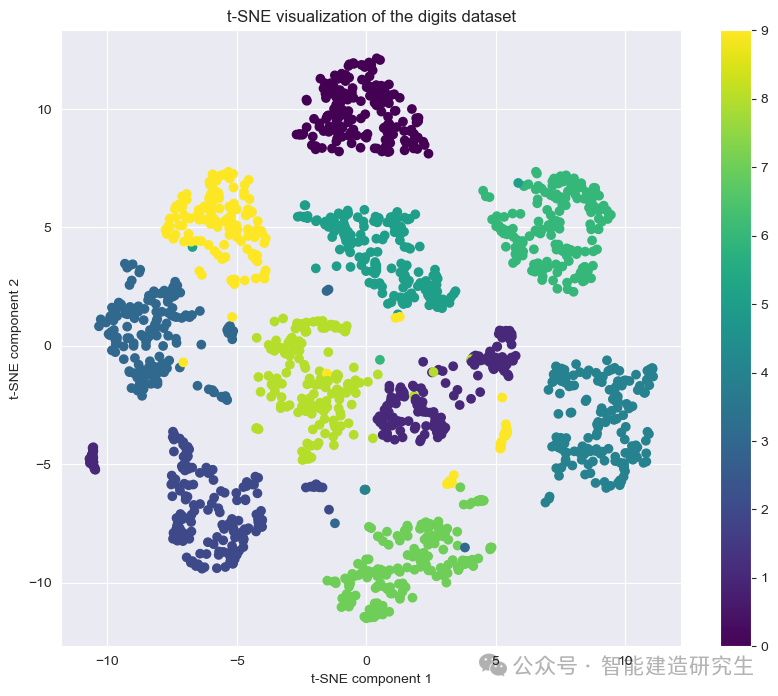
Python28-7.5 降维算法之t-分布邻域嵌入t-SNE
t-分布邻域嵌入(t-distributed Stochastic Neighbor Embedding,t-SNE)是一种用于数据降维和可视化的机器学习算法,尤其适用于高维数据的降维。t-SNE通过将高维数据嵌入到低维空间(通常是二维或三维)中&…...

一个最简单的comsol斜坡稳定性分析例子——详细步骤
一个最简单的comsol斜坡稳定性分析例子——详细步骤 标准模型例子—详细步骤 线弹性模型下的地应力平衡预应力与预应变、土壤塑性和安全系数求解的辅助扫描...

Java 变量类型
在Java中,变量类型包括基本数据类型和引用数据类型,每种类型有其特定的用途和存储方式。 ### 1. 基本数据类型 Java的基本数据类型包括整数类型、浮点类型、字符类型和布尔类型,它们分别是: - **整数类型**:用于存储…...
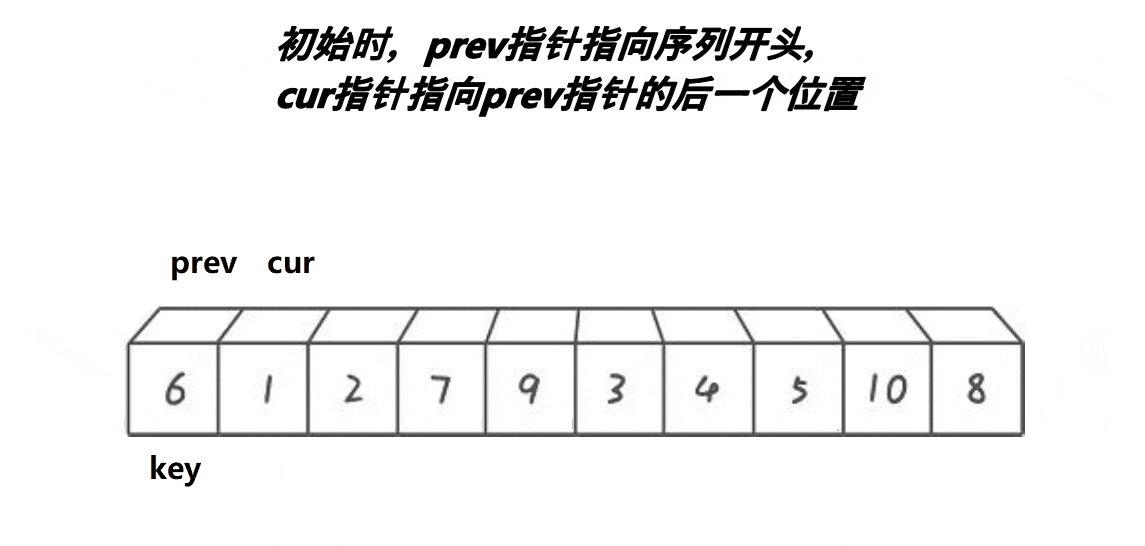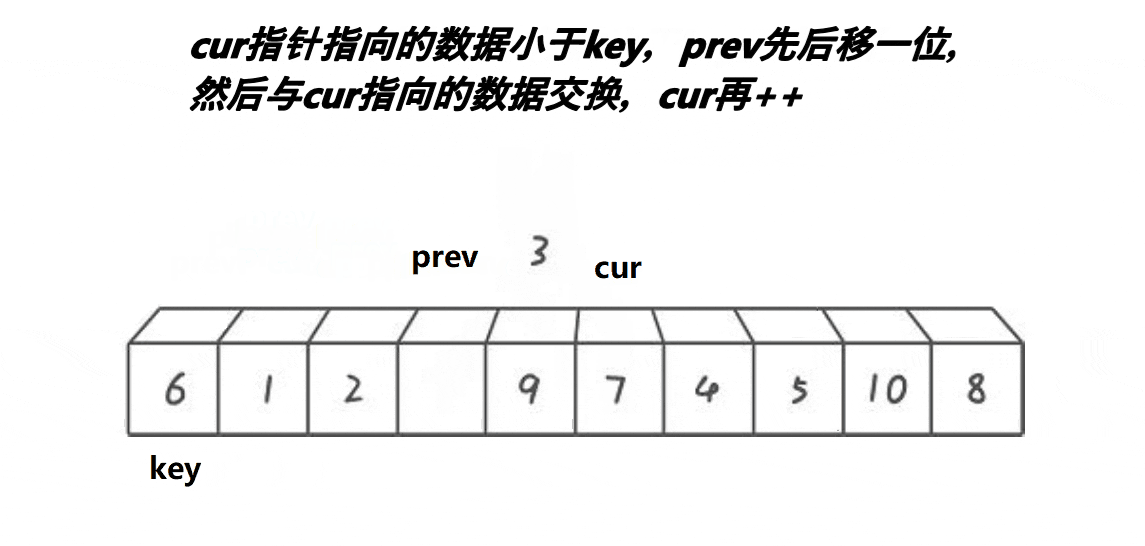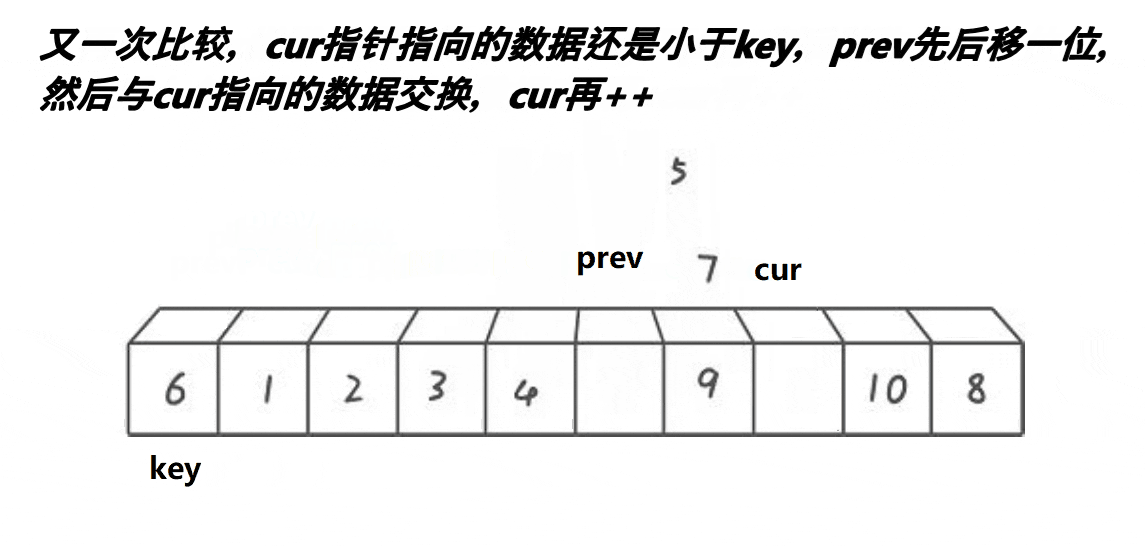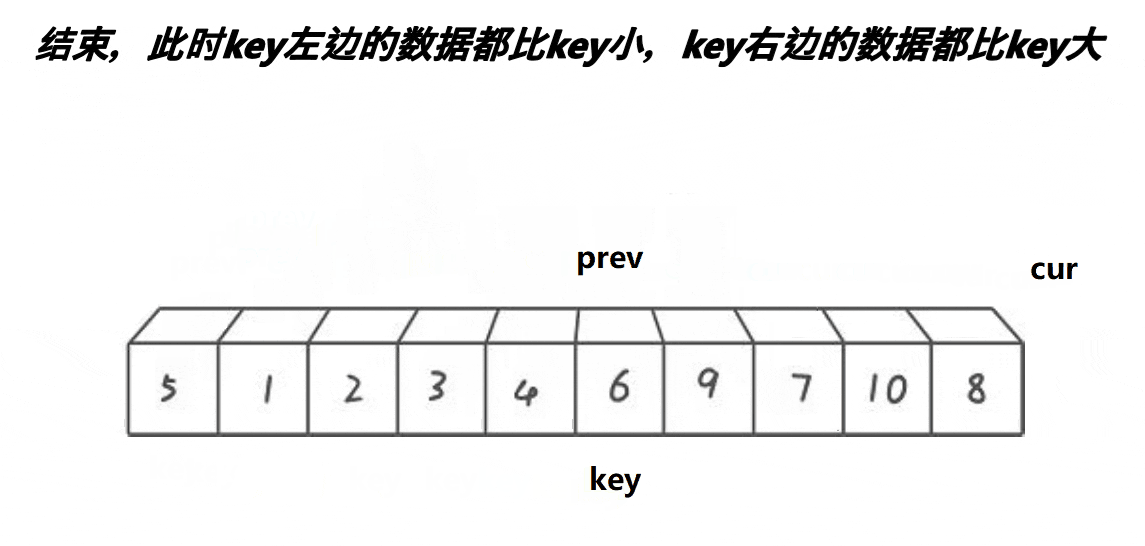
【排序算法】—— 快速排序
快速排序的原理是交换排序,其中qsort函数用的排序原理就是快速排序,它是一种效率较高的不稳定函数,时间复杂度为O(N*longN),接下来就来学习一下快速排序。 一、快速排序思路 1.整体思路 以升序排序为例: (1)、首先随…...
前端JS特效第22波:jQuery滑动手风琴内容切换特效
jQuery滑动手风琴内容切换特效,先来看看效果: 部分核心的代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xm…...

redis的数据类型对应的使用场景
Redis提供了多种数据类型,每种数据类型都有其特定的适用场景。以下是Redis主要数据类型及其典型应用场景:1. 字符串(String) 应用场景:适用于存储简单的键值对数据,如用户基本信息、计数器(如网页访问次数&…...

ctfshow-web入门-命令执行(web118详解)Linux 内置变量与Bash切片
输入数字和小写字母,回显 evil input 查看源码,发现这里会将提交的参数 code 传给 system 函数 使用 burpsuite 抓包进行单个字符的模糊测试 fuzz: 发现过滤掉了数字和小写字母以及一些符号,下面框起来的部分是可用的 结合题目提…...

C语言 指针和数组——指针和二维数组之间的关系
目录 换个角度看二维数组 指向二维数组的行指针 按行指针访问二维数组元素 再换一个角度看二维数组 按列指针访问二维数组元素 二维数组作函数参数 指向二维数组的行指针作函数参数 指向二维数组的列指针作函数参数编辑 用const保护你传给函数的数据 小结 换个角度看…...
问题集锦1
01.inner中使用JwtTokenUtil.getUserCode() 前端调用上传(java),上传使用加购 Overridepublic Boolean insertShoppingCart(InsertShoppingCartParamsDto dto) {// 通过userCode,itemCode和supplierCode来判断当前加购人添加到购物车的商品是…...

浅析MySQL-索引篇01
什么是索引? 索引是帮助存储引擎快速获取数据的一种数据结构,类似于数据的目录。 索引的分类 按数据结构分类: MySQL 常见索引有 BTree 索引、HASH 索引、Full-Text 索引。 Innodb是MySQL5.5之后的默认存储引擎,BTree索引类型也…...

2028年企业云存储支出翻倍,达到1280亿美元
根据Omdia的研究,到2028年,企业云存储支出将从去年的570亿美元翻一番以上,达到1280亿美元。该研究分析了基础设施即服务(IaaS)和平台即服务(PaaS)数据中心的收入,作为年度存储数据服…...

ActiViz中的颜色映射表vtkLookupTable
文章目录 一、简介二、VtkLookupTable的创建与初始化三、设置数据范围四、颜色映射设置五、不透明度设置六、自定义颜色映射七、 不连续性颜色映射八、 预设颜色映射方案九、可视化效果优化十、与其他VTK组件的整合十一、 动态调整映射表十二、保存和加载颜色映射表一、简介 V…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...
)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理(附dpkg/apt组合拳)
UOS系统下WPS卸载不干净?手把手教你用命令行精准清理 在UOS系统日常使用中,WPS Office作为常用办公软件,有时因版本更新或功能调整需要彻底卸载。但不少用户发现,通过图形界面或简单命令卸载后,系统中仍残留配置文件、…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

机器学习在射电天文数据分类中的应用:以MIGHTEE巡天SFG/AGN分类为例
1. 项目概述:当机器学习遇见深空射电巡天在射电天文学领域,我们正经历一场数据洪流。以MeerKAT望远镜阵列主导的MIGHTEE巡天项目为例,其在COSMOS天区的一次早期科学数据释放,就在不到1平方度的天区内探测到了超过6000个射电源。传…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...
)
从数据到模型:手把手教你预处理MPIIFaceGaze和EyeDiap数据集(Python实战)
从数据到模型:手把手教你预处理MPIIFaceGaze和EyeDiap数据集(Python实战)当你第一次打开MPIIFaceGaze或EyeDiap数据集的压缩包时,那种面对杂乱文件夹和神秘.mat文件的迷茫感,我太熟悉了。作为计算机视觉工程师…...