LeetCode 744, 49, 207
目录
- 744. 寻找比目标字母大的最小字母
- 题目链接
- 标签
- 思路
- 代码
- 49. 字母异位词分组
- 题目链接
- 标签
- 思路
- 代码
- 207. 课程表
- 题目链接
- 标签
- 思路
- 代码
744. 寻找比目标字母大的最小字母
题目链接
744. 寻找比目标字母大的最小字母
标签
数组 二分查找
思路
本题比 基础二分查找 难的一点是 需要处理数组中的重复值,另外需要提前判断目标字母target是否比字符数组letters中最大的字母letters[letters.length - 1]还要大,如果是,则按照题目要求直接返回letters的第一个字符;否则才进行二分查找。
如何处理重复值?可以 在找到与target相同的字符时,不急于返回这个字符,而是继续缩小查询区间。
而缩小查询区间的策略与题目的要求有关,如果要找 小于target的字符,则下一轮在 左子区间 查询,最后的右指针right就指向小于target的元素;如果要找 大于target的字符,则下一轮在 右子区间 查询,最后的左指针left就指向大于target的元素。
例如对于在letters = ['a', 'a', 'b', 'b', 'c', 'c']中查找大于target = 'b'的字符,有如下的二分查找流程:
开始
left = 0, right = 5, mid = 2,发现target == letters[mid],于是下一轮查询右子区间;
此时left = 3, right = 5, mid = 4,发现target < letters[mid],于是下一轮查询左子区间;
此时left = 3, right = 3, mid = 3,发现target == letters[mid],于是下一轮查询右子区间;
此时left = 4, right = 3,有left > right,退出查找。
最后left为4,而letters[left]为'c',这正是要求查找的字符。
代码
class Solution {public char nextGreatestLetter(char[] letters, char target) {int left = 0, right = letters.length - 1;if (target >= letters[right]) { // 如果letters中没有比target大的字符return letters[0]; // 则返回letters的第一个字符}while (left <= right) {int mid = left + (right - left >> 1);if (target < letters[mid]) { // 若target小于mid指向的元素right = mid - 1; // 则下一轮查找左子区间} else if (target > letters[mid]) { // 若target大于mid指向的元素left = mid + 1; // 则下一轮查找右子区间} else { // 由于不确定mid是否为 最后一个等于target的字符left = mid + 1; // 所以下一轮查找右子区间,而不是急于返回}}// 循环结束后left指向letters中第一个大于target的元素return letters[left];}
}
49. 字母异位词分组
题目链接
49. 字母异位词分组
标签
数组 哈希表 字符串 排序
思路
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。所以字母异位词不关心字符的顺序,只关心 字符的出现次数。
所以可以 将字符串中的字符出现次数作为字符串的键,将这个字符串存储到 这个键对应的字符串链表中,即有如此结构Map<Cnt, List<String>>。这里的Cnt是自己实现的数据类型,它内部存储着字符的出现次数,并重写了equals & hashCode方法,可以作为HashMap的键。
将字符串根据不同的字符出现此时分配完之后,将Map的values()作为构建ArrayList的参数,构建一个List<List<String>>,并将其返回。
代码
class Solution {public List<List<String>> groupAnagrams(String[] strs) {Map<Cnt, List<String>> map = new HashMap<>();for (String str : strs) {Cnt cnt = new Cnt(str); // 获取这个字符串的字符出现次数// 获取cnt对应的字符串链表,如果没有,则创建一个新链表List<String> list = map.computeIfAbsent(cnt, k -> new ArrayList<>());list.add(str); // 将这个字符串放入cnt对应的字符串链表中}// 由map的多个 字符串链表List<String> 构建一个 List<List<String>> 并返回return new ArrayList<>(map.values());}private static class Cnt { // 统计字符串的字符出现次数private int[] key = new int[26];public Cnt(String str) { // 计算字符串str的字符出现次数 并保存for (int i = 0; i < str.length(); i++) {key[str.charAt(i) - 'a']++;}}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Cnt cnt = (Cnt) o;return Arrays.equals(key, cnt.key);}@Overridepublic int hashCode() { // 以统计数组key作为本对象生成的hashCodereturn Arrays.hashCode(key);}}
}
207. 课程表
题目链接
207. 课程表
标签
深度优先搜索 广度优先搜索 图 拓扑排序
思路
要做本题需要对 图论 有一定的了解:
- 节点:图中的一个点。
- 边:连通一个点到另一个点。对于 有向图 来说,指向别的节点的节点称为 始点,被指向的节点称为 终点。
- 入度:对于一个节点来说,它的入度就是它作为 终点 的次数。

例如对于上面这个有向图,有以下的结论:
节点1的入度为0
节点2的入度为1
节点3的入度为1
节点4的入度为1
节点5的入度为1
节点6的入度为1
节点7的入度为1
节点8的入度为1
节点9的入度为1
节点10的入度为4
节点11的入度为1
本题很像 图的拓扑排序:入度越小,越靠前。在排序之前,先将所有入度为0的节点加入 队列,然后将队列中的节点移出队列,并把节点所指向的节点的入度减一,当某个节点的入度被减到0时,将它加入队列,重复这样的操作,直到队列为空。如果需要返回拓扑排序的结果,则在将节点移出队列时将其加入到结果链表中即可。
回到本题上,要使用拓扑排序得先构建图,并获取图中每个节点的入度,然后才能进行拓扑排序,在拓扑排序的时候记录移出队列的节点数,如果最终这个数字与图中的节点数不一致,则返回false,否则返回true。
图实际上就是一堆边和一堆节点的集合,不过本题解不使用这样的集合,而是将图理解为一堆节点连接的一堆节点,即为List<List<Integer>>结构,外层的List包含了所有的节点,内层的List包含的这个节点指向的所有节点。在构建图时,获取图中的每条边,将边的终点加入 边的始点所指向的节点集合 中。
获取图中每个节点的入度很简单,只需要在构建图时,对于每条边,将终点的入度加一即可。
现在的问题就只剩下如何寻找边了,题目中提到prerequisites[i] = [a, b] 表示如果要学习课程 a 则 必须 先学习课程 b,这句话说明prerequisites[i]数组为图中的一条边,第一个元素为 终点,第二个元素为 始点。
代码
class Solution {public boolean canFinish(int numCourses, int[][] prerequisites) {// 初始化存储图的数据结构List<List<Integer>> graph = new ArrayList<>();for (int i = 0; i < numCourses; i++) {graph.add(new ArrayList<>());}// 统计每个节点的入度,并构建图int[] inDegree = new int[numCourses]; // 存储每个节点的入度for (int[] pair : prerequisites) {int start = pair[1]; // 始点int end = pair[0]; // 终点List<Integer> toList = graph.get(start); // 获取 始点的 指向节点集合toList.add(end); // 将 终点 加入 始点的 指向节点集合 中inDegree[end]++; // 让终点的入度加一}// 寻找入度为0的节点,初始化队列LinkedList<Integer> queue = new LinkedList<>();for (int i = 0; i < inDegree.length; i++) {if (inDegree[i] == 0) { // 如果索引为i的节点的入度为0queue.offer(i); // 则将索引i放入队列}}// 拓扑排序int cnt = 0; // 统计移出队列的节点while (!queue.isEmpty()) { // 直到队列为空才退出循环cnt++;int start = queue.poll(); // 将节点移出队列,获取始点在graph中的索引List<Integer> toList = graph.get(start); // 获取始点指向的所有终点的索引for (int end : toList) { // 将始点指向的所有终点的入度减一if (--inDegree[end] == 0) { // 当终点的入度减到0时queue.offer(end); // 将其加入队列}}}return cnt == numCourses; // 返回移出队列的节点数 是否等于 节点总数}
}
相关文章:
LeetCode 744, 49, 207
目录 744. 寻找比目标字母大的最小字母题目链接标签思路代码 49. 字母异位词分组题目链接标签思路代码 207. 课程表题目链接标签思路代码 744. 寻找比目标字母大的最小字母 题目链接 744. 寻找比目标字母大的最小字母 标签 数组 二分查找 思路 本题比 基础二分查找 难的一…...
【AI资讯】可以媲美GPT-SoVITS的低显存开源文本转语音模型Fish Speech
Fish Speech是一款由fishaudio开发的全新文本转语音工具,支持中英日三种语言,语音处理接近人类水平,使用Flash-Attn算法处理大规模数据,提供高效、准确、稳定的TTS体验。 Fish Audio...

微服务数据流的协同:Eureka与Spring Cloud Data Flow集成指南
微服务数据流的协同:Eureka与Spring Cloud Data Flow集成指南 在构建基于Spring Cloud的微服务架构时,服务发现和数据流处理是两个关键的组成部分。Eureka作为服务发现工具,而Spring Cloud Data Flow提供了数据流处理的能力。本文将详细介绍…...

java生成json格式文件(包含缩进等格式)
生成json文件的同时保留原json格式,拥有良好的格式(如缩进等),提供友善阅读支持。 pom.xml依赖增加: <dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactI…...

Python面试题:如何在 Python 中读取和写入 JSON 文件?
在 Python 中读取和写入 JSON 文件可以使用 json 模块。以下是具体的示例,展示了如何读取和写入 JSON 文件。 读取 JSON 文件 要读取 JSON 文件,可以使用 json.load() 方法。下面是一个示例代码: import json# 假设有一个名为 data.json 的…...

FlutterWeb渲染模式及提速
背景 在使用Flutter Web开发的网站过程中,常常会遇到不同浏览器之间的兼容性问题。例如,在Google浏览器中动画和交互都非常流畅,但在360浏览器中却会出现卡顿现象;在Google浏览器中动态设置图标颜色正常显示,而在Safa…...

群体优化算法----化学反应优化算法介绍,解决蛋白质-配体对接问题示例
介绍 化学反应优化算法(Chemical Reaction Optimization, CRO)是一种新兴的基于自然现象的元启发式算法,受化学反应过程中分子碰撞和反应机制的启发而设计。CRO算法模拟了分子在化学反应过程中通过能量转换和分子间相互作用来寻找稳定结构的…...

Go语言如何入门,有哪些书推荐?
Go 语言之所以如此受欢迎,其编译器功不可没。Go 语言的发展也得益于其编译速度够快。 对开发者来说,更快的编译速度意味着更短的反馈周期。大型的 Go 应用程序总是能在几秒钟之 内完成编译。而当使用 go run编译和执行小型的 Go 应用程序时,其…...
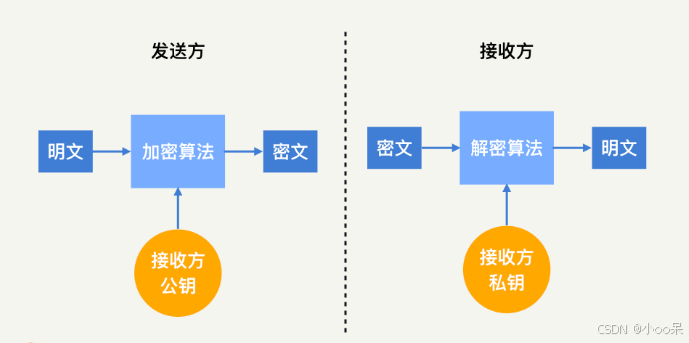
【密码学】密码学体系
密码学体系是信息安全领域的基石,它主要分为两大类:对称密码体制和非对称密码体制。 一、对称密码体制(Symmetric Cryptography) 在对称密码体制中,加密和解密使用相同的密钥。这意味着发送方和接收方都必须事先拥有这…...

Bean的管理
1.主动获取Bean spring项目在需要时,会自动从IOC容器中获取需要的Bean 我们也可以自己主动的得到Bean对象 (1)获取bean对象,首先获取SpringIOC对象 private ApplicationContext applicationContext //IOC容器对象 (2 )方法…...
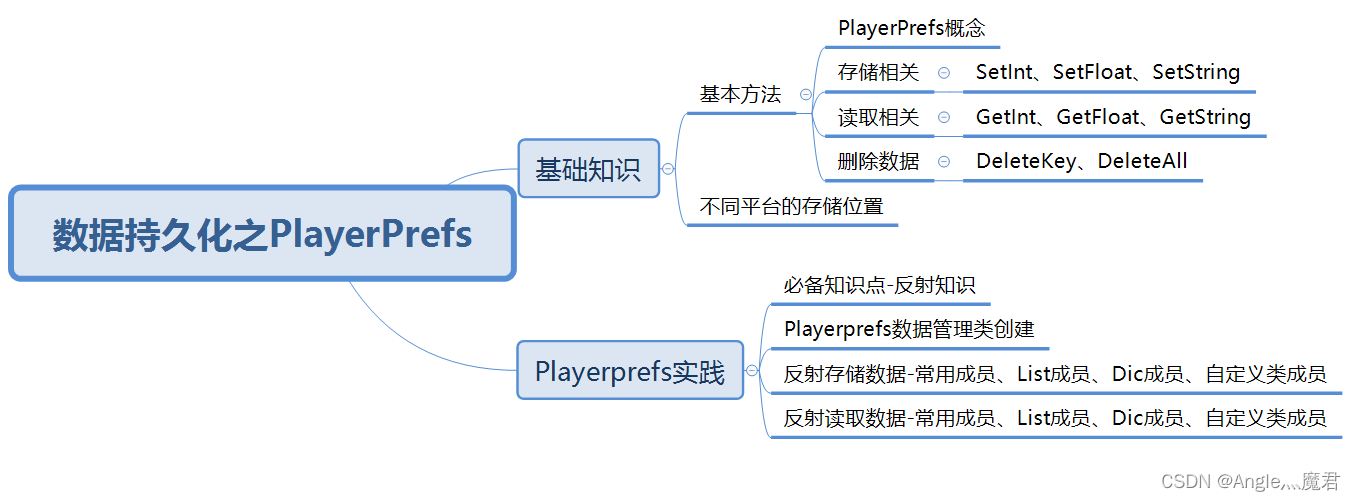
Unity 数据持久化【PlayerPrefs】
1、数据持久化 文章目录 1、数据持久化PlayerPrefs基本方法1、PlayerPrefs概念2、存储相关3、读取相关4、删除数据思考 信息的存储和读取 PlayerPrefs存储位置1、PlayerPrefs存储的数据在哪个位置2、PlayerPrefs 数据唯一性思考 排行榜功能 2、Playerprefs实践1、必备知识点-反…...
linux-虚拟内存-虚拟cpu
1、进程: 计算机中的程序关于某数据集合上的一次运行活动。 狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。广义定义:进程是一个具有一定独立功能的程序关于某个…...
某某市信息科技学业水平测试软件打开加载失败逆向分析(笔记)
引言:笔者在工作过程中,用户上报某某市信息科技学业水平测试软件在云电脑上打开初始化的情况下出现了加载和绑定机器失败的问题。一般情况下,在实体机上用户进行登录后,用户的账号信息跟主机的机器码进行绑定然后保存到配置文件&a…...
vue3+antd 实现点击按钮弹出对话框
格式1:确认对话框 按钮: 点击按钮之后: 完整代码: <template><div><a-button click"showConfirm">Confirm</a-button></div> </template> <script setup> import {Mod…...

Python一些可能用的到的函数系列130 UCS-Time Brick
说明 UCS对象是基于GFGoLite进行封装,且侧重于实现UCS规范。 内容 1 函数 我发现pydantic真是一个特别好用的东西,可以确保在数据传递时的可靠,以及对某个数据模型的描述。 以下,UCS给出了id、time相关的brick映射࿰…...

Java实现布隆过滤器的几种方式
布隆过滤器应用场景: 为预防大量黑客故意发起非法的时间查询请求,造成缓存击穿,建议采用布隆过滤器的方法解决。布隆过滤器通过一个很长的二进制向量和一系列随机映射函数(哈希函数)来记录与识别某个数据是否在一个集合中。如果数据不在集合中,能被识别出来,不需要到数…...
最新整理的机器人相关数据合集(1993-2022年不等 具体看数据类型)
机器人安装数据是指记录全球或特定区域内工业机器人新安装数量的信息,这一数据由国际机器人联合会(IFR)等权威机构定期发布。这些数据不仅揭示了机器人技术的市场需求趋势,还反映了各国和地区自动化水平及产业升级的步伐。例如,数据显示中国在…...
Python打开Excel文档并读取数据
Python 版本 目前 Python 3 版本为主流版本,这里测试的版本是:Python 3.10.5。 常用库说明 Python 操作 Excel 的常用库有:xlrd、xlwt、xlutils、openpyxl、pandas。这里主要说明下 Excel 文档 .xls 格式和 .xlsx 格式的文档打开和读取。 …...
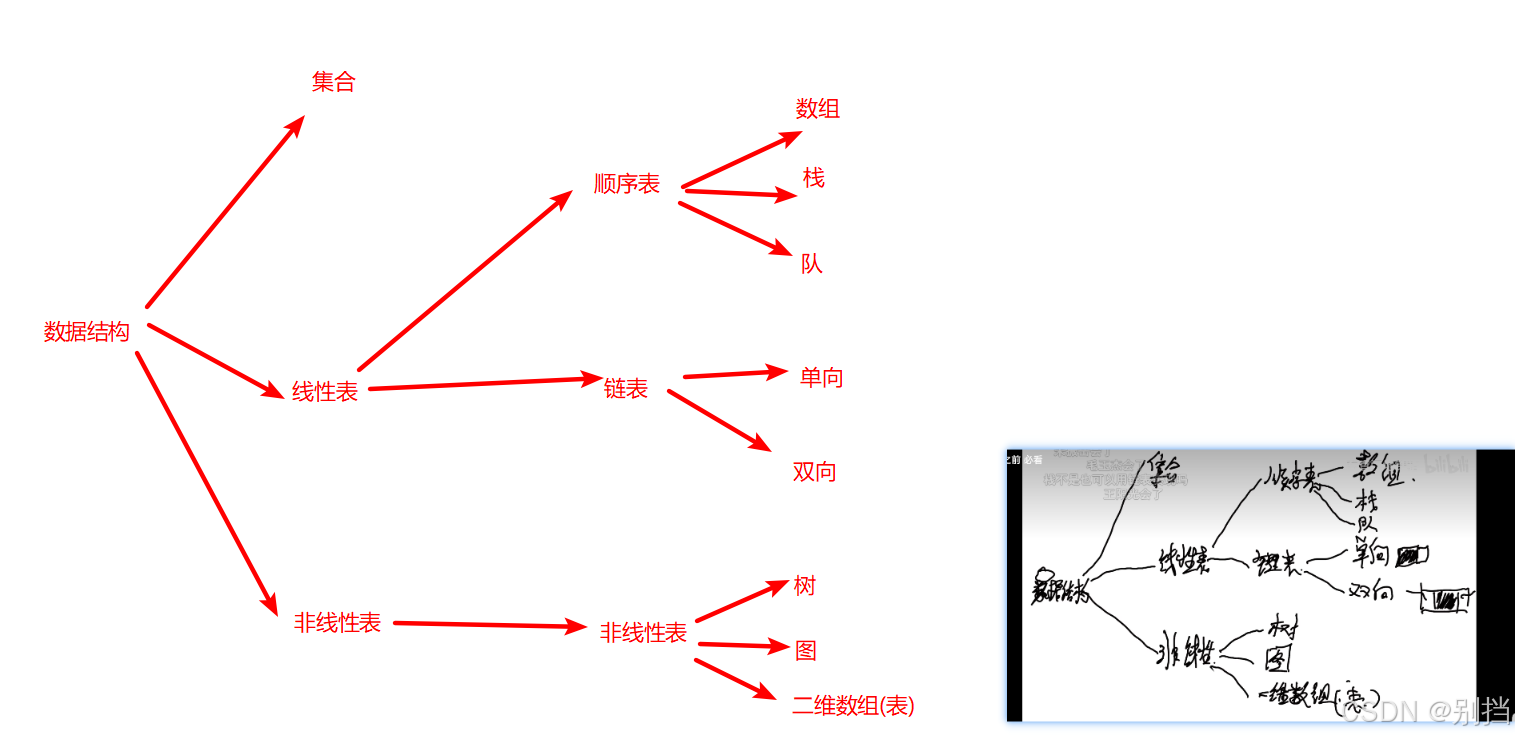
算法day03 桶排序 数据结构分类 时间复杂度 异或运算
学数据结构之前 必看_哔哩哔哩_bilibili 1.认识复杂度和简单排序算法_哔哩哔哩_bilibili 桶排序(Bucket sort)------时间复杂度为O(n)的排序方法(一)_多桶排序时间复杂度-CSDN博客 桶排序 测试场景:数组中有10000个随…...

k8s学习之cobra命令库学习
1.前言 打开k8s代码的时候,我发现基本上那几个核心服务都是使用cobra库作为命令行处理的能力。因此,为了对代码之后的代码学习的有比较深入的理解,因此先基于这个库写个demo,加深对这个库的一些理解吧 2.cobra库的基本简介 Git…...

暗黑破坏神2存档编辑器:3分钟学会可视化存档修改
暗黑破坏神2存档编辑器:3分钟学会可视化存档修改 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为复杂的十六进制编辑而烦恼吗?d2s-editor 是一款专为《暗黑破坏神2》玩家设计的 Web 存档编辑器&…...

Qwen3-ForcedAligner-0.6B与LaTeX的学术工作流整合
Qwen3-ForcedAligner-0.6B与LaTeX的学术工作流整合 1. 引言 学术研究过程中,我们经常需要处理大量的访谈录音、讲座内容或实验讨论。传统的手工转录不仅耗时耗力,更让人头疼的是如何在最终论文中精准引用特定时间点的对话内容。想象一下,你…...

HoRain云--Bootstrap5图像形状全攻略
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

Llama-3.2V-11B-cot效果展示:识别艺术海报中风格与主题逻辑断层
Llama-3.2V-11B-cot效果展示:识别艺术海报中风格与主题逻辑断层 1. 工具介绍 Llama-3.2V-11B-cot是基于Meta Llama-3.2V-11B-cot多模态大模型开发的高性能视觉推理工具。该工具针对双卡4090环境进行了深度优化,特别适合需要分析复杂视觉内容的场景&…...

Qwen3-1.7B能做什么?实测写邮件、生成故事、智能聊天
Qwen3-1.7B能做什么?实测写邮件、生成故事、智能聊天 1. 认识Qwen3-1.7B Qwen3(千问3)是阿里巴巴集团开源的新一代通义千问大语言模型系列中的一员,1.7B版本虽然参数量不大,但在日常应用中表现出色。这个17亿参数的模…...

从新手小白到资深开发者:GISBox与QGIS如何适配你的成长路径?
随着地理信息技术的加速演进,工具选型已成为提升空间数据处理效率的关键环节。本文立足于产品定位、功能体系与目标用户三大核心维度,系统梳理GISBox与QGIS的差异化特征,旨在为教育、科研、企业及个人开发者提供清晰、务实的工具决策依据。 …...

qt模块学习记录
qt模块学习记录一、Qt Core其他模块都用到的核心非图形类二、Qt GUI 设计 GUI 界面的基础类,包括 OpenGL三、功能模块Qt Network 使网络编程更简单和轻便的类Qt SQL 使用 SQL 用于数据库操作的类Qt Multimedia 音频、视频、摄像头和广播功能的类四、老式界面Qt Widg…...

从单片机到Linux驱动的技术成长与转型
1. 从单片机到Linux驱动的技术成长之路 刚毕业那会儿,我和大多数电子工程专业的同学一样,怀揣着对技术的无限憧憬。记得大四校招时,我固执地只投递了几家知名大厂的嵌入式开发岗位,甚至在面试时直接报出了远超应届生水平的薪资期望…...

golang.org/x/net WebSocket开发完全手册:实现实时双向通信
golang.org/x/net WebSocket开发完全手册:实现实时双向通信 【免费下载链接】net [mirror] Go supplementary network libraries 项目地址: https://gitcode.com/gh_mirrors/ne/net 在现代Web应用开发中,实时双向通信已成为提升用户体验的关键技术…...

嵌入式系统栈溢出问题分析与防护实践
1. 栈溢出问题现象与初步分析最近在调试一个嵌入式系统时,遇到了一个非常典型的栈溢出问题。现象很简单:一个局部变量status的值莫名其妙地从0x01变成了其他值。最诡异的是,在两次打印status之间,代码并没有直接修改这个变量。简化…...