【数据分析】Pandas_DataFrame读写详解:案例解析(第24天)
系列文章目录
一、 读写文件数据
二、df查询数据操作
三、df增加列操作
四、df删除行列操作
五、df数据去重操作
六、df数据修改操作
文章目录
- 系列文章目录
- 前言
- 一、 读写文件数据
- 1.1 读写excel文件
- 1.2 读写csv文件
- 1.3 读写mysql数据库
- 二、df查询数据操作
- 2.1 查询df子集基本方法
- 2.2 loc/iloc获取子集
- 2.2.1 loc/iloc基本介绍
- 2.2.2 loc属性获取子集
- 2.2.3 iloc属性获取子集
- 2.3 query函数获取子集
- 2.4 isin函数获取子集
- 三、df增加列操作
- 四、df删除行列操作
- 五、df数据去重操作
- 六、df数据修改操作
- 6.1 直接修改数据
- 6.2 replace函数修改
- 6.3 s对象通过apply函数执行自定义函数
- 6.4 df对象通过apply函数执行自定义函数
- 6.5 df对象通过applymap函数执行自定义函数
前言
本文主要详解了Pandas_DataFrame的读写。
提示:以下是本篇文章正文内容,下面案例可供参考
一、 读写文件数据
可以参考pandas的官网文档
https://pandas.pydata.org/
1.1 读写excel文件
-
数据保存到excel文件
# 导入模块 import pandas as pd # 构造数据集 data = [[1,'张三', '1990-10-02', 34],[2, '李四', '2000-03-03', 24],[3, '王五', '2005-12-23', 19],[4, '隔壁老王', '1982-11-12',42]] df = pd.DataFrame(data=data, columns=['id', 'name', 'birthday', 'age']) df # 存储路径 # sheet名称 # 是否存储行索引作为一列 # 是否存储列名 df.to_excel('./output/student.xls', sheet_name='student',index=True, header=True) -
读取excel文件数据
df_excel = pd.read_excel('output/student.xls') df_excel # 通过index_col指定某列的值作为行索引, 可以写列名或列下标值 # pd.read_excel('output/student.xls',index_col='id') pd.read_excel('output/student.xls',index_col=0)
1.2 读写csv文件
-
数据保存到csv(逗号,分隔符)/tsv(制表符
\t分隔符)文件中# 参数1:存储路径 # index:是否存储行索引值 # mode:存储的方式 df.to_csv('output/student.csv', index=False, mode='w') # 存储到tsv文件中 \t # sep:指定列值之间的分隔符 df.to_csv('output/student.tsv', sep='\t') -
读取csv/tsv文件数据
df_csv = pd.read_csv('output/student.csv') df_csv # parse_dates: 将指定的列转换成日期时间类型, 可以传入列名或列下标值 # temp_df = pd.read_csv('output/student.csv', parse_dates=['birthday']) # temp_df = pd.read_csv('output/student.csv', parse_dates=[2]) # parse_dates: 可以传入True或False, 将行索引值转换成日期时间类型, 需要和行索引值进行结合使用 temp_df = pd.read_csv('output/student.csv',index_col='birthday' ,parse_dates=True) temp_df.info() # 读取tsv文件数据 pd.read_csv('output/student.tsv', sep='\t', index_col=0)
1.3 读写mysql数据库
-
保存数据到mysql数据库
from sqlalchemy import create_engine # 创建数据库链接对象 engine = create_engine('mysql+pymysql://root:123456@192.168.88.100:3306/BI_db') # name:表名, 表不存在会自动创建 # con:数据库链接对象 # index:是否存储行索引 # if_exists:存储方式, append:追加写 replace:覆盖写 df.to_sql(name='student', con=engine, index=False, if_exists='append') -
读取mysql数据库数据
# sql:可以读取表名, 也可以读取sql语句 # columns: 指定读取表中的字段 df_mysql = pd.read_sql(sql='student', con=engine, columns=['name', 'birthday']) df_mysql # 读取sql语句 pd.read_sql(sql='select * from student limit 2', con=engine) # 只能读取sql语句 pd.read_sql_query(sql='select * from student limit 2;',con=engine) # 只能读取表名 pd.read_sql_table(table_name='student', con=engine)
二、df查询数据操作
2.1 查询df子集基本方法
-
head()&tail()
import pandas as pd # 加载数据集, 链家租房数据集 df = pd.read_csv('data/LJdata.csv') df df.head() df.tail() df.head(n=8) -
获取一列或多列数据
# df[列名]或df.列名 # 获取一列数据, 返回s对象 df['价格'] type(df['价格']) df.价格 # 获取一列数据, 返回df对象 df[['价格']] # 获取多列数据 df[[列名1, 列名2, ...]] # 传入列名的列表 df[['区域', '面积', '价格']] -
布尔值向量获取行数据
# 布尔值s对象 df['价格']>8000 df[df['价格']>8000] # 布尔值列表 df_head = df.head() df_head # 构建布尔值列表 bool_list = [True,False,True,False,True] df_head[bool_list] # 布尔值数组 import numpy as np n1 = np.array([True,False,True,False,True]) n1 df_head[n1] -
行索引下标切片获取行数据
# df[起始行下标值:结束行下标值:步长] 类似于字符串/列表/元组的切片操作 # 下标值(只能是整数)和索引值(整数,字符串,日期时间)不是一个东西 # 左闭右开 -> 包含起始值, 不包含结束值 temp_df = df.head(10) temp_df # 获取1,3,5行数据 temp_df[:5:2] # 获取前3行数据 temp_df[:3] # 步长为负数, 倒序获取行数据, 下标值可以为负数 temp_df[-1:-3:-1]
2.2 loc/iloc获取子集
2.2.1 loc/iloc基本介绍
loc和iloc是s/df对象的属性
loc是通过索引值(肉眼看到的值), iloc是通过索引下标值(0,1,2,3…) 获取数据
df.loc[行索引值] -> 获取行数据
df.loc[行索引值, 列名] -> 获取行列数据
df.iloc[行索引下标] -> 获取行数据
df.iloc[行索引下标, 列名下标] -> 获取行列数据
2.2.2 loc属性获取子集
# 获取一行数据 df[行索引值]
# 获取第5行数据, 返回s对象
temp_df.loc[4]
# 获取第5行数据, 返回df对象
temp_df.loc[[4]]
# 获取多行数据 df[[行索引值1, 行索引值2, ...]]
# 获取第1, 3, 5行数据
temp_df.loc[[0, 2, 4]]
# 行索引值切片获取行数据
# df.loc[起始索引值:结束索引值:步长]
# 左闭右闭 -> 包含起始值, 包含结束值
# 获取第2,3,4行数据
temp_df.loc[1:3]
# 根据索引下标值
temp_df[1:3]
# 隔一行获取一行数据
temp_df.loc[::2]
# 倒序获取子集, 起始值和结束值要反过来, 步长为负数
temp_df.loc[8:2:-1]
# 布尔值向量获取行数据 df.loc[布尔值向量]
temp_df['朝向']=='南'
temp_df.loc[temp_df['朝向']=='南']
# 布尔值向量结合列名获取行列数据 df.loc[布尔值向量, [列名1, 列名2, ...]]
temp_df.loc[temp_df['朝向']=='南', ['地址', '朝向']]
# 行索引值结合列名获取行列数据 df.loc[[行索引值1, 行索引值2,...],[列名1, 列名2, ...]]
# 获取某个值数据
temp_df.loc[0, '价格']
# 获取多行多列数据
temp_df.loc[[0, 2, 4], ['地址', '户型', '价格']]
# 行索引值切片结合列名获取行列数据 df.loc[起始索引值:结束索引值:步长, [列名1, 列名2, ...]]
temp_df.loc[:4:2, ['地址', '面积', '价格']]
2.2.3 iloc属性获取子集
# 获取一行数据 df.iloc[行下标值]
# 获取第一行数据, 返回s对象
temp_df.iloc[0]
temp_df.iloc[[0]]
# 获取最后一行数据
temp_df.iloc[-1]
# 获取多行数据 df.iloc[[行下标1, 行下标2, ...]]
temp_df.iloc[[0, 2, 4]]
# 行下标切片获取多行数据 df.iloc[起始下标值:结束下标值:步长] 等同于 df[起始下标值:结束下标值:步长]
# 左闭右开
temp_df.iloc[:5:2]
temp_df[:5:2]
# 行列下标切片获取子集 df.iloc[起始下标值:结束下标值:步长, 起始列下标值:结束列下标值:步长]
# 获取1,3,5行, 并且获取地址,面积和朝向列
temp_df.iloc[:5:2, 1:6:2]
# 行下标切片和列下标值获取子集 df.iloc[起始下标值:结束下标值:步长, [列下标1, 列下标2, ...]]
# 获取1,3,5行, 并且获取地址,面积和朝向列
temp_df.iloc[:5:2, [1, 3, 5]]
# 行列下标值获取子集 df.iloc[[行下标值1, 行下标值2, ...], [列下标值1, 列下标值2, ...]]
# 获取1,3,5行, 并且获取地址,面积和朝向列
temp_df.iloc[[0, 2, 4], [1, 3, 5]]
# 行下标值和列下标切片获取子集 df.iloc[[行下标值1, 行下标值2, ...], 起始列下标值:结束列下标值:步长]
# 获取1,3,5行, 并且获取地址,面积和朝向列
temp_df.iloc[[0,2,4],1:6:2]
2.3 query函数获取子集
# df.query(判断表达式) -> 判断表达式和df[布尔值向量]相同
# 获取区域列中为 望京租房 的数据
temp_df['区域'] == '望京租房'
temp_df[temp_df['区域'] == '望京租房']
# sql语句 select * from 表a where 区域 == "望京租房"
temp_df.query('区域 == "望京租房"')
# 判断表达式中有多个判断条件, 可以使用 and(&)或or(|)
# 查询租房区域为望京、天通苑、回龙观并且朝向为东、南的房源数据
# 链式调用, query函数返回新的df, 新的df继续可以调用query()
temp_df.query('区域 in ("望京租房", "天通苑租房", "回龙观租房")').query('朝向 in ("东", "南")')
temp_df.query('(区域 in ("望京租房", "天通苑租房", "回龙观租房")) & (朝向 in ("东", "南"))')
# temp_df.query('(区域 in ("望京租房", "天通苑租房", "回龙观租房")) and (朝向 in ("东", "南"))')temp_df[((temp_df["区域"]=='望京租房') | (temp_df['区域']=='天通苑租房') | (temp_df['区域']=='回龙观租房')) & ((temp_df['朝向']=='东') | (temp_df['朝向']=='南'))]
2.4 isin函数获取子集
# 判断s或df对象中的数据值是否在values列表中, 如果在返回True, 否则返回False -> s/df.isin(values=[值1, 值2, ...])
# 返回一个布尔值构成的df对象
temp_df.isin(values=['2室1厅','东'])
temp_df[temp_df.isin(values=['2室1厅','东'])]
# 返回布尔值构成的s对象
temp_df['区域'].isin(values=["望京租房", "天通苑租房", "回龙观租房"])
temp_df['区域'][temp_df['区域'].isin(values=["望京租房", "天通苑租房", "回龙观租房"])]
temp_df[temp_df['区域'].isin(values=["望京租房", "天通苑租房", "回龙观租房"])]
# 查询租房区域为望京、天通苑、回龙观并且朝向为东、南的房源数据
temp_df['区域'].isin(values=["望京租房", "天通苑租房", "回龙观租房"]) & temp_df['朝向'].isin(values=['东', '南'])
temp_df[(temp_df['区域'].isin(values=["望京租房", "天通苑租房", "回龙观租房"])) & (temp_df['朝向'].isin(values=['东', '南']))]
三、df增加列操作
# 导入模块
import pandas as pd
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
# 加载数据集
df = pd.read_csv('data/LJdata.csv')
# 获取前5行数据
temp_df = df.head().copy()
temp_df
# 在df末尾增加新列数据 df['新列名'] = 常数值/列表/series对象
# 在df末尾新增一列省份列, 值都为北京 -> 常数值
temp_df['省份'] = '北京'
temp_df
# 在df末尾新增一列区县列, 值为['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区'] -> 列表
# df的行数要和新增列表中的元素个数要相等
temp_df['区县'] = ['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区']
temp_df
# 在df末尾新增一列新价格列, 在原价格上加1000 -> series对象 (s对象的运算)
temp_df['新价格'] = temp_df['价格'] + 1000
temp_df
# 通过insert()在指定位置新增一列
# df.insert(loc=列下标值, column=新列名, value=常数值/列表/s对象)
# 在区域和地址列之间新增一列国家列, 值都为中国
temp_df.insert(loc=1, column='国家', value='中国')
temp_df
# 在价格新增一列价格2列, 值为 价格和新价格的求和
temp_df.insert(loc=6, column='价格2', value=temp_df['价格'] + temp_df['新价格'])
temp_df
四、df删除行列操作
# df.drop(labels=, axis=, inplace=)
# labels: 根据 行索引值或列名 进行删除
# axis: 按行或列删除, 默认是按行 0或index; 按列 1或columns
# inplace: 是否在源数据集上删除, 默认是False, True
# 删除第1, 3, 5行数据, 默认删除行数据
drop_df = temp_df.drop(labels=[0, 2, 4])
drop_df
# 删除价格2列数据
temp_df.drop(labels='价格2', axis='columns')
# 在源df上删除价格2列数据
temp_df.drop(labels='价格2', axis=1, inplace=True)
# 保留地址, 户型, 面积三列数据
temp_df[['地址', '户型', '面积']]
五、df数据去重操作
# s/df.drop_duplicates(subset=,keep=,inplace=)
# subset: 默认不写, 所有列值都相同的行数据; 可以通过列名列表指定对应列相同的行数据
# keep: 默认保留第一条数据 first, 保留最后一条数据 last, 删除所有重复数据 false
# inplace: 是否在源数据集上修改
# 根据所有列相同的行数据进行去重
temp_df.drop_duplicates()
# 根据户型和朝向列判断是否有重复行数据
# 默认保留第一条重复数据
temp_df.drop_duplicates(subset=['户型', '朝向'])
# 保留最后一条重复数据
temp_df.drop_duplicates(subset=['户型', '朝向'], keep='last')
# 删除重复的数据
temp_df['朝向'].drop_duplicates(keep=False)
# df对象没有unique操作
temp_df['朝向'].unique() # 返回数组
temp_df['朝向'].nunique() # 去重计数 count(distinct)
六、df数据修改操作
6.1 直接修改数据
# 直接修改数据值 df[列名] = 新值 -> 常数值/列表/s对象
temp_df = df.head().copy()
temp_df
# 修改看房人数列, 改为 100
temp_df['看房人数'] = 100
temp_df
# 修改面积列, 改为 [70, 99, 90, 120, 80] -> df的行数和列表中的元素个数相同
temp_df['面积'] = [70, 99, 90, 120, 80]
temp_df
# 修改价格列, 价格列+1000
temp_df['价格'] = temp_df['价格'] + 1000
temp_df
# 获取s对象
temp_s = temp_df['价格']
temp_s# s[索引下标值] = 新值
temp_s[2] = 20000
temp_s
6.2 replace函数修改
# 通过replace函数实现修改
# s/df.replace(to_replace=, value=, inplace=)
# to_replace:需要替换的值
# value:替换后的值
# 将2室1厅替换成3室2厅
temp_df.replace(to_replace='2室1厅', value='3室2厅', inplace=True)
temp_df
temp_df.replace(to_replace=[20000, 100], value=999)
# 对s对象实现替换操作
temp_df['朝向'].replace(to_replace='东南', value='北')
6.3 s对象通过apply函数执行自定义函数
temp_df = df.head().copy()
temp_df
# 编写自定义函数 根据区域列的值判断是否为天通苑租房, 是返回昌平区, 否返回其他区
# 最少接受一个形参, 形参对应的实参值是s对象中每个值
def func1(x):print('x的值是->',x)if x == '天通苑租房':return '昌平区'else:return '其他区'
# 通过apply函数调用自定义函数 s/df.apply(自定义函数名)
temp_df['区域'] = temp_df['区域'].apply(func1)
temp_df
temp_df = df.head().copy()
temp_df
# 定义自定义函数式, 可以定义多个形参
def func2(x, arg1, arg2):
# print('x的值是->', x)
# print('arg1的值是->', arg1)
# print('arg2的值是->', arg2)if x == '天通苑租房':return arg1else:return arg2
# s对象调用自定义函数
# args=(arg1, arg2)
temp_df['区域'].apply(func2, args=('昌平区', '其他区'))
# 形参名=实参值
temp_df['区域'].apply(func2, arg1='昌平区', arg2='其他区')
6.4 df对象通过apply函数执行自定义函数
-
按列计算
# df对象调用apply函数来执行自定义函数 # 自定义函数接收的是df中一列或一行数据 # 定义自定义函数 def func3(x, arg1):# x是df中一行或一列数据 -> s对象print('x的值是->', x)print('arg1的值是->', arg1)print(x.__dict__)# _name:获取当前列的列名, 或者是获取当前行的行索引值if x._name == '价格':# s对象和数值型变量计算return x + arg1else:return x# 默认是按列进行处理 axis=0 # temp_df.apply(func3, args=(1000,), axis=0) temp_df.apply(func3, arg1 = 2000, axis=0) -
按行计算
# 如果区域列的值为望京租房, 修改价格列的值为arg1 # 自定义函数 def func4(x, arg1):print('x的值是->', x)# 根据s对象的索引值获取数据值 s[索引值]if x['区域']== '望京租房':x['价格'] = arg1return xelse:return x# 按行进行处理, axis=1 temp_df.apply(func4, arg1=3000, axis=1)
6.5 df对象通过applymap函数执行自定义函数
# df对象调用applymap函数来执行自定义函数
# 自定义函数中接收的是df中每个值, 不再是一列或一行数据
# 自定义函数
def func5(x):print('x的值是->', x)if x in ['燕莎租房','望京租房','团结湖租房']:return '朝阳区'elif x == '天通苑租房':return '昌平区'elif x == '团结湖租房':return '西城区'else:return xtemp_df.applymap(func5)

相关文章:
【数据分析】Pandas_DataFrame读写详解:案例解析(第24天)
系列文章目录 一、 读写文件数据 二、df查询数据操作 三、df增加列操作 四、df删除行列操作 五、df数据去重操作 六、df数据修改操作 文章目录 系列文章目录前言一、 读写文件数据1.1 读写excel文件1.2 读写csv文件1.3 读写mysql数据库 二、df查询数据操作2.1 查询df子集基本方…...

quill编辑器使用总结
一、vue-quill-editor 与 quill 若使用版本1.0,这两个组件使用哪个都是一样的,无非代码有点偏差;若需要使用表格功能,必须使用 quill2.0 版本,因为 vue-quill-editor 不支持table功能。 二、webpack版本问题 在使用 q…...

快手矩阵管理系统:引领短视频运营新潮流
在短视频行业蓬勃发展的今天,如何高效运营和优化内容创作已成为企业和创作者关注的焦点。快手矩阵管理系统以其强大的核心功能,为短视频内容的创作、发布和管理提供了一站式解决方案。 智能创作:AI自动生成文案 快手矩阵管理系统的智能创作…...

文心一言:探索AI写作的新境界
在人工智能飞速发展的今天,AI写作助手已经成为许多写作者、内容创作者和营销专家的重要工具。"文心一言"作为一个先进的AI写作平台,以其强大的语言理解和生成能力,为用户提供了从文本生成到编辑、优化等一系列服务。本文将介绍如何…...
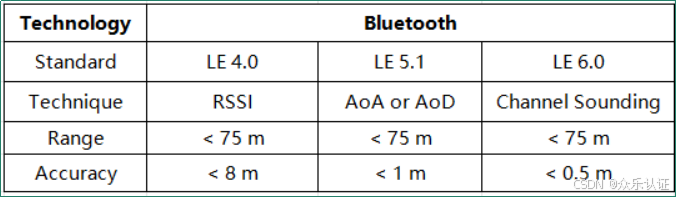
认证资讯|Bluetooth SIG认证
在当今高度互联的世界中,无线技术的普及已经成为我们生活和工作中不可或缺的一部分。作为领先的无线通信技术之一,Bluetooth技术以其稳定性、便捷性和广泛的应用场景而备受青睐。然而,要想在激烈的市场竞争中脱颖而出,获得Bluetoo…...

我国静止无功发生器(SVG)市场规模逐渐扩大 高压SVG为主流产品
我国静止无功发生器(SVG)市场规模逐渐扩大 高压SVG为主流产品 静止无功发生器(SVG)又称为静止同步补偿器、先进静止补偿器、静止调相机等,是利用全控型功率器件组成的桥式变流器来实现动态无功调节的一种先进无功自动补…...
【漏洞复现】用友U8 CRM downloadfile 任意文件读取漏洞
0x01 产品简介 用友U8 CRM客户关系管理系统是一款专业的企业级CRM软件,旨在帮助企业高效管理客户关系、提升销售业绩和提供优质的客户服务。 0x02 漏洞概述 用友 U8 CRM客户关系管理系统 /pub/downloadfile.php接囗处存在任意文件读取漏洞,未经身份验证的远程攻击…...

计算机网络 | 期末复习
物理层: 奈氏准则:带宽(w Hz),在不考虑噪音的情况下,最大速率(2W)码元/秒 信噪比S/N:以分贝(dB)为度量单位。信噪比(dB)…...

动手实操微软开源的GraphRAG
微软在今年4月份的时候提出了GraphRAG的概念,然后在上周开源了GraphRAG,Github链接见https://github.com/microsoft/graphrag,截止当前,已有6900Star。 安装教程 官方推荐使用Python3.10-3.12版本,我使用Python3.10版本安装时,在…...
【网络安全】实验七(ISA防火墙的规则设置)
一、实验目的 二、配置环境 打开两台虚拟机,并参照下图,搭建网络拓扑环境,要求两台虚拟机的IP地址要按照图中的标识进行设置,并根据搭建完成情况,勾选对应选项。注:此处的学号本人学号的最后两位数字&…...

实验代码结构介绍
提高模型复用性,让模型对应的配置更加清晰,代码书写条理 学习自https://zhuanlan.zhihu.com/p/409662511 Project ├── checkpoints # 存放模型 ├── data # 定义各种用于训练测试的数据集 ├── eval.py # 测试代码 ├── loss.py # 定义的…...

Java多线程不会?一文解决——
方法一 新建类如MyThread继承Thread类重写run()方法再通过new MyThread类来新建线程通过start方法启动新线程 案例: class MyThread extends Thread {public MyThread(String name) {super(name);}Overridepublic void run() {for(int i0;i<10;i){System.out.…...

Mac上pyenv的安装及使用
Mac上pyenv的安装及使用 安装 brew update brew install pyenv 报错 git -C /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core fetch --unshallowgit -C /usr/local/Homebrew/Library/Taps/homebrew/homebrew-cask fetch --unshallow那就执行这2句 还报错 git -C /…...

【SpringBoot】IDEA查看spring bean的依赖关系
前因:研究springcloud config组件时,我发现config-server包下的EnvironmentController不在扫描的包路径下却可以响应客户端的请求,这引起了我的注意,我的问题是:EnvironmentController是怎么被添加进bean工厂的。本章就…...

项目代码优化(1)——下单逻辑
给一个电商开发的系统排查,发现漏洞很多。很多经验不够的开发者很容易忽视的逻辑错误陷阱。在给一个项目做二次开发时候,检测到的相关经典案例。这里整理支付和产品相关的逻辑,方便后续查看。,这里进行一些简单的逻辑漏洞梳理与修…...

探索 WebKit 的缓存迷宫:深入理解其高效缓存机制
探索 WebKit 的缓存迷宫:深入理解其高效缓存机制 在当今快速变化的网络世界中,WebKit 作为领先的浏览器引擎之一,其缓存机制对于提升网页加载速度、减少服务器负载以及改善用户体验起着至关重要的作用。本文将深入探讨 WebKit 的缓存机制&am…...

JVM:介绍
文章目录 一、什么是JVM二、JVM的功能1、解释和运行2、内存管理3、即时编译 三、常见的JVM四、Java虚拟机规范五、HotSpot发展历程 一、什么是JVM JVM的全称为Java Virtual Machine,Java虚拟机。本质上是一个运行在计算机上的程序,职责是运行Java字节码…...

和鲸“101”计划领航!和鲸科技携手北中医,共话医学+AI 实验室建设及创新人才培养
为进一步加强医学院校大数据管理与应用、信息管理与信息系统,医学信息工程等专业建设,交流实验室建设、专业发展与人才培养经验,6 月 22 日,由北京中医药大学(简称“北中医”)主办,上海和今信息…...

Linux 网络抓包工具tcpdump编译
tcpdump 的编译步骤 1. 下载源代码 访问 tcpdump 的官方网站(如:http://www.tcpdump.org/)下载最新的源代码压缩包,如tcpdump-4.9.2.tar.gz(注意版本号可能会有所不同)。 2. 解压缩源代码 使用 tar 命令…...

『C++成长记』string模拟实现
🔥博客主页:小王又困了 📚系列专栏:C 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、存储结构 二、默认成员函数 📒2.1构造函数 📒2.…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...

Vue3 图片标框功能实现方案
基于 Vue3 组合式 API 的图片标框(画框、标注、选框)完整实现,核心逻辑封装在 GetBoxes 组件里,复制就能用 一、功能说明 ✅ 在图片上鼠标拖拽画矩形框 ✅ 实时显示框坐标(x, y, width, height) ✅ 支持多…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...