Python酷库之旅-第三方库Pandas(010)
目录
一、用法精讲
22、pandas.read_hdf函数
22-1、语法
22-2、参数
22-3、功能
22-4、返回值
22-5、说明
22-6、用法
22-6-1、数据准备
22-6-2、代码示例
22-6-3、结果输出
23、pandas.HDFStore.put方法
23-1、语法
23-2、参数
23-3、功能
23-4、返回值
23-5、说明
23-6、用法
23-6-1、数据准备
23-6-2、代码示例
23-6-3、结果输出
24、pandas.HDFStore.append方法
24-1、语法
24-2、参数
24-3、功能
24-4、返回值
24-5、说明
24-6、用法
24-6-1、数据准备
24-6-2、代码示例
24-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
22、pandas.read_hdf函数
22-1、语法
# 22、pandas.read_hdf函数
pandas.read_hdf(path_or_buf, key=None, mode='r', errors='strict', where=None, start=None, stop=None, columns=None, iterator=False, chunksize=None, **kwargs)
Read from the store, close it if we opened it.Retrieve pandas object stored in file, optionally based on where criteria.WarningPandas uses PyTables for reading and writing HDF5 files, which allows serializing object-dtype data with pickle when using the “fixed” format. Loading pickled data received from untrusted sources can be unsafe.See: https://docs.python.org/3/library/pickle.html for more.Parameters:
path_or_bufstr, path object, pandas.HDFStore
Any valid string path is acceptable. Only supports the local file system, remote URLs and file-like objects are not supported.If you want to pass in a path object, pandas accepts any os.PathLike.Alternatively, pandas accepts an open pandas.HDFStore object.keyobject, optional
The group identifier in the store. Can be omitted if the HDF file contains a single pandas object.mode{‘r’, ‘r+’, ‘a’}, default ‘r’
Mode to use when opening the file. Ignored if path_or_buf is a pandas.HDFStore. Default is ‘r’.errorsstr, default ‘strict’
Specifies how encoding and decoding errors are to be handled. See the errors argument for open() for a full list of options.wherelist, optional
A list of Term (or convertible) objects.startint, optional
Row number to start selection.stopint, optional
Row number to stop selection.columnslist, optional
A list of columns names to return.iteratorbool, optional
Return an iterator object.chunksizeint, optional
Number of rows to include in an iteration when using an iterator.**kwargs
Additional keyword arguments passed to HDFStore.Returns:
object
The selected object. Return type depends on the object stored.22-2、参数
22-2-1、path_or_buf(必须):字符串或文件样对象(如文件句柄或类似文件的对象),指定要读取的HDF5文件的路径或文件对象。
22-2-2、key(可选,默认值为None):字符串或列表,指定要从HDF5文件中读取的键(即数据集/表的名称)。如果文件包含多个数据集,则需要使用此参数来指定要读取哪一个;如果未指定,则尝试读取默认的数据集(如果存在)。
22-2-3、mode(可选,默认值为'r'):字符串,指定文件打开模式。其他可能的值包括'r+'(读写模式),但注意在使用pandas时,通常不需要写模式,因为read_hdf专门用于读取数据。
22-2-4、errors(可选,默认值为'strict'):字符串,指定错误处理模式。默认为'strict',表示如果发生错误则抛出异常,其他选项包括'ignore',表示忽略错误。
22-2-5、where(可选,默认值为None):字符串或表达式,用于在读取数据之前对数据进行过滤,这可以是一个字符串表达式,Pandas会尝试在读取数据时应用此表达式以筛选行。
22-2-6、start/stop(可选,默认值为None):用于指定要读取的行范围(基于0的索引),这可以用于分块读取大型数据集的一部分。
22-2-7、columns(可选,默认值为None):字符串或列表,指定要读取的列名列表。如果指定,则只读取这些列。
22-2-8、iterator(可选,默认值为False):布尔值,如果设置为True,则返回一个迭代器,该迭代器在每次迭代时返回下一块数据(由chunksize指定大小),这对于处理非常大的数据集非常有用,因为它允许逐个处理数据块而不是一次性将所有数据加载到内存中。
22-2-9、chunksize(可选,默认值为None):整数,当iterator=True时有效。指定每次迭代时返回的块的大小(以行为单位)。
22-2-10、**kwargs(可选):其他关键字参数,这些参数将被传递给底层的PyTables或HDFStore对象,这些参数通常用于控制更底层的HDF5文件操作,如压缩选项等。
22-3、功能
从HDF5文件中读取数据。
22-4、返回值
22-4-1、DataFrame或Series:默认情况下,read_hdf返回一个Pandas DataFrame对象,该对象包含了从HDF5文件中读取的数据,如果HDF5数据集只包含一列,并且用户没有指定squeeze=False(尽管在read_hdf的典型用法中,squeeze参数不是直接暴露的,但在Pandas的其他读取函数中,如read_csv,squeeze可以用来控制单列数据的返回类型),则可能会返回一个Pandas Series对象。
22-4-2、迭代器:如果设置了iterator=True,则read_hdf返回一个迭代器,该迭代器在每次迭代时返回下一块数据(由chunksize指定大小),这允许用户以流式方式处理大型数据集,减少内存使用。
22-5、说明
HDF5(Hierarchical Data Format version 5)是一种用于存储和组织大量数据的文件格式,它特别适合于存储和组织大量科学数据。
22-6、用法
22-6-1、数据准备
# 22、pandas.read_hdf函数
# 22-1、创建.h5文件example.h5
import pandas as pd
import numpy as np
# 创建一个示例DataFrame
data = {'column1': np.random.randint(0, 100, size=100),'column2': np.random.random(size=100),'column3': np.random.choice(['A', 'B', 'C', 'D'], size=100)
}
df = pd.DataFrame(data)
# 定义HDF5文件路径和要保存的key
hdf5_file_path = 'example.h5'
key = 'dataset1'
try:# 使用to_hdf函数将DataFrame写入HDF5文件df.to_hdf(hdf5_file_path, key=key, mode='w', format='table', complevel=9, complib='blosc')print(f"数据已成功写入 {hdf5_file_path} 文件中的 {key} 数据集")# 验证写入的文件read_df = pd.read_hdf(hdf5_file_path, key=key)print("读取写入的数据:")print(read_df.head())
except Exception as e:print(f"发生错误: {e}")22-6-2、代码示例
# 22、pandas.read_hdf函数
# 22-2、读取HDF5文件
import pandas as pd
# 定义HDF5文件路径和要读取的key
hdf5_file_path = 'example.h5'
key = 'dataset1'
# 使用read_hdf函数读取HDF5文件
try:df = pd.read_hdf(hdf5_file_path, key=key, mode='r', errors='strict', where=None, start=None, stop=None, columns=None, iterator=False, chunksize=None)print("数据读取成功:")print(df)
except Exception as e:print(f"读取HDF5文件时发生错误: {e}")22-6-3、结果输出
# 22、pandas.read_hdf函数
# 22-1、创建.h5文件example.h5
# 数据已成功写入 example.h5 文件中的 dataset1 数据集
# 读取写入的数据:
# column1 column2 column3
# 0 40 0.530045 C
# 1 80 0.769853 C
# 2 9 0.437948 B
# 3 47 0.896335 D
# 4 12 0.017834 B# 22-2、读取HDF5文件
# 数据读取成功:
# column1 column2 column3
# 0 40 0.530045 C
# 1 80 0.769853 C
# 2 9 0.437948 B
# 3 47 0.896335 D
# 4 12 0.017834 B
# .. ... ... ...
# 95 70 0.172173 B
# 96 2 0.077893 C
# 97 4 0.825904 D
# 98 52 0.092274 A
# 99 7 0.210899 C
#
# [100 rows x 3 columns]23、pandas.HDFStore.put方法
23-1、语法
# 23、pandas.HDFStore.put函数
HDFStore.put(key, value, format=None, index=True, append=False, complib=None, complevel=None, min_itemsize=None, nan_rep=None, data_columns=None, encoding=None, errors='strict', track_times=True, dropna=False)
Store object in HDFStore.Parameters:
keystr
value{Series, DataFrame}
format‘fixed(f)|table(t)’, default is ‘fixed’
Format to use when storing object in HDFStore. Value can be one of:'fixed'
Fixed format. Fast writing/reading. Not-appendable, nor searchable.'table'
Table format. Write as a PyTables Table structure which may perform worse but allow more flexible operations like searching / selecting subsets of the data.indexbool, default True
Write DataFrame index as a column.appendbool, default False
This will force Table format, append the input data to the existing.data_columnslist of columns or True, default None
List of columns to create as data columns, or True to use all columns. See here.encodingstr, default None
Provide an encoding for strings.track_timesbool, default True
Parameter is propagated to ‘create_table’ method of ‘PyTables’. If set to False it enables to have the same h5 files (same hashes) independent on creation time.dropnabool, default False, optional
Remove missing values.23-2、参数
23-2-1、key(必须):字符串,表示要存储的数据在HDF5文件中的键(或路径),这个键用于后续从文件中检索数据。
23-2-2、value(必须):要存储的DataFrame或Series对象。
23-2-3、format(可选,默认值为None):字符串,指定存储格式。对于表格数据,通常使用'table',它支持更复杂的查询和数据操作。对于简单的数据,可以使用'fixed',但它不支持查询。如果为None,则根据value的类型自动选择。
23-2-4、index(可选,默认值为True):布尔值,指定是否将DataFrame的索引也存储在文件中。
23-2-5、append(可选,默认值为False):布尔值,如果为True,则尝试将数据追加到已存在的键下,而不是覆盖它,这要求format='table'。
23-2-6、complib(可选,默认值为None):字符串,指定用于压缩的库。pandas支持多种压缩库,如'zlib'、'lzo'、'blosc'等,选择合适的压缩库可以显著减少文件大小,但会增加存储和检索时间。如果为None,则不压缩。
23-2-7、complevel(可选,默认值为None):整数,指定压缩级别。级别越高,压缩率越高,但处理速度越慢,范围从0(无压缩)到9(最大压缩),如果complib为None,则此参数无效。
23-2-8、min_itemsize(可选,默认值为None):字典,指定列中字符串的最小存储大小(以字节为单位),这有助于避免在追加数据时截断字符串,键是列名,值是整数。
23-2-9、nan_rep(可选,默认值为None):用于表示NaN值的字符串。默认为None,表示使用HDF5的NaN表示。
23-2-10、data_columns(可选,默认值为None):列表或布尔值,指定哪些列应该作为数据列进行索引,以便可以进行快速查询。如果为True,则所有列都作为数据列;如果为False,则没有列作为数据列;如果为列表,则列表中的列名作为数据列。
23-2-11、encoding(可选,默认值为None):字符串,指定用于写入文件的编码,这对于存储包含非ASCII字符的字符串列很有用。
23-2-12、errors(可选,默认值为'strict'):字符串,指定在编码或解码字符串时如何处理错误,'strict'表示抛出异常,'ignore'表示忽略错误,'replace'表示用占位符替换错误字符。
23-2-13、track_times(可选,默认值为True):布尔值,如果为True,则跟踪数据的创建和修改时间,并作为元数据存储在文件中,这对于数据版本控制可能很有用。
23-2-14、dropna(可选,默认值为False):布尔值,当与append=True一起使用时,如果为True,则在追加之前从DataFrame中删除包含NaN值的行。注意,这仅影响要追加的数据,不会影响已存储在文件中的数据。
23-3、功能
将一个DataFrame或Series对象保存到HDF5文件中。
23-4、返回值
没有直接的返回值,它的主要目的是将数据写入文件,而不是返回任何数据给调用者。
23-5、说明
无
23-6、用法
23-6-1、数据准备
无23-6-2、代码示例
# 23、pandas.HDFStore.put方法
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3, 4, 5],'B': ['a', 'b', 'c', 'd', 'e'],'C': [True, False, True, False, True]
}
df = pd.DataFrame(data)
# 使用HDFStore保存DataFrame
with pd.HDFStore('example.h5') as store:# 使用put方法将数据保存到HDF5文件中# 这里我们指定键为'dataset1',格式为'table',并使用Blosc压缩store.put('dataset1', df, format='table', complib='blosc', complevel=9)
# 从HDF5文件中读取数据
with pd.HDFStore('example.h5') as store:# 使用get方法(或read_hdf函数,但在这里我们使用get来展示HDFStore的用法)# 根据键'dataset1'检索数据retrieved_df = store.get('dataset1')
# 显示检索到的DataFrame
print("Retrieved DataFrame:")
print(retrieved_df)23-6-3、结果输出
# 23、pandas.HDFStore.put方法
# Retrieved DataFrame:
# A B C
# 0 1 a True
# 1 2 b False
# 2 3 c True
# 3 4 d False
# 4 5 e True24、pandas.HDFStore.append方法
24-1、语法
# 24、pandas.HDFStore.append方法
HDFStore.append(key, value, format=None, axes=None, index=True, append=True, complib=None, complevel=None, columns=None, min_itemsize=None, nan_rep=None, chunksize=None, expectedrows=None, dropna=None, data_columns=None, encoding=None, errors='strict')
Append to Table in file.Node must already exist and be Table format.Parameters:
keystr
value{Series, DataFrame}
format‘table’ is the default
Format to use when storing object in HDFStore. Value can be one of:'table'
Table format. Write as a PyTables Table structure which may perform worse but allow more flexible operations like searching / selecting subsets of the data.indexbool, default True
Write DataFrame index as a column.appendbool, default True
Append the input data to the existing.data_columnslist of columns, or True, default None
List of columns to create as indexed data columns for on-disk queries, or True to use all columns. By default only the axes of the object are indexed. See here.min_itemsizedict of columns that specify minimum str sizes
nan_repstr to use as str nan representation
chunksizesize to chunk the writing
expectedrowsexpected TOTAL row size of this table
encodingdefault None, provide an encoding for str
dropnabool, default False, optional
Do not write an ALL nan row to the store settable by the option ‘io.hdf.dropna_table’.24-2、参数
24-2-1、key(必须):字符串,表示要追加数据的键(或路径)在HDF5文件中,如果键已存在且format='table',则数据将被追加到该键下的表中。
24-2-2、value(必须):要追加的DataFrame或Series对象。
24-2-3、 format(可选,默认值为None):字符串,指定存储格式。对于追加操作,通常使用'table',因为它支持追加和复杂查询。如果为None,则根据value的类型和已存在的数据集(如果有的话)来推断。
24-2-4、 axes(可选,默认值为None):已弃用,不推荐使用。
24-2-5、 index(可选,默认值为True):布尔值,指定是否将DataFrame的索引也追加到文件中。对于追加操作,这通常应该保持为True,以确保索引的连续性。
24-2-6、append(可选,默认值为True):布尔值,对于append方法本身来说,这个参数实际上总是True,因为它就是用来追加数据的。但在某些上下文中,这个参数可能用于区分追加和覆盖操作,但在这里不适用。
24-2-7、complib(可选,默认值为None):字符串,指定用于压缩的库。与put方法相同,pandas支持多种压缩库,如'zlib'、'lzo'、'blosc'等,选择合适的压缩库可以显著减少文件大小。
24-2-8、complevel(可选,默认值为None):整数,指定压缩级别。级别越高,压缩率越高,但处理速度越慢,范围从0(无压缩)到9(最大压缩)。
24-2-9、columns(可选,默认值为None):列表,指定要追加的列,如果为None,则追加所有列,这可以用于筛选要追加的列。
24-2-10、min_itemsize(可选,默认值为None):字典,指定列中字符串的最小存储大小(以字节为单位),这有助于避免在追加数据时截断字符串,键是列名,值是整数。
24-2-11、nan_rep(可选,默认值为None):用于表示NaN值的字符串。默认为None,表示使用HDF5的NaN表示。
24-2-12、chunksize(可选,默认值为None):整数,指定写入时的块大小(以行数为单位),这对于处理大数据集时减少内存使用很有用,如果为None,则一次性写入整个数据集。
24-2-13、expectedrows(可选,默认值为None):整数,预期要追加的行数,这可以帮助优化存储结构,但通常不是必需的。
24-2-14、dropna(可选,默认值为None):布尔值,如果为True,则在追加之前从DataFrame中删除包含NaN值的行。请注意,这与put方法中的dropna参数不同,后者在append=True时无效。
24-2-15、data_columns(可选,默认值为None):列表或布尔值,指定哪些列应该作为数据列进行索引,以便可以进行快速查询。如果为True,则所有列都作为数据列;如果为False,则没有列作为数据列;如果为列表,则列表中的列名作为数据列。
24-2-16、encoding(可选,默认值为None):字符串,指定用于写入文件的编码,这对于存储包含非ASCII字符的字符串列很有用。
24-2-17、errors(可选,默认值为'strict'):字符串,指定在编码或解码字符串时如何处理错误,'strict'表示抛出异常,'ignore'表示忽略错误,'replace'表示用占位符替换错误字符。
24-3、功能
用于将DataFrame或Series对象追加到已存在的HDF5文件中的数据集的一个方法。
24-4、返回值
没有直接的返回值,它的主要作用是执行追加操作,并将数据写入到HDF5文件中。
24-5、说明
无
24-6、用法
24-6-1、数据准备
无24-6-2、代码示例
# 24、pandas.HDFStore.append方法
import pandas as pd
# 创建一个示例DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
df2 = pd.DataFrame({'A': [4, 5, 6], 'B': ['d', 'e', 'f']})
# 将df1保存到HDF5文件中
with pd.HDFStore('example.h5') as store:store.put('dataset', df1, format='table')
# 将df2追加到HDF5文件中的dataset数据集
with pd.HDFStore('example.h5') as store:store.append('dataset', df2, format='table', index=False) # 假设我们不想追加索引
# 验证数据是否已追加
with pd.HDFStore('example.h5') as store:retrieved_df = store.get('dataset')
print(retrieved_df)
# 输出将显示包含df1和df2数据的完整DataFrame24-6-3、结果输出
# 24、pandas.HDFStore.append方法
# A B
# 0 1 a
# 1 2 b
# 2 3 c
# 0 4 d
# 1 5 e
# 2 6 f二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
相关文章:
Python酷库之旅-第三方库Pandas(010)
目录 一、用法精讲 22、pandas.read_hdf函数 22-1、语法 22-2、参数 22-3、功能 22-4、返回值 22-5、说明 22-6、用法 22-6-1、数据准备 22-6-2、代码示例 22-6-3、结果输出 23、pandas.HDFStore.put方法 23-1、语法 23-2、参数 23-3、功能 23-4、返回值 23-5…...

海康威视监控web实时预览解决方案
海康威视摄像头都试rtsp流,web页面无法加载播放,所以就得转换成web页面可以播放的hls、rtmp等数据流来播放。 一:萤石云 使用萤石云平台,把rtsp转化成ezopen协议,然后使用组件UIKit 最佳实践 萤石开放平台API文档 …...
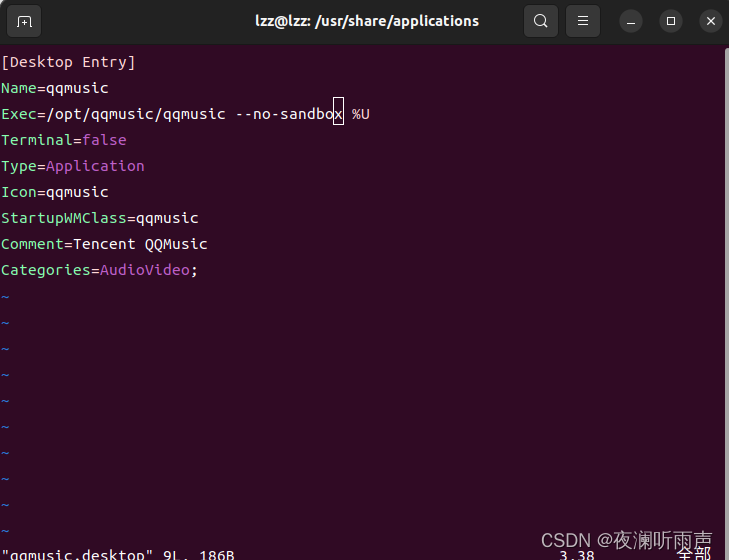
ubuntu运行qq音乐闪退
ubuntu运行qq音乐闪退 修改/usr/share/applications中的qqmusic.desktop,在Exec后加上 --no-sandbox,如下图所示: 该文件有可能是只读,权限不够的话用sudo vim qqmusic.desktop...

人脸检测(Python)
目录 环境: 初始化摄像头: 初始化FaceDetector对象: 获取摄像头帧: 获取数据: 绘制数据: 显示图像: 完整代码: 环境: cvzone库:cvzone是一个基于…...

Offer150-23:链表中环的入口节点
题目描述:如果一个链表中包含环,找了环的入口节点。例如,在下图所示的链表中,环的入口节点是节点4。 分析:第一步需要确定一个链表中是否包含环,可以用快慢指针来解决这个问题。定义两个指针,同时从链表的头…...

【linux】服务器创建RAID1
【linux】服务器创建RAID1 文章目录 【linux】服务器创建RAID1一、配置介绍raid介绍raid类型RAID 0:RAID 1:RAID 5:RAID 6:二、配置RAID硬件RAID:软件RAID:三、软件配置RAID1(以linux为例)1.先进入管理员模式2.安装mdadm工具3.创建raid1数组4.查看RAID数组状态5.格式化和挂载…...

记录自己Ubuntu加Nvidia驱动从入门到入土的一天
前言 记录一下自己这波澜壮阔的一天,遇到了很多问题,解决了很多问题,但是还有很多问题,终于在晚上的零点彻底放弃,重启windows。 安装乌班图 1.安装虚拟机 我开始什么操作系统的基础都没有,网上随便搜了…...

基于现有Docker镜像构建新的Docker镜像
1.拉取ubuntu 22.04的系统镜像 docker pull ubuntu:22.04 拉取成功后在DockerDesktop中可发现该镜像 2.启动刚才接取的ubuntu镜像 docker run --name Ubuntu22.04 -it -d -p 22:22 -p 80:80 -p 443:443 340d9b015b194dc6e2a13938944e0d016e57b9679963fdeb9ce021daac430221 启…...

Java 静态变量、静态代码块、普通代码块、构造方法的执行顺序
今天碰到这个问题,看了课程以及资料,做出解答。这是我自己绘制的图,按从上到下,从左到右的顺序执行。如有问题请联系我修正。 要点: 1、执行顺序分为两步,类加载和初始化阶段。 2、因为静态变量和静态代码块…...

计算机网络性能指标概述:速率、带宽、时延等
在计算机网络中,性能指标是衡量网络效率和质量的重要参数。本文将综合三篇关于计算机网络性能指标的文章,详细介绍速率、带宽、吞吐量、时延、时延带宽积、往返时延(RTT) 和利用率的概念及其在网络中的应用。 1. 速率(…...

众所周知沃尔玛1P是怎么运营?
沃尔玛的1P模式,即第一方供应商模式,是其独特的采购策略。在这种模式下,供应商先将商品卖给沃尔玛,由沃尔玛负责库存管理和销售。沃尔玛通过强大的采购和物流能力控制库存,确保商品品质,为客户提供更加…...
【Linux】静态库的制作和使用详解
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...

2.贪心算法.基础
2.贪心算法.基础 基础知识题目1.分发饼干2.摆动序列2.1.思路二:动态规划法 3.最大子序和4.买股票的最佳时机24.1.思路二:动态规划法4.2.买股票的最佳时机 5.跳跃游戏5.1.跳跃游戏2 6.K次取反后最大化的数组和7.加油站8.分发糖果 总结 基础知识 什么是贪…...

用Python轻松转换PDF为CSV
数据的可访问性和可操作性是数据管理的核心要素。PDF格式因其跨平台兼容性和版面固定性,在文档分享和打印方面表现出色,尤其适用于报表、调查结果等数据的存储。然而,PDF的非结构化特性限制了其在数据分析领域的应用。相比之下,CS…...

关于微信支付-商户平台:查询订单提示“查询失败:操作失败,请稍候重试”的分析
目录 引子 分析 应对 小结 引子 在开发和实施微信 JSAPI 支付的应用后,我们遇到了一些问题,订单的状态更新不正常,当然我们首先需要从自身寻找原因和完善解决问题的办法和方案。在支付的过程中,客户会给我们一些反馈…...

掌握【Python异常处理】:打造健壮代码的现代编程指南
目录 编辑 1. 什么是异常? 知识点 示例 小李的理解 2. 常见的内置异常类型 知识点 示例 小李的理解 3. 异常机制的意义 知识点 示例 小李的理解 4. 如何处理异常 知识点 示例 小李的理解 5. 抛出异常 知识点 示例 小李的理解 6. Python内置…...

STM32点灯闪烁
stm32c8t6引脚图 开发板引脚图 GPIO端口的每个位可以由软件分别配置成 多种模式。 ─ 输入浮空 ─ 输入上拉 ─ 输入下拉 ─ 模拟输入 ─ 开漏输出 ─ 推挽式输出 ─ 推挽式复用功能 ─ 开漏复用功能 配置GPIO端口步骤:开启时钟->使用结构体设置输出模式…...

Java-01-源码篇-04集合-05-SortedMap NavigableMap TreeMap
目录 一,SortedMap 二,NavigableMap 三,TreeMap 3.1 TreeMap 继承结构 3.2 TreeMap 属性 3.3 TreeMap 构造器 3.4 TreeMap 内部类 3.4.1 Values 3.4.2 KeySet 3.4.3 EntrySet 3.4.5 相关集合迭代器 3.4.5.1 PrivateEntryIterato…...
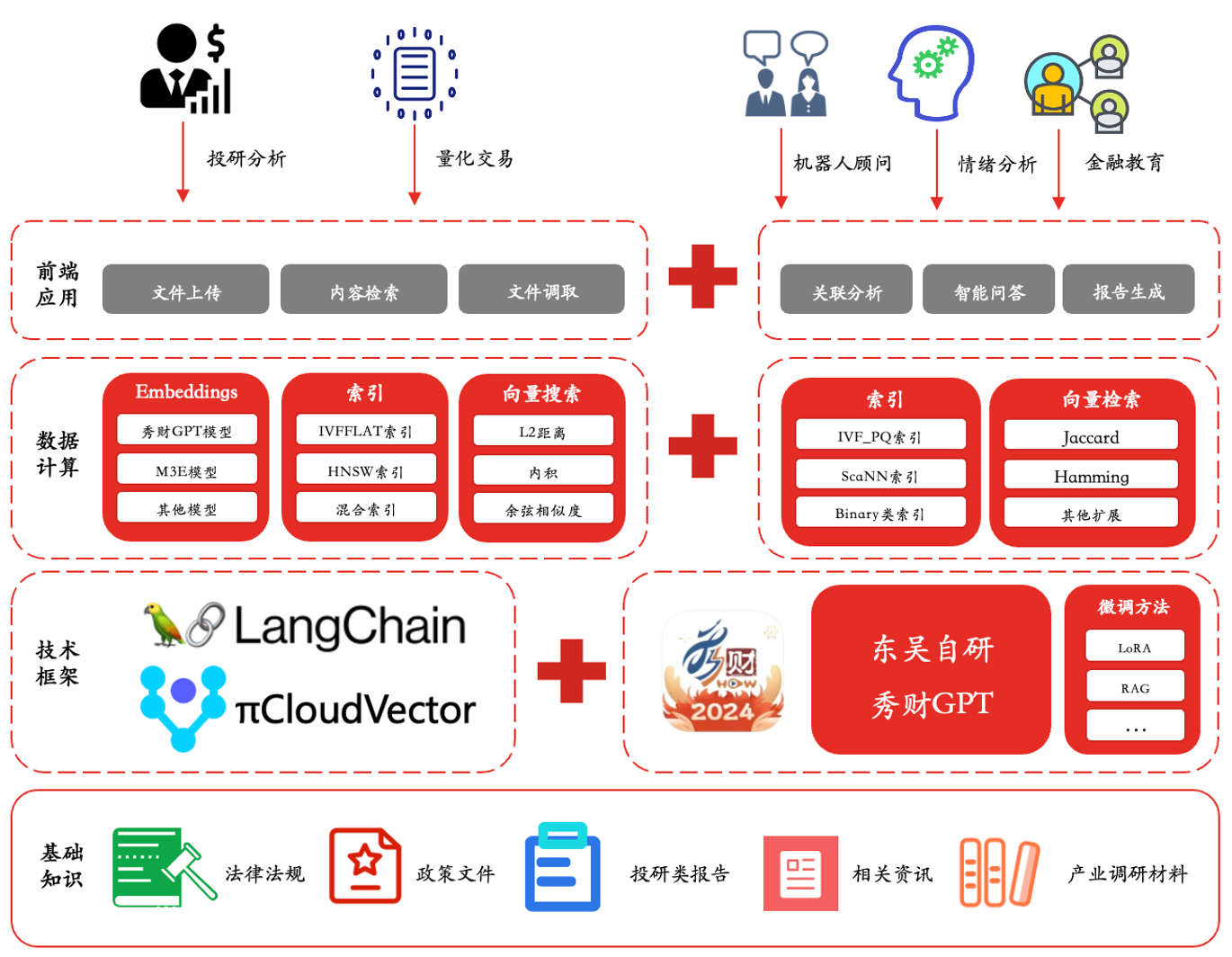
拥抱 AGI:PieDataCS 引领云原生数据计算系统新范式
自2023年后,人工智能技术进入了一个更为成熟和广泛应用的阶段,人工通用智能(AGI)这一概念也成为了科技界和产业界热议的焦点。本文将结合 AGI 时代背景,从架构设计到落地实践,详细介绍拓数派云原生数据计算…...

开放式耳机哪个品牌好?开放式耳机推荐
开放式耳机因其独特的设计,提供了更自然的听音体验和更好的环境声音感知,尤其适合长时间佩戴和户外运动使用,下面来推荐几款表现出色的开放式耳机: 悠律ringbuds pro凝声环(499元):凭借时尚潮流…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次‘交叉验证’吧
你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次"交叉验证"当你在GEO数据库中下载了三个肺癌研究的差异表达结果,却发现三个DEG列表的重叠基因不到20%——这种令人沮丧的场景每天都在全球实验室上演。单项研究的差异分析结果就像…...

如何用OpenHRMS打造企业级人力资源管理系统:30+模块完全指南
如何用OpenHRMS打造企业级人力资源管理系统:30模块完全指南 【免费下载链接】OpenHRMS 项目地址: https://gitcode.com/gh_mirrors/op/OpenHRMS 还在为繁琐的人力资源管理头疼吗?🤔 面对员工考勤、薪酬计算、绩效评估等复杂流程&…...