Hive 分区表新增字段 cascade
背景
在以前上线的分区表中新加一个字段,并且要求添加到指定的位置列。
模拟测试
加 cascade 操作
- 创建测试表
create table if not exists sqltest.table_add_column_test(org_col1 string comment '原始数据1',org_col2 string comment '原始数据2'
)
comment '增加分区表字段的测试表'
partitioned by (dt string comment '分区日期')
;
- 插入测试数据
insert into table sqltest.table_add_column_test partition(dt='20230313') values ('org_col1_0313','org_col2_0313');
insert into table sqltest.table_add_column_test partition(dt='20230314') values ('org_col1_0314','org_col2_0314');
- 查看现有数据
select * from table_add_column_test;
+---------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | org_col2_0313 | 20230313 |
| org_col1_0314 | org_col2_0314 | 20230314 |
+---------------------------------+---------------------------------+---------------------------+--+
- 官网添加列的语法
ALTER TABLE table_name [PARTITION partition_spec] -- (Note: Hive 0.14.0 and later)ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)[CASCADE|RESTRICT] -- (Note: Hive 1.1.0 and later)
注意: Hive 1.1.0 中有 CASCADE|RESTRICT 子句。ALTER TABLE ADD|REPLACE COLUMNS CASCADE命令修改表元数据的列,并将相同的更改级联到所有分区元数据。RESTRICT 是默认值,即不修改元数据。
- 增加一列,指定增加到原始的两列中间
先添加一列(注意: 必须添加cascade关键字,不然不会刷新旧分区数据,关键字cascade能修改元数据)
alter table sqltest.table_add_column_test add columns (added_column string comment '新添加的列') cascade;
查看数据
+---------------------------------+---------------------------------+-------------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.org_col2 | table_add_column_test.added_column | table_add_column_test.dt |
+---------------------------------+---------------------------------+-------------------------------------+---------------------------+--+
| org_col1_0313 | org_col2_0313 | NULL | 20230313 |
| org_col1_0314 | org_col2_0314 | NULL | 20230314 |
+---------------------------------+---------------------------------+-------------------------------------+---------------------------+--+
再对列进行排序(注意: 必须添加 cascade 关键字,不然不会刷新旧分区数据,关键字 cascade 能修改元数据)
alter table sqltest.table_add_column_test change column added_column added_column string after org_col1 cascade;
再查看数据(注意: 虽然列名顺序变了,但 HDFS 文件内容并没有变化,所以结果第二列还是有数据,第三列没数据)
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.added_column | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | org_col2_0313 | NULL | 20230313 |
| org_col1_0314 | org_col2_0314 | NULL | 20230314 |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
- 重刷旧分区数据(将以前第二列放到第三列位置,现第二列为新数据)
insert overwrite table sqltest.table_add_column_test partition(dt='20230313') select org_col1, 'added_col_0313', added_column from sqltest.table_add_column_test where dt = '20230313';
insert overwrite table sqltest.table_add_column_test partition(dt='20230314') select org_col1, 'added_col_0314', added_column from sqltest.table_add_column_test where dt = '20230314';
查看数据(旧分区数据有更新)
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.added_column | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | added_col_0313 | org_col2_0313 | 20230313 |
| org_col1_0314 | added_col_0314 | org_col2_0314 | 20230314 |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
不加 cascade 操作(针对已有分区数据)
- 删除表
drop table if exists sqltest.table_add_column_test;
- 创建测试表
create table if not exists sqltest.table_add_column_test(org_col1 string comment '原始数据1',org_col2 string comment '原始数据2'
)
comment '增加分区表字段的测试表'
partitioned by (dt string comment '分区日期')
;
- 插入测试数据
insert into table sqltest.table_add_column_test partition(dt='20230313') values ('org_col1_0313','org_col2_0313');
insert into table sqltest.table_add_column_test partition(dt='20230314') values ('org_col1_0314','org_col2_0314');
- 添加列(不加关键字 cascade)
alter table sqltest.table_add_column_test add columns (added_column string comment '新添加的列');alter table sqltest.table_add_column_test change column added_column added_column string after org_col1;
查看数据
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.added_column | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | org_col2_0313 | NULL | 20230313 |
| org_col1_0314 | org_col2_0314 | NULL | 20230314 |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
- 重刷旧分区数据
insert overwrite table sqltest.table_add_column_test partition(dt='20230313') select org_col1, 'added_col_0313', added_column from sqltest.table_add_column_test where dt = '20230313';
insert overwrite table sqltest.table_add_column_test partition(dt='20230314') select org_col1, 'added_col_0314', added_column from sqltest.table_add_column_test where dt = '20230314';
- 查看数据(旧分区没有变化)
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.added_column | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | added_col_0313 | NULL | 20230313 |
| org_col1_0314 | added_col_0314 | NULL | 20230314 |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
相关文章:

Hive 分区表新增字段 cascade
背景 在以前上线的分区表中新加一个字段,并且要求添加到指定的位置列。 模拟测试 加 cascade 操作 创建测试表 create table if not exists sqltest.table_add_column_test(org_col1 string comment 原始数据1,org_col2 string comment 原始数据2 ) comment 增…...

【Java版oj】day08两种排序方法、最小公倍数
目录 一、两种排序方法 (1)原题再现 (2)问题分析 (3)完整代码 二、最小公倍数 (1)原题再现 (2)问题分析 (3)完整代码 一、两种…...

FinOps,从概念到落地 | UGeek大咖说第一期直播回顾(上)
2023年2月28日,由优维科技联合FinOps产业推进方阵举办了第1期「UGeek大咖说-极致用云共济FinOps」线上直播活动,来自中国信通院及美图公司技术专家共同带来了一场精彩的技术视听盛宴。 直 播 背 景 目前,许多以“上云”为数字化转型路径的企…...

k8s java程序实现kubernetes Controller Operator 使用CRD 学习总结
k8s java程序实现kubernetes Controller & Operator 使用CRD 学习总结 大纲 原理Controller 与 Operator自定义资源定义 CRD ( CustomResourceDefinition)kubernetes-client使用java fabric8io/kubernetes-client操作k8s 原生资源使用java abric8io/kubernetes-clientt操…...
Unity笔记:修改代码执行的默认打开方式
使用 External Tools 偏好设置可设置用于编写脚本、处理图像和进行源代码控制的外部应用程序。 External Script Editor:选择 Unity 应使用哪个应用程序来打开脚本文件。Unity 会自动将正确的参数传递给内置支持的脚本编辑器。Unity 内置支持 Visual Studio Commun…...

Linux IPC:匿名管道 与 命名管道
目录一、管道的理解二、匿名管道三、命名管道四、管道的通信流程五、管道的特性进程间通信方式有多种,本文介绍的是管道,管道分为匿名管道和命名管道。 一、管道的理解 生活中的管道用来传输资源,例如水、石油之类的资源。而进程间通信的管道…...

阿里研发工程师JAVA暑期实习一面
文章目录先说一下我自己的情况面试过程总结先说一下我自己的情况 我就读于湖南大学,软件工程专业,现在大三下 很巧的是,我在大二的时候就在相同的时间面过相同的部门和相同的岗位,所以我没有做笔试就直接让我去面试了。我当时还纳…...
第十四届蓝桥杯三月真题刷题训练——第 11 天
目录 第 1 题:卡片 题目描述 运行限制 第 2 题:路径_dpgcd 运行限制 第 3 题:字符统计 问题描述 输入格式 输出格式 样例输入 样例输出 评测用例规模与约定 运行限制 第 4 题:费用报销 第 1 题:卡片 题…...
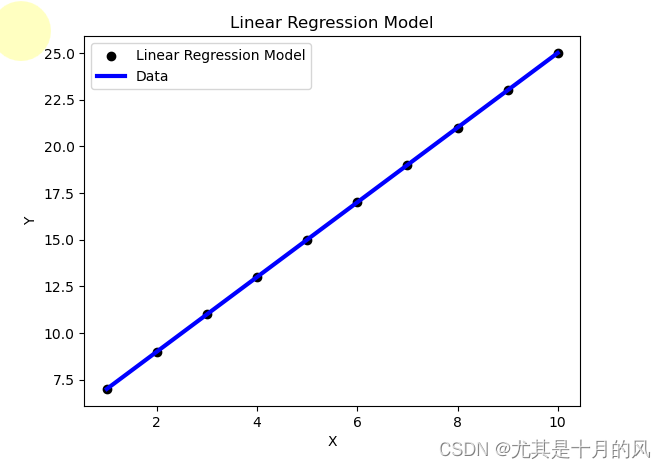
机器学习入门——线性回归
线性回归什么是线性回归?回归分析:线性回归:回归问题求解单因子线性回归简单实例评估模型表现可视化模型展示多因子线性回归什么是线性回归? 回归分析: 根据数据,确定两种或两种以上变量间相互依赖的定量…...
)
Microsoft Word 远程代码执行漏洞(CVE-2023-21716)
本文转载于: https://mp.weixin.qq.com/s?__bizMzI5NTUzNzY3Ng&mid2247485476&idx1&sneee5c7fd1c4855be6441b8933b10051e&chksmec535547db24dc516d013d3d76097e985aaad7f10f82f15b4e355a97af75fd333acdab6232af&mpshare1&scene23&srci…...
SharedPreferences存储及测试)
Android kotlin 系列讲解(数据篇)SharedPreferences存储及测试
文章目录 一、什么是SharedPreferences1、将数据存储到SharedPreferences中2、从SharedPreferences中读取数据二、登录使用SharedPreferences一、什么是SharedPreferences SharedPreferences是使用键值对的方式来存储数据的。也就是说,当保存一条数据的时候,需要给这条数据提…...
一文了解Web Worker
一、概述 众所周知,JavaScript最初设计是运行在浏览器中的,为了防止多个线程同时操作DOM带来的渲染冲突问题,所以JavaScript执行器被设计成单线程。但是随着前端技术的发展,JavaScript要处理的工作也越来越复杂,当我们…...
接口文档包含哪些内容?怎么才能写好接口文档?十年测试老司机来告诉你
目录 接口文档结构 参数说明 示例 错误码说明 语言基调通俗易懂 及时更新与维护 总结 那么我们该如何写好一份优秀的接口文档呢? 接口文档结构 首先我们要知道文档结构是什么样子的。接口文档应该有清晰明确的结构,以便开发人员能快速定位自己需…...
java面试八股文之------Java并发夺命23问
java面试八股文之------Java并发夺命23问👨🎓1.java中线程的真正实现方式👨🎓2.java中线程的真正状态👨🎓3.如何正确停止线程👨🎓4.java中sleep和wait的区别👨…...

CANoe中使用CAPL刷写流程详解(Trace图解)(CAN总线)
🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】🍅 玩转CANoe&…...

【MySQL】002 -- 日志系统:一条SQL更新语句是如何执行的
此文章为《MySQL 实战 45 讲》的学习笔记,其课程链接可参见:MySQL实战45讲_MySQL_数据库-极客时间 目录 一、日志系统 1、重做日志:redo log(引擎层) 2、归档日记:binlog(Server层) …...
)
C++---背包模型---数字组合(每日一道算法2023.3.14)
注意事项: 本题是"动态规划—01背包"的扩展题,优化思路不多赘述,dp思路会稍有不同,下面详细讲解。 题目: 给定 N个正整数 A1,A2,…,AN,从中选出若干个数,使它们的和为 M,…...
并查集(不相交集)详解
目录 一.并查集 1.什么是并查集 2.并查集的基本操作 3.并查集的应用 4.力扣上的题目 二.三大操作 1.初始化 2.查找 3.合并 三.省份数量 1.题目描述 2.问题分析 3.代码实现 四.冗余连接 1.题目描述 2.问题分析 3.代码实现 一.并查集 1.什么是并查集 并查集&…...

10个最频繁用于解释机器学习模型的 Python 库
文章目录什么是XAI?可解释性实践的步骤技术交流1、SHAP2、LIME3、Eli54、Shapash5、Anchors6、BreakDown7、Interpret-Text8、aix360 (AI Explainability 360)9、OmniXAI10、XAI (eXplainable AI)XAI的目标是为模型的行为和决定提供有意义的解释,本文整理…...

final关键字:我偏不让你继承
哈喽,小伙伴们大家好,我是兔哥呀,今天就让我们继续这个JavaSE成神之路! 这一节啊,咱们要学习的内容是Java所有final关键字。 之前呢,我们学习了继承,这大大提高了代码的灵活性和复用性。但是总…...

dcm2niix终极指南:免费高效的医学影像格式转换神器
dcm2niix终极指南:免费高效的医学影像格式转换神器 【免费下载链接】dcm2niix dcm2nii DICOM to NIfTI converter: compiled versions available from NITRC 项目地址: https://gitcode.com/gh_mirrors/dc/dcm2niix dcm2niix是一款功能强大的开源医学影像转换…...

模块化电脑设计:从主板重构到硬件可持续性的创新实践
1. 项目概述:当“模块化”遇见“不无聊”的桌面电脑如果你觉得桌面电脑已经是一潭死水,被一体机和笔记本挤压得毫无新意,那 Xi3 这家硬件初创公司可能会让你眼前一亮。2012年,他们带着一个大胆的宣言闯入市场:要彻底改…...

Chromatic深度解析:基于QuickJS的跨平台动态代码注入框架实现原理
Chromatic深度解析:基于QuickJS的跨平台动态代码注入框架实现原理 【免费下载链接】chromatic Universal modifier for Chromium/V8 | 广谱注入 Chromium/V8 的通用修改器 项目地址: https://gitcode.com/gh_mirrors/be/chromatic 你是否曾经遇到过这样的技术…...

OpenVSP参数化飞机设计深度解析:从几何建模到气动分析的完整技术栈
OpenVSP参数化飞机设计深度解析:从几何建模到气动分析的完整技术栈 【免费下载链接】OpenVSP A parametric aircraft geometry tool 项目地址: https://gitcode.com/gh_mirrors/ope/OpenVSP OpenVSP是一款由NASA开发的开源参数化飞机几何设计工具,…...

AI编程套餐怎么选:别只看模型和额度,更要看你会不会被绑定
AI Coding 套餐已经不是单纯比模型强弱的时代。Copilot 改成按量计费,Claude 开始做身份验证,真正决定你成本和稳定性的,越来越不是“今天谁最强”,而是“明天规则变了,你还能不能无痛切走”。以前看模型,2…...

QMCDecode:解锁QQ音乐加密文件,三步实现音乐格式自由转换
QMCDecode:解锁QQ音乐加密文件,三步实现音乐格式自由转换 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&am…...

模拟芯片巨头Maxim 2010技术日深度解读:从工艺到应用的创新启示
1. 一场迟到的“技术盛宴”:深入解读Maxim 2010年编辑分析师日 在半导体行业,尤其是模拟芯片这个领域,巨头们的一举一动都牵动着整个产业链的神经。2010年9月底,模拟与混合信号半导体领域的“安静巨人”——Maxim Integrated&…...

XUnity.AutoTranslator完整指南:让Unity游戏告别语言障碍的终极解决方案
XUnity.AutoTranslator完整指南:让Unity游戏告别语言障碍的终极解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因为语言不通而错过精彩的日本RPG游戏?是否面对欧…...

Pikachu 靶场 XSS 通关笔记:从反射型到盲打与过滤绕过
目录 一、基础 XSS 类型 1. 反射型 XSS (GET)2. 反射型 XSS (POST)3. 存储型 XSS4. DOM 型 XSS5. DOM 型 XSS-x 二、进阶 XSS 场景 6. XSS 之盲打 (Blind XSS)7. XSS 之过滤8. XSS 之 htmlspecialchars9. XSS 之 href 输出10. XSS 之 JS 输出 三、XSS 绕过速查表 四、Pikach…...

GoAmzAI:开源本地化部署,AI赋能亚马逊卖家高效生成运营文案
1. 项目概述:一个面向亚马逊卖家的AI助手最近在和一些做跨境电商的朋友聊天,发现他们每天花在亚马逊店铺运营上的时间,很大一部分都耗在了重复性的文案工作上。从产品标题、五点描述、A页面,到广告文案、客户邮件回复,…...