10个最频繁用于解释机器学习模型的 Python 库

文章目录
- 什么是XAI?
- 可解释性实践的步骤
- 技术交流
- 1、SHAP
- 2、LIME
- 3、Eli5
- 4、Shapash
- 5、Anchors
- 6、BreakDown
- 7、Interpret-Text
- 8、aix360 (AI Explainability 360)
- 9、OmniXAI
- 10、XAI (eXplainable AI)
XAI的目标是为模型的行为和决定提供有意义的解释,本文整理了目前能够看到的10个用于可解释AI的Python库。
什么是XAI?
XAI,Explainable AI是指可以为人工智能(AI)决策过程和预测提供清晰易懂的解释的系统或策略。XAI 的目标是为他们的行为和决策提供有意义的解释,这有助于增加信任、提供问责制和模型决策的透明度。XAI 不仅限于解释,还以一种使推理更容易为用户提取和解释的方式进行 ML 实验。
在实践中,XAI 可以通过多种方法实现,例如使用特征重要性度量、可视化技术,或者通过构建本质上可解释的模型,例如决策树或线性回归模型。方法的选择取决于所解决问题的类型和所需的可解释性水平。
AI 系统被用于越来越多的应用程序,包括医疗保健、金融和刑事司法,在这些应用程序中,AI 对人们生活的潜在影响很大,并且了解做出了决定特定原因至关重要。因为这些领域的错误决策成本很高(风险很高),所以XAI 变得越来越重要,因为即使是 AI 做出的决定也需要仔细检查其有效性和可解释性。
可解释性实践的步骤
数据准备:这个阶段包括数据的收集和处理。数据应该是高质量的、平衡的并且代表正在解决的现实问题。拥有平衡的、有代表性的、干净的数据可以减少未来为保持 AI 的可解释性而付出的努力。
模型训练:模型在准备好的数据上进行训练,传统的机器学习模型或深度学习神经网络都可以。模型的选择取决于要解决的问题和所需的可解释性水平。模型越简单就越容易解释结果,但是简单模型的性能并不会很高。
模型评估:选择适当的评估方法和性能指标对于保持模型的可解释性是必要的。在此阶段评估模型的可解释性也很重要,这样确保它能够为其预测提供有意义的解释。
解释生成:这可以使用各种技术来完成,例如特征重要性度量、可视化技术,或通过构建固有的可解释模型。
解释验证:验证模型生成的解释的准确性和完整性。这有助于确保解释是可信的。
部署和监控:XAI 的工作不会在模型创建和验证时结束。它需要在部署后进行持续的可解释性工作。在真实环境中进行监控,定期评估系统的性能和可解释性非常重要。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
本文来自技术群粉丝分享整理,文章源码、数据、技术交流,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自CSDN +备注来意
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
1、SHAP
(SHapley Additive exPlanations)
SHAP是一种博弈论方法,可用于解释任何机器学习模型的输出。它使用博弈论中的经典Shapley值及其相关扩展将最佳信用分配与本地解释联系起来。

2、LIME
(Local Interpretable Model-agnostic Explanations)
LIME 是一种与模型无关的方法,它通过围绕特定预测在局部近似模型的行为来工作。LIME 试图解释机器学习模型在做什么。LIME 支持解释文本分类器、表格类数据或图像的分类器的个别预测。

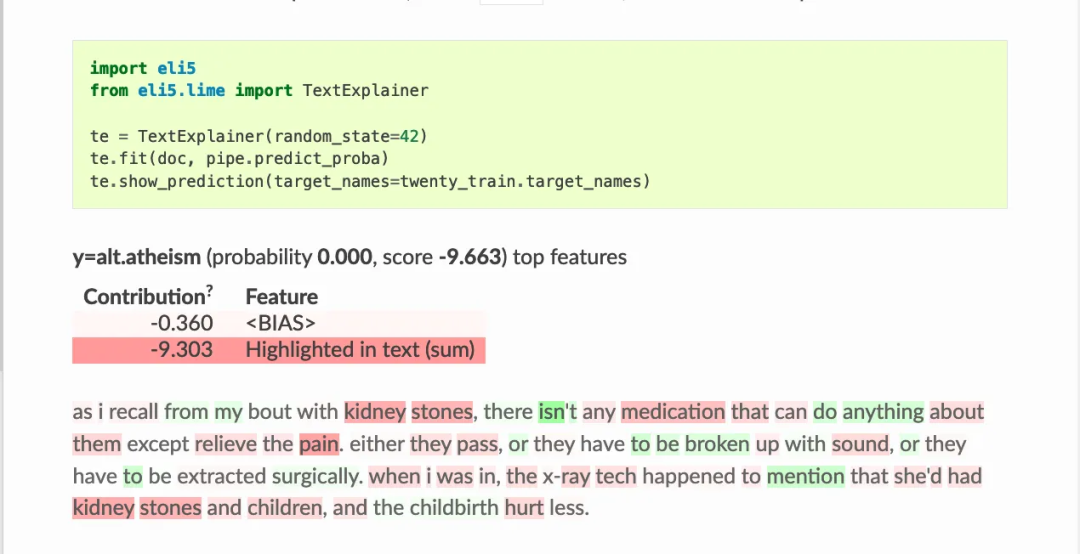
3、Eli5
ELI5是一个Python包,它可以帮助调试机器学习分类器并解释它们的预测。它提供了以下机器学习框架和包的支持:
-
scikit-learn:ELI5可以解释scikit-learn线性分类器和回归器的权重和预测,可以将决策树打印为文本或SVG,显示特征的重要性,并解释决策树和基于树集成的预测。ELI5还可以理解scikit-learn中的文本处理程序,并相应地突出显示文本数据。
-
Keras -通过Grad-CAM可视化解释图像分类器的预测。
-
XGBoost -显示特征的重要性,解释XGBClassifier, XGBRegressor和XGBoost . booster的预测。
-
LightGBM -显示特征的重要性,解释LGBMClassifier和LGBMRegressor的预测。
-
CatBoost:显示CatBoostClassifier和CatBoostRegressor的特征重要性。
-
lightning -解释lightning 分类器和回归器的权重和预测。
-
sklearn-crfsuite。ELI5允许检查sklearn_crfsuite.CRF模型的权重。
基本用法:
Show_weights() 显示模型的所有权重,Show_prediction() 可用于检查模型的个体预测

ELI5还实现了一些检查黑盒模型的算法:
TextExplainer使用LIME算法解释任何文本分类器的预测。排列重要性法可用于计算黑盒估计器的特征重要性。
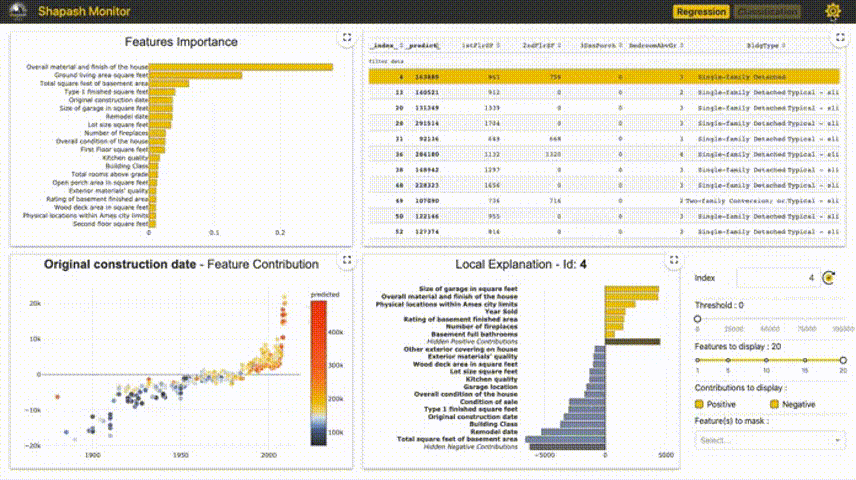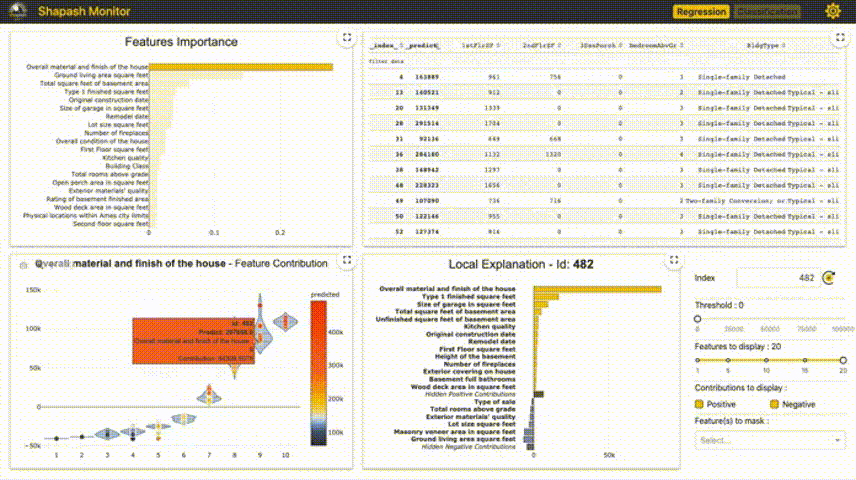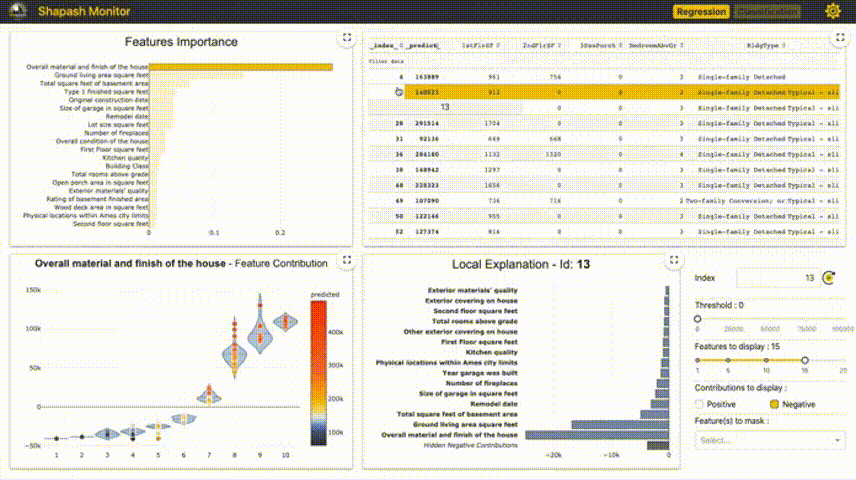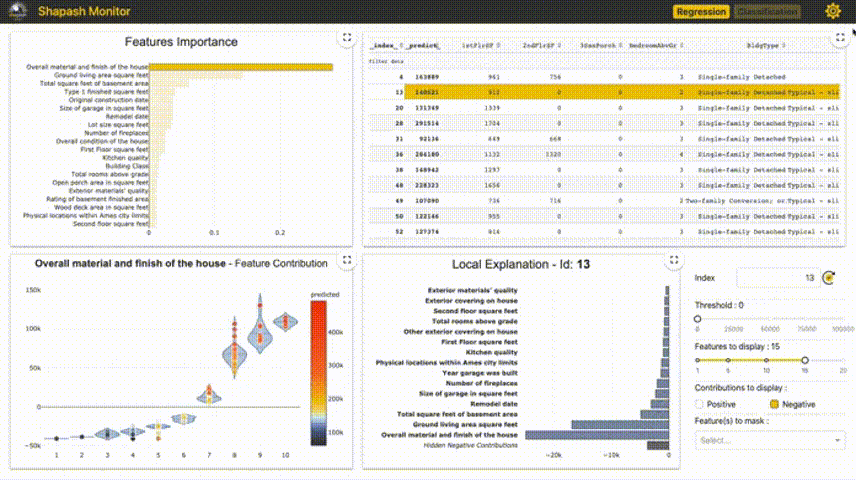
4、Shapash
Shapash提供了几种类型的可视化,可以更容易地理解模型。通过摘要来理解模型提出的决策。该项目由MAIF数据科学家开发。Shapash主要通过一组出色的可视化来解释模型。
Shapash通过web应用程序机制工作,与Jupyter/ipython可以完美的结合。
from shapash import SmartExplainer xpl = SmartExplainer( model=regressor, preprocessing=encoder, # Optional: compile step can use inverse_transform method features_dict=house_dict # Optional parameter, dict specifies label for features name ) xpl.compile(x=Xtest, y_pred=y_pred, y_target=ytest, # Optional: allows to display True Values vs Predicted Values ) xpl.plot.contribution_plot("OverallQual")
5、Anchors
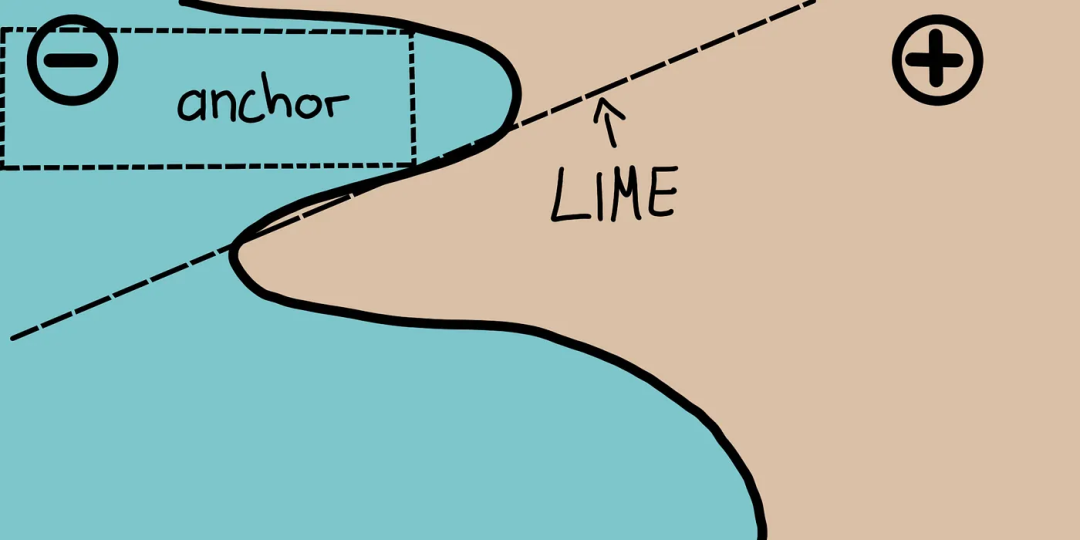
Anchors使用称为锚点的高精度规则解释复杂模型的行为,代表局部的“充分”预测条件。该算法可以有效地计算任何具有高概率保证的黑盒模型的解释。
Anchors可以被看作为LIME v2,其中LIME的一些限制(例如不能为数据的不可见实例拟合模型)已经得到纠正。Anchors使用局部区域,而不是每个单独的观察点。它在计算上比SHAP轻量,因此可以用于高维或大数据集。但是有些限制是标签只能是整数。
6、BreakDown
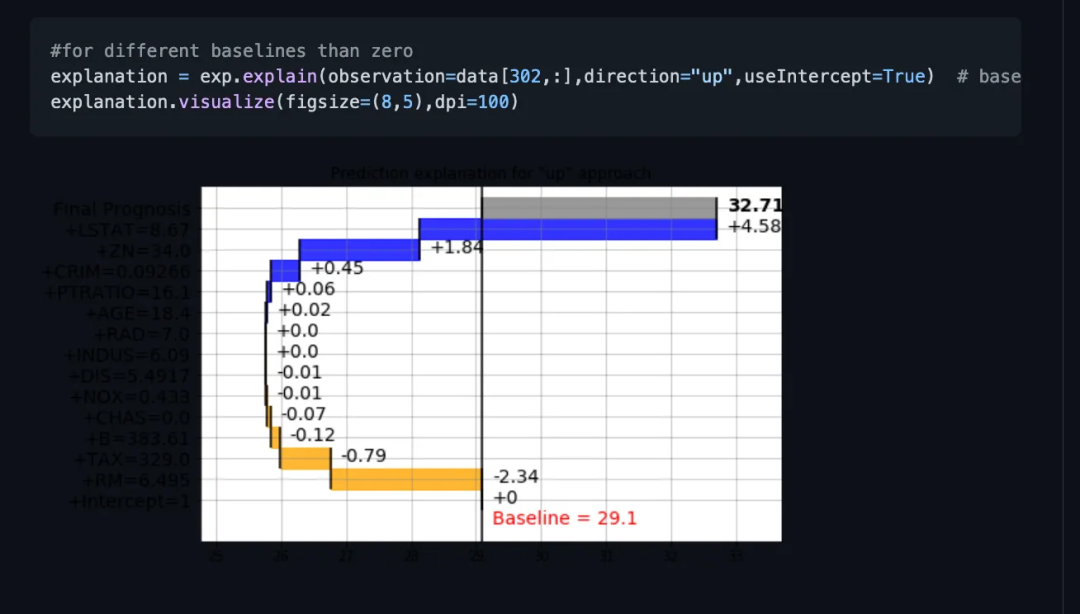
BreakDown是一种可以用来解释线性模型预测的工具。它的工作原理是将模型的输出分解为每个输入特征的贡献。这个包中有两个主要方法。Explainer()和Explanation()
model = tree.DecisionTreeRegressor() model = model.fit(train_data,y=train_labels) #necessary imports from pyBreakDown.explainer import Explainer from pyBreakDown.explanation import Explanation #make explainer object exp = Explainer(clf=model, data=train_data, colnames=feature_names) #What do you want to be explained from the data (select an observation) explanation = exp.explain(observation=data[302,:],direction="up")

7、Interpret-Text
Interpret-Text 结合了社区为 NLP 模型开发的可解释性技术和用于查看结果的可视化面板。可以在多个最先进的解释器上运行实验,并对它们进行比较分析。这个工具包可以在每个标签上全局或在每个文档本地解释机器学习模型。
以下是此包中可用的解释器列表:
-
Classical Text Explainer——(默认:逻辑回归的词袋)
-
Unified Information Explainer
-
Introspective Rationale Explainer
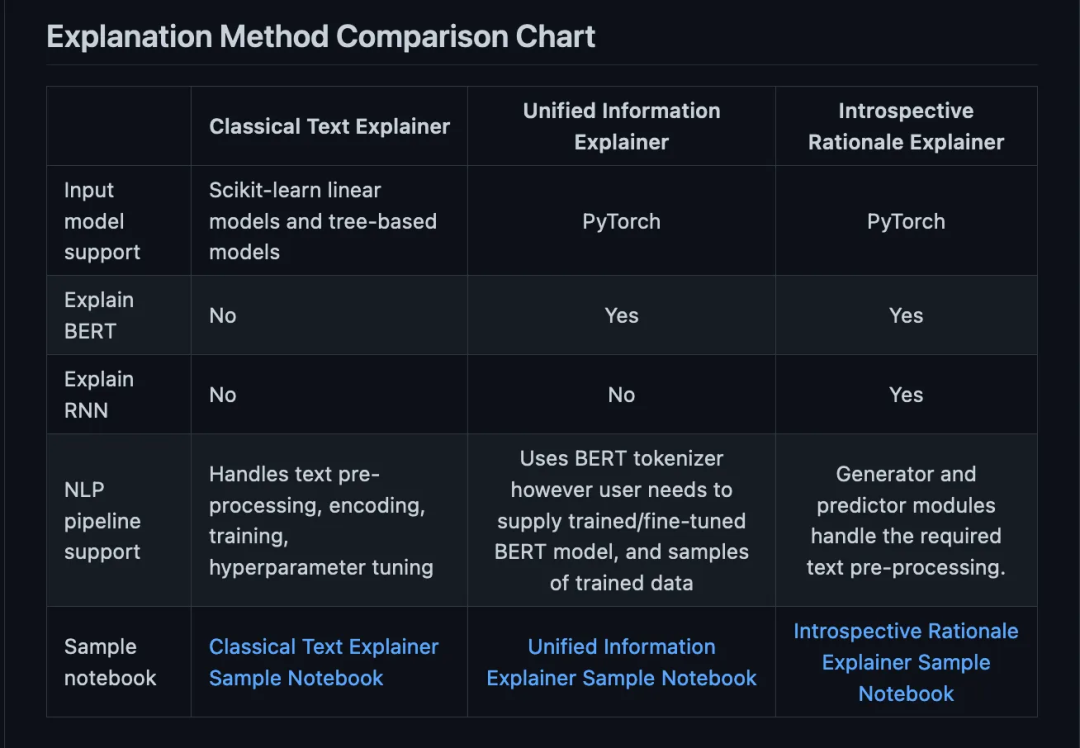
它的好处是支持CUDA,RNN和BERT等模型。并且可以为文档中特性的重要性生成一个面板
from interpret_text.widget import ExplanationDashboard from interpret_text.explanation.explanation import _create_local_explanation # create local explanation local_explanantion = _create_local_explanation( classification=True, text_explanation=True, local_importance_values=feature_importance_values, method=name_of_model, model_task="classification", features=parsed_sentence_list, classes=list_of_classes, ) # Dash it ExplanationDashboard(local_explanantion)

8、aix360 (AI Explainability 360)
AI Explainbability 360工具包是一个开源库,这个包是由IBM开发的,在他们的平台上广泛使用。AI Explainability 360包含一套全面的算法,涵盖了不同维度的解释以及代理解释性指标。
工具包结合了以下论文中的算法和指标:
-
Towards Robust Interpretability with Self-Explaining Neural Networks, 2018. ref
-
Boolean Decision Rules via Column Generation, 2018. ref
-
Explanations Based on the Missing: Towards Contrastive Explanations with Pertinent Negatives, 2018. ref
-
Improving Simple Models with Confidence Profiles, , 2018. ref
-
Efficient Data Representation by Selecting Prototypes with Importance Weights, 2019. ref
-
TED: Teaching AI to Explain Its Decisions, 2019. ref
-
Variational Inference of Disentangled Latent Concepts from Unlabeled Data, 2018. ref
-
Generating Contrastive Explanations with Monotonic Attribute Functions, 2019. ref
-
Generalized Linear Rule Models, 2019. ref
9、OmniXAI
OmniXAI (Omni explable AI的缩写),解决了在实践中解释机器学习模型产生的判断的几个问题。
它是一个用于可解释AI (XAI)的Python机器学习库,提供全方位的可解释AI和可解释机器学习功能,并能够解决实践中解释机器学习模型所做决策的许多痛点。OmniXAI旨在成为一站式综合库,为数据科学家、ML研究人员和从业者提供可解释的AI。
from omnixai.visualization.dashboard import Dashboard # Launch a dashboard for visualization dashboard = Dashboard( instances=test_instances, # The instances to explain local_explanations=local_explanations, # Set the local explanations global_explanations=global_explanations, # Set the global explanations prediction_explanations=prediction_explanations, # Set the prediction metrics class_names=class_names, # Set class names explainer=explainer # The created TabularExplainer for what if analysis ) dashboard.show()

10、XAI (eXplainable AI)
XAI 库由 The Institute for Ethical AI & ML 维护,它是根据 Responsible Machine Learning 的 8 条原则开发的。它仍处于 alpha 阶段因此请不要将其用于生产工作流程。
相关文章:
10个最频繁用于解释机器学习模型的 Python 库
文章目录什么是XAI?可解释性实践的步骤技术交流1、SHAP2、LIME3、Eli54、Shapash5、Anchors6、BreakDown7、Interpret-Text8、aix360 (AI Explainability 360)9、OmniXAI10、XAI (eXplainable AI)XAI的目标是为模型的行为和决定提供有意义的解释,本文整理…...

final关键字:我偏不让你继承
哈喽,小伙伴们大家好,我是兔哥呀,今天就让我们继续这个JavaSE成神之路! 这一节啊,咱们要学习的内容是Java所有final关键字。 之前呢,我们学习了继承,这大大提高了代码的灵活性和复用性。但是总…...

8大主流编程语言的适用领域,你可能选错了语言
很多人学编程经常是脑子一热然后就去网上一搜资源就开始学习了,但学到了后面发现目前所学的东西并不是自己最喜欢的,好像自己更喜欢另一个技术,感觉自己学错了,于是乎又去学习别的东西。 结果竹篮打水一场空,前面所付…...

关于Python库的问题
关于Python库的问题 问题1: ModuleNotFoundError: No module named ‘requests’ Python库 Pycharm使用Requests库时报错: No module named requests’解决方法 未安装requests库,使用"pip install requests"命令安装 依然提示P…...
)
好记性不如烂笔头(2)
概述:用来记录一些小技巧。 1.查看MyBatis执行的sql 类:org.apache.ibatis.mapping.MappedStatement方法:getBoundSql(Object parameterObject)在IDEA的Evaluate Expression查看sql:boundSql.getSql() 2.maven仓库地址为https&…...
Java for循环嵌套for循环,你需要懂的代码性能优化技巧
前言 本篇分析的技巧点其实是比较常见的,但是最近的几次的代码评审还是发现有不少兄弟没注意到。 所以还是想拿出来说下。 正文 是个什么场景呢? 就是 for循环 里面还有 for循环, 然后做一些数据匹配、处理 这种场景。 我们结合实例代码来…...

关于我拒绝了腾讯测试开发岗offer这件事
2022年刚开始有了向要跳槽的想法,之前的公司不能算大厂但在重庆也算是数一数二。开始跳槽的的时候我其实挺犹豫的 其实说是有跳槽的想法在2022年过年的时候就有了,因为每年公司3月会有涨薪的机会,所以想着看看那能不能涨(其实还是…...

从GPT到GPT-3:自然语言处理领域的prompt方法
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
Git代码提交规范
Git 代码规范Git 每次提交代码,都是需要写 Commit message(提交说明),否则就不允许提交。Commit message 的格式 (三部分):Heaher ----- 必填type ---必需scope --- 可选subject --- 必需Body ---- 可省略Footer ---- …...

【JavaScript速成之路】JavaScript内置对象--Math和Date对象
📃个人主页:「小杨」的csdn博客 🔥系列专栏:【JavaScript速成之路】 🐳希望大家多多支持🥰一起进步呀! 文章目录前言1,Math对象1.1,常用属性方法1.1.1,获取x的…...
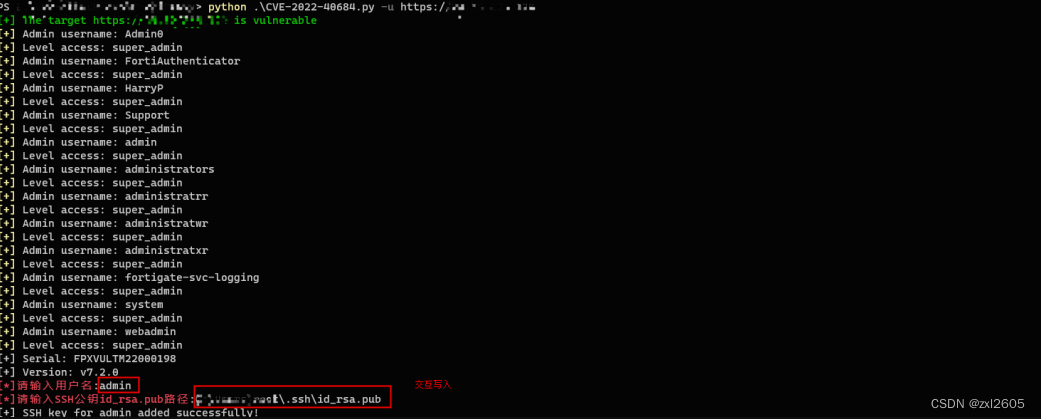
(自用POC)Fortinet-CVE-2022-40684
本文转载于:https://mp.weixin.qq.com/s?__bizMzIzNDU5Mzk2OQ&mid2247485332&idx1&sn85931aa474f1ae2c23a66bf6486eec63&chksme8f54c4adf82c55c44bc7b1ea919d44d377e35a18c74f83a15e6e20ec6c7bc65965dbc70130d&mpshare1&scene23&srcid…...

ConvNeXt V2实战:使用ConvNeXt V2实现图像分类任务(二)
文章目录训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整算法设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法运行以及结果查看测试热力图可视化展示完…...

【人工智能与深度学习】基于正则化潜在可变能量的模型
【人工智能与深度学习】基于正则化潜在可变能量的模型 正则化潜变量能量基础模型稀疏编码FISTALISTA稀疏编码示例卷积稀疏编码自然图像上的卷积稀疏编码可变自动编码器正则化潜变量能量基础模型 具有潜在变量的模型能够生成预测分布 y ‾ \overline{y}...
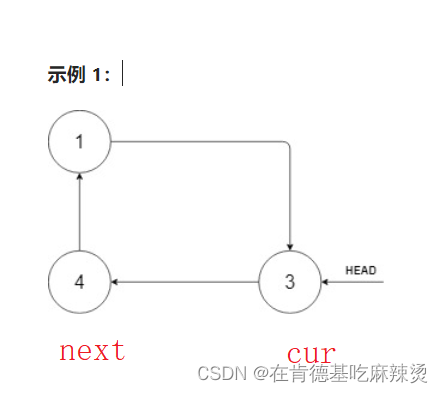
【Leetcode——排序的循环链表】
😊😊😊 文章目录一、力扣题之排序循环链表二、解题思路1. 使用双指针法2、找出最大节点,最大节点的下一个节点是最小节点,由此展开讨论总结一、力扣题之排序循环链表 题目如下:航班直达!&#…...
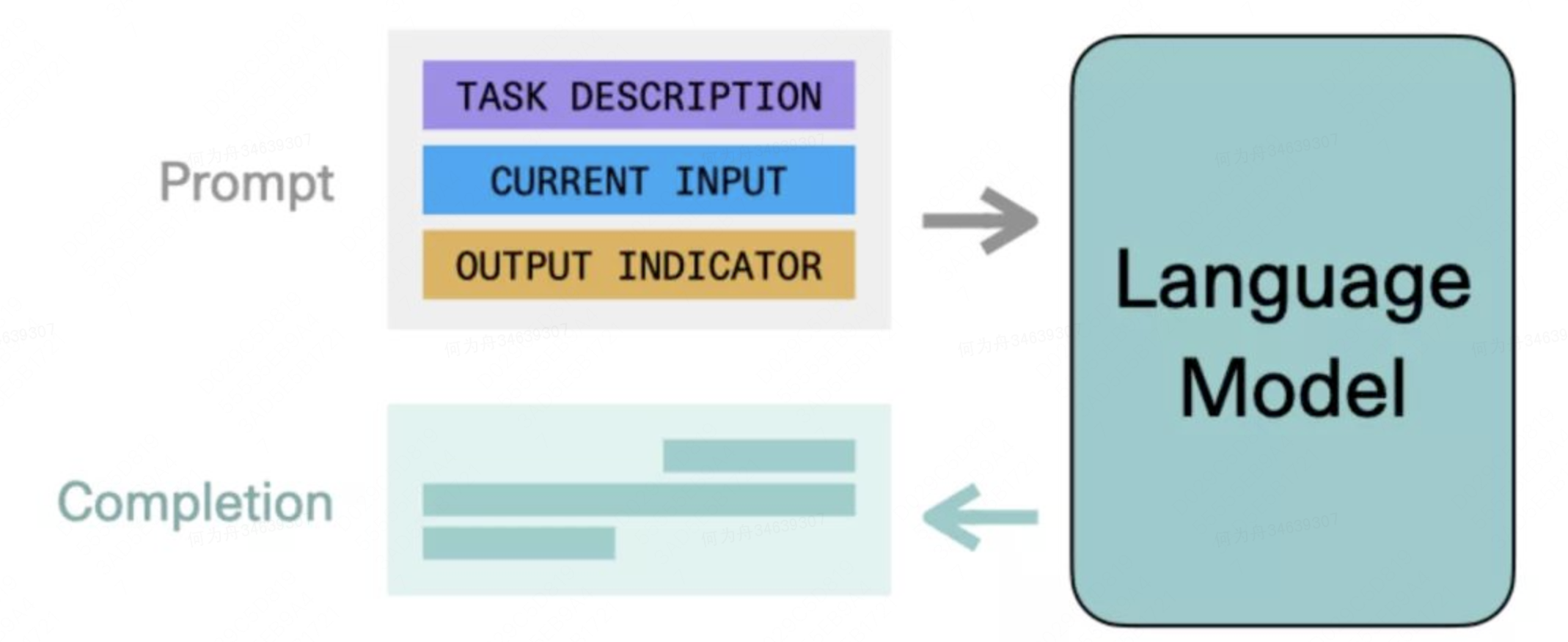
ChatGPT研究分享:机器第一次开始理解人类世界目录
0、为什么会对ChatGPT感兴趣一开始,我对ChatGPT是没什么关注的,无非就是有更大的数据集,完成了更大规模的计算,所以能够回答更多的问题。但后来了解到几个案例,开始觉得这个事情并不简单。我先分别列举出来,…...

【linux】Linux基本指令(上)
前言: 在之前我们已经简单了介绍了一下【Linux】,包括它的概念,由来啊等进行了讲解,接下来我们就将正式的踏入对其的学习!!! 本文目录👉操作系统的概念1.命令的语法1.1命令介绍1.2选…...
程序员必会技能—— 使用日志
目录 1、为什么要使用日志 2、自定义日志打印 2.1、在程序中得到日志对象 2.2、使用日志对象打印日志 2.3、日志格式 3、日志的级别 3.1、日志级别的分类 3.2、日志级别的设置 4、持久化日志 5、更简单的日志输出——lombok 5.1、如何在已经创建好的SpringBoot项目中添加…...
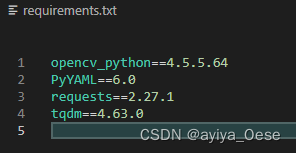
生成项目的包依赖文件requirements.txt
目录生成项目的包依赖文件requirements.txtrequirements.txt文件怎么来?使用pipreqs第三方库requirements.txt文件使用requirements.txt生成项目的包依赖文件requirements.txt 在安装部署代码时或者使用别人的项目时,会需要安装项目的依赖包,…...

安卓渐变的背景框实现
安卓渐变的背景框实现1.背景实现方法1.利用PorterDuffXfermode进行图层的混合,这是最推荐的方法,也是最有效的。2.利用canvas裁剪实现,这个方法有个缺陷,就是圆角会出现毛边,也就是锯齿。3.利用layer绘制边框1.背景 万…...

【拳打蓝桥杯】算法前置课——时间复杂度与空间复杂度
文章目录前言为什么需要复杂度分析?大O复杂度表示法时间复杂度分析几种常见时间复杂度实例分析空间复杂度分析内容小结最后说一句🐱🐉作者简介:大家好,我是黑洞晓威,一名大二学生,希望和大家一…...

二分查找算法:选择开区间还是闭区间?
如大家所熟悉的,在二分查找算法的实现过程中,通常会选择左闭右开区间 [st, ed) 或是全闭区间 [st, ed] 这两种搜索区间的表示方式。左闭右开区间比较符合大家的编程习惯,而全闭区间在解决某些问题上更加方便。首先看一下不同区间的选择对 主循…...

H3C交换机三层组网配置保姆级复盘:从拓扑设计到排错命令一条龙
H3C交换机三层组网实战指南:从规划到排错的完整工作流 当企业网络规模逐渐扩大,部门间的隔离与互通需求变得复杂时,二层交换网络往往显得力不从心。这时,三层交换技术的引入就成为网络工程师的必修课。本文将带你深入一个真实的办…...

Moveit2 automaticaddison mycobot_ros2 代码讲解
github地址 https://github.com/automaticaddison/mycobot_ros2/tree/jazzy 一.mycobot_moveit_config 1.moveit2基本控制 在mycobot_moveit_config下面创建config/mycobot_280 initial_positions.yaml 定义了机械臂所有关节的初始位置 joint_limits.yaml 定义每个关节的…...
)
别再到处找激活码了!手把手教你用vlmcsd在Windows Server上自建KMS服务器(附全版本密钥)
企业级Windows系统激活解决方案:私有化部署KMS服务实战指南 在IT基础设施管理中,系统激活常常被忽视却至关重要。想象一下这样的场景:当50台办公电脑同时弹出激活警告,或新采购的服务器因未激活导致功能受限时,传统的人…...

FGO自动化终极指南:告别枯燥刷本,每天节省3小时游戏时间
FGO自动化终极指南:告别枯燥刷本,每天节省3小时游戏时间 【免费下载链接】FGA Auto-battle app for F/GO Android 项目地址: https://gitcode.com/gh_mirrors/fg/FGA 你是否厌倦了在《Fate/Grand Order》(FGO)中重复点击刷…...

【大模型服务治理实战指南】:奇点智能大会首发的7大避坑法则与3套可落地架构模板
更多请点击: https://intelliparadigm.com 第一章:大模型服务治理:奇点智能大会 在2024年奇点智能大会上,大模型服务治理成为核心议题。随着LLM推理服务规模化部署,企业面临模型版本混乱、流量调度失衡、资源隔离缺失…...

从混淆矩阵到mIOU:手把手解析语义分割核心评价指标
1. 从像素战场到成绩单:理解混淆矩阵 第一次接触语义分割任务时,我盯着那些五彩斑斓的分割图直发懵——怎么判断这个模型到底好不好?直到导师扔给我一张"混淆矩阵"的表格,才恍然大悟这就像学生时代的考试成绩单。想象你…...

简单学习 --> SpringAOP
spring 两大核心: ioc 和 aop ; (ioc : 控制反转 , aop : 面相切面编程)AOPAOP: 面向切面编程 , 可以看作是面向对象编程的补充 ;aop是一种思想,是对某一类事情的集中处理 (例如: 统一功能处理(拦截器,统一结果,统一异常) , 统一功能处理事AOP 的实现 )切面: 某一类公共的事情 …...
— 基于SPI驱动TFTLCD实现动态数据可视化)
RT-Thread开发实战(8)— 基于SPI驱动TFTLCD实现动态数据可视化
1. 从零开始玩转SPI驱动TFTLCD 第一次用RT-Thread驱动TFTLCD屏幕时,我盯着那堆密密麻麻的引脚直发懵。后来才发现,只要搞明白SPI通信和屏幕驱动芯片的关系,这事儿其实比想象中简单多了。我们这次要对付的是ST7789V2这款驱动芯片,它…...

Groundhog:基于Git仓库的开发者时间自动追踪工具
1. 项目概述:一个面向开发者的时间管理利器如果你是一名开发者,或者你的工作与代码、项目、任务紧密相关,那么你一定对“时间都去哪儿了”这个问题深有感触。我们每天在各种编辑器、终端、浏览器标签页之间切换,处理着功能开发、B…...