【Python学习笔记】菜鸟教程Scrapy案例 + B站amazon案例视频
背景前摇(省流可以跳过这部分)
实习的时候厚脸皮请教了一位办公室负责做爬虫这块的老师,给我推荐了Scrapy框架。
我之前学过一些爬虫基础,但是用的是比较常见的BeautifulSoup和Request,于是得到Scrapy这个关键词后,先问了一下Kimi这些爬虫框架的区别和优劣:

可以看出,BeautifulSoup适合学校教授课程用的小项目,但遇到大型的爬虫还是需要技术老师推荐的Scrapy。
时间充裕的话可以先从BeautifulSoup入门学起来。
以前BeautifulSoup我学的时候B站有个UP讲得挺好的,手把手教实操,结果今天一看都找不到视频了,实在是可惜。所以这次我学习Scrapy就决定把看到的好教程和遇到的问题都记下来。
菜鸟教程
链接:https://www.runoob.com/w3cnote/scrapy-detail.html
点此进入菜鸟教程
这个算是我看过的教程帖子里面比较通俗易懂、简明扼要又流程规范的了,当然也不是十全十美,跟着步骤操作还是会遇到一些小问题。
1.安装库

这一步没啥问题,正常按着步骤装就是,我电脑环境算是复杂的,都没遇到奇怪的报错。但是有条件的话建议装个Anaconda,然后为Scrapy专门建一个虚拟环境,免得日后跟其他库不兼容的情况发生。
以下步骤展示的是有Anaconda的情况下安装虚拟环境,没有Anaconda的可以跳过这步。



从创建项目这一步开始,就可以和菜鸟教程介绍的流程第一步接上了。

菜鸟教程的第二步没什么问题,跟这做就行。

到了第三步这里,有一个地方需要做一点小改动。
运行到这一步,会发现一直报一个莫名其妙的错误:


AI的方法并没有什么卵用,可见这错误多半不是我们该背的锅。

解决方案也很简单——将写入模式改为 ‘wb+’ 就不会报错了
参考链接:https://zoyi14.smartapps.cn/pages/note/index?origin=share&slug=b53ac2effb85&_swebfr=1&_swebFromHost=baiduboxapp
简书大神的回答

然后继续往下走菜鸟教程,直到执行完爬虫,这个时候应该文件目录里会存在一个html文件。


但是,千万不要双击该html文件直接打开!!否则你会惊喜地发现——什么也没有。
(很奇怪我这次的文件居然打开有内容,之前尝试点开好几次都是白板……不知道触发了什么奇怪的buff)

如果确实遇到了白板也别害怕,用Pycharm或者VScode这类支持写程序的软件打开看看,你就会发现其实爬取是成功了的。
这一步能看见网页源代码的话,继续跟着菜鸟教程走就是了。

直到有一个步骤的命令有一个奇怪的$符号打头,询问Kimi后发现并没有什么意义,我猜或许是编写教程的人手误?不管这个符号,正常输入命令就行:

附上我的示例执行效果图:

最后看到Spider Closed就是OK了(我的代码是最终版,加了一些命令,所以输出比较多,看不见这句话“”传智播客官网-好口碑IT培训机构,一样的教育,不一样的品质”,如果正常走到这一步的话能在黑窗口看见这句话顺利打印出来。

后面按着教程来,输出json,csv文件啥的步骤都没什么问题。

(思考题这弱弱问一句,我咋没找到yield函数在哪呢???
不过这个问题不大,上网查查别的教程或者问问Kimi都行,菜鸟这里自带的补充学习链接也可以看看。)

我会把我照着菜鸟教程写的项目打包上传CSDN存档,有需要的朋友可以自行下载。
(我每次都设置了免费不需要积分,但是好像CSDN会自动调整价格……)
菜鸟教程部分到此结束
下面进入B站视频部分
这个视频也是我自己看了一些后觉得讲的很清楚并且流程很规范的,从零开始建工程目录,而且涉及到翻页爬虫的处理。
链接:https://www.bilibili.com/list/watchlater?oid=30493305&bvid=BV1es411F73F&spm_id_from=333.337.top_right_bar_window_view_later.content.click
B站传送门
3分钟左右的时候在settings.py里加了一行LOG_LEVEL = ‘WARN’,起一个减少日志负担的作用。


很不幸的是我和评论区的这位遇到了一模一样的问题,我也还没有找到靠谱的解决方案,但是没关系,重点学视频里翻页爬取的方法,把代码思路写熟手以后,下次复用到其他网页就不一定会遇到503错误了


我这搜罗了一些可能的解决办法给大家参考,如果有成功解决的小伙伴可以评论区分享一下。
https://docs.pingcode.com/ask/218781.html
可以试试,不保证结果

没有源码,特别难打的这句话我手敲了:
print(respomse.xpath(‘//ul[@id=“s-results-list-atf”]/li//h2/text()’).extract())

关于这部分HTML和XPath我之前学BeautifulSoup的时候有一些基础,所以就没有看该视频之前的内容,可以去这位UP的主页自行寻找,或者遇事不决问Kimi。
我个人感觉BeautifulSoup和Scrapy的思路很相似,都是给url,然后获取html内容,再通过类似正则表达式的思路把需要的文字提取出来,放在变量里,再把同类的变量归类到列表里,排得整整齐齐,就得到了结构化的数据。
这个价格分为了整数和小数两部分,UP的处理方法可以学习和参考,我觉得是个很好的思路,可以积累经验,下次遇到就知道怎么处理了。(还有一些类似的小细节,比如ul下级是li这种HTML知识)
分别获取小数点前和小数点后的数据price1,price2,然后拼起来。
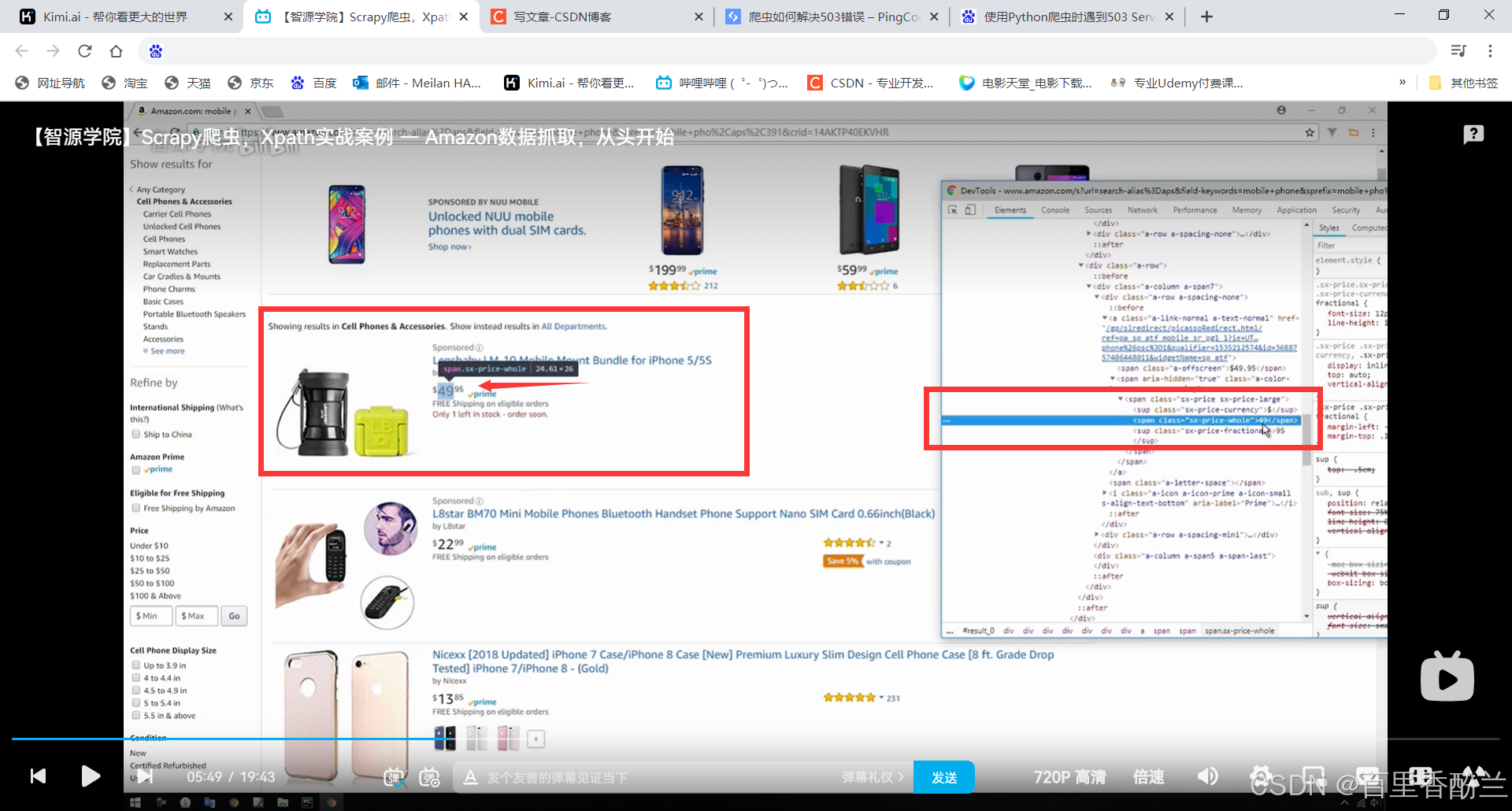


别忘了设置为float,存进数据库(如果有)的话更容易处理(比如比较大小)。
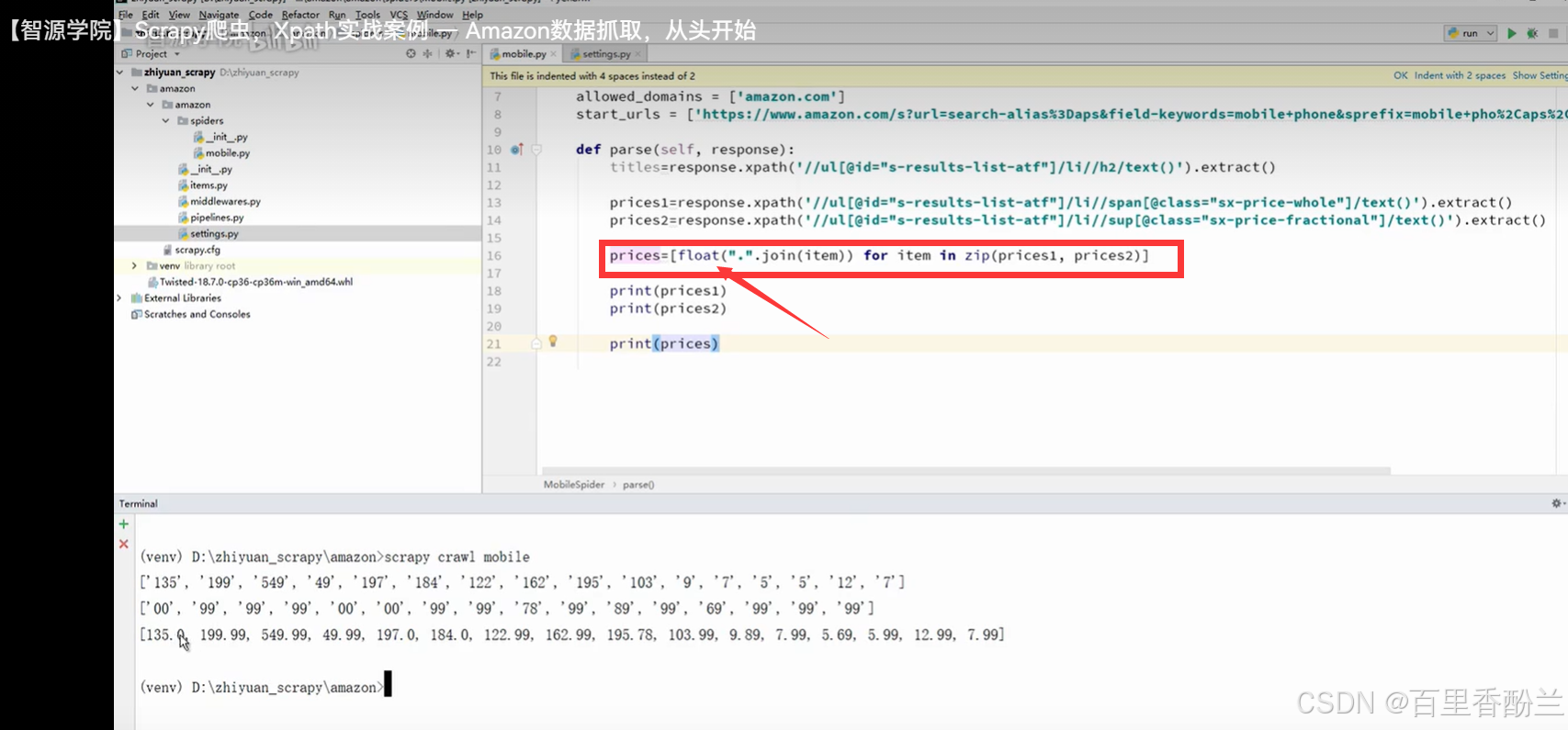
后面遇到比较大的数有逗号碍事(比如’1,299’这种),就用replace方法,通过空字符串替代’,',避免组合遇到困难。
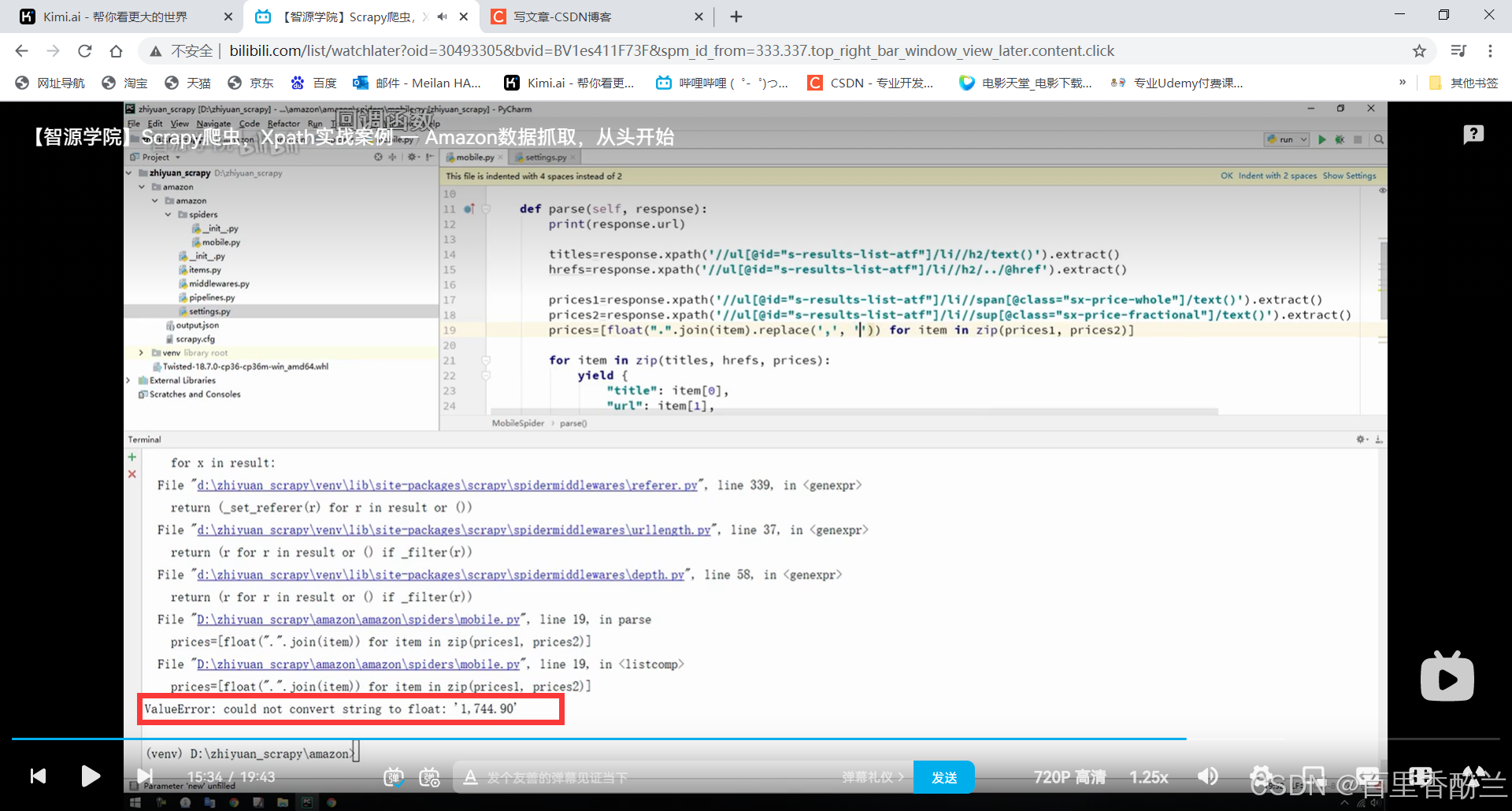

比较难打的代码块:
def parse(self, response):titles = response.xpath('//ul[@id="s-results-list-atf"]/li//h2/text()').extract()hrefs = response.xpath('//ul[@id="s-results-list-atf"]/li//h2/../@href').extract()prices1 = response.xpath('//ul[@id="s-results-list-atf"]/li//span[@class="sx-price-whole"]/text()').extract()prices2 = response.xpath('//ul[@id="s-results-list-atf"]/li//sup[@class="sx-price-fractional"]/text()').extract()price = [float(".".join(item)) for item in zip(price1,price2)]print(prices1)print(prices2)print(price)
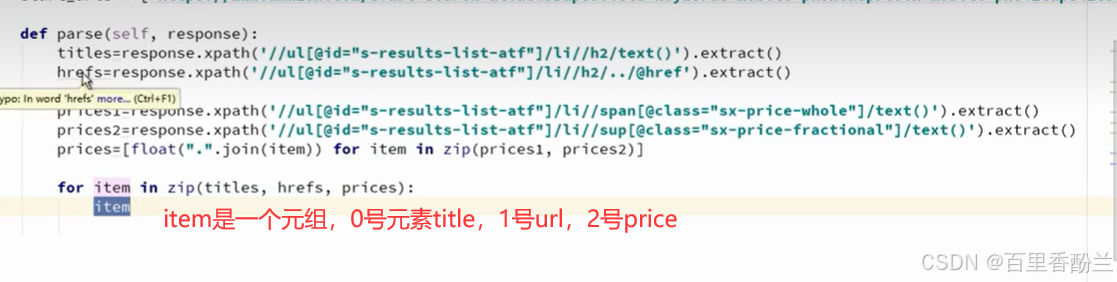
把获取到的信息通过zip函数整理打包成元组:
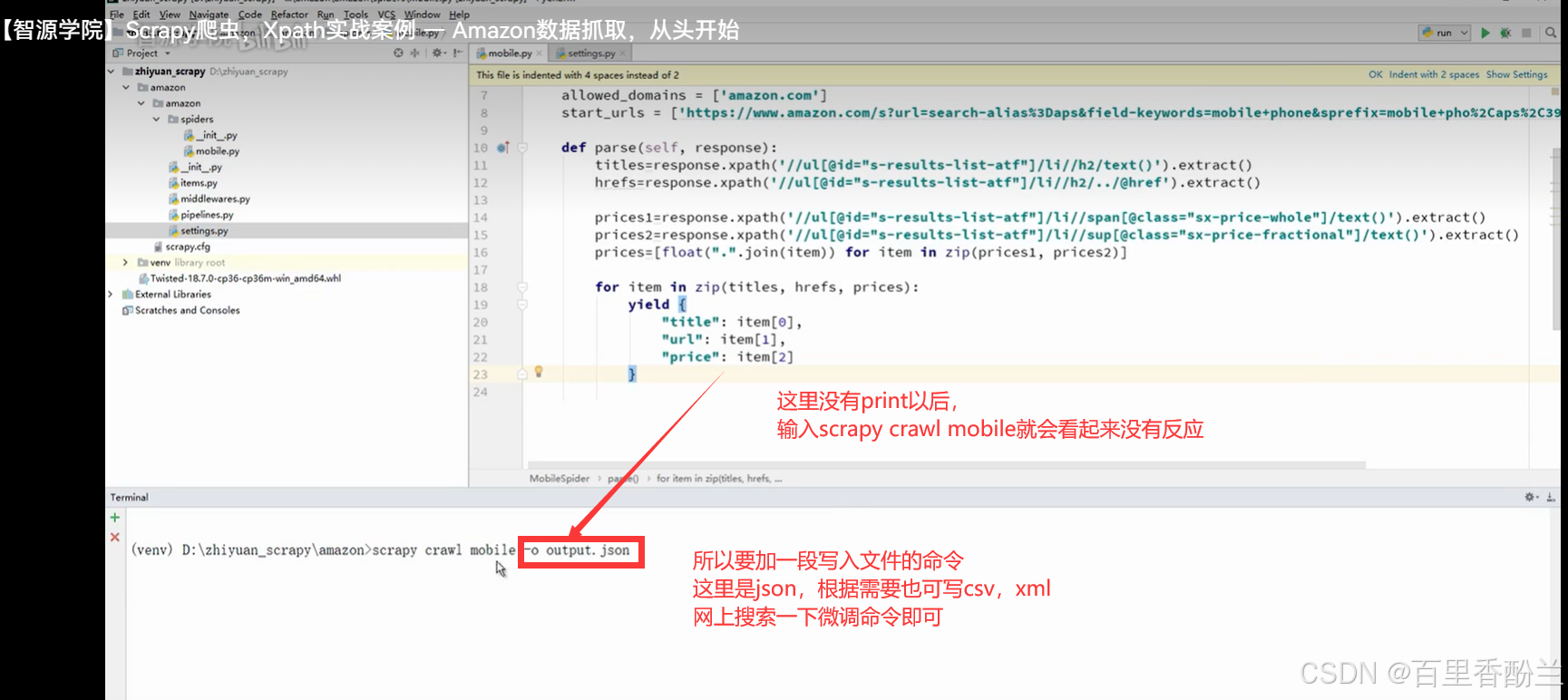
爬取多页的话就需要获取点击下一页的按钮,这也正是我看中这个教程的地方,前面写到Scrapy本身就更适合大规模数据爬取,那只爬一页也太屈才了。

检查网页源代码,找到这个“下一页”按钮的源链接和id。

然后照样的套路,XPath获取到链接,不过这里是个相对地址。
《相对地址也没关系,前面的域名我们自己加就完了》这里确实能解决问题,但我还是想知道这种走捷径的方法如果有应付不了的时候,应该怎么办呢?

遇到这个NoneType问题,老师判断是取到头了,没有下一页的内容造成的。
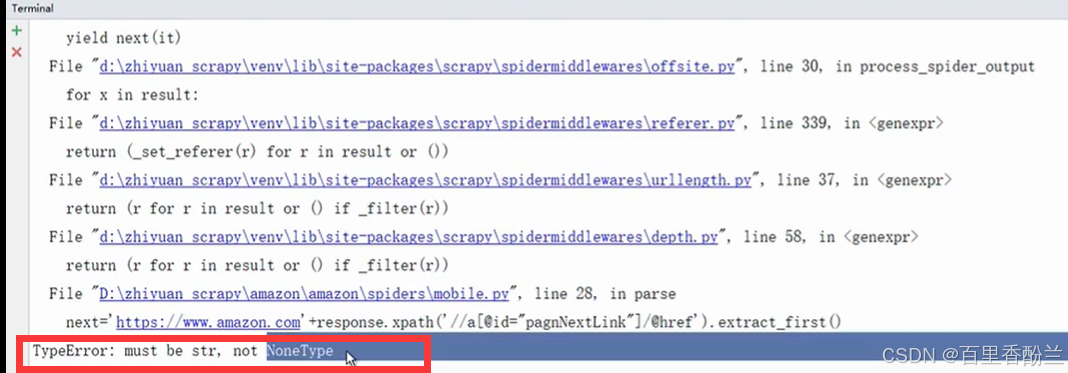
解决办法是在取下一页以前加个判断语句:

mobile.py完整代码:

import scrapy
from scrapy import Requestclass MobileSpider(scrapy.Spider):name = "mobile"allowed_domains = ["amazon.com"]start_urls = ["https://www.amazon.com/s?k=mobile+phone&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&crid=266D1NQXSO7K4&sprefix=mobile+phon%2Caps%2C250&ref=nb_sb_noss_2"]def parse(self, response):print(response.url)titles = response.xpath('//ul[@id="s-results-list-atf"]/li//h2/text()').extract()hrefs = response.xpath('//ul[@id="s-results-list-atf"]/li//h2/../@href').extract()prices1 = response.xpath('//ul[@id="s-results-list-atf"]/li//span[@class="sx-price-whole"]/text()').extract()prices2 = response.xpath('//ul[@id="s-results-list-atf"]/li//sup[@class="sx-price-fractional"]/text()').extract()prices = [float(".".join(item).replace(',','')) for item in zip(price1,price2)]for item in zip(titles, hrefs, prices):yield{"title": item[0],"url": item[1],"price": item[2]}next = response.xpath('//a[@id="pagnNextLink"]/@href').extract_first()if next != None:next_url = 'https://www.amazon.com' + nextyield Request(next_url)
结合这两个案例,我找了个大陆能登上去的网站七禾网,自己写了一段Scrapy代码爬取测试,成功获取到了专栏文章标题。
被爬取的七禾网链接:https://www.7hcn.com//category/88-27.html
点击打开,这次爬取测试应该不会503错误了

成果展示:

爬取到的HTML:

爬取到的Json:

爬取到的XML:

爬取到的CSV:

唯一美中不足的是这个网站的翻页只有逐页翻或者直达下一页,没有Next Page这个选项,所以无法测试全部学到的功能,但用来做练习来说已经完全够用了。
我自己写的练习代码也会同步上传到CSDN,欢迎有需要的朋友下载~

。
相关文章:
【Python学习笔记】菜鸟教程Scrapy案例 + B站amazon案例视频
背景前摇(省流可以跳过这部分) 实习的时候厚脸皮请教了一位办公室负责做爬虫这块的老师,给我推荐了Scrapy框架。 我之前学过一些爬虫基础,但是用的是比较常见的BeautifulSoup和Request,于是得到Scrapy这个关键词后&am…...
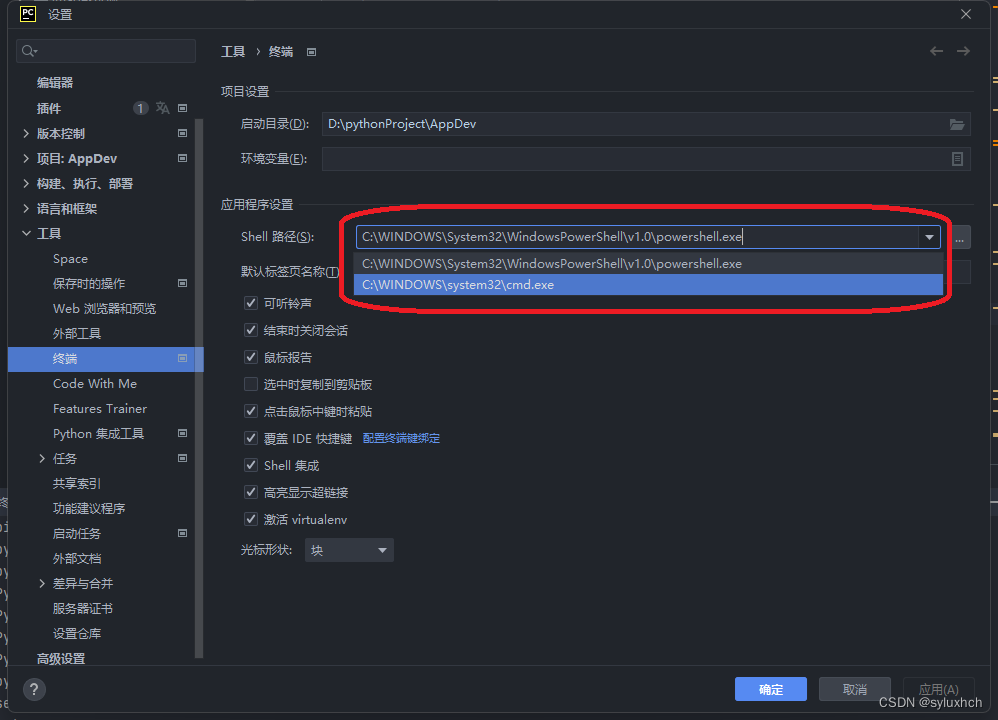
Pycharm的终端(Terminal)中切换到当前项目所在的虚拟环境
1.在Pycharm最下端点击终端/Terminal, 2.点击终端窗口最上端最右边的∨, 3.点击Command Prompt,切换环境, 可以看到现在环境已经由默认的PS(Window PowerShell)切换为项目所使用的虚拟环境。 4.更近一步,如果想让Pycharm默认显示…...

Nginx 高效加速策略:动静分离与缓存详解
在现代Web开发中,网站性能是衡量用户体验的关键指标之一。Nginx,以其出色的性能和灵活性,成为众多网站架构中不可或缺的一部分。本文将深度解析如何利用Nginx实现动静分离与缓存,从而大幅提升网站加载速度和响应效率。 理解动静分…...

Unity3D 游戏摇杆的制作与实现详解
在Unity3D游戏开发中,摇杆是一种非常常见的输入方式,特别适用于移动设备的游戏控制。本文将详细介绍如何在Unity3D中制作和实现一个虚拟摇杆,包括技术详解和代码实现。 对惹,这里有一个游戏开发交流小组,大家可以点击…...

从nginx返回404来看http1.0和http1.1的区别
序言 什么样的人可以称之为有智慧的人呢?如果下一个定义,你会如何来定义? 所谓智慧,就是能区分自己能改变的部分,自己无法改变的部分,努力去做自己能改变的,而不要天天想着那些无法改变的东西&a…...
MySQL 代理层:ProxySQL
文章目录 说明安装部署1.1 yum 安装1.2 启停管理1.3 查询版本1.4 Admin 管理接口 入门体验功能介绍3.1 多层次配置系统 读写分离将实例接入到代理服务定义主机组之间的复制关系配置路由规则事务读的配置延迟阈值和请求转发 ProxySQL 核心表mysql_usersmysql_serversmysql_repli…...

异步主从复制
主从复制的概念 主从复制是一种在数据库系统中常用的数据备份和读取扩展技术,通过将一个数据库服务器(主服务器)上的数据变更自动同步到一个或多个数据库服务器(从服务器)上,以此来实现数据的冗余备份、读…...

论文解析——Full Stack Optimization of Transformer Inference: a Survey
作者及发刊详情 摘要 正文 主要工作贡献 这篇文章的贡献主要有两部分: 分析Transformer的特征,调查高效transformer推理的方法通过应用方法学展现一个DNN加速器生成器Gemmini的case研究 1)分析和解析Transformer架构的运行时特性和瓶颈…...

selenium处理cookie问题实战
1. cookie获取不完整 需要进入的资损平台(web)首页,才会出现有效的ctoken等信息 1.1. 原因说明 未进入指定页面而获取的 cookie 与进入页面后获取的 cookie 可能会有一些差异,这取决于网站的具体实现和 cookie 的设置方式。 通常情况下,一些…...

(十五)GLM库对矩阵操作
GLM简单使用 glm是一个开源的对矩阵运算的库,下载地址: https://github.com/g-truc/glm/releases 直接包含其头文件即可使用: #include <glad/glad.h>//glad必须在glfw头文件之前包含 #include <GLFW/glfw3.h> #include <io…...

android中activity与fragment之间的各种跳转
我们以音乐播放、视频播放、用户注册与登录为例【Musicfragment(音乐列表页)、Videofragment(视频列表页)、MusicAvtivity(音乐详情页)、VideoFragment(视频详情页)、LoginActivity&…...

动态规划算法-以中学排课管理系统为例
1.动态规划算法介绍 1.算法思路 动态规划算法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解。每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若…...

本安防爆手机:危险环境下的安全通信解决方案
在石油化工、煤矿、天然气等危险环境中,通信安全是保障工作人员生命安全和生产顺利进行的关键。防爆智能手机作为专为这些环境设计的通信工具,提供了全方位的安全通信解决方案。 防爆设计与材料: 防爆智能手机采用特殊的防爆结构和材料&…...

算法学习笔记(8)-动态规划基础篇
目录 基础内容: 动态规划: 动态规划理解的问题引入: 解析:(暴力回溯) 代码示例: 暴力搜索: Dfs代码示例:(搜索) 暴力递归产生的递归树&…...
)
数据库常见问题(持续更新)
数据库常见问题(持续更新) 1、数据库范式? 1NF:不可分割2NF:没有非主属性对候选码存在部分依赖3NF:没有非主属性传递依赖候选码BCNF:消除了主属性对对候选码的传递依赖或部分依赖 2、InnoDB事务的实现? …...
)
定个小目标之刷LeetCode热题(40)
94. 二叉树的中序遍历 给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。 直接上代码吧,中序遍历左根右 class Solution {public List<Integer> inorderTraversal(TreeNode root) {List<Integer> res new ArrayList<Integer>(…...

Linux--线程(概念篇)
目录 1.背景知识 再谈地址空间: 关于页表(32bit机器上) 2.线程的概念和Linux中线程的实现 概念部分: 代码部分: 问题: 3.关于线程的有点与缺点 4.进程VS线程 1.背景知识 再谈地址空间:…...

Mojo: 轻量级Perl框架的魔力
在Perl的丰富生态系统中,Mojolicious(简称Mojo)是一个轻量级的实时Web框架,以其极简的API和强大的功能而受到开发者的喜爱。Mojo不仅适用于构建高性能的Web应用,还可以用来编写简单的脚本和命令行工具。本文将带你探索…...

Python 游戏服务器架构优化
优化 Python 游戏服务器的架构涉及多个方面,包括性能、可伸缩性、并发处理和网络通信。下面是一些优化建议: 1、问题背景 在设计 Python 游戏服务器时,如何实现服务器的横向扩展,以利用多核处理器的资源,并确保服务器…...

13 学习总结:指针 · 其一
目录 一、内存和地址 (一)内存 (二)内存单元 (三)地址 (四)拓展:CPU与内存的联系 二、指针变量和地址 (一)创建变量的本质 (二…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...

Armv9-A架构解析:SVE/SME与安全增强技术
1. Armv9-A架构演进与核心特性全景Armv9-A架构代表了Arm公司面向未来十年计算需求的设计哲学,其核心在于三个维度的突破:性能、安全与专用计算。作为长期从事Arm架构开发的工程师,我见证了从Armv7到Armv9的技术跃迁。与固定宽度向量指令的NEO…...