昇思25天学习打卡营第15天|应用实践之ShuffleNet图像分类
基本介绍
今天的应用实践的领域是计算机视觉领域,更确切的说是图像分类任务,不过,与昨日不同的是,今天所使用的模型是ShuffleNet模型。ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到最好的模型精度。今天会简单介绍一些ShuffleNet模型,并使用CIFAR-10数据集进行训练与评估,最后进行模型预测
ShuffleNet模型简介
ShuffleNetV1的设计核心是引入了两种操作:Pointwise Group Convolution和Channel Shuffle,这在保持精度的同时大大降低了模型的计算量。因此,ShuffleNetV1和MobileNet类似,都是通过设计更高效的网络结构来实现模型的压缩和加速
-
Pointwise Group Convolution
Group Convolution(分组卷积)原理如下图所示,相比于普通的卷积操作,分组卷积的情况下,每一组的卷积核大小为in_channels/g*k*k,一共有g组,所有组共有(in_channels/g*k*k)*out_channels个参数,是正常卷积参数的1/g。分组卷积中,每个卷积核只处理输入特征图的一部分通道,其优点在于参数量会有所降低,但输出通道数仍等于卷积核的数量

- Channel Shuffle
Group Convolution的弊端在于不同组别的通道无法进行信息交流,堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分成了g个互不相干的道路,每一个人各走各的,这可能会降低网络的特征提取能力。这也是Xception,MobileNet等网络采用密集的1x1卷积(Dense Pointwise Convolution)的原因。为了解决不同组别通道“近亲繁殖”的问题,ShuffleNet优化了大量密集的1x1卷积(在使用的情况下计算量占用率达到了惊人的93.4%),引入Channel Shuffle机制(通道重排)。这项操作直观上表现为将不同分组通道均匀分散重组,使网络在下一层能处理不同组别通道的信息。

以上两个结构就是ShuffleNet的主要结构,ShuffleNet的模型代码(MindSpore版)如下:
class ShuffleNetV1(nn.Cell):def __init__(self, n_class=1000, model_size='2.0x', group=3):super(ShuffleNetV1, self).__init__()print('model size is ', model_size)self.stage_repeats = [4, 8, 4]self.model_size = model_sizeif group == 3:if model_size == '0.5x':self.stage_out_channels = [-1, 12, 120, 240, 480]elif model_size == '1.0x':self.stage_out_channels = [-1, 24, 240, 480, 960]elif model_size == '1.5x':self.stage_out_channels = [-1, 24, 360, 720, 1440]elif model_size == '2.0x':self.stage_out_channels = [-1, 48, 480, 960, 1920]else:raise NotImplementedErrorelif group == 8:if model_size == '0.5x':self.stage_out_channels = [-1, 16, 192, 384, 768]elif model_size == '1.0x':self.stage_out_channels = [-1, 24, 384, 768, 1536]elif model_size == '1.5x':self.stage_out_channels = [-1, 24, 576, 1152, 2304]elif model_size == '2.0x':self.stage_out_channels = [-1, 48, 768, 1536, 3072]else:raise NotImplementedErrorinput_channel = self.stage_out_channels[1]self.first_conv = nn.SequentialCell(nn.Conv2d(3, input_channel, 3, 2, 'pad', 1, weight_init='xavier_uniform', has_bias=False),nn.BatchNorm2d(input_channel),nn.ReLU(),)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')features = []for idxstage in range(len(self.stage_repeats)):numrepeat = self.stage_repeats[idxstage]output_channel = self.stage_out_channels[idxstage + 2]for i in range(numrepeat):stride = 2 if i == 0 else 1first_group = idxstage == 0 and i == 0features.append(ShuffleV1Block(input_channel, output_channel,group=group, first_group=first_group,mid_channels=output_channel // 4, ksize=3, stride=stride))input_channel = output_channelself.features = nn.SequentialCell(features)self.globalpool = nn.AvgPool2d(7)self.classifier = nn.Dense(self.stage_out_channels[-1], n_class)def construct(self, x):x = self.first_conv(x)x = self.maxpool(x)x = self.features(x)x = self.globalpool(x)x = ops.reshape(x, (-1, self.stage_out_channels[-1]))x = self.classifier(x)return x数据集准备
采用CIFAR-10数据集对ShuffleNet进行预训练。CIFAR-10共有60000张32*32的彩色图像,均匀地分为10个类别,其中50000张图片作为训练集,10000图片作为测试集。可直接使用mindspore.dataset.Cifar10Dataset接口下载并加载CIFAR-10的训练集。这部分的操作和昨天几乎一样,就不进行展示
模型训练与评估
采用随机初始化的参数做预训练。首先调用ShuffleNetV1定义网络,参数量选择"2.0x",并定义损失函数为交叉熵损失,学习率经过4轮的warmup后采用余弦退火,优化器采用Momentum,总共训练5轮。最后用train.model中的Model接口将模型、损失函数、优化器封装在model中,并用model.train()对网络进行训练。将ModelCheckpoint、CheckpointConfig、TimeMonitor和LossMonitor传入回调函数中,将会打印训练的轮数、损失和时间,并将ckpt文件保存在当前目录下。具体训练代码如下:
def train():mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target="Ascend")net = ShuffleNetV1(model_size="2.0x", n_class=10)loss = nn.CrossEntropyLoss(weight=None, reduction='mean', label_smoothing=0.1)min_lr = 0.0005base_lr = 0.05lr_scheduler = mindspore.nn.cosine_decay_lr(min_lr,base_lr,batches_per_epoch*250,batches_per_epoch,decay_epoch=250)lr = Tensor(lr_scheduler[-1])optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.00004, loss_scale=1024)loss_scale_manager = ms.amp.FixedLossScaleManager(1024, drop_overflow_update=False)model = Model(net, loss_fn=loss, optimizer=optimizer, amp_level="O3", loss_scale_manager=loss_scale_manager)callback = [TimeMonitor(), LossMonitor()]save_ckpt_path = "./"config_ckpt = CheckpointConfig(save_checkpoint_steps=batches_per_epoch, keep_checkpoint_max=5)ckpt_callback = ModelCheckpoint("shufflenetv1", directory=save_ckpt_path, config=config_ckpt)callback += [ckpt_callback]print("============== Starting Training ==============")start_time = time.time()# 由于时间原因,epoch = 5,可根据需求进行调整model.train(5, dataset, callbacks=callback)use_time = time.time() - start_timehour = str(int(use_time // 60 // 60))minute = str(int(use_time // 60 % 60))second = str(int(use_time % 60))print("total time:" + hour + "h " + minute + "m " + second + "s")print("============== Train Success ==============")评估的时候直接使用model.eval()进行评估,具体代码如下:
def test():mindspore.set_context(mode=mindspore.GRAPH_MODE, device_target="Ascend")dataset = get_dataset("./dataset/cifar-10-batches-bin", 128, "test")net = ShuffleNetV1(model_size="2.0x", n_class=10)param_dict = load_checkpoint("shufflenetv1-5_390.ckpt")load_param_into_net(net, param_dict)net.set_train(False)loss = nn.CrossEntropyLoss(weight=None, reduction='mean', label_smoothing=0.1)eval_metrics = {'Loss': nn.Loss(), 'Top_1_Acc': Top1CategoricalAccuracy(),'Top_5_Acc': Top5CategoricalAccuracy()}model = Model(net, loss_fn=loss, metrics=eval_metrics)start_time = time.time()res = model.eval(dataset, dataset_sink_mode=False)use_time = time.time() - start_timehour = str(int(use_time // 60 // 60))minute = str(int(use_time // 60 % 60))second = str(int(use_time % 60))log = "result:" + str(res) + ", ckpt:'" + "./shufflenetv1-5_390.ckpt" \+ "', time: " + hour + "h " + minute + "m " + second + "s"print(log)filename = './eval_log.txt'with open(filename, 'a') as file_object:file_object.write(log + '\n')模型预测
训练完毕则可进行模型预测,并将预测结果可视化,结果如下:

可以看出,shuffleNet效果还是不错的,在轻量化的前提下也保证了一定的精度。
Jupyter运行情况
相关文章:

昇思25天学习打卡营第15天|应用实践之ShuffleNet图像分类
基本介绍 今天的应用实践的领域是计算机视觉领域,更确切的说是图像分类任务,不过,与昨日不同的是,今天所使用的模型是ShuffleNet模型。ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一…...

怀庄之醉适合搭配什么食物?
怀庄之醉作为一种独特的佳酿,其丰富的香气和层次感使其能够与多种食物搭配,提升餐饮体验。以下将具体探讨怀庄之醉适合搭配的食物类型,并分析为何这些搭配能够带来卓越的味觉享受。 一、肉类佳肴 怀庄之醉因其浓郁的口感,特别适…...

Java | Leetcode Java题解之第223题矩形面积
题目: 题解: class Solution {public int computeArea(int ax1, int ay1, int ax2, int ay2, int bx1, int by1, int bx2, int by2) {int area1 (ax2 - ax1) * (ay2 - ay1), area2 (bx2 - bx1) * (by2 - by1);int overlapWidth Math.min(ax2, bx2) -…...

基于单片机的空调控制器的设计
摘 要 : 以单片机为核心的空调控制器因其体积小 、 成本低 、 功能强 、 简便易行而得到广泛应用 。 本设计通过 AT89S52 控制DS18&a…...

企业如何利用短视频平台做口碑塑造和品牌营销?
随着短视频平台的不断发展,新型的双微一抖小红书等新媒体平台,正在成为网民聚集的核心平台,小马识途营销顾问认为越来越多的企业应该利用这些平台进行品牌营销和宣传。其中,抖音和小红书作为短视频平台的代表,吸引了大…...

SQL INSERT批量插入方式
1、常规INSERT写法 INSERT INTO ... VALUES (...);INSERT INTO 表名( 字段1, 字段2) VALUES (字段1的值, 字段2的值);2、SELECT语句返回值INSERT INSERT INTO ...VALUES (..., (select ...));INSERT INTO 表名1(字段1, 字段2) VALUES (字段1的值, (select 查询字段 from 表名2 …...
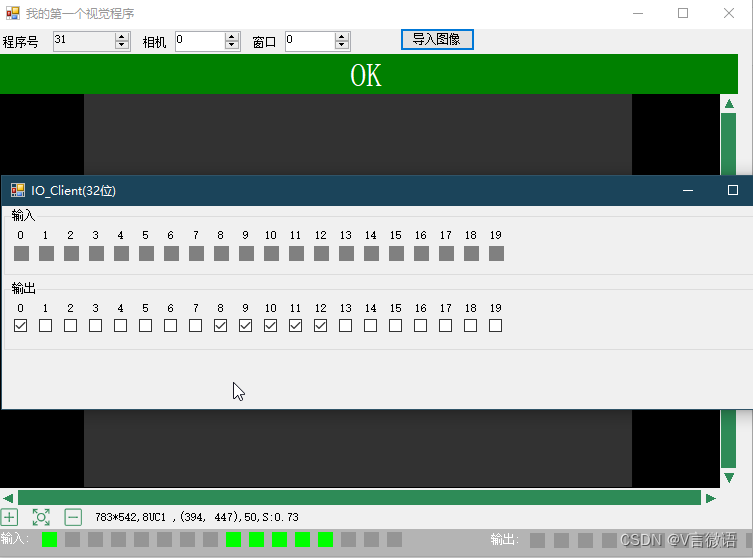
2.5 C#视觉程序开发实例1----IO_Manager实现切换程序
2.5 C#视觉程序开发实例1----IO_Manager实现切换程序 1 IO_Manager中输入实现 1.0 IO_Manager中输入部分引脚定义 // 设定index 目的是为了今后可以配置这些参数、 // 输入引脚定义 private int index_trig0 0; // trig index private int index_cst 7; //cst index priva…...
)
【入门篇】STM32寻址范围(更新中)
写在前面 STM32的寻址范围涉及存储器映射和32位地址线的使用。并且STM32的内存地址访问是按字节编址的,即每个存储单元是1字节(8位)。 一、寻址大小与范围 地址线根数 地址编号(二进制) 地址编号数(即内存大小) <...

DDD架构
1.DDD架构的概念: 领域驱动设计(Domain-Driven Design, DDD)是一种软件设计方法,旨在将软件系统的设计和开发焦点集中在领域模型上,以解决复杂业务问题 2.DDD架构解决了什么问题: 在以前的mvc架构种,三层结…...

Open3D KDtree的建立与使用
目录 一、概述 1.1kd树原理 1.2kd树搜索原理 1.3kd树构建示例 二、常见的领域搜索方式 2.1K近邻搜索(K-Nearest Neighbors, KNN Search) 2.2半径搜索(Radius Search) 2.3混合搜索(Hybrid Search) …...
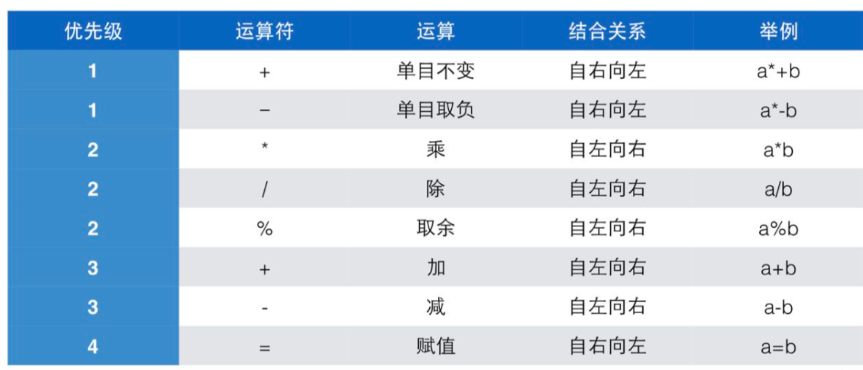
C语言编程3:运算符,运算符的基本用法
C语言3🔥:运算符,运算符的基本用法 一、运算符🌿 🎇1.1 定义 运算符是指进行运算的动作,比如加法运算符"“,减法运算符”-" 算子是指参与运算的值,这个值可能是常数&a…...

如何通过SPI机制去实现读取配置文件并动态加载对应实现类
最近写完鱼皮的RPC项目后,打算整理出来一些编程技巧的模版。 有两种实现:1.ServiceLoader 2.SpiLoader 一、直接使用java.util下的ServiceLoader 首先在resource目录下创建 META-INF/services 目录,并且创一个名称为对应要实现的接口的包…...

双链表(数组模拟)
双链表(数组模拟) 什么是双链表数组模拟双链表题目 什么是双链表 双链表不同于单链表的是 每一个节点不但存储了下一个节点的位置,也存储了上一个节点的位置。 数组模拟双链表 所以如果用数组的话,就需要创建三个数组。 题目 …...

ChatGPT 5.0:一年半后的展望与看法
在人工智能领域,每一次技术的飞跃都预示着未来生活与工作方式的深刻变革。随着OpenAI在人工智能领域的不断探索与突破,ChatGPT系列模型已成为全球关注的焦点。当谈及ChatGPT 5.0在未来一年半后可能发布的前景时,我们不禁充满期待,…...
城市地下综合管廊物联网远程监控
城市地下综合管廊物联网远程监控 城市地下综合管廊,作为现代都市基础设施的重要组成部分,其物联网远程监控系统的构建是实现智慧城市建设的关键环节。这一系统集成了先进的信息技术、传感器技术、通信技术和数据处理技术,旨在对埋设于地下的…...

VS 附加进程调试
背景: 此方式适合VS、代码和待调试的exe在同一台机器上。 一、还原代码到和正在跑的exe同版本 此操作可以保证能够调试生产环境的exe 二、设置符号路径 1.调试->选项 三、附加进程 方式1: 打开VS,调试->附加到进程,出…...

核函数的深入理解
核函数 (Kernel Function)是一种在高维特征空间中隐式计算内积的方法,它允许在原始低维空间中通过一个简单的函数来实现高维空间中的内积计算,而无需显式地计算高维特征向量。 核函数 的基本思想是通过一个映射函数 ϕ \phi ϕ …...
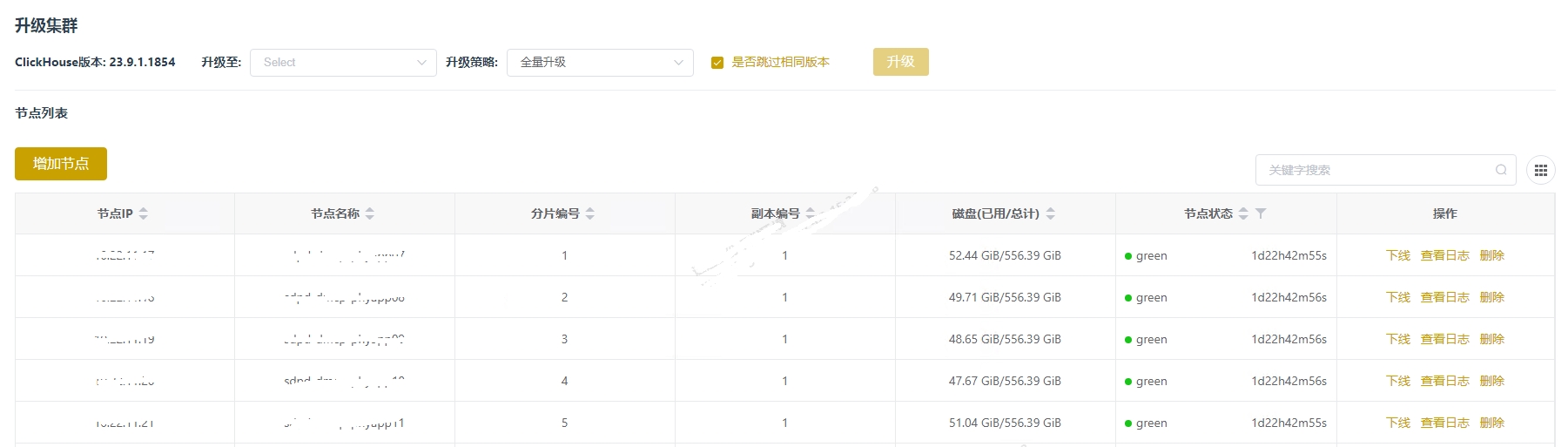
使用Ckman部署ClickHouse集群介绍
使用Ckman部署ClickHouse集群介绍 1. Ckman简介 ClickHouse Manager是一个为ClickHouse数据库量身定制的管理工具,它是由擎创科技数据库团队主导研发的一款用来管理和监控ClickHouse集群的可视化运维工具。目前该工具已在github上开源,开源地址为&…...

「前端工具」postman接口测试工具详解
Postman 是一款流行的 API 开发工具,用于构建和测试 RESTful API。以下是 Postman 的一些关键特性和使用方法的详解: 1. 界面和基本操作 工作区:Postman 的主界面,用于显示集合、环境和全局变量。请求构建器:用于输入请求的 URL、HTTP 方法、请求头、请求体等。响应区:显…...

生成requirements.txt
pip install pipreqs pipreqs ./ --encodingutf-8 --force python导出requirements.txt的几种方法总结...

虚拟机异常断电后卡在initramfs阶段?手把手教你用xfs_repair修复系统分区
1. 虚拟机异常断电的常见后果 最近在调试一个基于KVM的虚拟机集群时,遇到了一个典型问题:机房突然断电后,几台虚拟机重启时卡在了initramfs阶段,屏幕上不断刷出"generating /run/initramfs/rdsosreport.txt"的提示。这种…...

CSS 嵌套语法最佳实践:从入门到精通的完整指南
CSS 嵌套语法最佳实践:从入门到精通的完整指南 CSS 是流动的韵律,JS 是叙事的节奏。而 CSS 嵌套,是让这份韵律更加优雅、结构更加清晰的魔法。 一、CSS 嵌套:现代样式表的革命 CSS 嵌套(Nesting)是 CSS 原…...

Cayenne-MQTT-ESP:面向IoT平台的轻量级嵌入式MQTT客户端
1. 项目概述 Cayenne-MQTT-ESP 是一个专为 ESP8266 和 ESP32 平台设计的轻量级 MQTT 客户端库,其核心目标是将嵌入式设备无缝接入 Cayenne IoT 云平台(现为 myDevices IoT Platform),实现双向数据通信与可视化控制。该库并非从零…...

卡证检测矫正模型开发环境搭建:PyCharm/IDEA项目配置全攻略
卡证检测矫正模型开发环境搭建:PyCharm/IDEA项目配置全攻略 你是不是刚拿到一个卡证检测矫正模型的项目,看着一堆代码和配置文件有点无从下手?特别是想用PyCharm或者IDEA这样的专业工具来开发调试,却不知道从哪一步开始配置环境&…...

3个步骤实现教育资源高效获取:电子教材下载工具全攻略
3个步骤实现教育资源高效获取:电子教材下载工具全攻略 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具 项目地址: https://gitcode.com/GitHub_Trending/tc/tchMaterial-parser tchMaterial-parser是一款专为教育工作者和学习…...

像素幻梦·创意工坊实操手册:实时HUD状态栏信息读取与调试技巧
像素幻梦创意工坊实操手册:实时HUD状态栏信息读取与调试技巧 1. 认识像素幻梦的HUD状态栏 像素幻梦创意工坊的HUD(Head-Up Display)状态栏位于界面顶部,采用16-bit像素风格设计,为创作者提供实时系统状态反馈。这个看…...

SRS服务器从编译到实战:Ubuntu环境下的RTMP/WebRTC全协议测试
SRS服务器从编译到实战:Ubuntu环境下的RTMP/WebRTC全协议测试 在流媒体技术快速发展的今天,构建一个高效、稳定的视频服务器成为许多开发者和企业的核心需求。SRS(Simple Realtime Server)作为一款开源的实时视频服务器,凭借其对多种流媒体协…...

libtorrent会话管理终极指南:10个关键配置参数详解
libtorrent会话管理终极指南:10个关键配置参数详解 【免费下载链接】libtorrent an efficient feature complete C bittorrent implementation 项目地址: https://gitcode.com/gh_mirrors/li/libtorrent libtorrent是一个高效且功能完善的C BitTorrent实现&a…...

终极指南:如何灵活配置flamegraph性能分析参数生成自定义火焰图
终极指南:如何灵活配置flamegraph性能分析参数生成自定义火焰图 【免费下载链接】flamegraph Easy flamegraphs for Rust projects and everything else, without Perl or pipes <3 项目地址: https://gitcode.com/gh_mirrors/fla/flamegraph flamegraph是…...

Hasklig 可变字体终极指南:单一文件实现多字重支持的完整教程
Hasklig 可变字体终极指南:单一文件实现多字重支持的完整教程 【免费下载链接】Hasklig Hasklig - a code font with monospaced ligatures 项目地址: https://gitcode.com/gh_mirrors/ha/Hasklig Hasklig 是一款专为程序员设计的开源代码字体,以…...