YOLOv8改进 | 注意力机制 | 对密集和小目标友好的EVAblock 【原理 + 完整代码】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录 :《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有50+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进——点击即可跳转
视觉特征金字塔在广泛的应用中显示出其有效性和效率的优越性。然而,现有的方法过分地集中于层间特征交互,而忽略了层内特征规则,这是经验证明是有益的。尽管一些方法试图借助注意机制或视觉变换器学习紧凑的层内特征表示,但它们忽略了对密集预测任务很重要的被忽略的角点区域。为了解决这一问题,提出了一种基于全局显式集中式特征规则的集中式特征金字塔(CFP)对象检测方法。具体而言,我们首先提出了一种空间显式视觉中心方案,其中使用轻量级MLP来捕捉全局长距离依赖关系,并使用并行可学习视觉中心机制来捕捉输入图像的局部角区域。在此基础上,我们以自顶向下的方式对常用的特征金字塔提出了一个全局集中的规则,其中使用从 最深层内特征获得的显式视觉中心信息。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:YOLOv8改进——更新各种有效涨点方法——点击即可跳转

目录
1. 原理
2. 将EVC添加到YOLOv8中
2.1 EVC代码实现
2.2 更改init.py文件
2.3 添加yaml文件
2.4 在task.py中进行注册
2.5 执行程序
3. 完整代码分享
4. GFLOPs
5. 进阶
6. 总结
1. 原理

论文地址:Centralized Feature Pyramid for Object Detection——点击即可跳转
官方代码:官方代码仓库——点击即可跳转
Explicit Visual Center (EVC) 主要原理如下:
-
整体架构: EVC 主要由两个并行连接的模块组成:一个轻量级的多层感知器(MLP)用于捕捉顶层特征的全局长距离依赖(即全局信息),另一个是可学习的视觉中心机制,用于聚合层内的局部区域特征。这两个模块的结果特征图在通道维度上连接在一起,作为 EVC 的输出,用于下游识别任务。
-
输入特征处理: 输入图像首先通过一个主干网络(如 Modified CSP v5)提取五层特征金字塔(X0, X1, X2, X3, X4),其中每层特征的空间大小分别是输入图像的1/2, 1/4, 1/8, 1/16, 1/32。EVC 实现于特征金字塔的顶层(X4)上。
-
轻量级 MLP 模块: 轻量级 MLP 模块主要包括两个残差模块:基于深度卷积的模块和基于通道 MLP 的模块。深度卷积模块通过组归一化和深度卷积处理输入特征,然后进行通道缩放和 DropPath 操作,最后通过残差连接输出特征。
-
视觉中心机制: 可学习的视觉中心机制通过计算特征图中每个像素点相对于一组可学习的视觉词的位置信息来聚合局部特征。具体过程包括计算像素点与视觉词之间的距离,通过一个全连接层和一个 1x1 卷积层预测出突出关键类别的特征,然后与 Stem block 的输入特征进行通道乘法和通道加法操作。
-
输出特征整合: 最终,两个并行模块的输出特征图在通道维度上连接在一起,形成 EVC 的输出,用于下游的分类和回归任务。
EVC 机制通过结合全局和局部信息,有效地提升了视觉特征的表示能力,对于密集预测任务(如目标检测)非常重要。
2. 将EVC添加到YOLOv8中
2.1 EVC代码实现
关键步骤一: 将下面代码粘贴到在/ultralytics/ultralytics/nn/modules/block.py中,并在该文件的__all__中添加“EVCBlock”
class Encoding(nn.Module):def __init__(self, in_channels, num_codes):super(Encoding, self).__init__()# init codewords and smoothing factorself.in_channels, self.num_codes = in_channels, num_codesnum_codes = 64std = 1. / ((num_codes * in_channels) ** 0.5)# [num_codes, channels]self.codewords = nn.Parameter(torch.empty(num_codes, in_channels, dtype=torch.float).uniform_(-std, std), requires_grad=True)# [num_codes]self.scale = nn.Parameter(torch.empty(num_codes, dtype=torch.float).uniform_(-1, 0), requires_grad=True)@staticmethoddef scaled_l2(x, codewords, scale):num_codes, in_channels = codewords.size()b = x.size(0)expanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))# ---处理codebook (num_code, c1)reshaped_codewords = codewords.view((1, 1, num_codes, in_channels))# 把scale从1, num_code变成 batch, c2, N, num_codesreshaped_scale = scale.view((1, 1, num_codes)) # N, num_codes# ---计算rik = z1 - d # b, N, num_codesscaled_l2_norm = reshaped_scale * (expanded_x - reshaped_codewords).pow(2).sum(dim=3)return scaled_l2_norm@staticmethoddef aggregate(assignment_weights, x, codewords):num_codes, in_channels = codewords.size()# ---处理codebookreshaped_codewords = codewords.view((1, 1, num_codes, in_channels))b = x.size(0)# ---处理特征向量x b, c1, Nexpanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))# 变换rei b, N, num_codes,-assignment_weights = assignment_weights.unsqueeze(3) # b, N, num_codes,# ---开始计算eik,必须在Rei计算完之后encoded_feat = (assignment_weights * (expanded_x - reshaped_codewords)).sum(1)return encoded_featdef forward(self, x):assert x.dim() == 4 and x.size(1) == self.in_channelsb, in_channels, w, h = x.size()# [batch_size, height x width, channels]x = x.view(b, self.in_channels, -1).transpose(1, 2).contiguous()# assignment_weights: [batch_size, channels, num_codes]assignment_weights = torch.softmax(self.scaled_l2(x, self.codewords, self.scale), dim=2)# aggregateencoded_feat = self.aggregate(assignment_weights, x, self.codewords)return encoded_featclass Mlp(nn.Module):"""Implementation of MLP with 1*1 convolutions. Input: tensor with shape [B, C, H, W]"""def __init__(self, in_features, hidden_features=None,out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Conv2d(in_features, hidden_features, 1)self.act = act_layer()self.fc2 = nn.Conv2d(hidden_features, out_features, 1)self.drop = nn.Dropout(drop)self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Conv2d):trunc_normal_(m.weight, std=.02)if m.bias is not None:nn.init.constant_(m.bias, 0)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x# 1*1 3*3 1*1
class ConvBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1, res_conv=False, act_layer=nn.SiLU, groups=1,norm_layer=partial(nn.BatchNorm2d, eps=1e-6)):super(ConvBlock, self).__init__()self.in_channels = in_channelsexpansion = 4c = out_channels // expansionself.conv1 = Conv(in_channels, c, act=nn.SiLU())self.conv2 = Conv(c, c, k=3, s=stride, g=groups, act=nn.SiLU())self.conv3 = Conv(c, out_channels, 1, act=False)self.act3 = act_layer(inplace=True)if res_conv:self.residual_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)self.residual_bn = norm_layer(out_channels)self.res_conv = res_convdef zero_init_last_bn(self):nn.init.zeros_(self.bn3.weight)def forward(self, x, return_x_2=True):residual = xx = self.conv1(x)x2 = self.conv2(x) # if x_t_r is None else self.conv2(x + x_t_r)x = self.conv3(x2)if self.res_conv:residual = self.residual_conv(residual)residual = self.residual_bn(residual)x += residualx = self.act3(x)if return_x_2:return x, x2else:return xclass Mean(nn.Module):def __init__(self, dim, keep_dim=False):super(Mean, self).__init__()self.dim = dimself.keep_dim = keep_dimdef forward(self, input):return input.mean(self.dim, self.keep_dim)class LVCBlock(nn.Module):def __init__(self, in_channels, out_channels, num_codes, channel_ratio=0.25, base_channel=64):super(LVCBlock, self).__init__()self.out_channels = out_channelsself.num_codes = num_codesnum_codes = 64self.conv_1 = ConvBlock(in_channels=in_channels, out_channels=in_channels, res_conv=True, stride=1)self.LVC = nn.Sequential(Conv(in_channels, in_channels, 1, act=nn.SiLU()),Encoding(in_channels=in_channels, num_codes=num_codes),nn.BatchNorm1d(num_codes),nn.SiLU(inplace=True),Mean(dim=1))self.fc = nn.Sequential(nn.Linear(in_channels, in_channels), nn.Sigmoid())def forward(self, x):x = self.conv_1(x, return_x_2=False)en = self.LVC(x)gam = self.fc(en)b, in_channels, _, _ = x.size()y = gam.view(b, in_channels, 1, 1)x = F.relu_(x + x * y)return xclass GroupNorm(nn.GroupNorm):"""Group Normalization with 1 group.Input: tensor in shape [B, C, H, W]"""def __init__(self, num_channels, **kwargs):super().__init__(1, num_channels, **kwargs)class DWConv_LMLP(nn.Module):"""Depthwise Conv + Conv"""def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):super().__init__()self.dconv = Conv(in_channels,in_channels,k=ksize,s=stride,g=in_channels,)self.pconv = Conv(in_channels, out_channels, k=1, s=1, g=1)def forward(self, x):x = self.dconv(x)return self.pconv(x)# LightMLPBlock
class LightMLPBlock(nn.Module):def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu",mlp_ratio=4., drop=0., act_layer=nn.GELU,use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0.,norm_layer=GroupNorm): # act_layer=nn.GELU,super().__init__()self.dw = DWConv_LMLP(in_channels, out_channels, ksize=1, stride=1, act="silu")self.linear = nn.Linear(out_channels, out_channels) # learnable position embeddingself.out_channels = out_channelsself.norm1 = norm_layer(in_channels)self.norm2 = norm_layer(in_channels)mlp_hidden_dim = int(in_channels * mlp_ratio)self.mlp = Mlp(in_features=in_channels, hidden_features=mlp_hidden_dim, act_layer=nn.GELU,drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. \else nn.Identity()self.use_layer_scale = use_layer_scaleif use_layer_scale:self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones(out_channels), requires_grad=True)self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones(out_channels), requires_grad=True)def forward(self, x):if self.use_layer_scale:x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.dw(self.norm1(x)))x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))else:x = x + self.drop_path(self.dw(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return x# EVCBlock
class EVCBlock(nn.Module):def __init__(self, in_channels, out_channels, channel_ratio=4, base_channel=16):super().__init__()expansion = 2ch = out_channels * expansion# Stem stage: get the feature maps by conv block (copied form resnet.py) 进入conformer框架之前的处理self.conv1 = Conv(in_channels, in_channels, k=3, act=nn.SiLU())self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # 1 / 4 [56, 56]# LVCself.lvc = LVCBlock(in_channels=in_channels, out_channels=out_channels, num_codes=64) # c1值暂时未定# LightMLPBlockself.l_MLP = LightMLPBlock(in_channels, out_channels, ksize=3, stride=1, act="silu", act_layer=nn.GELU,mlp_ratio=4., drop=0.,use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0.,norm_layer=GroupNorm)self.cnv1 = nn.Conv2d(ch, out_channels, kernel_size=1, stride=1, padding=0)def forward(self, x):x1 = self.maxpool((self.conv1(x)))# LVCBlockx_lvc = self.lvc(x1)# LightMLPBlockx_lmlp = self.l_MLP(x1)# concatx = torch.cat((x_lvc, x_lmlp), dim=1)x = self.cnv1(x)return xEVCBlock 处理图像的主要流程如下:
输入图像处理:
输入图像首先通过一个主干网络(如 Modified CSP v5)提取出五层特征金字塔(X0, X1, X2, X3, X4),每层特征图的空间大小分别是输入图像的1/2, 1/4, 1/8, 1/16, 1/32。
轻量级 MLP 模块:
对于顶层特征图(X4),首先输入到轻量级 MLP 模块。这个模块包括基于深度卷积的残差模块和基于通道 MLP 的残差模块。深度卷积模块通过组归一化和深度卷积处理输入特征,然后进行通道缩放和 DropPath 操作,最后通过残差连接输出特征。
视觉中心机制:
顶层特征图(X4)同时也输入到视觉中心机制。这个机制通过计算特征图中每个像素点相对于一组可学习的视觉词的位置信息来聚合局部特征。具体过程如下:
- 计算像素点与视觉词之间的距离。
- 通过一个全连接层和一个 1x1 卷积层预测出突出关键类别的特征。
-
然后与 Stem block 的输入特征进行通道乘法和通道加法操作。
特征整合:
-
轻量级 MLP 模块和视觉中心机制的输出特征图在通道维度上连接在一起,形成 EVC 的输出特征。
下游任务处理:
-
最终的 EVC 输出特征图用于下游的分类和回归任务,提升了视觉特征的表示能力,有效地增强了密集预测任务(如目标检测)的性能。

2.2 更改init.py文件
关键步骤二:修改modules文件夹下的__init__.py文件,先导入函数

然后在下面的__all__中声明函数

2.3 添加yaml文件
关键步骤三:在/ultralytics/ultralytics/cfg/models/v8下面新建文件yolov8_EVC.yaml文件,粘贴下面的内容
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see # Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [ 0.33, 0.25, 1024 ] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [ -1, 1, Conv, [ 64, 3, 2 ] ] # 0-P1/2- [ -1, 1, Conv, [ 128, 3, 2 ] ] # 1-P2/4- [ -1, 3, C2f, [ 128, True ] ]- [ -1, 1, Conv, [ 256, 3, 2 ] ] # 3-P3/8- [ -1, 6, C2f, [ 256, True ] ]- [ -1, 1, Conv, [ 512, 3, 2 ] ] # 5-P4/16- [ -1, 6, C2f, [ 512, True ] ]- [ -1, 1, Conv, [ 1024, 3, 2 ] ] # 7-P5/32- [ -1, 3, C2f, [ 1024, True ] ]- [ -1, 1, SPPF, [ 1024, 5 ] ] # 9# YOLOv8.0n head
head:- [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ]- [ -1, 1, EVCBlock, [ 1024 ] ] # 12 - [ [ -1, 6 ], 1, Concat, [ 1 ] ] # cat backbone P4- [ -1, 3, C2f, [ 512 ] ] # 12- [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ]- [ [ -1, 4 ], 1, Concat, [ 1 ] ] # cat backbone P3- [ -1, 3, C2f, [ 256 ] ] # 15 (P3/8-small)- [ -1, 1, Conv, [ 256, 3, 2 ] ]- [ [ -1, 12 ], 1, Concat, [ 1 ] ] # cat head P4- [ -1, 3, C2f, [ 512 ] ] # 18 (P4/16-medium)- [ -1, 1, Conv, [ 512, 3, 2 ] ]- [ [ -1, 9 ], 1, Concat, [ 1 ] ] # cat head P5- [ -1, 3, C2f, [ 1024 ] ] # 21 (P5/32-large)- [ [ 16, 19, 22 ], 1, Detect, [ nc ] ] # Detect(P3, P4, P5)温馨提示:因为本文只是对yolov8基础上添加模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv8n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
max_channels: 1024 # max_channels# YOLOv8s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
max_channels: 1024 # max_channels# YOLOv8l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
max_channels: 512 # max_channels# YOLOv8m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
max_channels: 768 # max_channels# YOLOv8x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
max_channels: 512 # max_channels2.4 在task.py中进行注册
关键步骤四:在task.py的parse_model函数中进行注册,

2.5 执行程序
关键步骤五:在ultralytics文件中新建train.py,将model的参数路径设置为yolov8_EVC.yaml的路径即可
from ultralytics import YOLO# Load a model
# model = YOLO('yolov8n.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)model = YOLO(r'/projects/ultralytics/ultralytics/cfg/models/v8/yolov8_EVC.yaml') # build from YAML and transfer weights# Train the model
model.train(batch=16)🚀运行程序,如果出现下面的内容则说明添加成功🚀

3. 完整代码分享
https://pan.baidu.com/s/1p48Q3TiVU7Yp2LKv4bAm_Q?pwd=kjgv提取码: kjgv
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的YOLOv8nGFLOPs

改进后的GFLOPs

5. 进阶
可以结合损失函数或者卷积模块进行多重改进
6. 总结
Explicit Visual Center (EVC) 是一种结合全局和局部信息的新型视觉特征提取机制。其主要通过两个并行模块处理图像顶层特征,一个是轻量级的多层感知器(MLP)模块,用于捕捉全局长距离依赖,另一个是可学习的视觉中心机制,用于聚合局部区域特征。轻量级 MLP 模块包括基于深度卷积和通道 MLP 的残差模块,而视觉中心机制通过计算特征图中每个像素点与可学习视觉词之间的距离来突出关键类别的特征。最终,这两个模块的输出特征图在通道维度上连接在一起,生成的特征图用于下游识别任务,从而有效提升了视觉特征的表示能力,特别是在密集预测任务中表现出色。
相关文章:
YOLOv8改进 | 注意力机制 | 对密集和小目标友好的EVAblock 【原理 + 完整代码】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录 :《YOLOv8改进有效…...

高效前端开发:解密pnpm的存储与链接
什么是pnpm PNPM(Performant NPM)是一种快速且节省磁盘空间的包管理工具。相较于其他包管理器如NPM和Yarn,PNPM通过独特的存储机制和链接技术解决了许多常见的问题。以下是PNPM如何避免这些问题以及其关键技术的详细介绍。 特性 PNPM Store…...

设置单实例Apache HTTP服务器
配置仓库 [rootlocalhost ~]# cd /etc/yum.repos.d/ [rootlocalhost yum.repos.d]# vi rpm.repo仓库代码: [BaseOS] nameBaseOS baseurl/mnt/BaseOS enabled1 gpgcheck0[AppStream] nameAppStream baseurl/mnt/AppStream enabled1 gpgcheck0挂载 [rootlocalhost …...

Python | Leetcode Python题解之第221题最大正方形
题目: 题解: class Solution:def maximalSquare(self, matrix: List[List[str]]) -> int:if len(matrix) 0 or len(matrix[0]) 0:return 0maxSide 0rows, columns len(matrix), len(matrix[0])dp [[0] * columns for _ in range(rows)]for i in…...

使用Python实现线性拟合
如下 Python 代码主要用于处理和分析数据,并使用 Matplotlib 库绘制出数据的拟合曲线。它的主要步骤包括数据预处理、进行线性回归分析,并根据结果绘图展示。下面是对代码及其所引用库的详细解释: 引用的库 numpy (np): 用于进行数值计算。这…...

如何在浏览器控制台Console中引入外部 JS
想要在某个网页执行一些脚本,却发现某个工具类,如 ajax 请求的 axios 该网页没有引入,或者引入了但控制台却访问不到,这时要怎么办呢? 只需要控制台执行如下代码就好了 var script document.createElement(script);…...

后端——全局异常处理
一、老办法try-catch 当我们执行一些错误操作导致程序报错时,程序会捕捉到异常报错,这个异常会存在一个Exception对象里 那我们在spring boot工程开发时,当我们执行一个sql查询时报错了,那就会从最底层的Mapper层捕捉到Exceptio…...

软件开发面试题(C#语言,.NET框架)
1. 解释什么是委托(Delegate),并举例说明它在C#中的用法。 委托是一种引用类型,它可以用于封装一个或多个方法。委托对象可以像方法一样调用,甚至可以用于创建事件处理程序。委托是C#中实现事件和回调函数的重要机制。…...

Spring学习04-[Spring容器核心技术AOP学习]
AOP学习 AOP介绍使用对业务方法添加计算时间的增强 EnableAspectJAutoProxyAOP的术语通知前置通知Before后置通知After返回通知AfterReturning异常通知AfterThrowing总结-通知执行顺序 切点表达式的提取-使用Pointcut进行抽取切点表达式的详细用法execution和annotation组合 Sp…...

第5章-组合序列类型
#全部是重点知识,必须会。 了解序列和索引|的相关概念 掌握序列的相关操作 掌握列表的相关操作 掌握元组的相关操作 掌握字典的相关操作 掌握集合的相关操作1,序列和索引 1,序列是一个用于存储多个值的连续空间,每一个值都对应一…...

大话光学原理:2.最短时间原理、“魔法石”与彩虹
一、最短时间原理 1662年左右,费马在一张信纸的边角,用他那著名的潦草笔迹,随意地写下了一行字:“光在两点间选择的路,总是耗时最少的。”这句话,简单而深邃,像是一颗悄然种下的种子,…...

spring tx @Transactional 详解 `Advisor`、`Target`、`ProxyFactory
在Spring中,Transactional注解的处理涉及到多个关键组件,包括Advisor、Target、ProxyFactory等。下面是详细的解析和代码示例,解释这些组件是如何协同工作的。 1. 关键组件介绍 1.1 Advisor Advisor是一个Spring AOP的概念,它包…...
)
`CyclicBarrier` 是 Java 中的一个同步辅助工具类,它允许一组线程相互等待,直到所有线程都达到了某个公共屏障点(barrier point)
CyclicBarrier 是 Java 中的一个同步辅助工具类,它允许一组线程相互等待,直到所有线程都达到了某个公共屏障点(barrier point)。当所有线程都到达屏障点时,它们可以继续执行后续操作。CyclicBarrier 的特点是可以重复使…...

华为机试HJ108求最小公倍数
华为机试HJ108求最小公倍数 题目: 想法: 要找到输入的两个数的最小公倍数,这个最小公倍数要大于等于其中最大的那个数值,遍历最大的那个数值的倍数,最大的最小公倍数就是输入的两个数值的乘积 input_number_list i…...
Debezium报错处理系列之第114篇:No TableMapEventData has been found for table id:256.
Debezium报错处理系列之第114篇:Caused by: com.github.shyiko.mysql.binlog.event.deserialization.MissingTableMapEventException: No TableMapEventData has been found for table id:256. Usually that means that you have started reading binary log within the logic…...

开发者必看:MySQL主从复制与Laravel读写分离的完美搭配
介绍 主从同步配置的主要性不用多说,本文将详细介绍了如何在MySQL数据库中设置主从复制,以及如何在Laravel框架中实现数据库的读写分离。 通过一系列的步骤,包括修改MySQL配置、创建同步账户、获取二进制日志文件名和位置、导出主服务器数据…...

二战架构师,拿下
前言 已经许久更新文章了,并不是因为我懒了,而是在备考系统架构师考试。个人感觉还是比较幸运的,低分飘过。现阶段任务也算完成了,记录一下感受。 什么是软考 软考,全称“计算机技术与软件专业技术资格(…...

泛微开发修炼之旅--35关于基于页面扩展和自定义按钮实现与后端交互调用的方法
文章链接:35关于基于页面扩展和自定义按钮实现与后端交互调用的方法...
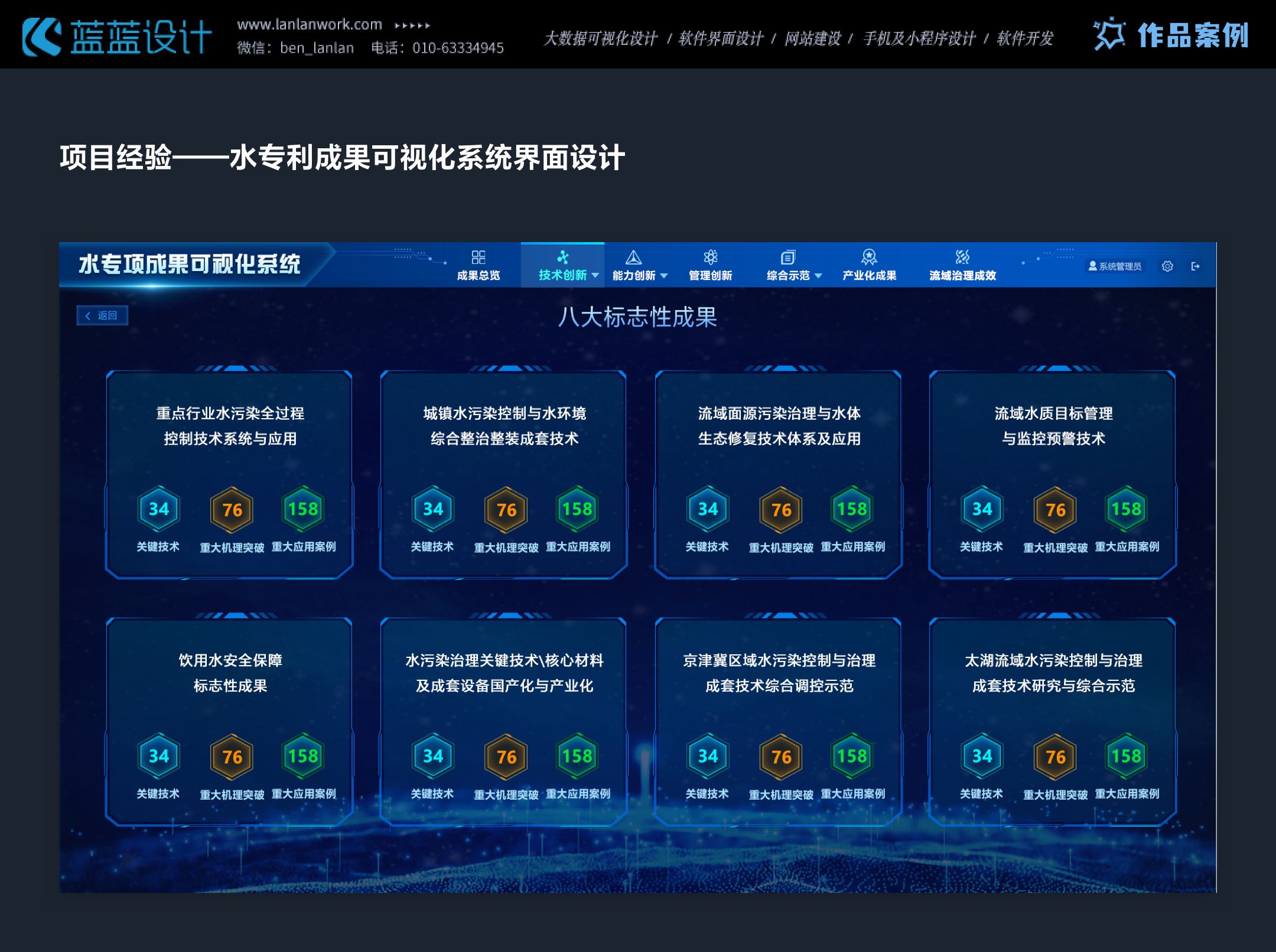
原创作品—数据可视化大屏
设计数据可视化大屏时,用户体验方面需注重以下几点:首先,确保大屏信息层次分明,主要数据突出显示,次要信息适当弱化,帮助用户快速捕捉关键信息。其次,设计应直观易懂,避免复杂难懂的…...
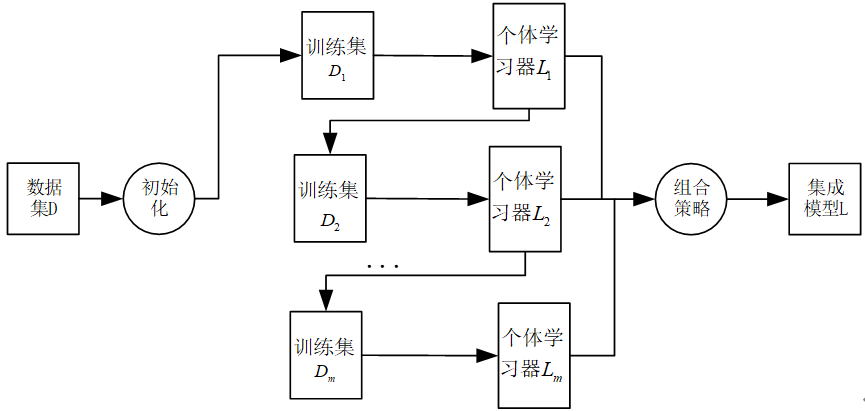
AdaBoost集成学习算法理论解读以及公式为什么这么设计?
本文致力于阐述AdaBoost基本步骤涉及的每一个公式和公式为什么这么设计。 AdaBoost集成学习算法基本上遵从Boosting集成学习思想,通过不断迭代更新训练样本集的样本权重分布获得一组性能互补的弱学习器,然后通过加权投票等方式将这些弱学习器集成起来得到…...

G-Helper深度解析:如何用1MB工具彻底替代华硕Armoury Crate
G-Helper深度解析:如何用1MB工具彻底替代华硕Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenboo…...

Eviews面板数据回归实战:手把手教你用Hausman检验搞定固定效应与随机效应模型选择
Eviews面板数据回归实战:Hausman检验在固定与随机效应模型选择中的应用 计量经济学研究中,面板数据分析因其能同时捕捉时间和个体维度的信息而备受青睐。但面对固定效应(FE)和随机效应(RE)模型的选择,许多研究者常常陷入困惑。本文将带您深入…...

系统安全加固实战:在统信UOS与麒麟KOS中精准禁用指定网卡
1. 为什么需要精准禁用网卡? 在企业办公环境或高安全需求的服务器场景中,网络接口就像房子的门窗。你可能需要关闭某些不常用的出入口来防止入侵——比如禁用员工电脑的无线网卡来防止连接外部热点,或者在服务器上关闭非必要的物理网口来减少…...
全解析)
智慧展馆(数字孪生 + 三维重建)全解析
智慧展馆(数字孪生 三维重建)全解析一、核心技术体系(含动态目标实时重构、数字孪生、透明建筑)智慧展馆的数字化升级,核心依托四大核心技术 ——视频孪生、三维重建、动态目标实时重构、透明建筑渲染,四大…...

从电话到流媒体:聊聊G.711、G.726这些老牌音频编码为啥还在用?
从电话到流媒体:G.711与G.726音频编码的生存之道 在数字音频技术日新月异的今天,MP3、AAC、Opus等现代编码格式早已成为流媒体和消费级应用的标配。然而,当你拆开一台最新的IP电话机,或是调试某款工业级语音设备时,大概…...

探索物联网通信新高度:STM32 MQTT协议功能实现
探索物联网通信新高度:STM32 MQTT协议功能实现 【下载地址】STM32MQTT协议功能实现分享 本仓库提供了一个资源文件,标题为“STM32 MQTT协议功能实现”。该资源文件包含了使用C语言实现的MQTT协议客户端功能,并且已经成功移植到STM32平台上。经…...

3分钟掌握无人机日志分析:免费在线工具UAV Log Viewer完全指南
3分钟掌握无人机日志分析:免费在线工具UAV Log Viewer完全指南 【免费下载链接】UAVLogViewer An online viewer for UAV log files 项目地址: https://gitcode.com/gh_mirrors/ua/UAVLogViewer 面对复杂的无人机飞行数据,你是否曾为分析日志文件…...

量子纠错与Floquet码:动态编码与ZX演算实践
1. 量子纠错与Floquet码基础量子纠错码是构建容错量子计算机的核心技术。与传统纠错码不同,量子态具有不可克隆特性,使得量子纠错必须采用特殊方法。稳定子码(Stabilizer Codes)是目前最成熟的量子纠错方案,通过测量多…...

C51函数可重入性原理与实践指南
1. C51函数可重入性深度解析在嵌入式C51开发中,函数可重入性(Reentrancy)是一个直接影响系统稳定性的关键特性。简单来说,可重入函数是指能够被多个执行流(如主程序和中断服务例程)同时调用而不会引发数据冲…...

Windows右键菜单终极清理:3个简单步骤让您的右键菜单重获新生
Windows右键菜单终极清理:3个简单步骤让您的右键菜单重获新生 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 我们都有过这样的经历:在桌…...