Neo4j 图数据库 高级操作
Neo4j 图数据库 高级操作
文章目录
- Neo4j 图数据库 高级操作
- 1 批量添加节点、关系
- 1.1 直接使用 `UNWIND` 批量创建关系
- 1.2 使用 CSV 文件批量创建关系
- 1.3 选择方法
- 2 索引
- 2.1 创建单一属性索引
- 2.2 创建组合属性索引
- 2.3 创建全文索引
- 2.4 列出所有索引
- 2.5 删除索引
- 2.6 注意事项
- 3 清空所有数据
- 3.1 删除所有节点和关系
- 3.2 使用 APOC 扩展
- 3.3 重置数据库(针对 Neo4j 4.0 及以上版本)
- 3.4 删除数据库文件(仅适用于本地开发环境)
- 3.5 注意事项
1 批量添加节点、关系
1.1 直接使用 UNWIND 批量创建关系
假设你已经有了 100,000 个节点数据和它们之间的关系数据,可以使用 UNWIND 语句来批量创建节点和关系。
-
批量创建节点:
首先,使用
UNWIND创建节点。WITH [{eGuid: 'guid1', eId: 'id1', layer: 'layer1'},{eGuid: 'guid2', eId: 'id2', layer: 'layer2'},...{eGuid: 'guid100000', eId: 'id100000', layer: 'layer100000'} ] AS data UNWIND data AS row CREATE (n:Node {eGuid: row.eGuid, eId: row.eId, layer: row.layer}) RETURN count(n) -
批量创建关系:
假设关系数据如下:
startGuid,endGuid,relationshipType guid1,guid2,RELATED_TO guid3,guid4,CONNECTED_TO ... guid99999,guid100000,ASSOCIATED_WITH将关系数据存储在一个列表中,并使用
UNWIND创建关系:WITH [{startGuid: 'guid1', endGuid: 'guid2', relationshipType: 'RELATED_TO'},{startGuid: 'guid3', endGuid: 'guid4', relationshipType: 'CONNECTED_TO'},...{startGuid: 'guid99999', endGuid: 'guid100000', relationshipType: 'ASSOCIATED_WITH'} ] AS relationships UNWIND relationships AS rel MATCH (startNode:Node {eGuid: rel.startGuid}), (endNode:Node {eGuid: rel.endGuid}) CREATE (startNode)-[r:RELATIONSHIP {type: rel.relationshipType}]->(endNode) RETURN count(r) -
C# 代码实现
List<Dictionary<string, object>> nodeData = new List<Dictionary<string, object>>{new Dictionary<string, object>{{ "eGuid", guid },{ "eId", id },{ "layer", layer },} }; IResultCursor batchInsertNode = await session.RunAsync(@"UNWIND $nodeData AS rowMERGE (n: PrimitiveNode { eGuid: row.eGuid, eId: row.eId, layer: row.layer})RETURN count(n)",new { nodeData });List<Dictionary<string, object>> relationData = new List<Dictionary<string, object>>{new Dictionary<string, object>{{ "startGuid", s_eGuid },{ "endGuid", t_eGuid },{ "relationName", relation },} }; IResultCursor batchInsertRelation = await session.RunAsync(@"UNWIND $relationData AS relMATCH (startNode:PrimitiveNode {eGuid: rel.startGuid}), (endNode:PrimitiveNode {eGuid: rel.endGuid})MERGE (startNode)-[r:PrimitiveRelation {name: rel.relationName}]->(endNode)",new { relationData });
1.2 使用 CSV 文件批量创建关系
如果数据量很大,可以将数据存储在 CSV 文件中,然后使用 LOAD CSV 导入。
-
创建 CSV 文件:
创建两个 CSV 文件,一个用于节点数据,另一个用于关系数据。
nodes.csv:
eGuid,eId,layer guid1,id1,layer1 guid2,id2,layer2 ... guid100000,id100000,layer100000relationships.csv:
startGuid,endGuid,relationshipType guid1,guid2,RELATED_TO guid3,guid4,CONNECTED_TO ... guid99999,guid100000,ASSOCIATED_WITH -
加载 CSV 文件并创建节点:
LOAD CSV WITH HEADERS FROM 'file:///nodes.csv' AS row CREATE (:Node {eGuid: row.eGuid, eId: row.eId, layer: row.layer}) RETURN count(*) -
加载 CSV 文件并创建关系:
LOAD CSV WITH HEADERS FROM 'file:///relationships.csv' AS row MATCH (startNode:Node {eGuid: row.startGuid}), (endNode:Node {eGuid: row.endGuid}) CREATE (startNode)-[r:RELATIONSHIP {type: row.relationshipType}]->(endNode) RETURN count(r)
1.3 选择方法
- 如果数据结构简单,且数据量不大,可以直接在 Cypher 查询中使用
UNWIND。 - 对于大量数据,CSV 文件导入方法非常高效。
- 使用编程语言的批量插入方法适合需要复杂逻辑处理的数据。
2 索引
2.1 创建单一属性索引
要在单个属性上创建索引,可以使用以下命令:
CREATE INDEX index_name FOR (n:Label) ON (n.property)
例如:
CREATE INDEX person_name_index FOR (p:Person) ON (p.name)
2.2 创建组合属性索引
要在多个属性上创建组合索引,可以使用以下命令:
CREATE INDEX index_name FOR (n:Label) ON (n.property1, n.property2)
例如:
CREATE INDEX person_name_dob_index FOR (p:Person) ON (p.name, p.dob)
2.3 创建全文索引
Neo4j 还支持全文索引,可以用于全文搜索。要创建全文索引,可以使用以下命令:
CALL db.index.fulltext.createNodeIndex('index_name', ['Label'], ['property'])
例如:
CALL db.index.fulltext.createNodeIndex('person_name_index', ['Person'], ['name'])
2.4 列出所有索引
要查看数据库中现有的所有索引,可以使用以下命令:
CALL db.indexes
2.5 删除索引
要删除一个索引,可以使用以下命令:
DROP INDEX index_name
例如:
DROP INDEX person_name_index
2.6 注意事项
- 索引创建时间:索引的创建可能需要一些时间,特别是在包含大量数据的情况下。建议在数据库维护时创建索引。
- 索引类型:Neo4j 支持多种类型的索引,包括 B-tree 索引、全文索引等。选择适合查询需求的索引类型。
- 版本差异:不同版本的 Neo4j 在索引语法和功能上可能有所不同,建议查阅对应版本的官方文档以获取准确的信息。
3 清空所有数据
3.1 删除所有节点和关系
-
删除所有关系:
MATCH ()-[r]-() DELETE r -
删除所有节点:
MATCH (n) DELETE n该命令尝试直接删除匹配到的节点
n。如果节点n还有任何连接的关系,这条命令会失败并报错,因为 Neo4j 不允许直接删除仍然连接着关系的节点。使用限制:只能删除没有任何关系的孤立节点。
-
删除所有节点:
MATCH (n) DETACH DELETE n该命令不仅删除匹配到的节点
n,还会先删除与该节点连接的所有关系。这样就避免了直接删除节点时可能遇到的错误。使用优势:能够删除任何节点,无论它们是否连接着关系。
3.2 使用 APOC 扩展
如果安装了 APOC 扩展,可以使用更简便的方法:
CALL apoc.periodic.iterate('MATCH (n) RETURN n','DETACH DELETE n',{batchSize: 1000}
)
3.3 重置数据库(针对 Neo4j 4.0 及以上版本)
如果你使用的是 Neo4j 4.0 及以上版本,可以使用 dbms.clearDatabase() 命令重置数据库:
CALL dbms.clearDatabase()
3.4 删除数据库文件(仅适用于本地开发环境)
如果你在本地开发环境中,可以通过删除数据库文件来清空所有数据。这需要停止 Neo4j 服务,删除数据库文件,然后重新启动服务。
-
停止 Neo4j 服务:
neo4j stop -
删除数据库文件:
默认情况下,数据库文件位于
data/databases/目录下。例如,对于默认数据库neo4j,删除相应文件:rm -rf data/databases/neo4j -
重新启动 Neo4j 服务:
neo4j start
3.5 注意事项
- 备份数据:在清空数据之前,建议先备份现有数据,以防需要恢复。
- 权限:确保执行清空数据操作的用户具有足够的权限。
- 环境:在生产环境中执行这些操作时要格外小心,确保不会影响正常运行的数据和服务。
相关文章:

Neo4j 图数据库 高级操作
Neo4j 图数据库 高级操作 文章目录 Neo4j 图数据库 高级操作1 批量添加节点、关系1.1 直接使用 UNWIND 批量创建关系1.2 使用 CSV 文件批量创建关系1.3 选择方法 2 索引2.1 创建单一属性索引2.2 创建组合属性索引2.3 创建全文索引2.4 列出所有索引2.5 删除索引2.6 注意事项 3 清…...

《RWKV》论文笔记
原文出处 [2305.13048] RWKV: Reinventing RNNs for the Transformer Era (arxiv.org) 原文笔记 What RWKV(RawKuv):Reinventing RNNs for the Transformer Era 本文贡献如下: 提出了 RWKV 网络架构,结合了RNNS 和Transformer 的优点,同…...
——显色指数(Ra))
相机光学(二十九)——显色指数(Ra)
显指Ra是衡量光源显色性的数值,表示光源对物体颜色的还原能力。显色性是指光源对物体颜色的呈现能力,即光源照射在同一颜色的物体上时,所呈现的颜色特性。通常用显色指数(CRI)来表示光源的显色性,而显指Ra是…...

【Swoole 的生命周期,文件描述符,协程数量,以及默认值】
目录 Swoole 的生命周期 Swoole 文件描述符(FD)缓存 Swoole设置协程的数量 Swoole 默认值 Swoole 是一个基于 PHP 的高性能网络通信引擎,它采用 C 编写,提供了协程和高性能的网络编程支持。Swoole 支持多种网络服务器和客户端…...

“不要卷模型,要卷应用”之高考志愿填报智能体
摘要:李总的发言深刻洞察了当前人工智能领域的发展趋势与核心价值所在,具有高度的前瞻性和实践性。“大家不要卷模型,要卷应用”这一观点强调了在当前人工智能领域,应该更加注重技术的实际应用而非单纯的技术竞赛或模型优化。个性…...

k8s离线部署芋道源码后端
目录 概述实践Dockerfilek8s部署脚本 概述 本篇将对 k8s离线部署芋道源码后端 进行详细的说明,对如何构建 Dockerfile,如何整合 Nginx,如何整合 ingress 进行实践。 相关文章:[nacos在k8s上的集群安装实践] k8s离线部署芋道源码前…...
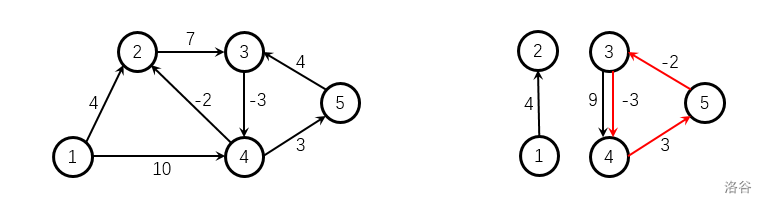
图论·Day01
P3371 P4779 P3371 【模板】单源最短路径(弱化版) 注意的点: 边有重复,选择最小边!对于SPFA算法容易出现重大BUG,没有负权值的边时不要使用!!! 70分代码 朴素板dijsk…...

hutool ExcelUtil 导出导入excel
引入依赖 <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.15</version></dependency>文件导入 public void savelist(String filepath,String keyname){ExcelReader reader Exce…...

打卡第7天-----哈希表
继续坚持✊,我现在看到leetcode上的题不再没有思路了,真的是思路决定出路,在做题之前一定要把思路梳理清楚。 一、四数相加 leetcode题目编号:第454题.四数相加II 题目描述: 给定四个包含整数的数组列表 A , B , C , …...
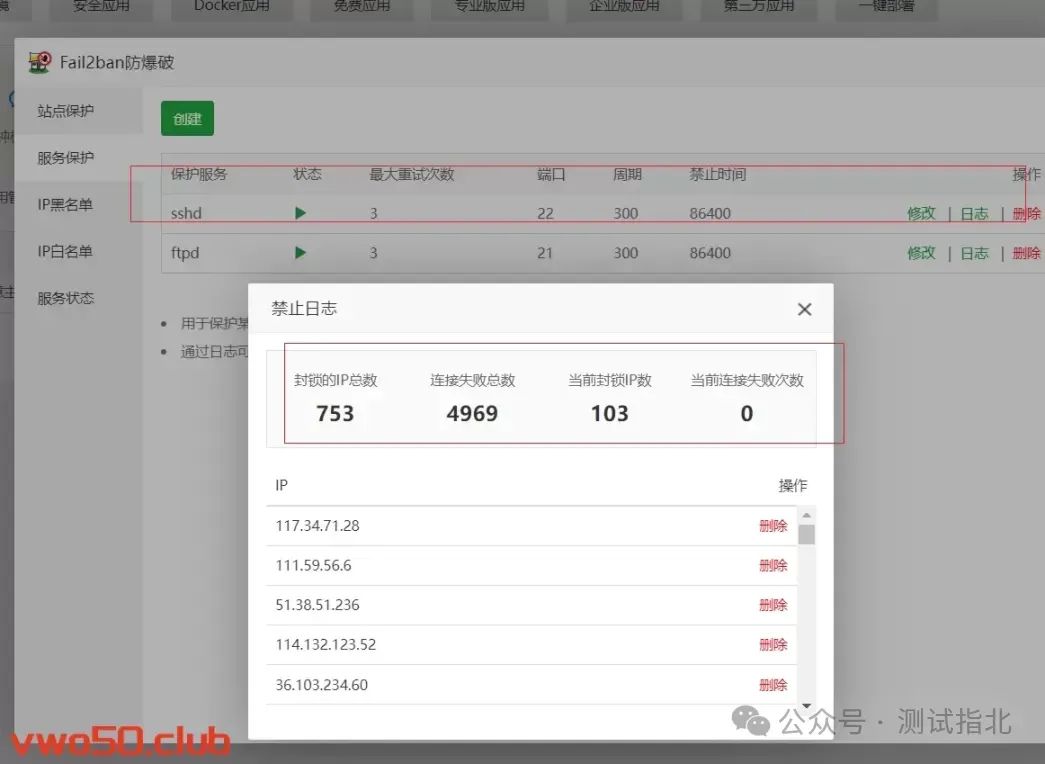
【Linux】WEB网站网络防火墙(WAF软件)Fail2ban:保护服务器免受恶意攻击的必备工具
随着互联网的迅速发展,服务器的安全性日益成为用户和管理员关注的焦点。恶意攻击者不断寻找机会侵入服务器,窃取敏感信息、破坏数据或者滥用系统资源。为了抵御这些威胁,许多安全工具应运而生,其中一款备受推崇的工具就是 Fail2ba…...

妙笔生词智能写歌词软件:创新助力还是艺术之殇?
在音乐创作日益普及和多样化的当下,各种辅助工具层出不穷,妙笔生词智能写歌词软件便是其中之一。那么,它到底表现如何呢? 妙笔生词智能写歌词软件(veve522)的突出优点在于其便捷性和高效性。对于那些灵感稍…...

力扣hot100-普通数组
文章目录 题目:最大子数组和方法1 动态规划方法2 题目:合并区间题解 题目:轮转数组方法1-使用额外的数组方法2-三次反转数组 题目:除自身以外数组的乘积方法1-用到了除法方法2-前后缀乘积法 题目:最大子数组和 原题链…...
深入浅出Transformer:大语言模型的核心技术
引言 随着自然语言处理(NLP)领域的不断发展,Transformer模型逐渐成为现代大语言模型的核心技术。无论是BERT、GPT系列,还是最近的T5和Transformer-XL,这些模型的背后都离不开Transformer架构。本文将详细介绍Transfor…...

MacOS隐藏文件打开指南
MacOS隐藏文件打开指南 方法一: 直接按下键盘上的【commandshift.】,这时候就可以在mac系统中就会自动显示隐藏的文件夹了 方法二: 在终端查看 ls -la...

grafana数据展示
目录 一、安装步骤 二、如何添加喜欢的界面 三、自动添加注册客户端主机 一、安装步骤 启动成功后 可以查看端口3000是否启动 如果启动了就在浏览器输入IP地址:3000 账号密码默认是admin 然后点击 log in 第一次会让你修改密码 根据自定义密码然后就能登录到界面…...

53-4 内网代理6 - frp搭建三层代理
前提:53-3 内网代理5 - frp搭建二级代理-CSDN博客 三级网络代理 在办公区入侵后,发现需要进一步渗透核心区网络(192.168.60.0/24),并登录域控制器的远程桌面。使用FRP在EDMZ区、办公区与核心区之间建立三级网络的SOCKS5代理,以便访问核心区的域控制器。 VPS上的FRP服…...

SQLite 命令行客户端 + HTA 实现简易UI
SQLite 命令行客户端 HTA 实现简易UI SQLite 客户端.hta目录结构参考资料 仅用于探索可行性,就只实现了 SELECT。 SQLite 客户端.hta <!DOCTYPE html> <html> <head><meta http-equiv"Content-Type" content"text/html; cha…...

TikTok小店推出“百万英镑俱乐部”,实力宠卖家!
TikTok Shop近期在英国市场重磅推出了“百万英镑俱乐部”激励计划,这一举措旨在通过一系列诱人福利,助力商家在TikTok平台上实现销售飞跃。该计划不仅彰显了TikTok Shop对于商家成长的深切关怀,更以实际行动诠释了“实力宠卖家”的承诺。 我…...

路径规划 | 基于蚁群算法的三维无人机航迹规划(Matlab)
目录 效果一览基本介绍程序设计参考文献 效果一览 基本介绍 基于蚁群算法的三维无人机航迹规划(Matlab)。 蚁群算法(Ant Colony Optimization,ACO)是一种模拟蚂蚁觅食行为的启发式算法。该算法通过模拟蚂蚁在寻找食物时…...
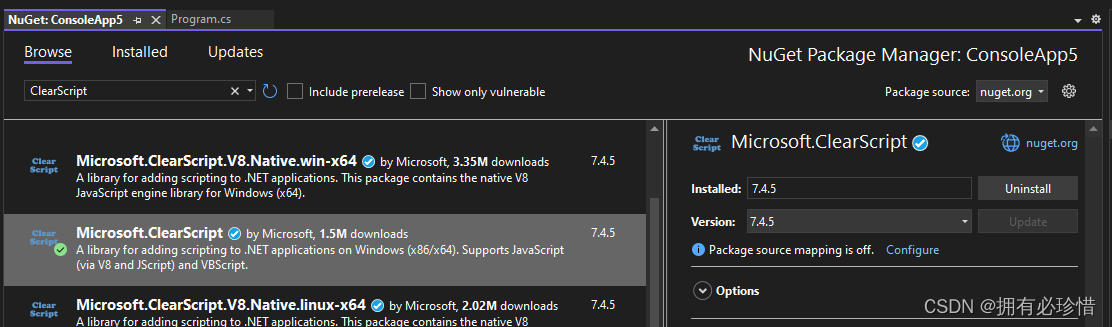
.Net C#执行JavaScript脚本
文章目录 前言一、安装二、执行 JavaScript 脚本三、与脚本交互四、JS 调用 C# 方法五、多线程使用总结 前言 ClearScript 是一个 .NET 平台下的开源库,用于在 C# 和其他 .NET 语言中执行脚本代码。它提供了一种方便和安全的方法来将脚本与应用程序集成,…...

Python字节码反编译技术深度解析:pycdc项目的架构实现与实战应用
Python字节码反编译技术深度解析:pycdc项目的架构实现与实战应用 【免费下载链接】pycdc C python bytecode disassembler and decompiler 项目地址: https://gitcode.com/GitHub_Trending/py/pycdc 在Python生态系统中,字节码反编译技术一直是系…...

终极指南:如何在3DS上原生运行GBA游戏,告别模拟器卡顿
终极指南:如何在3DS上原生运行GBA游戏,告别模拟器卡顿 【免费下载链接】open_agb_firm open_agb_firm is a bare metal app for running GBA homebrew/games using the 3DS builtin GBA hardware. 项目地址: https://gitcode.com/gh_mirrors/op/open_a…...

金融级语音质检系统上线倒计时72小时:PlayAI最新v3.2.1版本如何用动态声纹隔离+情绪敏感词熔断机制,让监管抽查通过率从61%飙升至99.2%
更多请点击: https://kaifayun.com 第一章:金融级语音质检系统的监管挑战与技术跃迁 金融行业对语音交互的合规性要求极为严苛,监管机构如银保监会、证监会及《个人信息保护法》《金融消费者权益保护实施办法》等持续强化对语音数据采集、存…...

黑苹果配置终极简化:OpCore Simplify三步搞定OpenCore EFI
黑苹果配置终极简化:OpCore Simplify三步搞定OpenCore EFI 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置而烦恼吗…...

脑机接口的 “信号生命线”:自研模拟前端如何破解非侵入式采集的性能困局
近些年来,脑机接口技术飞速发展,打破了人脑与外部设备之间的沟通壁垒,摆脱肢体、语言的限制,实现大脑信号与机器设备的直接交互。这项技术广泛应用于医疗康复、智能交互、疲劳监测、认知分析等领域,也是当下人工智能、…...
与理想匹配层(PML)的实战对比与设置要点)
别再乱设边界了!HFSS中辐射边界(Radiation)与理想匹配层(PML)的实战对比与设置要点
HFSS仿真中的边界条件艺术:Radiation与PML的深度解析与实战选择 在电磁场仿真领域,边界条件的设置往往决定了模拟结果的准确性与计算效率。对于天线设计、雷达散射截面(RCS)分析等开放空间电磁问题,工程师们常常面临一个关键选择:…...

基于AM62x核心板的微电网智能化改造:异构多核驱动与边缘计算实践
1. 项目概述:当嵌入式核心板遇上微电网最近在做一个挺有意思的项目,客户想把他们园区里那套老旧的微电网系统给“智能化”一下。原来的系统,说白了就是一堆继电器、PLC和工控机攒起来的,数据采集靠串口,控制逻辑写在梯…...

保姆级教程:用MATLAB R2019a搞定小波分析,从数据导入到等值线图绘制全流程
MATLAB小波分析实战:从数据清洗到可视化呈现的完整指南 小波分析作为时频域分析的利器,在信号处理、地球物理、生物医学等领域广泛应用。但对于刚接触MATLAB的研究生或数据分析师而言,如何将Excel中的原始数据一步步转化为专业的小波系数图和…...

Proxmox-Arm64:ARM架构企业级虚拟化的技术突破与实现
Proxmox-Arm64:ARM架构企业级虚拟化的技术突破与实现 【免费下载链接】Proxmox-Arm64 Proxmox VE & PBS unofficial arm64 version 项目地址: https://gitcode.com/gh_mirrors/pr/Proxmox-Arm64 随着ARM64架构在服务器、边缘计算和嵌入式领域的快速普及&…...

视频硬字幕提取革命:87种语言本地OCR识别,让字幕提取从未如此简单
视频硬字幕提取革命:87种语言本地OCR识别,让字幕提取从未如此简单 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含…...