人工智能算法工程师(中级)课程3-sklearn机器学习之数据处理与代码详解
大家好,我是微学AI,今天给大家分享一下人工智能算法工程师(中级)课程3-sklearn机器学习之数据处理与代码详解。 Sklearn(Scikit-learn)是一个基于Python的开源机器学习库,它提供了简单有效的数据挖掘和数据分析工具。Sklearn包含了许多机器学习算法,如分类、回归、聚类、降维等,广泛应用于各种机器学习任务中。本文将介绍Sklearn的基本使用方法,包括数据预处理、数据集划分和读取使用等内容,并附上完整可运行的代码。

文章目录
- Sklearn机器学习中的数据处理与代码详解
- 1. Sklearn包的介绍
- 2. 机器学习任务介绍
- 2.1 分类任务
- 2.2 回归任务
- 3. 数据的标准化处理
- 4. 数据集划分和读取使用
- 5. 总结
Sklearn机器学习中的数据处理与代码详解
1. Sklearn包的介绍
Sklearn是一个基于Python的开源机器学习库,它提供了一系列简单有效的数据挖掘和数据分析工具。Sklearn的主要特点如下:
- 简单易用:Sklearn提供了简洁的API,使得用户可以轻松实现各种机器学习算法。
- 功能丰富:Sklearn包含了大量的机器学习算法,如分类、回归、聚类、降维等。
- 良好的文档和社区支持:Sklearn拥有详细的文档和活跃的社区,方便用户学习和解决问题。
- 广泛的适用性:Sklearn可以与NumPy、Pandas、Matplotlib等Python库无缝集成,适用于各种机器学习任务。
2. 机器学习任务介绍
机器学习任务主要包括监督学习、无监督学习和强化学习。本文将重点介绍监督学习中的分类任务和回归任务。
2.1 分类任务
分类任务是监督学习的一种,它的目的是根据给定的特征将数据集划分为不同的类别。分类问题的目标变量通常是离散的。分类算法通过学习输入特征和目标变量之间的关系,构建一个模型,用于对新的数据进行类别预测。常见的分类算法包括逻辑回归、支持向量机、决策树、随机森林等。
分类任务的数学描述可以表示为:给定一个特征空间 X X X和一个标签空间 Y Y Y,其中 Y Y Y是一个有限集合,分类任务的目标是学习一个映射函数 h : X → Y h: X \rightarrow Y h:X→Y,使得对于给定的输入 x x x,可以预测出最可能的标签 y y y。
2.2 回归任务
回归任务是监督学习的另一种类型,它的目的是预测一个连续的数值。回归问题的目标变量通常是连续的。回归算法通过学习输入特征和目标变量之间的函数关系,构建一个模型,用于对新的数据进行数值预测。常见的回归算法包括线性回归、岭回归、Lasso回归等。
回归任务的数学描述可以表示为:给定一个特征空间 X X X和一个实数集 Y Y Y,回归任务的目标是学习一个映射函数 h : X → Y h: X \rightarrow Y h:X→Y,使得对于给定的输入 x x x,可以预测出一个实数 y y y。
3. 数据的标准化处理
在机器学习任务中,数据的标准化处理是非常重要的一步。数据标准化可以消除不同特征之间的量纲影响,提高模型的训练效率和预测精度。Sklearn提供了StandardScaler类来实现数据的标准化处理。
数据标准化是数据处理中的一个重要步骤,它的目的是消除不同特征之间的量纲影响,使得各特征对模型的贡献相同,提高模型的训练效率和预测精度。标准化处理通常包括两种方法:归一化和标准化。
归一化的数学描述为:将特征 x x x的值缩放到一个固定的范围,通常为 [ 0 , 1 ] [0, 1] [0,1]。归一化公式可以表示为:
x norm = x − x min x max − x min x_{\text{norm}} = \frac{x - x_{\text{min}}}{x_{\text{max}} - x_{\text{min}}} xnorm=xmax−xminx−xmin
其中, x min x_{\text{min}} xmin和 x max x_{\text{max}} xmax分别是特征 x x x的最小值和最大值。
标准化的数学描述为:将特征 x x x的值转换为具有零均值和单位标准差的分布。标准化公式可以表示为:
x std = x − μ σ x_{\text{std}} = \frac{x - \mu}{\sigma} xstd=σx−μ
其中, μ \mu μ是特征 x x x的均值, σ \sigma σ是特征 x x x的标准差。
接下来我将使用StandardScaler对数据进行标准化的示例代码:
from sklearn.preprocessing import StandardScaler
import numpy as np
# 创建数据
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 创建StandardScaler对象
scaler = StandardScaler()
# 训练标准化器
scaler.fit(data)
# 对数据进行标准化处理
data_standardized = scaler.transform(data)
print("原始数据:")
print(data)
print("标准化后的数据:")
print(data_standardized)
输出结果:
原始数据:
[[1 2 3][4 5 6][7 8 9]]
标准化后的数据:
[[-1.22474487 -1.22474487 -1.22474487][ 0. 0. 0. ][ 1.22474487 1.22474487 1.22474487]]
4. 数据集划分和读取使用
在机器学习任务中,通常需要将数据集划分为训练集和测试集。Sklearn提供了train_test_split函数来实现这一功能。
下面是一个使用train_test_split划分数据集的示例代码:
from sklearn.model_selection import train_test_split
import numpy as np
# 创建数据
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
labels = np.array([0, 1, 0, 1, 0])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.3, random_state=42)
print("训练集数据:")
print(X_train)
print("测试集数据:")
print(X_test)
print("训练集标签:")
print(y_train)
print("测试集标签:")
print(y_test)
输出结果:
训练集数据:
[[1 2][5 6][9 10]]
测试集数据:
[[3 4][7 8]]
训练集标签:
[0 0 0]
测试集标签:
[1 1]
5. 总结
文章主要介绍了Sklearn机器学习中的数据处理与代码详解,包括Sklearn包的介绍、机器学习任务介绍、数据的标准化处理、数据集划分和读取使用等内容。通过阅读本文,读者可以了解Sklearn的基本使用方法,并学会如何使用Sklearn进行数据预处理和模型训练。
相关文章:
人工智能算法工程师(中级)课程3-sklearn机器学习之数据处理与代码详解
大家好,我是微学AI,今天给大家分享一下人工智能算法工程师(中级)课程3-sklearn机器学习之数据处理与代码详解。 Sklearn(Scikit-learn)是一个基于Python的开源机器学习库,它提供了简单有效的数据挖掘和数据分析工具。Sklearn包含了…...

华为机考真题 -- 螺旋数字矩阵
题目描述: 疫情期间,小明隔离在家,百无聊赖,在纸上写数字玩。他发明了一种写法:给出数字 个数 n 和行数 m(0 < n ≤ 999,0 < m ≤ 999),从左上角的 1 开始&#x…...

防御笔记第四天(持续更新)
1.状态检测技术 检测数据包是否符合协议的逻辑顺序;检查是否是逻辑上的首包,只有首包才会创建会话表。 状态检测机制可以选择关闭或则开启 [USG6000V1]firewall session link-state tcp ? check Indicate link state check [USG6000V1]firewall ses…...

HUAWEI VRRP 实验
实验要求:在汇聚交换机上SW1和SW2中实施VRRP以保证终端网关的高可靠性(当某一个网关设备失效时,其他网关设备依旧可以实现业务数据的转发。) 1.在SW1和SW2之间配置链路聚合,以提高带宽速度。 2.PC1 访问远端网络8.8.8.8 ,优先走…...
领取serv00免费虚拟主机
参考 教程地址【免费serv00虚拟机SSH登录搭建网站】 领取地址 领到了 SSH登录要魔法,网页登录不用 轻松搭建自己的静态网站 soulio.serv00.net 网页加载速度还可以。 ...

云开发技术的壁纸小程序源码,无需服务期无需域名
1、本款小程序为云开发版本,不需要服务器域名 2、文件内有图文搭建教程,小白也不用担心不会搭建。 3、本程序反应速度极快,拥有用户投稿、积分系统帮助各位老板更多盈利。 4、独家动态壁纸在线下载,给用户更多的选择 5、最新版套图…...
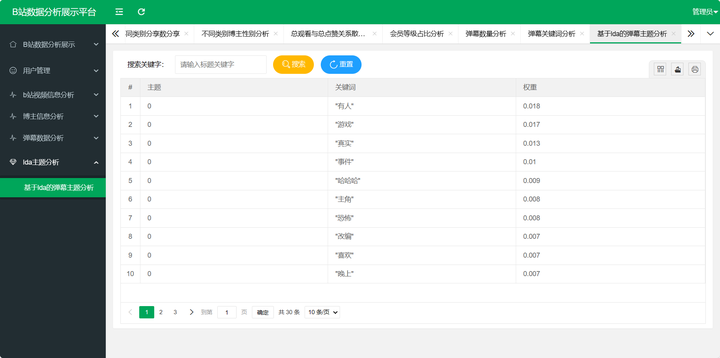
基于Python的哔哩哔哩数据分析系统设计实现过程,技术使用flask、MySQL、echarts,前端使用Layui
背景和意义 随着互联网和数字媒体行业的快速发展,视频网站作为重要的内容传播平台之一,用户量和内容丰富度呈现爆发式增长。本研究旨在设计并实现一种基于Python的哔哩哔哩数据分析系统,采用Flask框架、MySQL数据库以及echarts数据可视化技术…...

顺序结构 ( 四 ) —— 标准数据类型 【互三互三】
序 C语言提供了丰富的数据类型,本节介绍几种基本的数据类型:整型、实型、字符型。它们都是系统定义的简单数据类型,称为标准数据类型。 整型(integer) 在C语言中,整型类型标识符为int。根据整型变量的取值范…...

科普文:jvm笔记
一、JVM概述# 1. JVM内部结构# 跨语言的平台,只要遵循编译出来的字节码的规范,都可以由JVM运行 虚拟机 系统虚拟机 VMvare 程序虚拟机 JVM JVM结构 HotSpot虚拟机 详细结构图 前端编译器是编译为字节码文件 执行引擎中的JIT Compiler编译器是把字节…...

springboot对象参数赋值变化
java springboot 项目, 通过接口修改Person类 name值, 在别的类中,注入Person类 Resource Person person, 为什么拿不到 接口修改的 name的值,是Person类 不同的对象造成的 吗 参数对象和注入对象区别 Person类&…...

树形结构的一种便捷实现方案
背景 在开发过程中经常需要把平铺的数据结构转为树形的数据结构,例如多级菜单、组织机构等。 实现方案有很多种。 1、可以使用递归查询,但是这样数据一多会导致频繁的多次查询数据库,产生很多额外的IO开销,总体的响应时间会比较…...

探索AI数字人的开源解决方案
引言 随着人工智能(AI)技术的迅猛发展,AI数字人(或虚拟人)正逐渐走进我们的生活,从虚拟助手到虚拟主播,再到虚拟客服,AI数字人在各个领域展现出巨大的潜力。开源解决方案的出现&…...

科普文:深入理解负载均衡(四层负载均衡、七层负载均衡)
概叙 网络模型:OSI七层模型、TCP/IP四层模型、现实的五层模型 应用层:对软件提供接口以使程序能使用网络服务,如事务处理程序、文件传送协议和网络管理等。(HTTP、Telnet、FTP、SMTP) 表示层:程序和网络之…...

华为模拟器ensp中USG6000V防火墙web界面使用
防火墙需要配置 新建拓扑选择USG6000V型号 在防火墙中导包 忘记截图了 启动设备 输入用户名密码 默认用户名:admin 默认密码:Admin123 修改密码 然后他会提示你是否要修改密码,想改就改不想改就不改 进入命令行界面 进入系统视图开启web…...

使用Python绘制气泡图
使用Python绘制气泡图 气泡图效果代码 气泡图 气泡图通过气泡的大小表示数据的一个维度,用于展示三个维度的数据。例如,可以展示城市的人口、面积和GDP。 效果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mjj27sP7-1720…...

政安晨:【Keras机器学习示例演绎】(五十四)—— 使用神经决策森林进行分类
目录 导言 数据集 设置 准备数据 定义数据集元数据 为训练和验证创建 tf_data.Dataset 对象 创建模型输入 输入特征编码 深度神经决策树 深度神经决策森林 实验 1:训练决策树模型 实验 2:训练森林模型 政安晨的个人主页:政安晨 欢…...
洞察消费者心理:Transformer模型在消费者行为分析的创新应用
洞察消费者心理:Transformer模型在消费者行为分析的创新应用 在数字化时代,消费者行为分析对于企业理解市场动态、制定营销策略至关重要。Transformer模型,以其在处理序列数据方面的优势,为消费者行为分析提供了新的视角和工具。…...

如何安全使用代理ip
1、选择可靠的代理服务提供商:选择知名的、信誉良好的代理服务提供商,避免使用免费的代理服务,因为免费的代理服务可能存在安全隐患。 2、使用HTTPS代理:使用HTTPS代理可以加密你的网络流量,保护你的隐私和安全。 3、…...

机器学习——LR、GBDT、SVM、CNN、DNN、RNN、Word2Vec等模型的原理和应用
LR(逻辑回归) 原理: 逻辑回归模型(Logistic Regression, LR)是一种广泛应用于分类问题的统计方法,尤其适用于二分类问题。其核心思想是通过Sigmoid函数将线性回归模型的输出映射到(0,1)区间,从…...

揭秘SQL Server数据库选项:性能与行为的调控者
揭秘SQL Server数据库选项:性能与行为的调控者 在SQL Server的世界中,数据库选项是那些可以调整以优化数据库性能和行为的设置。它们是数据库管理员和开发者的得力助手,通过精细调控,可以显著提升数据库的响应速度和资源利用率。…...

抖音批量下载工具架构解析:从技术实现到实战配置指南
抖音批量下载工具架构解析:从技术实现到实战配置指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

从F1赛车到无人机:雷达测距测速公式在现实世界中的5个酷应用
从F1赛车到无人机:雷达测距测速公式在现实世界中的5个酷应用 当F1赛车以300公里时速呼啸而过时,车手如何精确判断与前车的安全距离?当无人机在复杂环境中自主飞行时,又是怎样避开突然出现的障碍物?这些看似科幻的场景背…...
)
从机器人到游戏引擎:用Eigen库搞定C++中的3D数学(附完整代码示例)
从机器人到游戏引擎:用Eigen库搞定C中的3D数学(附完整代码示例) 在计算机图形学、机器人学和游戏开发中,3D数学是不可或缺的基础。无论是计算机器人末端执行器的位姿,还是实现3D相机的变换,亦或是进行刚体运…...

QKeyMapper:Windows平台下无需重启系统的终极按键映射解决方案
QKeyMapper:Windows平台下无需重启系统的终极按键映射解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&am…...

自制编程语言:挑战与乐趣并存,10000 行 C++ 代码实现多项功能,未来规划丰富!
自制编程语言:比想象中容易,也更具挑战2026 年 5 月 6 日。去年 12 月中旬,作者开始打造自己的编程语言,目前距生产级质量有差距,但已编写约 1000 行代码的蒙特卡罗路径追踪器。项目暂停,作者分享相关内容。…...

Neat Bookmarks:重构浏览器书签管理的技术架构与实践方案
Neat Bookmarks:重构浏览器书签管理的技术架构与实践方案 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 开篇:数字信息过载时…...

ngx_unix_recv
1 定义 ngx_unix_recv 函数 定义在 ./nginx-1.24.0/src/os/unix/ngx_recv.cssize_t ngx_unix_recv(ngx_connection_t *c, u_char *buf, size_t size) {ssize_t n;ngx_err_t err;ngx_event_t *rev;rev c->read;#if (NGX_HAVE_KQUEUE)if (ngx_event_flags & N…...

Netgear路由器终极救援指南:nmrpflash工具快速恢复变砖设备
Netgear路由器终极救援指南:nmrpflash工具快速恢复变砖设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器固件升级失败、意外断电或系统崩溃时,设备会变成一…...

如何永久保存微信聊天记录?三步搞定数据备份与深度分析指南
如何永久保存微信聊天记录?三步搞定数据备份与深度分析指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...

LinkSwift:八大网盘直链解析工具的技术实现与使用指南
LinkSwift:八大网盘直链解析工具的技术实现与使用指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...