根据样本数据的区域分布进行重采样
希望根据数据的区域分布进行重采样,通常用于处理空间数据或具有明显区域特征的数据。
文章目录
- 重采样整体思路
- 数据集
- 重采样步骤
- 区域划分的方法
- 具体代码案例
- 1. 基于规则的划分
- 2. 基于密度的划分
- 3. 基于层次的划分
- 4. 基于图的划分
- 5. 基于网格的划分
- 6. 基于自组织映射(SOM)的划分
重采样整体思路
数据集
假设有一个包含地理位置和相关特征的数据集。
| 样本编号 | 经度 | 纬度 | 特征1 | 特征2 | 特征3 |
|---|---|---|---|---|---|
| 1 | 10.1 | 20.2 | 0.2 | 0.5 | 0.3 |
| 2 | 10.3 | 20.4 | 0.8 | 0.1 | 0.7 |
| … | … | … | … | … | … |
| 1000 | 10.5 | 20.6 | 0.4 | 0.6 | 0.2 |
重采样步骤
-
区域划分:将数据集划分为不同的区域。可以使用聚类算法(如K-means)或基于地理位置的划分方法。
from sklearn.cluster import KMeans# 提取经纬度作为特征 X_geo = X[:, :2]# 使用K-means进行区域划分 kmeans = KMeans(n_clusters=10) regions = kmeans.fit_predict(X_geo) -
计算区域权重:根据每个区域的样本数量计算权重。样本数量较少的区域权重较高。
import numpy as np# 计算每个区域的样本数量 region_counts = np.bincount(regions)# 计算权重 weights = 1 / region_counts[regions] -
生成新样本:使用有放回的随机抽样方法,从原始样本中抽取样本点,每次抽样时根据区域权重来决定每个样本点被抽中的概率。假设生成1000个新样本。
import randomn_samples = len(df.index)def weighted_region_sampling(X, weights, n_samples):indices = random.choices(range(len(X)), weights=weights, k=n_samples)X_resampled = X.iloc[indices]return X_resampledX_resampled = weighted_region_sampling(X, weights, 1000) -
构建新数据集:将新生成的样本组合成一个新的数据集。
new_dataset = X_resampled
区域划分的方法
-
基于规则的划分:根据特定的规则或标准手动划分区域。例如,可以根据地理位置的经纬度范围、行政区划、自然地理特征等进行划分。
-
基于密度的划分:使用基于密度的聚类算法(如DBSCAN)来识别数据中的高密度区域,并将其作为不同的区域。
-
基于层次的划分:使用层次聚类算法(如Agglomerative Clustering)来构建数据的层次结构,并根据需要选择合适的层次进行区域划分。
-
基于图的划分:将数据表示为图结构,并使用图划分算法(如Spectral Clustering)来识别图中的不同社区或区域。
-
基于网格的划分:将数据空间划分为规则的网格,并根据数据点在网格中的分布进行区域划分。
-
基于自组织映射(SOM)的划分:使用自组织映射(Self-Organizing Maps, SOM)来将高维数据映射到低维空间,并根据映射结果进行区域划分。
具体代码案例
1. 基于规则的划分
假设有一个包含地理位置和相关特征的数据集,希望根据经纬度范围进行区域划分。
def assign_region(longitude, latitude):if 10.0 <= longitude < 10.2 and 20.0 <= latitude < 20.3:return 0elif 10.2 <= longitude < 10.4 and 20.3 <= latitude < 20.6:return 1else:return 2regions = [assign_region(lon, lat) for lon, lat in zip(X[:, 0], X[:, 1])]
2. 基于密度的划分
使用DBSCAN算法进行基于密度的区域划分。
from sklearn.cluster import DBSCAN# 提取经纬度作为特征
X_geo = X[:, :2]# 使用DBSCAN进行区域划分
dbscan = DBSCAN(eps=0.1, min_samples=5)
regions = dbscan.fit_predict(X_geo)
3. 基于层次的划分
使用Agglomerative Clustering算法进行基于层次的区域划分。
from sklearn.cluster import AgglomerativeClustering# 提取经纬度作为特征
X_geo = X[:, :2]# 使用Agglomerative Clustering进行区域划分
agg_clustering = AgglomerativeClustering(n_clusters=10)
regions = agg_clustering.fit_predict(X_geo)
4. 基于图的划分
使用Spectral Clustering算法进行基于图的区域划分。
from sklearn.cluster import SpectralClustering# 提取经纬度作为特征
X_geo = X[:, :2]# 使用Spectral Clustering进行区域划分
spectral_clustering = SpectralClustering(n_clusters=10, affinity='nearest_neighbors')
regions = spectral_clustering.fit_predict(X_geo)
5. 基于网格的划分
将数据空间划分为规则的网格,并根据数据点在网格中的分布进行区域划分。
import numpy as np# 定义网格范围和大小
grid_lon = np.linspace(10.0, 10.6, 3)
grid_lat = np.linspace(20.0, 20.6, 3)def assign_grid_region(longitude, latitude):for i in range(len(grid_lon) - 1):for j in range(len(grid_lat) - 1):if grid_lon[i] <= longitude < grid_lon[i + 1] and grid_lat[j] <= latitude < grid_lat[j + 1]:return (i, j)return Noneregions = [assign_grid_region(lon, lat) for lon, lat in zip(X[:, 0], X[:, 1])]
6. 基于自组织映射(SOM)的划分
使用自组织映射(Self-Organizing Maps, SOM)来将高维数据映射到低维空间,并根据映射结果进行区域划分。
from minisom import MiniSom# 提取经纬度作为特征
X_geo = X[:, :2]# 使用SOM进行区域划分
som = MiniSom(10, 10, 2, sigma=0.5, learning_rate=0.5)
som.train_random(X_geo, 100)# 获取每个样本的映射结果
regions = np.array([som.winner(x) for x in X_geo])
相关文章:

根据样本数据的区域分布进行重采样
希望根据数据的区域分布进行重采样,通常用于处理空间数据或具有明显区域特征的数据。 文章目录 重采样整体思路数据集重采样步骤 区域划分的方法具体代码案例1. 基于规则的划分2. 基于密度的划分3. 基于层次的划分4. 基于图的划分5. 基于网格的划分6. 基于自组织映射…...

数据库之MQL
1,查询所有 mysql> select * from grade;2, mysql> select id,firstname,lastname from grade;3, mysql> select firstname,lastname from grade where id > 4;4, mysql> select * from grade where sex f;5&…...
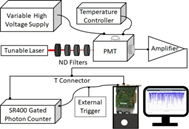
LabVIEW平台从离散光子到连续光子的光子计数技术
光子计数技术用于将输入光子数转换为离散脉冲。常见的光子计数器假设光子是离散到达的,记录到来的每一个光子。但是,当两个或多个光子同时到达时,计数器会将其记录为单个脉冲,从而只计数一次。当连续光子到达时,离散光…...

【Linux】Windows平台使用gdb调试FFmpeg源码
FFmpeg是一个跨平台的多媒体库,有时需要在别的平台上进行开发和调试,记录一下在linux环境下使用gdb来调试FFmpeg源码的基本方式 1.可执行文件 在windows平台使用linux环境来调试FFmpeg源码,需要编译生成一个后缀有_g的exe文件,参…...

提交表单form之后发送表单内容到指定邮箱(单php文件实现)
提交各种表单之后,自动将表单的内容通过邮件api接口的形式自动发送到指定的邮箱。步骤如下: 1.在aoksend注册一个账号。 2.绑定一个自己的域名。做域名解析之后验证。验证通过后自动提交审核。等待审核通过。 3.设置一个邮件模板。aoksend内置了一些优…...

【设计模式之美】策略模式方法论:解耦策略的定义、创建和使用
文章目录 一. 策略的定义-封装策略,面向接口二. 策略的创建-创建策略工厂1. 对于无状态策略2. 对于有状态策略 三. 策略的使用:动态选择四. 避免分支判断-策略的优雅1. 对于无状态的策略2. 对于有状态的策略 策略模式是定义一族算法类,将每个…...

解析 pdfminer pdfparser.py
解析 pdfminer pdfparser.py 1. 导入必要的模块2. 定义PDFParser类2.1 初始化方法2.2 设置文档方法2.3 处理关键词方法举例说明: 3. 定义PDFStreamParser类3.1 初始化方法3.2 刷新方法3.3 处理关键词方法 总结 今天我们来看一段Python代码,这段代码实现了一个PDF文件的解析器。…...

day10:03 一文搞懂encode和encoding的区别
在Python中,处理字符串时经常会遇到encode()方法和encoding参数,它们都与字符串的编码和解码有关,但用途和上下文有所不同。下面通过案例来解释它们的关系和区别。 1. encode() 方法 encode()方法是字符串(str)类型的…...

【wordpress教程】wordpress博客网站添加非法关键词拦截
有的网站经常被恶意搜索,站长们不胜其烦。那我们如何屏蔽恶意搜索关键词呢?下面就随小编一起来解决这个问题吧。 后台设置预览图: 设置教程: 1、把以下代码添加至当前主题的 functions.php 文件中: add_action(admi…...

untiy 在菜单栏添加自定义按钮 点击按钮弹出一个Unity窗口,并在窗口里添加属性
using System.Collections.Generic; using UnityEditor; using UnityEngine; using UnityEngine.Rendering.PostProcessing;public class AutoGenerateWindow : EditorWindow //这是定义一个窗口 {public string subjecttName "科目名字";//科目的名字public GameOb…...

VIM模式之间的切换
命令行界面下,常用的文本编辑器是 VI / VIM(VI增强版),VI 是 Linux 最通用的文本编辑器,VIM相较于VI,提供了代码高亮等功能,两者用法完全兼容; 1. 进入 VIM 工作界面 vim 文件名 2. 进入编辑模式 三种方…...

Linux操作系统安全分析与防护
Linux操作系统安全机制 Linux操作系统由于其开放源代码和广泛应用,在服务器和嵌入式系统中占有重要地位。为了确保Linux系统的安全,必须了解并实施一系列有效的安全机制。这些机制包括用户身份验证、访问控制、数据加密、日志和审计、安全更新等。 一、…...

【LeetCode】面试题 16.21. 交换和
质量还不错的一道题,适合用于考察二分法。 1. 题目 2. 分析 求出两个数组的总和,我们令总和少的为less,总和多的为more;如果两个数组的总和是奇数,那么怎么都配不平,直接返回false;如果两个数…...
Web知识库应用程序LibreKB
什么是 LibreKB ? LibreKB 是一款知识库 Web 应用程序。免费、开源、自托管,基于 PHP/MySQL。 官方并没有 Docker 镜像,老苏这次图省事,并没有像往常一样构建一个镜像,而是基于 Docker 搭建了一个 LAMP 环境࿰…...

神经网络和安全结合:一种基于神经网络的智能攻击检测与防御系统;构建攻击行为预测模型
目录 神经网络和安全结合 摘要 引言 理论基础 技术实现与创新点 实验验证 结论与展望 一种基于神经网络的智能攻击检测与防御系统 一、系统概述 二、主要功能 三、技术特点 四、应用前景 构建攻击行为预测模型 一、构建攻击行为预测模型的步骤 1. 数据收集 2. …...
得到文件中的H264数据和AAC数据(纯手工,不依赖第三方开源库))
音视频解封装demo:将FLV文件解封装(demux)得到文件中的H264数据和AAC数据(纯手工,不依赖第三方开源库)
1、README 前言 注意:flv是不支持h.265封装的。目前解封装功能正常,所得到的H.264文件与AAC文件均可正常播放。 a. demo使用 $ make clean && make DEBUG1 $ $ $ ./flv_demux_h264_aac Usage: ./flv_demux_h264_aac avfile/test1.flv./flv_d…...

51单片机(STC8051U34K64)_RA8889_SPI4参考代码(v1.3)
硬件:STC8051U34K64 RA8889开发板(硬件跳线变更为SPI-4模式,PS101,R143,R141短接,R142不接) STC8051U34K64是STC最新推出来的单片机,主要用于替换传统的8051单片机,与标…...

关于C# 开发Winfrom事后总结
一:要求能读取文件夹中视频及图片并判断 private void Form1_Load(object sender, EventArgs e){string foldPath "路径";//获取该目录下的文件 string[] files Directory.GetFiles(foldPath "\\", "*.*", System.IO.SearchOption…...

Python学习笔记35:进阶篇(二十四)pygame的使用之音频文件播放
前言 基础模块的知识通过这么长时间的学习已经有所了解,更加深入的话需要通过完成各种项目,在这个过程中逐渐学习,成长。 我们的下一步目标是完成python crash course中的外星人入侵项目,这是一个2D游戏项目。在这之前ÿ…...
Transformer-LSTM预测 | Matlab实现Transformer-LSTM多变量时间序列预测
Transformer-LSTM预测 | Matlab实现Transformer-LSTM多变量时间序列预测 目录 Transformer-LSTM预测 | Matlab实现Transformer-LSTM多变量时间序列预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现Transformer-LSTM多变量时间序列预测,Transf…...

智能车底盘DIY避坑指南:直流电机、减速器、编码器怎么选?TB6612FNG够用吗?
智能车底盘DIY避坑指南:直流电机、减速器、编码器怎么选?TB6612FNG够用吗? 当你第一次尝试组装智能车底盘时,站在琳琅满目的电机、减速器和驱动器面前,很容易陷入选择困难。本文将带你避开新手常踩的坑,从实…...

Arduino与WS2812B打造智能节日彩灯:从硬件连接到编程实战
1. 项目概述:从零到一,点亮你的节日氛围又到年底了,各种节日接踵而至,无论是圣诞、元旦还是春节,家里总感觉少了点氛围感。买来的成品彩灯,要么模式单一,要么造型固定,总感觉差点意思…...

英雄联盟个性化改造神器:3分钟打造专属游戏身份
英雄联盟个性化改造神器:3分钟打造专属游戏身份 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 还在为千篇一律的英雄联盟个人资料感到乏味吗?想要在好友面前展示与众不同的游戏身份却苦于官方限制&…...

Android MediaCodec 编码实战:从 Camera 采集到 ByteBuffer 编码,生成 MP4 文件
1. Android Camera数据采集与YUV格式解析 在Android平台上使用Camera API采集视频数据是编码流程的第一步。我遇到过不少开发者在这一步就卡壳,主要问题集中在Camera2 API的复杂配置和YUV数据格式的理解上。这里分享几个实战经验: Camera2 API的基本工作…...

第7周学习总结:多工具Agent、RAG基础与环境搭建
多工具Agent、RAG基础与环境搭建 本周的学习重点围绕两个方向展开:一是完成了第七周的多工具协同与规划任务,并进入了第八周的流式思考链优化;二是正式启动了RAG(检索增强生成)的系统学习,搭建了知识库和环…...

Android 11 热点永不关闭的三种实现方案:从源码修改到API调用
Android 11热点持久化方案深度解析:从系统底层到应用层的完整实现 在移动设备开发领域,热点功能的稳定性与持久性一直是开发者关注的重点。Android 11系统默认的热点超时机制(10分钟无连接自动关闭)虽然考虑了节能因素,…...
)
【更新至2025年】2001-2025年上市公司年报文本数据(txt格式)
【更新至2025年】2001-2025年上市公司年报文本数据(txt格式) 1、时间:2001-2025年 2、来源:巨潮资讯网 3、范围:A股上市公司 4、样本量:共7.2W份 5、说明:上市公司年报文本数据可以挖掘文本…...

企业无线网络进阶:FreeRadius服务器配置与TLS证书实战
1. 为什么企业无线网络需要FreeRadius与TLS证书 想象一下你公司的Wi-Fi像是一个没有门禁的公共广场,任何人都能随意进出。这种情况对于企业网络来说简直是灾难——数据泄露、带宽被占、内网渗透风险接踵而至。而FreeRadiusTLS证书的方案,就相当于给这个广…...

别再手动算q值了!用Excel地理探测器软件包,5分钟搞定空间分异分析
别再手动算q值了!用Excel地理探测器软件包,5分钟搞定空间分异分析 地理空间数据分析中,识别变量间的分异特征和驱动因子一直是研究难点。传统方法依赖复杂公式推导和编程实现,让许多研究者望而却步。而地理探测器(Geod…...
 全解析|≤68kg 包装件部分模拟运输测试指南)
ISTA 2A-2011 (2022) 全解析|≤68kg 包装件部分模拟运输测试指南
前言ISTA 2A-2011 (2022) 属于 ISTA 2 系列部分模拟性能测试,专门面向 **≤68kg(150lb)的单个小型运输包装件 **,是电商小件、3C 数码、小家电、仪器仪表最常用的入门级包装验证标准。它结合基础测试与仿真要素,快速验…...