基于深度学习LightWeight的人体姿态之行为识别系统源码
一. LightWeight概述
light weight openpose是openpose的简化版本,使用了openpose的大体流程。
Light weight openpose和openpose的区别是:
a 前者使用的是Mobilenet V1(到conv5_5),后者使用的是Vgg19(前10层)。
b 前者部分层使用了空洞卷积(dilated convolution)来提升感受视野,后者使用一般的卷积。
c 前者卷积核大小为3*3,后者为7*7。
d 前者只有一个refine stage,后者有5个stage。
e 前者的initial stage和refine stage里面的两个分支(hotmaps和pafs)使用权值共享,后者则是并行的两个分支
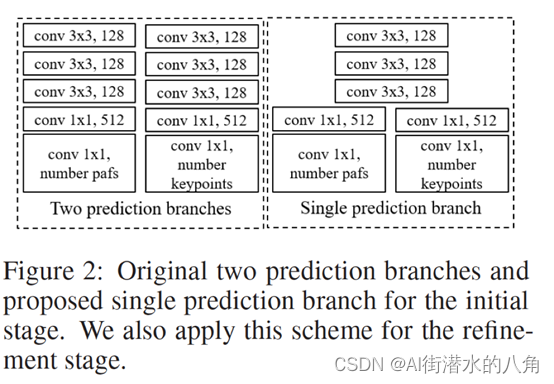
二. LightWeight的网络结构
openpose的每个stage使用下图中左侧的两个并行的分支,分别预测hotmaps和pafs,为了进一步降低计算量,light weight openpose中将前几层进行权值共享,如下图右侧所示。
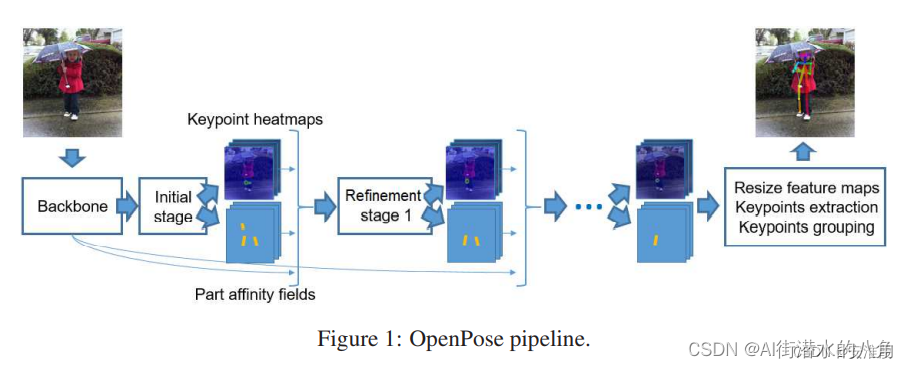
其网络流程:
三. LightWeight的网络结构代码
import torch
from torch import nnfrom modules.conv import conv, conv_dw, conv_dw_no_bnclass Cpm(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.align = conv(in_channels, out_channels, kernel_size=1, padding=0, bn=False)self.trunk = nn.Sequential(conv_dw_no_bn(out_channels, out_channels),conv_dw_no_bn(out_channels, out_channels),conv_dw_no_bn(out_channels, out_channels))self.conv = conv(out_channels, out_channels, bn=False)def forward(self, x):x = self.align(x)x = self.conv(x + self.trunk(x))return xclass InitialStage(nn.Module):def __init__(self, num_channels, num_heatmaps, num_pafs):super().__init__()self.trunk = nn.Sequential(conv(num_channels, num_channels, bn=False),conv(num_channels, num_channels, bn=False),conv(num_channels, num_channels, bn=False))self.heatmaps = nn.Sequential(conv(num_channels, 512, kernel_size=1, padding=0, bn=False),conv(512, num_heatmaps, kernel_size=1, padding=0, bn=False, relu=False))self.pafs = nn.Sequential(conv(num_channels, 512, kernel_size=1, padding=0, bn=False),conv(512, num_pafs, kernel_size=1, padding=0, bn=False, relu=False))def forward(self, x):trunk_features = self.trunk(x)heatmaps = self.heatmaps(trunk_features)pafs = self.pafs(trunk_features)return [heatmaps, pafs]class RefinementStageBlock(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.initial = conv(in_channels, out_channels, kernel_size=1, padding=0, bn=False)self.trunk = nn.Sequential(conv(out_channels, out_channels),conv(out_channels, out_channels, dilation=2, padding=2))def forward(self, x):initial_features = self.initial(x)trunk_features = self.trunk(initial_features)return initial_features + trunk_featuresclass RefinementStage(nn.Module):def __init__(self, in_channels, out_channels, num_heatmaps, num_pafs):super().__init__()self.trunk = nn.Sequential(RefinementStageBlock(in_channels, out_channels),RefinementStageBlock(out_channels, out_channels),RefinementStageBlock(out_channels, out_channels),RefinementStageBlock(out_channels, out_channels),RefinementStageBlock(out_channels, out_channels))self.heatmaps = nn.Sequential(conv(out_channels, out_channels, kernel_size=1, padding=0, bn=False),conv(out_channels, num_heatmaps, kernel_size=1, padding=0, bn=False, relu=False))self.pafs = nn.Sequential(conv(out_channels, out_channels, kernel_size=1, padding=0, bn=False),conv(out_channels, num_pafs, kernel_size=1, padding=0, bn=False, relu=False))def forward(self, x):trunk_features = self.trunk(x)heatmaps = self.heatmaps(trunk_features)pafs = self.pafs(trunk_features)return [heatmaps, pafs]class PoseEstimationWithMobileNet(nn.Module):def __init__(self, num_refinement_stages=1, num_channels=128, num_heatmaps=19, num_pafs=38):super().__init__()self.model = nn.Sequential(conv( 3, 32, stride=2, bias=False),conv_dw( 32, 64),conv_dw( 64, 128, stride=2),conv_dw(128, 128),conv_dw(128, 256, stride=2),conv_dw(256, 256),conv_dw(256, 512), # conv4_2conv_dw(512, 512, dilation=2, padding=2),conv_dw(512, 512),conv_dw(512, 512),conv_dw(512, 512),conv_dw(512, 512) # conv5_5)self.cpm = Cpm(512, num_channels)self.initial_stage = InitialStage(num_channels, num_heatmaps, num_pafs)self.refinement_stages = nn.ModuleList()for idx in range(num_refinement_stages):self.refinement_stages.append(RefinementStage(num_channels + num_heatmaps + num_pafs, num_channels,num_heatmaps, num_pafs))def forward(self, x):backbone_features = self.model(x)backbone_features = self.cpm(backbone_features)stages_output = self.initial_stage(backbone_features)for refinement_stage in self.refinement_stages:stages_output.extend(refinement_stage(torch.cat([backbone_features, stages_output[-2], stages_output[-1]], dim=1)))return stages_output
四. LightWeight是怎么去识别行为呢
LightWeight可以检测到人体的关键点,所以可以通过两种方式来判断行为,第一种方法是通过计算角度,第二种方式,是通过判断整体的关键点(把抠出的关键点图送入到分类网络),本文的做法是第一种方式
# 计算姿态
def get_pos(keypoints):str_pose = ""# 计算左臂与水平方向的夹角keypoints = np.array(keypoints)v1 = keypoints[1] - keypoints[0]v2 = keypoints[2] - keypoints[0]angle_left_arm = get_angle(v1, v2)#计算右臂与水平方向的夹角v1 = keypoints[0] - keypoints[1]v2 = keypoints[3] - keypoints[1]angle_right_arm = get_angle(v1, v2)if angle_left_arm>0 and angle_right_arm>0:str_pose = "LEFT_UP"elif angle_left_arm<0 and angle_right_arm<0:str_pose = "RIGHT_UP"elif angle_left_arm>0 and angle_right_arm<0:str_pose = "ALL_HANDS_UP"elif angle_left_arm>0 and angle_right_arm<0:str_pose = "NORMAL"return str_pose五. LightWeight的演示效果
视频演示地址:基于深度学习LightWeight的人体姿态之行为识别系统源码_哔哩哔哩_bilibili




六. 整个工程的内容
提供源代码,模型,提供GUI界面代码

代码的下载路径(新窗口打开链接):基于深度学习LightWeight的人体姿态之行为识别系统源码

有问题可以私信或者留言,有问必答
相关文章:
基于深度学习LightWeight的人体姿态之行为识别系统源码
一. LightWeight概述 light weight openpose是openpose的简化版本,使用了openpose的大体流程。 Light weight openpose和openpose的区别是: a 前者使用的是Mobilenet V1(到conv5_5),后者使用的是Vgg19(前10…...

Mac窗口辅助管理工具:Magnet for mac激活版
magnet mac版是一款运行在苹果电脑上的一款优秀的窗口大小控制工具,拖拽窗口到屏幕边缘可以自动半屏,全屏或者四分之一屏幕,还可以设定快捷键完成分屏。这款专业的窗口管理工具当您每次将内容从一个应用移动到另一应用时,当您需要…...
DWM 相关实现代码 [自用]
1. DWM 缩略图和模糊隐藏实现半透明 #include <windows.h> #include <dwmapi.h> #include <string> #pragma comment(lib, "dwmapi.lib")// 检查 UWP 窗口是否可见 bool IsUWPWindowVisible(HWND hwnd) {DWORD cloaked 0;DwmGetWindowAttribute(…...

根据样本数据的区域分布进行重采样
希望根据数据的区域分布进行重采样,通常用于处理空间数据或具有明显区域特征的数据。 文章目录 重采样整体思路数据集重采样步骤 区域划分的方法具体代码案例1. 基于规则的划分2. 基于密度的划分3. 基于层次的划分4. 基于图的划分5. 基于网格的划分6. 基于自组织映射…...

数据库之MQL
1,查询所有 mysql> select * from grade;2, mysql> select id,firstname,lastname from grade;3, mysql> select firstname,lastname from grade where id > 4;4, mysql> select * from grade where sex f;5&…...
LabVIEW平台从离散光子到连续光子的光子计数技术
光子计数技术用于将输入光子数转换为离散脉冲。常见的光子计数器假设光子是离散到达的,记录到来的每一个光子。但是,当两个或多个光子同时到达时,计数器会将其记录为单个脉冲,从而只计数一次。当连续光子到达时,离散光…...

【Linux】Windows平台使用gdb调试FFmpeg源码
FFmpeg是一个跨平台的多媒体库,有时需要在别的平台上进行开发和调试,记录一下在linux环境下使用gdb来调试FFmpeg源码的基本方式 1.可执行文件 在windows平台使用linux环境来调试FFmpeg源码,需要编译生成一个后缀有_g的exe文件,参…...

提交表单form之后发送表单内容到指定邮箱(单php文件实现)
提交各种表单之后,自动将表单的内容通过邮件api接口的形式自动发送到指定的邮箱。步骤如下: 1.在aoksend注册一个账号。 2.绑定一个自己的域名。做域名解析之后验证。验证通过后自动提交审核。等待审核通过。 3.设置一个邮件模板。aoksend内置了一些优…...

【设计模式之美】策略模式方法论:解耦策略的定义、创建和使用
文章目录 一. 策略的定义-封装策略,面向接口二. 策略的创建-创建策略工厂1. 对于无状态策略2. 对于有状态策略 三. 策略的使用:动态选择四. 避免分支判断-策略的优雅1. 对于无状态的策略2. 对于有状态的策略 策略模式是定义一族算法类,将每个…...

解析 pdfminer pdfparser.py
解析 pdfminer pdfparser.py 1. 导入必要的模块2. 定义PDFParser类2.1 初始化方法2.2 设置文档方法2.3 处理关键词方法举例说明: 3. 定义PDFStreamParser类3.1 初始化方法3.2 刷新方法3.3 处理关键词方法 总结 今天我们来看一段Python代码,这段代码实现了一个PDF文件的解析器。…...

day10:03 一文搞懂encode和encoding的区别
在Python中,处理字符串时经常会遇到encode()方法和encoding参数,它们都与字符串的编码和解码有关,但用途和上下文有所不同。下面通过案例来解释它们的关系和区别。 1. encode() 方法 encode()方法是字符串(str)类型的…...

【wordpress教程】wordpress博客网站添加非法关键词拦截
有的网站经常被恶意搜索,站长们不胜其烦。那我们如何屏蔽恶意搜索关键词呢?下面就随小编一起来解决这个问题吧。 后台设置预览图: 设置教程: 1、把以下代码添加至当前主题的 functions.php 文件中: add_action(admi…...

untiy 在菜单栏添加自定义按钮 点击按钮弹出一个Unity窗口,并在窗口里添加属性
using System.Collections.Generic; using UnityEditor; using UnityEngine; using UnityEngine.Rendering.PostProcessing;public class AutoGenerateWindow : EditorWindow //这是定义一个窗口 {public string subjecttName "科目名字";//科目的名字public GameOb…...

VIM模式之间的切换
命令行界面下,常用的文本编辑器是 VI / VIM(VI增强版),VI 是 Linux 最通用的文本编辑器,VIM相较于VI,提供了代码高亮等功能,两者用法完全兼容; 1. 进入 VIM 工作界面 vim 文件名 2. 进入编辑模式 三种方…...

Linux操作系统安全分析与防护
Linux操作系统安全机制 Linux操作系统由于其开放源代码和广泛应用,在服务器和嵌入式系统中占有重要地位。为了确保Linux系统的安全,必须了解并实施一系列有效的安全机制。这些机制包括用户身份验证、访问控制、数据加密、日志和审计、安全更新等。 一、…...

【LeetCode】面试题 16.21. 交换和
质量还不错的一道题,适合用于考察二分法。 1. 题目 2. 分析 求出两个数组的总和,我们令总和少的为less,总和多的为more;如果两个数组的总和是奇数,那么怎么都配不平,直接返回false;如果两个数…...
Web知识库应用程序LibreKB
什么是 LibreKB ? LibreKB 是一款知识库 Web 应用程序。免费、开源、自托管,基于 PHP/MySQL。 官方并没有 Docker 镜像,老苏这次图省事,并没有像往常一样构建一个镜像,而是基于 Docker 搭建了一个 LAMP 环境࿰…...

神经网络和安全结合:一种基于神经网络的智能攻击检测与防御系统;构建攻击行为预测模型
目录 神经网络和安全结合 摘要 引言 理论基础 技术实现与创新点 实验验证 结论与展望 一种基于神经网络的智能攻击检测与防御系统 一、系统概述 二、主要功能 三、技术特点 四、应用前景 构建攻击行为预测模型 一、构建攻击行为预测模型的步骤 1. 数据收集 2. …...
得到文件中的H264数据和AAC数据(纯手工,不依赖第三方开源库))
音视频解封装demo:将FLV文件解封装(demux)得到文件中的H264数据和AAC数据(纯手工,不依赖第三方开源库)
1、README 前言 注意:flv是不支持h.265封装的。目前解封装功能正常,所得到的H.264文件与AAC文件均可正常播放。 a. demo使用 $ make clean && make DEBUG1 $ $ $ ./flv_demux_h264_aac Usage: ./flv_demux_h264_aac avfile/test1.flv./flv_d…...

51单片机(STC8051U34K64)_RA8889_SPI4参考代码(v1.3)
硬件:STC8051U34K64 RA8889开发板(硬件跳线变更为SPI-4模式,PS101,R143,R141短接,R142不接) STC8051U34K64是STC最新推出来的单片机,主要用于替换传统的8051单片机,与标…...

Rdkit实战:从2D到3D,解锁分子构象生成与优化的全流程
1. 从2D到3D:分子构象生成的基础概念 第一次接触分子构象生成时,我完全被各种术语搞晕了——距离几何、ETKDG、MMFF这些名词听起来就像天书。直到用RDKit实际操作了几次,才发现这个过程其实就像搭积木:先有个平面设计图ÿ…...

别再只用DS18B20了!用51单片机和ADC0804做个PT100温度计,从硬件接线到代码调试全流程
从DS18B20到PT100:用51单片机打造工业级温度监测系统 在嵌入式开发领域,温度测量是一个永恒的话题。当大多数初学者还停留在使用DS18B20这类数字温度传感器时,工业领域早已广泛采用PT100铂电阻作为温度测量的主力军。本文将带你跨越数字传感器…...
)
Jupyter Notebook 云GPU配置全解析(含实操+选型指南)
一、前言:为什么需要Jupyter Notebook云GPU配置?Jupyter Notebook作为交互式编程工具,广泛应用于AI训练、数据建模、算法调试等场景,其“代码文本”一体化特性,大幅提升开发效率。但本地环境存在明显局限:普…...
内存数据解码实战指南)
嵌入式追踪路由器(ETR)内存数据解码实战指南
1. 嵌入式追踪路由器(ETR)内存数据解码实战指南在嵌入式系统调试中,获取处理器执行踪迹(trace)是诊断复杂问题的关键手段。CoreSight SoC-600架构中的Trace Memory Controller(TMC)通过Embedded Trace Router(ETR)组件,可以将ATB(Advanced Trace Bus)追踪…...

微软:小模型替代大模型执行终端任务
📖标题:Terminus-4B: Can a Smaller Model Replace Frontier LLMs at Agentic Execution Tasks? 🌐来源:arXiv, 2605.03195v1 🛎️文章简介 🔸研究问题:在代码智能体的终端执行子任务中&#x…...

告别内存焦虑!手把手教你读懂中科蓝讯AB530X的ram.ld文件,精准控制RAM复用
告别内存焦虑!手把手教你读懂中科蓝讯AB530X的ram.ld文件,精准控制RAM复用 第一次打开中科蓝讯AB530X的ram.ld文件时,那些密密麻麻的符号和数字让我头皮发麻。作为一款主打性价比的蓝牙芯片,AB530X的RAM资源相当有限——就像在寸土…...

JLink V9.5 固件资源包
JLink V9.5 固件资源包 【下载地址】JLinkV9.5固件资源包 JLink V9.5 固件资源包欢迎使用JLink V9.5全套固件资源 项目地址: https://gitcode.com/open-source-toolkit/4bb56 欢迎使用JLink V9.5全套固件资源。本资源包专为那些需要对JLink调试器进行固件升级和自定义配…...

【免费下载】 Airplayer:苹果设备投屏的终极解决方案
Airplayer:苹果设备投屏的终极解决方案 【下载地址】Airplayer苹果投屏软件 Airplayer是一款专为苹果设备设计的高效投屏软件,它允许用户轻松地将iPhone或iPad屏幕的内容无线传输到电脑上显示。无论是播放视频、展示照片、进行会议演示还是游戏分享&…...

ESJsonFormat-Xcode与MJExtension完美结合:构建高效iOS数据模型
ESJsonFormat-Xcode与MJExtension完美结合:构建高效iOS数据模型 【免费下载链接】ESJsonFormat-Xcode 将JSON格式化输出为模型的属性 项目地址: https://gitcode.com/gh_mirrors/es/ESJsonFormat-Xcode ESJsonFormat-Xcode是一款专为iOS开发者打造的JSON转模…...

如何通过Magisk实现Android系统无痕定制:开发者的终极实战指南
如何通过Magisk实现Android系统无痕定制:开发者的终极实战指南 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为一款革命性的Android系统定制框架,以其独特的"无系…...