【Hive SQL 每日一题】在线峰值人数计算
文章目录
- 测试数据
- 需求说明
- 需求实现
测试数据
-- 创建 user_activity 表
DROP TABLE IF EXISTS user_activity ;
CREATE TABLE user_activity (user_id STRING,activity_start TIMESTAMP,activity_end TIMESTAMP
);-- 插入数据
INSERT INTO user_activity VALUES
('user1', '2024-07-11 08:00:00', '2024-07-11 09:00:00'),
('user2', '2024-07-11 08:30:00', '2024-07-11 09:30:00'),
('user3', '2024-07-11 09:00:00', '2024-07-11 10:00:00'),
('user4', '2024-07-11 09:15:00', '2024-07-11 09:45:00'),
('user5', '2024-07-11 09:30:00', '2024-07-11 10:30:00'),
('user6', '2024-07-11 10:00:00', '2024-07-11 11:00:00'),
('user7', '2024-07-11 08:05:00', '2024-07-11 08:55:00'),
('user8', '2024-07-11 08:45:00', '2024-07-11 09:15:00'),
('user9', '2024-07-11 09:05:00', '2024-07-11 10:05:00'),
('user10', '2024-07-11 09:25:00', '2024-07-11 10:25:00'),
('user11', '2024-07-11 08:10:00', '2024-07-11 09:10:00'),
('user12', '2024-07-11 08:20:00', '2024-07-11 09:20:00'),
('user13', '2024-07-11 08:35:00', '2024-07-11 09:35:00'),
('user14', '2024-07-11 08:50:00', '2024-07-11 09:50:00'),
('user15', '2024-07-11 09:10:00', '2024-07-11 10:10:00'),
('user16', '2024-07-11 09:20:00', '2024-07-11 10:20:00'),
('user17', '2024-07-11 09:40:00', '2024-07-11 10:40:00'),
('user18', '2024-07-11 10:05:00', '2024-07-11 11:05:00'),
('user19', '2024-07-11 10:15:00', '2024-07-11 11:15:00'),
('user20', '2024-07-11 10:25:00', '2024-07-11 11:25:00');
需求说明
计算某系统每个时间点的在线峰值人数。
结果示例:
| activity_time | max_users |
|---|---|
| 2024-07-11 08 | 8 |
| 2024-07-11 09 | 9 |
| … | … |
结果按 activity_time 升序排列。
其中:
activity_time表示统计的时间点;max_users表示该时间点内的最高峰值人数。
需求实现
selectdate_format(activity_time,'yyyy-MM-dd HH') activity_time,max(total_users) max_users
from(selectactivity_time,sum(flag) over(order by activity_time) total_usersfrom(selectactivity_start activity_time,1 flagfromuser_activityunion allselectactivity_end activity_time,-1 flagfromuser_activity)t1)t2
group bydate_format(activity_time,'yyyy-MM-dd HH');
输出结果如下:

本题最核心的地方在于子查询 t2 中的逻辑:
selectactivity_time,sum(flag) over(order by activity_time) total_usersfrom(selectactivity_start activity_time,1 flagfromuser_activityunion allselectactivity_end activity_time,-1 flagfromuser_activity)t1;
首先,我们在子查询 t1 中将列转为了行,那为什么需要这样做呢?当然是为了方便统计。
我们来想想,当一个用户登录后进入系统,那么人数是不是会 +1,反之当用户退出时,人数是不是会 -1。
当我们把登录和退出时间都放在同一列时,按照时间排序,是不是就可以精准算出每个时刻在线的人数了,这就是子查询 t2 做的事情,通过窗口函数进行累加计算,t2 结果如下所示:
2024-07-11 08:00:00 1
2024-07-11 08:05:00 2
2024-07-11 08:10:00 3
2024-07-11 08:20:00 4
2024-07-11 08:30:00 5
2024-07-11 08:35:00 6
2024-07-11 08:45:00 7
2024-07-11 08:50:00 8
2024-07-11 08:55:00 7
2024-07-11 09:00:00 7
2024-07-11 09:00:00 7
2024-07-11 09:05:00 8
2024-07-11 09:10:00 8
2024-07-11 09:10:00 8
2024-07-11 09:15:00 8
2024-07-11 09:15:00 8
2024-07-11 09:20:00 8
2024-07-11 09:20:00 8
2024-07-11 09:25:00 9
2024-07-11 09:30:00 9
2024-07-11 09:30:00 9
2024-07-11 09:35:00 8
2024-07-11 09:40:00 9
2024-07-11 09:45:00 8
2024-07-11 09:50:00 7
2024-07-11 10:00:00 7
2024-07-11 10:00:00 7
2024-07-11 10:05:00 7
2024-07-11 10:05:00 7
2024-07-11 10:10:00 6
2024-07-11 10:15:00 7
2024-07-11 10:20:00 6
2024-07-11 10:25:00 6
2024-07-11 10:25:00 6
2024-07-11 10:30:00 5
2024-07-11 10:40:00 4
2024-07-11 11:00:00 3
2024-07-11 11:05:00 2
2024-07-11 11:15:00 1
2024-07-11 11:25:00 0
最终按时间点分组聚合,通过 max 函数找出各个时间点内最大的峰值人数,完成~
相关文章:
【Hive SQL 每日一题】在线峰值人数计算
文章目录 测试数据需求说明需求实现 测试数据 -- 创建 user_activity 表 DROP TABLE IF EXISTS user_activity ; CREATE TABLE user_activity (user_id STRING,activity_start TIMESTAMP,activity_end TIMESTAMP );-- 插入数据 INSERT INTO user_activity VALUES (user1, 2024…...

谷粒商城学习笔记-18-快速开发-配置测试微服务基本CRUD功能
文章目录 一,product模块整合mybatis-plus1,引入依赖2,product启动类指定mapper所在包3,在配置文件配置数据库连接信息4,在配置文件中配置mapper.xml映射文件信息 二,单元测试1,编写测试代码&am…...

机器学习库实战:DL4J与Weka在Java中的应用
机器学习是当今技术领域的热门话题,而Java作为一门广泛使用的编程语言,也有许多强大的机器学习库可供选择。本文将深入探讨两个流行的Java机器学习库:Deeplearning4j(DL4J)和Weka,并通过详细的代码示例帮助…...

MongoDB教程(一):Linux系统安装mongoDB详细教程
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 文章目录 引言一、Ubuntu…...

leetcode74. 搜索二维矩阵
给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。…...

Redis 布隆过滤器性能对比分析
redis 实现布隆过滤器实现方法: 1、redis 的 setbit 和 getbit 特点:对于某个bit 设置0或1,对于大量的值需要存储,非常节省空间,查询速度极快,但是不能查询整个key所有的bit,在一次请求有大量…...

Java List不同实现类的对比
List不同实现类的对比 文章目录 List不同实现类的对比实现类之一ArrayList实现类之二 LinkedList实现类之三 Vector练习 java.util.Collection用于存储一个一个数据的框架子接口:List存储有序的、可重复的数据(相当于动态数组) ArrayList lis…...

【C语言】 —— 预处理详解(下)
【C语言】 —— 预处理详解(下) 前言七、# 和 \##7.1 # 运算符7.2 ## 运算符 八、命名约定九、# u n d e f undef undef十、命令行定义十一、条件编译11.1、单分支的条件编译11.2、多分支的条件编译11.3、判断是否被定义11.4、嵌套指令 十二、头文件的包…...

Jupyter Notebook简介
Jupyter Notebook是一个开源的Web应用程序,允许你创建和共享包含实时代码、方程、可视化和解释性文本的文档。它广泛用于数据清理和转换、数值模拟、统计建模、机器学习等领域。 Jupyter Notebook的优势包括: 1. **交互式计算**:可以在网页…...

ChatGPT 5.0:一年后的猜想
对于ChatGPT 5.0在未来一年半后的展望与看法,我们可以从以下几个方面进行详细探讨: 一、技术提升与功能拓展 语言翻译能力: ChatGPT 5.0在语言翻译方面有望实现更大突破。据推测,新版本将利用更先进的自然语言处理技术和深度学习…...
Java套红:指定位置合并文档-NiceXWPFDocument
需求:做个公文系统,需要将正文文档在某个节点点击套红按钮,实现文档套红 试了很多方法,大多数网上能查到但是实际代码不能找到关键方法,可能是跟包的版本有关系,下面记录能用的这个。 一:添加依…...

【操作系统】进程管理——进程的同步与互斥(个人笔记)
学习日期:2024.7.8 内容摘要:进程同步/互斥的概念和意义,基于软/硬件的实现方法 进程同步与互斥的概念和意义 为什么要有进程同步机制? 回顾:在《进程管理》第一章中,我们学习了进程具有异步性的特征&am…...

Qt:13.多元素控件(QLinstWidget-用于显示项目列表的窗口部件、QTableWidget- 用于显示二维数据表)
目录 一、QLinstWidget-用于显示项目列表的窗口部件: 1.1QLinstWidget介绍: 1.2属性介绍: 1.3常用方法介绍: 1.4信号介绍: 1.5实例演示: 二、QTableWidget- 用于显示二维数据表: 2.1QTabl…...

恢复出厂设置手机变成砖
上周,许多Google Pixel 6(6、6a、6 Pro)手机用户在恢复出厂设置后都面临着设备冻结的问题。 用户说他们在下载过程中遇到了丢失 tune2fs 文件的错误 。 这会导致屏幕显示以下消息:“Android 系统无法启动。您的数据可能会被损坏…...

解决IntelliJ IDEA中克隆GitHub项目不显示目录结构的问题
前言 当您从GitHub等代码托管平台克隆项目到IntelliJ IDEA,却遇到项目目录结构未能正确加载的情况时,不必太过困扰,本文将为您提供一系列解决方案,帮助您快速找回丢失的目录视图。 1. 调整Project View设置 操作步骤࿱…...

Git错误分析
错误案例1: 原因:TortoiseGit多次安装导致,会记录首次安装路径,若安装路径改变,需要配置最后安装的路径。...

pom.xml中重要标签介绍
在 Maven 项目中,pom.xml 文件是项目对象模型(POM)的配置文件,它定义了项目的依赖关系、插件、构建配置等。以下是 pom.xml 文件中一些重要的标签及其作用: <modelVersion>: 定义 POM 模型的版本。当…...

大模型日报 2024-07-11
大模型日报 2024-07-11 大模型资讯 CVPR世界第二仅次Nature!谷歌2024学术指标出炉,NeurIPS、ICLR跻身前十 谷歌2024学术指标公布,CVPR位居第二,超越Science仅次于Nature。CVPR、NeurIPS、ICLR三大顶会跻身TOP 10。 CVPR成全球第二…...
Redis基础教程(十六):Redis Stream
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 💝Ὁ…...
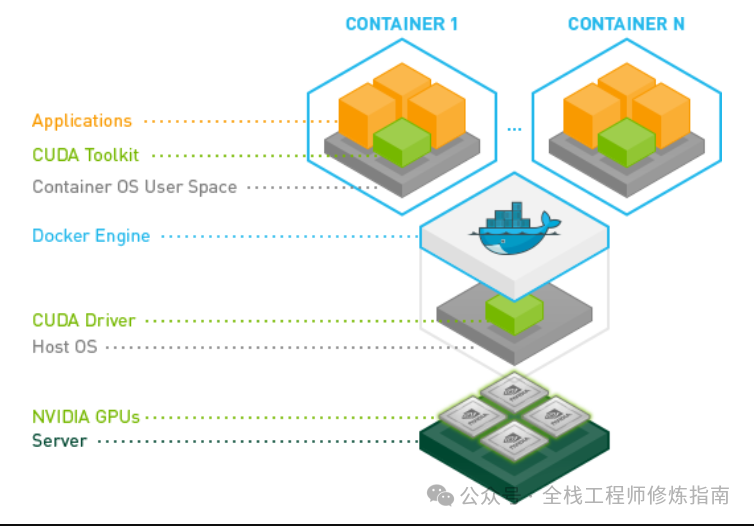
机器学习筑基篇,容器调用显卡计算资源,Ubuntu 24.04 快速安装 NVIDIA Container Toolkit!...
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] Ubuntu 24.04 安装 NVIDIA Container Toolkit 什么是 NVIDIA Container Toolkit? 描述:NVIDIA Container Toolkit(容器工具包)使用户能够构建和运行 GPU 加速的容器,该工具包括一个容器运行时库和实用程序,用于自动…...

大空间中庭水平防火卷帘防火分隔技术应用探讨
摘要大空间中庭广泛应用于商业综合体、大型会展中心、高端写字楼等现代公共建筑,具备通透开阔、流线连贯、美观性强的空间优势,但多层贯通的结构特性极易造成火灾烟气快速扩散、火势纵向蔓延,大幅提升建筑消防防控难度。水平防火卷帘作为柔性…...

开发上下文管理工具:原理、实现与工程实践
1. 项目概述:一个为开发者量身定制的上下文管理工具如果你和我一样,每天要在多个项目、多种技术栈、甚至多个开发环境之间反复横跳,那你一定对“上下文切换”这个词深恶痛绝。我说的不是操作系统的上下文切换,而是我们开发者大脑里…...

apk 包管理器完全指南:Alpine Linux 的轻量级利器
一、apk 体系架构全景 apk(Alpine Package Keeper)是 Alpine Linux 的核心包管理工具,与 Debian 的 APT 相比,它遵循极简主义设计哲学:代码量少、依赖解析简单、资源占用极低。这使得 Alpine 成为 Docker 容器的默认基…...

开源自动化工具用例集:从网页监控到GUI自动化的实践指南
1. 项目概述:一个中文开源“利爪”用例集最近在整理一些自动化脚本和工具链时,我一直在思考一个问题:一个真正好用的、能解决实际问题的自动化工具,它的价值边界到底在哪里?是仅仅完成一个预设的、简单的任务ÿ…...

矩阵键盘原理与实战:从扫描算法到Arduino/CircuitPython驱动指南
1. 项目概述:为什么我们需要矩阵键盘? 在嵌入式项目里,给设备加几个按钮是再常见不过的需求。但如果你需要10个、12个甚至16个独立的按键呢?按照传统思路,一个按键对应一个微控制器的数字输入引脚,那你的Ar…...

基于PyPortal与AirNow API的物联网空气质量监测显示系统实战
1. 项目概述与核心价值如果你对物联网开发感兴趣,或者一直想做一个能摆在桌面上、实时显示环境数据的“小玩意儿”,那么这个基于PyPortal和AirNow API的空气质量监测显示系统,绝对是一个能让你从零到一跑通整个物联网数据流、并且最终获得一个…...

终极指南:如何让Figma说中文,快速提升设计效率
终极指南:如何让Figma说中文,快速提升设计效率 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN FigmaCN是一款专为中文用户设计的Figma中文界面插件,通…...

在Windows上安装APK的终极指南:5步掌握APK Installer工具
在Windows上安装APK的终极指南:5步掌握APK Installer工具 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直接安装Android应用…...

基于Python的自动化科研写作工具:Aut_Sci_Write架构与实现
1. 项目概述:一个面向科研写作的自动化工具最近在GitHub上看到一个挺有意思的项目,叫“Aut_Sci_Write”。光看名字,大概就能猜到它的核心方向:自动化科学写作。作为一个在科研和工程领域摸爬滚打多年的从业者,我深知一…...

3个简单步骤彻底解决GitHub下载龟速问题:Fast-GitHub插件完全指南
3个简单步骤彻底解决GitHub下载龟速问题:Fast-GitHub插件完全指南 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是…...