YOLOv10改进 | 添加注意力机制篇 | 添加LSKAttention大核注意力机制助力极限涨点
一、本文介绍
在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于YOLOv10,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到YOLOv10的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文还将提供代码实现细节和使用方法,展示这种改进对目标检测、语义分割等方面的积极影响。通过实验YOLOv10在整合LSKAttention机制后,实现了检测精度提升(下面会附上改进LSKAttention机制和基础版本的结果对比图)。
专栏回顾:YOLOv10改进系列专栏——本专栏持续复习各种顶会内容——科研必备
目录
一、本文介绍
二、LSKAttention的机制原理
三、LSKAttention的代码
四、手把手教你将LSKAttention添加到你的网络结构中
4.1 LSKAttention的添加教程
4.2 LSKAttention的yaml文件和训练截图
4.2.1 LSKAttention的yaml文件
4.2.2 LSKAttention的训练过程截图
五、LSKAttention可添加的位置
5.1 推荐LSKAttention可添加的位置
5.2图示LSKAttention可添加的位置
六、本文总结
二、LSKAttention的机制原理

论文地址:官方论文地址
代码地址:官方代码地址

《Large Separable Kernel Attention》这篇论文提出的LSKAttention的机制原理是针对传统大核注意力(Large Kernel Attention,LKA)模块在视觉注意网络(Visual Attention Networks,VAN)中的应用问题进行的改进。LKA模块在处理大尺寸卷积核时面临着高计算和内存需求的挑战。LSKAttention通过以下几个关键步骤和原理来解决这些问题:
-
核分解:LSKAttention的核心创新是将传统的2D卷积核分解为两个1D卷积核。首先,它将一个大的2D核分解成水平(横向)和垂直(纵向)的两个1D核。这样的分解大幅降低了参数数量和计算复杂度。
-
串联卷积操作:在进行卷积操作时,LSKAttention首先使用一个1D核对输入进行水平方向上的卷积,然后使用另一个1D核进行垂直方向上的卷积。这两步卷积操作串联执行,从而实现了与原始大尺寸2D核相似的效果。
-
计算效率提升:由于分解后的1D卷积核大大减少了参数的数量,LSKAttention在执行时的计算效率得到显著提升。这种方法特别适用于处理大尺寸的卷积核,能够有效降低内存占用和计算成本。
-
保持效果:虽然采用了分解和串联的策略,LSKAttention仍然能够保持类似于原始LKA的性能。这意味着在处理图像的关键特征(如边缘、纹理和形状)时,LSKAttention能够有效地捕捉到重要信息。
-
适用于多种任务:LSKAttention不仅在图像分类任务中表现出色,还能够在目标检测、语义分割等多种计算机视觉任务中有效应用,显示出其广泛的适用性。
总结:LSKAttention通过创新的核分解和串联卷积策略,在降低计算和内存成本的同时,保持了高效的图像处理能力,这在处理大尺寸核和复杂图像数据时特别有价值。
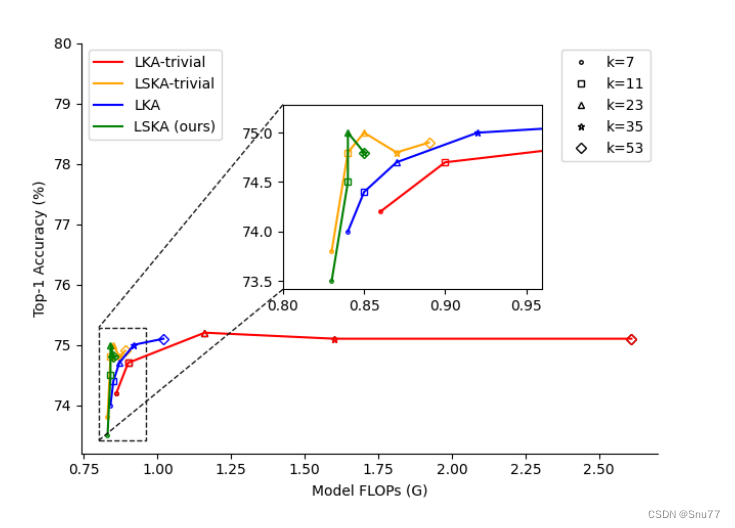
上图展示了在不同大核分解方法和核大小下的速度-精度权衡。在这个比较中,使用了不同的标记来代表不同的核大小,并且以VAN-Tiny作为对比的模型。从图中可以看出,LKA的朴素设计(LKA-trivial)以及在VAN中的实际设计,在核大小增加时会导致更高的GFLOPs(十亿浮点运算次数)。相比之下,论文提出的LSKA(Large Separable Kernel Attention)-trivial和VAN中的LSKA在核大小增加时显著降低了GFLOPs,同时没有降低性能

上图展示了大核注意力模块不同设计的比较,具体包括:
- LKA-trivial:朴素的2D大核深度卷积(DW-Conv)与1×1卷积结合(图a)。
- LSKA-trivial:串联的水平和垂直1D大核深度卷积与1×1卷积结合(图b)。
- 原始LKA设计:在VAN中包括标准深度卷积(DW-Conv)、扩张深度卷积(DW-D-Conv)和1×1卷积(图c)。
- 提出的LSKA设计:将LKA的前两层分解为四层,每层由两个1D卷积层组成(图d)。其中,N代表Hadamard乘积,k代表最大感受野,d代表扩张率。
个人总结:提出了一种创新的大型可分离核注意力(LSKA)模块,用于改进卷积神经网络(CNN)。这种模块通过将2D卷积核分解为串联的1D核,有效降低了计算复杂度和内存需求。LSKA模块在保持与标准大核注意力(LKA)模块相当的性能的同时,显示出更高的计算效率和更小的内存占用。
三、LSKAttention的代码
将下面的代码在"ultralytics/nn/modules" 目录下创建一个py文件复制粘贴进去然后按照章节四进行添加即可(需要按照有参数的注意力机制添加)。
import torch
import torch.nn as nnclass LSKA(nn.Module):def __init__(self, dim, k_size):super().__init__()self.k_size = k_sizeif k_size == 7:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,2), groups=dim, dilation=2)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=(2,0), groups=dim, dilation=2)elif k_size == 11:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,4), groups=dim, dilation=2)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=(4,0), groups=dim, dilation=2)elif k_size == 23:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 7), stride=(1,1), padding=(0,9), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(7, 1), stride=(1,1), padding=(9,0), groups=dim, dilation=3)elif k_size == 35:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 11), stride=(1,1), padding=(0,15), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(11, 1), stride=(1,1), padding=(15,0), groups=dim, dilation=3)elif k_size == 41:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 13), stride=(1,1), padding=(0,18), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(13, 1), stride=(1,1), padding=(18,0), groups=dim, dilation=3)elif k_size == 53:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 17), stride=(1,1), padding=(0,24), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(17, 1), stride=(1,1), padding=(24,0), groups=dim, dilation=3)self.conv1 = nn.Conv2d(dim, dim, 1)def forward(self, x):u = x.clone()attn = self.conv0h(x)attn = self.conv0v(attn)attn = self.conv_spatial_h(attn)attn = self.conv_spatial_v(attn)attn = self.conv1(attn)return u * attn
四、手把手教你将LSKAttention添加到你的网络结构中
4.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。

4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
4.4 修改四
按照我的添加在parse_model里添加即可。

到此就修改完成了,大家可以复制下面的yaml文件运行。
五、LSKA的yaml文件和运行记录
5.1 LSKA的yaml文件1
此版本训练信息:YOLOv10n-LSKA summary: 403 layers, 2810422 parameters, 2810406 gradients, 8.6 GFLOPs
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov10n.yaml' will call yolov10.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSA, [1024]] # 10# YOLOv10.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, LSKA, []] # 17 (P3/8-small) 小目标检测层输出位置增加注意力机制- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 20 (P4/16-medium)- [-1, 1, LSKA, []] # 21 (P4/16-medium) 中目标检测层输出位置增加注意力机制- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2fCIB, [1024, True, True]] # 24 (P5/32-large)- [-1, 1, LSKA, []] # 25 (P5/32-large) 大目标检测层输出位置增加注意力机制# 如果你自己配置注意力位置注意from[17, 21, 25]位置要对应上对应的检测层!- [[17, 21, 25], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
5.2 PSALSKA的yaml文件2
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov10n.yaml' will call yolov10.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSALSKA, [1024]] # 10# YOLOv10.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
5.2 训练代码
大家可以创建一个py文件将我给的代码复制粘贴进去,配置好自己的文件路径即可运行。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('ultralytics/cfg/models/v8/yolov8-C2f-FasterBlock.yaml')# model.load('yolov8n.pt') # loading pretrain weightsmodel.train(data=r'替换数据集yaml文件地址',# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, posecache=False,imgsz=640,epochs=150,single_cls=False, # 是否是单类别检测batch=4,close_mosaic=10,workers=0,device='0',optimizer='SGD', # using SGD# resume='', # 如过想续训就设置last.pt的地址amp=False, # 如果出现训练损失为Nan可以关闭ampproject='runs/train',name='exp',)5.3 GhostModule的训练过程截图
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:
相关文章:
YOLOv10改进 | 添加注意力机制篇 | 添加LSKAttention大核注意力机制助力极限涨点
一、本文介绍 在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于YOLOv10,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核࿰…...

学习笔记——动态路由——IS-IS中间系统到中间系统(特性之路由撤销)
6、路由撤销 ISIS路由协议的路由信息是封装在LSP报文中的TLV中的,但是它对撤销路由的处理和OSPF的处理方式类似。 在ISIS中撤销一条路由实则是将接口下的ISIS关闭: 撤销内部路由: 在ISIS中路由信息是由IP接口TLV和IP内部可达性TLV共同来描…...
)
智能无人机控制:STM32微控制器与机器学习集成(内附资料)
智能无人机控制结合了STM32微控制器的实时处理能力和机器学习算法的决策能力,以实现更高级的自主飞行和任务执行。以下是智能无人机控制系统的概述,包括系统架构、关键组件、集成方法和示例代码。 系统概述 智能无人机控制系统利用STM32微控制器进行实…...

力扣 454四数相加
这个题给了四个数组,可以两两判断,就类比两数相加那道题了 对于num1 num2 用unordered_map存储,key是num1,num2中数字相加之和,value是值出现的次数 for(int a:num1) {for(int b:num2 {map[ab]; 最后要计算四个数…...

Java面试题系列 - 第9天
题目:深入探讨Java中的设计模式及其应用场景 背景说明:设计模式是软件工程中解决问题的常见方案,它们提供了经过验证的模板,帮助开发者解决在软件设计过程中遇到的特定问题。在Java中,熟悉并正确应用设计模式能够显著…...

数据结构【顺序表】
目录 线性表 顺序表 概念与结构 分类 静态顺序表 动态顺序表 动态顺序表的实现 在头文件中创建结构体 初始化顺序表 销毁顺序表(可以留到后面再看) 尾插数据 申请空间 打印顺序表数据 头插数据 尾删除数据 头删除数据 在指定位置插…...

【JavaScript 报错】未捕获的类型错误:Uncaught TypeError
🔥 个人主页:空白诗 文章目录 一、错误原因分析1. 调用不存在的方法2. 访问未定义的属性3. 数据类型不匹配4. 函数参数类型不匹配 二、解决方案1. 检查方法和属性是否存在2. 使用可选链操作符3. 数据类型验证4. 函数参数类型检查 三、实例讲解四、总结 在…...
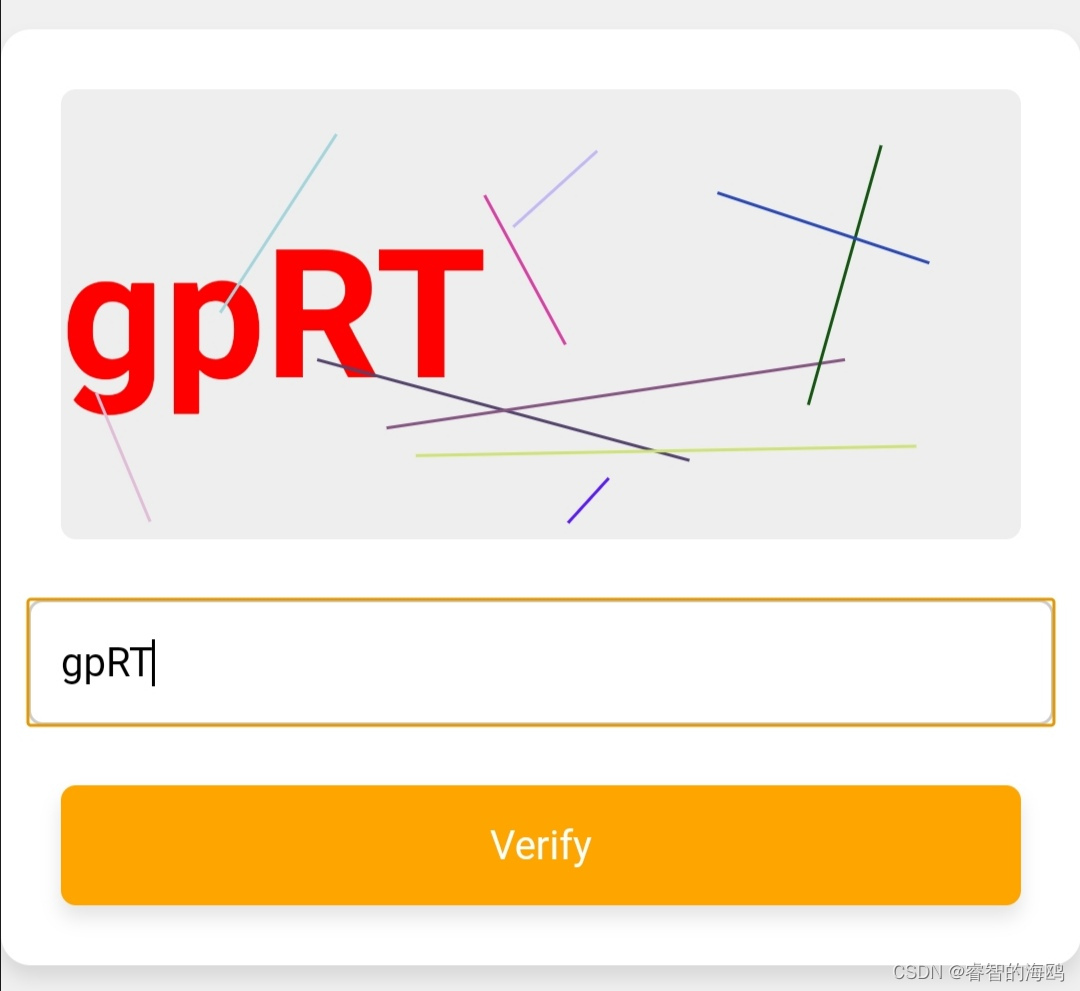
html+css+js随机验证码
随机画入字符、线条 源代码在图片后面 点赞❤️关注😍收藏⭐️ 互粉必回 图示 源代码 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport" content"…...

WPS打开PDF文件的目录
WPS打开PDF文件的目录 其实WPS中PDF文件并没有像Word那样标准的目录,但是倒是有书签,和目录一个效果 点击左上角书签选项,或者使用Alt Shift 1快捷键即可...

常见 Web漏洞分析与防范研究
前言: 在当今数字化时代,Web应用程序扮演着重要的角色,为我们提供了各种在线服务和功能。然而,这些应用程序往往面临着各种潜在的安全威胁,这些威胁可能会导致敏感信息泄露、系统瘫痪以及其他不良后果。 SQL注入漏洞 …...

暗黑魅力:Xcode全面拥抱应用暗黑模式开发指南
暗黑魅力:Xcode全面拥抱应用暗黑模式开发指南 随着苹果在iOS 13和iPadOS 13中引入暗黑模式,用户可以根据自己的喜好或环境光线选择不同的界面主题。作为开发者,支持暗黑模式不仅能提升用户体验,还能彰显应用的专业性。Xcode提供了…...

【游戏引擎之路】登神长阶(七)——x86汇编学习:凡做难事,必有所得
5月20日-6月4日:攻克2D物理引擎。 6月4日-6月13日:攻克《3D数学基础》。 6月13日-6月20日:攻克《3D图形教程》。 6月21日-6月22日:攻克《Raycasting游戏教程》。 6月23日-7月1日:攻克《Windows游戏编程大师技巧》。 7月…...
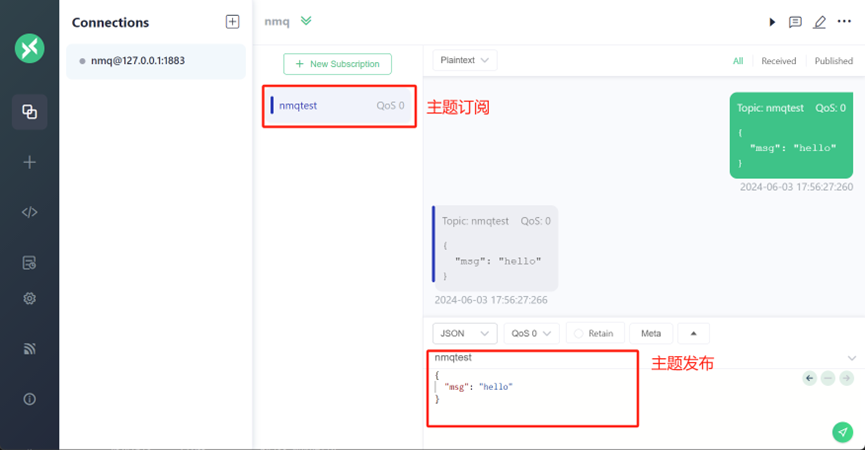
在 Windows 平台搭建 MQTT 服务
引言 MQTT 是一种轻量级、基于发布/订阅模式的消息传输协议,旨在用极小的代码空间和网络带宽为物联网设备提供简单、可靠的消息传递服务。MQTT 经过多年的发展,如今已被广泛应用于资源开采、工业制造、移动通信、智能汽车等各行各业,使得 MQ…...

jdevelope安装
准备 1.jdk1.8(已经安装不做记录) 2.下载jdevelope安装包 3.安装包安装jdevelope开发工具 4.创建或导入项目 下载jdevelope安装包 官网下载地址:https://edelivery.oracle.com 安装包安装jdevelope开发工具 cmd管理员权限运行安装脚本…...

排序(一)——冒泡排序、直接插入排序、希尔排序(BubbleSOrt,InsertSort,ShellSort)
欢迎来到繁星的CSDN,本期的内容主要包括冒泡排序(BubbleSort),直接插入排序(InsertSort),以及插入排序进阶版希尔排序(ShellSort)。 废话不多说,直接上正题! 一、冒泡排序 冒泡排序…...

synchronized关键字详解(全面分析)
目录 synchronized关键字详解1、synchronized关键字简介2、synchronized作用和使用场景作用使用场景①、用在代码块上(类级别同步)②、用在代码块上(对象级别同步)③、用在普通方法上(对象级别同步)④、用在静态方法上(类级别同步)总结: 3、synchronized底层原理&am…...
)
数据建设实践之大数据平台(三)
安装hadoop 上传安装文件到/opt/software目录并解压 [bigdatanode101 software]$ tar -zxvf hadoop-3.3.5.tar.gz -C /opt/services/ 配置环境变量 [bigdatanode101 ~]$ sudo vim /etc/profile.d/bigdata_env.sh export JAVA_HOME/opt/services/jdk1.8.0_161 export ZK_HO…...

TypeScript中的交叉类型
交叉类型:将多个类型合并为一个类型,使用&符号连接。 type AProps { a: string }type BProps { b: number }type allProps AProps & BPropsconst Info: allProps {a: 小月月,b: 7} 我们可以看到交叉类型是结合两个属性的属性值,那…...

CNN -1 神经网络-概述2
CNN -1 神经网络-概述2 一:神经网络(operator)1> 线性层(Fully Connected Layer)2> 卷积层(Convolutional Layer)3> 池化层(Pooling Layer)4> 循环层(Recurrent Layer)5> 归一化层(Normalization Layer)6> 激活函数(Activation Function)7>…...

利用js实现图片压缩功能
图片压缩在众多应用场景中扮演着至关重要的角色,尤其是在客户端上传图片时。原始图片往往体积庞大,直接上传不仅消耗大量带宽资源,还可能导致上传速度缓慢,严重影响用户体验。因此,在图片上传至服务器前对其进行压缩处…...

VR-Reversal:打破设备限制,让3D视频在普通屏幕“活“起来
VR-Reversal:打破设备限制,让3D视频在普通屏幕"活"起来 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: htt…...
)
别再只盯着P0XXX了!一文搞懂UDS诊断中DTC的三个字节到底在说什么(附实战解析)
解码UDS诊断中的DTC三字节:从十六进制到故障真相 当诊断仪屏幕上跳出"0x43E711"这样的神秘代码时,多数工程师的第一反应是翻查故障码手册。但真正的高手会像破译密码一样,直接拆解这三个字节背后的工程语言。本文将带您深入DTC的二…...
三分钟掌握Translumo:打破语言障碍的实时屏幕翻译神器
三分钟掌握Translumo:打破语言障碍的实时屏幕翻译神器 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾…...

基于STM32H750XBH6开发板调试LwIP裸机程序
目录 1 前言 2 正点原子STM32H750XBH6阿波罗开发板介绍 3 配置和调试 3.1 CubeMX配置 3.2 代码修改 1 前言 LwIP 是物联网 / 嵌入式领域使用最广的开源 精简版TCP/IP 协议栈,STM32、ESP32、国产 MCU 全都用它,对于嵌入式 / 物联网初学者来说,亲手调试 LwIP 裸机程序(无操作…...

LSTM比特币价格预测:特征工程驱动的交易信号生成器
1. 项目概述:为什么用RNN/LSTM做比特币价格预测,而不是随便套个模型?我从2018年开始接触加密资产量化分析,最早用的是ARIMA和随机森林——前者对趋势拐点完全失灵,后者在训练集上准确率92%,一到实盘就跌破6…...

TensorFlow+GCP+Firebase构建生产级AI Web应用
1. 项目概述:这不是一个“AI玩具”,而是一套可上线、可运维、可迭代的生产级Web应用工作流你有没有遇到过这样的情况:用TensorFlow训练好一个模型,本地Jupyter里跑得飞起,准确率98%,但一想到要把它变成网页…...

STM32H750 ADC性能调优指南:牺牲分辨率换速度?快速转换模式深度实测
STM32H750 ADC性能调优实战:如何在速度与精度间找到最佳平衡点 最近在做一个电机控制项目时,遇到了一个棘手的问题——ADC采样速度跟不上PWM频率的变化。当我尝试将PWM频率提升到20kHz以上时,系统开始出现明显的控制延迟。这个问题让我不得不…...

用 TLA+ 形式化验证 Harness 的并发安全性
从零到一:用TLA+形式化验证Harness CI/CD平台的并发操作安全性 副标题:解决分布式环境下流水线执行、资源抢占、状态一致性的核心痛点 摘要/引言 如果你是云原生团队的开发或运维工程师,大概率遇到过这样的场景:两个生产部署流水线同时触发,同时抢占同一个K8s集群的环境…...

BurpSuite中文乱码根因解析:Java字体渲染与系统编码协同调试
1. 为什么中文设置不是“点一下就完事”——BurpSuite里被低估的本地化陷阱刚接触渗透测试的新手,打开BurpSuite第一反应往往是:界面全是英文,看着费劲。于是搜到“BurpSuite 中文设置”,点开几篇教程,照着复制粘贴几行…...

今天不学这5个专业级Refinement技巧,你的ChatGPT文章永远过不了主编终审关
更多请点击: https://codechina.net 第一章:Refinement技巧在ChatGPT内容生产中的战略价值 Refinement(精炼)并非简单的二次润色,而是以目标导向的迭代式提示工程策略——它通过结构化反馈、上下文锚定与语义约束&…...