elasticsearch 查询超10000的解决方案
前言
默认情况下,Elasticsearch集群中每个分片的搜索结果数量限制为10000。这是为了避免潜在的性能问题。
但是我们 在实际工作过程中时常会遇到 需要深度分页,以及查询批量数据更新的情况
问题:当请求form + size >10000 时,请求直接报错

1:修改max_result_window 参数(不推荐)
在此方案中,我们建议仅限于测试用,生产禁用,毕竟当数据量大的时候,过大的数据量可能导致es的内存溢出,直接崩掉,一年绩效白干。
PUT wkl_test/_settings
{"index":{"max_result_window":2147483647}
}
查看索引的 settings

重新查数据:

2:使用游标 scroll API
使用scroll API:scroll API可以帮助我们在不加载所有数据的情况下获取所有结果。它会在后台执行查询以获取滚动ID,并将其用于进行后续查询。这样就可以一次性获取所有结果,而不必担心限制
ES语句查询
在游标方案中,我们只需要在第一次拿到游标id,之后通过游标就能唯一确定查询,在这个查询中通过我们指定的 size 移动游标,具体操作看看下面实操。
- 游标查询,设置游标有效时间,有效时间内,游标都可以使用,过期就不行了
GET wkl_test/_search?scroll=5m
{"query": {"match_all": {}},"sort": [{"seq": {"order": "asc"}}],"size": 200
}
- 上面操作中通过游标的结果返回

- 之后将_scroll_id 复制到窗口,就可以不端通过这个_scroll_id 进行之前设置的页数不断翻页
以此类推,后面每次滚屏都把前一个的scroll_id复制过来。注意到,后续请求时没有了index信息,size信息等,这些都在初始请求中,只需要使用scroll_id和scroll两个参数即可。

注意,此时游标移动了,所以我们可以通过游标的方式不断后移,直到移动到我们想要的 from+size 范围内。再次点击

java实现
@Testpublic void testScroll(){RestHighLevelClient restHighLevelClient ;BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.mustNot(QueryBuilders.existsQuery("seq"));try {//滚动查询的Scroll,设置请求滚动时间窗口时间Scroll scroll = new Scroll(TimeValue.timeValueMillis(180000));SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//加入query语句sourceBuilder.query(boolQueryBuilder);//每次滚动的长度sourceBuilder.size(SIZE);//加入排序字段sourceBuilder.sort("id", SortOrder.DESC);//构建searchRequest//加入scroll和构造器SearchRequest searchRequest = new SearchRequest().indices("wkl_test").source(sourceBuilder).scroll(scroll);//存储scroll的listList<String> scrollIdList = new ArrayList<>();//执行首次检索SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//首次检索返回scrollId,用于下一次的滚动查询String scrollId = searchResponse.getScrollId();//拿到hits结果SearchHit[] hits = searchResponse.getHits().getHits();long value = searchResponse.getHits().getTotalHits().value;//保存返回结果List大小Long resultSize = 0L;scrollIdList.add(scrollId);try {//滚动查询将SearchHit封装到result中while (ArrayUtils.isNotEmpty(hits) && hits.length > 0) {BulkRequest bulkRequest = new BulkRequest();JSONArray esArray = new JSONArray();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();String index = hit.getIndex();JSONObject jsonObject = JSONObject.parseObject(sourceAsString);String seq = jsonObject.getString("seq");if(StringUtils.isBlank(seq) ){esArray.add(jsonObject);String uuid = jsonObject.getString("id");jsonObject.put("is_del",1);bulkRequest.add(new UpdateRequest(index, uuid).doc(jsonObject));}}resultSize = resultSize+hits.length;//发送请求//实时更新bulkRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.getTook()+"-------"+bulk.getItems().length);//说明滚动完了,返回结果即可if (resultSize > 20000) {break;}//继续滚动,根据上一个游标,得到这次开始查询位置SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);searchScrollRequest.scroll(scroll);//得到结果SearchResponse searchScrollResponse = restHighLevelClient.scroll(searchScrollRequest, RequestOptions.DEFAULT);//定位游标scrollId = searchScrollResponse.getScrollId();hits = searchScrollResponse.getHits().getHits();scrollIdList.add(scrollId);}System.out.println("----彻底结束了-----");} finally {//清理scroll,释放资源ClearScrollRequest clearScrollRequest = new ClearScrollRequest();clearScrollRequest.setScrollIds(scrollIdList);restHighLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);}} catch (Exception e) {throw new RuntimeException(e);}}
scroll API 的优缺点和总结
优缺点:
- scroll查询的相应数据是非实时的,如果遍历过程中插入新的数据,是查询不到的。并且保留上下文需要足够的堆内存空间。
- 相比于 from/size 和 search_after 返回一页数据,Scroll API 可用于从单个搜索请求中检索大量结果。但是 scroll 滚动遍历查询是非实时的,数据量大的时候,响应时间可能会比较长
适用场景
- 全量或数据量很大时遍历结果数据,而非分页查询。
- scroll方案基于快照,不能用在高实时性的场景下,建议用在类似数据导出场景下使用
3: search_after + PIT 深度查询
- Search_after是 ES 5 新引入的一种分页查询机制,其原理几乎就是和scroll一样,因此代码也几乎是一样的。
- 官方文档说明不再建议使用scroll滚动分页和from size分页,建议使用search_after
- search_after 分页的方式和 scroll 搜索有一些显著的区别,首先它是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
不带PIT
ES语句实现
检索第一页的查询如下所示:
GET wkl_test/_search
{"query": {"match_all": {}},"sort": [{"seq": {"order": "asc"}}],"size": 200
}上述请求的结果包括每个文档的 sort 值数组。

这些 sort 值可以与 search_after 参数一起使用,以开始返回在这个结果列表之后的任何文档。例如,我们可以使用上一个文档的 sort 值并将其传递给 search_after 以检索下一页结果:

Java 实现
@Testpublic void testSearchAfter() throws IOException {RestHighLevelClient restHighLevelClient = es7UtilApi.getRestHighLevelClient();MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(matchAllQueryBuilder);searchSourceBuilder.from(0);searchSourceBuilder.size(200);searchSourceBuilder.sort("seq", SortOrder.ASC);searchSourceBuilder.trackTotalHits(true);SearchRequest searchRequest = new SearchRequest().indices("wkl_test").source(searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);SearchHits hits = searchResponse.getHits();long value = hits.getTotalHits().value;System.out.println("查询到记录数=" + value);List<JSONObject> list = new ArrayList<>();SearchHit[] searchHists = hits.getHits();Object[] sortValues = searchHists[searchHists.length - 1].getSortValues();if (searchHists.length > 0) {for (SearchHit hit : searchHists) {String sourceAsString = hit.getSourceAsString();JSONObject jsonObject = JSON.parseObject(sourceAsString);jsonObject.put("_id", hit.getId());list.add(jsonObject);}}//往后的每次请求都携带上一次的sort_id进行访问。while (ArrayUtils.isNotEmpty(searchHists) && searchHists.length > 0){searchSourceBuilder.searchAfter(sortValues);searchRequest.source(searchSourceBuilder);SearchResponse searchResponseAfter = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);hits = searchResponseAfter.getHits();searchHists = hits.getHits();sortValues = searchHists[searchHists.length - 1].getSortValues();if (searchHists.length > 0) {for (SearchHit hit : searchHists) {String sourceAsString = hit.getSourceAsString();JSONObject jsonObject = JSON.parseObject(sourceAsString);jsonObject.put("_id", hit.getId());list.add(jsonObject);}}if(list.size()>20000){break;}System.out.println("-----彻底结束了-------");}}
问题
「优点:」
-
无状态查询,可以防止在查询过程中,数据的变更无法及时反映到查询中。
-
不需要维护scroll_id,不需要维护快照,因此可以避免消耗大量的资源。
「缺点:」
-
由于无状态查询,因此在查询期间的变更可能会导致跨页面的不一值。
-
排序顺序可能会在执行期间发生变化,具体取决于索引的更新和删除。
-
至少需要制定一个唯一的不重复字段来排序。
-
它不适用于大幅度跳页查询,或者全量导出,对第N页的跳转查询相当于对es不断重复的执行N次search after,而全量导出则是在短时间内执行大量的重复查询。
带PIT
关于PIT
-
在7.*版本中,ES官方不再推荐使用Scroll方法来进行深分页,而是推荐使用带PIT的search_after来进行查询;
-
从7.*版本开始,您可以使用SEARCH_AFTER参数通过上一页中的一组排序值检索下一页命中。
-
使用SEARCH_AFTER需要多个具有相同查询和排序值的搜索请求。
-
如果这些请求之间发生刷新,则结果的顺序可能会更改,从而导致页面之间的结果不一致。
为防止出现这种情况,您可以创建一个时间点(PIT)来在搜索过程中保留当前索引状态。
ES语句实现
1:生成pit
#keep_alive必须要加上,它表示这个pit能存在多久,这里设置的是1分钟
POST wkl_test/_pit?keep_alive=1m

2:在搜索请求中指定PIT:
在每个搜索请求中添加 keep_alive 参数来延长 PIT 的保留期,相当于是重置了一下时间
GET _search
{"query": {"match_all": {}},"pit":{"id":"t_yxAwEId2tsX3Rlc3QWU0hzbEJkYWNTVEd0ZGRoN0xsQVVNdwAWUGQtaXJpT0xTa2VUN0RGLXZfTlBvZwAAAAAACHG1fxY1UWNKX1RHOFMybXBaV20zbWx3enp3ARZTSHNsQmRhY1NUR3RkZGg3TGxBVU13AAA=","keep_alive":"5m"},"sort": [{"seq": {"order": "asc"}}],"size": 200
}

3:删除PIT
DELETE _pit
{"id":"t_yxAwEId2tsX3Rlc3QWU0hzbEJkYWNTVEd0ZGRoN0xsQVVNdwAWUGQtaXJpT0xTa2VUN0RGLXZfTlBvZwAAAAAACHG1fxY1UWNKX1RHOFMybXBaV20zbWx3enp3ARZTSHNsQmRhY1NUR3RkZGg3TGxBVU13AAA="
}

总结
-
如果数据量小(from+size在10000条内),或者只关注结果集的TopN数据,可以使用from/size 分页,简单粗暴
-
数据量大,深度翻页,后台批处理任务(数据迁移)之类的任务,使用 scroll 方式
-
数据量大,深度翻页,用户实时、高并发查询需求,使用 search after 方式
相关文章:
elasticsearch 查询超10000的解决方案
前言 默认情况下,Elasticsearch集群中每个分片的搜索结果数量限制为10000。这是为了避免潜在的性能问题。 但是我们 在实际工作过程中时常会遇到 需要深度分页,以及查询批量数据更新的情况 问题:当请求form size >10000 时,…...

SpringCloud集成kafka集群
目录 1.引入kafka依赖 2.在yml文件配置配置kafka连接 3.注入KafkaTemplate模版 4.创建kafka消息监听和消费端 5.搭建kafka集群 5.1 下载 kafka Apache KafkaApache Kafka: A Distributed Streaming Platform.https://kafka.apache.org/downloads.html 5.2 在config目录下做…...

Macos 远程登录 Ubuntu22.04 桌面
这里使用的桌面程序为 xfce, 而 gnome 桌面则测试失败。 1,安装 在ubuntu上,安装 vnc server与桌面程序xfce sudo apt install xfce4 xfce4-goodies tightvncserver 2,第一次启动和配置 $ tightvncserver :1 设置密码。 然后修改配置:…...

第十届MathorCup高校数学建模挑战赛-A题:无车承运人平台线路定价问题
目录 摘 要 1 问题重述 1.1 研究背景 1.2 研究问题 2 符号说明与模型假设 2.1 符号说明 2.2 模型假设 3 问题一:模型建立与求解 3.1 问题分析与思路 3.2 模型建立 3.2.1 多因素回归模型 3.3 模型求解 3.3.1 数据预处理 3.3.2 重要度计算 4 问题二:模型建立与求…...

在分布式环境中,怎样保证 PostgreSQL 数据的一致性和完整性?
文章目录 在分布式环境中保证 PostgreSQL 数据的一致性和完整性一、数据一致性和完整性的重要性二、分布式环境对数据一致性和完整性的挑战(一)网络延迟和故障(二)并发操作(三)数据分区和复制 三、保证 Pos…...

RabbitMq如何保证消息的可靠性和稳定性
RabbitMq如何保证消息的可靠性和稳定性 rabbitMq不会百分之百让我们的消息安全被消费,但是rabbitMq提供了一些机制来保证我们的消息可以被安全的消费。 消息确认 消息者在成功处理消息后可以发送确认(ACK)给rabbitMq,通知消息已…...

druid(德鲁伊)数据线程池连接MySQL数据库
文章目录 1、druid连接MySQL2、编写JDBCUtils 工具类 1、druid连接MySQL 初学JDBC时,连接数据库是先建立连接,用完直接关闭。这就需要不断的创建和销毁连接,会消耗系统的资源。 借鉴线程池的思想,数据连接池就这么被设计出来了。…...

观察者模式的实现
引言:观察者模式——程序中的“通信兵” 在现代战争中,通信是胜利的关键。信息力以网络、数据、算法、算力等为底层支撑,在现代战争中不断推动感知、决策、指控等各环节产生量变与质变。在软件架构中,观察者模式扮演着类似的角色…...

Eureka: Netflix开源的服务发现框架
在微服务架构中,服务发现是一个关键组件,它允许服务实例之间相互发现并进行通信。Eureka是由Netflix开源的服务发现框架,它是Spring Cloud体系中的核心组件之一。Eureka提供了服务注册与发现的功能,支持区域感知和自我保护机制&am…...

go-基准测试
基准测试 Demo // fib_test.go package mainimport "testing"func BenchmarkFib(b *testing.B) {for n : 0; n < b.N; n {fib(30) // run fib(30) b.N times} }func fib(n int) int {if n 0 || n 1 {return n}return fib(n-2) fib(n-1) }benchmark 和普通的单…...

线性代数|机器学习-P23梯度下降
文章目录 1. 梯度下降[线搜索方法]1.1 线搜索方法,运用一阶导数信息1.2 经典牛顿方法,运用二阶导数信息 2. hessian矩阵和凸函数2.1 实对称矩阵函数求导2.2. 线性函数求导 3. 无约束条件下的最值问题4. 正则化4.1 定义4.2 性质 5. 回溯线性搜索法 1. 梯度…...

SQL,python,knime将数据混合的文字数字拆出来,合并计算实战
将下面将数据混合的文字数字拆出来,合并计算 一、SQL解决: ---创建表插入数据 CREATE TABLE original_data (id INT AUTO_INCREMENT PRIMARY KEY,city VARCHAR(255),value DECIMAL(10, 2) );INSERT INTO original_data (city, value) VALUES (上海0.5…...

mac ssh连接工具
在Mac上,有多个SSH连接工具可供选择,这些工具根据其功能和适用场景的不同,可以满足不同用户的需求。以下是一些推荐的SSH客户端软件:12 iTerm2:这是一款功能强大的终端应用程序,提供了丰富的功能和定制选项…...
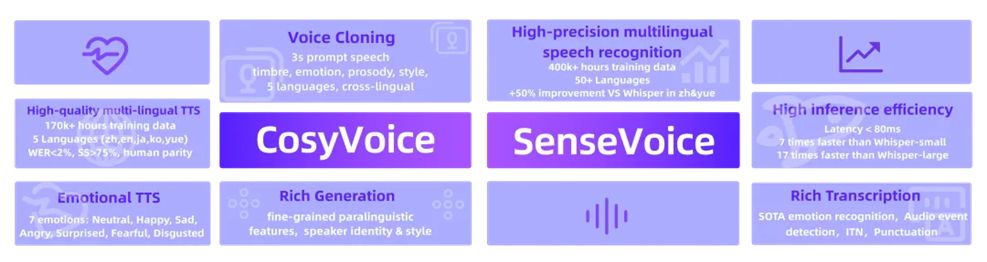
阿里通义音频生成大模型 FunAudioLLM 开源
简介 近年来,人工智能(AI)技术的进步极大地改变了人类与机器的互动方式,特别是在语音处理领域。阿里巴巴通义实验室最近开源了一个名为FunAudioLLM的语音大模型项目,旨在促进人类与大型语言模型(LLMs&…...
通用详情页的打造
背景介绍 大家都知道,详情页承载了站内的核心流量。它的量级到底有多大呢? 我们来看一下,日均播放次数数亿次,这么大的流量,其重要程度可想而知。 在这样一个页面,每一个功能都是大量业务的汇总点。 作为…...

java内部类的本质
定义在类内部,可以实现对外部完全隐藏,可以有更好的封装性,代码实现上也往往更为简洁。 内部类可以方便地访问外部类的私有变量,可以声明为private从而实现对外完全隐藏。 在Java中,根据定义的位置和方式不同…...

vue3 学习笔记08 -- computed 和 watch
vue3 学习笔记08 – computed 和 watch computed computed 是 Vue 3 中用于创建计算属性的重要 API,它能够根据其它响应式数据动态计算出一个新的值,并确保在依赖数据变化时自动更新。 基本用法 squaredCount 是一个计算属性,它依赖于 count…...

Python-PLAXIS自动化建模技术与典型岩土工程案例
有限单元法在岩土工程问题中应用非常广泛,很多软件都采用有限单元解法。在使用各大软件进行数值模拟建模的过程中,岩土工程中的各种问题(塑性、渗流、固结、动力、稳定安全、热力TM),一步一步地搭建自己的Plaxis模型&a…...

license系统模型设计使用django models
User (用户)License (许可证)Product (产品)LicenseAssignment (许可证分配) 简单的模型定义: from django.db import models from django.contrib.auth.models import Userclass Product(models.Model):name models.CharField(max_length255)description model…...

【通信协议-RTCM】MSM语句(1) - 多信号GNSS观测数据消息格式
注释: RTCM响应消息1020为GLONASS星历信息,暂不介绍,前公司暂未研发RTCM消息类型版本的DR/RTK模块,DR/RTK模块仅NMEA消息类型使用 注释: 公司使用的多信号语句类型为MSM4&MSM7,也应该是运用最广泛的语句…...

Open MCT性能压测实战:JMeter定制化四阶测试方法论
1. 为什么Open MCT的性能不能只靠“感觉”来判断?Open MCT——NASA开源的航天器监控与控制平台,这几年在工业SCADA、能源调度、实验室数据可视化等场景里越来越常见。但凡用过它的团队,几乎都经历过这样一个阶段:开发阶段一切丝滑…...

抖音获客失效?拆解本地商家流量困局的底层逻辑与破局路径
一、一个反直觉的数据先看两组数据,它们指向同一个方向。第一组:2025年,抖音本地生活服务GMV突破8500亿元。同期,入驻商家达到1519.8万家动销门店,399万新商家在一年内涌入。第二组:2026年Q1,抖…...

河南话TTS项目踩坑实录:为什么你的“中”字总发成“zōng”?——基于127小时方言语料的韵律建模纠偏指南
更多请点击: https://kaifayun.com 第一章:河南话TTS项目踩坑实录:为什么你的“中”字总发成“zōng”? 在构建河南方言语音合成(TTS)系统时,我们发现一个高频且顽固的问题:标准普通…...

告别演讲焦虑:PPTTimer如何让时间管理变得简单智能
告别演讲焦虑:PPTTimer如何让时间管理变得简单智能 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 你是否曾在重要演讲时频繁看表,担心时间不够用?是否在PPT演示中因时间控制…...

长期使用后回顾 Taotoken 在 API 调用稳定性与客服响应上的综合体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用后回顾 Taotoken 在 API 调用稳定性与客服响应上的综合体验 作为一项服务于项目开发的基础设施,大模型 API 的…...

SDR++软件无线电:3个关键步骤让你轻松探索无线电频谱世界
SDR软件无线电:3个关键步骤让你轻松探索无线电频谱世界 【免费下载链接】SDRPlusPlus Cross-Platform SDR Software 项目地址: https://gitcode.com/GitHub_Trending/sd/SDRPlusPlus 你是否曾经好奇过无线电波中隐藏着怎样的秘密?从FM广播到航空通…...

Taotoken API Key的权限管理与审计日志功能初探
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key的权限管理与审计日志功能初探 对于将大模型能力集成到业务流程中的团队而言,API Key的安全管理与操作…...

罗技鼠标宏逆向工程:PUBG后坐力补偿系统的架构设计与实现
罗技鼠标宏逆向工程:PUBG后坐力补偿系统的架构设计与实现 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在竞技射击游戏中ÿ…...

为内部知识库问答系统集成 Taotoken 多模型增强回答多样性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答系统集成 Taotoken 多模型增强回答多样性 在企业内部知识库中构建智能问答系统,核心目标之一是提供准…...

PX4固件编译避坑指南:自定义机型后如何正确生成airframe_metadata并更新QGC
PX4固件编译避坑指南:自定义机型后如何正确生成airframe_metadata并更新QGC 当你花费数小时精心设计了一个全新的无人机机型,修改完所有参数并准备在QGroundControl(QGC)中测试时,却发现地面站无法识别你的自定义机型—…...