Snap Video:用于文本到视频合成的扩展时空变换器
图像生成模型的质量和多功能性的显著提升,研究界开始将其应用于视频生成领域。但是视频内容高度冗余,直接将图像模型技术应用于视频生成可能会降低运动的保真度和视觉质量,并影响可扩展性。来自 Snap 的研究团队及其合作者提出了 "Snap Video",这是一个以视频为中心的模型,系统地解决了这些挑战。它扩展了EDM(Energetic Diffusion Model)框架,以考虑空间和时间冗余像素,并自然支持视频生成。另外,由于U-Net在生成视频时扩展性差,需要显著的计算开销。因此本文还提出了一种新的基于变换器的架构,其训练速度比U-Nets快3.31倍(在推理时大约快4.5倍)。这使本模型能够首次高效地训练具有数十亿参数的文本到视频模型,达到一系列基准测试的最新结果,并生成质量更高、时间一致性和运动复杂性显著的视频。用户研究表明,本模型在文本对齐和运动质量方面比其他最新方法更受好评。

这些样本展示了生成器能够合成具有大运动的暂时连贯视频(左侧),同时保留大规模文本到视频生成器的语义控制能力(右侧)
方法
EDM 通过模拟一个数据生成的随机过程,其中数据样本逐渐被噪声所覆盖,这个过程称为前向扩散过程。在这个过程中,噪声水平由一个扩散时间步长 σ 来控制,它与噪声的标准差相对应。随着噪声的逐步增加,数据样本从原始状态逐渐转变为高噪声状态。
与此相对的是一个学习到的去噪器,它执行一个逆向过程,即从噪声数据中逐步去除噪声,恢复出清晰的数据样本。这个过程称为反向扩散过程,去噪器 Dθ 通过最小化去噪后样本与原始数据之间的差异来进行训练。去噪目标函数 L(Dθ) 定义了去噪器的性能,它通常以去噪后样本与原始样本之间的均方误差为基础。
对于高分辨率视频生成,EDM 框架面临的挑战是:视频数据帧之间的高度冗余,如果直接应用图像生成模型的方法在视频生成时可能导致运动的保真度降低和视觉质量下降。为了解决这个问题,研究者对 EDM 框架进行了扩展和修改,使其能够更好地处理视频数据的特性。

表格展示了原始EDM框架和本文提出的修改版本之间的对比
研究者引入了一个输入缩放因子 σin,用于调整前向过程中噪声的强度,以保持在原始分辨率下的信噪比。这样做可以防止在高分辨率视频生成过程中出现的不稳定性,如在初始采样步骤中由于平均帧尚未包含清晰的信号而导致的训练-推理不匹配问题。通过重新定义前向过程和调整采样器,作者确保了即使在高分辨率视频生成的情况下,EDM 框架也能够维持其设计的信噪比,从而提高了生成视频的质量和运动的连贯性。

在处理图像和视频数据时的挑战是如何有效地结合这两种模态,尤其是当可用的带字幕视频数据相对较少时。研究者们通常采用联合图像-视频训练方法,以便利用更丰富的图像数据来提升视频生成的性能。然而,视频数据具有时间维度上的特性,即连续帧之间的内容可能高度相关,这与单独的图像数据存在本质的不同。
为了解决这个问题,研究者提出了一种图像-视频模态匹配方法,该方法通过将图像视为具有无限帧率的 T 帧视频来实现。这种方法允许使用统一的扩散过程同时处理图像和视频数据,而无需为每种模态单独设计和优化模型。通过这种可变帧率训练过程,模型能够学习到图像和视频数据之间的共同特征,同时保留对视频特有动态特性的捕捉能力,从而有效地弥合了图像和视频模态之间的差距。
在视频生成器的设计方面,U-Net 架构虽然在图像生成方面表现出色,但在扩展到视频生成时,其计算效率和模型可扩展性面临挑战。特别是当处理高分辨率视频时,U-Net 需要对每一帧都执行完整的网络前向传播,这导致了显著的计算开销,并限制了模型处理更大数据的能力。
为了克服这些限制,研究者提出了一种基于 FIT(Far-reaching Interleaved Transformers)的高效变换器架构。FIT 架构的核心思想是学习输入数据的压缩表示,将空间和时间维度的信息编码到一个单一的、压缩的 1D 潜在向量中。这样,即使输入数据的维度增加,模型也能够高效地处理,因为大部分计算都集中在这个压缩的潜在空间上。

3.a 展示了基于U-Net的文本到图像架构如何通过插入时间层来适应视频生成,创建可分离的时空块。指出了这种方法在可扩展性方面的限制
3.b 描述了所提出的Snap Video FIT架构。展示了给定带噪声的输入视频,模型如何通过递归应用FIT块来估计去噪视频
通过这种设计,FIT 架构不仅能够处理高分辨率视频,还能够实现对复杂动态场景的建模,同时显著提高了训练和推理的速度。这种架构的可扩展性使得它可以轻松扩展到数十亿参数的规模,而推理速度的提高则使得它能够快速生成高质量的视频内容。
在训练 Snap Video 模型时,研究者选择了 LAMB 优化器,这是一种在深度学习中广泛使用的优化算法,特别适合于大型模型的训练。LAMB 的全称是 "Layer-wise Adaptive Moments optimizer for Batch training",它结合了 Adam 优化器的自适应学习率特性和 Momentum 优化器的动量累积特性,有助于加速模型的收敛并提高训练的稳定性。
训练过程中,研究者实施了一个余弦退火学习率调度策略,这种策略可以随着训练的进行逐渐降低学习率,从而在训练初期快速收敛,在训练后期微调模型参数。研究者采用了较大的批量大小,总共 2048 个视频和 2048 个图像,这样的批量大小得益于他们设计的可扩展视频生成架构,允许模型有效处理大规模数据。
模型的训练分为两个阶段。在第一阶段,研究者训练了一个基础模型,进行了 550k 步的迭代。随后,为了生成更高分辨率的视频,研究者在第一阶段的基础上,对第二阶段模型进行了微调,使用了 370k 次迭代,从第一阶段的模型权重开始,进一步优化模型以适应更高分辨率的视频数据。
在推理或生成视频的阶段,研究者采用了确定性采样器,这种采样器可以从头开始,使用高斯噪声作为初始化状态,逐步生成视频数据。他们使用了两阶段的级联模型来生成最终的视频样本。第一阶段模型使用 256 个采样步骤来生成一个初步的视频,然后第二阶段模型在这个基础上进一步细化,使用 40 个采样步骤来提高视频的分辨率和质量。
为了改善生成视频与文本描述之间的对齐度,研究者还采用了分类器自由引导技术。这种技术可以在不依赖于显式分类器的情况下,引导模型生成与文本描述更加吻合的视频内容。除非有其他特殊说明,否则在推理过程中默认使用这种引导技术。
评估
研究者使用了内部数据集,该数据集包含 126.5 万张图像和 23.8 万小时的视频,每个都有相应的文本标题。由于为视频获取高质量字幕的难度较大,研究者开发了一个视频字幕模型,用于为数据集中缺少标注的视频生成合成字幕。他们还使用了以下未在训练中观察过的数据集进行评估:UCF-101 和 MSR-VTT。UCF-101 是一个包含 13,320 个 YouTube 视频的数据集,涵盖 101 个动作类别。MSR-VTT 包含 10,000 个视频,每个视频都有 20 个文本标题的手动注释。
为了验证在扩散框架和模型架构上所做的选择,研究者在 64 × 36 像素分辨率下使用第一阶段模型进行了消融实验,并计算了 FID、FVD 和 CLIPSIM 指标,以评估内部数据集测试集上的 50k 个生成视频。在与基线的零样本评估中,他们遵循了 UCF-101 和 MSR-VTT 数据集上的协议,生成了 16 帧、512 × 288 像素分辨率、24fps 的视频,并在这些数据集上评估了视频质量和文本-视频对齐。
为了评估所提出的架构,研究者考虑了不同容量的 U-Net 变体,并将其适应到视频生成设置中,通过插入时间注意力操作。他们展示了不同配置的消融研究,包括原始的 EDM 框架和提出的扩散框架的不同配置,以及将图像视为无限帧率视频的处理方式。

研究者在 UCF101 和 MSR-VTT 数据集上对 Snap Video 进行了与基线的比较。他们发现,与基线相比,FID 和 FVD 视频质量指标有所提高,这归因于采用的扩散框架和联合时空建模。在 UCF101 上,他们的方法产生了第二好的 IS 分数,表明了良好的文本-视频对齐。尽管在 MSR-VTT 上,他们的方法在 CLIPSIM 分数上超过了 Make-A-Video,但注意到它产生了较低的分数,这可能归因于使用了 T5 文本嵌入而不是常用的 CLIP 嵌入。


在定性评估部分,研究者展示了 Snap Video 与现有最先进视频生成器的比较结果。他们展示了在公共样本上的比较,包括 Make-A-Video、PYoCo、Video LDM 和 Imagen Video。Snap Video 生成的视频在保持时间连贯性的同时,避免了基线方法中由于时间不一致性导致的闪烁伪影。

通过这一系列的评估,研究者证明了 Snap Video 在文本到视频合成方面的先进性能,特别是在生成具有丰富动作的视频方面。随着文本到视频合成技术的飞速发展,Snap Video 模型的提出标志着该领域的一个重要进展。
论文链接:https://arxiv.org/abs/2402.14797
相关文章:
Snap Video:用于文本到视频合成的扩展时空变换器
图像生成模型的质量和多功能性的显著提升,研究界开始将其应用于视频生成领域。但是视频内容高度冗余,直接将图像模型技术应用于视频生成可能会降低运动的保真度和视觉质量,并影响可扩展性。来自 Snap 的研究团队及其合作者提出了 "Snap …...

实验8 视图创建与管理实验
一、实验目的 理解视图的概念。掌握创建、更改、删除视图的方法。掌握使用视图来访问数据的方法。 二、实验内容 在job数据库中,有聘任人员信息表:Work_lnfo表,其表结构如下表所示: 其中表中练习数据如下: 1.‘张明…...

C++ 开源库
1 PDFium PDFium 是一个开源的 PDF 渲染和处理库,最初由 Foxit Software 开发,并于2014年捐赠给了 Chromium 项目。PDFium 旨在为各种应用程序提供高效、灵活的 PDF 渲染和操作功能。 2 代码地址 https://github.com/chromium/pdfium 主要特性 渲染…...
LabVIEW滤波器性能研究
为了研究滤波器的滤波性能,采用LabVIEW设计了一套滤波器性能研究系统。该系统通过LabVIEW中的波形生成函数,输出幅值及频率可调的正弦波和白噪声两种信号,并将白噪声与正弦波叠加,再通过滤波器输出纯净的正弦波信号。系统通过FFT&…...

『C++成长记』vector模拟实现
🔥博客主页:小王又困了 📚系列专栏:C 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、存储结构 二、默认成员函数 📒2.1构造函数 📒2.2拷贝…...

【Mac】Charles for Mac(HTTP协议抓包工具)及同类型软件介绍
软件介绍 Charles for Mac 是一款功能强大的网络调试工具,主要用于HTTP代理/HTTP监视器。以下是它的一些主要特点和功能: 1.HTTP代理:Charles 可以作为HTTP代理服务器,允许你查看客户端和服务器之间的所有HTTP和SSL/TLS通信。 …...

LVS集群及其它的NAT模式
1.lvs集群作用:是linux的内核层面实现负载均衡的软件;将多个后端服务器组成一个高可用、高性能的服务器的集群,通过负载均衡的算法将客户端的请求分发到后端的服务器上,通过这种方式实现高可用和负载均衡。 2.集群和分布式&#…...

【RNN练习】天气预测
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、环境及数据准备 1. 我的环境 语言环境:Python3.11.9编译器:Jupyter notebook深度学习框架:TensorFlow 2.15.0 2. 导…...

prompt第四讲-fewshot
文章目录 前提回顾FewShotPromptTemplateforamt格式化 前提回顾 前面已经实现了一个翻译助手了[prompt第三讲-PromptTemplate],prompt模板设计中,有说明、案例、和实际的问题 # -*- coding: utf-8 -*- """ Time : 2024/7/8 …...
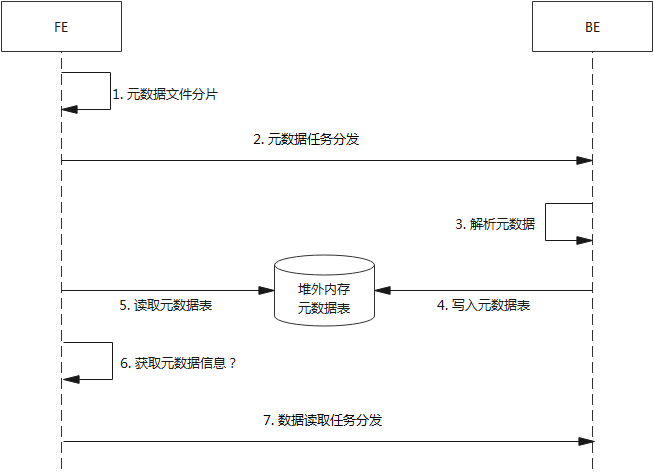
StarRocks分布式元数据源码解析
1. 支持元数据表 https://github.com/StarRocks/starrocks/pull/44276/files 核心类:LogicalIcebergMetadataTable,Iceberg元数据表,将元数据的各个字段做成表的列,后期可以通过sql操作从元数据获取字段,这个表的组成…...

阅读笔记——《Fuzz4All: Universal Fuzzing with Large Language Models》
【参考文献】Xia C S, Paltenghi M, Le Tian J, et al. Fuzz4all: Universal fuzzing with large language models[C]//Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 2024: 1-13.【注】本文仅为作者个人学习笔记,如有冒犯&…...

【C++】使用gtest做单元测试框架写单元测试
本文主要介绍在将gtest框架引入到项目里过程中遇到的问题。 我的需求如下: 用CMake构建项目。我要写一些测试程序验证某些功能,但是不想每一个测试都新建一个main函数。 因为新建一个main函数就要在CMakeList.txt里增加一个project,非常不方便。 于是我搜了下,C++里有没…...

Java类与对象
类是对现实世界中实体的抽象,是对一类事物的描述。 类的属性位置在类的内部、方法的外部。 类的属性描述一个类的一些可描述的特性,比如人的姓名、年龄、性别等。 [public] [abstract|final] class 类名 [extends父类] [implements接口列表] { 属性声…...

xlwings 链接到 指定sheet 从别的 excel 复制 sheet 到指定 sheet
重点 可以参考 宏录制 cell sheet.range(G4)cell.api.Hyperlinks.Add(Anchorcell.api, Address"", SubAddress"001-000-02301!A1")def deal_excel(self):with xw.App(visibleTrue) as app:wb app.books.open(self.summary_path, update_linksFalse)sheet…...

风光摄影:相机设置和镜头选择
写在前面 博文内容为《斯科特凯尔比的风光摄影手册》读书笔记整理涉及在风景拍摄中一些相机设置,镜头选择的建议对小白来讲很实用,避免拍摄一些过曝或者过暗的风景照片理解不足小伙伴帮忙指正 😃,生活加油 99%的焦虑都来自于虚度时间和没有好…...
python制作甘特图的基本知识(附Demo)
目录 前言1. matplotlib2. plotly 前言 甘特图是一种常见的项目管理工具,用于表示项目任务的时间进度 直观地看到项目的各个任务在时间上的分布和进度 常用的绘制甘特图的工具是 matplotlib 和 plotly 主要以Demo的形式展示 1. matplotlib 功能强大的绘图库&a…...

javascript设计模式总结
参考 通过设计模式可以增加代码的可重用性、可扩展性、可维护性 设计模式五大设计原则 单一职责:一个程序只需要做好一件事,如果结构过于复杂就拆分开,保证每个部分独立 开放封闭原则:对扩展开放,对修改封闭。增加需…...

gpt-4o看图说话-根据图片回答问题
问题:中国的人口老龄化究竟有多严重? 代码下实现如下:(直接调用openai的chat接口) import os import base64 import requests def encode_image(image_path): """ 对图片文件进行 Base64 编码 输入…...

【MySQL】7.MySQL 的内置函数
MySQL的内置函数 一.日期函数二.字符串函数三.数学函数四.其它函数 一.日期函数 函数名称说明current_date()当前日期current_time()当前时间current_timestamp当前时间戳(日期时间)date(datetime)截取 datetime 的日期部分date_add(date, interval d_value_type)给 date 添加…...

爬虫:Sentry-Span参数逆向
在抓某眼查数据太过频繁时会出现极验的验证码。极验的教程有很多,主要是发现在这里获取验证码的时候需要携带参数Sentry-Span。在这里记录一下逆向的主要过程,直接上补环境的代码。 window global; location {}; my_log console.log;(function () {l…...

ComfyUI插件革命:如何用AI字幕生成器彻底改变你的图片描述体验
ComfyUI插件革命:如何用AI字幕生成器彻底改变你的图片描述体验 【免费下载链接】ComfyUI_SLK_joy_caption_two ComfyUI Node 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_SLK_joy_caption_two 你是否曾经为了一张图片绞尽脑汁却写不出合适的描述&a…...

【Appium 系列】第13节-混合测试执行器 — API + UI 的协同执行
对应代码:配套代码/test/core/hybrid_test_executor.py说明:本节讲解当一个测试用例需要同时使用接口测试和 UI 测试时,如何协调执行。这节讲什么有些测试用例,光靠接口测试或 UI 测试都不够。比如"验证用户注册后能登录&quo…...

如何在5分钟内掌握ToolsFx密码学工具箱:新手完全指南
如何在5分钟内掌握ToolsFx密码学工具箱:新手完全指南 【免费下载链接】ToolsFx 跨平台密码学工具箱。包含编解码,编码转换,加解密, 哈希,MAC,签名,大数运算,压缩,二维码功…...

MCP协议技术架构深度解析:构建AI工具生态系统的标准化方案
MCP协议技术架构深度解析:构建AI工具生态系统的标准化方案 【免费下载链接】Awesome-MCP-ZH MCP 资源精选, MCP指南,Claude MCP,MCP Servers, MCP Clients 项目地址: https://gitcode.com/gh_mirrors/aw/Awesome-MCP-ZH MC…...

如何在GTA5在线模式中保护自己?YimMenu安全增强菜单完整指南
如何在GTA5在线模式中保护自己?YimMenu安全增强菜单完整指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/y…...

如何5分钟实现桌面股票实时监控:TrafficMonitor股票插件完全指南
如何5分钟实现桌面股票实时监控:TrafficMonitor股票插件完全指南 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为错过重要行情而烦恼吗?想在工作时…...

程序员会被产品经理替代吗?——当AI让“全栈”成为常态,我们的价值在哪里?
程序员会被产品经理替代吗?——当AI让“全栈”成为常态,我们的价值在哪里? 最近,V2EX上一个帖子引发了激烈讨论:随着AI能力的指数级增长,一个人就能完成从前需要整个团队才能做到的全栈开发。如果产品经理借…...

终极macOS Windows启动盘制作工具:WinDiskWriter完整指南
终极macOS Windows启动盘制作工具:WinDiskWriter完整指南 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI & Legac…...

从原理图到PCB:STM32最小系统外围电路布局布线实战避坑指南
从原理图到PCB:STM32最小系统外围电路布局布线实战避坑指南 在嵌入式硬件开发中,设计一个可靠的STM32最小系统PCB远比绘制原理图更具挑战性。许多开发者能够正确连接原理图符号,却在将设计转化为实际电路板时遭遇各种问题——从莫名其妙的复位…...

Cursor Pro破解工具完整指南:三步实现永久免费使用AI编程助手
Cursor Pro破解工具完整指南:三步实现永久免费使用AI编程助手 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...