StarRocks分布式元数据源码解析
1. 支持元数据表
https://github.com/StarRocks/starrocks/pull/44276/files
核心类:LogicalIcebergMetadataTable,Iceberg元数据表,将元数据的各个字段做成表的列,后期可以通过sql操作从元数据获取字段,这个表的组成字段是DataFile相关的字段
public static LogicalIcebergMetadataTable create(String catalogName, String originDb, String originTable) {return new LogicalIcebergMetadataTable(catalogName,ConnectorTableId.CONNECTOR_ID_GENERATOR.getNextId().asInt(),ICEBERG_LOGICAL_METADATA_TABLE_NAME,Table.TableType.METADATA,builder().columns(PLACEHOLDER_COLUMNS).column("content", ScalarType.createType(PrimitiveType.INT)).column("file_path", ScalarType.createVarcharType()).column("file_format", ScalarType.createVarcharType()).column("spec_id", ScalarType.createType(PrimitiveType.INT)).column("partition_data", ScalarType.createType(PrimitiveType.VARBINARY)).column("record_count", ScalarType.createType(PrimitiveType.BIGINT)).column("file_size_in_bytes", ScalarType.createType(PrimitiveType.BIGINT)).column("split_offsets", ARRAY_BIGINT).column("sort_id", ScalarType.createType(PrimitiveType.INT)).column("equality_ids", ARRAY_INT).column("file_sequence_number", ScalarType.createType(PrimitiveType.BIGINT)).column("data_sequence_number", ScalarType.createType(PrimitiveType.BIGINT)).column("column_stats", ScalarType.createType(PrimitiveType.VARBINARY)).column("key_metadata", ScalarType.createType(PrimitiveType.VARBINARY)).build(),originDb,originTable,MetadataTableType.LOGICAL_ICEBERG_METADATA);
}2. Iceberg表扫描
https://github.com/StarRocks/starrocks/pull/44313
核心类:StarRocksIcebergTableScan,扫描Iceberg表的实现类,基于Iceberg的上层接口实现,类似Iceberg默认提供的DataTableScan,doPlanFiles中定义实际的元数据文件扫描逻辑
这一块应当属于数据上层扫描逻辑
protected CloseableIterable<FileScanTask> doPlanFiles() {List<ManifestFile> dataManifests = findMatchingDataManifests(snapshot());List<ManifestFile> deleteManifests = findMatchingDeleteManifests(snapshot());boolean mayHaveEqualityDeletes = !deleteManifests.isEmpty() && mayHaveEqualityDeletes(snapshot());boolean loadColumnStats = mayHaveEqualityDeletes || shouldReturnColumnStats();if (shouldPlanLocally(dataManifests, loadColumnStats)) {return planFileTasksLocally(dataManifests, deleteManifests);} else {return planFileTasksRemotely(dataManifests, deleteManifests);}
}3. Iceberg元数据信息接口
[Feature] Introduce meta spec interface by stephen-shelby · Pull Request #44527 · StarRocks/starrocks · GitHub
核心类:IcebergMetaSpec,Iceberg元数据描述,核心是RemoteMetaSplit的一个List,代表了元数据文件的列表,基于这个做分布式解析
这一块应当属于元数据文件的切片逻辑
public List<RemoteMetaSplit> getSplits() {return splits;
}4. Iceberg元数据扫描节点
https://github.com/StarRocks/starrocks/pull/44581
核心类:IcebergMetadataScanNode,Iceberg元数据的扫描节点,袭乘自PlanNode类,主要是把上节的RemoteMetaSplit放到StarRocks的执行结构当中
这一块属于Iceberg逻辑向StarRocks逻辑的中间转换层
private void addSplitScanRangeLocations(RemoteMetaSplit split) {TScanRangeLocations scanRangeLocations = new TScanRangeLocations();THdfsScanRange hdfsScanRange = new THdfsScanRange();hdfsScanRange.setUse_iceberg_jni_metadata_reader(true);hdfsScanRange.setSerialized_split(split.getSerializeSplit());hdfsScanRange.setFile_length(split.length());hdfsScanRange.setLength(split.length());// for distributed schedulerhdfsScanRange.setFull_path(split.path());hdfsScanRange.setOffset(0);TScanRange scanRange = new TScanRange();scanRange.setHdfs_scan_range(hdfsScanRange);scanRangeLocations.setScan_range(scanRange);TScanRangeLocation scanRangeLocation = new TScanRangeLocation(new TNetworkAddress("-1", -1));scanRangeLocations.addToLocations(scanRangeLocation);result.add(scanRangeLocations);
}5. Iceberg元数据读取
https://github.com/StarRocks/starrocks/pull/44632
核心类:IcebergMetadataScanner,这个应该是Iceberg元数据的实际读取类,实现自StarRocks的ConnectorScanner
ConnectorScanner是StarRocks的设计的介于C++-based的BE和Java-based的大数据组件之间的JNI抽象中间层,可以直接复用Java SDK,规避了对BE代码的侵入以及使用C++访问大数据存储的诸多不便
这一块属于时实际元数据文件读取的Java侧代码
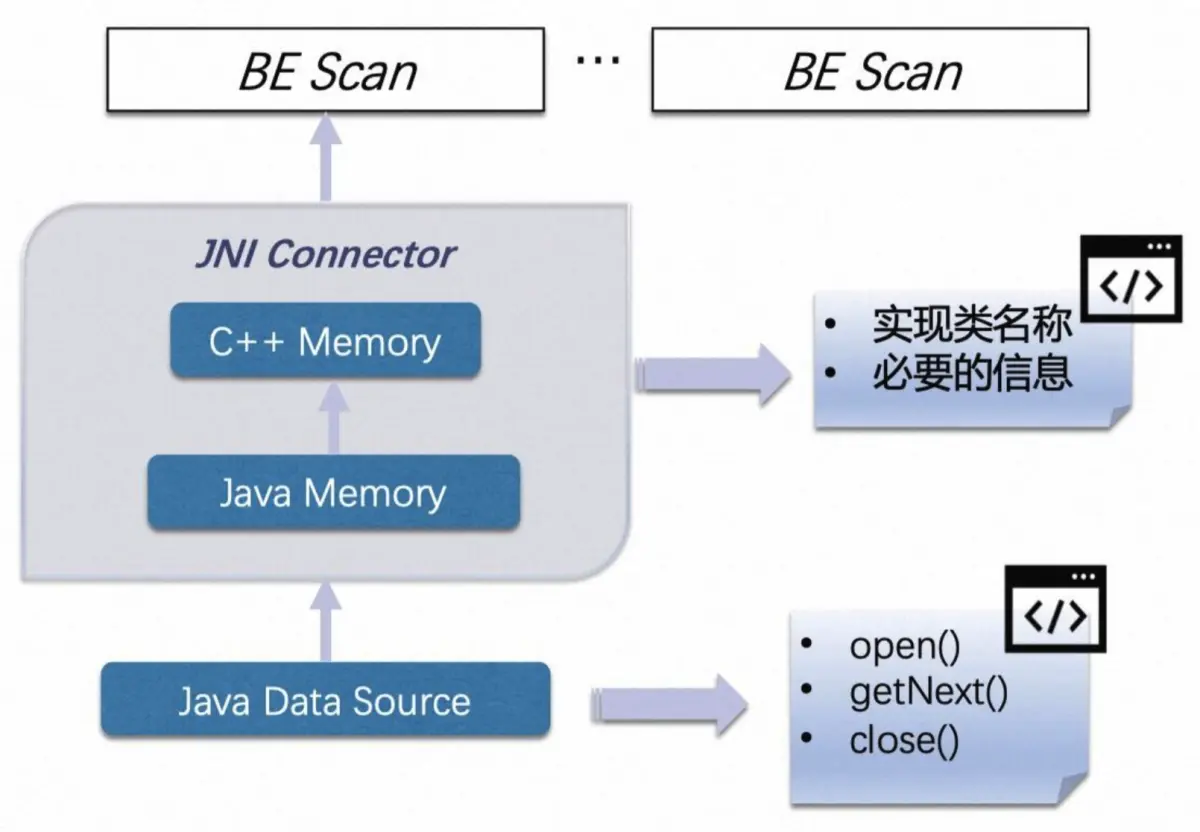
public int getNext() throws IOException {try (ThreadContextClassLoader ignored = new ThreadContextClassLoader(classLoader)) {int numRows = 0;for (; numRows < getTableSize(); numRows++) {if (!reader.hasNext()) {break;}ContentFile<?> file = reader.next();for (int i = 0; i < requiredFields.length; i++) {Object fieldData = get(requiredFields[i], file);if (fieldData == null) {appendData(i, null);} else {ColumnValue fieldValue = new IcebergMetadataColumnValue(fieldData);appendData(i, fieldValue);}}}return numRows;} catch (Exception e) {close();LOG.error("Failed to get the next off-heap table chunk of iceberg metadata.", e);throw new IOException("Failed to get the next off-heap table chunk of iceberg metadata.", e);}
}这一块目前没有找到Java侧的上层调用,应该在C++中调用,如下,其构造类是在C++中的
// ---------------iceberg metadata jni scanner------------------
std::unique_ptr<JniScanner> create_iceberg_metadata_jni_scanner(const JniScanner::CreateOptions& options) {const auto& scan_range = *(options.scan_range);;const auto* hdfs_table = dynamic_cast<const IcebergMetadataTableDescriptor*>(options.hive_table);std::map<std::string, std::string> jni_scanner_params;jni_scanner_params["required_fields"] = hdfs_table->get_hive_column_names();jni_scanner_params["metadata_column_types"] = hdfs_table->get_hive_column_types();jni_scanner_params["serialized_predicate"] = options.scan_node->serialized_predicate;jni_scanner_params["serialized_table"] = options.scan_node->serialized_table;jni_scanner_params["split_info"] = scan_range.serialized_split;jni_scanner_params["load_column_stats"] = options.scan_node->load_column_stats ? "true" : "false";const std::string scanner_factory_class = "com/starrocks/connector/iceberg/IcebergMetadataScannerFactory";return std::make_unique<JniScanner>(scanner_factory_class, jni_scanner_params);
}6. 元数据收集任务
https://github.com/StarRocks/starrocks/pull/44679/files
核心类:IcebergMetadataCollectJob,Iceberg元数据的收集类,实现自MetadataCollectJob,目前看就是通过执行SQL语句,从前文的LogicalIcebergMetadataTable表当中获取数据
这一块属于最终的元数据收集
private static final String ICEBERG_METADATA_TEMPLATE = "SELECT content" + // INTEGER", file_path" + // VARCHAR", file_format" + // VARCHAR", spec_id" + // INTEGER", partition_data" + // BINARY", record_count" + // BIGINT", file_size_in_bytes" + // BIGINT", split_offsets" + // ARRAY<BIGINT>", sort_id" + // INTEGER", equality_ids" + // ARRAY<INTEGER>", file_sequence_number" + // BIGINT", data_sequence_number " + // BIGINT", column_stats " + // BINARY", key_metadata " + // BINARY"FROM `$catalogName`.`$dbName`.`$tableName$logical_iceberg_metadata` " +"FOR VERSION AS OF $snapshotId " +"WHERE $predicate'";7. 流程梳理
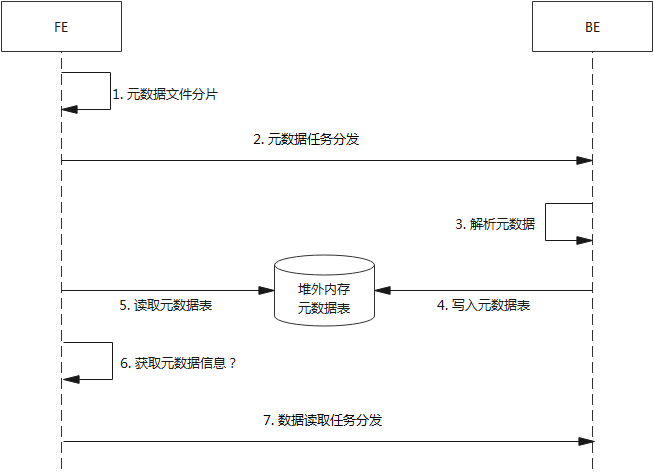
1. IcebergMetadataCollectJob的调用
IcebergMetadataCollectJob -> StarRocksIcebergTableScan.planFileTasksRemotely -> StarRocksIcebergTableScan.doPlanFiles -> 由Iceberg定义的TableScan流程触发
2. StarRocksIcebergTableScan的构建
StarRocksIcebergTableScan -> IcebergCatalog.getTableScan -> IcebergMetadata.collectTableStatisticsAndCacheIcebergSplit -> prepareMetadata()和triggerIcebergPlanFilesIfNeeded()
prepareMetadata()线路由PrepareCollectMetaTask任务触发,其执行逻辑中调用了prepareMetadata()接口。PrepareCollectMetaTask是OptimizerTask的子类,属于StarRocks优化器的一环,在Optimizer类执行优化的时候会。这一块属于CBO优化,默认是false,没找到设置成true的地方,目前应该没有启用
triggerIcebergPlanFilesIfNeeded()路线有几个调用的地方,主路线应该是getRemoteFileInfos(),其他两个看内容属于统计信息之类的信息收集
IcebergMetadata.getRemoteFileInfos -> IcebergScanNode.setupScanRangeLocations -> PlanFragmentBuilder.visitPhysicalIcebergScan -> PhysicalIcebergScanOperator
这一条调用链最终源头到PhysicalIcebergScanOperator,这个应当是IcebergScanNode经过SQL计划转换后的实际执行节点类
3. 元数据扫描
IcebergMetaSpec -> IcebergMetadata.getSerializedMetaSpec -> MetadataMgr.getSerializedMetaSpec -> IcebergMetadataScanNode.setupScanRangeLocations -> PlanFragmentBuilder.visitPhysicalIcebergMetadataScan -> PhysicalIcebergMetadataScanOperator
元数据扫描这一块源头最终走到PhysicalIcebergMetadataScanOperator,也就是IcebergMetadataScanNode对应的执行类
4. 元数据扫描和数据扫描的逻辑关系
目前整体流程在最上层就差PhysicalIcebergMetadataScanOperator和PhysicalIcebergScanOperator的逻辑关系,这个逻辑在StarRocks的SQL到执行计划的转换过程当中
往上追踪到BackendSelectorFactory,注意这里有两个扫描节点的分配策略:LocalFragmentAssignmentStrategy、RemoteFragmentAssignmentStrategy。根据类的说明,最左节点为scanNode的时候,使用LocalFragmentAssignmentStrategy,它首先将扫描范围分配给 worker,然后将分配给每个 worker 的扫描范围分派给片段实例
在LocalFragmentAssignmentStrategy的assignFragmentToWorker当中可以看到入参包含很多scanNode,追踪上层到CoordinatorPreprocessor,scanNode的来源是StarRocks的DAG图。这之后的源头就涉及到任务解析和DAG图的顺序构建,应当是先扫描元数据再扫描数据这样构建
for (ExecutionFragment execFragment : executionDAG.getFragmentsInPostorder()) {fragmentAssignmentStrategyFactory.create(execFragment, workerProvider).assignFragmentToWorker(execFragment);
}8. 代码解析
1. 元数据扫描
-
LogicalIcebergMetadataTable
首先从PhysicalIcebergMetadataScanOperator出发,访问者模式调用接口accept,走到PlanFragmentBuilder.visitPhysicalIcebergMetadataScan
这里首先跟LogicalIcebergMetadataTable关联了起来,这里PhysicalIcebergMetadataScanOperator里包含的表是LogicalIcebergMetadataTable表
LogicalIcebergMetadataTable的初始创建根据调用链追踪应当由CatalogMgr.createCatalog触发
PhysicalIcebergMetadataScanOperator node = (PhysicalIcebergMetadataScanOperator) optExpression.getOp();LogicalIcebergMetadataTable table = (LogicalIcebergMetadataTable) node.getTable();-
IcebergMetadataScanNode
中间经历一些列的设置,之后构建了IcebergMetadataScanNode
IcebergMetadataScanNode metadataScanNode =new IcebergMetadataScanNode(context.getNextNodeId(), tupleDescriptor,"IcebergMetadataScanNode", node.getTemporalClause());构建之后调用了setupScanRangeLocations,走到了IcebergMetadataScanNode的类逻辑,首先获取元数据文件的分片信息
IcebergMetaSpec serializedMetaSpec = GlobalStateMgr.getCurrentState().getMetadataMgr().getSerializedMetaSpec(catalogName, originDbName, originTableName, snapshotId, icebergPredicate).cast();-
IcebergMetadata
这段逻辑跟IcebergMetadata关联了起来,调用其getSerializedMetaSpec接口,接口中就是获取Iceberg的元数据文件,中间经历了一定的过滤
List<ManifestFile> dataManifests = snapshot.dataManifests(nativeTable.io());List<ManifestFile> matchingDataManifests = filterManifests(dataManifests, nativeTable, predicate);
for (ManifestFile file : matchingDataManifests) {remoteMetaSplits.add(IcebergMetaSplit.from(file));
}获取分片之后就是按StarRocks的扫描结构组装TScanRangeLocations,最终在实际执行时分布式分配解析
private void addSplitScanRangeLocations(RemoteMetaSplit split) {TScanRangeLocations scanRangeLocations = new TScanRangeLocations();THdfsScanRange hdfsScanRange = new THdfsScanRange();hdfsScanRange.setUse_iceberg_jni_metadata_reader(true);hdfsScanRange.setSerialized_split(split.getSerializeSplit());hdfsScanRange.setFile_length(split.length());hdfsScanRange.setLength(split.length());// for distributed schedulerhdfsScanRange.setFull_path(split.path());hdfsScanRange.setOffset(0);TScanRange scanRange = new TScanRange();scanRange.setHdfs_scan_range(hdfsScanRange);scanRangeLocations.setScan_range(scanRange);TScanRangeLocation scanRangeLocation = new TScanRangeLocation(new TNetworkAddress("-1", -1));scanRangeLocations.addToLocations(scanRangeLocation);result.add(scanRangeLocations);
}-
PlanFragment
visitPhysicalIcebergMetadataScan接口最终组装的是一个PlanFragment,这大体类似于Spark的stage,是物理执行计划的计划块
PlanFragment fragment =new PlanFragment(context.getNextFragmentId(), metadataScanNode, DataPartition.RANDOM);
context.getFragments().add(fragment);
return fragment-
IcebergMetadataScanner
IcebergMetadataScanner由于其调用逻辑来自于C++的代码,暂未梳理其逻辑,但是假定其执行了,可以看其效果,主要在getNext()接口中读取数据
可以看到其读取后的数据结构是ContentFile,是Iceberg中DataFile的上层父类
ContentFile<?> file = reader.next();
for (int i = 0; i < requiredFields.length; i++) {Object fieldData = get(requiredFields[i], file);if (fieldData == null) {appendData(i, null);} else {ColumnValue fieldValue = new IcebergMetadataColumnValue(fieldData);appendData(i, fieldValue);}
}主要在appendData接口当中,向表添加数据,可以看到这里设置了一个offHeapTable
offHeapTable是 StarRocks 中的一个特殊表类型,简单来说就是在堆外内存中建立一个表结构,将数据对应存储到堆外内存,之后可以以表形式去访问
protected void appendData(int index, ColumnValue value) {offHeapTable.appendData(index, value);
}2. 数据扫描中的元数据解析
首先同样到PlanFragmentBuilder.visitPhysicalIcebergScan,流程与visitPhysicalIcebergMetadataScan类似
首先是这里的表是数据表
Table referenceTable = node.getTable();
context.getDescTbl().addReferencedTable(referenceTable);
TupleDescriptor tupleDescriptor = context.getDescTbl().createTupleDescriptor();
tupleDescriptor.setTable(referenceTable);// set slot
prepareContextSlots(node, context, tupleDescriptor);之后是IcebergScanNode
IcebergScanNode icebergScanNode =new IcebergScanNode(context.getNextNodeId(), tupleDescriptor, "IcebergScanNode",equalityDeleteTupleDesc);IcebergScanNode这里核心是调用setupScanRangeLocations
icebergScanNode.setupScanRangeLocations(context.getDescTbl());最终同样封装成PlanFragment
PlanFragment fragment =new PlanFragment(context.getNextFragmentId(), icebergScanNode, DataPartition.RANDOM);
context.getFragments().add(fragment);
return fragment;-
IcebergScanNode
在setupScanRangeLocations当中,有一个操作是getRemoteFileInfos,这个就是获取数据文件信息,因此内部包含了元数据解析的部分
List<RemoteFileInfo> splits = GlobalStateMgr.getCurrentState().getMetadataMgr().getRemoteFileInfos(catalogName, icebergTable, null, snapshotId, predicate, null, -1);-
IcebergMetadata
getRemoteFileInfos是在IcebergMetadata当中,会调用triggerIcebergPlanFilesIfNeeded,看接口名字可以明确这是用来触发Iceberg的元数据解析的,最终走到了collectTableStatisticsAndCacheIcebergSplit
private void triggerIcebergPlanFilesIfNeeded(IcebergFilter key, IcebergTable table, ScalarOperator predicate,long limit, Tracers tracers, ConnectContext connectContext) {if (!scannedTables.contains(key)) {tracers = tracers == null ? Tracers.get() : tracers;try (Timer ignored = Tracers.watchScope(tracers, EXTERNAL, "ICEBERG.processSplit." + key)) {collectTableStatisticsAndCacheIcebergSplit(table, predicate, limit, tracers, connectContext);}}
}collectTableStatisticsAndCacheIcebergSplit当中获取了TableScan,这里的Scan就是StarRocksIcebergTableScan
TableScan scan = icebergCatalog.getTableScan(nativeTbl, new StarRocksIcebergTableScanContext(catalogName, dbName, tableName, planMode(connectContext), connectContext)).useSnapshot(snapshotId).metricsReporter(metricsReporter).planWith(jobPlanningExecutor);-
StarRocksIcebergTableScan
之后走scan.planFiles(),这个中间会基于Iceberg的逻辑进行调用
CloseableIterable<FileScanTask> fileScanTaskIterable = TableScanUtil.splitFiles(scan.planFiles(), scan.targetSplitSize());Icberg的逻辑中planFiles最终会调用TableScan的doPlanFiles,这里调用的就是StarRocksIcebergTableScan的实现接口,根据场景有本地和远程的调用方式
if (shouldPlanLocally(dataManifests, loadColumnStats)) {return planFileTasksLocally(dataManifests, deleteManifests);
} else {return planFileTasksRemotely(dataManifests, deleteManifests);
}Iceberg应当是使用的planFileTasksRemotely,内部会构建IcebergMetadataCollectJob
MetadataCollectJob metadataCollectJob = new IcebergMetadataCollectJob(catalogName, dbName, tableName, TResultSinkType.METADATA_ICEBERG, snapshotId(), icebergSerializedPredicate);metadataCollectJob.init(connectContext.getSessionVariable());long currentTimestamp = System.currentTimeMillis();
String threadNamePrefix = String.format("%s-%s-%s-%d", catalogName, dbName, tableName, currentTimestamp);
executeInNewThread(threadNamePrefix + "-fetch_result", metadataCollectJob::asyncCollectMetadata);-
MetadataExecutor执行
IcebergMetadataCollectJob的执行在MetadataExecutor当中,就是基本的SQL执行,这里是异步的
public void asyncExecuteSQL(MetadataCollectJob job) {ConnectContext context = job.getContext();context.setThreadLocalInfo();String sql = job.getSql();ExecPlan execPlan;StatementBase parsedStmt;try {parsedStmt = SqlParser.parseOneWithStarRocksDialect(sql, context.getSessionVariable());execPlan = StatementPlanner.plan(parsedStmt, context, job.getSinkType());} catch (Exception e) {context.getState().setError(e.getMessage());return;}this.executor = new StmtExecutor(context, parsedStmt);context.setExecutor(executor);context.setQueryId(UUIDUtil.genUUID());context.getSessionVariable().setEnableMaterializedViewRewrite(false);LOG.info("Start to execute metadata collect job on {}.{}.{}", job.getCatalogName(), job.getDbName(), job.getTableName());executor.executeStmtWithResultQueue(context, execPlan, job.getResultQueue());
}相关文章:
StarRocks分布式元数据源码解析
1. 支持元数据表 https://github.com/StarRocks/starrocks/pull/44276/files 核心类:LogicalIcebergMetadataTable,Iceberg元数据表,将元数据的各个字段做成表的列,后期可以通过sql操作从元数据获取字段,这个表的组成…...

阅读笔记——《Fuzz4All: Universal Fuzzing with Large Language Models》
【参考文献】Xia C S, Paltenghi M, Le Tian J, et al. Fuzz4all: Universal fuzzing with large language models[C]//Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 2024: 1-13.【注】本文仅为作者个人学习笔记,如有冒犯&…...

【C++】使用gtest做单元测试框架写单元测试
本文主要介绍在将gtest框架引入到项目里过程中遇到的问题。 我的需求如下: 用CMake构建项目。我要写一些测试程序验证某些功能,但是不想每一个测试都新建一个main函数。 因为新建一个main函数就要在CMakeList.txt里增加一个project,非常不方便。 于是我搜了下,C++里有没…...

Java类与对象
类是对现实世界中实体的抽象,是对一类事物的描述。 类的属性位置在类的内部、方法的外部。 类的属性描述一个类的一些可描述的特性,比如人的姓名、年龄、性别等。 [public] [abstract|final] class 类名 [extends父类] [implements接口列表] { 属性声…...

xlwings 链接到 指定sheet 从别的 excel 复制 sheet 到指定 sheet
重点 可以参考 宏录制 cell sheet.range(G4)cell.api.Hyperlinks.Add(Anchorcell.api, Address"", SubAddress"001-000-02301!A1")def deal_excel(self):with xw.App(visibleTrue) as app:wb app.books.open(self.summary_path, update_linksFalse)sheet…...

风光摄影:相机设置和镜头选择
写在前面 博文内容为《斯科特凯尔比的风光摄影手册》读书笔记整理涉及在风景拍摄中一些相机设置,镜头选择的建议对小白来讲很实用,避免拍摄一些过曝或者过暗的风景照片理解不足小伙伴帮忙指正 😃,生活加油 99%的焦虑都来自于虚度时间和没有好…...
python制作甘特图的基本知识(附Demo)
目录 前言1. matplotlib2. plotly 前言 甘特图是一种常见的项目管理工具,用于表示项目任务的时间进度 直观地看到项目的各个任务在时间上的分布和进度 常用的绘制甘特图的工具是 matplotlib 和 plotly 主要以Demo的形式展示 1. matplotlib 功能强大的绘图库&a…...

javascript设计模式总结
参考 通过设计模式可以增加代码的可重用性、可扩展性、可维护性 设计模式五大设计原则 单一职责:一个程序只需要做好一件事,如果结构过于复杂就拆分开,保证每个部分独立 开放封闭原则:对扩展开放,对修改封闭。增加需…...

gpt-4o看图说话-根据图片回答问题
问题:中国的人口老龄化究竟有多严重? 代码下实现如下:(直接调用openai的chat接口) import os import base64 import requests def encode_image(image_path): """ 对图片文件进行 Base64 编码 输入…...

【MySQL】7.MySQL 的内置函数
MySQL的内置函数 一.日期函数二.字符串函数三.数学函数四.其它函数 一.日期函数 函数名称说明current_date()当前日期current_time()当前时间current_timestamp当前时间戳(日期时间)date(datetime)截取 datetime 的日期部分date_add(date, interval d_value_type)给 date 添加…...

爬虫:Sentry-Span参数逆向
在抓某眼查数据太过频繁时会出现极验的验证码。极验的教程有很多,主要是发现在这里获取验证码的时候需要携带参数Sentry-Span。在这里记录一下逆向的主要过程,直接上补环境的代码。 window global; location {}; my_log console.log;(function () {l…...
——FFmpeg源码中通过SPS属性计算视频分辨率的实现)
音视频入门基础:H.264专题(12)——FFmpeg源码中通过SPS属性计算视频分辨率的实现
一、引言 在上一节《音视频入门基础:H.264专题(11)——计算视频分辨率的公式》中,讲述了通过SPS中的属性计算H.264编码的视频的分辨率的公式。本文讲解FFmpeg源码中计算视频分辨率的实现。 二、FFmpeg源码中计算视频分辨率的实现…...

基于颜色模型和边缘检测的火焰识别FPGA实现,包含testbench和matlab验证程序
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) 将FPGA仿真结果导入到matlab显示结果: 测试样本1 测试样本2 测试样本3 2.算法运行软件版本 vivado2019.2 …...

golang json反序列化科学计数法的坑
问题背景 func CheckSign(c *gin.Context, signKey string, singExpire int) (string, error) {r : c.Requestvar formParams map[string]interface{}if c.Request.Body ! nil {bodyBytes, _ : io.ReadAll(c.Request.Body)defer c.Request.Body.Close()if len(bodyBytes) >…...

罗技K380无线键盘及鼠标:智慧互联,一触即通
目录 1. 背景2. K380无线键盘连接电脑2.1 键盘准备工作2.2 电脑配置键盘的连接 3. 无线鼠标的连接3.1 鼠标准备工作3.2 电脑配置鼠标的连接 1. 背景 有一阵子经常使用 ipad,但是对于我这个习惯于键盘打字的人来说,慢慢在 ipad 上打字,实在是…...
卸载wps office的几种方法收录
第一种方法: 1.打开【任务管理器】,找到相关程序,点击【结束任务】。任务管理器可以通过左下角搜索找到。 2.点击【开始】-【设置】-【应用】-下拉找到WPS应用,右键卸载,不保留软件配置 …...

SpringCloud第一篇Docker基础
文章目录 一、常见命令二、数据卷三、数据挂载四、自定义镜像五、网络 一、常见命令 Docker最常见的命令就是操作镜像、容器的命令,详见官方文档: https://docs.docker.com/ 需求: 在DockerHub中搜索Nginx镜像,查看镜像的名称 …...

从零开始学习PX4源码3(如何上传官网源码到自己的仓库中)
目录 文章目录 目录摘要1.将PX4源码上传至腾讯工蜂2.从腾讯工蜂克隆源码到本地ubuntu3.如何查看自己源码的版本信息 摘要 本节主要记录从零开始学习PX4源码3(如何上传官网源码到自己的仓库中)及如何查看PX4的固件版本信息,欢迎批评指正! PX4源码版本V1.…...

Docker Compose 启动容器例子
Docker Compose 启动容器例子 Docker Compose 文件 (docker-compose.yml) version: 3.8services:web:image: nginx:latestports:- "8080:80"volumes:- ./html:/usr/share/nginx/htmlnetworks:- webnetdb:image: mysql:latestenvironment:MYSQL_ROOT_PASSWORD: exam…...

守护服务之门:Eureka中分布式认证与授权的实现策略
守护服务之门:Eureka中分布式认证与授权的实现策略 引言 在微服务架构中,服务间的通信安全至关重要。Eureka作为Netflix开源的服务发现框架,虽然本身提供了服务注册与发现的功能,但并不直接提供认证与授权机制。为了实现服务的分…...

观察Taotoken用量看板如何帮助控制月度API支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken用量看板如何帮助控制月度API支出 在项目开发中,大模型API的调用成本往往是预算管理的重要一环。如果缺乏…...
)
从零开始:用严恭敏老师的PSINS工具箱搞定SINS/GPS组合导航(附完整代码流程)
从零开始:用严恭敏老师的PSINS工具箱实现SINS/GPS组合导航实战指南 1. 初识PSINS工具箱:导航算法开发的瑞士军刀 在惯性导航与组合导航领域,严恭敏教授团队开发的PSINS(Precise Strapdown Inertial Navigation System࿰…...

告别传统测深方式,超声波测深仪优势大盘点
在水文勘测、河道治理、库区运维、水域环境监测工作中,水深测量是最基础也最关键的作业环节。以往很多工作人员依赖测深杆、测深锤等传统工具测深,不仅操作繁琐、作业效率低,人工读数还容易产生误差,遇到流动水域、深水区域更是作…...

【独家首发】ElevenLabs未公开的粤语语音增强技巧:3个隐藏prompt指令+2个音频后处理脚本
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs广东话语音合成的技术边界与本地化挑战 ElevenLabs 作为全球领先的语音合成平台,其多语言支持能力广受关注,但粤语(广东话)尚未被官方列为正式…...

在Taotoken模型广场根据任务需求与预算快速选型实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务需求与预算快速选型实践 面对众多大模型,如何为自己的项目选择一个既满足需求又符合预算的…...

3分钟快速上手:Buzz音频转录软件完整使用指南
3分钟快速上手:Buzz音频转录软件完整使用指南 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Trending/buz/buzz 还在为音频转录烦恼…...

DS4Windows终极指南:如何免费解决手柄漂移并优化游戏操控精度
DS4Windows终极指南:如何免费解决手柄漂移并优化游戏操控精度 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否遇到过手柄摇杆自动漂移、瞄准时准星抖动、按键响应延迟等…...

告别繁琐点击:3大功能助你实现智能文档获取与自动化下载
告别繁琐点击:3大功能助你实现智能文档获取与自动化下载 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了…...

Co-IP/MS:蛋白免疫共沉淀质谱分析服务
免疫共沉淀质谱法(Co-IP/MS)是一种由免疫共沉淀技术联用质谱技术的蛋白互作研究技术,具备高分辨率鉴定和精确定量蛋白质复合物中每个组分的优势。Co-IP/MS使用靶向目标蛋白的特异性抗体,选择性地捕获目标蛋白质与其相互作用的分子…...

Win11Debloat终极指南:快速清理Windows系统臃肿的完整教程
Win11Debloat终极指南:快速清理Windows系统臃肿的完整教程 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...