Python酷库之旅-第三方库Pandas(021)
目录
一、用法精讲
52、pandas.from_dummies函数
52-1、语法
52-2、参数
52-3、功能
52-4、返回值
52-5、说明
52-6、用法
52-6-1、数据准备
52-6-2、代码示例
52-6-3、结果输出
53、pandas.factorize函数
53-1、语法
53-2、参数
53-3、功能
53-4、返回值
53-5、说明
53-6、用法
53-6-1、数据准备
53-6-2、代码示例
53-6-3、结果输出
54、pandas.unique函数
54-1、语法
54-2、参数
54-3、功能
54-4、返回值
54-5、说明
54-6、用法
54-6-1、数据准备
54-6-2、代码示例
54-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
52、pandas.from_dummies函数
52-1、语法
# 52、pandas.from_dummies函数
pandas.from_dummies(data, sep=None, default_category=None)
Create a categorical DataFrame from a DataFrame of dummy variables.Inverts the operation performed by get_dummies().New in version 1.5.0.Parameters:
data
DataFrame
Data which contains dummy-coded variables in form of integer columns of 1’s and 0’s.sep
str, default None
Separator used in the column names of the dummy categories they are character indicating the separation of the categorical names from the prefixes. For example, if your column names are ‘prefix_A’ and ‘prefix_B’, you can strip the underscore by specifying sep=’_’.default_category
None, Hashable or dict of Hashables, default None
The default category is the implied category when a value has none of the listed categories specified with a one, i.e. if all dummies in a row are zero. Can be a single value for all variables or a dict directly mapping the default categories to a prefix of a variable.Returns:
DataFrame
Categorical data decoded from the dummy input-data.Raises:
ValueError
When the input DataFrame data contains NA values.When the input DataFrame data contains column names with separators that do not match the separator specified with sep.When a dict passed to default_category does not include an implied category for each prefix.When a value in data has more than one category assigned to it.When default_category=None and a value in data has no category assigned to it.TypeError
When the input data is not of type DataFrame.When the input DataFrame data contains non-dummy data.When the passed sep is of a wrong data type.When the passed default_category is of a wrong data type.52-2、参数
52-2-1、data(必须):一个DataFrame对象,包含了哑变量(0和1)的列,每列通常表示一个类别的存在或缺失。
52-2-2、sep(可选,默认值为None):用于分隔哑变量列名中类别信息的分隔符。例如,如果列名是A_cat和A_dog,并且用下划线分隔,那么sep应该设置为 _。
52-2-3、default_category(可选,默认值为None):在原始数据中,可能有一些类别在哑变量中缺失,这个参数允许指定一个默认类别,以便在缺失的情况下使用。
52-3、功能
接受一个包含哑变量的DataFrame,并将其转换回表示原始类别的DataFrame,哑变量通常是通过对分类变量进行独热编码(one-hot encoding)生成的。
52-4、返回值
返回值是一个DataFrame,其中包含了原始的分类数据,这些数据是根据哑变量的值重构的,即每行数据中值为1的哑变量列对应的列名(去掉分隔符和前缀)即为原始分类变量的值。
52-5、说明
该函数非常有用,特别是在对数据进行独热编码之后希望恢复原始分类变量的情况下,它简化了数据预处理和模型结果解释的过程。
52-6、用法
52-6-1、数据准备
无52-6-2、代码示例
# 52、pandas.from_dummies函数
import pandas as pd
# 示例哑变量DataFrame
data = pd.DataFrame({'color_red': [1, 0, 0],'color_blue': [0, 1, 0],'color_green': [0, 0, 1]
})
# 使用pandas.from_dummies将哑变量转换回原始分类数据
original_data = pd.from_dummies(data, sep='_')
print(original_data)52-6-3、结果输出
# 52、pandas.from_dummies函数
# color
# 0 red
# 1 blue
# 2 green53、pandas.factorize函数
53-1、语法
# 53、pandas.factorize函数
pandas.factorize(values, sort=False, use_na_sentinel=True, size_hint=None)
Encode the object as an enumerated type or categorical variable.This method is useful for obtaining a numeric representation of an array when all that matters is identifying distinct values. factorize is available as both a top-level function pandas.factorize(), and as a method Series.factorize() and Index.factorize().Parameters:
valuessequence
A 1-D sequence. Sequences that aren’t pandas objects are coerced to ndarrays before factorization.sortbool, default False
Sort uniques and shuffle codes to maintain the relationship.use_na_sentinelbool, default True
If True, the sentinel -1 will be used for NaN values. If False, NaN values will be encoded as non-negative integers and will not drop the NaN from the uniques of the values.New in version 1.5.0.size_hintint, optional
Hint to the hashtable sizer.Returns:
codesndarray
An integer ndarray that’s an indexer into uniques. uniques.take(codes) will have the same values as values.uniquesndarray, Index, or Categorical
The unique valid values. When values is Categorical, uniques is a Categorical. When values is some other pandas object, an Index is returned. Otherwise, a 1-D ndarray is returned.NoteEven if there’s a missing value in values, uniques will not contain an entry for it.53-2、参数
53-2-1、values(必须):需要编码的数组或序列,可以是列表、NumPy数组、Pandas系列等。
53-2-2、sort(可选,默认值为False):是否对唯一值数组进行排序,如果为True,返回的唯一值数组将按字典顺序排序。
53-2-3、use_na_sentinel(可选,默认值为True):是否在输出整数数组中使用-1作为NaN的标记,如果为False,则将NaN也编码为一个唯一的整数。
53-2-4、size_hint(可选,默认值为None):一个整数提示,用于内部优化,指示预期的唯一值的数量,这可以提高大规模数据的处理性能。
53-3、功能
将一组值(如列表、数组或序列)编码为整数索引。具体来说,它会为每个唯一值分配一个唯一的整数,并返回这些整数索引以及唯一值的数组。
53-4、返回值
返回两个对象:
53-4-1、整数索引数组:一个与输入数组大小相同的整数数组,其中每个整数对应于输入数组中的一个值。
53-4-2、唯一值数组:一个包含输入数组中所有唯一值的数组,按它们首次出现的顺序排列,除非使用sort=True参数。
53-5、说明
pandas.factorize的主要功能是:
53-5-1、将类别数据转换为整数索引:通过为每个唯一值分配一个整数,使得类别数据可以用于数值计算或进一步分析。
53-5-2、处理缺失值:可以选择是否将缺失值(NaN)编码为一个特定的整数(默认为-1)。
53-6、用法
53-6-1、数据准备
无53-6-2、代码示例
# 53、pandas.factorize函数
# 53-1、基本用法
import pandas as pd
values = ['a', 'b', 'a', 'c', 'b']
factorized_values, unique_values = pd.factorize(values)
print(factorized_values)
print(unique_values)# 53-2、使用sort参数
import pandas as pd
values = ['a', 'b', 'a', 'c', 'b']
factorized_values, unique_values = pd.factorize(values, sort=True)
print(factorized_values)
print(unique_values)# 53-3、处理NaN
import pandas as pd
values_with_nan = ['a', 'b', None, 'a', 'c']
factorized_values, unique_values = pd.factorize(values_with_nan, use_na_sentinel=True)
print(factorized_values)
print(unique_values)# 53-4、使用size_hint参数
import pandas as pd
large_values = ['a'] * 100000 + ['b'] * 100000
factorized_values, unique_values = pd.factorize(large_values, size_hint=2)
print(factorized_values[:10])
print(unique_values)53-6-3、结果输出
# 53、pandas.factorize函数
# 53-1、基本用法
# [0 1 0 2 1]
# ['a' 'b' 'c']# 53-2、使用sort参数
# [0 1 0 2 1]
# ['a' 'b' 'c']# 53-3、处理NaN
# [ 0 1 -1 0 2]
# ['a' 'b' 'c']# 53-4、使用size_hint参数
# [0 0 0 0 0 0 0 0 0 0]
# ['a' 'b']54、pandas.unique函数
54-1、语法
# 54、pandas.unique函数
pandas.unique(values)
Return unique values based on a hash table.Uniques are returned in order of appearance. This does NOT sort.Significantly faster than numpy.unique for long enough sequences. Includes NA values.Parameters:
values
1d array-like
Returns:
numpy.ndarray or ExtensionArray
The return can be:Index : when the input is an IndexCategorical : when the input is a Categorical dtypendarray : when the input is a Series/ndarrayReturn numpy.ndarray or ExtensionArray.54-2、参数
54-2-1、values(必须):可以是以下几种类型的对象:
- 一维的pandas.Series
- 一维的pandas.Index
- 一维的numpy.ndarray
- 一维的列表或序列
54-3、功能
返回输入数组中的唯一值,按它们在数组中首次出现的顺序排列。
54-4、返回值
返回一个numpy.ndarray,其中包含输入数组中的唯一值。
54-5、说明
pandas.unique是一个简单且高效的函数,用于从一维数组、Series或Index中提取唯一值,它只需要一个参数,即要处理的数组,并返回一个包含唯一值的numpy.ndarray,这种功能在数据预处理和清理阶段非常有用,可以帮助识别数据集中的独特元素。
54-6、用法
54-6-1、数据准备
无54-6-2、代码示例
# 54、pandas.unique函数
# 54-1、处理列表
import pandas as pd
values = [1, 2, 2, 3, 4, 4, 4, 5]
unique_values = pd.unique(values)
print(unique_values)# 54-2、处理pandas Series
import pandas as pd
series = pd.Series(['a', 'b', 'a', 'c', 'b', 'd'])
unique_values = pd.unique(series)
print(unique_values)# 54-3、处理numpy数组
import pandas as pd
import numpy as np
array = np.array([1, 2, 3, 1, 2, 3, 4])
unique_values = pd.unique(array)
print(unique_values)# 54-4、处理含有NaN的数据
import pandas as pd
values_with_nan = [1, 2, np.nan, 2, np.nan, 3]
unique_values = pd.unique(values_with_nan)
print(unique_values)54-6-3、结果输出
# 54、pandas.unique函数
# 54-1、处理列表
# [1 2 3 4 5]# 54-2、处理pandas Series
# ['a' 'b' 'c' 'd']# 54-3、处理numpy数组
# [1 2 3 4]# 54-4、处理含有NaN的数据
# [ 1. 2. nan 3.]二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
相关文章:
Python酷库之旅-第三方库Pandas(021)
目录 一、用法精讲 52、pandas.from_dummies函数 52-1、语法 52-2、参数 52-3、功能 52-4、返回值 52-5、说明 52-6、用法 52-6-1、数据准备 52-6-2、代码示例 52-6-3、结果输出 53、pandas.factorize函数 53-1、语法 53-2、参数 53-3、功能 53-4、返回值 53-…...

jvm 06 补充 OOM 和具体工具使用
1.OOM 是什么 OOM,全称“Out Of Memory”,翻译成中文就是“内存用完了”,来源于java.lang.OutOfMemoryError。看下关于的官方说明: Thrown when the Java Virtual Machine cannot allocate an object because it is out of memor…...

使用机器学习 最近邻算法(Nearest Neighbors)进行点云分析 (scikit-learn Open3D numpy)
使用 NearestNeighbors 进行点云分析 在数据分析和机器学习领域,最近邻算法(Nearest Neighbors)是一种常用的非参数方法。它广泛应用于分类、回归和聚类分析等任务。下面将介绍如何使用 scikit-learn 库中的 NearestNeighbors 类来进行点云数…...

安装jenkins最新版本初始化配置及使用JDK1.8构建项目详细讲解
导读 1.安装1.1.相关网址1.2.准备环境1.3.下载安装 2. 配置jenkins2.1.安装插件2.2.配置全局工具2.3.系统配置 3. 使用3.1.配置job3.2.构建 提示:如果只想看如何使用jdk1.8构建项目,直接看3.1即可。 1.安装 1.1.相关网址 Jenkins官网:https…...

微软子公司Xandr遭隐私诉讼,或面临巨额罚款
近日,欧洲隐私权倡导组织noyb对微软子公司Xandr提起了诉讼,指控其透明度不足,侵犯了欧盟公民的数据访问权。据指控,Xandr的行为涉嫌违反《通用数据保护条例》(GFPR),因其处理信息并创建用于微目…...

【VRP】基于常春藤算法IVY求解带时间窗的车辆路径问题TWVRP,最短距离附Matlab代码
% VRP - 基于IVY算法的TWVRP最短距离求解 % 数据准备 % 假设有一组客户点的坐标和对应的时间窗信息 % 假设数据已经存储在 coordinates、timeWindows 和 demands 变量中 % 参数设置 numCustomers size(coordinates, 1); % 客户点数量 vehicleCapacity 100; % 车辆容量 numV…...

常用软件的docker compose安装
简介 Docker Compose 是 Docker 的一个工具,用于定义和管理多容器 Docker 应用。通过使用一个单独的 YAML 文件,您可以定义应用所需的所有服务,然后使用一个简单的命令来启动和运行这些服务。Docker Compose 非常适合于微服务架构或任何需要…...

Excel第28享:如何新建一个Excel表格
一、背景需求 小姑电话说:要新建一个表格,并实现将几个单元格进行合并的需求。 二、解决方案 1、在电脑桌面上空白地方,点击鼠标右键,在下拉的功能框中选择“XLS工作表”或“XLSX工作表”都可以,如下图所示。 之后&…...

计算机网络知识汇总
OSI七层模型 七层模型一般指开放系统互连参考模型,开放系统互连参考模型 (Open System Interconnect 简称OSI),OSI参考模型是具有7个层次的框架,自底向上的7个层次分别是物理层、数据链路层、网络层、传输层、会话层、…...
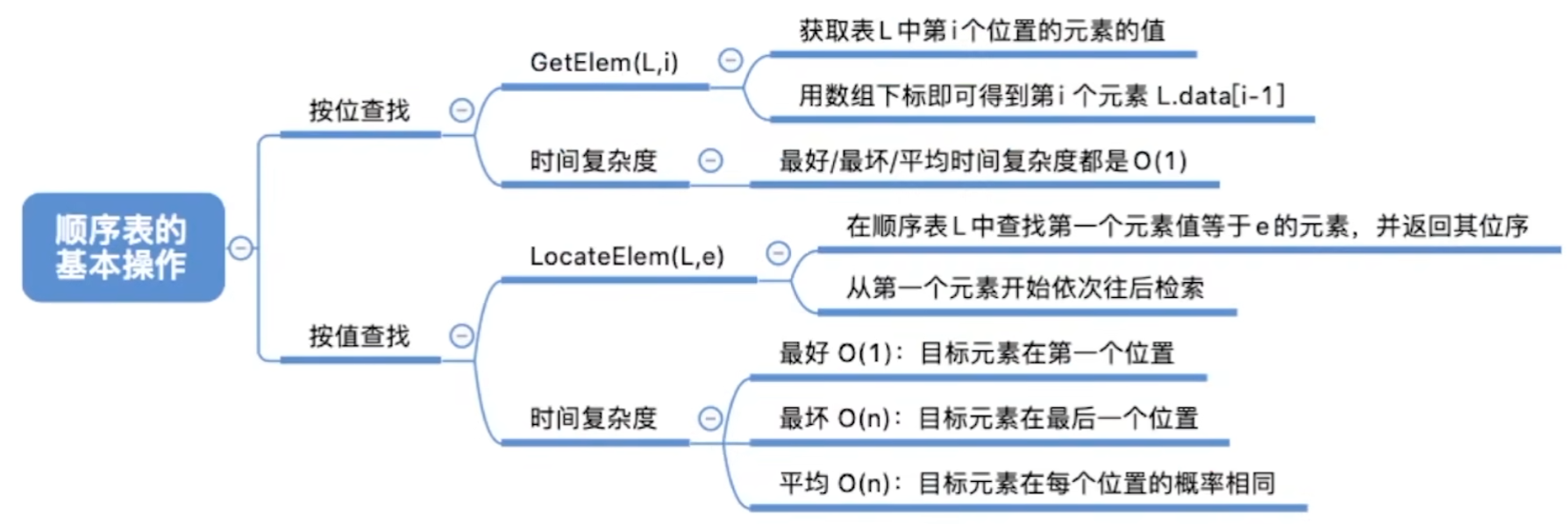
数据结构——考研笔记(二)线性表的定义和线性表之顺序表
文章目录 二、线性表2.1 定义、基本操作2.1.1 知识总览2.1.2 线性表的定义2.1.3 线性表的基本操作2.1.4 知识回顾与重要考点 2.2 顺序表2.2.1 知识总览2.2.2 顺序表的定义2.2.3 顺序表的实现——静态分配2.2.4 顺序表的实现——动态分配2.2.5 知识回顾与重要考点2.2.6 顺序表的…...

quota使用
一、检查系统是否支持 grep CONFIG_QUOTA /boot/config* CONFIG_QUOTAy CONFIG_QUOTA_NETLINK_INTERFACEy # CONFIG_QUOTA_DEBUG is not set CONFIG_QUOTA_TREEy CONFIG_QUOTACTLy CONFIG_QUOTACTL_COMPATy二、安装 yum install -y quota三、配置 3.1 创建磁盘 格式一定要 …...

解决fidder小黑怪倒出JMeter文件缺失域名、请求头
解决fidder小黑怪倒出JMeter文件缺失域名、请求头 1、目录结构: 2、代码 coding:utf-8 Software:PyCharm Time:2024/7/10 14:02 Author:Dr.zxyimport zipfile import os import xml.etree.ElementTree as ET import re#定义信息头 headers_to_extract [Host, Conn…...
智慧城市的神经网络:Transformer模型在智能城市构建中的应用
智慧城市的神经网络:Transformer模型在智能城市构建中的应用 随着城市化的快速发展,智能城市的概念应运而生,旨在通过先进的信息技术提升城市管理效率和居民生活质量。Transformer模型,作为人工智能领域的一颗新星,其…...

产品经理-研发流程-敏捷开发-迭代-需求评审及产品规划(15)
敏捷开发是以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发。 通俗来说,敏捷开发是一个软件开发流程,是一个采用了迭代方法的开发流程 简单来说,迭代就是把一个大产品拆分出一些最小的实现单位。完成不同的迭代就最…...

Ansible 安装及使用说明
方案1. 直接下载 源码包到本地后安装 ansible 下载地址:https://releases.ansible.com/ansible/ ansible社区: https://github.com/ansible/ansible 下载地址:GitHub - ansible/ansible at v2.9.0 方案2. 以腾讯的yum源说明:腾讯云文档…...

MyBatisPlus实现增删改查
文章目录 MyBatisPlus实现增删改查基本操作分页查询配置分页插件 MyBatisPlus实现增删改查 实体类GkUser package com.geekmice.springbootselfexercise.entity;import com.baomidou.mybatisplus.annotation.IdType; import com.baomidou.mybatisplus.annotation.TableField;…...

【Rust】——不安全Rust
💻博主现有专栏: C51单片机(STC89C516),c语言,c,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux…...

使机器人在执行任务时更加稳定
为了使机器人在执行任务时更加稳定,调整参数时需要考虑多个因素,如步态、速度、角度等。这些参数的调整需要基于实际环境、任务需求和机器人自身的物理特性。以下是一些具体的调整建议: 1. 调整步态和步高 gait_type3; step_height0.03;步态…...
-- libswresample使用说明及函数介绍)
FFmpeg学习(五)-- libswresample使用说明及函数介绍
libswresample Audio合成和重采样 libswresample库用来进行audio数据的合成和重采样操作。调用流程: 调用 swr_alloc 创建SwrContext结构体。设置SwrContext参数,有两种方法: 调用av_opt_set_xx函数逐项设置参数;swr_alloc_set_…...
车载视频监控管理方案:无人驾驶出租车安全出行的保障
近日,无人驾驶出租车“萝卜快跑”在武汉开放载人测试成为热门话题。随着科技的飞速发展,无人驾驶技术已逐渐从概念走向现实,特别是在出租车行业中,无人驾驶出租车的推出将为公众提供更为安全、便捷、高效的出行服务。 视频监控技…...


ARM SVE2指令集与USUBWB指令优化实践
1. ARM SVE2指令集概述在当今计算密集型应用领域,向量处理能力已成为衡量处理器性能的关键指标。ARM架构的Scalable Vector Extension 2(SVE2)作为第二代可扩展向量指令集,在2021年随ARMv9架构一同发布,为高性能计算领…...

专业级AI音频处理实战指南:OpenVINO插件让Audacity变身智能音频工作站 [特殊字符]
专业级AI音频处理实战指南:OpenVINO插件让Audacity变身智能音频工作站 🎵 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openv…...

3个技巧解除索尼相机限制:OpenMemories-Tweak项目实战指南
3个技巧解除索尼相机限制:OpenMemories-Tweak项目实战指南 【免费下载链接】OpenMemories-Tweak Unlock your Sony cameras settings 项目地址: https://gitcode.com/gh_mirrors/op/OpenMemories-Tweak 你是否曾经因为索尼相机的30分钟视频录制限制而错过重要…...

3分钟让AI自动分层?LayerDivider如何拯救你的PSD编辑噩梦
3分钟让AI自动分层?LayerDivider如何拯救你的PSD编辑噩梦 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 还在为一张扁平插画需要分层编辑而头…...
)
GORM 标签详解(数据库字段映射核心)
很多人刚学 GORM: 会觉得: gorm:"primaryKey" gorm:"index" gorm:"not null"这些东西: 像“魔法字符串”。 其实: 它本质上是在告诉 GORM: 数据库这一列应该怎么创建也就是:…...

【VibeCoding系列教程05】AI编程工具别瞎选!我用过一遍后,把它们分成了3个段位
我刚用AI做出了人生第一个网页应用,正沉浸在"原来我也能当程序员"的幻觉中。结果第二天我就遇到了一个更头疼的问题——市面上的AI编程工具,多得像超市里的酸奶,看着都差不多,拿起来才发现有的过期了有的加糖太多。有人…...

Mac Mouse Fix终极指南:让你的普通鼠标秒变专业神器
Mac Mouse Fix终极指南:让你的普通鼠标秒变专业神器 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为Mac鼠标操作不够流畅、功…...

Arknights-Mower:解放双手的明日方舟智能基建管理工具
Arknights-Mower:解放双手的明日方舟智能基建管理工具 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 在《明日方舟》的日常游戏过程中,基建管理、资源刷取和日常任务占据…...
)
用ChatGPT写投资人邮件:72小时内获3家TS的实测框架(含Prompt工程+合规校验清单)
更多请点击: https://codechina.net 第一章:用ChatGPT写投资人邮件:72小时内获3家TS的实测框架(含Prompt工程合规校验清单) 在融资关键期,一封精准、可信、有温度的投资人邮件,往往比BP更早决定…...