VLM技术介绍
1、背景
视觉语言模型(Visual Language Models)是可以同时从图像和文本中学习以处理许多任务的模型,从视觉问答到图像字幕。
视觉识别(如图像分类、物体保护和语义分割)是计算机视觉研究中一个长期存在的难题,也是自动驾驶、遥感、机器人等无数计算机视觉应用的基石。随着深度学习的出现,视觉识别研究通过利用端到端可训练深度神经网络(DNN)取得了巨大成功。 然而,从传统机器学习向深度学习的转变带来了两个新的巨大挑战,即在 "从零开始深度学习 "的经典设置下 DNN 训练收敛缓慢以及 DNN 训练中大规模、特定任务和人群标签数据的费力收集。
最近,一种新的学习范式 “预训练、微调和预测”(Pre-training, Fine tuning and Prediction)已在广泛的视觉识别任务中显示出极大的有效性。 在这种新范式下,DNN 模型首先使用某些现成的大规模训练数据(有注释或无注释)进行预训练,然后使用特定任务的注释训练数据对预训练模型进行微调。通过预训练模型学到的全面知识,这种学习范式可以加速网络收敛,并为各种下游任务训练出性能良好的模型。
2、什么是视觉语言模型
视觉语言模型被广泛定义为可以从图像和文本中学习的多模态模型。它们是一种生成式模型,可以接受图像和文本输入并生成文本输出。
大型视觉语言模型具有良好的零样本能力,具有良好的泛化能力,并且可以处理多种类型的图像,包括文档、网页等。用例包括谈论图像、通过指令进行图像识别、视觉问答、文档理解、图像字幕等。一些视觉语言模型还可以捕获图像中的空间属性。当系统提示检测或分割特定主题时,这些模型可以输出边界框或分割掩码,也可以定位不同的实体或回答有关其相对或绝对位置的问题。现有的大型视觉语言模型集、它们所训练的数据、它们对图像的编码方式以及它们的能力都存在很大差异。
3、VLM分类
VLM按训练范式分成了四类:
第一类是对比式训练(contrastive training),这是一种使用正例和负例对来训练模型的常用策略。VLM 的训练目标是为正例对预测相似的表征,为负例对预测不同的表征。
第二类是掩码(masking),其方法是根据某些未被遮掩的文本来重建被遮掩的图块。类似地,通过遮掩描述中的词,也可以让 VLM 根据未被遮掩的图像来重建这些被遮掩的词。
另一类是基于预训练骨干网络来训练 VLM,这往往是使用 Llama 等开源 LLM 来学习图像编码器(也可能是预训练的)和 LLM 之间的映射关系。相比于从头开始训练文本和图像编码器,学习预训练模型之间的映射关系的计算成本往往更低。大部分这类方法都是使用中间表征或部分重建,而生成式 VLM 则能生成图像或描述。有鉴于这类模型的性质,它们的训练成本通常是最高的。
需要说明:这些范式并不是互斥的,很多方法都混合使用了对比、掩码和生成范式。

3.1 基于 Transformer 的 VLM 早期研究
通过使用 Transformer 架构,BERT(使用 Transformer 的双向编码器表征)一诞生,就超过了当时所有的语言建模方法。之后不久,BERT 就被扩展用来处理视觉数据。visual-BERT 和 ViLBERT 是其中两个代表,它们的做法是将文本与图像 token 组合到一起。
这些模型有两个训练目标:1) 经典的掩码建模任务,目标是预测给定输入中缺失的部分;2) 句子 - 图像预测任务,目标是预测图像标注是否描述了图像内容。通过利用这两个目标,这些模型在多种视觉 - 语言任务上表现出色,这主要是得益于 Transformer 模型有能力学会通过注意力机制将词与视觉线索关联起来。
3.2 基于对比的 VLM
基于对比的训练往往能通过基于能量的模型(EBM)更好地解释,即模型的训练目标是为观察到的变量分配低能量,为未被观察到的变量分配高能量。来自目标分布的数据的能量应该较低,其它数据点的能量应该较高。
3.3 使用掩码目标的 VLM
在深度学习研究中,掩码是一种常用技术。它可被视为一种特定形式的去噪自动编码器,其中的噪声有一种空间结构。它也与修复(inpainting)策略有关,该策略曾被用于学习强大的视觉表征。BERT 也在训练阶段使用了掩码式语言建模(MLM)来预测句子中缺失的 token。掩码方法非常适合 Transformer 架构,因此输入信号的 token 化使得随机丢弃特定的输入 token 变得更容易。
已经有一些研究在图像方面探索这一方法,即掩码式图像建模(MIM),具体案例包括 MAE 和 I-JEPA。很自然地,也有人将这两者组合起来训练 VLM。其一是 FLAVA,其使用了掩码在内的多种训练策略来学习文本和图像表征。另一个是 MaskVLM,这是一种独立模型。
3.4 基于生成的 VLM
上面的训练范式主要是操作隐含表征来构建图像或文本抽象,之后再在它们之间映射,生成范式则不同,它考虑文本和 / 或图像的生成。
3.5 用预训练骨干网络构建的 VLM
VLM 的一个缺点是从头开始训练的成本很高。这通常需要成百上千台 GPU,同时还必须使用上亿对图像和文本。因此,也有很多研究者探索使用已有的 LLM 或视觉提取器,而不是从头开始训练模型。这种做法的另一个优势是可以利用现在很多开源且易用的 LLM。通过使用这样的模型,有可能学习到仅在文本模态和图像模态之间的映射。通过学习这样的映射,仅需要少量计算资源就可让 LLM 有能力回答视觉问题。
4、将 VLM 扩展用于视频
之前谈到的 VLM 基本都是在静态视觉数据(图像)上训练和评估的。但是,视觉数据还有动态的,即视频。对 VLM 而言,视频数据既能带来新挑战,也有望为其带来新能力,比如理解物体的运动和动态或在空间和时间中定位物体和动作。用文本检索视频、视频问答和视频生成正在快速成为基础的计算机视觉任务。
视频的时间属性对存储、CPU 内存来说都是一个巨大挑战(如果把每一帧都视为一张图像,那么帧率越高,成本就越高)。于是对于处理视频的 VLM 而言,就需要考虑多个权衡因素,比如数据加载器中动态视频解码器的压缩格式、基于图像编码器来初始化视频编码器、为视频编码器使用时空池化 / 掩码机制、非端到端 VLM。
与图像 - 文本模型类似,早期的视频 - 文本模型也是使用自监督指标来从头开始训练视觉和文本组件。但不同于图像模型,对比式视频 - 文本模型并非首选方法,早期时人们更喜欢融合和时间对齐方法,因为相比于计算视频的全局表征,让表征中有更多时间粒度更重要。
近段时间,视频 - 语言模型领域出现了图像 - 语言模型领域类似的趋势:使用预训练 LLM 并将其与视频编码器对齐,从而增强 LLM 的视频理解能力。视觉指令微调等现代技术也被广泛使用并被适配用于视频。
相关文章:
VLM技术介绍
1、背景 视觉语言模型(Visual Language Models)是可以同时从图像和文本中学习以处理许多任务的模型,从视觉问答到图像字幕。 视觉识别(如图像分类、物体保护和语义分割)是计算机视觉研究中一个长期存在的难题ÿ…...

x264 编码器 AArch64 汇编函数模块关系分析
x264 编码器 AArch64 汇编介绍 x264 是一个流行的开源视频编码器,它实现了 H.264/MPEG-4 AVC 标准。x264 项目致力于提供一个高性能、高质量的编码器,支持多种平台和架构。对于 AArch64(即 64 位 ARM 架构),x264 编码器利用该架构的特性来优化编码过程。在 x264 编码器中,…...

windows10开启防火墙,增加入站规则后不生效,还是不能访问后端程序
一、背景: 公司护网要求开启防火墙,开启防火墙后,前后端分离的项目调试受影响,于是增加入站规则开放固定的后台服务端口,增加的mysql端口3306和redis端口6379,别人都可以访问,但是程序的端口808…...
academic-homepage:快速搭建个人学术主页,页面内容包括个人简介、教育经历、发布过的学术列表等,同时页面布局兼容移动端。
今天给大家分享GitHub 上一个开源的 GitHub Pages 模板 academic-homepage。 可帮助你快速搭建个人学术主页,页面内容包括个人简介、教育经历、发布过的学术列表等最基本内容,同时页面布局兼容移动端。 相关链接 github.com/luost26/academic-homepage …...

.env.development、.env.production、.env.staging
环境变量文件(如 .env.development、.env.production、.env.staging)用于根据不同的环境(开发、生产、测试等)配置应用程序的行为。 作用 .env.development:用于开发环境的配置。开发人员在本地开发时会使用这个文件…...
在Kylin Server V10下安装)
国密证书(gmssl)在Kylin Server V10下安装
1.查看操作系统信息 [root@localhost ~]# cat /etc/.kyinfo [dist] name=Kylin milestone=Server-V10-GFB-Release-ZF9_01-2204-Build03 arch=arm64 beta=False time=2023-01-09 11:04:36 dist_id=Kylin-Server-V10-GFB-Release-ZF9_01-2204-Build03-arm64-2023-01-09 11:04:…...

【数据服务篇】法律快车问答数据:为法律智能化铺就道路
数据来源 法律快车汇集了广泛的法律问题和专业律师的回答,这些来自用户和律师的数据构成了丰富的问答资源。用户通过平台提交各类法律疑问,得到资深律师的详尽解答,形成了一系列真实、多样化的法律案例和讨论。 数据获取见文末。 数据内容…...

各向异性含水层中地下水三维流基本微分方程的推导(二)
各向异性含水层中地下水三维流基本微分方程的推导 参考文献: [1] 刘欣怡,付小莉.论连续性方程的推导及几种形式转换的方法[J].力学与实践,2023,45(02):469-474. 书接上回: 我们能得到三个方向的流入流出平衡方程: ∂ ρ u x ∂ x d x d y d…...

2024 微信小程序 学习笔记 第一天
微信公众平台 (qq.com) 小程序代码的构成 项目结构 JSON 配置文件 WXML 模板 WXSS 样式 JS 逻辑交互 小程序的宿主环境 宿主 通信模型 运行机制 组件 视图组件 view scrioll-view swiper swiper-item swiper属性 text button image image mode属性 小程序API 协…...

PCIe驱动开发(3)— 驱动设备文件的创建与操作
PCIe驱动开发(3)— 驱动设备文件的创建与操作 一、前言 在 Linux 中一切皆为文件,驱动加载成功以后会在“/dev”目录下生成一个相应的文件,应用程序通过对这个名为“/dev/xxx” (xxx 是具体的驱动文件名字)的文件进行相应的操作即…...

【Redis】简单了解Redis中常用的命令与数据结构
希望文章能给到你启发和灵感~ 如果觉得文章对你有帮助的话,点赞 关注 收藏 支持一下博主吧~ 阅读指南 开篇说明一、基础环境说明1.1 硬件环境1.2 软件环境 二、Redis的特点和适用场景三、Redis的数据类型和使用3.1字符串(String&…...

IDEA启动Web项目总是提示端口占用
文章目录 IDEA启动Web项目总是提示端口占用一、前言1.场景2.环境 二、正文1.场景一:真端口占用2. 场景二:假端口占用 IDEA启动Web项目总是提示端口占用 一、前言 1.场景 IDEA启动Web项目总是提示端口占用: 确实是端口被占用,比如:没有正常…...

JRT打印鉴定记录单
良好的基础会使上层实现越做越简单,jrt在开始写业务之前就把运用场景需要的基础实验和设计完毕了。基于jrt的基础可以很轻松的实现强大的打印效果。jrt的打印和lodop比较像,是高度为满足建议系统打印定制的打印实现,设计器可能没lodop通用&am…...
数据处理-Matplotlib 绘图展示
文章目录 1. Matplotlib 简介2. 安装3. Matplotlib Pyplot4. 绘制图表1. 折线图2. 散点图3. 柱状图4. 饼图5. 直方图 5. 中文显示 1. Matplotlib 简介 Matplotlib 是 Python 的绘图库,它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式。 Ma…...
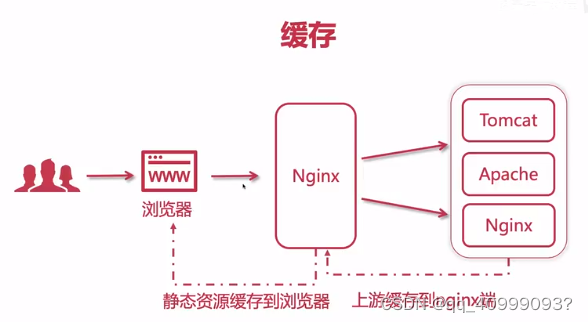
Nginx -Web服务器/反向代理/负载均衡
文章目录 一、web服务1.1 nginx安装1.2 配置文件1.3 Nginx处理Web机制 二、反向代理三、负载均衡3.1 分类3.2 负载相关配置文件3.3 keepalive 提高吞吐量3.4 配置浏览器缓存 附、JMeter性能测试工具 以赛促学内容,大概率感觉会使用nginx做web服务,特对nginx做总结归纳. Nginx是…...

机器人三定律及伦理分析
全世界的机器人定律并没有一个统一的标准或体系,但是在科学文献中,最广为人知的是由科幻小说家阿西莫夫提出的“机器人三定律”。本文将以这些定律为基础,分析现有的机器人伦理和实际应用中的问题,给出若干实例,并对相…...
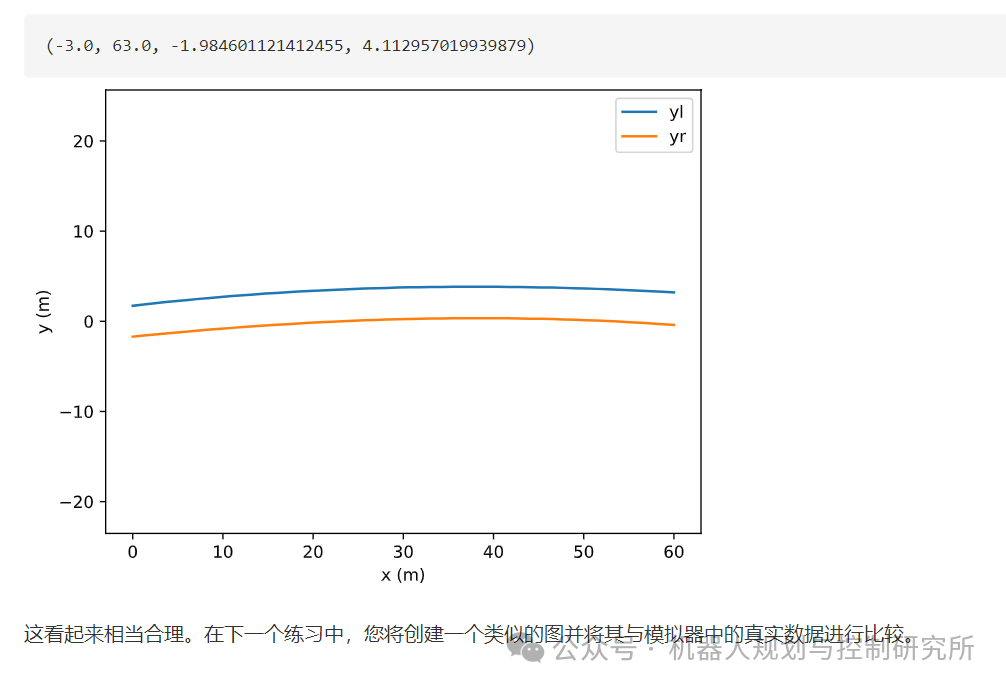
自动驾驶算法———车道检测(一)
“ 在本章中,我将指导您构建一个简单但有效的车道检测管道,并将其应用于Carla 模拟器中捕获的图像。管道将图像作为输入,并产生车道边界的数学模型作为输出。图像由行车记录仪(固定在车辆挡风玻璃后面的摄像头)捕获。…...

小程序自学教程
从0开始搭建微信小程序前后台 0、准备 如何安装?去CSDN搜索“xxx安装教程”即可。 (1)工具 IntelliJ IDEA(必选)——Java开发集成环境,可以前后端同时使用 Web Storm——web开发集成环境,主要…...

How do I format markdown chatgpt response in tkinter frame python?
题意:怎样在Tkinter框架中使用Python来格式化Markdown格式的ChatGPT响应? 问题背景: Chatgpt sometimes responds in markdown language. Sometimes the respond contains ** ** which means the text in between should be bold and ### te…...

vs2019 QT无法打开源文件QModbusTcpClient
vs2019无法打开源文件QModbusTcpClient 如果配置的msvc2019,则查找到Include目录 然后包含: #include <QtSerialBus/qmodbustcpclient.h>...

Taotoken的Token Plan如何帮助我们控制月度AI支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的Token Plan如何帮助我们控制月度AI支出 1. 从按需付费到计划消费的转变 作为自由职业者或小型工作室,我们在…...

3大核心技术深度解析:泉盛UV-K5/K6对讲机LOSEHU固件完全配置指南
3大核心技术深度解析:泉盛UV-K5/K6对讲机LOSEHU固件完全配置指南 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 泉盛UV-K5/K6对讲机L…...

深入解析tsMuxer:高效无损视频封装解决方案与实战配置指南
深入解析tsMuxer:高效无损视频封装解决方案与实战配置指南 【免费下载链接】tsMuxer tsMuxer is a transport stream muxer for remuxing/muxing elementary streams, EVO/VOB/MPG, MKV/MKA, MP4/MOV, TS, M2TS to TS to M2TS. Supported video codecs H.264/AVC, H…...
)
DeepSeek微调吞吐量翻倍实践:LoRA+梯度检查点+FlashAttention-3三重协同调优(附A100/A800实测QPS对比表)
更多请点击: https://codechina.net 第一章:DeepSeek性能调优指南 DeepSeek系列大模型在推理与训练阶段的性能表现高度依赖于硬件适配、计算图优化及内存管理策略。本章聚焦于可落地的调优实践,涵盖推理加速、显存压缩与计算精度协同配置三大…...
)
DeepSeek v3升级后成本激增41%?紧急发布:兼容性迁移成本对冲清单(含6个可立即执行的config开关)
更多请点击: https://kaifayun.com 第一章:DeepSeek成本控制策略 DeepSeek系列大模型在推理与训练阶段的资源消耗显著,因此精细化的成本控制策略是保障其规模化落地的关键。核心思路在于“按需调度、动态降级、硬件感知”,而非简…...

揭秘Gemini ESG引擎底层逻辑:3大AI模型协同如何将人工撰写耗时压缩90%?
更多请点击: https://codechina.net 第一章:Gemini ESG报告生成的演进与价值定位 传统ESG(环境、社会与治理)报告编制长期依赖人工数据收集、跨部门协调与静态模板套用,平均耗时长达3–6个月,且易出现口径…...
)
Gemini SQL查询生成落地手册(企业级生产环境已验证)
更多请点击: https://kaifayun.com 第一章:Gemini SQL查询生成落地手册(企业级生产环境已验证) 在大型金融与电商客户的真实生产环境中,Gemini 模型已被成功集成至自助分析平台,日均稳定生成超 12,000 条符…...

Linux AppImage终极管理指南:如何一键集成便携应用到系统菜单
Linux AppImage终极管理指南:如何一键集成便携应用到系统菜单 【免费下载链接】AppImageLauncher Helper application for Linux distributions serving as a kind of "entry point" for running and integrating AppImages 项目地址: https://gitcode.…...

【紧急预警】ChatGPT默认图表存在3类隐性误导风险!金融/医疗行业已发生2起决策偏差事故
更多请点击: https://intelliparadigm.com 第一章:ChatGPT数据可视化建议 在利用ChatGPT辅助数据分析与可视化时,需特别注意输入提示(prompt)的结构化设计,以引导模型生成可执行、可复现的可视化代码。Cha…...

Play Integrity API Checker:构建企业级Android安全防御体系的技术架构与商业价值
Play Integrity API Checker:构建企业级Android安全防御体系的技术架构与商业价值 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integ…...