PyTorch DataLoader 学习
1. DataLoader的核心概念
DataLoader是PyTorch中一个重要的类,用于将数据集(dataset)和数据加载器(sampler)结合起来,以实现批量数据加载和处理。它可以高效地处理数据加载、多线程加载、批处理和数据增强等任务。
核心参数
dataset: 数据集对象,必须是继承自torch.utils.data.Dataset的类。batch_size: 每个批次的大小。shuffle: 是否在每个epoch开始时打乱数据。sampler: 定义数据加载顺序的对象,通常与shuffle互斥。num_workers: 使用多少个子进程加载数据。collate_fn: 如何将单个样本合并为一个批次的函数。pin_memory: 是否将数据加载到CUDA固定内存中。
2. 基本使用方法
定义数据集类
首先定义一个数据集类,该类需要继承自torch.utils.data.Dataset并实现__len__和__getitem__方法。
import torch
from torch.utils.data import Dataset, DataLoaderclass CustomDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, idx):sample = {'data': self.data[idx], 'label': self.labels[idx]}return sample# 创建一些示例数据
data = torch.randn(100, 3, 64, 64) # 100个样本,每个样本为3x64x64的图像
labels = torch.randint(0, 2, (100,)) # 100个标签,0或1dataset = CustomDataset(data, labels)创建DataLoader
使用自定义数据集类创建DataLoader对象。
batch_size = 4
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2)
迭代DataLoader
遍历DataLoader获取批量数据。
for batch in dataloader:data, labels = batch['data'], batch['label']print(data.shape, labels.shape)
3. 进阶技巧
自定义collate_fn
如果需要自定义如何将样本合并为批次,可以定义自己的collate_fn函数。
def custom_collate_fn(batch):data = [item['data'] for item in batch]labels = [item['label'] for item in batch]return {'data': torch.stack(data), 'label': torch.tensor(labels)}dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2, collate_fn=custom_collate_fn)使用Sampler
Sampler定义了数据加载的顺序。可以自定义一个Sampler来实现更复杂的数据加载策略。
from torch.utils.data import Samplerclass CustomSampler(Sampler):def __init__(self, data_source):self.data_source = data_sourcedef __iter__(self):return iter(range(len(self.data_source)))def __len__(self):return len(self.data_source)custom_sampler = CustomSampler(dataset)
dataloader = DataLoader(dataset, batch_size=batch_size, sampler=custom_sampler, num_workers=2)数据增强
在图像处理中,数据增强(Data Augmentation)是提高模型泛化能力的一种有效方法。可以使用torchvision.transforms进行数据增强。
import torchvision.transforms as transformstransform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomCrop(32, padding=4),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])dataset = CustomDataset(data, labels, transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2)4. 实战示例:CIFAR-10数据集
以下是使用CIFAR-10数据集的完整示例代码,包括数据加载、数据增强和模型训练。
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10# 定义数据增强和标准化
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])# 加载训练和测试数据集
trainset = CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)testset = CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)# 定义简单的卷积神经网络
import torch.nn as nn
import torch.nn.functional as Fclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)self.fc1 = nn.Linear(64 * 8 * 8, 512)self.fc2 = nn.Linear(512, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 64 * 8 * 8)x = F.relu(self.fc1(x))x = self.fc2(x)return x# 创建模型、定义损失函数和优化器
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(10):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 100 == 99:print(f'Epoch {epoch + 1}, Batch {i + 1}, Loss: {running_loss / 100}')running_loss = 0.0print('Finished Training')# 测试模型
correct = 0
total = 0
with torch.no_grad():for data in testloader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy of the network on the 10000 test images: {100 * correct / total} %')5. 数据加载加速技巧
使用多进程数据加载
通过设置num_workers参数,可以启用多进程数据加载,加速数据读取过程。
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)使用pin_memory
如果使用GPU进行训练,将pin_memory设置为True可以加速数据传输。
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)预取数据
使用prefetch_factor参数来预取数据,以减少数据加载等待时间。
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4, prefetch_factor=2)6. 处理不规则数据
在某些情况下,数据样本可能不规则,例如变长序列。可以使用自定义的collate_fn来处理这种数据。
def custom_collate_fn(batch):batch = sorted(batch, key=lambda x: len(x['data']), reverse=True)data = [item['data'] for item in batch]labels = [item['label'] for item in batch]data_padded = torch.nn.utils.rnn.pad_sequence(data, batch_first=True)labels = torch.tensor(labels)return {'data': data_padded, 'label': labels}dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2, collate_fn=custom_collate_fn)7. 使用中应注意的问题
数据加载效率
设置num_workers
- 多线程数据加载:
num_workers参数决定了用于数据加载的子进程数量。合理设置num_workers可以显著提升数据加载速度。一般来说,设置为CPU核心数的一半或等于核心数是一个不错的选择,但需要根据具体情况进行调整。
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)使用pin_memory
- 固定内存: 当使用GPU进行训练时,将pin_memory设置为True可以加速数据从CPU传输到GPU的速度。固定内存使得数据可以直接从页面锁定内存复制到GPU内存。
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)预取数据
- 预取因子: 使用prefetch_factor参数来预取数据,以减少数据加载等待时间。默认情况下,预取因子为2。
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4, prefetch_factor=2)数据集与DataLoader的兼容性
正确实现 __getitem__ 和 __len__
- 数据集类的实现: 确保自定义数据集类正确实现了
__getitem__和__len__方法,确保DataLoader能够正确地索引和迭代数据。
class CustomDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, idx):sample = {'data': self.data[idx], 'label': self.labels[idx]}return sample数据增强与预处理
数据增强
- 变换操作: 在图像处理中,数据增强可以提高模型的泛化能力。可以使用
torchvision.transforms进行数据增强和标准化。
import torchvision.transforms as transformstransform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomCrop(32, padding=4),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])dataset = CustomDataset(data, labels, transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2)数据加载过程中的内存问题
避免内存泄漏
- 防止内存泄漏: 在使用DataLoader时,尤其是多进程加载时,注意内存泄漏问题。确保在训练过程中及时释放不再使用的数据。
合理设置batch_size
- 批次大小: 根据GPU显存和内存大小合理设置
batch_size。过大可能导致内存不足,过小可能导致计算效率低。
batch_size = 64 # 根据实际情况调整
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)数据顺序与随机性
shuffle与sampler
- 数据随机性: 在训练集上使用
shuffle=True,可以在每个epoch开始时打乱数据,防止模型过拟合。 - 使用Sampler: 对于特殊的数据加载顺序需求,可以自定义Sampler。
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)数据不一致性
自定义collate_fn
- 处理变长序列:在处理变长序列或不规则数据时,自定义
collate_fn函数,确保每个批次的数据能够正确合并。
def custom_collate_fn(batch):data = [item['data'] for item in batch]labels = [item['label'] for item in batch]return {'data': torch.stack(data), 'label': torch.tensor(labels)}dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2, collate_fn=custom_collate_fn)数据加载调试
调试与错误处理
- 调试: 在数据加载过程中,可以打印或检查部分数据样本,确保数据预处理和加载过程正确无误。
- 错误处理: 使用try-except块捕捉并处理数据加载中的异常,防止程序崩溃。
for i, data in enumerate(dataloader, 0):try:inputs, labels = data['data'], data['label']# 数据处理和训练代码except Exception as e:print(f"Error loading data at batch {i}: {e}")性能优化
数据加载性能
- Profile数据加载: 使用profiling工具(如PyTorch的
torch.utils.bottleneck)分析数据加载和训练过程中的性能瓶颈,进行相应优化。
import torch.utils.bottleneck# 在命令行运行以下命令进行性能分析
# python -m torch.utils.bottleneck <script.py>相关文章:

PyTorch DataLoader 学习
1. DataLoader的核心概念 DataLoader是PyTorch中一个重要的类,用于将数据集(dataset)和数据加载器(sampler)结合起来,以实现批量数据加载和处理。它可以高效地处理数据加载、多线程加载、批处理和数据增强…...
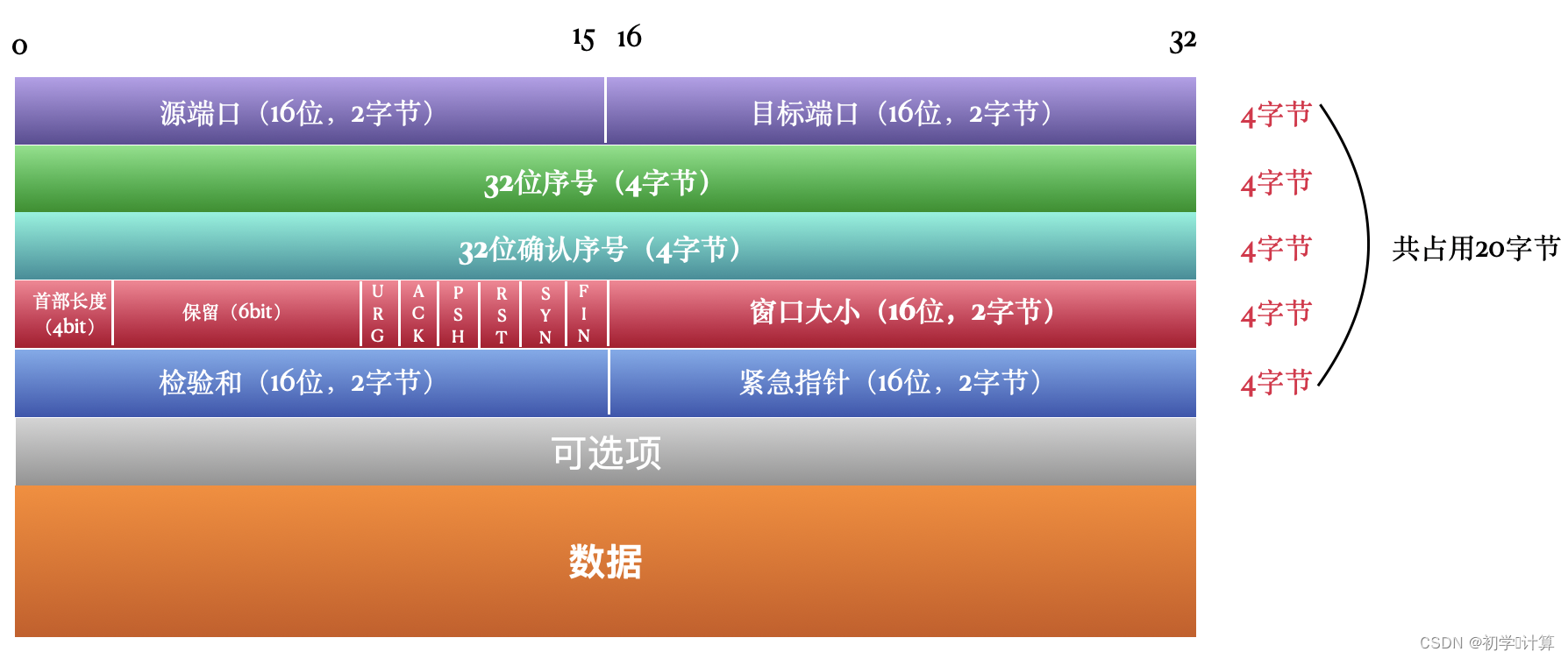
TCP传输控制协议二
TCP 是 TCP/IP 模型中的传输层一个最核心的协议,不仅如此,在整个 4 层模型中,它都是核心的协议,要不然模型怎么会叫做 TCP/IP 模型呢。 它向下使用网络层的 IP 协议,向上为 FTP、SMTP、POP3、SSH、Telnet、HTTP 等应用…...

【学习笔记】无人机(UAV)在3GPP系统中的增强支持(五)-同时支持无人机和eMBB用户数据传输的用例
引言 本文是3GPP TR 22.829 V17.1.0技术报告,专注于无人机(UAV)在3GPP系统中的增强支持。文章提出了多个无人机应用场景,分析了相应的能力要求,并建议了新的服务级别要求和关键性能指标(KPIs)。…...
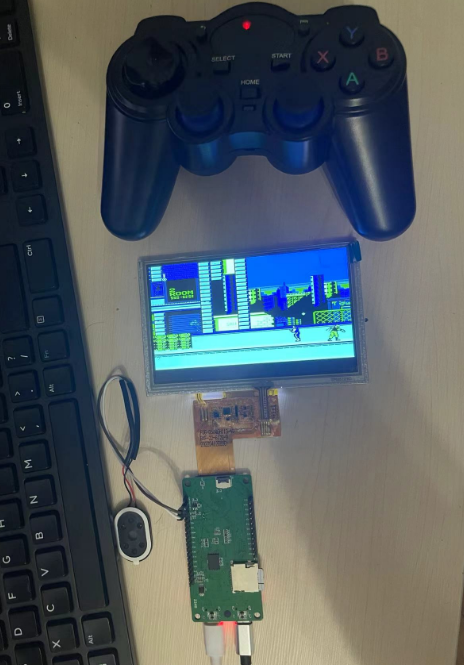
使用F1C200S从零制作掌机之debian文件系统完善NES
一、模拟器源码 源码:https://files.cnblogs.com/files/twzy/arm-NES-linux-master.zip 二、文件系统 文件系统:debian bullseye 使用builtroot2018构建的文件系统,使用InfoNES模拟器存在bug,搞不定,所以放弃&…...

Vue 3 与 TypeScript:最佳实践详解
大家好,我是CodeQi! 很多人问我为什么要用TypeScript? 因为 Vue3 喜欢它! 开个玩笑... 在我们开始探索 Vue 3 和 TypeScript 最佳实践之前,让我们先打个比方。 如果你曾经尝试过在没有 GPS 的情况下开车到一个陌生的地方,你可能会知道那种迷失方向的感觉。 而 Typ…...

PyMysql error : Packet Sequence Number Wrong - got 1 expected 0
文章目录 错误一错误原因解决方案 错误二原因解决方案 我自己知道的,这类问题有两类原因,两种解决方案。 错误一 错误原因 pymysql的主进程启动的connect无法给子进程中使用,所以读取大批量数据时最后容易出现了此类问题。 解决方案 换成…...
MVC 生成验证码
在mvc 出现之前 生成验证码思路 在一个html页面上,生成一个验证码,在把这个页面嵌入到需要验证码的页面中。 JS生成验证码 <script type"text/javascript">jQuery(function ($) {/**生成一个随机数**/function randomNum(min, max) {…...

OSPF.综合实验
1、首先将各个网段基于172.16.0.0 16 进行划分 1.1、划分为4个大区域 172.16.0.0 18 172.16.64.0 18 172.16.128.0 18 172.16.192.0 18 四个网段 划分R4 划分area2 划分area3 划分area1 2、进行IP配置 如图使用配置指令进行配置 ip address x.x.x.x /x 并且将缺省路由…...
云计算【第一阶段(29)】远程访问及控制
一、ssh远程管理 1.1、ssh (secureshell)协议 是一种安全通道协议对通信数据进行了加密处理,用于远程管理功能SSH 协议对通信双方的数据传输进行了加密处理,其中包括用户登录时输入的用户口令,建立在应用层和传输层基础上的安全协议。SSH客…...

2024前端面试真题【CSS篇】
盒子模型 盒子模型:box-sizing,描述了文档中的元素如何生成矩形盒子,并通过这些盒子的布局来组织和设计网页。包含content、padding、margin、border四个部分。 分类 W3C盒子模型(content-box):标准盒子模…...

python中设置代码格式,函数编写指南,类的编程风格
4.6 设置代码格式 随着你编写的程序越来越长,确保代码格式一致变得尤为重要。花时间让代码尽可能易于阅读,这不仅有助于你理解程序的功能,也能帮助他人理解你的代码。 为了保证所有人的代码结构大致一致,Python程序员遵循一系列…...

CentOS 8升级gcc版本
1、查看gcc版本 gcc -v发现gcc版本为8.x.x,而跑某个项目的finetune需要gcc-9,之前搜索过很多更新gcc版本的方式,例如https://blog.csdn.net/xunye_dream/article/details/108918316?spm1001.2014.3001.5506,但执行指令 sudo yu…...

Kafka基础入门篇(深度好文)
Kafka简介 Kafka 是一个高吞吐量的分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用与大数据实时处理领域。 1. 以时间复杂度为O(1)的方式提供消息持久化能力。 2. 高吞吐率。(Kafka 的吞吐量是MySQL 吞吐量的30…...

C++之复合资料型态KU网址第二部V蒐NAY3989
结构 结构可存放不同资料型态的数值,例如 #include <iostream>struct Demo {int member1;char *member2;float member3; };int main() {Demo d;d.member1 19823;d.member2 "203";d.member3 3.011;std::cout << "member1: " &l…...

乡镇集装箱生活污水处理设备处理效率高
乡镇集装箱生活污水处理设备处理效率高 乡镇集装箱生活污水处理设备优势 结构紧凑:集装箱式设计减少了占地面积,便于在土地资源紧张的乡镇地区部署。 安装方便:设备出厂前已完成组装和调试,现场只需进行简单的连接和调试即可投入使…...

计算机网络高频面试题
从输入URL到展现页面的全过程: 用户在浏览器中输入URL。浏览器解析URL,确定协议、主机名和路径。浏览器查找本地DNS缓存,如果没有找到,向DNS服务器发起查询请求。DNS服务器解析主机名,返回IP地址。浏览器使用IP地址建立…...

进程通信(1):无名管道(pipe)
无名管道(pipe)用来具有亲缘关系的进程之间进行单向通信。半双工的通信方式,数据只能单向流动。 管道以字节流的方式通信,数据格式由用户自行定义。 无名管道多用于父子进程间通信,也可用于其他亲缘关系进程间通信。 因为父进程调用fork函…...

YOLOv10改进 | 损失函数篇 | SlideLoss、FocalLoss、VFLoss分类损失函数助力细节涨点(全网最全)
一、本文介绍 本文给大家带来的是分类损失 SlideLoss、VFLoss、FocalLoss损失函数,我们之前看那的那些IoU都是边界框回归损失,和本文的修改内容并不冲突,所以大家可以知道损失函数分为两种一种是分类损失另一种是边界框回归损失,…...
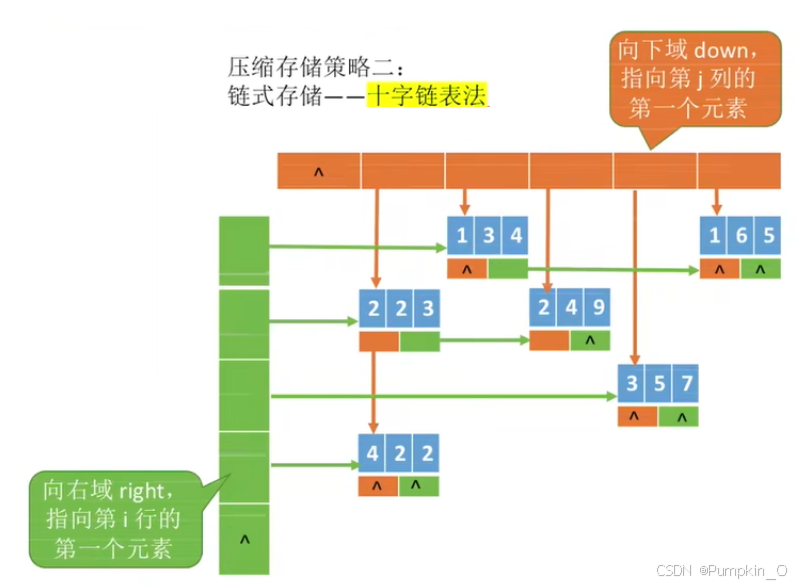
【数组、特殊矩阵的压缩存储】
目录 一、数组1.1、一维数组1.1.1 、一维数组的定义方式1.1.2、一维数组的数组名 1.2、二维数组1.2.1、二维数组的定义方式1.2.2、二维数组的数组名 二、对称矩阵的压缩存储三、三角矩阵的压缩存储四、三对角矩阵的压缩存储五、稀疏矩阵的压缩存储 一、数组 概述:数…...

Flat Ads:金融APP海外广告投放素材的优化指南
在当今全球化的数字营销环境中,金融APP的海外营销推广已成为众多金融机构与开发者最为关注的环节之一。面对不同地域、文化及用户习惯的挑战,如何优化广告素材,以吸引目标受众的注意并促成有效转化,成为了广告主们亟待解决的问题。 作为领先的全球化营销推广平台,Flat Ads凭借…...

蓝奏云API终极指南:快速获取文件直链的完整解决方案
蓝奏云API终极指南:快速获取文件直链的完整解决方案 【免费下载链接】LanzouAPI 蓝奏云直链,蓝奏api,蓝奏解析,蓝奏云解析API,蓝奏云带密码解析 项目地址: https://gitcode.com/gh_mirrors/la/LanzouAPI 蓝奏云…...

如何快速集成AdvancedSessionsPlugin:终极多人游戏开发指南
如何快速集成AdvancedSessionsPlugin:终极多人游戏开发指南 【免费下载链接】AdvancedSessionsPlugin Advanced Sessions Plugin for UE4 项目地址: https://gitcode.com/gh_mirrors/ad/AdvancedSessionsPlugin 你是否正在为虚幻引擎4的多人游戏开发而烦恼&a…...

如何在3分钟内完成Windows与Office批量激活:开源KMS工具完整指南
如何在3分钟内完成Windows与Office批量激活:开源KMS工具完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 如果您正在寻找一个简单高效的Windows与Office批量激活解决方案&…...

终极指南:如何用Awoo Installer一站式解决Switch游戏安装兼容性问题
终极指南:如何用Awoo Installer一站式解决Switch游戏安装兼容性问题 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安…...

想知道你的AI提示词到底用了多少Token?这个可视化工具告诉你答案
想知道你的AI提示词到底用了多少Token?这个可视化工具告诉你答案 【免费下载链接】tiktokenizer Online playground for OpenAPI tokenizers 项目地址: https://gitcode.com/gh_mirrors/ti/tiktokenizer 在构建AI应用时,你是否经常遇到这样的困惑…...
)
Arduino入门教程十三|自制模拟传感器(分压原理详解+光敏夜灯+constrain范围限制)
我整理了一套Arduino 零基础 从入门到高级 完整系统课程,包含视频讲解、全套源码、接线图纸、库文件、ESP32/ESP32-S3 摄像头 & 物联网实战项目,循序渐进,新手也能零基础吃透。需要系统学习可以查看我主页专属课程(零基础保姆级Arduino教程从入门到实战_在线视频教程-C…...

实时控制系统中VoU传输优化框架的设计与实践
1. 实时控制系统的网络传输挑战 在工业物联网和网络化控制系统中,传感器、控制器和执行器之间的实时数据传输质量直接影响整个系统的控制性能。传统控制系统通常假设通信链路是理想的——零延迟、无丢包且带宽无限。然而在实际无线多跳网络环境中,这种假…...

Cortex-R5不可中断事务机制与内存类型配置详解
1. Cortex-R5不可中断事务机制解析在实时嵌入式系统中,事务的原子性和可预测性往往至关重要。Cortex-R5作为一款面向实时应用的处理器,其内存事务的中断行为直接影响系统可靠性。当处理器核心响应中断异常时,按照Armv7-R架构规范,…...

融合FIWARE与TinyML:构建工业级边缘智能的MLOps系统工程实践
1. 项目概述:当边缘智能遇见工业级平台在物联网项目里摸爬滚打十几年,我见过太多这样的场景:传感器数据源源不断地上传到云端,一个简单的“开”或“关”的决策,需要经过网络传输、云端服务器处理、再传回指令ÿ…...

SSH连接报kex_exchange_identification的4步根因定位法
1. 这个报错不是SSH客户端的问题,而是服务器在“拒之门外” “kex_exchange_identification”——这串字符第一次出现在终端里时,我正帮一位刚转行做运维的同事排查一台新部署的Ubuntu云服务器。他反复执行 ssh userip ,每次都在输入密码前…...