Kafka基础入门篇(深度好文)
Kafka简介
Kafka 是一个高吞吐量的分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用与大数据实时处理领域。
1. 以时间复杂度为O(1)的方式提供消息持久化能力。
2. 高吞吐率。(Kafka 的吞吐量是MySQL 吞吐量的30-40倍,并且Kafka的扩展性远高于MySQL)
3. 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输,同时支持离线数据处理和实时数据处理。
Kafka架构演变
JMS架构
- JAVA中可以根据JMS(Java Message Service)实现在多个应用程序之间的消息传递,它类似于JDBC,提供一种和厂商无关的公共API,通过标准的生产、发送、接收消息的接口简化企业应用的开发。
- JMS消息有两种类型:
点对点(Point-to-Point):消息分发给一个单独的使用者。
发布/订阅(Publish/Subscribe):生产者发布事件,而使用者订阅感兴趣的事件,并使用事件。该类型消息一般与特定的主题**(Topic)**关联。
可以用下面的图表示一下JMS的两种消息模型
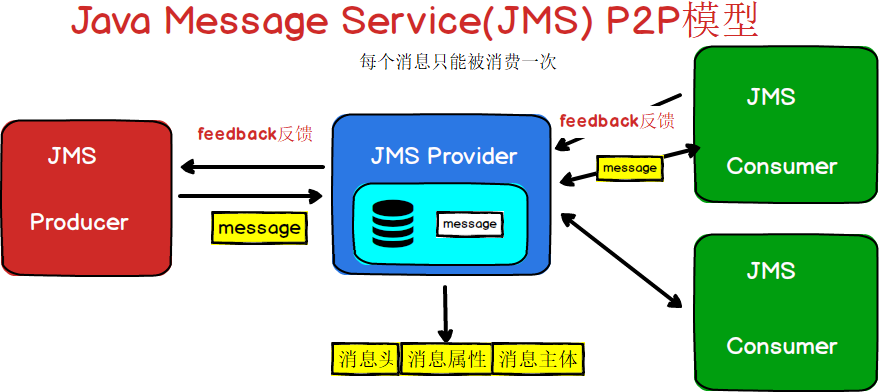
图1
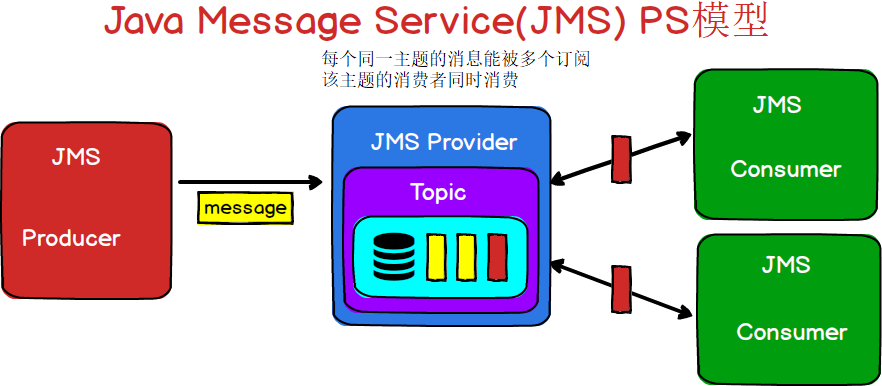
图2
Kafka架构
我们常听到的几个消息中间,例如:RabbitMQ、RocketMQ、ActiveMQ、Kafka。
那么为什么Kafka不叫KafkaMQ呢?
因为其他几个MQ基本上都遵循了JMS的协议,而Kafka虽然也借鉴了JMS的思想,但是呢,它又并没有完全的遵循JMS的设计。
下面我们根据我们对JMS的分析,来看下Kafka具备的特点:
- 在Kafka中,使用的是发布/订阅模式
- 在Kafka中,传递的消息被称为record对象
- 在Kafka中,通过启动一个独立的进程来提供消息的临时存储,由于这个进程只是用来进行消息的传递,并不会对数据进行修改,所以我们将这个进程可以看做是一个代理或者中介。也就是一个Broker
- 在Kafka中,也是通过主题(Topic)对消息进行分类。
- 在Kafka中,为了保证数据的安全性,将消息也会保存到磁盘文件中。基于早起的Kafka就是用来做日志传输的,所以Kafka用来持久化的文件都是以 .log结尾的。
- 在Kafka中,为了保证消息的有序性,在同一个主题下的消息都会分配一个类似于数组索引的标记,记作:偏移量(offset),它是从O开始的。
那么,通过上面的了解,我们可以得到一个简易版的Kafka结构
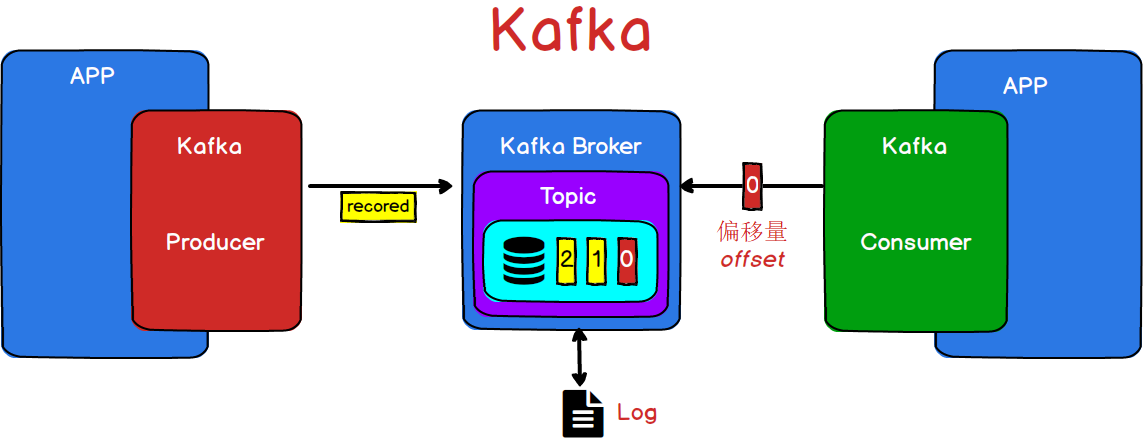
图3
看到图3这个图,是不是感觉对Kafka已经有了基本的了解,那么我们思考一个问题。
Kafka既然一直以单机10万级的高吞吐量而闻名,上面的这个架构明显无法满足其要求,那么它是如何实现的呢?
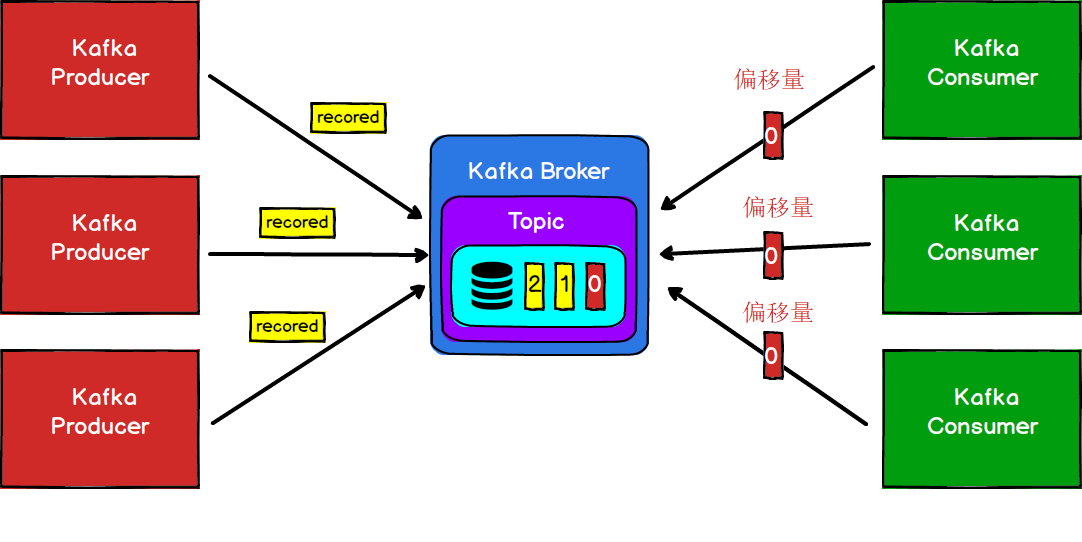
图4
一般情况下我们的生产者和消费者都会有多个,就像图4一样。但是这样的话,一旦大量的请求同事访问同一个Broker势必会造成IO热点问题,从而造成单一的Broker成为其性能瓶颈。甚至当Broker节点宕机以后,造成数据的丢失。
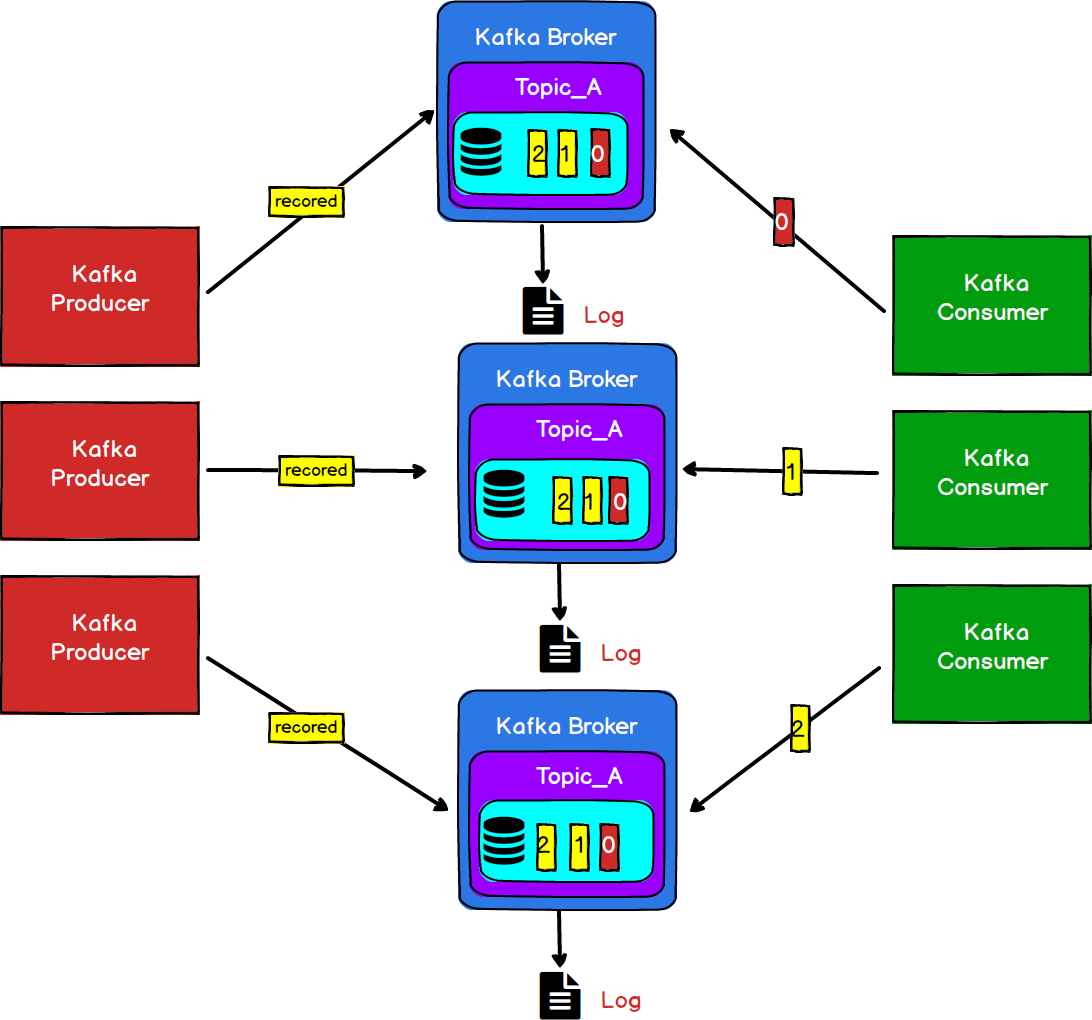
图5
我们通常会采用横向扩展(增加服务节点,搭建服务器集群)的方式来降低单点服务器故障带来的风险。如图5所示。
这样的设计确实可以缓解一部分服务器的压力,但是我们知道,在Kafka中是根据Topic来区分消息的,如果我们的多个生产者和消费者都需要订阅同一个Topic,那么我们全部的请求是不是还是都请求到一个同一个Broker上了,这样还是会造同样的性能瓶颈。
我们看下Kafka是怎么做的。(重点)
Kafka中,会把一个大的Topic分配到不同的Broker上,也就是说在不同的Broker中保存的是同一个Topic中的数据,Kafka把不同Broker中存放同一个Topic的数据的区域叫做Partition,也叫做分区,本质是一个有序的队列。同时为了区分同一个Topi下不同Broker中的Partition,会给每一个Partition进行编号。
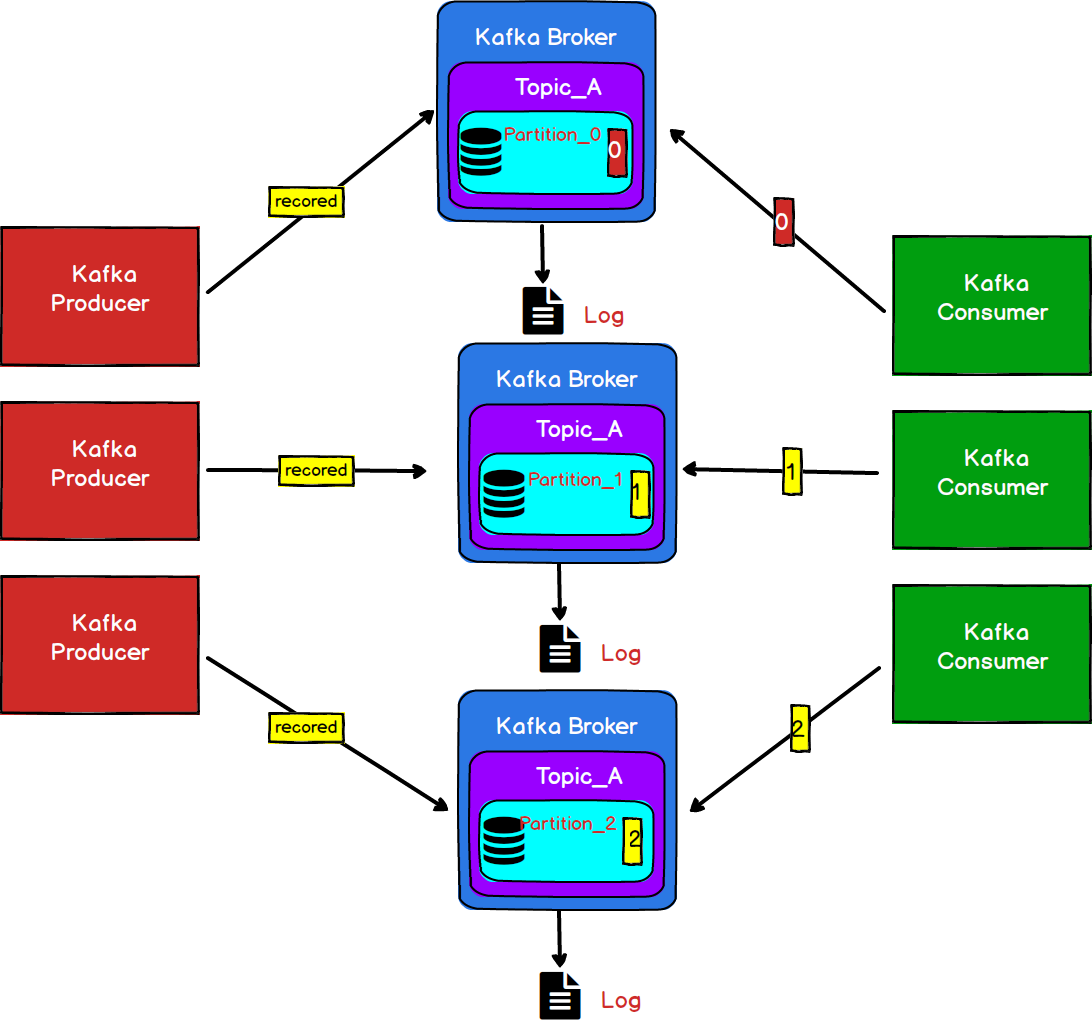
图6
这样,我们的生产者就可以将消息发送到不同的分区,同理,消费者也可以从不同的分区上对消息进行消费,是不是就能够极大地降低了单个节点的IO次数。
上面的结构虽然能够降低我们单个Broker的压力,但是,每个消费者只是消费了固定分区的数据,也就是说消费者虽然订阅了同一个主题,但是并没有去消费一个完整的Topic的数据,这样肯定不行的,我们必须要保证每一个消费者都能消费到完整的topic的消息。
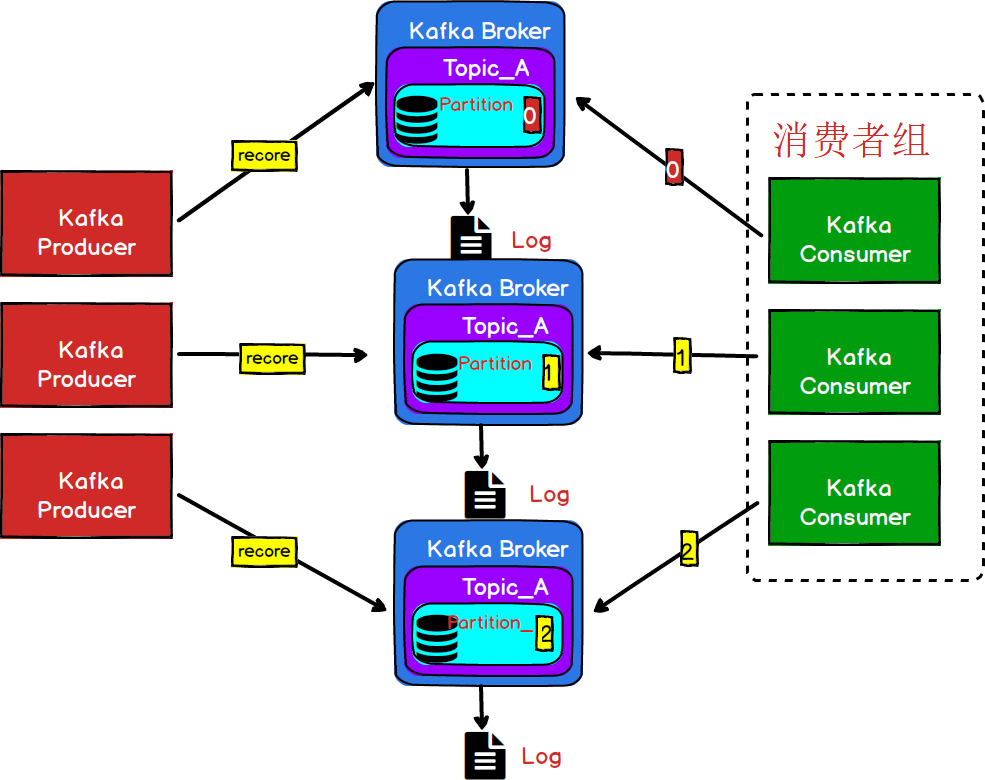
图7
为了解决消费者能够完整的消费同一个Topic下不同分区的数据,Kafka引入了消费者组(Consumer Grop)的概念。保证多个分区的消息能够被同一个消费者组消费。
- 消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- **消费者组之间互不影响。**所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
我们了解了Kafka在生产者和消费者之间的关系,那么作为一个消息中间件,保证消息的可靠性和完整无疑是非常重要的。目前的架构中,虽然每一个Broker节点都会有一个.log的文件用于数据的持久化,但是如果其中一个Broker节点宕机,那么这个节点下的.log文件肯定也就无法被加载了。所以,仅仅将消息持久化到磁盘文件中,还是无法保证数据的完整性。
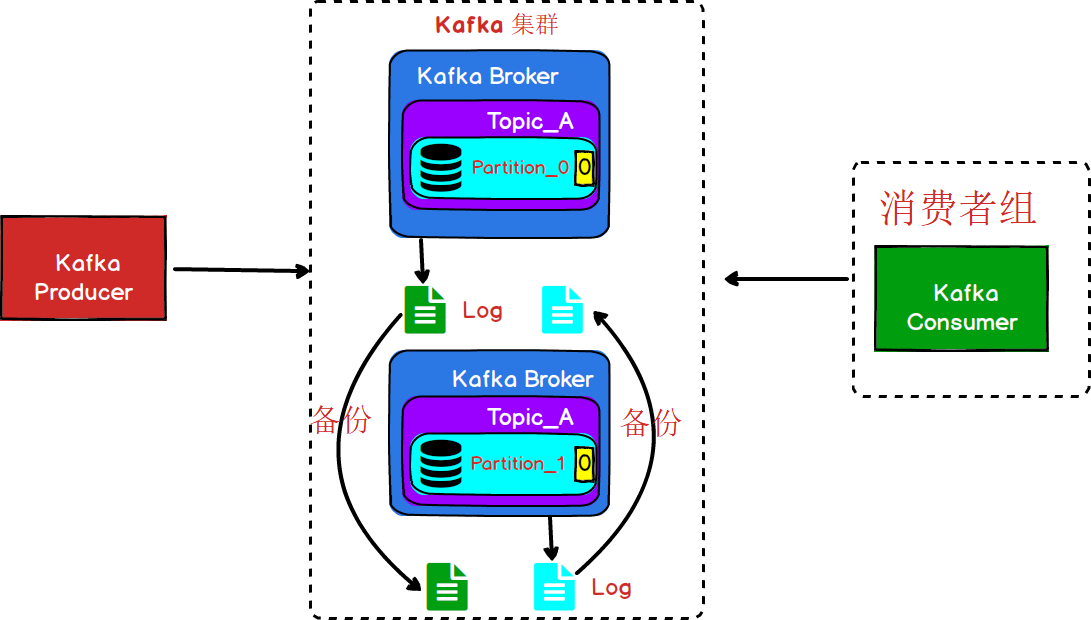
图8
从图8中我们可以看到,Kafka中其实是采用的备份的机制,但是并不是在同一个Broker进行备份,这种方式下的备份,及时某一个Broker宕机了,其他的Broker节点还是会有完整的数据。(这种备份机制一般都会满足一个条件,备份数量<=集群中Broker数量-1,就像图8的情况,集群中有2个节点,如果每个节点的备份数量>1是没有意义的。因为任何一个节点的宕机,无论备份多少份数据都是无法被读取的。)
- 为了数据的可靠性,可以将数据文件进行备份,但是Kafka中没有备份的概念,Kafka中称之为副本。
- 多个副本中,同时只能有一个提供数据的读写操作。其他文件只是用来作备份。
- 具有读写能力的副本被称作Leader,作为备份的的副本称之为Follower副本。
Kafka基础组件
下面总结了Kafka一些重要组件概念,帮组大家对Kafka有个整体的认识和感知。
-
**Producer:**即消息生产者,向Kafka Broker 发消息的客户端。
-
**Consumer:**即消息消费者,从 Kafka Broker 读消息的客户端。
-
**Broker:**一台 Kafka 机器就是一个 Broker。一个集群是由多个 Broker 组成的且一个 Broker 可以容纳多个 Topic。
-
**Topic:**可以简单理解为队列,Topic 将消息分类,生产者和消费者面向的都是同一个 Topic。
-
**Partition:**为了实现Topic扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker 上,一个 Topic 可以分为多个 Partition 进行存储,每个 Partition 是一个有序的队列。
-
**Consumer Group:**即消费者组,消费者组内每个消费者负责消费不同分区的数据,以提高消费能力。一个分区只能由组内一个消费者消费,不同消费者组之间互不影响。
-
**Replica:**即副本,为实现数据备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,为此Kafka提供了副本机制,一个 Topic 的每个 Partition 都有若干个副本,一个 Leader 副本和若干个 Follower 副本。
-
**Leader:**即每个分区多个副本的主副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。
-
**Follower:**即每个分区多个副本的从副本,会实时从 Leader 副本中同步数据,并保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会被选举并成为新的 Leader , 且不能跟 Leader 在同一个broker上, 防止崩溃数据可恢复。
-
**Offset:**消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
点击下方名片,关注『编程青衫客』
随时随地获取最新好文章!
相关文章:
Kafka基础入门篇(深度好文)
Kafka简介 Kafka 是一个高吞吐量的分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用与大数据实时处理领域。 1. 以时间复杂度为O(1)的方式提供消息持久化能力。 2. 高吞吐率。(Kafka 的吞吐量是MySQL 吞吐量的30…...

C++之复合资料型态KU网址第二部V蒐NAY3989
结构 结构可存放不同资料型态的数值,例如 #include <iostream>struct Demo {int member1;char *member2;float member3; };int main() {Demo d;d.member1 19823;d.member2 "203";d.member3 3.011;std::cout << "member1: " &l…...

乡镇集装箱生活污水处理设备处理效率高
乡镇集装箱生活污水处理设备处理效率高 乡镇集装箱生活污水处理设备优势 结构紧凑:集装箱式设计减少了占地面积,便于在土地资源紧张的乡镇地区部署。 安装方便:设备出厂前已完成组装和调试,现场只需进行简单的连接和调试即可投入使…...

计算机网络高频面试题
从输入URL到展现页面的全过程: 用户在浏览器中输入URL。浏览器解析URL,确定协议、主机名和路径。浏览器查找本地DNS缓存,如果没有找到,向DNS服务器发起查询请求。DNS服务器解析主机名,返回IP地址。浏览器使用IP地址建立…...

进程通信(1):无名管道(pipe)
无名管道(pipe)用来具有亲缘关系的进程之间进行单向通信。半双工的通信方式,数据只能单向流动。 管道以字节流的方式通信,数据格式由用户自行定义。 无名管道多用于父子进程间通信,也可用于其他亲缘关系进程间通信。 因为父进程调用fork函…...

YOLOv10改进 | 损失函数篇 | SlideLoss、FocalLoss、VFLoss分类损失函数助力细节涨点(全网最全)
一、本文介绍 本文给大家带来的是分类损失 SlideLoss、VFLoss、FocalLoss损失函数,我们之前看那的那些IoU都是边界框回归损失,和本文的修改内容并不冲突,所以大家可以知道损失函数分为两种一种是分类损失另一种是边界框回归损失,…...
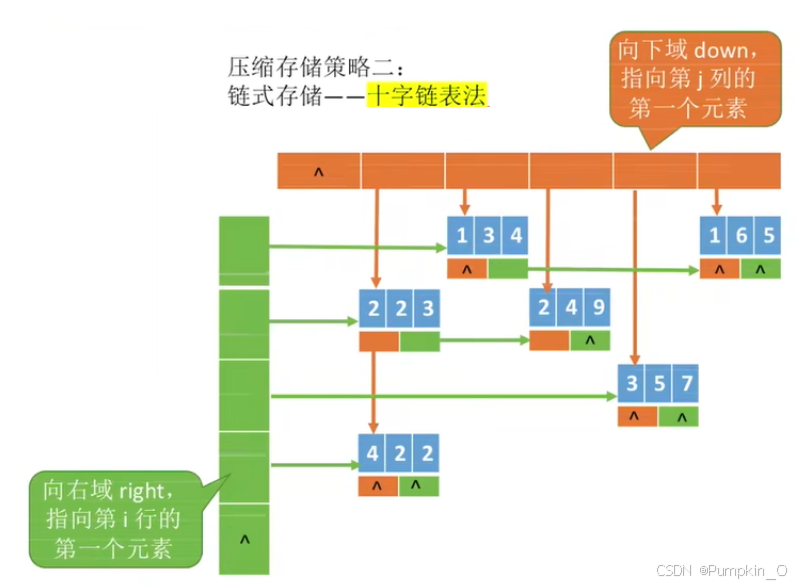
【数组、特殊矩阵的压缩存储】
目录 一、数组1.1、一维数组1.1.1 、一维数组的定义方式1.1.2、一维数组的数组名 1.2、二维数组1.2.1、二维数组的定义方式1.2.2、二维数组的数组名 二、对称矩阵的压缩存储三、三角矩阵的压缩存储四、三对角矩阵的压缩存储五、稀疏矩阵的压缩存储 一、数组 概述:数…...

Flat Ads:金融APP海外广告投放素材的优化指南
在当今全球化的数字营销环境中,金融APP的海外营销推广已成为众多金融机构与开发者最为关注的环节之一。面对不同地域、文化及用户习惯的挑战,如何优化广告素材,以吸引目标受众的注意并促成有效转化,成为了广告主们亟待解决的问题。 作为领先的全球化营销推广平台,Flat Ads凭借…...
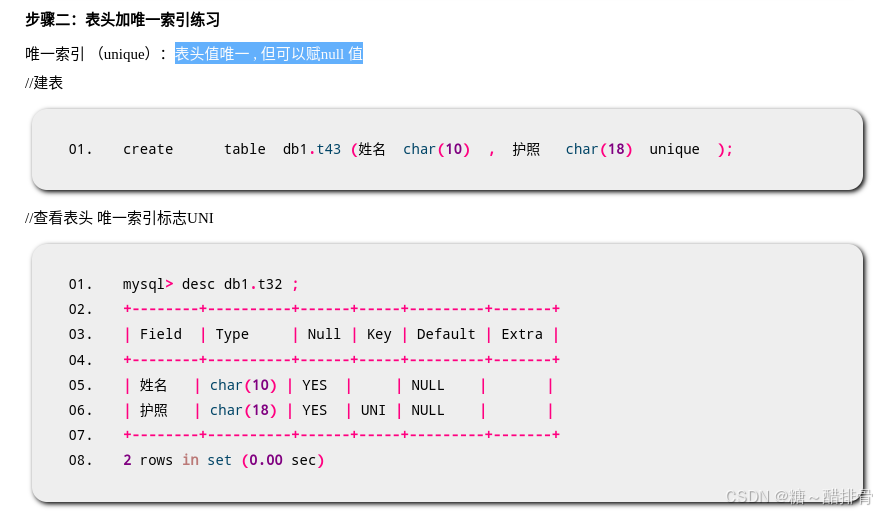
DBA 数据库管理 表管理 数据批量处理。表头约束
表管理 建库 库名命名规则:仅可以使用数字、字母、下划线、不能纯数字 不可使用MySQL命令或特殊字符 库名区分字母大小写 加if not exists 命令避免重名报错 create database if not exists gamedb; 建表 drop database if exists gamedb ; 删表…...
C# 上位机开发之旅-委托事件的那些事[2]
上位机项目开发过程,应该不少遇见界面同步实时刷新的情况,设备的运行情况以及设备数据的实时更新,应用场景非常之多。 那么这个时候,我们就可以用到C#语言中的一些关键功能来实现,比如事件,委托,…...
浏览器出现 502 Bad Gateway的原理分析以及解决方法
目录 前言1. 问题所示2. 原理分析3. 解决方法 前言 此类问题主要作为疑难杂症 1. 问题所示 2. 原理分析 502 Bad Gateway 错误表示服务器作为网关或代理时,从上游服务器收到了无效的响应 通常出现在充当代理或网关的网络服务器上,例如 Nginx、Apache…...
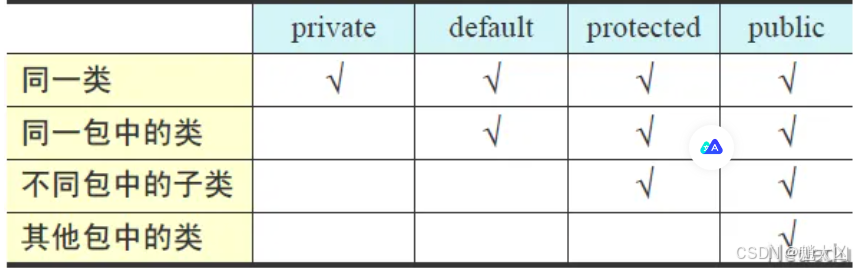
Java的高级特性
类的继承 继承是从已有的类中派生出新的类,新的类能拥有已有类的属性和行为,并且可以拓展新的属性和行为 public class 子类 extends 父类{子类类体 } 优点 代码的复用 提高编码效率 易于维护 使类与类产生关联,是多态的前提 缺点 类缺乏独…...

pip install selenium异常
error: externally-managed-environment This environment is externally managed ╰─> To install Python packages system-wide, try brew install xyz, where xyz is the package you are trying to install. If you wish to install a Python library that isnt in Ho…...

应急响应总结
应急响应 日志 windows IIS 6.0 及更早版本: C:\WINDOWS\system32\LogFiles\W3SVC[SiteID]\ IIS 7.0 及更高版本: C:\inetpub\logs\LogFiles\W3SVC[SiteID]\ Apache HTTP Server C:\Program Files (x86)\Apache Group\Apache2\logs\ 或者 C:\Prog…...
)
一些资源(●ˇ∀ˇ●)
GPT Kimi.ai - 帮你看更大的世界 (moonshot.cn) 文心一言 (baidu.com) 搜索AI伙伴 (baidu.com) 讯飞星火大模型-AI大语言模型-星火大模型-科大讯飞 (xfyun.cn) 秘塔AI搜索 (metaso.cn) GitHub打不开 下载Watt Toolkit...
WGCLOUD的ping设备监测可以导入excel数据吗
可以的 WGCLOUD的v3.5.3版本,已经支持导入excel数据,如下说明 数通设备PING监测使用说明 - WGCLOUD...

vue 画二维码及长按保存
需求 想要做如下图的二维码带文字,且能够长按保存 前期准备 一个canvas安装qrcode(命令:npm i qrcode) 画二维码及文字 初始化画布 <template><div><canvas ref"canvas" width"300" he…...
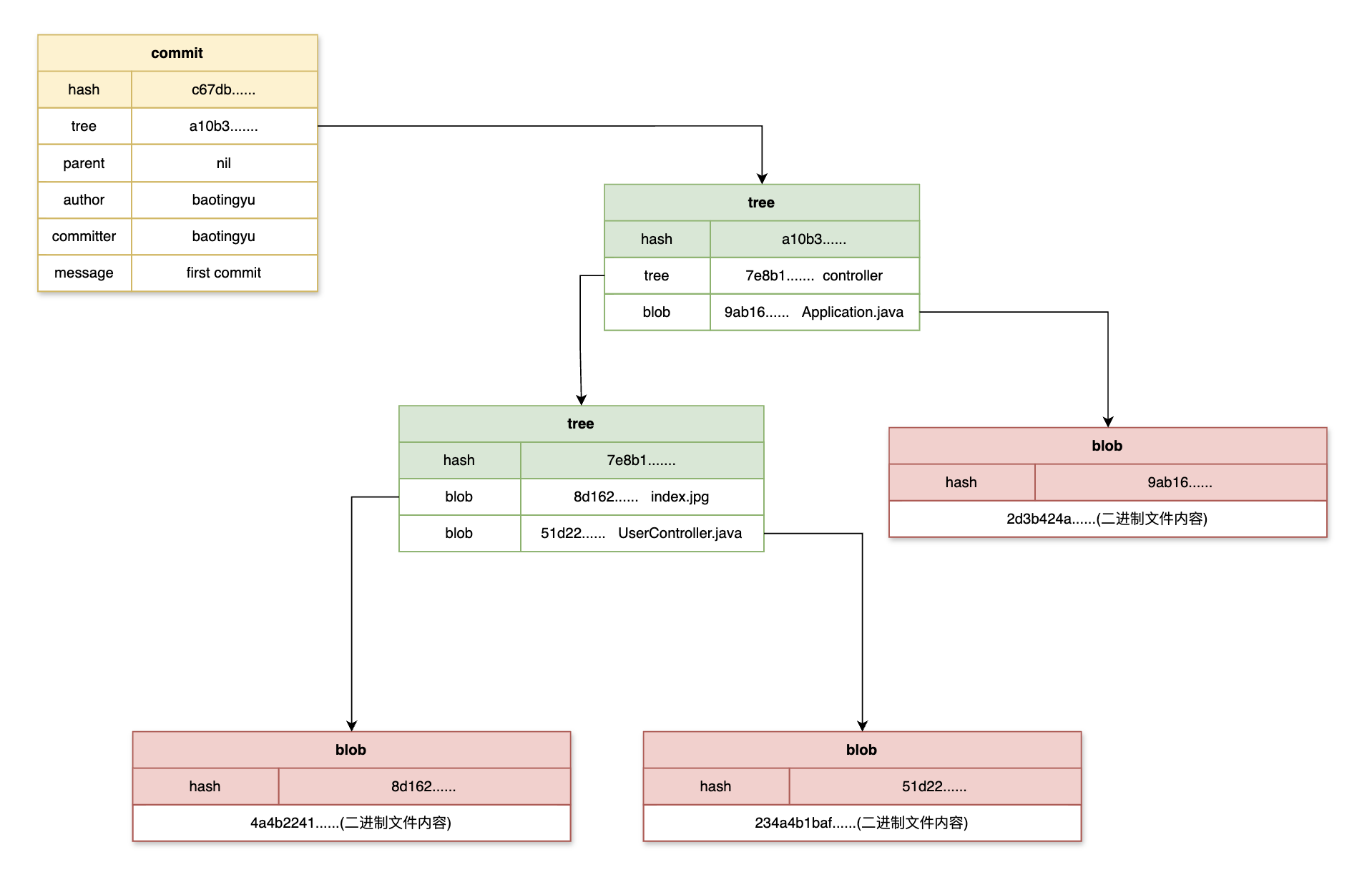
IDEA中Git常用操作及Git存储原理
Git简介与使用 Intro Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency. Git是一款分布式版本控制系统(VSC),是团队合作开发…...
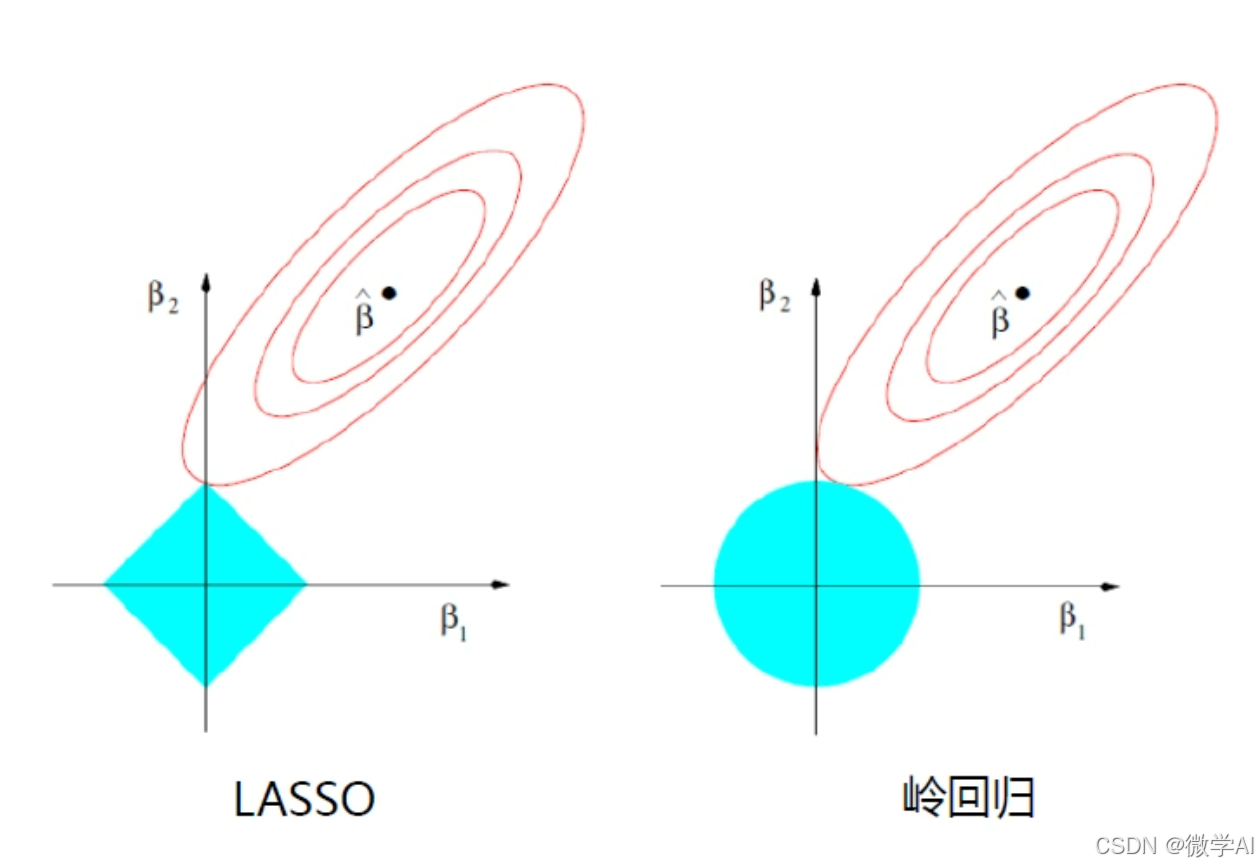
人工智能算法工程师(中级)课程4-sklearn机器学习之回归问题与代码详解
大家好,我是微学AI,今天给大家介绍一下人工智能算法工程师(中级)课程4-sklearn机器学习之回归问题与代码详解。回归分析是统计学和机器学习中的一种重要方法,用于研究因变量和自变量之间的关系。在机器学习中,回归算法被广泛应用于…...

智能制造热点词汇科普篇——工业微服务
随着互联网技术的不断发展,近十年来,微服务也逐渐走进人们的视线中来。何为微服务?让我们先来看看百度百科上的定义:微服务(或称微服务架构)是一种云原生架构方法,在单个应用中包含众多松散耦合…...

3步搞定B站m4s转MP4:开源工具让你的缓存视频重获新生
3步搞定B站m4s转MP4:开源工具让你的缓存视频重获新生 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的烦恼&am…...

Chat2DB:基于插件化架构的AI驱动数据库管理平台技术解析
Chat2DB:基于插件化架构的AI驱动数据库管理平台技术解析 【免费下载链接】Chat2DB AI-driven database tool and SQL client, The hottest GUI client, supporting MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, ClickHouse, and more. 项目地址…...
Informer2020:突破Transformer计算瓶颈,实现长序列时间预测的工业级解决方案
Informer2020:突破Transformer计算瓶颈,实现长序列时间预测的工业级解决方案 【免费下载链接】Informer2020 The GitHub repository for the paper "Informer" accepted by AAAI 2021. 项目地址: https://gitcode.com/gh_mirrors/in/Informe…...

Monitorian多显示器亮度管理终极指南:条件命令、定时任务与快捷键实战技巧
Monitorian多显示器亮度管理终极指南:条件命令、定时任务与快捷键实战技巧 【免费下载链接】Monitorian A Windows desktop tool to adjust the brightness of multiple monitors with ease 项目地址: https://gitcode.com/gh_mirrors/mo/Monitorian 还在为多…...

Steam创意工坊下载器WorkshopDL:跨平台模组自由下载终极指南
Steam创意工坊下载器WorkshopDL:跨平台模组自由下载终极指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台上的游戏无法使用Steam创意工…...

WechatDecrypt终极指南:3步解锁你的微信聊天记忆
WechatDecrypt终极指南:3步解锁你的微信聊天记忆 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 你是否曾经有过这样的经历?换了新手机,却发现珍贵的微信聊天记录无法完…...

FuSa RTX RTOS多核支持与AMP架构解析
1. FuSa RTX RTOS多核支持解析 在嵌入式安全关键系统开发领域,多核处理器架构已成为提升性能的主流选择。作为Arm FuSa RTS(功能安全运行时系统)的核心组件,FuSa RTX RTOS的多核支持能力自然成为开发者关注的焦点。本文将深入剖析…...

arXiv开始拒收综述,CS新人发论文得找人背书
一水 发自 凹非寺量子位 | 公众号 QbitAI坏了!在arXiv发综述的门,已经被关上了。arXiv接收门槛收紧后,最新受害者已急哭:arXiv的审核越来越严格了。综述论文已经不再被允许发表了,计算机科学领域彻底完蛋了,…...

智慧树刷课插件:3分钟搞定网课,解放你的宝贵时间![特殊字符]
智慧树刷课插件:3分钟搞定网课,解放你的宝贵时间!🚀 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的…...

JMeter并发与持续性压测:从按钮操作到系统心跳诊断
1. 这不是“点几下就出报告”的玩具,而是压测工程师的听诊器很多人第一次打开 JMeter,以为它就是个高级版的 Postman:填个 URL、点个“启动”,等几秒弹出个 Summary Report,看到平均响应时间 86ms 就松一口气ÿ…...