Python酷库之旅-第三方库Pandas(022)
目录
一、用法精讲
55、pandas.lreshape函数
55-1、语法
55-2、参数
55-3、功能
55-4、返回值
55-5、说明
55-6、用法
55-6-1、数据准备
55-6-2、代码示例
55-6-3、结果输出
56、pandas.wide_to_long函数
56-1、语法
56-2、参数
56-3、功能
56-4、返回值
56-5、说明
56-6、用法
56-6-1、数据准备
56-6-2、代码示例
56-6-3、结果输出
57、pandas.isna函数
57-1、语法
57-2、参数
57-3、功能
57-4、返回值
57-5、说明
57-6、用法
57-6-1、数据准备
57-6-2、代码示例
57-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
55、pandas.lreshape函数
55-1、语法
# 55、pandas.lreshape函数
pandas.lreshape(data, groups, dropna=True)
Reshape wide-format data to long. Generalized inverse of DataFrame.pivot.Accepts a dictionary, groups, in which each key is a new column name and each value is a list of old column names that will be “melted” under the new column name as part of the reshape.Parameters:
data
DataFrame
The wide-format DataFrame.groups
dict
{new_name : list_of_columns}.dropna
bool, default True
Do not include columns whose entries are all NaN.Returns:
DataFrame
Reshaped DataFrame.55-2、参数
55-2-1、data(必须):要进行重塑的Pandas数据框。
55-2-2、groups(必须):一个字典,用于指定要重塑的列组,字典的键是新列的名称,值是要重塑的列列表,例如:{'A': ['A1', 'A2'], 'B': ['B1', 'B2']}。
55-2-3、dropna(可选,默认值为True):指定是否在重塑过程中丢弃包含NaN的行,如果设置为True,则会丢弃包含NaN的行;如果设置为False,则保留NaN。
55-3、功能
根据指定的列组对数据框进行重塑,将宽格式的数据转换为长格式。
55-4、返回值
返回一个重塑后的Pandas数据框,其中包含从宽格式转换为长格式的数据。
55-5、说明
Pandas.Ireshape是一个强大的工具,可以根据指定的列组对数据框进行宽转长的重塑,它具有三个参数:
55-5-1、data:要重塑的DataFrame。
55-5-2、groups:一个字典,定义新的列组。
55-5-3、dropna:指定是否丢弃包含NaN的行。
通过理解和正确使用这些参数,可以灵活地重塑数据框,从而更好地组织和分析数据。
55-6、用法
55-6-1、数据准备
无55-6-2、代码示例
# 55、pandas.lreshape函数
import pandas as pd
# 创建示例数据框
data = pd.DataFrame({'A1': [1, 2, 3],'A2': [4, 5, 6],'B1': ['a', 'b', 'c'],'B2': ['d', 'e', 'f']
})
# 定义列组
groups = {'A': ['A1', 'A2'],'B': ['B1', 'B2']
}
# 使用pandas.lreshape进行重塑
reshaped = pd.lreshape(data, groups)
print(reshaped)55-6-3、结果输出
# 55、pandas.lreshape函数
# A B
# 0 1 a
# 1 2 b
# 2 3 c
# 3 4 d
# 4 5 e
# 5 6 f56、pandas.wide_to_long函数
56-1、语法
# 56、pandas.wide_to_long函数
pandas.wide_to_long(df, stubnames, i, j, sep='', suffix='\\d+')
Unpivot a DataFrame from wide to long format.Less flexible but more user-friendly than melt.With stubnames [‘A’, ‘B’], this function expects to find one or more group of columns with format A-suffix1, A-suffix2,…, B-suffix1, B-suffix2,… You specify what you want to call this suffix in the resulting long format with j (for example j=’year’)Each row of these wide variables are assumed to be uniquely identified by i (can be a single column name or a list of column names)All remaining variables in the data frame are left intact.Parameters:
df
DataFrame
The wide-format DataFrame.stubnames
str or list-like
The stub name(s). The wide format variables are assumed to start with the stub names.i
str or list-like
Column(s) to use as id variable(s).j
str
The name of the sub-observation variable. What you wish to name your suffix in the long format.sep
str, default “”
A character indicating the separation of the variable names in the wide format, to be stripped from the names in the long format. For example, if your column names are A-suffix1, A-suffix2, you can strip the hyphen by specifying sep=’-’.suffix
str, default ‘\d+’
A regular expression capturing the wanted suffixes. ‘\d+’ captures numeric suffixes. Suffixes with no numbers could be specified with the negated character class ‘\D+’. You can also further disambiguate suffixes, for example, if your wide variables are of the form A-one, B-two,.., and you have an unrelated column A-rating, you can ignore the last one by specifying suffix=’(!?one|two)’. When all suffixes are numeric, they are cast to int64/float64.Returns:
DataFrame
A DataFrame that contains each stub name as a variable, with new index (i, j).56-2、参数
56-2-1、df(必须):要进行重塑的Pandas数据框。
56-2-2、stubnames(必须):列名前缀的列表,这些列将被转换为长格式。比如,如果列名是A1970, A1980, B1970, B1980,那么stubnames应该是['A', 'B']。
56-2-3、i(必须):表示唯一标识每一行的列名或列名列表,重塑后的每一行将保留这些列。
56-2-4、j(必须):新列的名称,这列将包含从宽格式中提取的时间或编号信息。例如,'year'可以作为j。
56-2-5、sep(可选,默认值为''):列名中stubnames和j部分之间的分隔符。例如,如果列名是A-1970,那么sep应该是'-'。
56-2-6、suffix(可选,默认值为'\\d+'):stubnames后缀的正则表达式模式,用于匹配列名中的时间或编号部分,默认情况下,匹配一个或多个数字。
56-3、功能
用于将数据从宽格式(wide format)转换为长格式(long format),这个函数特别适用于处理时间序列数据或面板数据。
56-4、返回值
返回一个重塑后的Pandas数据框,其中包含从宽格式转换为长格式的数据。
56-5、说明
Pandas.wide_to_long是一个强大的工具,可以通过指定列名前缀、标识列、时间或编号列来将宽格式的数据转换为长格式。它具有以下参数:
56-5-1、df:要重塑的DataFrame。
56-5-2、stubnames:列名前缀列表。
56-5-3、i:唯一标识每一行的列名或列名列表。
56-5-4、j:新列的名称,用于包含时间或编号信息。
56-5-5、sep:列名中前缀和时间/编号部分之间的分隔符。
56-5-6、suffix:匹配时间或编号部分的正则表达式模式。
理解并正确使用这些参数,可以灵活地重塑数据框,以便更好地进行数据分析和处理。
56-6、用法
56-6-1、数据准备
无56-6-2、代码示例
# 56、pandas.wide_to_long函数
import pandas as pd
# 创建示例数据框
df = pd.DataFrame({'id': [1, 2, 3],'A1970': [2.5, 1.5, 3.0],'A1980': [2.0, 1.0, 3.5],'B1970': [3.0, 2.0, 4.0],'B1980': [3.5, 2.5, 4.5]
})
# 使用pandas.wide_to_long进行重塑
df_long = pd.wide_to_long(df, stubnames=['A', 'B'], i='id', j='year', sep='', suffix='\\d+')
print(df_long)56-6-3、结果输出
# 56、pandas.wide_to_long函数
# A B
# id year
# 1 1970 2.5 3.0
# 2 1970 1.5 2.0
# 3 1970 3.0 4.0
# 1 1980 2.0 3.5
# 2 1980 1.0 2.5
# 3 1980 3.5 4.557、pandas.isna函数
57-1、语法
# 57、pandas.isna函数
pandas.isna(obj)
Detect missing values for an array-like object.This function takes a scalar or array-like object and indicates whether values are missing (NaN in numeric arrays, None or NaN in object arrays, NaT in datetimelike).Parameters:
obj
scalar or array-like
Object to check for null or missing values.Returns:
bool or array-like of bool
For scalar input, returns a scalar boolean. For array input, returns an array of boolean indicating whether each corresponding element is missing.57-2、参数
57-2-1、obj(必须):要检查缺失值的对象,可以是单个标量值、数组、Series、DataFrame或其他类似的pandas对象。
57-3、功能
用于检测缺失值,NA值在Pandas中表示缺失或无效的数据。
57-4、返回值
返回一个布尔型对象,与输入obj具有相同的形状,布尔型对象中的True表示对应位置的值为缺失值,False表示不是缺失值。
57-5、说明
pandas.isna(obj)是一个非常实用的函数,用于检测任何pandas对象中的缺失值,它适用于单个值、数组、Series和DataFrame等多种类型的数据结构,返回的布尔型对象可以用于进一步的数据清洗和处理操作。
57-6、用法
57-6-1、数据准备
无57-6-2、代码示例
# 57、pandas.isna函数
# 57-1、检查单个标量值
import pandas as pd
import numpy as np
print(pd.isna(np.nan))
print(pd.isna(3.14))
print(pd.isna(None), end='\n\n')# 57-2、检查Series
import pandas as pd
# 创建一个Series
s = pd.Series([1, 2, np.nan, 4, None])
# 检查Series中的缺失值
print(pd.isna(s), end='\n\n')# 57-3、检查DataFrame
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({'A': [1, 2, np.nan],'B': [np.nan, 4, 5],'C': [1, np.nan, np.nan]
})
# 检查DataFrame中的缺失值
print(pd.isna(df))57-6-3、结果输出
# 57、pandas.isna函数
# 57-1、检查单个标量值
# True
# False
# True# 57-2、检查Series
# 0 False
# 1 False
# 2 True
# 3 False
# 4 True
# dtype: bool# 57-3、检查DataFrame
# A B C
# 0 False True False
# 1 False False True
# 2 True False True二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
相关文章:
Python酷库之旅-第三方库Pandas(022)
目录 一、用法精讲 55、pandas.lreshape函数 55-1、语法 55-2、参数 55-3、功能 55-4、返回值 55-5、说明 55-6、用法 55-6-1、数据准备 55-6-2、代码示例 55-6-3、结果输出 56、pandas.wide_to_long函数 56-1、语法 56-2、参数 56-3、功能 56-4、返回值 56-5…...

数据建设实践之大数据平台(一)准备环境
大数据组件版本信息 zookeeper-3.5.7hadoop-3.3.5mysql-5.7.28apache-hive-3.1.3spark-3.3.1dataxapache-dolphinscheduler-3.1.9大数据技术架构 大数据组件部署规划 node101node102node103node104node105datax datax datax ZK ZK ZK RM RM NM...

VUE2用elementUI实现父组件中校验子组件中的表单
需求是VUE2框架用elementUI写复杂表单组件,比如,3个相同功能的表单共用一个提交按钮,把相同功能的表单写成一个子组件,另一个父组件包含子组件的重复调用和一个提交按钮,并且要求提交时校验必填项。 注意: …...

人工智能算法工程师(中级)课程9-PyTorch神经网络之全连接神经网络实战与代码详解
大家好,我是微学AI,今天给大家介绍一下人工智能算法工程师(中级)课程9-PyTorch神经网络之全连接神经网络实战与代码详解。本文将给大家展示全连接神经网络与代码详解,包括全连接模型的设计、数学原理介绍,并从手写数字识别到猫狗识…...

UDP网络通信(发送端+接收端)实例 —— Python
简介 在网络通信编程中,用的最多的就是UDP和TCP通信了,原理这里就不分析了,网上介绍也很多,这里简单列举一下各自的优缺点和使用场景 通信方式优点缺点适用场景UDP及时性好,快速视网络情况,存在丢包 与嵌入…...
:缩放点积注意力机制)
从零开始实现大语言模型(五):缩放点积注意力机制
1. 前言 缩放点积注意力机制(scaled dot-product attention)是OpenAI的GPT系列大语言模型所使用的多头注意力机制(multi-head attention)的核心,其目标与前文所述简单自注意力机制完全相同,即输入向量序列 x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x...

PTA 7-15 希尔排序
本题目要求读入N个整数,采用希尔排序法进行排序,采用增量序列{5,3,1},输出完成增量5和增量3后的5子排序和3子排序结果。 输入格式: 输入不超过100的正整数N和N个整数(空格分隔)。 输出格式: …...

【密码学】分组密码的设计原则
分组密码设计的目标是在密钥控制下,从一个巨大的置换集合中高效地选取一个置换,用于加密给定的明文块。 一、混淆原则 混淆原则是密码学中一个至关重要的概念,由克劳德香农提出。混淆原则就是将密文、明文、密钥三者之间的统计关系和代数关系…...

深入解析【C++ list 容器】:高效数据管理的秘密武器
目录 1. list 的介绍及使用 1.1 list 的介绍 知识点: 小李的理解: 1.2 list 的使用 1.2.1 list 的构造 知识点: 小李的理解: 代码示例: 1.2.2 list 迭代器的使用 知识点: 小李的理解࿱…...

NFS服务器、autofs自动挂载综合实验
综合实验 现有主机 node01 和 node02,完成如下需求: 1、在 node01 主机上提供 DNS 和 WEB 服务 2、dns 服务提供本实验所有主机名解析 3、web服务提供 www.rhce.com 虚拟主机 4、该虚拟主机的documentroot目录在 /nfs/rhce 目录 5、该目录由 node02 主机…...

自动驾驶事故频发,安全痛点在哪里?
大数据产业创新服务媒体 ——聚焦数据 改变商业 近日,武汉城市留言板上出现了多条关于萝卜快跑的投诉,多名市民反映萝卜快跑出现无故停在马路中间、高架上占最左道低速行驶、转弯卡着不动等情况,导致早晚高峰时段出现拥堵。萝卜快跑是百度 A…...

SpringSecurity框架【认证】
目录 一. 快速入门 二. 认证 2.1 登陆校验流程 2.2 原理初探 2.3 解决问题 2.3.1 思路分析 2.3.2 准备工作 2.3.3 实现 2.3.3.1 数据库校验用户 2.3.3.2 密码加密存储 2.3.3.3 登录接口 2.3.3.4 认证过滤器 2.3.3.5 退出登录 Spring Security是Spring家族中的一个…...

python安全脚本开发简单思路
文章目录 为什么选择python作为安全脚本开发语言如何编写人生第一个安全脚本开发后续学习 为什么选择python作为安全脚本开发语言 易读性和易维护性:Python以其简洁的语法和清晰的代码结构著称,这使得它非常易于阅读和维护。在安全领域,代码…...

WPF学习(4) -- 数据模板
一、DataTemplate 在WPF(Windows Presentation Foundation)中,DataTemplate 用于定义数据的可视化呈现方式。它允许你自定义如何展示数据对象,从而实现更灵活和丰富的用户界面。DataTemplate 通常用于控件(如ListBox、…...

GuLi商城-商品服务-API-品牌管理-JSR303分组校验
注解:@Validated 实体类: package com.nanjing.gulimall.product.entity;import com.baomidou.mybatisplus.annotation.TableId; import com.baomidou.mybatisplus.annotation.TableName; import com.nanjing.common.valid.ListValue; import com.nanjing.common.valid.Updat…...

PyTorch DataLoader 学习
1. DataLoader的核心概念 DataLoader是PyTorch中一个重要的类,用于将数据集(dataset)和数据加载器(sampler)结合起来,以实现批量数据加载和处理。它可以高效地处理数据加载、多线程加载、批处理和数据增强…...
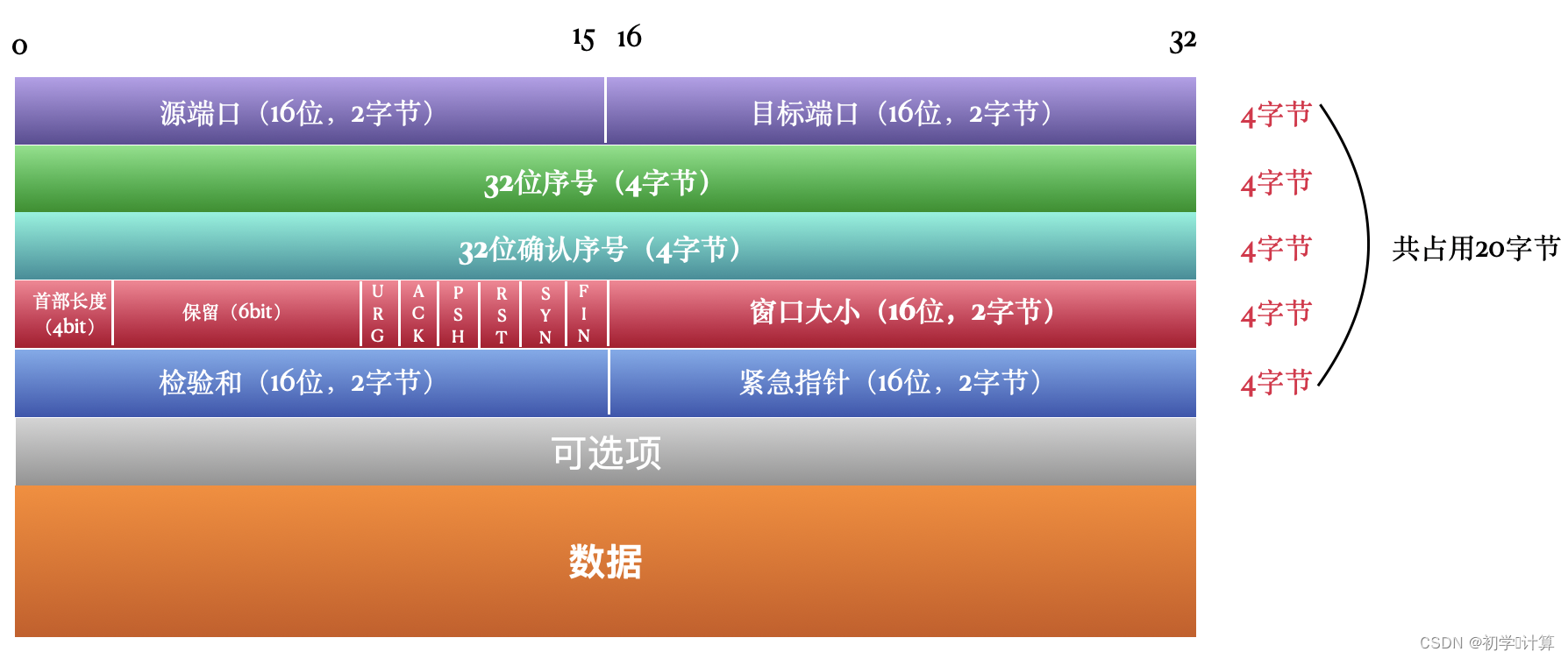
TCP传输控制协议二
TCP 是 TCP/IP 模型中的传输层一个最核心的协议,不仅如此,在整个 4 层模型中,它都是核心的协议,要不然模型怎么会叫做 TCP/IP 模型呢。 它向下使用网络层的 IP 协议,向上为 FTP、SMTP、POP3、SSH、Telnet、HTTP 等应用…...

【学习笔记】无人机(UAV)在3GPP系统中的增强支持(五)-同时支持无人机和eMBB用户数据传输的用例
引言 本文是3GPP TR 22.829 V17.1.0技术报告,专注于无人机(UAV)在3GPP系统中的增强支持。文章提出了多个无人机应用场景,分析了相应的能力要求,并建议了新的服务级别要求和关键性能指标(KPIs)。…...
使用F1C200S从零制作掌机之debian文件系统完善NES
一、模拟器源码 源码:https://files.cnblogs.com/files/twzy/arm-NES-linux-master.zip 二、文件系统 文件系统:debian bullseye 使用builtroot2018构建的文件系统,使用InfoNES模拟器存在bug,搞不定,所以放弃&…...

Vue 3 与 TypeScript:最佳实践详解
大家好,我是CodeQi! 很多人问我为什么要用TypeScript? 因为 Vue3 喜欢它! 开个玩笑... 在我们开始探索 Vue 3 和 TypeScript 最佳实践之前,让我们先打个比方。 如果你曾经尝试过在没有 GPS 的情况下开车到一个陌生的地方,你可能会知道那种迷失方向的感觉。 而 Typ…...

告别VNC客户端!用noVNC在浏览器里远程操控CentOS桌面,附Xshell/Xftp联动技巧
浏览器原生远程桌面方案:noVNC与终端工具链的高效整合指南每次连接远程服务器都要切换多个客户端的日子该结束了。想象一下这样的场景:清晨的咖啡馆里,你只需打开浏览器就能直接访问CentOS的图形界面,同时在一个标签页里用Xshell执…...

基于多保真度机器学习与飞秒激光的光子表面逆向设计实践
1. 项目概述与核心价值在光子学和先进制造领域,我们常常面临一个核心挑战:如何根据一个理想的光学性能目标,比如特定的光谱吸收或发射曲线,反向找到能够实现这一目标的精确物理结构或制造工艺参数。这就是逆向设计的魅力所在。传统…...

AMD Ryzen硬件调试神器:5分钟掌握SMU Debug Tool核心技巧
AMD Ryzen硬件调试神器:5分钟掌握SMU Debug Tool核心技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:/…...
)
Claude医学文献分析准确率实测:对比GPT-4o、Gemini 2.0与专业文献数据库(n=1,847篇RCT,Kappa=0.91)
更多请点击: https://codechina.net 第一章:Claude医学文献分析案例 在临床研究与循证医学实践中,研究人员常需从海量PubMed、NEJM或Lancet等来源的PDF或HTML格式文献中快速提取关键信息。Claude系列大模型凭借其长上下文(最高20…...

3分钟彻底清理Windows右键菜单!ContextMenuManager让你的效率提升200%
3分钟彻底清理Windows右键菜单!ContextMenuManager让你的效率提升200% 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是也遇到过这种情况&…...

Windows Cleaner深度解析:4步彻底解决C盘空间不足的完整技术方案
Windows Cleaner深度解析:4步彻底解决C盘空间不足的完整技术方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

量子核方法:从经典核技巧到量子特征映射的实践指南
1. 量子核方法:从理论到实践的跨越 核方法在机器学习领域已经是一个相当成熟的技术,它的核心魅力在于“核技巧”——通过一个巧妙的函数,我们可以在不显式计算高维甚至无限维特征向量的情况下,直接得到它们的内积。这让我们能用线…...

Burp Suite安装失败原因与Java环境配置全解
1. 为什么Burp Suite安装失败不是“运气差”,而是环境逻辑没对齐 Burp Suite安装问题总结——这标题听起来像一份运维日志,但实际是每个刚接触Web安全测试的人必经的“成人礼”。我带过十几期渗透测试实操班,92%的新手在第一天卡在Burp启动环…...

计算材料学驱动新型硅光伏材料发现:进化算法与机器学习融合设计
1. 项目概述:当计算材料学遇上光伏革命在光伏领域,硅材料长期占据着主导地位,这得益于其储量丰富、工艺成熟和稳定性好。然而,传统晶体硅(金刚石结构)一个众所周知的“阿喀琉斯之踵”是其间接带隙特性。这意…...

高熵合金熔化温度计算:EAM+MTP+FEP混合框架实现高精度低成本预测
1. 项目概述:为什么高熵合金的熔化温度计算是个“硬骨头”?在材料研发的前沿,高熵合金(HEAs)以其独特的“鸡尾酒效应”和优异的力学性能、耐腐蚀性及高温稳定性,吸引了无数研究者的目光。然而,当…...