神经网络识别数字图像案例
学习资料:从零设计并训练一个神经网络,你就能真正理解它了_哔哩哔哩_bilibili
这个视频讲得相当清楚。本文是学习笔记,不是原创,图都是从视频上截图的。
1. 神经网络

2. 案例说明

具体来说,设计一个三层的神经网络。以数字图像作为输入,经过神经网络的计算,识别出图像中的数字是几,从而实现数字图像的分类。

3. 视频讲解内容的提纲

4. 神经网络的设计和实现
我们要处理的数据是28*28像素的灰色通道图像。

这样的灰色图像包括了28*28=784个数据点。需要先将他展平为1*784大小的向量。然后将这个向量输入到神经网络中。

用一个三层神经网络处理图片对应的向量X。输入成需要接收784维的图片向量X。X里面每个维度的数据都有一个神经元来接收。因此输入层要包含784个神经元。

隐藏成用于特征提取特征向量,将输入的特征向量处理成更高级的特征向量。

因为手写数字图像识别并不复杂,所以将隐藏层的神经元个数设置为256。这样,输入层和隐藏层之间就会有个784*256的线性层。它可以将一个784维的输入向量转换为256维的输出向量。

该输出向量会继续向前传播到达输出层。

由于最终要将数字图像识别为0~9,十种可能的数字。因此,输出层需要定义10个神经元,对应这十种数字。

256维的向量在经过隐藏层和输出层之间的线性层计算后,就得到了10维的输出结果。这个10维的向量就代表了10个数字的预测得分。

为了继续得到输出层的预测概率,还要将输出层的输出输入到softmax层。softmax层会将10维的向量转换为10个概率值p0~p9。p0~p9相加的总和等于1.

5. 神经网络的Pytorch实现

import torch
from torch import nn# 定义神经网络Network
class Network(nn.Module):def __init__(self):super().__init__()# 线性层1,输入层和隐藏层之间的线性层self.layer1 = nn.Linear(784, 258)# 线性层2,隐藏层和输出层之间的线性层self.layer2 = nn.Linear(256, 10)# 在前向传播,forward函数中,输入为图像xdef forward(self, x):x = x.view(-1, 28 * 28) # 使用view函数,将x展平x = self.layer1(x) # 将x输入到layer1x = torch.relu(x) # 使用relu激活return self.layer2(x) # 输入至layer2计算结果# 这里没有直接定义softmax层,因为后面会使用CrossEntropyLoss损失函数# 在这个损失函数中,会实现softmax的计算6. 训练数据的准备和处理






from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader# 初学只要知道大致的数据处理流程即可
if __name__ == '__main__'# 实现图像的预处理pipelinetransform = trnasforms.Compose([# 转换成单通道灰度图transforms.Grayscale(num_output_channels=1),# 转换为张量transforms.ToTensor()])# 使用ImageFolder函数,读取数据文件夹,构建数据集dataset# 这个函数会将保持数据的文件夹的名字,作为数据的标签,组织数据train_dataset = datasets.ImageFolder(root='./mnist_images/train', transform=transform)test_dataset = datasets.ImageFolder(root='./mnist_images/test', transform=transform)# 打印他们的长度print("train_dataset length: ", len(train_dataset))print("test_dataset length: ", len(test_dataset))# 使用train_loader, 实现小批量的数据读取# 这里设置小批量的大小,batch_size=64. 也就是每个批次,包括64个数据train_loader = DataLoader(train_datase, batch_size=64, shuffle=True)# 打印train_loader的长度print("train_loader length: ", len(train_loader))# 6000个训练数据,如果每个小批量,读入64个样本,那么60000个数据会被分成938组# 938*64=60032,说明最后一组不够64个数据# 循环遍历train_loader# 每一次循环,都会取出64个图像数据,作为一个小批量batchfor batch_idx, (data, label) in enumerate(train_loader)if batch_idx == 3:breakprint("batch_idx: ", batch_idx)print("data.shape: ", data.shape) # 数据的尺寸print("label: ", label.shape) # 图像中的数字print(label)7. 模型的训练和测试



import torch
from torch import nn
from torch import optim
from model import Network
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoaderif __name__ == '__main__'# 图像的预处理transform = transforms.Compose([transforms.Grayscale(num_output_channels=1),transforms.ToTensor()])# 读入并构造数据集train_dataset = datasets.ImageFolder(root='./mnist_images/train', transform=transform)print("train_dataset length: ", len(train_dataset))# 小批量的数据读入train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)print("train_loader length: ", len(train_loader))# 在使用Pytorch训练模型时,需要创建三个对象:model = Network() # 1.模型本身,就是我们设计的神经网络optimizer = optim.Adam(model.parameters()) #2.优化器,优化模型中的参数criterion = nn.CrossEntropyLoss() #3.损失函数,分类问题,使用交叉熵损失误差# 进入模型的循环迭代# 外层循环,代表了整个训练数据集的遍历次数for epoch in range(10):# 内层循环使用train_loader, 进行小批量的数据读取for batch_idx, (data, label) in enumerate(train_loader):# 内层每循环一次,就会进行一次梯度下降算法# 包括了5个步骤# 这5个步骤是使用pytorch框架训练模型的定式,初学时先记住即可# 1. 计算神经网络的前向传播结果output = model(data)# 2. 计算output和标签label之间的损失lossloss = criterion(output, label)# 3. 使用backward计算梯度loss.backward()# 4. 使用optimizer.step更新参数optimizer.step()# 5.将梯度清零optimizer.zero_grad()if batch_idx % 100 == 0:print(f"Epoch {epoch + 1}/10"f"| Batch {batch_idx}/{len(train_loader)}"f"| Loss: {loss.item():.4f}")torch.save(model.state_dict(), 'mnist.pth')

from model import Network
from torchvision import transforms
from torchvision import datasets
import torchif __name__ == '__main__'transform = transforms.Compose([transforms.Grayscale(num_output_channels=1),transforms.ToTensor()])# 读取测试数据集test_dataset = datasets.ImageFolder(root='./mnist_images/test', transform=transform)print("test_dataset length: ", len(test_dataset))model = Network() # 定义神经网络模型model.load_state_dict(torch.load('mnist.pth')) # 加载刚刚训练好的模型文件rigth = 0 # 保存正确识别的数量for i, (x, y) in enumerate(test_dataset):output = model(x) # 将其中的数据x输入到模型predict = output.argmax(1).item() # 选择概率最大标签的作为预测结果# 对比预测值predict和真实标签yif predict == y:right += 1else:# 将识别错误的样例打印出来img_path = test_dataset.samples[i][0]print(f"wrong case: predict = {predict} y = {y} img_path = {img_path}")# 计算出测试效果sample_num = len(test_dataset)acc = right * 1.0 / sample_numprint("test accuracy = %d / %d = %.3lf" % (right, sample_num, acc))相关文章:
神经网络识别数字图像案例
学习资料:从零设计并训练一个神经网络,你就能真正理解它了_哔哩哔哩_bilibili 这个视频讲得相当清楚。本文是学习笔记,不是原创,图都是从视频上截图的。 1. 神经网络 2. 案例说明 具体来说,设计一个三层的神经网络。…...

c++包管理器
conan conan search,查看网络库 conan profile detect,生成缓存信息conan new cmake_exe/cmake_lib,创建cmakelists.txtconan install .,执行Conanfile.txt中的配置,生成相关的bat文件 项目中配置Conanfile.txt(或者…...

监控易V7.6.6.15升级详解7,日志分析更高效
随着企业IT系统的日益复杂,日志管理成为了保障系统稳定运行、快速定位问题的重要工具。为了满足广大用户对日志管理功能的更高需求,监控易系统近日完成了重要版本升级,对日志管理功能进行了全面优化和新增。 一、Syslog日志与SnmpTrap日志统…...

HTML表格、表单标签
目录 一、表格 (1)关于表格中标签说明 (2)关于表格中属性说明 (3)简单操作演示 (4)表格小结 二、表单 (1)简单操作演示 (2)注…...

(Windows环境)FFMPEG编译,包含编译x264以及x265
本文使用 MSYS2 来编译 ffmpeg 一、安装MSYS2 MSYS2 是 Windows 下的一组编译套件,它可以在 Windows 系统中模拟 Linux 下的编译环境,如使用 shell 运行命令、使用 pacman 安装软件包、使用 gcc (MinGW) 编译代码等。 MSYS2 的安装也非常省心&#x…...

notepad++中文出现异体汉字,怎么改正
notepad显示异体字,如何恢复? 比如 “门” 和 “直接” 的"直"字,显示成了 方法 修改字体, 菜单栏选择 Settings(设置),Style Configurator…(语言格式设置…)…...
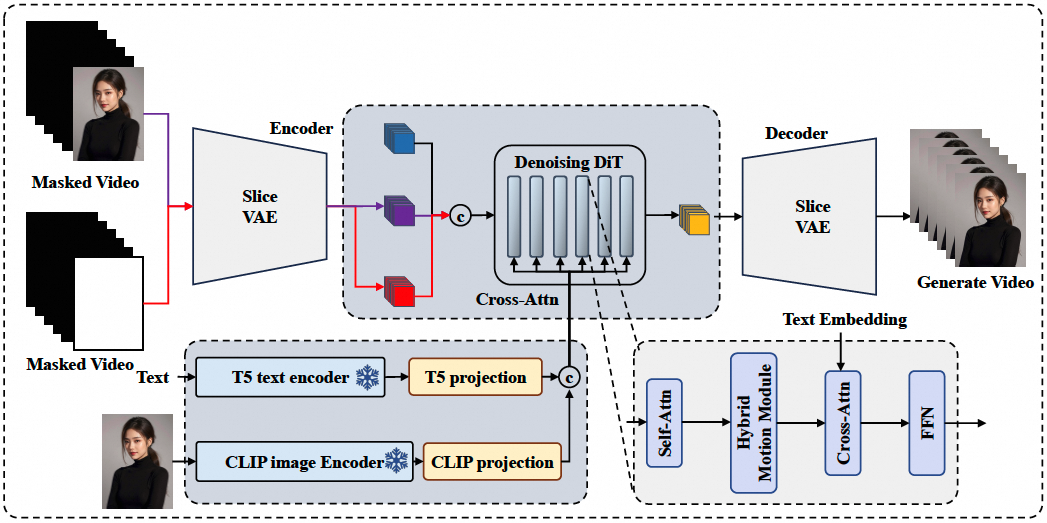
EasyAnimate-v3版本支持I2V及超长视频生成
阿里云人工智能平台(PAI)自研开源的视频生成项目EasyAnimate正式发布v3版本: 支持 图片(可配合文字) 生成视频 支持 上传两张图片作为起止画面 生成视频 最大支持720p(960*960分辨率) 144帧视…...

最新PHP自助商城源码,彩虹商城源码
演示效果图 后台效果图 运行环境: Nginx 1.22.1 Mysql5.7 PHP7.4 直接访问域名即可安装 彩虹自助下单系统二次开发 拥有供货商系统 多余模板删除 保留一套商城,两套发卡 源码无后门隐患 已知存在的BUG修复 彩虹商城源码:下载 密码:chsc 免责声明&…...

Vue2打包部署后动态修改后端接口地址的解决方法
文章目录 前言一、背景二、解决方法1.在public文件夹下创建config文件夹,并创建config.js文件2.编写config.js内容3.在index.html中加载config.js4.在封装axios工具类的js中修改配置 总结 前言 本篇文章将介绍使用Vue2开发前后端分离项目时,前端打包部署…...

【后端开发实习】用MongoDB实现仓库管理的出库入库实战
用MongoDB实现仓库管理的出库入库 MongoDB什么是MongoDBMongoDB安装以及开始运行配置启动以及mongoshmongodb的基础使用命令启动和使用MongoDB服务数据库操作集合操作文档操作 项目部署在数据库中创建一张商品信息表提供信息表的增删改查操作接口 MongoDB 什么是MongoDB Mong…...

内网信息收集——用户凭据窃取
文章目录 一、获取域内单机密码和hash1.1 在线读取lsass进程内存1.2 离线读取lsass.exe进程内存1.3 在线读取本地SAM文件1.4 离线读取本地SAM文件 二、域hash获取三、windows凭据导出 一、获取域内单机密码和hash 在windows中,SAM文件是windows用户的账户数据库&am…...

组串式逆变器散热分析
1 引言 组串式逆变器散热方式主要有强制风冷和自然冷却两种,针对两种散热方式的实际效果,笔者抽取了不同厂家不同散热方式的两款组串式逆变器进行实验对比,发现在同样的环境温度下,强制风冷的逆变器内部环境温度及核心器件温升比…...

WEB07Vue+Ajax
1. Vue概述 Vue(读音 /vjuː/, 类似于 view),是一款用于构建用户界面的渐进式的JavaScript框架(官方网站:https://cn.vuejs.org)。 在上面的这句话中呢,出现了三个词,分别是&#x…...

uniapp打包成Android时,使用uni.chooseLocation在App端显示的地址列表是空白?一直转圈的解决办法
问题描述: uniapp打包后的测试版app在ios里可以显示高德地图的定位列表,但是安卓手机却不显示定位列表,一直在转圈圈,怎么回事?之前的功能在正式版都能用,真机运行也能用,为什么测试版的安卓手…...

删除矩阵中0所在行 matlab
%for验证 new[]; for i1:size(old,1)if old(i,4)~0 %assume 0所在列在第4列new(end1,:)old(i,:);end enda(a(:,2)0,:)[]参考: 两种方式...

JavaWeb---HTML
一 HTML入门 1.1 HTML&CSS&JavaScript的作用 HTML 主要用于网页主体结构的搭建 CSS 主要用于页面元素美化 JavaScript 主要用于页面元素的动态处理 1.2 什么是HTML HTML是Hyper Text Markup Language的缩写。意思是超文本标记语言。它的作用是搭建网页结构,…...

Apache Doris:下一代实时数据仓库
Apache Doris:下一代实时数据仓库 概念架构设计快速的原因——其性能的架构设计、特性和机制基于成本的优化器面向列的数据库的快速点查询数据摄取数据更新服务可用性和数据可靠性跨集群复制多租户管理便于使用半结构化数据分析据仓一体分层存储 词条诞生技术概述适…...

t-SNE降维可视化并生成excel文件使用其他画图软件美化
t-sne t-SNE(t-分布随机邻域嵌入,t-distributed Stochastic Neighbor Embedding)是由 Laurens van der Maaten 和 Geoffrey Hinton 于 2008 年提出的一种非线性降维技术。它特别适合用于高维数据的可视化。t-SNE 的主要目标是将高维数据映射…...
End-to-End Object Detection with Transformers【方法详细解读】
摘要 我们提出了一种新的方法,将目标检测视为一个直接的集合预测问题。我们的方法简化了检测流程,有效地消除了许多手工设计的组件,如非极大值抑制程序或锚生成,这些组件显式编码了我们关于任务的先验知识。新框架的主要成分,称为DEtection TRansformer或DETR,是一个基于…...

SQLite数据库与ROOM数据库
目录 1、SQLite数据库 目的: 基本操作: 缺点: 解决: 2、ROOM持久性库 目的: 优点: 导入依赖: 主要组件: 编辑 使用步骤: a.定义数据实体 b.定义数据访问对象(接…...

物联网安全新思路:轻量级机器学习算法实战评测与选型指南
1. 项目概述:当物联网遇上轻量级机器学习在物联网的世界里,安全从来不是一道选择题,而是一道生存题。想象一下,你家里的智能门锁、工厂里的传感器、街头的智能路灯,这些数以亿计的设备每时每刻都在产生和交换数据。它们…...

Ubuntu 22.04 LTS下,UE5打包的程序报‘Vulkan设备找不到’?别急着重装驱动,先试试这个库文件修复法
Ubuntu 22.04 LTS下解决UE5 Vulkan设备报错的深度修复指南当你在Ubuntu 22.04 LTS上已经确认NVIDIA驱动安装成功(通过nvidia-smi验证),但Unreal Engine 5打包的程序仍然抛出"Vulkan设备找不到"的错误时,问题往往比表面看…...

SELA框架:融合MCTS与LLM的智能AutoML新范式
1. SELA框架:当MCTS的“棋手”思维遇上LLM的“专家”直觉在数据科学项目里,最耗时的往往不是敲代码,而是做决策。面对一个新的表格数据集,从数据清洗、特征工程到模型选型、调参,每一步都像站在一个岔路口,…...

机器学习赋能系统综述:SyROCCo项目实战解析与NLP应用指南
1. 项目概述:当系统综述遇上机器学习如果你做过系统综述,一定对那种“望洋兴叹”的感觉不陌生。面对动辄成千上万的文献,光是筛选、阅读、提取数据这几步,就足以耗掉一个团队数月甚至数年的精力。更头疼的是,等你终于完…...

【芯片测试】:6. 向量、Sequencer 指令与高速串行 IO
Pattern 详解:向量、Sequencer 指令与高速串行 IO系列: Advantest V93000 SmarTest 8 核心概念解析|第 6 篇(共 8 篇) 适合读者: 需要理解数字测试激励数据结构的工程师前言 Pattern(模式&#…...

量子机器学习数据集构建:从核心要素到工程实践
1. 量子机器学习数据集构建:从分类到实践的核心思路量子机器学习(QML)这个领域,现在就像十年前的深度学习,概念很热,但真正能上手、能复现、能出成果的“基础设施”还非常稀缺。我接触过不少从经典机器学习…...

五八同城登录接口逆向:RSA加密、动态salt与sign验签实战
1. 这不是“爬个登录”那么简单:五八同城登录接口逆向的真实战场你点开浏览器开发者工具,F12,Network 面板里筛选 XHR,找到那个/login请求,点开看 Headers 和 Payload —— 然后傻眼了:password字段是一串 …...

Unity编辑器AI增强:本地化轻量模型驱动的开发效率升级
1. 不是“接管”,而是编辑器能力的自然延伸:从Unity传统工作流说起你有没有过这样的时刻:在Unity里改完一段C#脚本,保存,切回编辑器,等几秒——然后发现Scene视图没刷新;再点一下Play࿰…...

计算机视觉如何让外骨骼机器人实现预见式步态辅助控制
1. 项目概述:当外骨骼“睁开双眼”在康复工程和可穿戴机器人领域,让外骨骼机器人像人类一样“聪明”地辅助行走,一直是个核心挑战。传统的控制策略高度依赖惯性测量单元、足底压力传感器等本体传感器来估计步态相位,进而提供力矩辅…...

基于SpringBoot的运动会报名与成绩录入系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的运动会报名与成绩录入系统以解决传统体育赛事管理中存在的信息处理效率低下数据准确性不足以及资源分配不科学等问…...