我用Python写了一个下载网站所有内容的软件,可见即可下,室友表示非常好用
Python 写一个下载网站内容的GUI工具,所有内容都能下载,真的太方便了!
- 前言
- 本次要实现的功能
- 效果展示
- 代码实战
- 获取数据
- GUI部分
- 最后
前言
哈喽大家好,我是轻松。
今天我们分享一个用Python写下载视频+弹幕+评论的代码。
之前自游写了采集视频、弹幕、评论的代码,还录了视频。
我当时就问他,你就不能把这些写成GUI,把这些功能放到一起不是别人用起来更方便么?
本来他还想反抗,当时我就直接叫他看着办!

他哪受得了这种委屈,当时就乖乖写代码去了,现在我把代码分享给大家。
本次要实现的功能
咱们本次先简单的实现一下
- 评论
- 弹幕
- 视频
效果展示
我们来看看实现效果吧

代码实战
主要代码分为界面和采集部分
获取数据
网址我屏蔽了,防止误杀。
获取视频
import requests
import re
import json
from pprint import pprint
import subprocess
import osdef Video(bv_id):url = f'https://www.***.com/video/{bv_id}'headers = {# 防盗链'referer': 'https://www.***.com/video/',# 浏览器基本身份标识 表示浏览器'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}# 发送请求 ---> <Response [200]> 响应对象, 200状态码 表示请求成功response = requests.get(url=url, headers=headers)# 获取视频标题title = re.findall('"title":"(.*?)","pubdate"', response.text)[0].replace(' ', '')# 获取视频数据信息 前端标签两个两个一起html_data = re.findall('<script>window.__playinfo__=(.*?)</script>', response.text)[0]# 转换数据类型 字符串数据转成json字典数据类型json_data = json.loads(html_data)# print打印字典数据, 输出一行内容 print(json_data)# pprint 打印字典数据, 格式化输出 展开效果 pprint(json_data)# 字典数据 B站数据 音频和视频分开的 根据冒号左边的内容, 提取冒号右边的内容 键值对取值audio_url = json_data['data']['dash']['audio'][0]['baseUrl']video_url = json_data['data']['dash']['video'][0]['baseUrl']# 403 Forbidden 没有访问权限.....audio_content = requests.get(url=audio_url, headers=headers).contentvideo_content = requests.get(url=video_url, headers=headers).contentif not os.path.exists('video\\'):os.mkdir('video\\')with open('video\\' + title + '.mp3', mode='wb') as audio:audio.write(audio_content)with open('video\\' + title + '.mp4', mode='wb') as video:video.write(video_content)# 获取音频内容以及视频画面内容cmd = f"ffmpeg -i video\\{title}.mp4 -i video\\{title}.mp3 -c:v copy -c:a aac -strict experimental video\\{title}output.mp4"subprocess.run(cmd, shell=True)os.remove(f'video\\{title}.mp4')os.remove(f'video\\{title}.mp3')return title
采集弹幕
import requests
import re
import osdef get_response(html_url):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}response = requests.get(url=html_url, headers=headers)response.encoding = response.apparent_encodingreturn responsedef get_Dm_url(bv_id):link = f'https://www.***.com/video/{bv_id}/'html_data = get_response(link).textDm_url = re.findall('<a href="(.*?)" class="btn btn-default" target="_blank">弹幕</a>', html_data)[0]title = re.findall('<input type="text" value="(.*?)"', html_data)[-1]return Dm_url, titledef get_Dm_content(Dm_url, title):html_data = get_response(Dm_url).textcontent_list = re.findall('<d p=".*?">(.*?)</d>', html_data)if not os.path.exists('弹幕\\'):os.mkdir('弹幕\\')for content in content_list:with open(f'弹幕\\{title}弹幕.txt', mode='a', encoding='utf-8') as f:f.write(content)f.write('\n')def main(bv_id):Dm_url, title = get_Dm_url(bv_id)get_Dm_content(Dm_url, title)
采集评论
import requests
import re
import osdef get_response(html_url, params=None):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}response = requests.get(url=html_url, params=params, headers=headers)return responsedef get_oid(bv_id):link = f'https://www.***.com/video/{bv_id}/'html_data = get_response(link).textoid = re.findall('window.__INITIAL_STATE__={"aid":(\d+),', html_data)[0]title = re.findall('"title":"(.*?)","pubdate"', html_data)[0].replace(' ', '')return oid, titledef get_content(oid, page, title):content_url = 'https://***.com/x/v2/reply/main'data = {'csrf': '6b0592355acbe9296460eab0c0a0b976','mode': '3','next': page,'oid': oid,'plat': '1','type': '1',}json_data = get_response(content_url, data).json()content = '\n'.join([i['content']['message'] for i in json_data['data']['replies']])if not os.path.exists('评论\\'):os.mkdir('评论\\')with open(f'评论\\{title}评论.txt', mode='a', encoding='utf-8') as f:f.write(content)def main(bv_id):oid, title = get_oid(bv_id)for page in range(1, 6):try:get_content(oid, page, title)except:pass
GUI部分
模块
import tkinter as tk
from tkinter import ttk
import tkinter.messagebox
from Video import Video
import Barrage
import Comment
下载完成提示
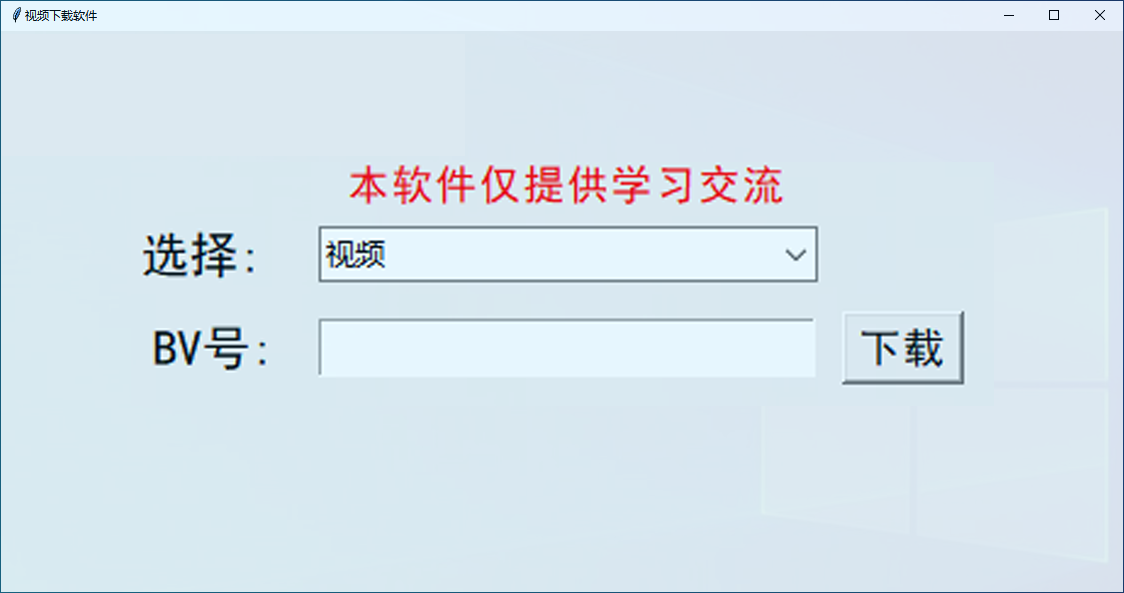
def get_content():result = number_int_var.get()if result == '视频':bv_id = bv_va.get()title = Video(bv_id)tk.messagebox.showinfo(title='温馨提示', message=f'{title}下载完成')elif result == '弹幕':bv_id = bv_va.get()Barrage.main(bv_id)tk.messagebox.showinfo(title='温馨提示', message=f'弹幕下载完成')elif result == '评论':bv_id = bv_va.get()Comment.main(bv_id)tk.messagebox.showinfo(title='温馨提示', message=f'评论下载完成')
主界面部分
root = tk.Tk()
root.title('B站视频下载软件')
root.geometry('367x134+200+200')
# 透明度的值:0~1 也可以是小数点,0:全透明;1:全不透明
# 完整源码自取q裙:708525271
root.attributes("-alpha", 0.9)
# -------------------------------------------------------
tk.Label(root, text='完整源码领取+扣裙708525271', font=('黑体', 13), fg="red").grid(row=0, column=1)
# 我已经把这个工具打包成了exe可执行文件,直接加这个裙获取。
# -------------------------------------------------------
text_label_1 = tk.Label(root, text='选择: ', font=('黑体', 15))
text_label_1.grid(row=1, column=0, padx=5, pady=5)
# -------------------------------------------------------
number_int_var = tk.StringVar()
# 创建一个下拉列表
numberChosen = ttk.Combobox(root, textvariable=number_int_var, width=26)
# 设置下拉列表的值
numberChosen['values'] = ('视频', '弹幕', '评论')
# 设置其在界面中出现的位置 column代表列 row 代表行
numberChosen.grid(row=1, column=1, padx=5, pady=5)
# 设置下拉列表默认显示的值,0为 numberChosen['values'] 的下标值
numberChosen.current(0)
# -------------------------------------------------------
text_label = tk.Label(root, text='BV号:', font=('黑体', 15))
text_label.grid(row=2, column=0, padx=5, pady=5)bv_va = tk.Variable()
entry_1 = tk.Entry(root, font=('黑体', 15), textvariable=bv_va)
entry_1.grid(row=2, column=1)Button_1 = tk.Button(root, text='下载', font=('黑体', 13), command=get_content)
Button_1.grid(row=2, column=2, padx=5, pady=5)
# -------------------------------------------------------
root.mainloop()
最后
像评论、弹幕咱们获取到以后,还能做成词云图等等,视频下载下来有水印,也能用Python直接去除视频水印,非常方便。
大家还可以把代码打包成exe可执行文件,这样就能直接把软件分享给小伙伴一起用了。
或者直接找我要也可以。

大家觉得有用的话可以来个免费的点赞+收藏+关注,防止下次我悄悄更新了好东西却不知道!
相关文章:
我用Python写了一个下载网站所有内容的软件,可见即可下,室友表示非常好用
Python 写一个下载网站内容的GUI工具,所有内容都能下载,真的太方便了!前言本次要实现的功能效果展示代码实战获取数据GUI部分最后前言 哈喽大家好,我是轻松。 今天我们分享一个用Python写下载视频弹幕评论的代码。 之前自游写了…...
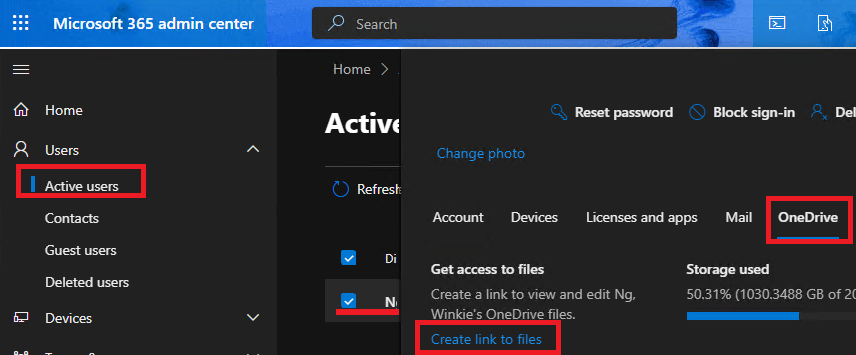
【M365运维】扩充OneDrive存储空间
【问题】E3,E5等订阅许可下,默认的OneDrive存储空间为 1TB,满了之后该如何扩充?【解决】1.运行Powershell2. 链接到Sharepoint Online: Connect-SPOSerivce -url https://<这里通常是公司名>-admin.sharepoint.com3. 定义三个扩充空间时…...
)
hashcat(爆破工具,支持GPU,精)
目录 简介 分类 参数 -m hash的类型 -a 攻击方式 掩码 使用方法 字典破解 简介 虽然John the R...

【机器学习】什么是监督学习、半监督学习、无监督学习、自监督学习以及弱监督学习
监督学习(Supervised Learning):利用大量的标注数据来训练模型,模型最终学习到输入与输出标签之间的相关性。半监督学习(Semi- supervised Learning):利用少量有标签数据和大量无标签数据来训练…...

HashiCorp packer 制作AWS AMI镜像示例
准备工作 验证AWS 可以先手动启动一个EC2实例验证自己创建的VPC, subnet, internet gateway 和routetable等, 确保实例创建后不会出现连接不上的情况. 可以按照下面的链接配置避免连接超时 https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/TroubleshootingInstan…...
)
【java基础】根据泛型动态构造jackson的TypeReference(json反序列化为带泛型的类的对象)
根据泛型动态构造jackson的TypeReference引出问题使用TypeReference反序列化的例子根据泛型动态构造TypeReference带泛型的类如何表示?完成HttpClient的实现引出问题 将json字符串反序列化为带泛型的类的对象怎么操作?怎么根据TypeReference<List<…...

为什么VMware会给我多创建了两个网络呢?Windows和Linux为什么可以彼此ping的通呢
为什么VMware会给我多创建了两个网络呢?Windows和Linux为什么可以彼此ping的通呢 文章目录为什么VMware会给我多创建了两个网络呢?Windows和Linux为什么可以彼此ping的通呢桥接模式ANT模式(VMnet8)仅主机模式(VMnet1&a…...

服务器带宽承载多少人同时访问计算方法-浏览器中查看当前网页所有资源数据大小-客服系统高并发承载人数【唯一客服】...
浏览器中怎么查看当前网页所有资源的数据大小 在开发者工具的“网络”选项卡中,可以看到所有请求和响应的详细信息,包括每个资源的大小。如果需要查看网页所有资源的总大小,可以按照以下步骤操作: 打开要查看的网页。打开开发者工…...
给新手----编译VSOMEIP保姆级别教程
前言:当你学习了SOMEIP理论基础后,一定很希望上手实操一波吧,本文档以SOMEIP协议里比较成熟的VSOMEIP开源框架为例,带你从0到1实现开源框架的下载到上手,坐稳啦,开车!!!&…...

MarkDown设置上下标
上标:$a^{2-5}$ 下标:$a_{n-1}$显示:结果 上标:a2−5a^{2-5}a2−5 下标:an−1a_{n-1}an−1 如果上下标中需要多个显示,需要用{}括起来,否则就像下面一样 上标:$a^2-5$ 下标&…...

Python批量爬取游戏卡牌信息
文章目录前言一、需求二、分析三、处理四、运行结果前言 本系列文章来源于真实的需求本系列文章你来提我来做本系列文章仅供学习参考阅读人群:有Python基础、Scrapy框架基础 一、需求 全站爬取游戏卡牌信息 二、分析 查看网页源代码,图片资源是否存在…...
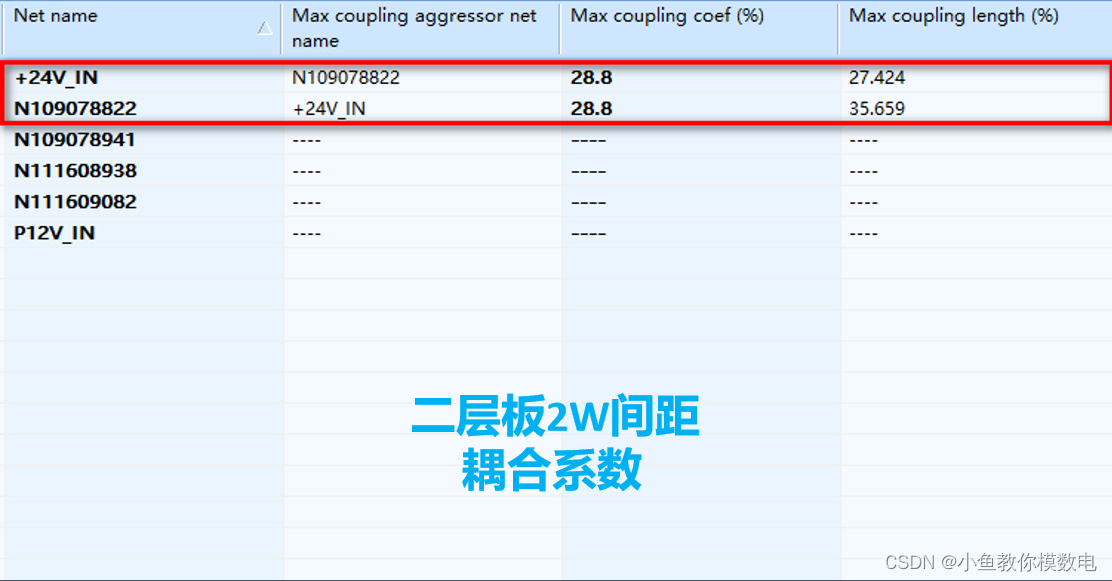
什么是PCB走线的3W原则
在设计PCB的时候我们会经常说到3W原则, 它指的是两个PCB走线它们的中心间距不小于3倍线宽,这个W就是PCB走线的宽度。这样做的目的主要是为了减小走线1和走线2之间的串扰,一般对于时钟信号,复位信号等一些关键信号需要遵循3W原则。…...

计算机网络面试总结
计算机网络 1.计算机网络 2.计算机网络拓扑结构 3.计算机网络覆盖 4.时延 5.交换技术 6.单工、半双工、全双工 7.OSI模型 8.TCP/IP模型 9.物理层有哪些设备 10.数据链路层介质访问控制 11.数据链路层有哪些设备 12.数据链路层流量控制 13.数据链路层的三个基本问题和解决方法 1…...
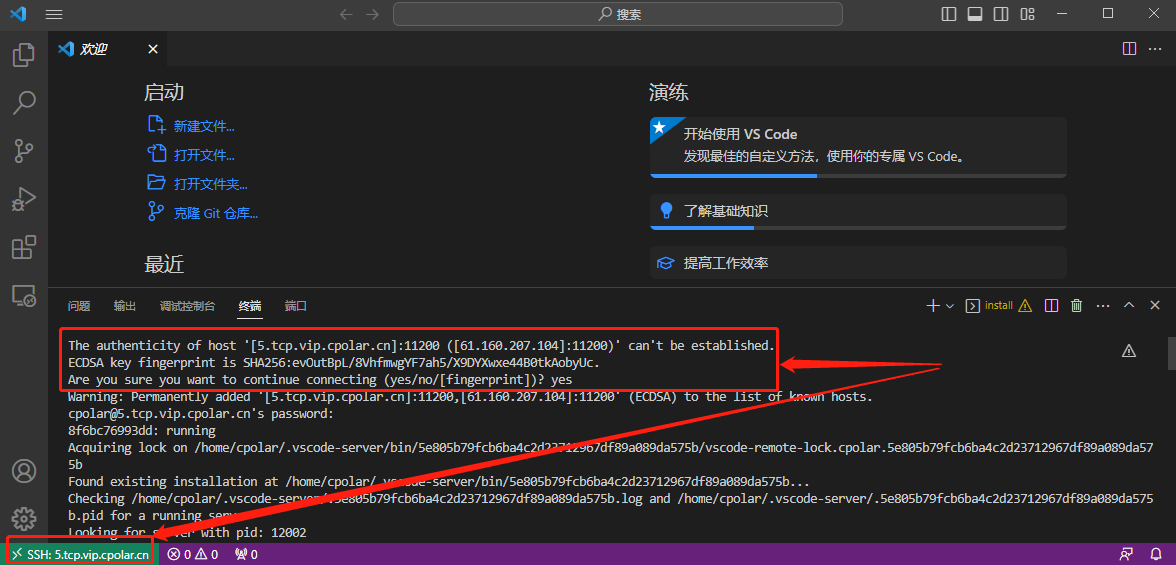
VsCode SSH远程连接服务器【内网穿透公网连接】
文章目录1.前言2.VS code的安装和设置2.1 VS code的下载安装2.2 OpenSSH的启用2.3 为VS code配置ssh2.4 局域网内测试VS code的ssh连接2.5 Cpolar下载安装3.Cpolar端口设置3.1 Cpolar云端设置3.2 Cpolar本地设置4.公网访问测试5.结语1.前言 记得笔者小时候看电视,看…...
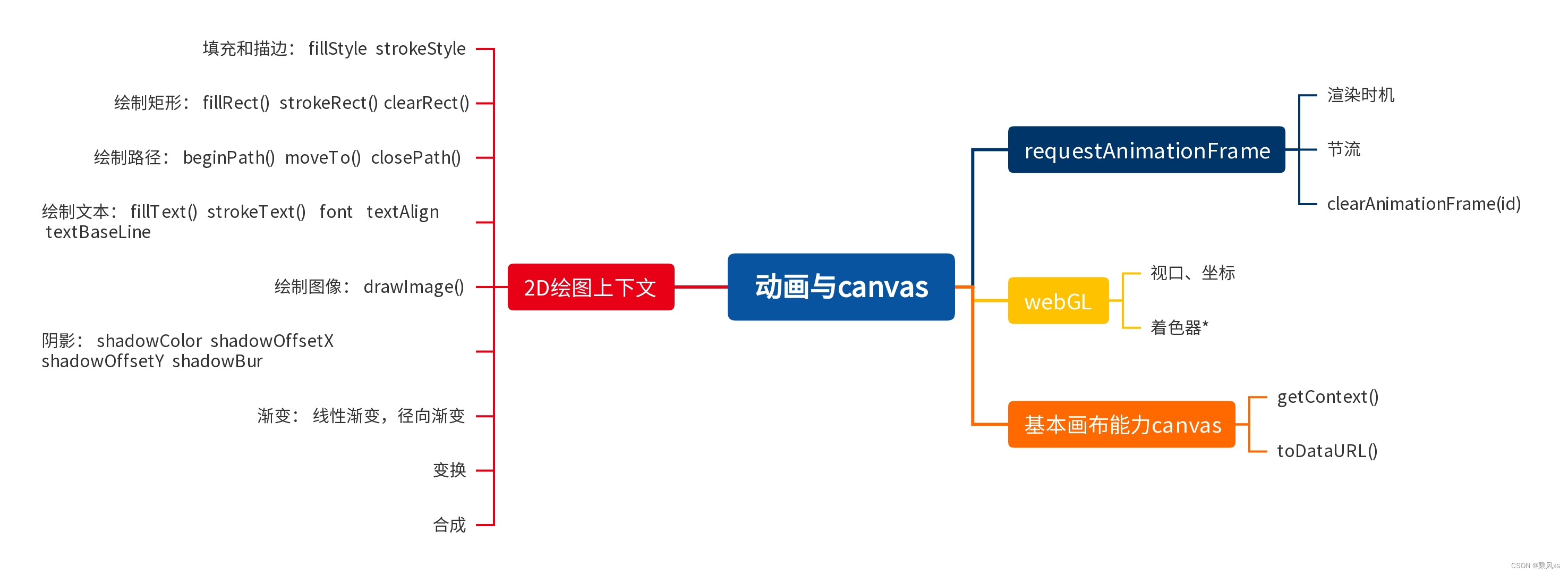
十八、动画与canvas
1.RequestAnimationFrame 早期定时动画 setTimeout和setInterval不能保证时间精度,第二个参数只能保证何时将代码添加到浏览器的任务队列 requestAnimationFrame(cb)的cb在浏览器重绘屏幕前调用 function updateProgress(){const div document.getElementById(d…...
自动化测试学习-Day4-selenium的安装和8种定位方法
哈喽,大家好! 本人21年毕业,软件工程专业,毕业后一直从事金融行业的软件测试。 希望大家一起见证一名卑微测试的成长之路。 目录 一、环境准备 1.浏览器下载 2.浏览器驱动下载 3.下载selenium 二、Selenium定位元素的8种方法…...
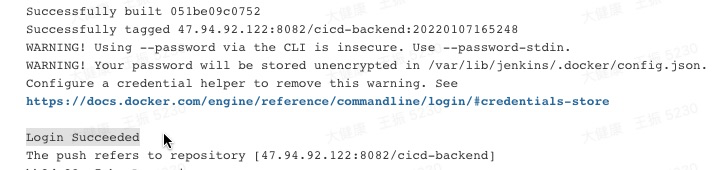
【Kubernetes】第二十五篇 - 布署 nodejs 后端项目(下)
一,前言 上一篇,介绍了部署后端项目之前,需要的准备的相关配置信息; 本篇,创建 Deployment、Service 完成后端项目布署; 二,解决 jenkins 安全问题 构建 docker 镜像之后,登录 do…...
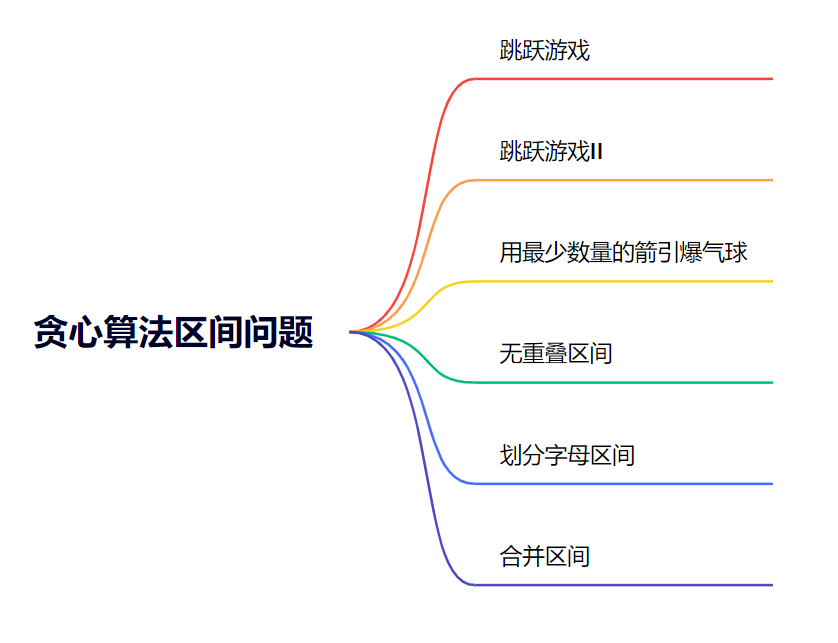
贪心算法之区间问题总结
一、跳跃游戏跳跃游戏类的问题,不关心每一步怎么跳,只需要关心最大覆盖范围这里注意i是在当前最大可覆盖范围内遍历,如{2,1,0,1},就是在0~2范围内遍历,千万不能0~numsSize-1范围内遍历!!&#x…...
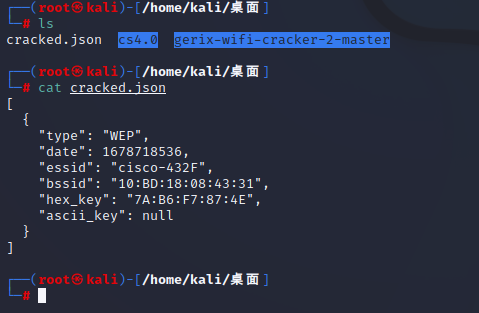
无线WiFi安全渗透与攻防(七)之WIFI07-WEP-wifite自动化渗透WEP加密
WIFI07-WEP-wifite自动化渗透WEP加密 1.wifite介绍 wifite是一款自动化wep、wpa以及wps破解工具,不支持windows和osx。wifite的特点是可以同时攻击多个采用wep和wpa加密的网络。wifite只需简单的配置即可自动化运行,期间无需人工干预。 目前支持任何li…...
震撼,支持多模态模型的ChatGPT 4.0发布了
最近几个月,互联网和科技圈几乎ChatGPT刷屏了,各种关于ChatGPT的概念和应用的帖子也是围绕在周围。当去年年底ChatGPT发布的那几天,ChatGPT确实震撼到了所有人,原来AI还可以这么玩,并且对国内的那些所谓的人工智能公司…...

3步掌握清华PPT模板:终极方案解决学术演示设计难题
3步掌握清华PPT模板:终极方案解决学术演示设计难题 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 还在为学术汇报PPT设计而苦恼吗?每次准备答辩、会议或教学演示,你都要…...

K8s网络插件Flannel与Calico:从原理到实战的选型与部署指南
1. Kubernetes网络插件基础认知 刚接触Kubernetes时,最让我头疼的就是容器网络问题。为什么Pod之间需要通信?为什么有的服务跨节点就访问不了?这些问题的答案都藏在CNI(Container Network Interface)插件里。Flannel和…...

基于 Harmony6.0 的城市空气质量监测页面开发实践:ArkUI 页面构建与跨端能力深度解析
基于 Harmony6.0 的城市空气质量监测页面开发实践:ArkUI 页面构建与跨端能力深度解析 前言 随着 HarmonyOS NEXT 与 Harmony6.0 的持续演进,鸿蒙生态已经不再只是“多设备互联”这么简单,而是逐渐形成了一套完整的分布式应用开发体系。相比传…...
创新点拉满!门控融合+可变形去噪+对比学习,LiDAR-Camera 3D检测暴力涨点!!!)
精读双模态检测论文二十六|DefDeN(兰州大学)创新点拉满!门控融合+可变形去噪+对比学习,LiDAR-Camera 3D检测暴力涨点!!!
🔥 本文定位:CSDN 原创干货 | 兰州大学/卧龙岗大学 LiDAR-Camera 3D目标检测 SOTA 方案 🎯 核心收益:一次性解决注意力融合三大痛点——收敛慢、计算量大、误检率高!基于门控多模态融合单元(GMFU࿰…...
实战指南:从原理到选型与应用)
示波器有效位数(ENOB)实战指南:从原理到选型与应用
1. 从“看见”到“看清”:示波器有效位数(ENOB)的实战解读在电子工程师的日常里,示波器就是我们观察电路世界的“眼睛”。它能让我们直观地看到信号在连接器、线缆、PCB走线和元器件之间穿梭的模样。但就像视力有1.0和1.5的区别一…...

让老旧游戏手柄重获新生:XOutput游戏手柄兼容工具使用指南
让老旧游戏手柄重获新生:XOutput游戏手柄兼容工具使用指南 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 还在为心爱的老手柄无法玩新游戏而烦恼吗?XOutput是一款专门解决Direct…...

ARM9EJ-S核心调试技术与系统速度访问机制解析
1. ARM9EJ-S核心调试技术概述 在嵌入式系统开发领域,调试技术的重要性不亚于代码编写本身。ARM9EJ-S作为经典的嵌入式处理器核心,其调试子系统设计体现了ARM架构对开发效率的深度考量。这套调试系统不仅仅是简单的"暂停-查看"工具,…...

手把手教你为STM32的SD卡驱动FatFs:从AU Size到disk_ioctl的完整配置流程
STM32实战:从SD卡协议到FatFs移植的全流程解析 在嵌入式开发中,存储系统设计往往是项目成败的关键一环。当我们需要在STM32平台上实现可靠的文件存储功能时,SD卡配合FatFs文件系统无疑是最经典的组合方案之一。然而,从硬件接口调试…...

书匠策AI到底能帮你搞定毕业论文几步?一个教育博主的拆解实录
你有没有经历过这样的夜晚——凌晨两点,对着空白文档,光标一闪一闪,仿佛在嘲笑你连选题都没定? 别慌,今天我不讲大道理,直接拿一个工具给你做一次"开颅式拆解"。这个工具叫书匠策AI,…...

从“砖头”到“复活”:一个大众车机蓝牙解锁的完整逆向工程记录
从“砖头”到“复活”:一个大众车机蓝牙解锁的完整逆向工程记录 当一台原本功能完整的车载娱乐系统因为缺少关键协议握手而变成"砖头",你会怎么做?这个问题困扰着许多汽车电子爱好者和安全研究人员。本文记录了我如何通过逆向工程手…...