python 正则使用详解
python 正则使用详解
- 什么是正则
- 在 python 中使用正则
- 一些正则的定义
- python 正则的方法
- match 从字符串开头匹配
- 正则返回的结果分析(重要)
- fullmatch 严格匹配整个字符串
- search 任意位置开始匹配
- sub 替换匹配内容
- subn 以元组方式返回替换结果
- split 正则切割
- findall 查找所有匹配结果
- finditer 返回一个迭代结果
- compile 正则表达式的预编译
- purge 清除缓存
- escape 正则表达式格式化
什么是正则
正则很简单的哦,不要因为看到和乱码差不多的样子就望而却步了,他很有规律的。
简单来说,就是用来描述字符串格式的,比如数字就可以是 [0-9],也可以是 [0123456789],还可以是 \d
而日常我们使用正则,则就是用这个描述格式来验证或匹配提取或批量替换用的,比如 html 代码,用 <[^<>]*?> 来匹配或删除所有标签
关于正则的入门知识,可以围观一下老顾的文章《文盲的正则表达式入门》,在这个文章里,老顾以正则各种符号使用的场景用途做了区分,和其他正则入门的教程不一样哦,当然,也没那么完整就是了。这个文章主要是用来方便理解正则的。
在 python 中使用正则
大部分的开发语言中,都有对正则的支持,毕竟,这也是字符验证的一个主要流派了,甚至不少数据库、命令行都有正则的支持,比如 linux系统,比如 mysql、oracle 数据库等,所以正则还是有必要学一学的。
在 python 中,正则的内容则放在 re 这个包里,使用也很简单,只要引用这个包就可以了
import re
print(re.findall('\d','123456 78/*9')) # 一个简单的例子,找出字符串中所有数字

在 python 的 re 包里,他提供了不少的指令,咱们来一一查看并学习,为了不遗漏内容,咱们把 re.py 这个文件打开,照着这个文档的内容来进行。文件位置如图,在 python 安装路径下的 lib 文件夹内。
一些正则的定义
在 re.py 这个文件中,从第29行开始,他简单的介绍了一些基本的特殊符号定义
The special characters are:
特殊字符为:"." Matches any character except a newline.匹配除换行符以外的任何字符。"^" Matches the start of the string.匹配字符串的开头。"$" Matches the end of the string or just before the newline at the end of the string.匹配字符串的末尾或位于的换行符之前新行的末端。"*" Matches 0 or more (greedy) repetitions of the preceding RE.Greedy means that it will match as many repetitions as possible.匹配0个或多个(默认是贪婪模式)由前边的正则片段定义的重复内容。贪婪模式意味着它会匹配尽可能多的重复。"+" Matches 1 or more (greedy) repetitions of the preceding RE.匹配1个或多个(默认是贪婪模式)由前边的正则片段定义的重复内容。"?" Matches 0 or 1 (greedy) of the preceding RE.匹配0个或1个(默认是贪婪模式)由前边的正则片段定义的内容。*?,+?,?? Non-greedy versions of the previous three special characters.前边三个定义的非贪婪版本。(老顾的正则入门里说过的哦,+*? 是长度定义,在长度定义后加 ? 就表示非贪婪模式,这个可以引用到任何长度定义中,包括下边也有出现){m,n} Matches from m to n repetitions of the preceding RE.匹配至少 m 个,最多 n 个由前边正则片段定义的内容。默认是贪婪模式{m,n}? Non-greedy version of the above.上边长度定义的非贪婪版本。"\\" Either escapes special characters or signals a special sequence.要么转义特殊字符,要么就是一个已经预定义的特殊序列。(好吧,老顾也不知道怎么准确翻译,这里的特殊序列指的就是预定义的字符集,比如\d表示数字,\n表示回车)[] Indicates a set of characters.A "^" as the first character indicates a complementing set.表示一组字符。(也就是老顾说的字符集,比如 \d 是已经预定义好的,但是是全部数字,也许我们只需要123,不需要其他数字,那么就必须自己定义字符集 [123] 这个样子)作为第一个字符的“^”表示一个补集。(在字符集定义中,如果 ^ 是第一个字符,则表示这个是个补集,换个说法,就是不包含之后定义的字符集的其他字符集,比如 [^\d] 就是所有非数字的字符)"|" A|B, creates an RE that will match either A or B.A|B,创建一个匹配A或B的正则片段。(...) Matches the RE inside the parentheses.The contents can be retrieved or matched later in the string.匹配括号内的正则片段。稍后可以在字符串中检索或匹配内容。(事实上,除了稍后在其他地方使用,在当前正则片段后的部分也可以使用)(?aiLmsux) The letters set the corresponding flags defined below.字母设置下面定义的相应标志。(这个用法老顾还没试过,翻译为百度翻译的结果)(?:...) Non-grouping version of regular parentheses.正则圆括号的非分组版本。(也就是不可引用、追溯的部分)(?P<name>...) The substring matched by the group is accessible by name.组匹配的子字符串可以通过名称访问。(给分组定个名字,然后通过名字访问)(?P=name) Matches the text matched earlier by the group named name.匹配前面由组名称匹配的文本。(?#...) A comment; ignored.一个注释,忽略掉。(嗯,我讨厌写注释)(?=...) Matches if ... matches next, but doesn't consume the string.右断言,位置修饰,如果能匹配成功则匹配之后的正则片段,该修饰不占用匹配空间。(?!...) Matches if ... doesn't match next.右断言,与上一个修饰意思相反,如果不符合之后的正则片段,则继续匹配。(?<=...) Matches if preceded by ... (must be fixed length).左断言,如果前边的字符符合正则片段...(必须定长)(?<!...) Matches if not preceded by ... (must be fixed length).左断言,如果前边的字符不符合正则片段...(必须定长)(?(id/name)yes|no) Matches yes pattern if the group with id/name matched, the (optional) no pattern otherwise.如果具有id/name的组匹配,则匹配yes模式,否则为(可选)无模式。(同样没用过的方法)
通过这个内容,我们基本就可以确定 python 中,正则能完成哪些描述,这样的描述又有什么样的限制了。
再之后,从62 行开始,还介绍了一些预定义字符集,这里就不翻译了,大家随便看看就好,基本都差不多。
再然后,87 行开始,说明了, re 这个包之中包含的各种方法,嗯,之后一一讲解
以及102行开始的,正则修饰。。。。老顾最常用的就是忽略大小写修饰,这个修饰是在正则定义之外的,还有多行匹配也偶尔用用,其他的说实话,老顾基本用不上。
python 正则的方法
约定,之后的所有内容,默认都已经引入了 re 包,即,代码中已经包含了 import re
match 从字符串开头匹配
Match a regular expression pattern to the beginning of a string.
将正则表达式模式与字符串的开头匹配。
语法:
match(pattern, string, flags=0)
match(正则表达式,匹配字符串,正则表达式修饰(默认为0))
需要注意,这个方法时严格从字符串开头进行匹配的,如果想在字符串中间找到匹配,不要用这个方法哦。
示例:
print(re.match('\d+','123.548'))
# 返回结果
<re.Match object; span=(0, 3), match='123'>
print(re.match('\s\d+','123.548'))
# 返回结果,匹配失败,没有Match信息
None
在python中,使用匹配返回的结果,大部分都是 re.Match 对象,他包含了一个 span 元组,这个元组就是匹配字符串对应的切片位置,match 就是匹配的结果了
正则返回的结果分析(重要)
ans = re.match('\d+','123.548')
print(ans)
<re.Match object; span=(0, 3), match='123'>
我们通过一个变量,来分析返回的结果该如何使用
print(ans.re) # 输出这个匹配的正则
re.compile('\\d+') # 包含了我们正则片段的正则编译对象
print(ans.string) # 输出这个匹配的原始匹配字符串
123.548
print(ans.pos,ans.endpos) # 输出原始字符串的切片,包括起始位置和结束位置
0 7
print(ans.regs) # 输出匹配的结果,注意,这里是元组,每一个内层元组是一个匹配
((0, 3),)
print(ans.span) # 输出span方法
<built-in method span of re.Match object at 0x00000148614E76C0>
print(ans.span(0)) # 输出第一个匹配的切片信息
(0, 3)
print(ans.start(0),ans.end(0)) # 返回指定匹配顺序的切片开始和结束位置
0 3
print(ans.group(0)) # 返回第一个匹配结果匹配到的内容
123
嗯,由于刚才的匹配,我们简单的匹配了一个 \d+,没有带分组信息,这次我们加上一个分组来尝试
ans = re.match('(\d+)\.(\d+)','123.548') # 带有两个分组的正则匹配
print(ans)
<re.Match object; span=(0, 7), match='123.548'>
print(ans.span(0),ans.span(1),ans.span(2)) # 返回所有的切片信息
#这里需要注意的是,如果带有分组,那么原始字符串自动占据返回结果的第一个分组,即下标为0的分组
#所以,实时上我们需要提取的结果,应该是从下标1开始的
(0, 7) (0, 3) (4, 7)
print(ans.group(0),ans.group(1),ans.group(2)) # 输出该匹配结果的分组结果
123.548 123 548
print(ans.groups()) # 输出该匹配的分组内容,注意,这里的groups没有参数,输入参数也是无效的
# 所以想要引用结果,必须使用 group
('123', '548')
print(ans.groups(101))
('123', '548')
print(ans.expand('\\1 is \\2')) # 将匹配结果按照指定的字符串格式输出,这里可以引用分组结果
123 is 548
好了,经过这几个输出,我们应该明白了正则匹配结果返回的内容都包含哪些信息了,还有个别的属性方法老顾也不太清楚,这里就不再讲解了
有了这些方法和属性,我们就可以很方便的使用正则返回结果中的内容了
fullmatch 严格匹配整个字符串
Match a regular expression pattern to all of a string.
将正则表达式模式与所有字符串匹配。
语法:
fullmatch(pattern, string, flags=0)
fullmatch(正则表达式,匹配字符串,正则表达式修饰(默认为0))
print(re.fullmatch('[a-z]+','0123456')) # 由于没有字母,匹配失败
None
print(re.fullmatch('[a-z]+','Abcd efgh',re.IGNORECASE)) # 虽然忽略大小写了,但是中间有空格,不能严格匹配,匹配失败
None
print(re.fullmatch('\d+','0123456')) # 整个字符串严格匹配 \d+
<re.Match object; span=(0, 7), match='0123456'>
print(re.fullmatch('[a-z]+','Abcdefgh',re.IGNORECASE)) # 整个字符串严格匹配 [a-z]+
<re.Match object; span=(0, 8), match='Abcdefgh'>
print(re.fullmatch('[a-z]','Abcdefgh',re.IGNORECASE)) # 长度对应不上,没有长度修饰则只匹配一个字符的字符串才可以成功
None
嗯,就是严格匹配字符串首尾,默认相当于 search 的正则前边带 ^ 后边带 $
search 任意位置开始匹配
Search a string for the presence of a pattern.
在字符串中搜索是否存在模式。
语法:
search(pattern, string, flags=0)
search(正则表达式,匹配字符串,正则表达式修饰(默认为0))
print(re.search('[a-z]+','0123456')) # 没有匹配到结果,返回 None
None
print(re.search('[a-z]+','Abcd efgh',re.IGNORECASE)) # 返回第一个匹配成功的结果片段
<re.Match object; span=(0, 4), match='Abcd'>
print(re.search('\d+','abcde0123456')) # 返回第一个匹配成功的结果片段
<re.Match object; span=(5, 12), match='0123456'>
print(re.search('[a-z]+','Abcdefgh',re.IGNORECASE)) # 整个字符串都符合正则,所以完整返回了
<re.Match object; span=(0, 8), match='Abcdefgh'>
print(re.search('[a-z]','Abcdefgh',re.IGNORECASE)) # 返回第一个匹配成功的片段
<re.Match object; span=(0, 1), match='A'>
很明显,search 要比 match 和 fullmatch 要宽松很多,我们可以更自由的发挥
sub 替换匹配内容
Substitute occurrences of a pattern found in a string.
替换字符串中发现的模式的出现次数。(百度翻译的什么鬼?)
替换字符串中所有或指定次数的符合匹配的内容。(老顾翻译)
语法:
sub(pattern, repl, string, count=0, flags=0)
sub(正则表达式,替换表达式,匹配字符串,替换次数,正则表达式修饰(默认为0))
print(re.sub('(\d{2})','\\1-','18300183000')) # 将数字每两位之后加一个减号
18-30-01-83-00-0
----
print(re.sub('(?=\d+)(?<!\d)','\n','1开始2结束3运行4调试11开会12报告')) # 在每个连续数字前插入一个换行,大家可以和下一个比较一下有什么不同1开始
2结束
3运行
4调试
11开会
12报告
----
print(re.sub('(?=\d+)','\n','1开始2结束3运行4调试11开会12报告')) # 在每个数字前,插入一个换行1开始
2结束
3运行
4调试
1
1开会
1
2报告
----
print(re.sub('(?=\d+)(?<!\d)','\n','1开始2结束3运行4调试11开会12报告',count=5)) # 指定了替换次数的正则替换1开始
2结束
3运行
4调试
11开会12报告
正则替换还是很好用的,但是,这里要说一个但是,python 的正则替换里描述的内容,有一个很重要的部分,很多人可能都忽略掉了。原文如下
def sub(pattern, repl, string, count=0, flags=0):"""Return the string obtained by replacing the leftmostnon-overlapping occurrences of the pattern in string by thereplacement repl. repl can be either a string or a callable;if a string, backslash escapes in it are processed. If it isa callable, it's passed the Match object and must returna replacement string to be used."""return _compile(pattern, flags).sub(repl, string, count)
repl can be either a string or a callable;
repl可以是字符串,也可以是可调用的
If it is a callable, it’s passed the Match object and must return a replacement string to be used.
如果是可调用的的话,它传递Match对象,并且必须返回要使用的替换字符串。
也就是说,我可以通过委托的方法,来处理匹配到的内容,并返回指定的结果
来,我们试试看哦
def star(n): # 这里的 n 就是一个正则匹配对象Matchreturn '*' * int(n.group(0)) + '\n' # 将匹配到的数字转成星星的数量,并返回星星print(re.sub('\d',star,'123456789')) # 委托匹配到的内容使用 star 方法来处理
*
**
***
****
*****
******
*******
********
*********
import random
def star(n):return ''.join([random.choice('abcdefghijklmnopqrstuvwxyz') for _ in range(int(n.group(0)))]) + '\n'print(re.sub('\d',star,'123454321'))
v
sr
lvd
trtm
rnhrq
loxb
vjd
su
i
以及,老顾在《在学习爬虫的路上,有多少坑在前边》一文中,实际用到的两个转编码的函数
正则替换如此强大,你还不心动吗?
subn 以元组方式返回替换结果
Same as sub, but also return the number of substitutions made.
与sub相同,但也返回进行的替换次数。(百度翻译持续不说人话)
和 sub 方法一样,但是,在元组中,记录了替换的次数。(老顾翻译)
语法:
subn(pattern, repl, string, count=0, flags=0)
subn(正则表达式,替换表达式,匹配字符串,替换次数,正则表达式修饰(默认为0))
print(re.subn('(?=\d+)(?<!\d)','\n','1开始2结束3运行4调试11开会12报告'))
('\n1开始\n2结束\n3运行\n4调试\n11开会\n12报告', 6) # 元组第一个元素为返回结果,第二个元素为替换次数def star(n):return '*' * int(n.group(0)) + '\n'print(re.subn('\d',star,'13243546576879'))
('*\n***\n**\n****\n***\n*****\n****\n******\n*****\n*******\n******\n********\n*******\n*********\n', 14)
subn 就不细说了,和sub一样的玩法
split 正则切割
Split a string by the occurrences of a pattern.
按出现的模式拆分字符串。
语法:
split(pattern, string, maxsplit=0, flags=0)
split(正则表达式,匹配字符串,最大切割次数(默认0,即不限制次数),正则表达式修饰(默认为0))
print(re.split('[^\d]','13 243,54uu6576879')) # 以非数字的字符为切割符,切割字符串
['13', '243', '54', '', '6576879'] # 由于两个 u 之间没有数字,所以结果中会出现空字符串print(re.split('[^\d]','13 243,54uu6576879',maxsplit=2)) # 指定最大切割次数的分割字符串
['13', '243', '54uu6576879']
嗯。。。。很常用实用以及很容易用,不细说了
需要注意的是,这里返回的就是字符串数组,没有Match信息了
findall 查找所有匹配结果
Find all occurrences of a pattern in a string.
查找字符串中出现的所有模式。
语法:
findall(pattern, string, flags=0)
findall(正则表达式,匹配字符串,正则表达式修饰(默认为0))
额。。。怎么说呢,在抛弃了Match信息的情况下,以字符串数组方式返回所有匹配
print(re.findall('\d+','13 243,54uu6576879'))
['13', '243', '54', '6576879']
在大部分的工作中,其实这个也就够用了,因为我们并不关心他出现在什么地方,前后文有什么,但在一些需求比较复杂的时候,这个 findall 就不如 finditer 了,因为 findall 丢失了Match信息,而finditer还保留着Match信息
finditer 返回一个迭代结果
Return an iterator yielding a Match object for each match.
返回一个迭代器,为每个匹配生成一个Match对象。
语法:
finditer(pattern, string, flags=0)
finditer(正则表达式,匹配字符串,正则表达式修饰(默认为0))
print(re.finditer('\d+','13 243,54uu6576879')) # 返回了一个迭代器
<callable_iterator object at 0x00000148615CD540>for m in re.finditer('\d+','13 243,54uu6576879'): #使用迭代,将所有匹配输出print(m)
<re.Match object; span=(0, 2), match='13'> # 第一个匹配
<re.Match object; span=(3, 6), match='243'> # 第二个匹配
<re.Match object; span=(7, 9), match='54'> # 第三个匹配
<re.Match object; span=(11, 18), match='6576879'> # 第四个匹配
由于这里完整的保留了Match的信息,所以我们可以对匹配到的结果进行定位,以及检查前后文之类的操作,需要用的人自然会用到,也就不细说了
compile 正则表达式的预编译
Compile a pattern into a Pattern object.
将模式编译为pattern对象。
语法:
compile(pattern, flags=0)
嗯。。。定义一个正则,也许复杂的正则会用到这个,老顾一般都直接写正则片段,除了上了1k的正则,老顾一般不会用这个
purge 清除缓存
Clear the regular expression cache.
清除正则表达式缓存。
语法:
purge()
没啥用,这是针对预编译的正则来说的,老顾基本上都是随手写正则随手用,没有预编译过
escape 正则表达式格式化
Backslash all non-alphanumerics in a string.
对正则表达式字符串中的所有非字母数字进行转义。
语法:
escape(pattern)
这个还算有点用,算是正则格式化的部分,比如我们想从字符串中提取到一部分作为匹配内容,但是匹配到的内容可能会有特殊符号,比如*号,?号之类的,这些在正则中有其他意义,所以我们需要提前将这些符号转义,escape就是干这个用的,将特殊符号都转义。老顾在 c# 中使用正则,还单独自己写了个FormatRegex 方法,就是干这个用的。郁闷。
print(re.escape('123.456*789=$100')) # 格式化正则片段,将其特殊符号都进行转义
123\.456\*789=\$100
相关文章:
python 正则使用详解
python 正则使用详解什么是正则在 python 中使用正则一些正则的定义python 正则的方法match 从字符串开头匹配正则返回的结果分析(重要)fullmatch 严格匹配整个字符串search 任意位置开始匹配sub 替换匹配内容subn 以元组方式返回替换结果split 正则切割…...

一个深度学习项目需要什么
DataLoader1.数据预处理在将数据提供给模型之前,DataLoader需要对数据进行预处理。预处理可以包括数据增强、归一化、裁剪、缩放等操作。这些操作可以提高模型的性能和准确度。在处理点云数据时,可以通过最远点下采样到固定的点数。2.读取标签文件我 1 2…...
【Java进阶篇】—— 常用类和基础API
一、String类 1.1 String的特性 java.lang.String 类代表字符串,由final关键字修饰,在赋值后不能改变(常量),不能继承String类String 对象的字符内容是存储在一个字符数组 value[]中的 我们来看一下String在JDK8中的…...
手敲Mybatis(六)-反射工具天花板
历时漫长的岁月,终于鼓起勇气继续研究Mybatis的反射工具类们,简直就是把反射玩出花,但是理解起来还是很有难度的,涉及的内容代码也颇多,所以花费时间也比较浩大,不过当了解套路每个类的功能也好,…...

内含18禁~~关于自学\跳槽\转行做网络安全行业的一些建议
作者:Eason_LYC 悲观者预言失败,十言九中。 乐观者创造奇迹,一次即可。 一个人的价值,在于他所拥有的。所以可以不学无术,但不能一无所有! 技术领域:WEB安全、网络攻防 关注WEB安全、网络攻防。…...

春分策划×运维老王主讲:CMDB数据运营精准化公开课启动报名啦!
『CMDB数据运营精准化』 公开直播课 要来了! 👆扫描海报二维码,预约直播 CMDB似乎是运维中永恒的老话题。 提到CMDB很多人都是又爱又恨,爱的是它给我们提供了一个美好的未来,有了CMDB我们可以解决诸多运维中的难题。…...

制作INCA和CANape通用的A2L
文章目录 前言制作A2LA2ML定义MOD_COMMON定义MOD_PAR定义MEMORY_SEGMENTTransportLayer定义PROTOCOL_LAYERDAQ总结前言 由于INCA和CANape是两个不同的公司对XCP协议的实现,所以A2L中也会有不一样的地方,但是在标定时若每次都用两个A2L,是非常不方便的,本文介绍如何设计A2L…...

Python人脸识别
#头文件:import cv2 as cvimport numpy as npimport osfrom PIL import Imageimport xlsxwriterimport psutilimport time#人脸录入def get_image_name(name):name_map {f.split(.)[1]:int(f.split(.)[0]) for f in os.listdir("./picture")}if not name…...

我用Python写了一个下载网站所有内容的软件,可见即可下,室友表示非常好用
Python 写一个下载网站内容的GUI工具,所有内容都能下载,真的太方便了!前言本次要实现的功能效果展示代码实战获取数据GUI部分最后前言 哈喽大家好,我是轻松。 今天我们分享一个用Python写下载视频弹幕评论的代码。 之前自游写了…...
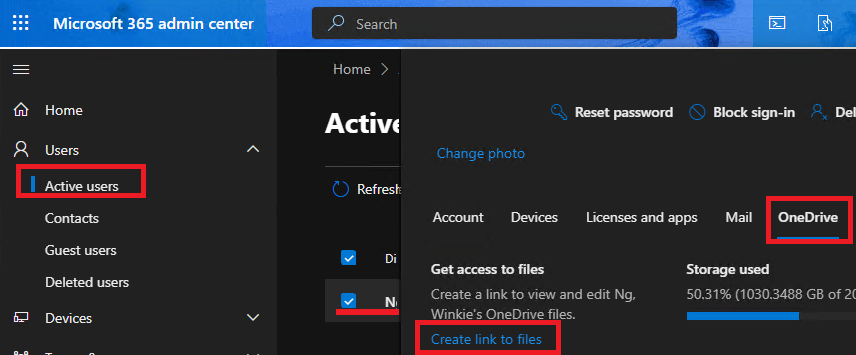
【M365运维】扩充OneDrive存储空间
【问题】E3,E5等订阅许可下,默认的OneDrive存储空间为 1TB,满了之后该如何扩充?【解决】1.运行Powershell2. 链接到Sharepoint Online: Connect-SPOSerivce -url https://<这里通常是公司名>-admin.sharepoint.com3. 定义三个扩充空间时…...
)
hashcat(爆破工具,支持GPU,精)
目录 简介 分类 参数 -m hash的类型 -a 攻击方式 掩码 使用方法 字典破解 简介 虽然John the R...

【机器学习】什么是监督学习、半监督学习、无监督学习、自监督学习以及弱监督学习
监督学习(Supervised Learning):利用大量的标注数据来训练模型,模型最终学习到输入与输出标签之间的相关性。半监督学习(Semi- supervised Learning):利用少量有标签数据和大量无标签数据来训练…...

HashiCorp packer 制作AWS AMI镜像示例
准备工作 验证AWS 可以先手动启动一个EC2实例验证自己创建的VPC, subnet, internet gateway 和routetable等, 确保实例创建后不会出现连接不上的情况. 可以按照下面的链接配置避免连接超时 https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/TroubleshootingInstan…...
)
【java基础】根据泛型动态构造jackson的TypeReference(json反序列化为带泛型的类的对象)
根据泛型动态构造jackson的TypeReference引出问题使用TypeReference反序列化的例子根据泛型动态构造TypeReference带泛型的类如何表示?完成HttpClient的实现引出问题 将json字符串反序列化为带泛型的类的对象怎么操作?怎么根据TypeReference<List<…...

为什么VMware会给我多创建了两个网络呢?Windows和Linux为什么可以彼此ping的通呢
为什么VMware会给我多创建了两个网络呢?Windows和Linux为什么可以彼此ping的通呢 文章目录为什么VMware会给我多创建了两个网络呢?Windows和Linux为什么可以彼此ping的通呢桥接模式ANT模式(VMnet8)仅主机模式(VMnet1&a…...

服务器带宽承载多少人同时访问计算方法-浏览器中查看当前网页所有资源数据大小-客服系统高并发承载人数【唯一客服】...
浏览器中怎么查看当前网页所有资源的数据大小 在开发者工具的“网络”选项卡中,可以看到所有请求和响应的详细信息,包括每个资源的大小。如果需要查看网页所有资源的总大小,可以按照以下步骤操作: 打开要查看的网页。打开开发者工…...
给新手----编译VSOMEIP保姆级别教程
前言:当你学习了SOMEIP理论基础后,一定很希望上手实操一波吧,本文档以SOMEIP协议里比较成熟的VSOMEIP开源框架为例,带你从0到1实现开源框架的下载到上手,坐稳啦,开车!!!&…...

MarkDown设置上下标
上标:$a^{2-5}$ 下标:$a_{n-1}$显示:结果 上标:a2−5a^{2-5}a2−5 下标:an−1a_{n-1}an−1 如果上下标中需要多个显示,需要用{}括起来,否则就像下面一样 上标:$a^2-5$ 下标&…...

Python批量爬取游戏卡牌信息
文章目录前言一、需求二、分析三、处理四、运行结果前言 本系列文章来源于真实的需求本系列文章你来提我来做本系列文章仅供学习参考阅读人群:有Python基础、Scrapy框架基础 一、需求 全站爬取游戏卡牌信息 二、分析 查看网页源代码,图片资源是否存在…...
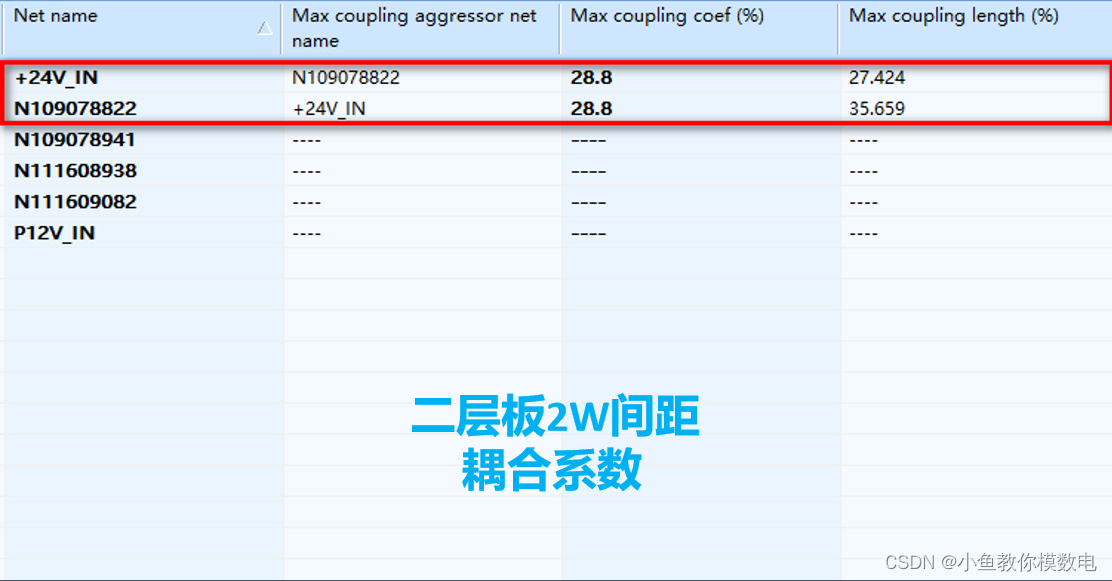
什么是PCB走线的3W原则
在设计PCB的时候我们会经常说到3W原则, 它指的是两个PCB走线它们的中心间距不小于3倍线宽,这个W就是PCB走线的宽度。这样做的目的主要是为了减小走线1和走线2之间的串扰,一般对于时钟信号,复位信号等一些关键信号需要遵循3W原则。…...

通过用量看板清晰观测各模型API调用成本与消耗
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板清晰观测各模型API调用成本与消耗 效果展示类,介绍开发者在接入Taotoken后,如何通过平台提供的…...

3分钟掌握MultiHighlight:让代码阅读效率提升300%的智能高亮插件
3分钟掌握MultiHighlight:让代码阅读效率提升300%的智能高亮插件 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight …...

热门推荐:收藏!软件研发小白必看:AI转型从思维转变开始,轻松掌握大模型协作
本文探讨了软件研发团队如何进行AI转型,强调不应从购买工具或引入Agent开始,而是应首先关注个体思维的转变、团队知识底座的统一以及协作流程的重新设计。文章指出,开发者需要从关注代码实现转向关注编码前的设计、上下文组织和边界定义&…...

如何完整破解Cursor Pro限制:终极免费激活方案全解析
如何完整破解Cursor Pro限制:终极免费激活方案全解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

3分钟掌握R3nzSkin:英雄联盟国服免费全皮肤终极方案
3分钟掌握R3nzSkin:英雄联盟国服免费全皮肤终极方案 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想在英雄联盟国服免费体验所有皮肤吗&a…...

揭秘AI专著撰写:工具加持,20万字专著快速成型!
AI专著写作:挑战与工具解决方案 学术专著的撰写,不仅考验着研究者的学术能力,更是对心理耐受力的一种挑战。与团队合作撰写论文不同,专著大多是由个人独立完成的。从选题到框架构建,再到具体内容的撰写、修改…...

书匠策AI:你的论文过不了关?http://www.shujiangce.com这套组合拳直接救场!
开篇一句话:2025年写论文,拼的不是文笔,是"过关能力"。 查重40%以上被打回,AIGC检测疑似度超标被标记——这两座大山压在每个毕业生头上。你是不是也经历过这种绝望:明明每个字都是自己敲的,系统…...

终极指南:如何在OBS Studio中免费使用VST插件实现专业级音频处理
终极指南:如何在OBS Studio中免费使用VST插件实现专业级音频处理 【免费下载链接】obs-vst Use VST plugins in OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-vst 想要让直播声音瞬间达到专业水准?OBS-VST插件就是你的答案!这…...

CANN/pypto Tensor索引功能
pypto.Tensor索引功能说明 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto Tensor索引是Tensor的核心操作之一,用于从Tensor中筛选、…...

2026年最新亲测3款生成会议纪要免费工具推荐,10分钟出稿非常好用!
兄弟们,我来了。作为一个天天泡在会议室、钉钉和飞书里来回切换的职场老兵,我太懂“开会一时爽,整理火葬场”的痛苦了。这几年,各种AI录音转文字、语音转写工具层出不穷,但真正能打、能免费白嫖、还不乱收费的…...