Large Language Model系列之二:Transformers和预训练语言模型
Large Language Model系列之二:Transformers和预训练语言模型
1 Transformer模型
Transformer模型是一种基于自注意力机制的深度学习模型,它最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,主要用于机器翻译任务。随后,Transformer模型因其出色的性能和灵活性被广泛应用于各种自然语言处理(NLP)任务,如文本分类、问答系统、文本摘要等,以及计算机视觉领域中的一些任务。

以下是Transformer模型的几个关键特点:
- 自注意力机制(Self-Attention):
允许模型在编码(编码器)或解码(解码器)过程中,计算序列中每个元素对于其他所有元素的注意力权重,从而捕捉序列内部的长距离依赖关系。 - 编码器-解码器架构(Encoder-Decoder Architecture):
Transformer模型由编码器和解码器组成,编码器处理输入序列,解码器生成输出序列。 - 多头注意力(Multi-Head Attention):
模型并行地执行多个注意力函数,每个头学习输入的不同表示,然后将这些表示合并,以捕获不同子空间的信息。 - 位置编码(Positional Encoding):
由于Transformer模型缺乏递归和卷积结构,因此需要位置编码来提供序列中单词的位置信息。 - 前馈网络(Feed-Forward Networks):
在每个编码器和解码器层中,自注意力层的输出会通过一个前馈神经网络,进一步提取特征。 - 层归一化(Layer Normalization) 和 残差连接(Residual Connections):
这些技术有助于避免训练过程中的梯度消失问题,使得可以训练更深的网络。 - 并行处理能力:
与循环神经网络(RNN)相比,Transformer模型可以并行处理整个序列,这大大提高了模型的计算效率。 - 可扩展性:
Transformer模型可以通过简单地堆叠更多的层或使用更大的模型尺寸来扩展,以提高模型的容量。
Transformer模型的成功推动了后续许多变体和改进,例如BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-trained Transformer)和T5(Text-to-Text Transfer Transformer)等,这些模型在预训练和微调范式下取得了显著的成果。
参考资料:
1 十分钟理解Transformer
2 The Illustrated Transformer
3 Transformer模型详解(图解最完整版)
4 万字长文,深入浅出Transformer,值得收藏!
2 早期PLMs
2-1 仅编码器PLMs
仅编码器模型,最初为语言理解任务设计,如文本分类,通过编码器网络将文本转换为类别标签。这类模型的代表包括BERT及其衍生模型,如RoBERTa、ALBERT、DeBERTa、XLM、XLNet、UNILM等。
BERT模型
组成:嵌入模块、Transformer编码器堆栈、全连接层。
预训练目标:掩蔽语言模型(MLM)和下一个句子预测。
微调应用:适用于多种语言理解任务,通过添加分类器层进行微调。
变体模型
RoBERTa:通过调整超参数和训练策略提高BERT的鲁棒性。
ALBERT:采用参数减少技术,降低内存消耗,加快训练速度。
DeBERTa:引入解耦注意力机制和增强的遮蔽解码器,提高模型泛化能力。
ELECTRA:使用替换token检测(RTD)作为预训练任务,效率更高。
跨语言模型
XLMs:将BERT扩展到跨语言模型,使用无监督和监督两种方法,通过新的跨语言模型目标提高跨语言能力。
这些模型在语言理解任务上取得了显著成果,推动了AI社区开发更多基于BERT的仅编码器语言模型。
2-2 仅解码器PLM
在仅解码器预训练语言模型领域,OpenAI开发的GPT系列模型扮演了关键角色,从GPT-1到GPT-2。
GPT-1模型
创新:首次证明仅解码器Transformer模型通过生成式预训练能在多种自然语言处理任务上展现优异性能。
预训练:在大量未标记文本上进行自监督学习,目标是预测下一个词。
微调:在特定下游任务上进行微调,需要的样本数量较少。
影响:为后续GPT模型奠定了基础,每一代都在架构上进行了优化,提升了语言任务的性能。
GPT-2模型
能力:在大规模WebText数据集上训练,展示了语言模型在无明确监督的情况下执行特定任务的能力。
改进:在GPT-1的基础上进行了架构上的调整,包括层归一化的位置变动、增加额外的层归一化、修改初始化过程、调整残差层权重。
扩展:扩大了词汇量至50,257个,并将上下文大小从512个标记增加至1024个标记。
GPT系列模型通过逐步的架构优化和扩展,实现了在自然语言处理领域的显著进步,为大型语言模型的发展提供了坚实的基础。
2-3 编码器-解码器PLM
Raffle等人提出,几乎所有的自然语言处理(NLP)任务都可被视为序列到序列的生成任务。基于这一理念,编码器-解码器语言模型被设计为一个统一框架,能够处理所有自然语言理解和生成任务。以下是几个代表性的编码器-解码器预训练语言模型(PLM)的概览:
T5模型
框架:T5是一个文本到文本转换的Transformer模型,将所有NLP任务统一为文本到文本的生成任务,有效利用迁移学习。
特点:通过转换任务格式,T5能够处理广泛的NLP任务。
mT5
多语言支持:mT5是T5的多语言版本,预训练涉及101种语言,基于Common Crawl的多语言数据集。
MASS模型
遮蔽序列到序列预训练:MASS采用编码器-解码器框架,通过遮蔽句子片段并预测这些片段来同时训练编码器和解码器,用于语言嵌入和生成。
BART模型
训练方式:BART基于标准的序列到序列翻译模型架构,通过引入噪声并学习重构原始文本进行预训练。
这些模型展示了编码器-解码器架构在处理多样化NLP任务时的灵活性和强大能力,推动了自然语言理解和生成任务的进展。
3 大型语言模型(LLMs)

3-1 GPT 家族
GPT家族是由OpenAI开发的一系列仅解码器Transformer语言模型,涵盖了从GPT-1到GPT-4等多个版本,以及其他衍生模型如CODEX、WebGPT、InstructGPT和ChatGPT。

开源与封闭源代码
早期的GPT-1和GPT-2模型是开源的,而GPT-3和GPT-4等近期模型则是封闭源代码,仅通过API提供服务。
GPT-3模型
参数规模:GPT-3拥有1750亿参数,是一个巨大的自回归语言模型。
能力:作为首个真正的大型语言模型(LLM),GPT-3展示了无需微调即可在多种任务上应用的能力。
性能:在翻译、问答等NLP任务上表现卓越,且能够处理需要推理或领域适应的任务。
CODEX模型
发布:2023年3月发布,是一个能将自然语言解析生成代码的通用编程模型。
应用:支持GitHub Copilot服务,是GPT-3针对编程应用的微调版本。
WebGPT模型
功能:经过微调,能够使用文本浏览器回答开放式问题,帮助用户搜索和浏览网页。
训练:包括模仿人类浏览行为、学习奖励函数,并通过强化学习进行优化。
InstructGPT
设计:旨在使语言模型遵循人类指令,通过人类反馈进行微调。
改进:提高了真实性,减少了有害输出,同时保持了在公共NLP数据集上的性能。
ChatGPT
发布:2022年11月30日发布,是一个能够完成问答、搜索、摘要等任务的聊天机器人。
技术基础:基于GPT-3.5和GPT-4,遵循InstructGPT的训练理念。
GPT-4模型
最新进展:GPT-4是GPT家族中最新且功能最强大的LLM,具备多模态能力,可以接受图像和文本输入。
性能表现:在专业和学术基准测试中展现出与人类相媲美的性能。
训练与微调:通过预训练和RLHF微调,使模型行为与人类期望一致。
GPT家族的模型不仅在规模上不断增长,而且在能力上也不断创新,推动了自然语言处理技术的发展。
3-2 LLaMA 家族
LLaMA家族是由Meta发布的一系列开源基础语言模型,旨在推动开源大型语言模型(LLMs)的发展,并为特定任务应用提供定制化的解决方案。与GPT模型不同,LLaMA模型在非商业许可下向研究社区开放模型权重。

LLaMA模型
发布时间与规模:2023年2月发布的第一组模型,参数从70亿到650亿不等。
预训练数据:在数万亿标记的公开数据集上进行预训练。
架构创新:采用改进的Transformer架构,包括SwiGLU激活函数、旋转位置嵌入和均方根层归一化。
性能对比:LLaMA-13B模型在基准测试中超越了GPT-3模型。
LLaMA-2
发布背景:2023年7月,Meta与微软合作发布,包括基础语言模型和对话微调的LLaMA-2 Chat。
性能优势:在公共基准测试中表现优于其他开源模型。
Alpaca
来源与微调:从LLaMA-7B模型微调而来,使用自我指导方式生成的遵循指令演示。
成本效益:特别适合学术研究,性能与GPT-3.5相似,但模型规模更小。
Vicuna-13B
开发背景:通过对LLaMA模型微调,利用用户共享对话开发。
初步评估:质量上达到ChatGPT和Google Bard的90%以上,训练成本仅为300美元。
Guanaco
微调方法:使用QLoRA技术高效微调,即使是650亿参数的模型也能在单个GPU上完成。
性能对比:在Vicuna基准测试中胜过所有之前发布的模型。
Koala
构建背景:基于LLaMA,特别关注交互数据,包括用户输入和高性能封闭源代码聊天模型生成的响应。
性能评估:在现实世界用户提示的评估中与最先进的聊天模型相当。
Mistral-7B
模型特点:70亿参数的语言模型,采用分组查询注意力和滑动窗口注意力技术。
性能对比:在多个基准测试中优于其他开源模型,实现了更快的推理和更低的推理成本。
LLaMA家族的模型通过不断的技术创新和性能优化,为开源LLMs领域提供了强有力的竞争者,推动了自然语言处理技术的发展。
3-3 PaLM 家族
PaLM(Pathways语言模型)家族是由谷歌开发的一系列大型语言模型(LLMs),以其庞大的规模和高质量的预训练数据而著称。
首款PaLM模型
发布时间:2022年4月。
规模:基于5400亿参数的Transformer架构。
预训练资源:在7800亿个标记的文本语料上预训练,使用6144个TPU v4芯片和Pathways系统。
性能和成果:PaLM在多个语言理解和生成基准测试中实现了最先进的小样本学习结果,部分任务上与人类表现相当。
U-PaLM模型的持续训练
规模:提供8B、62B和540B三个规模的模型。
持续训练方法:采用UL2R方法,实现计算节省。
Flan-PaLM的指令微调
微调特点:使用大量任务和数据集进行指令微调。
性能提升:在多个任务上显著提高了性能。
PaLM-2模型
性能提升:相比前身,PaLM-2在多语言和推理能力上表现更佳,同时具有更高的计算效率。
Med-PaLM:面向医疗领域的专用模型
模型定位:专门用于提供高质量医学问题答案。
微调方法:使用指令提示微调方法,适应医学领域。
Med-PaLM 2的进一步改进
改进方法:通过医学领域微调和合成提示进行改进。
性能提升:在MedQA数据集上得分显著提高,创造了新的最先进水平。
PaLM家族的模型通过不断的技术创新和性能优化,在自然语言处理领域展现了强大的能力,特别是在多语言理解和生成任务上。此外,通过持续训练和指令微调,PaLM家族的模型在特定领域如医疗保健中也展现出了巨大的潜力。
相关文章:
Large Language Model系列之二:Transformers和预训练语言模型
Large Language Model系列之二:Transformers和预训练语言模型 1 Transformer模型 Transformer模型是一种基于自注意力机制的深度学习模型,它最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,主要用于机器翻译任务。随…...

java后端项目启动失败,解决端口被占用问题
报错信息: Web server failed to start . Port 8020 was already in use. 1、查看端口号 netstat -ano | findstr 端口号 2、终止进程 taskkill /F /PID 进程ID 举例:关闭8020端口...
PostgreSQL安装/卸载(CentOS、Windows)
说明:PostgreSQL与MySQL一样,是一款开源免费的数据库技术,官方口号:The World’s Most Advanced Open Source Relational Database.(世界上最先进的开源关系数据库),本文介绍如何在Windows、Cen…...

OutOfMemoryError异常OOM排查
目录 参考工具MAT(Memory Analyzer)一、产生原因二、测试堆溢出 java.lang.OutOfMemoryError: Java heap space测试代码运行手动导出dump文件mat排查打开dump文件查看Leak Suspects(泄露疑点)参考 【JVM】八、OOM异常的模拟 MAT工具分析Dump文件(大对象定位) 用arthas排…...

【Python】Arcpy将excel点生成shp文件
根据excel点经纬度数据,生成shp,参考博主的代码,进行了修改,在属性表中保留excel中的数据。 参考资料:http://t.csdnimg.cn/OleyT 注意修改以下两句中的数字。 latitude float(row[1]) longitude float(row[2])imp…...

torch之从.datasets.CIFAR10解压出训练与测试图片 (附带网盘链接)
前言 从官网上下载的是长这个样子的 想看图片,咋办咧,看下面代码 import torch import torchvision import numpy as np import os import cv2 batch_size 50transform_predict torchvision.transforms.Compose([torchvision.transforms.ToTensor(),…...

什么ISP?什么是IAP?
做单片机开发的工程师经常会听到两个词:ISP和IAP,但新手往往对这两个概念不是很清楚,今天就来和大家聊聊什么是ISP,什么是IAP? 一、ISP ISP的全称是:In System Programming,即在系统编程&…...

外卖霸王餐系统怎么快速盈利赚钱?
微客云外卖霸王餐系统,作为近年来外卖行业中的一股新兴力量,以其独特的商业模式和营销策略,迅速吸引了大量消费者的目光。该系统通过提供显著的折扣和返利,让顾客能够以极低的价格甚至免费享受到美味的外卖,同时&#…...

Linux环境下安装Nodejs
Linux环境下安装Nodejs 下载地址:https://nodejs.org/zh-cn/download/package-manager 一、使用压缩包自定义安装 上述链接下载好对应版本的软件包后,我存放到 /evn/nodejs 目录下(根据自己实际情况设置) 设置软链接 sudo ln…...

【Rust】字符串String类型学习
什么是String Rust的核心语言中只有一个String类型,那就是String slice,str通常被当作是&str的借用。String类型是通过标准库提供的,而不是直接编码到核心语言中,它是一个可增长的、可变的、utf-8编码的类型。str和String都是utf-8编码的…...
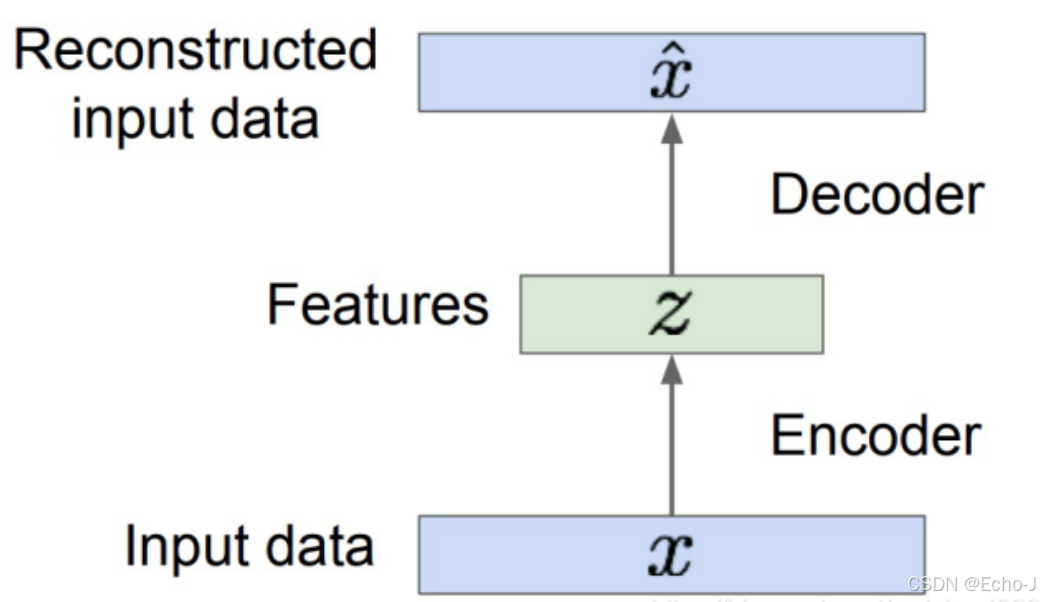
先验概率 后验概率 最大似然估计 自编码器AE
先验概率 先验概率:由因求果中的因 作用:后验概率是比较难以计算的,我们通常使用贝叶斯公式由先验概率计算后验概率。 贝叶斯公式:P(B|A)P(A|B)P(B)/P(A),其中P(B|A)为后验概率,P(A|B)为先验概率。 后验…...

qt 鼠标接近某线时,形状变化举例
1.qt 鼠标接近某线时,形状变化举例 在Qt中,要实现鼠标接近某条线时形状发生变化的效果,你需要利用QWidget的enterEvent和leaveEvent,或者更通用的mouseMoveEvent来检测鼠标的位置,并相应地改变鼠标的光标形状。 以下…...

800块,我从淘宝上买AGV……
导语 大家好,我是社长,老K。专注分享智能制造和智能仓储物流等内容。 新书《智能物流系统构成与技术实践》人俱乐部 从淘宝上打算够购买一台AGV小车,上去一搜,嘿,你别说,还真有。便宜的才200块钱。 很兴奋把…...

C++相关概念和易错语法(21)(虚函数、协变、析构函数的重写)
多态的核心是虚函数,本文从虚函数出发,根据原理慢慢推进得到结论,进而理解多态 1.虚函数 先看一下下面的代码,想想什么导致了这个结果 #include <iostream> using namespace std;class A { public:virtual void test(){co…...
SoulApp创始人张璐团队以AI驱动社交进化,平台社交玩法大变革
在科技飞速发展的今天,人工智能正逐步渗透到社交媒体的各个环节,赋能全链路社交体验。AI的引入不仅提升了内容推荐的精准度,使用户能够更快速地发现感兴趣的内容,还能通过用户行为预测,帮助平台更好地理解和满足用户需求。此外,AI驱动的虚拟助手和聊天机器人也正在改变用户互动…...

MySQL事务隔离级别+共享锁,排他锁,乐观锁,悲观锁
在操作数据库的时候,可能会由于并发问题而引起的数据的不一致性(数据冲突)。 MySQL事务隔离级别 一个事务的执行,本质上就是一条工作线程在执行,当出现多个事务同时执行时,这种情况则被称之为并发事务&am…...

Zynq系列FPGA实现SDI编解码转SFP光口传输(光端机),基于GTX高速接口,提供6套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐本博已有的 SDI 编解码方案本方案在Xilinx-Kintex7上的应用 3、详细设计方案设计原理框图输入Sensor之-->OV5640摄像头输入Sensor之-->HDMIVDMA图像缓存RGB转BT1120GTX 解串与串化SMPTE SD/HD/3G SDI IP核BT1120转RGBHDMI输…...

SpringBoot实现图形验证码
目录 项目创建 前端代码实现 约定前后端交互接口 需求分析 接口定义 Hutool工具 实现服务器端代码 引入依赖 获取验证码 验证码校验 调整前端代码 随着安全性的要求越来越高,目前许多项目中都使用了验证码,验证码也有各种类型,如 …...

【JVM基础01】——介绍-初识JVM运行流程
目录 1- 引言:初识JVM1-1 JVM是什么?(What)1-1-1 概念1-1-2 优点 1-2 为什么学习JVM?(Why) 2- 核心:JVM工作的原理(How)⭐2-1 JVM 的组成部分及工作流程2-2 学习侧重点 3- 小结(知识点大纲):3-1 JVM 组成3…...

图数据库 - Neo4j简介
深入理解 Neo4j 与 Cypher 语法 什么是 Neo4j Neo4j 是一个基于图的数据库管理系统,它使用图形理论来表示数据关系。这种数据库与传统的关系型数据库不同,它更适合处理高度互联的数据结构。 基本概念 图:在 Neo4j 中,数据以图的…...

出海技术团队的沟通挑战:不是语言问题,是文化差异
当软件测试从业者成为“出海先锋”,我们最先打包进行李箱的是什么?是精通JIRA操作,是熟练Python脚本,是深谙CI/CD流水线。我们自信满满,以为能用一口流利的英语、一套标准的ISTQB术语,在全球化的技术团队中…...

从B73到5000个RILs:手把手拆解玉米NAM群体构建的完整流程与关键决策
玉米NAM群体构建全流程解析:从亲本筛选到RILs优化的科学决策 站在玉米遗传研究的十字路口,我们常常面临一个核心挑战:如何在有限资源下构建既能捕获广泛遗传多样性,又能实现精准定位的群体?2009年,Buckler团…...

80C166/C167芯片内部RAM执行代码技术详解
1. 80C166/C167芯片内部RAM执行代码的技术解析在嵌入式系统开发中,有时我们需要将特定代码从ROM复制到芯片内部RAM执行。这种需求常见于需要改变总线模式的场景,比如在Siemens 80C166/C167微控制器上切换8位/16位模式或改变总线复用配置。根据Siemens官方…...

大数据搬运工 · Sqoop
🚛 在「关系型数据库」与「Hadoop 大仓库」之间 | 批量、高效、并行运输数据💡 生活比喻: 想象你的学校图书馆(关系型数据库)有一大堆超重的图书,而学校新建的“超级储藏大楼”(Hado…...

2026年ERP+分销一体化还是独立部署?两种架构的优劣对比与选型建议
分销ERP的选型是一个典型的“三年决策”——今天选了什么,未来三年就要和它绑定。选小了,业务一扩张系统就撑不住;选大了,为用不上的功能付了高昂成本。更棘手的困境是“换系统”——已经跑了好几年的业务数据和流程,迁…...

React Props:深入解析组件间的数据传递
React Props:深入解析组件间的数据传递 在React中,组件间的数据传递是构建复杂应用的关键。Props(属性)是React组件间数据传递的主要方式,它允许父组件向子组件传递数据。本文将深入探讨React Props的概念、使用方法以及注意事项。 一、Props的概念 Props是React组件的…...
 - 第二期)
【期刊征稿 | 录用后最快当月见刊,刊后1个月检索,且检索稳定】第九届艺术、教育与管理国际学术会议(ICAEM 2026) - 第二期
录用后最快当月见刊,刊后1个月检索,且检索稳定 | 含ISSN号,DOI,封面目录 第九届艺术、教育与管理国际学术会议(ICAEM 2026) - 第二期 2026 9th International Conference on Arts, Education and Management 2026年…...
亲测好用的AI写作辅助平台,毕业生收藏备用)
(良心整理)亲测好用的AI写作辅助平台,毕业生收藏备用
毕业季论文写作真的这么难吗?选题方向模糊、文献资料繁杂、写作进度缓慢、查重修改头疼、格式规范混乱…… 这份亲测好用的AI论文工具清单,涵盖中英文写作、全流程支持、专项功能、免费与高性价比选项,从开题构思到最终定稿全程护航ÿ…...

神作《盲视》,最硬核的反人类科幻,二十年前预言了AI的冰冷本质
哎呀好久不更新了,半夜睡不着起来随便写点,免得账号被回收了。《盲视》是是加拿大科幻作家彼得沃茨的一部硬科幻经典,入围雨果奖、轨迹奖、坎贝尔奖。但它也是一本阅读门槛很高阅读体验很差的小说。其不适感一部分来自它晦涩的文风和叙事方式…...

原神抽卡数据分析神器:告别盲目抽卡,用数据掌控你的欧皇之路
原神抽卡数据分析神器:告别盲目抽卡,用数据掌控你的欧皇之路 【免费下载链接】genshin-wish-export Easily export the Genshin Impact wish record. 项目地址: https://gitcode.com/GitHub_Trending/ge/genshin-wish-export 你是否曾在原神抽卡时…...