【python】pandas报错:UnicodeDecodeError详细分析,解决方案以及如何避免

✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Python全栈,PyQt5,Tkinter,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,云原生k8s,linux,shell脚本等实操经验,网站搭建,数据库等分享。所属的专栏:Python常见报错以及解决办法集锦
景天的主页:景天科技苑
文章目录
- Pandas运行报错`UnicodeDecodeError`深度解析:原因、解决与预防策略
- 1.报错示例
- 2.报错原因详解
- 3.解决办法
- 4.如何避免此类错误
- 5.代码示例与实战演练
- 6.深入分析与最佳实践
- (1)数据预处理
- (2)使用Pandas的高级功能
- (3)错误处理与日志记录
- (4)代码示例:数据预处理与异常处理
- 7.结论
Pandas运行报错UnicodeDecodeError深度解析:原因、解决与预防策略
在使用Pandas库进行数据处理时,我们可能会遇到各种报错。这些报错可能源于数据格式、文件路径、编码方式、数据类型不匹配等多种原因。本文将针对一种常见的Pandas运行报错进行深入分析,包括报错的具体原因、有效的解决办法以及如何避免此类错误的再次发生,并附带详细的代码示例。
1.报错示例
假设你在尝试使用Pandas的read_csv函数读取一个CSV文件时,遇到了以下报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid continuation byte
这个错误通常表明,文件编码与你在read_csv函数中指定的编码格式不匹配。
2.报错原因详解
-
文件编码不匹配:
CSV文件的实际编码格式可能与你在read_csv函数中指定的编码格式不一致。例如,文件可能使用gbk或latin1编码,而你在读取时指定了utf-8。 -
特殊字符问题:
文件中可能包含一些在当前编码下无法正确解析的特殊字符或字节序列。 -
文件损坏或不完整:
文件可能在保存或传输过程中损坏,导致无法按预期解码。 -
Python环境或Pandas版本问题:
在某些情况下,Python环境或Pandas库的特定版本可能与文件的编码方式不兼容。
3.解决办法
-
指定正确的编码格式:
首先,你需要确定CSV文件的实际编码格式。可以使用文本编辑器(如Notepad++、Sublime Text等)打开文件,并查看或修改其编码。一旦确定了正确的编码格式,你可以在read_csv函数中指定它:import pandas as pd# 假设文件实际使用'gbk'编码 data = pd.read_csv('./data.csv', encoding='gbk') -
尝试常见的编码格式:
如果你不确定文件的编码格式,可以尝试几种常见的编码格式来读取文件:import pandas as pdencodings = ['utf-8', 'gbk', 'latin1', 'iso-8859-1'] for enc in encodings:try:data = pd.read_csv('./data.csv', encoding=enc)print(f"Success with encoding: {enc}")breakexcept UnicodeDecodeError:print(f"Failed with encoding: {enc}") -
使用错误处理机制:
在读取文件时,你可以使用error_bad_lines参数来跳过无法解析的行:data = pd.read_csv('./data.csv', encoding='utf-8', error_bad_lines=False) -
检查并清理文件:
如果可能的话,打开CSV文件并检查是否有任何不寻常的字符或格式问题。你可以使用文本编辑器或编写一个简单的脚本来清理文件。 -
更新Python和Pandas库:
确保你的Python环境和Pandas库都是最新版本,以避免因版本不兼容导致的编码问题。pip install pandas --upgrade
4.如何避免此类错误
-
统一编码标准:
在处理多个文件时,尽量确保所有文件的编码格式一致。如果可能的话,将所有文件转换为UTF-8编码,这是目前最广泛支持的编码格式。 -
仔细检查文件路径和名称:
在编写代码时,不要手动输入文件路径和名称,而是使用文件对话框或复制粘贴来确保准确性。 -
使用专业的数据处理工具:
对于复杂的数据处理任务,考虑使用专业的数据处理工具或编程语言(如Python的Pandas库),它们提供了更强大的错误处理和数据处理功能。 -
定期备份数据:
定期备份你的数据文件,以防文件损坏或丢失。 -
编写健壮的代码:
在编写读取文件的代码时,使用异常处理来捕获并处理可能发生的错误。 -
测试和验证:
在将代码部署到生产环境之前,确保在不同的环境和数据集上充分测试和验证你的代码。
5.代码示例与实战演练
下面是一个完整的代码示例,展示了如何读取一个可能具有不同编码格式的CSV文件,并处理可能发生的编码错误:
import pandas as pd# 定义要尝试的编码列表
encodings = ['utf-8', 'gbk', 'latin1', 'iso-8859-1']# 尝试不同的编码来读取文件
for enc in encodings:try:# 尝试使用当前编码读取文件data = pd.read_csv('./data.csv', encoding=enc)print(f"成功使用编码:{enc} 读取文件")# 如果成功,则跳出循环breakexcept UnicodeDecodeError:# 如果失败,则尝试下一个编码print(f"使用编码:{enc} 读取文件失败")# 检查数据是否已成功读取
if 'data' in locals():print(data.head())
else:print("无法读取文件,请检查文件编码或文件是否损坏。")
在这个示例中,我们定义了一个编码列表,并尝试使用列表中的每个编码来读取CSV文件。如果某个编码成功读取了文件,我们就会打印出成功的消息,并跳出循环。如果所有编码都尝试失败,我们会打印出一个错误消息。
通过这种方法,我们可以有效地处理因编码不匹配而导致的读取错误,并确保我们的数据处理流程更加健壮和可靠。同时,我们也展示了如何通过编写健壮的代码和进行充分的测试来避免此类错误的再次发生。
6.深入分析与最佳实践
在解决了编码错误之后,我们进一步探讨如何优化数据处理流程,并分享一些最佳实践,以确保更高效、更稳定的数据操作。
(1)数据预处理
-
数据清洗:
在读取数据之前,对数据进行清洗是一个好习惯。这包括去除不必要的空格、替换或删除异常值、统一日期格式等。 -
数据类型转换:
确保数据列的数据类型与你的分析或模型要求相匹配。例如,将数字字符串转换为数值类型,将日期字符串转换为日期类型。 -
缺失值处理:
检查数据中的缺失值,并根据需要进行填充、删除或插值处理。
(2)使用Pandas的高级功能
-
分块读取:
对于非常大的文件,可以使用read_csv的chunksize参数分块读取数据,以避免内存不足的问题。 -
并行处理:
利用Pandas的DataFrame.apply方法结合multiprocessing库,可以对数据进行并行处理,显著提高处理速度。 -
使用
dtype参数:
在读取CSV文件时,使用dtype参数指定列的数据类型,可以减少内存使用并提高处理速度。
(3)错误处理与日志记录
-
异常捕获:
在数据处理代码中使用try-except块来捕获并处理可能发生的异常,如文件不存在、读取错误等。 -
日志记录:
使用Python的logging库记录数据处理过程中的关键步骤和错误信息,以便于问题追踪和性能监控。
(4)代码示例:数据预处理与异常处理
import pandas as pd
import logging# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')# 尝试读取并预处理数据
try:# 读取数据,同时指定数据类型以减少内存使用data = pd.read_csv('./data.csv', encoding='utf-8', dtype={'column1': 'int32', 'column2': 'float64'})# 数据清洗:去除空格、替换异常值等data['column1'] = data['column1'].str.strip()data['column2'] = data['column2'].replace({-999: None}) # 假设-999是异常值# 数据类型转换data['column1'] = data['column1'].astype('int32')# 缺失值处理:填充或删除data['column2'].fillna(data['column2'].mean(), inplace=True) # 用均值填充# 输出预处理后的数据头部logging.info('数据预处理完成,输出头部:')print(data.head())except Exception as e:# 记录错误信息logging.error(f'数据处理过程中发生错误:{e}')
在这个示例中,我们展示了如何在读取数据时进行数据类型指定,以减少内存使用。同时,我们也进行了数据清洗、类型转换和缺失值处理。通过使用try-except块和日志记录,我们能够更好地处理异常并监控数据处理过程。
7.结论
通过深入理解Pandas运行报错的原因,并采取有效的解决办法和预防措施,我们可以显著提高数据处理的稳定性和效率。同时,通过数据预处理、使用Pandas的高级功能、错误处理和日志记录等最佳实践,我们可以进一步优化数据处理流程,确保数据的准确性和一致性。在数据处理领域,持续学习和实践是提升技能的关键,希望本文能为你提供有价值的参考和指导。
相关文章:
【python】pandas报错:UnicodeDecodeError详细分析,解决方案以及如何避免
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

FlinkModule加载HiveModule异常
HiveModule这个模块加载不出来 加在不出来这个模块,网上查说是要加下面这个依赖 <dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_${scala.binary.version}</artifactId><version>${flink.…...

计算机硬件---如何更新自己电脑的BLOS
1找官网 例如“我使用的是HP(惠普)品牌的电脑”我只需要在浏览器上搜索“惠普官网”或“惠普-blos更新” 就可以看到,来自官网中更新blos的信息 2.有些品牌要查序列号该怎么办呢? 有许多方法可以查询,例如…...

AI算法17-贝叶斯岭回归算法Bayesian Ridge Regression | BRR
贝叶斯岭回归算法简介 贝叶斯岭回归(Bayesian Ridge Regression)是一种回归分析方法,它结合了岭回归(Ridge Regression)的正则化特性和贝叶斯统计的推断能力。这种方法在处理具有大量特征的数据集时特别有用ÿ…...
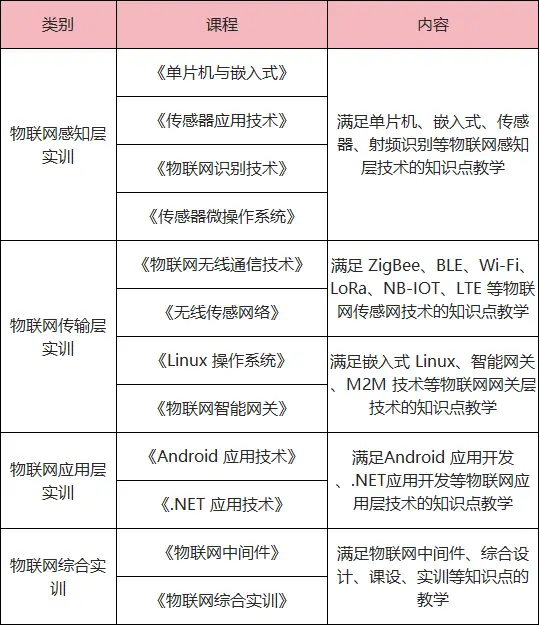
唯众物联网综合实训台 物联网实验室建设方案
物联网综合实训装置 物联网工程应用综合实训台是我公司针对职业院校物联网行业综合技能型人才培养,综合运用传感器技术、RFID技术、接口控制技术、无线传感网技术、Android应用开发等,配合实训台上的433M无线通信设备、ZigBee节点、射频设备、控制设备、…...

深入浅出 Vue.js:从基础到进阶的全面总结
深入浅出 Vue.js:从基础到进阶的全面总结 Vue.js 是一个用于构建用户界面的渐进式框架。它不仅易于上手,还能通过其强大的生态系统支持复杂的应用开发。本文将从基础到进阶,全面总结 Vue.js 的核心概念、常用技术和最佳实践,并提…...

路网双线合并单线——ArcGISpro 解决方法
路网双线合并成单线是一个在地图制作、交通规划以及GIS分析中常见的需求。双线路网定义:具有不同流向、不同平面结构的道路。此外,车道数较多的道路(例如,双黄实线车道数大于4的道路)也可以视为双线路网,本…...

邮箱验证码功能开发
该文章用于记录怎么进行邮箱验证码开发。 总所周知,我们在某些网站进行注册的适合总是会遇到什么填写邮箱,邮箱接收验证码,验证通过后才可以继续注册,那么这个功能是怎么实现的呢? 一,准备工作 1.1 邮箱…...
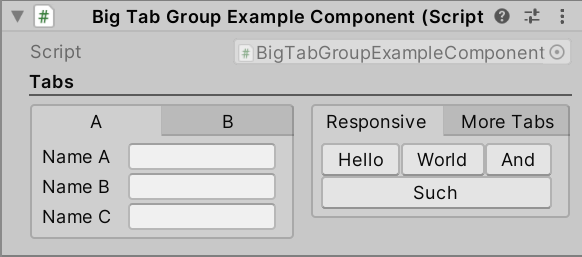
2024-07-15 Unity插件 Odin Inspector3 —— Button Attributes
文章目录 1 说明2 Button 特性2.1 Button2.2 ButtonGroup2.3 EnumPaging2.4 EnumToggleButtons2.5 InlineButton2.6 ResponsiveButtonGroup 1 说明 本文介绍 Odin Inspector 插件中有关 Button 特性的使用方法。 2 Button 特性 2.1 Button 依据方法,在 Inspec…...

根据脚手架archetype快速构建spring boot/cloud项目
1、找到archetype,并从私仓下载添加archetype到本地 点击IDEA的file,选择new project 选择maven项目,勾选create from archetype 填写archetype信息,(repository填写私仓地址) 2、选择自定义的脚手架arche…...

安灯系统在电力设备制造业中的应用效果
安灯系统作为面向制造业生产现场的专门应用软硬件系统,在电力设备制造企业中发挥着重要的作用。作为精益制造执行的核心工具,安灯系统为企业提供了快速联络生产、物料、维修、主管等部门的功能,以实时掌控和管理生产线状况,实现生…...

代码随想录打卡第二十五天
代码随想录–回溯部分 day 24 休息 day 25 回溯第三天 文章目录 代码随想录--回溯部分一、力扣93--复原IP地址二、力扣78--子集三、力扣90--子集Ⅱ 一、力扣93–复原IP地址 代码随想录题目链接:代码随想录 有效 IP 地址 正好由四个整数(每个整数位于 0…...

openharmony上传图片,并获取返回路径
适用条件: openharmony开发 4.0 release版本,对应能力API10 一直不断尝试,一会用官方提供的上传文件,一会用第三方库的axios都不行, 一会报错‘没权限,一会报错’路径错误,还有报错‘401参数错…...

git常用命令及git分支
git常用命令及git分支 git常用命令设置用户签名初始化本地库查看本地库状态将文件添加到暂存区提交到本地库查看历史记录版本穿梭 git分支什么是分支分支的好处分支的操作查看分支创建分支切换分支删除分支合并分支合并冲突 git常用命令 设置用户签名 //设置用户签名 git con…...

c# 依赖注入-服务的生命周期
在 C# 中,依赖注入服务的生命周期指的是在应用程序中管理和控制依赖项注入服务对象的生命周期的方式。常见的生命周期包括瞬态(transient)、作用域(scoped)和单例(singleton)三种。 瞬态&#…...

一站式短视频矩阵开发,高效托管!
短视频矩阵系统源码SaaS解决方案提供全面的开发服务,包括可视化视频编辑、矩阵式内容分发托管以及集成的多功能开发支持。 短视频矩阵:引爆您的数字营销革命 短视频矩阵系统是一套多功能集成解决方案,专为提升在短视频平台上的内容创作、管理…...

实践致知第16享:设置Word中某一页横着的效果及操作
一、背景需求 小姑电话说:现在有个word文档,里面有个表格太长(如下图所示),希望这一个设置成横的,其余页还是保持竖的! 二、解决方案 1、将鼠标放置在该页的最前面闪烁,然后选择“页面”》“↘…...

Leetcode—3011. 判断一个数组是否可以变为有序【中等】(__builtin_popcount()、ranges::is_sorted())
2024每日刷题(144) Leetcode—3011. 判断一个数组是否可以变为有序 O(n)复杂度实现代码 class Solution { public:bool canSortArray(vector<int>& nums) {// 二进制数位下1数目相同的元素就不进行组内排序// 只进行分组// 当前组的值若小于…...

盲盒一番赏小程序:开启惊喜之旅,探索无限创意!
在这个充满无限想象与惊喜的时代,盲盒已成为连接心灵与梦想的奇妙桥梁。为了将这份独特的乐趣与探索精神传递给每一位热爱生活、追求新鲜的你,我们自豪地推出了“盲盒一番赏”小程序——一个集创意、趣味、互动与社交于一体的盲盒新纪元,邀您…...

Linux基础知识之Linux文件系统权限
概述 文件权限控制对文件的访问可以针对文件所属用户、所属组和其他用户可以设置不同的权限权限具有优先级。user 权限覆盖 group 权限,后者覆盖 other 权限 权限:读取、写入和执行 权限 对文件的影响 对目录的影响 r (读取) 可以读取文件的内容 …...
GoogleTranslate_IPFinder高级功能详解:自定义IP段扫描与在线同步服务
GoogleTranslate_IPFinder高级功能详解:自定义IP段扫描与在线同步服务 【免费下载链接】GoogleTranslate_IPFinder 谷歌翻译API服务器的IP扫描、测速工具。 项目地址: https://gitcode.com/gh_mirrors/go/GoogleTranslate_IPFinder GoogleTranslate_IPFinder…...

VHS Pro深度解析:Unity中模拟录像带失真的物理建模与工业应用
1. 为什么今天还有人执着于“坏掉的画质”?——VHS Pro 不是怀旧装饰,而是视觉叙事新工具你有没有在剪辑软件里拖动一个“胶片颗粒”滑块,看着画面突然蒙上一层灰蒙蒙的噪点,然后心里咯噔一下:这玩意儿真能用ÿ…...

KMS智能激活终极指南:三步永久激活Windows和Office的完整教程
KMS智能激活终极指南:三步永久激活Windows和Office的完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然…...

电脑自动化 OpenClaw 安装教程 自然语言操控电脑
告别命令行!Windows OpenClaw 一键安装,5 分钟一键部署 ✨ 前言 OpenClaw(小龙虾)是一款能直接操控电脑的 AI 智能体,无需复杂配置、不用敲命令行,Windows 环境下全程可视化操作,5 分钟即可完…...

QTTabBar终极指南:5分钟掌握Windows文件管理标签页神器
QTTabBar终极指南:5分钟掌握Windows文件管理标签页神器 【免费下载链接】qttabbar QTTabBar is a small tool that allows you to use tab multi label function in Windows Explorer. https://www.yuque.com/indiff/qttabbar 项目地址: https://gitcode.com/gh_m…...
)
从厨房小白到AI大模型高手:小白程序员也能轻松掌握大模型的秘密(收藏版)
本文旨在打破对AI大模型的刻板印象,用通俗易懂的语言解释AI大模型的工作原理,并通过实例教学,帮助读者从零开始掌握AI大模型的应用。文章涵盖了AI大模型的基本概念、提示词工程、RAG技术、函数调用、智能体构建、微调与部署等关键知识点&…...

如何在Python中创建测试图像
原文地址:https://medium.com/itberrios6/how-to-make-a-test-image-in-python-1a6c2d41b6ab 学习如何制作测试图像 在计算机视觉和图像处理中,创建测试图像以更好地了解算法或滤波器将如何执行通常是有用的。测试图像是一个基准,可以将多种…...

企业级应用如何通过Taotoken聚合API管理多个大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken聚合API管理多个大模型调用 在构建企业级AI应用时,一个常见的需求是同时接入多个不同厂商的…...

智能停车系统告别拥堵!巨有科技让景区停车畅行无忧
每逢节假日,景区停车场便成了“重灾区”——入口大排长龙、场内找位半小时、缴费排队苦不堪言。这不仅严重消耗游客耐心,更直接拉低景区口碑与运营效率。在文旅消费持续回暖的今天,停车体验已成为衡量景区服务力的关键指标。巨有科技以数据驱…...

G-Helper:轻量级开源硬件控制工具的深度技术解析
G-Helper:轻量级开源硬件控制工具的深度技术解析 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertb…...