常见的五种聚类算法总结
常见的聚类算法总结
1. K-Means 聚类
描述
K-Means 是一种迭代优化的聚类算法,它通过最小化样本点到质心的距离平方和来进行聚类。
思想
- 随机选择 K 个初始质心。
- 分配每个数据点到最近的质心,形成 K 个簇。
- 重新计算每个簇的质心。
- 重复上述步骤,直到质心不再变化或达到最大迭代次数。
代码例子
from sklearn.cluster import KMeans
import numpy as np# 生成示例数据
X = np.array([[1, 2], [1, 4], [1, 0], [10, 2], [10, 4], [10, 0]])# 定义 KMeans 模型
kmeans = KMeans(n_clusters=2, random_state=0)# 训练模型
kmeans.fit(X)# 获取聚类结果
labels = kmeans.labels_
centroids = kmeans.cluster_centers_print("聚类标签:", labels)
print("质心:", centroids)
2. 层次聚类 (Hierarchical Clustering)
描述
层次聚类是一种基于树状结构的聚类方法,分为自下而上(凝聚)和自上而下(分裂)两种。
思想
- 自下而上:每个数据点开始为一个簇,不断合并最相似的簇,直到所有点合并为一个簇或达到预定的簇数。
- 自上而下:开始时将所有数据点视为一个簇,不断拆分最不相似的簇,直到每个点为一个簇或达到预定的簇数。
代码例子
from sklearn.cluster import AgglomerativeClustering# 定义层次聚类模型
hierarchical = AgglomerativeClustering(n_clusters=2)# 训练模型
hierarchical.fit(X)# 获取聚类结果
labels = hierarchical.labels_print("聚类标签:", labels)3. DBSCAN 聚类
描述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够发现任意形状的簇,同时识别噪声点。
思想
- 选择一个样本点,如果在其 ε 邻域内的点数不少于 minPts,则将这些点视为一个簇的核心点。
- 将核心点邻域内的点添加到该簇中,重复这个过程,直到簇不再增长。
- 标记未分配到任何簇的点为噪声点。
代码例子
from sklearn.cluster import DBSCAN# 定义 DBSCAN 模型
dbscan = DBSCAN(eps=3, min_samples=2)# 生成示例数据
X = np.array([[1, 2], [2, 2], [2, 3],[8, 7], [8, 8], [25, 80]])# 训练模型
dbscan.fit(X)# 获取聚类结果
labels = dbscan.labels_print("聚类标签:", labels)
4. 均值漂移 (Mean Shift) 聚类
描述
均值漂移是一种基于密度的聚类算法,通过不断移动数据点到高密度区域的中心,找到簇的质心。
思想
- 对每个点,计算其在一定窗口(带宽)内的密度中心,将点移动到密度中心。
- 重复上述过程,直到所有点都在其密度中心。
- 将密度中心附近的点合并为一个簇。
代码例子
from sklearn.cluster import MeanShift
import numpy as np# 生成示例数据
X = np.array([[1, 2], [2, 2], [2, 3],[8, 7], [8, 8], [25, 80]])# 定义均值漂移模型
meanshift = MeanShift(bandwidth=2)# 训练模型
meanshift.fit(X)# 获取聚类结果
labels = meanshift.labels_
centroids = meanshift.cluster_centers_print("聚类标签:", labels)
print("质心:", centroids)
5. 高斯混合模型 (Gaussian Mixture Model, GMM)
描述
高斯混合模型是一种基于概率模型的聚类方法,假设数据由多个高斯分布组成,通过期望最大化(EM)算法估计参数。
思想
- 初始化每个高斯分布的参数。
- E步:计算每个样本属于每个高斯分布的概率。
- M步:根据概率更新高斯分布的参数。
- 重复上述过程,直到参数收敛。
代码例子
from sklearn.mixture import GaussianMixture
import numpy as np# 生成示例数据
X = np.array([[1, 2], [2, 2], [2, 3],[8, 7], [8, 8], [25, 80]])# 定义高斯混合模型
gmm = GaussianMixture(n_components=2, random_state=0)# 训练模型
gmm.fit(X)# 获取聚类结果
labels = gmm.predict(X)
centroids = gmm.means_print("聚类标签:", labels)
print("质心:", centroids)
相关文章:

常见的五种聚类算法总结
常见的聚类算法总结 1. K-Means 聚类 描述 K-Means 是一种迭代优化的聚类算法,它通过最小化样本点到质心的距离平方和来进行聚类。 思想 随机选择 K 个初始质心。分配每个数据点到最近的质心,形成 K 个簇。重新计算每个簇的质心。重复上述步骤&…...

智能车存在网络安全隐患,如何应设计出更好的安全防护技术?
智能车网络安全防护技术的研究与设计 摘要:随着智能车技术的迅速发展,车辆的网络连接性不断增强,然而这也带来了诸多网络安全隐患。本文深入探讨了智能车面临的网络安全威胁,并提出了一系列创新的安全防护技术设计,旨…...
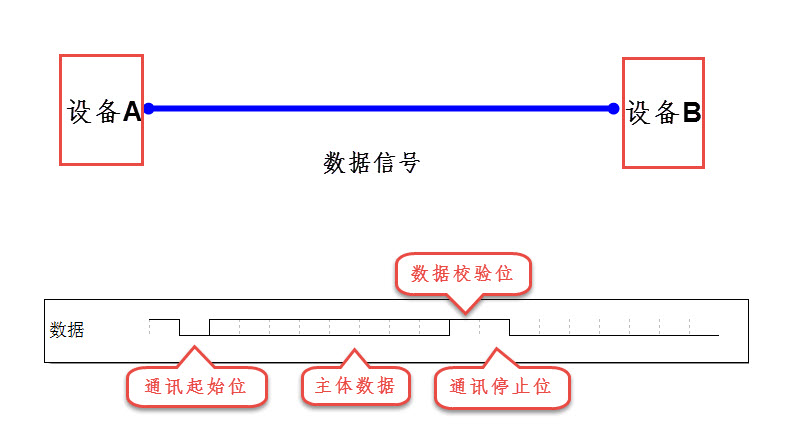
通讯的概念
通讯的概念 文章目录 通讯的概念1.通讯的基本概念2. 串行通讯与并行通讯2. 全双工、半双工及单工通讯3. 同步通讯与异步通讯4. 通讯速率 1.通讯的基本概念 通讯是指在嵌入式系统中实现数据交换的技术手段,它涉及到硬件与硬件、硬件与软件之间的信息传输。基本概念包…...
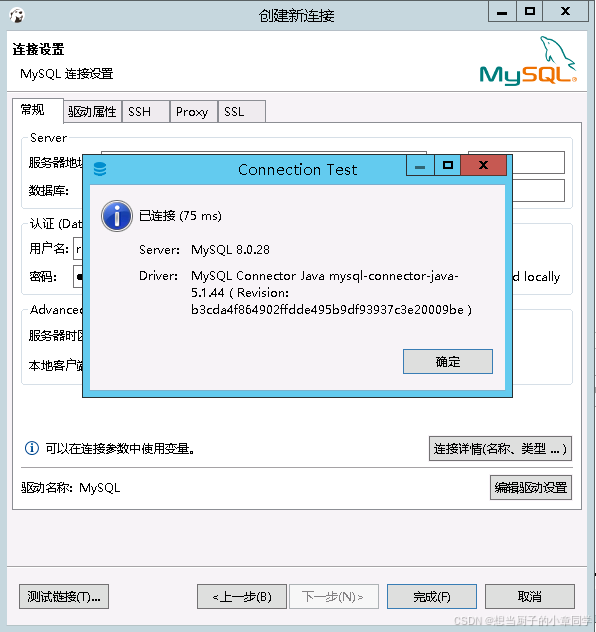
Centos7 rpm 安装 Mysql 8.0.28
Centos7 rpm 安装 Mysql 8.0.28 一、检查系统是否已经安装了Mysql 如果安装了则卸载 [rootiZbp1byzaznzn9jncxr010Z /]# rpm -qa | grep mysql[rootiZbp1byzaznzn9jncxr010Z /]# rpm -qa | grep mariadb mariadb-libs-5.5.68-1.el7.x86_64如果安装了 mysql ,maria…...

Linux 多进程编程详解
Linux 多进程编程详解 多进程编程是现代操作系统中一种重要的并发编程技术。通过在同一程序中运行多个独立的进程,可以实现并发处理,充分利用多核处理器的优势,提高程序的运行效率。本文将详细介绍Linux多进程的基本概念、创建方法、进程间通…...

C语言之大小端理解
目录 1前言2 大小端理解与区分3 大小端的识别和基本切换操作4 总结 1前言 在汽车CAN通讯报文中往往会接触到Intel类型和motorola类型,实际项目中涉及到多机通讯也会接触到大小端问题 2 大小端理解与区分 大端(Big_Endian) :低字节放在高地址小端(Little_Endian):…...

GIT相关操作,推送本地分支到远程仓库流程记录学习
git流程 切换到源文件夹:cd 源文件夹克隆远程仓库:git clone [ssh]进入项目文件夹:cd .\project\查看本地分支:git branch获取远程仓库更新,使远程同步:git fetch查看所有分支(包括远程分支&am…...
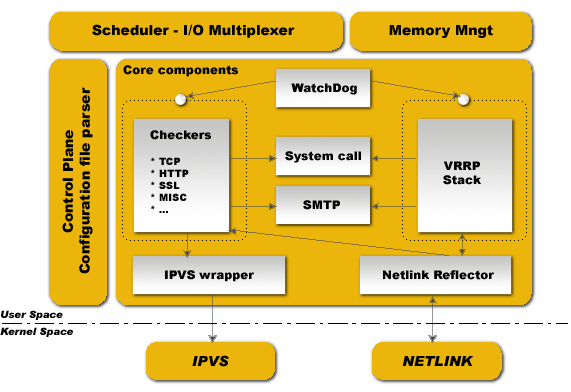
网络协议 — Keepalived 高可用方案
目录 文章目录 目录Keepalived 是实现了 VRRP 协议的软件Keepalived 的软件架构VRRP StackCheckersKeepalived 的配置Global configurationvrrp_scriptVRRP Configurationvrrp synchroization groupvrrp instancevirtual ip addressesvirtual routesLVS Configurationvirtual_s…...

前端报错adding CSS “touch-action: none“ to this element解决方案
目录 如图所示控制台出现报错: 原因: touch-action 介绍: 解决方案: 1.手动设置touch-action: 2.使用条件渲染: 3.CSS样式隔离: 4.浏览器兼容性: 5. 忽略警告 如图所示控制台…...

使用phpMyAdmin操作MYSQL(四)
一. 学会phpMyAdmin? phpMyAdminhttp://water.ve-techsz.cn/phpmyadmin/ 虽然我我们可以用命令行操作数据库,但这样难免没有那么直观,方便。所以接下来我们使用phpMyAdmin来操作MySQL,phpMyAdmin是众多MySQL图形化管理工具中使用…...

webpack配置代理请求
在 Webpack 中,可以通过配置devServer中的proxy选项来设置代理请求,以解决开发环境中的跨域问题或实现特定的请求转发逻辑。以下是一个常见的 Webpack 配置示例,展示了如何设置代理: module.exports {// 其他配置项...devServer…...

热门软件缺陷管理工具2024:专业评测与建议
国内外主流的10款软件缺陷管理工具软件对比:PingCode、Worktile、禅道、Tapd、Teambition、Tower、JIRA、Bugzilla、MantisBT、Trac。 在软件开发过程中,管理缺陷和漏洞常常成为一项挑战,尤其是在项目规模庞大时。选择一个高效的软件缺陷管理…...

冒泡,选择,插入,希尔排序
目录 一. 冒泡排序 1. 算法思想 2. 时间复杂度与空间复杂度 3. 代码实现 二. 选择排序 1. 算法思想 2. 时间复杂度与空间复杂度 3. 代码实现 三.插入排序 1. 直接插入排序 (1). 算法思想 (2). 时间复杂度与空间复杂度 (3). 代码实现 2. 希尔排序 (1). 算法思想 …...

【HarmonyOS学习】Calendar Kit日历管理
简介 Calendar Kit提供日历与日程管理能力,包括日历的获取和日程的创建能力。 Calendar Kit为用户提供了一系列接口来获取日历账户,并使用特定的接口向日历账户中写入日程。 如果写入的日程带有提醒时间则系统会在时间到达时向用户发送提醒。 约束点…...

RDMA 高性能架构基本原理与设计方案
RDMA的主要优点包括低延迟、高吞吐量、减少CPU负担和支持零拷贝网络。它允许数据直接在网络接口卡(NIC)和内存之间传输,减少了数据传输过程中的中间环节,从而显著降低了延迟。RDMA技术能够实现高速的数据传输,适用于需…...

【Springboot】事件机制发布与订阅的使用实践
文章目录 为什么要使用事件监听机制概念和原理使用场景用户注册系统实践案例1. 创建事件类2. 发布事件3. 监听事件3.1 通过注解EventListener实现监听3.2 通过实现ApplicationListener接口实现监听 4. 测试事件机制 总结 为什么要使用事件监听机制 在Springboot中,…...
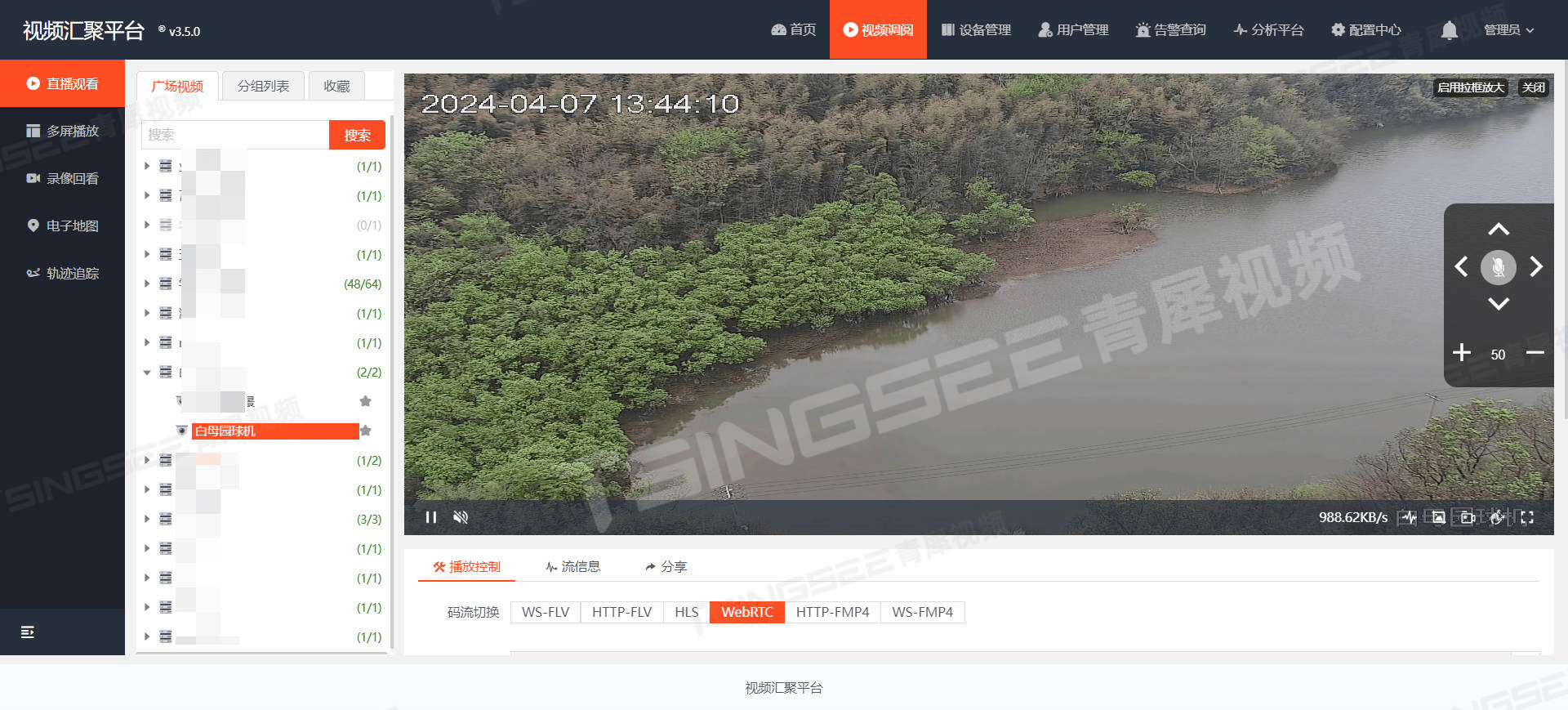
新版网页无插件H.265播放器EasyPlayer.js如何测试demo视频?
H5无插件流媒体播放器EasyPlayer属于一款高效、精炼、稳定且免费的流媒体播放器,可支持多种流媒体协议播放,支持H.264与H.265编码格式,性能稳定、播放流畅;支持WebSocket-FLV、HTTP-FLV,HLS(m3u8࿰…...

PXE、Kickstart和cobbler
一.系统装机 1.1 三种引导方式 启动操作系统 1.硬盘 2.光驱(u盘) 3.网络启动 pxe 1.2 系统安装过程 1.加载boot loader: Boot Loader 是在操作系统内核运行之前运行的一段小程序。通过这段小程序,我们可以初始化硬件设 备、建立内存空间的映射图,从而将系统的软硬…...

【GameFramework扩展应用】6-3、GameFramework框架增加日志保存功能
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址QQ群:398291828大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 【GameFramework框架】系列教程目录: https://blog.csdn.net/q764424567/article/details/1…...

将独热码应用到神经网络中
引言 接上回,本文继续说如何用TensorFlow将独热编码应用到一个简单的神经网络中,以实现从一段随机文本到另一段随机文本的转换。 步骤一:导入库 import tensorflow as tf import numpy as np import random import string步骤二࿱…...

Unity IL2CPP逆向实战:用frida-il2cpp-bridge穿透三重运行时屏障
1. 这不是“又一个 Frida 教程”,而是 Unity 逆向现场的生存手册 你刚在某款热门 Unity 游戏里发现一个可疑的加密逻辑,想确认它是否调用了 UnityEngine.PlayerPrefs.SetString 存储敏感 token;或者你在调试一款国产工具类 App,…...

ARM嵌入式开发板OpenSSH移植全攻略:从交叉编译到部署实战
1. 项目概述与核心价值给嵌入式开发板移植OpenSSH,这几乎是每一个从单片机转向Linux嵌入式开发的工程师都会遇到的“成人礼”。你可能已经习惯了用串口调试终端,一根线连着,虽然稳定,但也被束缚在工位前。当你的设备需要部署到某个…...

振弦采集模块精度检测实战:从原理到环境测试全解析
1. 项目概述与核心目标在工程监测领域,振弦式传感器因其长期稳定性好、抗干扰能力强、信号传输距离远等优点,被广泛应用于桥梁、大坝、隧道、边坡等结构物的应力、应变、位移和压力监测。而VM系列振弦采集模块,作为连接传感器与数据采集系统的…...

网页端嵌入 Agent 对接前端方案
本文将深入探讨「网页端嵌入AI」的核心概念与实战技巧,帮助你快速掌握关键要点。让我们开始吧! 网页端嵌入 Agent 对接前端方案 1. 引言 当前前端项目正从被动展示走向主动交互,AI Agent 嵌入网页端可自动化 UI 操作、优化布局并辅助编码。…...

Stable Diffusion 实战教程:从安装到图像生成
Stable Diffusion 实战教程:从安装到图像生成 前言 Stable Diffusion 是当前最流行的开源图像生成模型之一。它能够根据文字描述生成高质量的图像,在创意设计、游戏开发等领域有广泛应用。 我在多个项目中使用过 Stable Diffusion,从简单的图…...

洛圣都生存指南:YimMenu开源游戏增强工具与安全防护系统深度解析
洛圣都生存指南:YimMenu开源游戏增强工具与安全防护系统深度解析 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trendi…...

SchemaCrawler:终极数据库模式发现与理解工具完全指南
SchemaCrawler:终极数据库模式发现与理解工具完全指南 【免费下载链接】SchemaCrawler Free database schema discovery and comprehension tool 项目地址: https://gitcode.com/gh_mirrors/sc/SchemaCrawler 在当今数据驱动的时代,数据库模式发现…...

rebar3高级配置与性能优化:让你的构建速度提升300% [特殊字符]
rebar3高级配置与性能优化:让你的构建速度提升300% 🚀 【免费下载链接】rebar3 Erlang build tool that makes it easy to compile and test Erlang applications and releases. 项目地址: https://gitcode.com/gh_mirrors/re/rebar3 你是否曾经因…...
)
大型房地产集团战略规划数字化转型PMO项目进度管理解决方案(PPT)
导读 有一个问题值得认真想一想:一家布局全国、同时管理几十个楼盘的大型地产集团,它的"项目管理"问题,究竟出在哪里? 不是因为缺人,也不是因为团队不努力。事实上,大多数地产集团在规模扩张到一…...
)
别再手动复制文件了!Mathtype 7.4 一键配置脚本,搞定Office和WPS(附常见错误修复)
数学公式编辑神器Mathtype 7.4全自动部署方案:告别手动配置的繁琐时代 在科研论文、技术文档撰写过程中,数学公式的编辑效率直接影响工作进度。Mathtype作为专业数学公式编辑工具,其强大功能常被手动配置的复杂步骤所掩盖。传统方法需要用户反…...