LSTM从入门到精通(形象的图解,详细的代码和注释,完美的数学推导过程)

先附上这篇文章的一个思维导图
什么是RNN
按照八股文来说:RNN实际上就是一个带有记忆的时间序列的预测模型
RNN的细胞结构图如下:
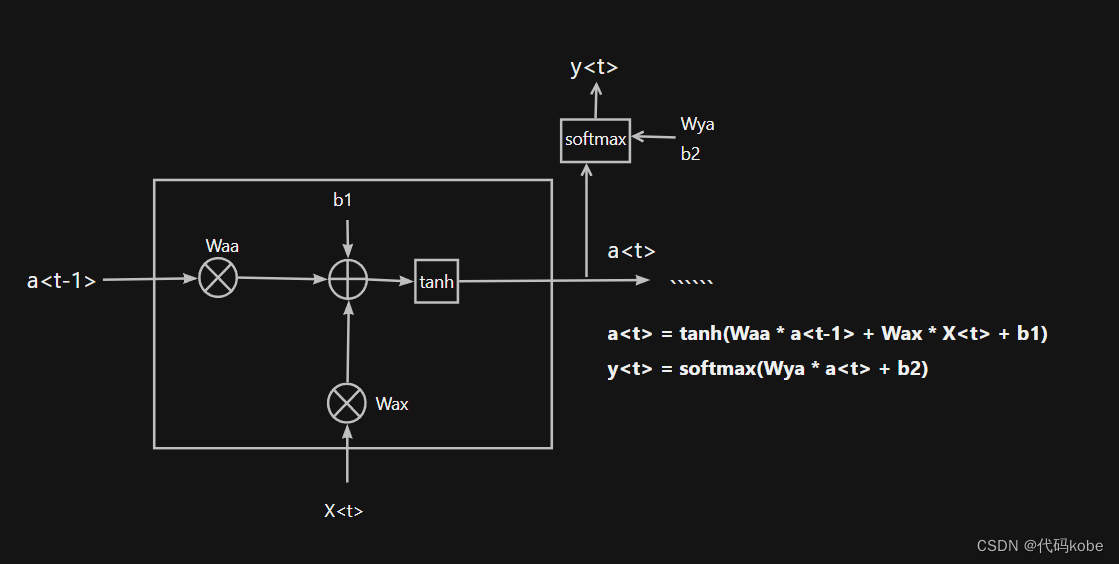
softmax激活函数只是我举的一个例子,实际上得到y<t>也可以通过其他的激活函数得到
其中a<t-1>代表t-1时刻隐藏状态,a<t>代表经过X<t>这一t时刻的输入之后,得到的新的隐藏状态。公式主要是a<t> = tanh(Waa * a<t-1> + Wax * X<t> + b1) ;大白话解释一下就是,X<t>是今天的吊针,a<t-1>是昨天的发烧度数39,经过今天这一针之后,a<t>变成38度。这里的记忆体现在今天的38度是在前一天的基础上,通过打吊针来达到第二天的降温状态。
1.1 RNN的应用
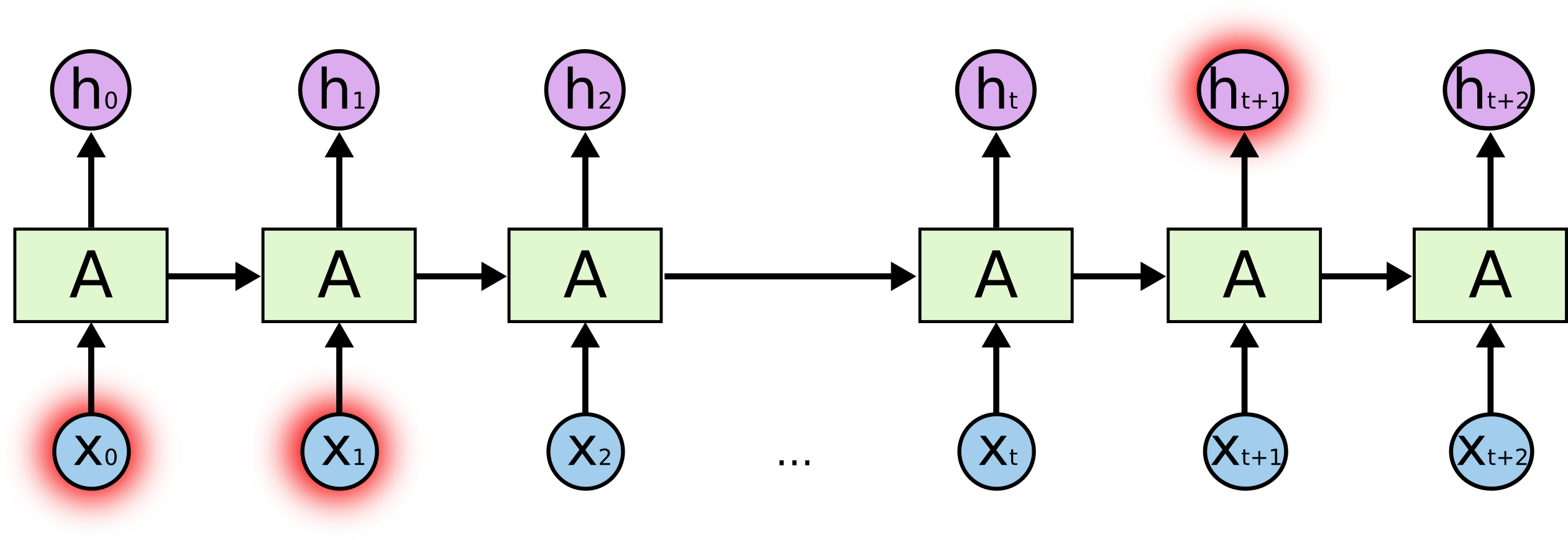
由于RNN的记忆性,我们最容易想到的就是RNN在自然语言处理方面的应用,譬如下面这张图,提前预测出下一个字。

除此之外,RNN的应用还包括下面的方向:
语言模型:RNN被广泛应用于语言模型的建模中,例如自然语言处理、机器翻译、语音识别等领域。
时间序列预测:RNN可以用于时间序列预测,例如股票价格预测、气象预测、心电图信号预测等。
生成模型:RNN可以用于生成模型,例如文本生成、音乐生成、艺术创作等。
强化学习:RNN可以用于强化学习中,例如在游戏、机器人控制和决策制定等领域。
1.2 RNN的缺陷
想必大家一定听说过LSTM,没错,就是由于RNN的尿性,所以才出现LSTM这一更精妙的时间序列预测模型的设计。但是我们知己知彼才能百战百胜,因此我还是决定详细分析一下RNN的缺陷,看过一些资料,但是只是肤浅的提到了梯度消失和梯度爆炸,没有实际的数学推导,这可不是一个求学之人应该有的态度!
主要的缺陷是两个:
长期依赖问题导致的梯度消失:众所周知RNN模型是一个具有记忆的模型,每一次的预测都和当前输入以及之前的状态有关,但是我们试想,如果我们的句子很长,他在第1000个记忆细胞还能记住并很好的利用第1个细胞的记忆状态吗?答案显然是否定的
梯度爆炸
1.2.1 梯度消失和梯度爆炸的详细公式推导
敲黑板(手写公式推导,大家最迷糊的地方):
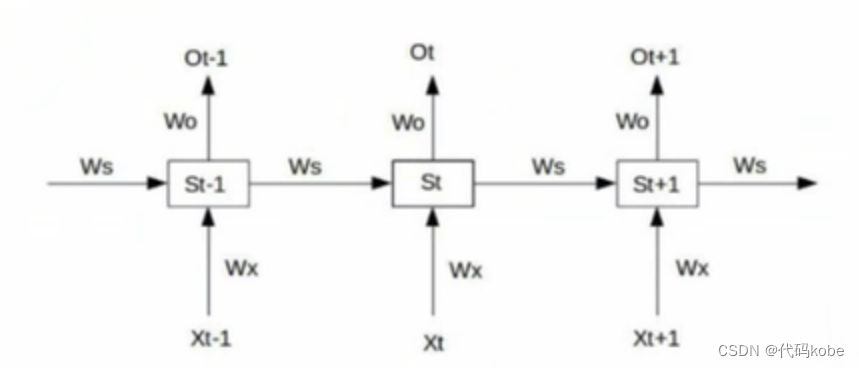
根据下面图示的例子,我手写并反复检查了自己的过程(下图),请各位看官务必认真看看,理解起来并不难,对于别的文章随口一提的梯度消失和梯度爆炸实在是透彻太多啦!!!
我们假设损失函数,Y是实际值,O是预测值;首先,我们假设只有三层,然后通过三层我们就能以此类推找出规律。反向传播我们需要对Wo,Wx,Ws,b四个变量都求偏导,在这里我们主要对Wx求偏导,其他三个以此类推,就很简单了。为了表示更清晰,笔者使用紫色的x表示乘法。


根据推导的公式我们得到一个指数函数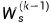 ,我们在高中时候就学到过指数函数的变化系数是极大的,因此在t趋于比较大的时候(也就是我们的句子比较长的时候),如果
,我们在高中时候就学到过指数函数的变化系数是极大的,因此在t趋于比较大的时候(也就是我们的句子比较长的时候),如果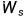 比1小不少,那么模型的一部分梯度会趋于0,因此优化会几乎停止;同理,如果比1大一些,那么模型的部分梯度会极大,导致模型和的变化无法控制,优化毫无意义。
比1小不少,那么模型的一部分梯度会趋于0,因此优化会几乎停止;同理,如果比1大一些,那么模型的部分梯度会极大,导致模型和的变化无法控制,优化毫无意义。
什么是LSTM
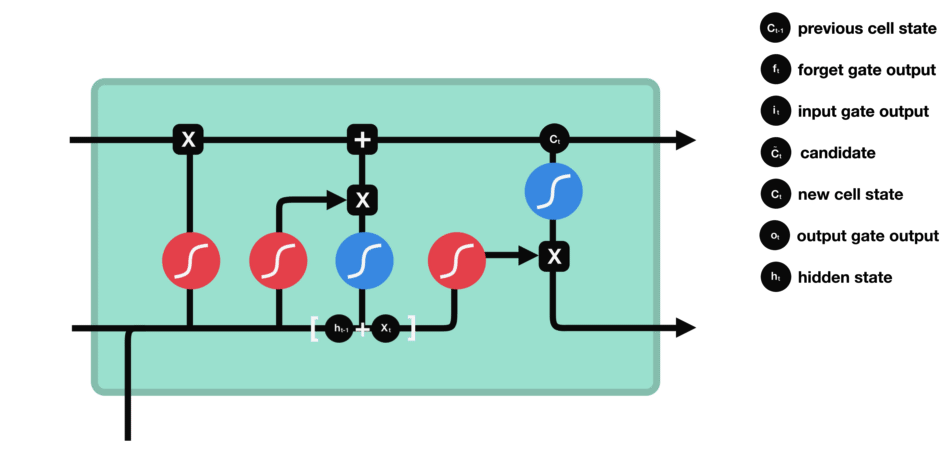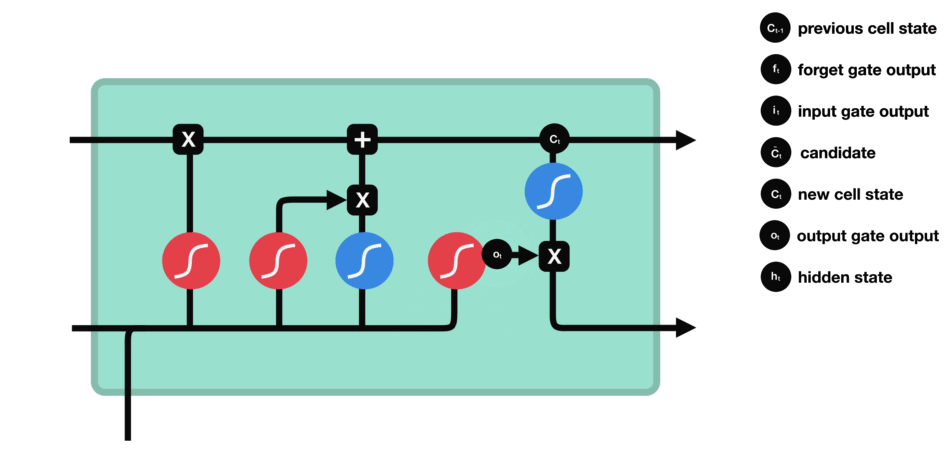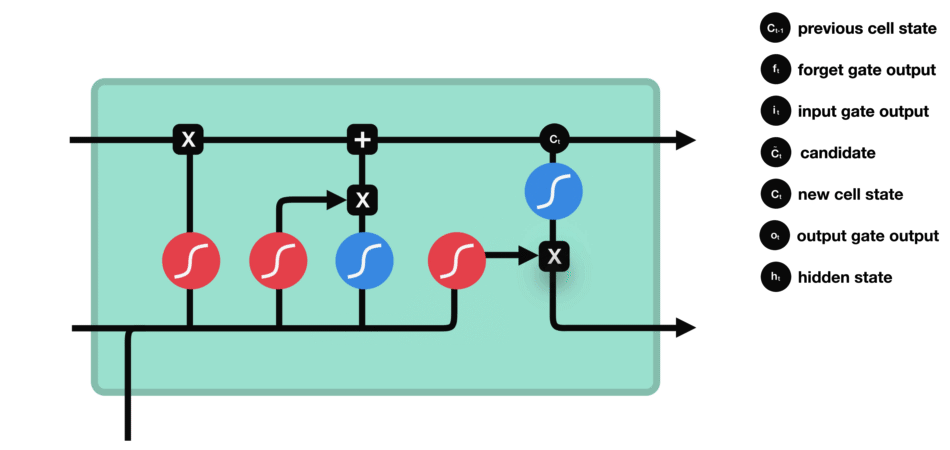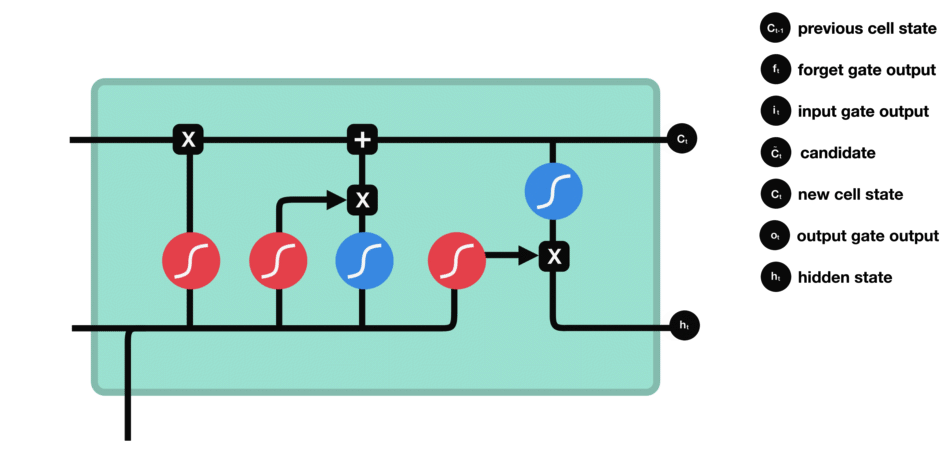
八股文解释:LSTM(长短时记忆网络)是一种常用于处理序列数据的深度学习模型,与传统的 RNN(循环神经网络)相比,LSTM引入了三个门(输入门、遗忘门、输出门,如下图所示)和一个细胞状态(cell state),这些机制使得LSTM能够更好地处理序列中的长期依赖关系。注意:小蝌蚪形状表示的是sigmoid激活函数
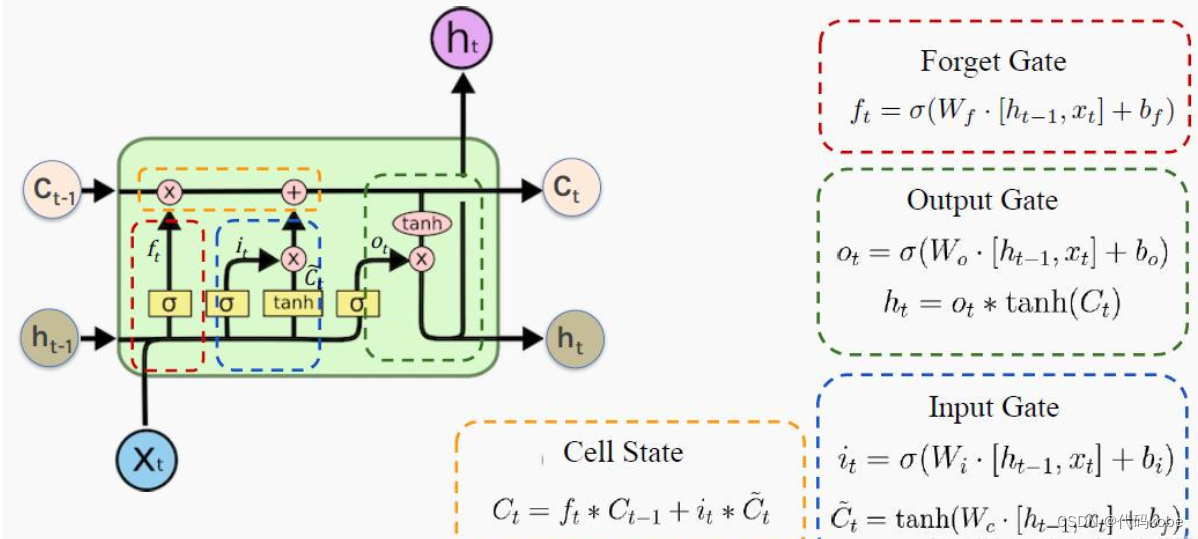
Ct是细胞状态(记忆状态),是输入的信息,
是隐藏状态(基于
得到的)
用最朴素的语言解释一下三个门,并且用两门考试来形象的解释一下LSTM:
遗忘门:通过x和ht的操作,并经过sigmoid函数,得到0,1的向量,0对应的就代表之前的记忆某一部分要忘记,1对应的就代表之前的记忆需要留下的部分 ===>
 代表复习上一门线性代数所包含的记忆,通过遗忘门,忘记掉和下一门高等数学无关的内容(比如矩阵的秩)
代表复习上一门线性代数所包含的记忆,通过遗忘门,忘记掉和下一门高等数学无关的内容(比如矩阵的秩)
输入门:通过将之前的需要留下的信息和现在需要记住的信息相加,也就是得到了新的记忆状态。===>
代表复习下一门科目高等数学的时候输入的一些记忆(比如洛必达法则等等),那么已经线性代数残余且和高数相关的部分(比如数学运算)+高数的知识=新的记忆状态
输出门:整合
,得到一个输出===>代表高数所需要的记忆,但是在实际的考试不一定全都发挥出来考到100分。因此,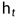 则代表实际的考试分数
则代表实际的考试分数
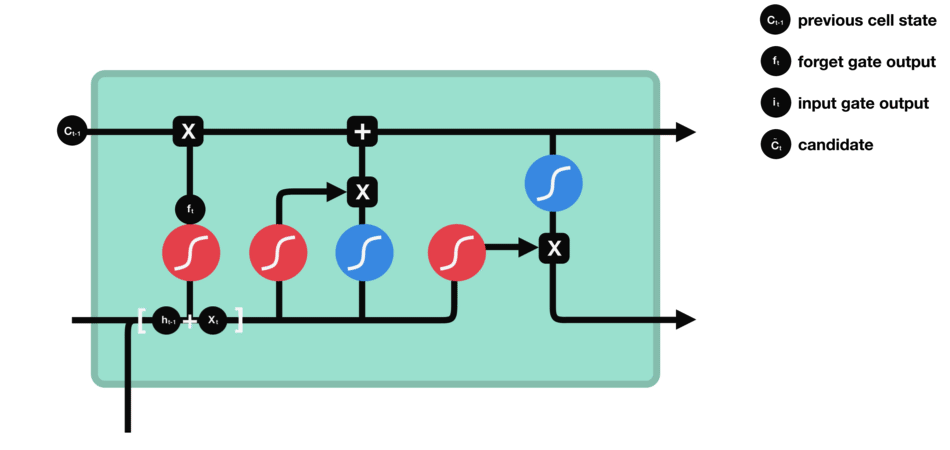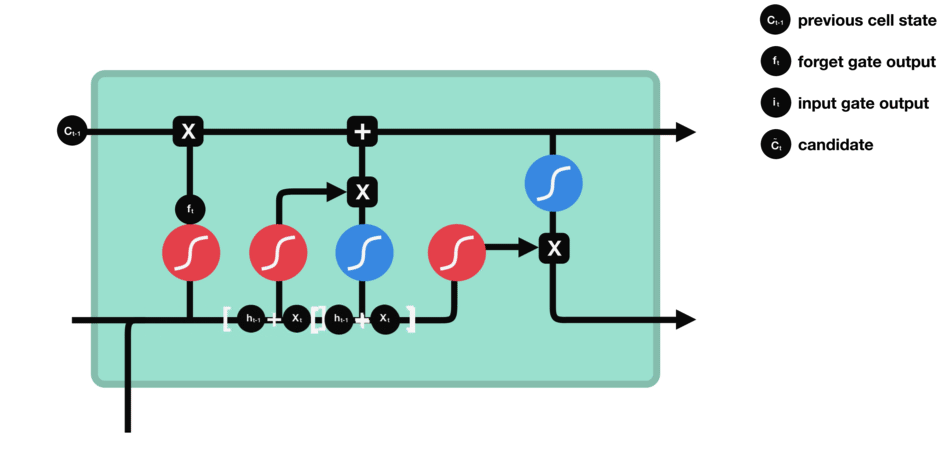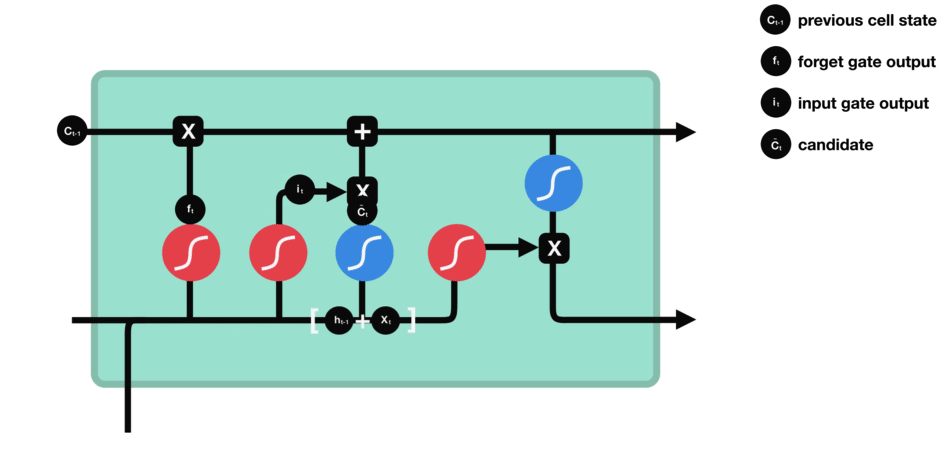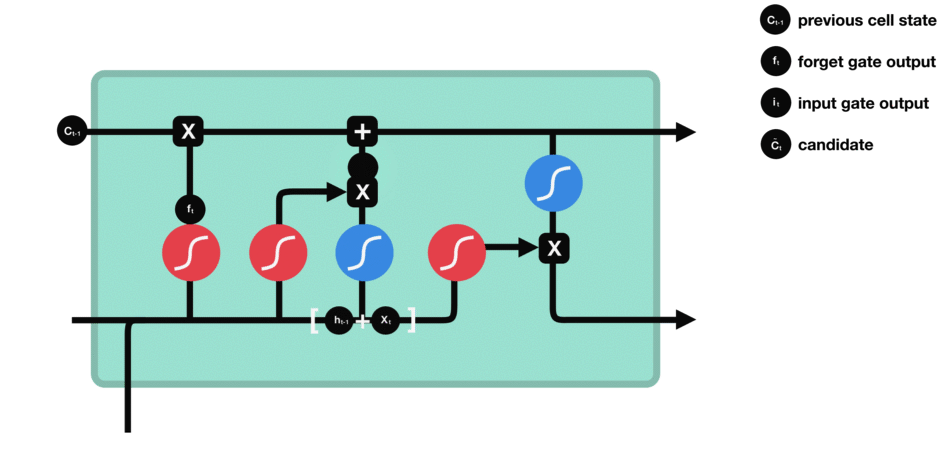
为了便于大家理解,附上几张非常好的图供大家理解完整的数据处理的流程:
遗忘门:
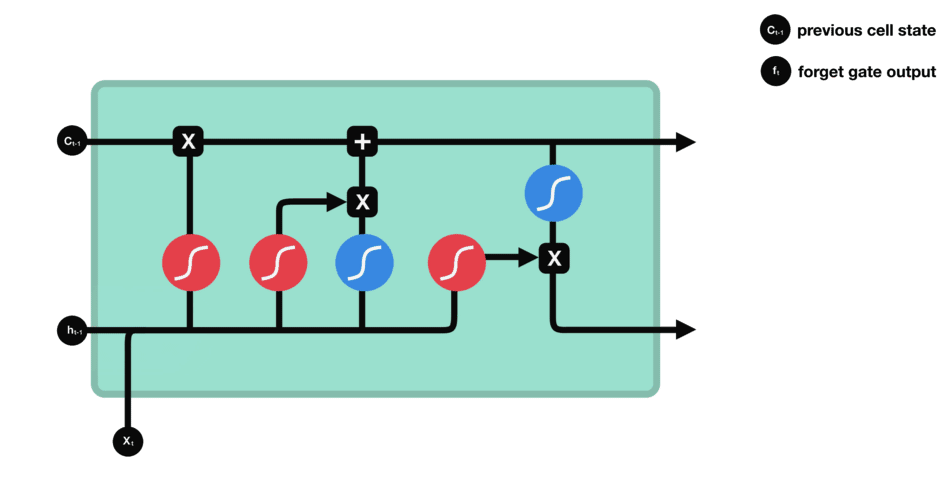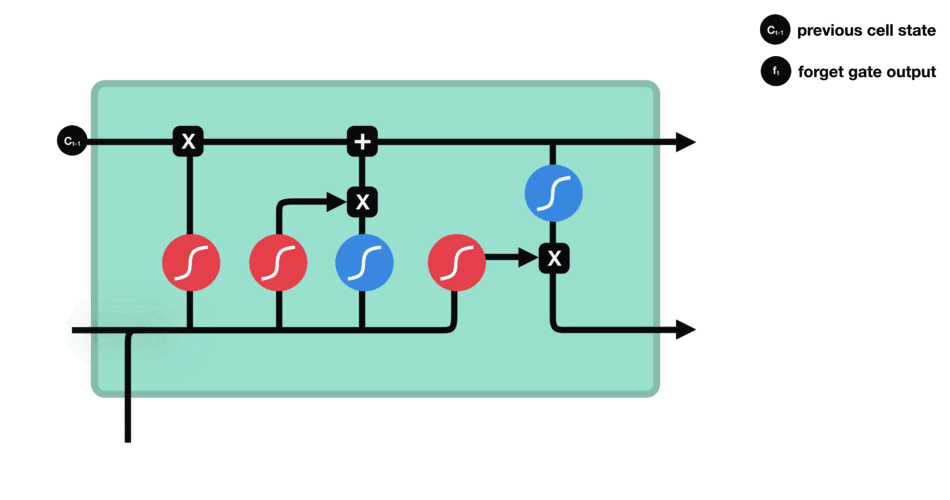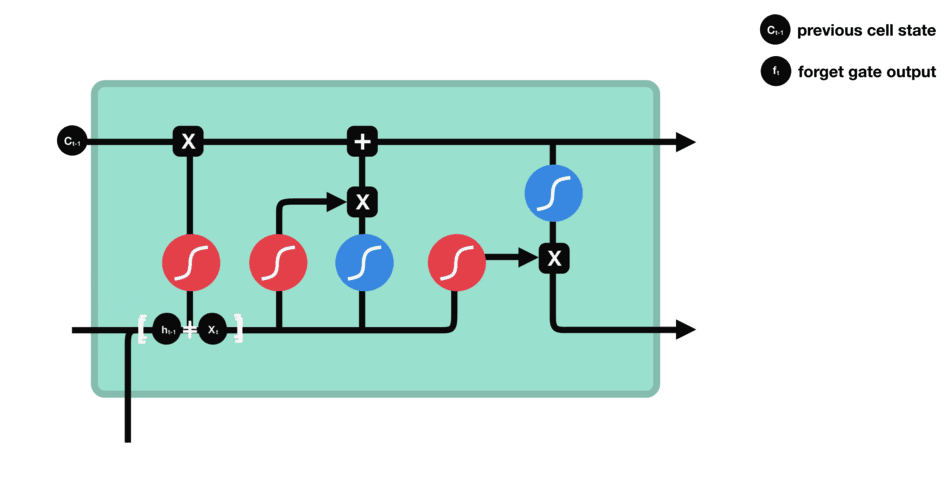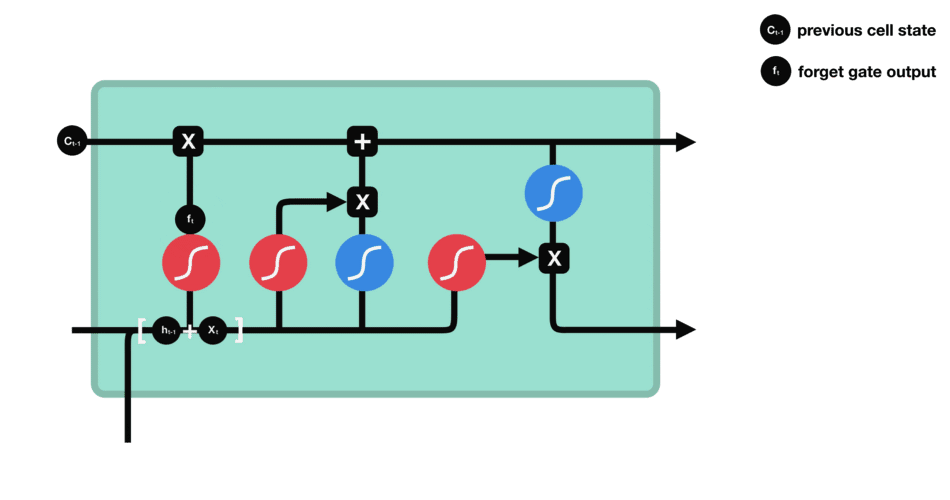
输入门:
细胞状态:

输出门:
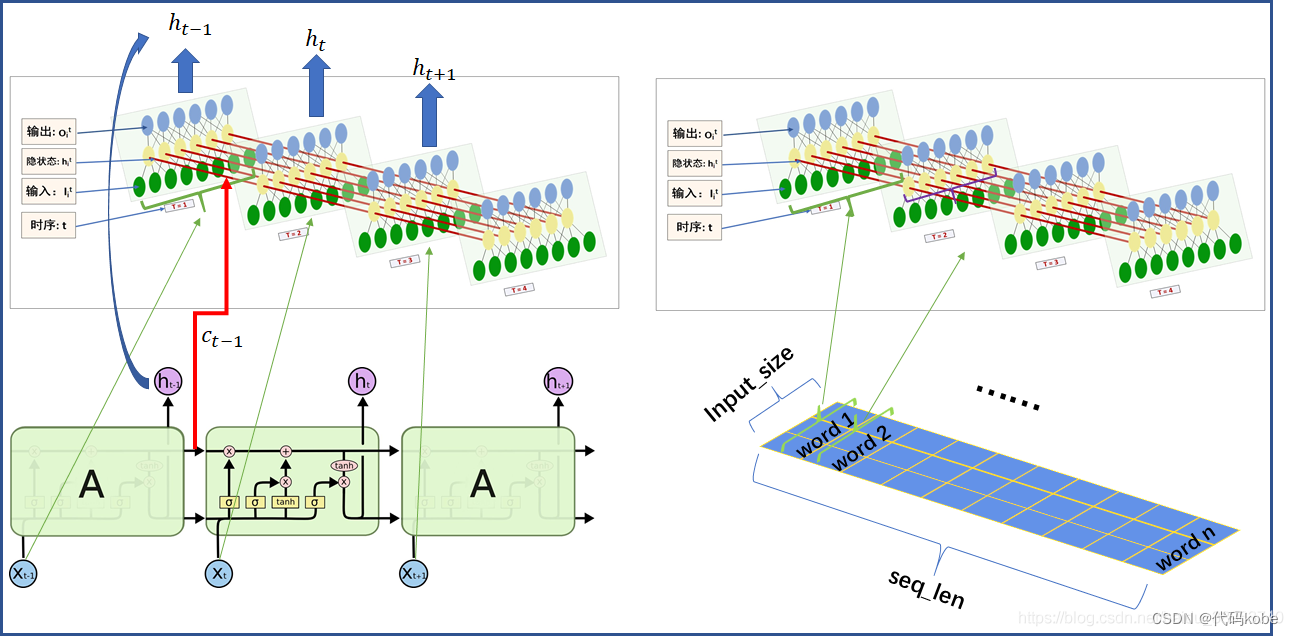
2.1 LSTM的模型结构
这里有两张别的博主的很好的图,我在初学的时候也是恍然大悟:
图的出处
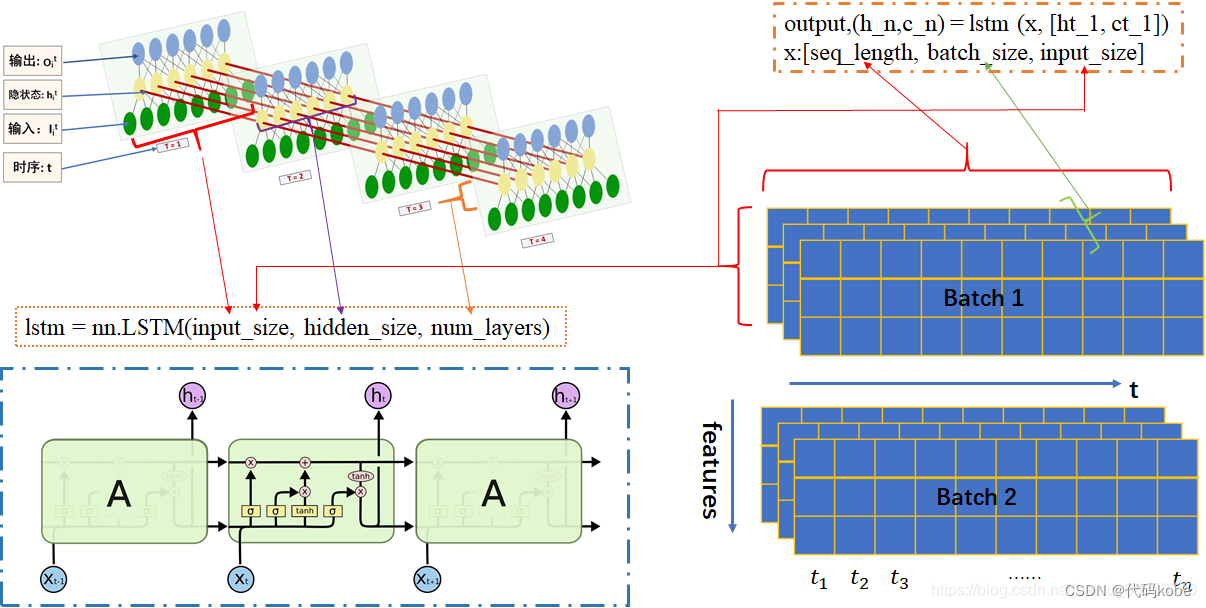
解释一下pytorch训练lstm所使用的参数:
这是利用pytorch调用LSTM所使用的参数
output,(h_n,c_n) = lstm (x, [ht_1, ct_1]),一般直接放入x就好,后面中括号的不用管
这是作为x(输入)喂给LSTM的参数
x:[seq_length, batch_size, input_size],这里有点反人类,batch_size一般都是放在开始的位置
这是pytorch简历LSTM是所需参数
lstm = LSTM(input_size,hidden_size,num_layers)
2.2 LSTM相比RNN的优势
LSTM的反向传播的数学推导很繁琐,因为涉及到的变量很多,但是LSTM确实是可以在一定程度上解决梯度消失和梯度爆炸的问题。我简单说一下,RNN的连乘主要是W的连乘,而W是一样的,因此就是一个指数函数(在梯度中出现指数函数并不是一件友好的事情);相反,LSTM的连乘是对的偏导的不断累乘,如果前后的记忆差别不大,那偏导的值就是1,那就是多个1相乘。当然,也可能出现某一一些偏导的值很大,但是一定不会很多(换句话说,一句话的前后没有逻辑,那完全没有训练的必要)。
2.3 pytorch实现LSTM对股票的预测(实战)
需要安装一下tushare的金融方面的数据集,代码的注解我已经写的很清楚了
#!/usr/bin/python3
# -*- encoding: utf-8 -*-import matplotlib.pyplot as plt
import numpy as np
import tushare as ts
import pandas as pd
import torch
from torch import nn
import datetime
import timeDAYS_FOR_TRAIN = 10class LSTM_Regression(nn.Module):"""使用LSTM进行回归参数:- input_size: feature size- hidden_size: number of hidden units- output_size: number of output- num_layers: layers of LSTM to stack"""def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):super().__init__()self.lstm = nn.LSTM(input_size, hidden_size, num_layers)self.fc = nn.Linear(hidden_size, output_size)def forward(self, _x):x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)s, b, h = x.shapex = x.view(s * b, h)x = self.fc(x)x = x.view(s, b, -1) # 把形状改回来return xdef create_dataset(data, days_for_train=5) -> (np.array, np.array):"""根据给定的序列data,生成数据集数据集分为输入和输出,每一个输入的长度为days_for_train,每一个输出的长度为1。也就是说用days_for_train天的数据,对应下一天的数据。若给定序列的长度为d,将输出长度为(d-days_for_train+1)个输入/输出对"""dataset_x, dataset_y = [], []for i in range(len(data) - days_for_train):_x = data[i:(i + days_for_train)]dataset_x.append(_x)dataset_y.append(data[i + days_for_train])return (np.array(dataset_x), np.array(dataset_y))if __name__ == '__main__':t0 = time.time()data_close = ts.get_k_data('000001', start='2019-01-01', index=True)['close'] # 取上证指数的收盘价data_close.to_csv('000001.csv', index=False) #将下载的数据转存为.csv格式保存data_close = pd.read_csv('000001.csv') # 读取文件df_sh = ts.get_k_data('sh', start='2019-01-01', end=datetime.datetime.now().strftime('%Y-%m-%d'))print(df_sh.shape)data_close = data_close.astype('float32').values # 转换数据类型plt.plot(data_close)plt.savefig('data.png', format='png', dpi=200)plt.close()# 将价格标准化到0~1max_value = np.max(data_close)min_value = np.min(data_close)data_close = (data_close - min_value) / (max_value - min_value)# dataset_x# 是形状为(样本数, 时间窗口大小)# 的二维数组,用于训练模型的输入# dataset_y# 是形状为(样本数, )# 的一维数组,用于训练模型的输出。dataset_x, dataset_y = create_dataset(data_close, DAYS_FOR_TRAIN) # 分别是(1007,10,1)(1007,1)# 划分训练集和测试集,70%作为训练集train_size = int(len(dataset_x) * 0.7)train_x = dataset_x[:train_size]train_y = dataset_y[:train_size]# 将数据改变形状,RNN 读入的数据维度是 (seq_size, batch_size, feature_size)train_x = train_x.reshape(-1, 1, DAYS_FOR_TRAIN)train_y = train_y.reshape(-1, 1, 1)# 转为pytorch的tensor对象train_x = torch.from_numpy(train_x)train_y = torch.from_numpy(train_y)model = LSTM_Regression(DAYS_FOR_TRAIN, 8, output_size=1, num_layers=2) # 导入模型并设置模型的参数输入输出层、隐藏层等model_total = sum([param.nelement() for param in model.parameters()]) # 计算模型参数print("Number of model_total parameter: %.8fM" % (model_total / 1e6))train_loss = []loss_function = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)for i in range(200):out = model(train_x)loss = loss_function(out, train_y)loss.backward()optimizer.step()optimizer.zero_grad()train_loss.append(loss.item())# 将训练过程的损失值写入文档保存,并在终端打印出来with open('log.txt', 'a+') as f:f.write('{} - {}\n'.format(i + 1, loss.item()))if (i + 1) % 1 == 0:print('Epoch: {}, Loss:{:.5f}'.format(i + 1, loss.item()))# 画loss曲线plt.figure()plt.plot(train_loss, 'b', label='loss')plt.title("Train_Loss_Curve")plt.ylabel('train_loss')plt.xlabel('epoch_num')plt.savefig('loss.png', format='png', dpi=200)plt.close()# torch.save(model.state_dict(), 'model_params.pkl') # 可以保存模型的参数供未来使用t1 = time.time()T = t1 - t0print('The training time took %.2f' % (T / 60) + ' mins.')tt0 = time.asctime(time.localtime(t0))tt1 = time.asctime(time.localtime(t1))print('The starting time was ', tt0)print('The finishing time was ', tt1)# for testmodel = model.eval() # 转换成评估模式# model.load_state_dict(torch.load('model_params.pkl')) # 读取参数# 注意这里用的是全集 模型的输出长度会比原数据少DAYS_FOR_TRAIN 填充使长度相等再作图dataset_x = dataset_x.reshape(-1, 1, DAYS_FOR_TRAIN) # (seq_size, batch_size, feature_size)dataset_x = torch.from_numpy(dataset_x)pred_test = model(dataset_x) # 全量训练集# 的模型输出 (seq_size, batch_size, output_size)pred_test = pred_test.view(-1).data.numpy()pred_test = np.concatenate((np.zeros(DAYS_FOR_TRAIN), pred_test)) # 填充0 使长度相同assert len(pred_test) == len(data_close)plt.plot(pred_test, 'r', label='prediction')plt.plot(data_close, 'b', label='real')plt.plot((train_size, train_size), (0, 1), 'g--') # 分割线 左边是训练数据 右边是测试数据的输出plt.legend(loc='best')plt.savefig('result.png', format='png', dpi=200)plt.close()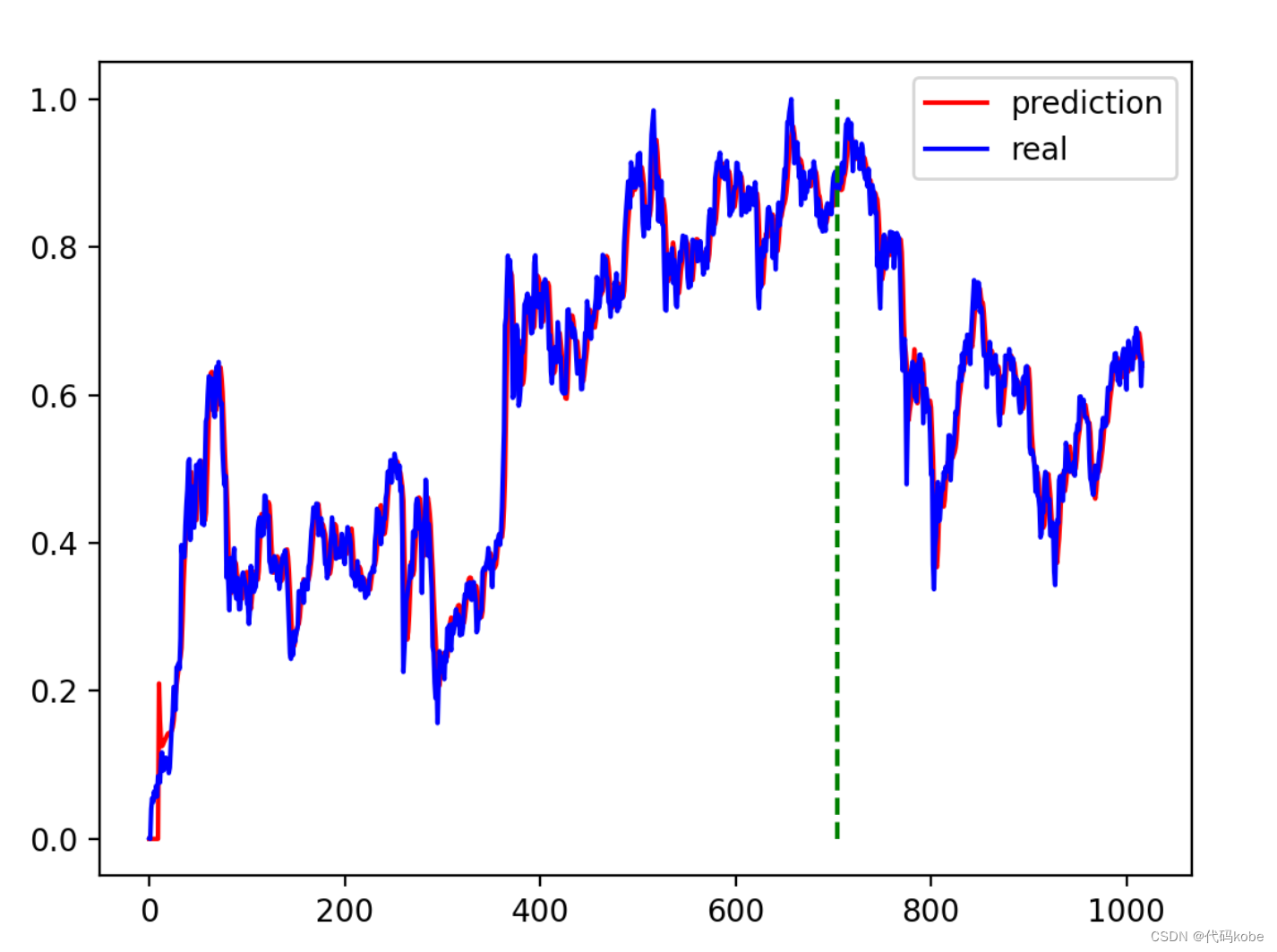
2.4 小问题:为什么采用tanh函数,不能都用sigmoid函数吗
先放上两个函数的图形:
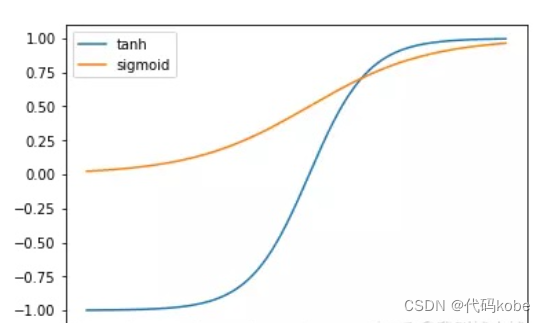
Sigmoid函数比Tanh函数收敛饱和速度慢
Sigmoid函数比Tanh函数值域范围更窄
tanh的均值是0,Sigmoid均值在0.5左右,均值在0的数据显然更便于数据处理
tanh的函数变化敏感区间更大
对两者求导,发现tanh对计算的压力更小,直接是1-原函数的平方,不需要指数操作
使用该问的图请标明出处,创作不易,希望收获你的赞赞
相关文章:
LSTM从入门到精通(形象的图解,详细的代码和注释,完美的数学推导过程)
先附上这篇文章的一个思维导图什么是RNN按照八股文来说:RNN实际上就是一个带有记忆的时间序列的预测模型RNN的细胞结构图如下:softmax激活函数只是我举的一个例子,实际上得到y<t>也可以通过其他的激活函数得到其中a<t-1>代表t-1时…...

19.特殊工具与技术
文章目录特殊工具与技术19.1控制内存分配19.1.1重载new和deleteoperator new接口和operator delete接口malloc函数与free函数19.1.2定位new表达式显式的析构函数调用19.2运行时类型识别(run-time type identification, RTTI)19.2.1dynamic_cast运算符指针类型的dynamic_cast引用…...

518. 零钱兑换 II ——【Leetcode每日一题】
518. 零钱兑换 II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 3…...

django DRF请求访问频率限制
Django REST framework(DRF)提供了一个throttle_classes属性,可以用于限制API的访问频率。它可以防止恶意用户发送大量请求以消耗服务器资源。使用throttle_classes属性,需要在settings.py中配置REST_FRAMEWORK:REST_F…...

二分查找创新性总结
LeetCode题目 704.二分查找35.搜索插入位置69.x 的平方根367.有效的完全平方数34.在排序数组中查找元素的第一个和最后一个位置 二分查找适用范围 可随机访问的数据结构数据已经有序要查找的值只有一个 上述的前四题都可直接使用二分查找,第五题要求查找上限和下限&…...

Java Web 实战 13 - 多线程进阶之 synchronized 原理以及 JUC 问题
文章目录一 . synchronized 原理1.1 synchronized 使用的锁策略1.2 synchronized 是怎样自适应的? (锁膨胀 / 升级 的过程)1.3 synchronized 其他的优化操作锁消除锁粗化1.4 常见面试题二 . JUC (java.util.concurrent)2.1 Callable 接口2.2 ReentrantLock2.3 原子类2.4 线程池…...
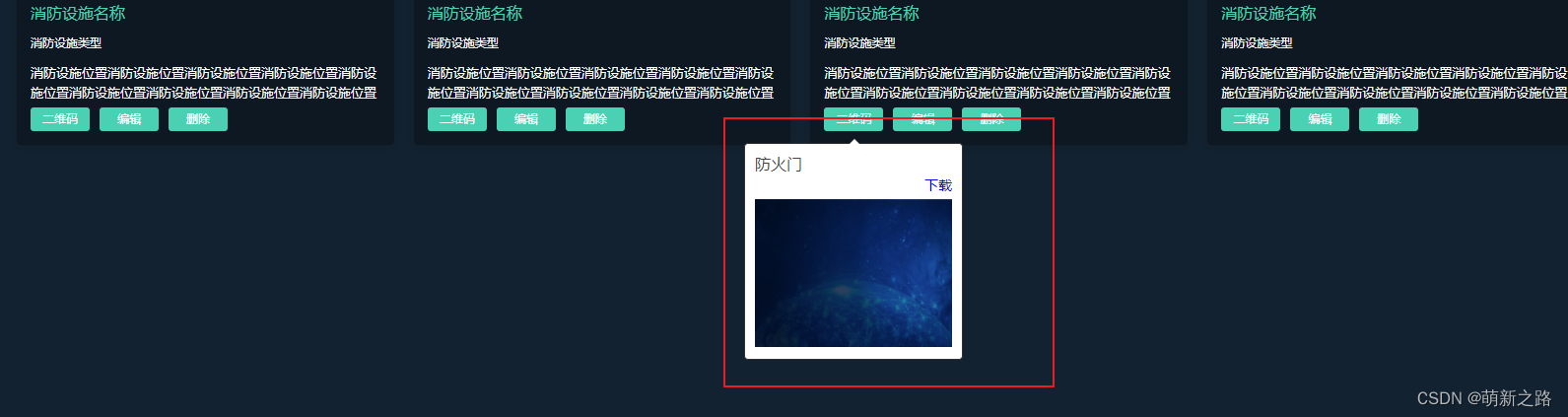
【解决】elementui ——tooltip提示在循环中点击一个,同时显示多个的问题!
同时显示多个tooltip——效果图: 点击第一个二维码把循环el-card中所有的tooltip都触发了 解决后效果图: 只显示点击的当前tooltip 解决办法: 通过循环item中定义字段,进行控制tooltip显示隐藏 代码: 页面代码&am…...
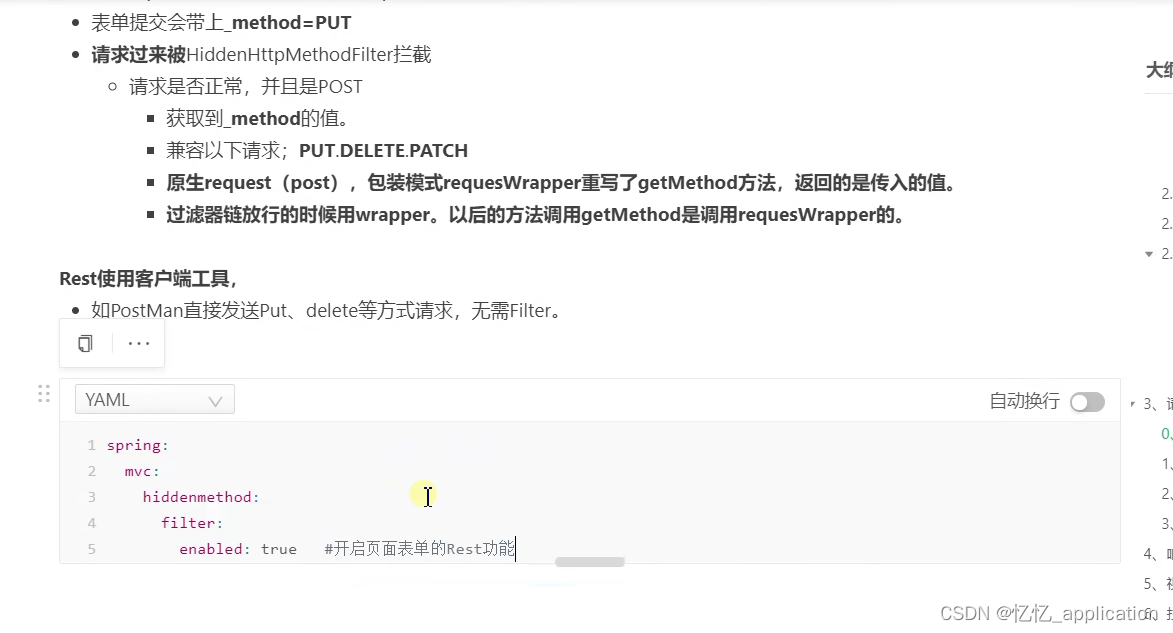
SpringBoot-核心技术篇
技术掌握导图 六个大标题↓ 配置文件web开发数据访问单元测试指标指控原理解析 配置文件 1.文件类型 1.1、properties 同以前的properties用法 1.2、yaml 1.2.1、简介 YAML是 “YAML Aint Markup Language”(YAML不是一种标记语言)的递归缩写。在…...

2023还有人不知道kubernetes?| 初步理解kubernetes
文章目录Kubernetes(K8s)一、Openstack&VM1、**认识虚拟化****1.1**、什么是虚拟化**1.2、虚拟化分类**2、OpenStack与KVM、VMWare2.1、OpenStack2.2、KVM2.3、VMWare二、容器&编排技术1、容器发展史1.1、Chroot1.2、FreeBSD Jails1.3、Solaris Zones1.4、LXC1.5、Dock…...

Docker 环境搭建
RabbitMq 安装与启动安装:运行命令:docker pull rabbitmq 默认版本是:latest启动rabbitmq:运行命令:docker run \ # 运行-e RABBITMQ_DETAULT_USERroot \ # 设置用户名-e RABBITMQ_DETAULT_PASS123456 \ # 设置 密码--…...

css实现炫酷充电动画
先绘制一个电池,电池头部和电池的身体 这里其实就是两个div,使用z-index改变层级,电池的身体盖住头部,圆角使用border-radius完成 html部分,完整的css部分在最后 <div class"chargerBox"><div class"ch…...

【Effective C++详细总结】第二章 构造/析构/赋值运算
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:C/C知识点 📣专栏定位:整理一下 C 相关的知识点,供大家学习参考~ ❤️如果有收获的话,欢迎点赞👍…...

webpack基础
webpack基础 webpack基础目录webpack基础前言Webpack 是什么?Webpack 有什么用?一、webpack的基本使用webpack如何使用文件和文件夹创建创建文件下载依赖二、基本配置5 大核心概念准备 Webpack 配置文件修改配置文件处理样式资源处理图片资源修改输出资源…...

jQuery《一篇搞定》
今日内容 一、JQuery 零、 复习昨日 1 写出至少15个标签 2 写出至少7个css属性font-size,color,font-familytext-algin,background-color,background-image,background-sizewidth,heighttop,bottom ,left ,rightpositionfloatbordermarginpadding 3 写出input标签的type的不…...
Spring Cloud学习笔记【负载均衡-Ribbon】
文章目录什么是Spring Cloud RibbonLB(负载均衡)是什么Ribbon本地负载均衡客户端 VS Nginx服务端负载均衡区别?Ribbon架构工作流程Ribbon Demo搭建IRule规则Ribbon负载均衡轮询算法的原理配置自定义IRule新建MyRuleConfig配置类启动类添加Rib…...
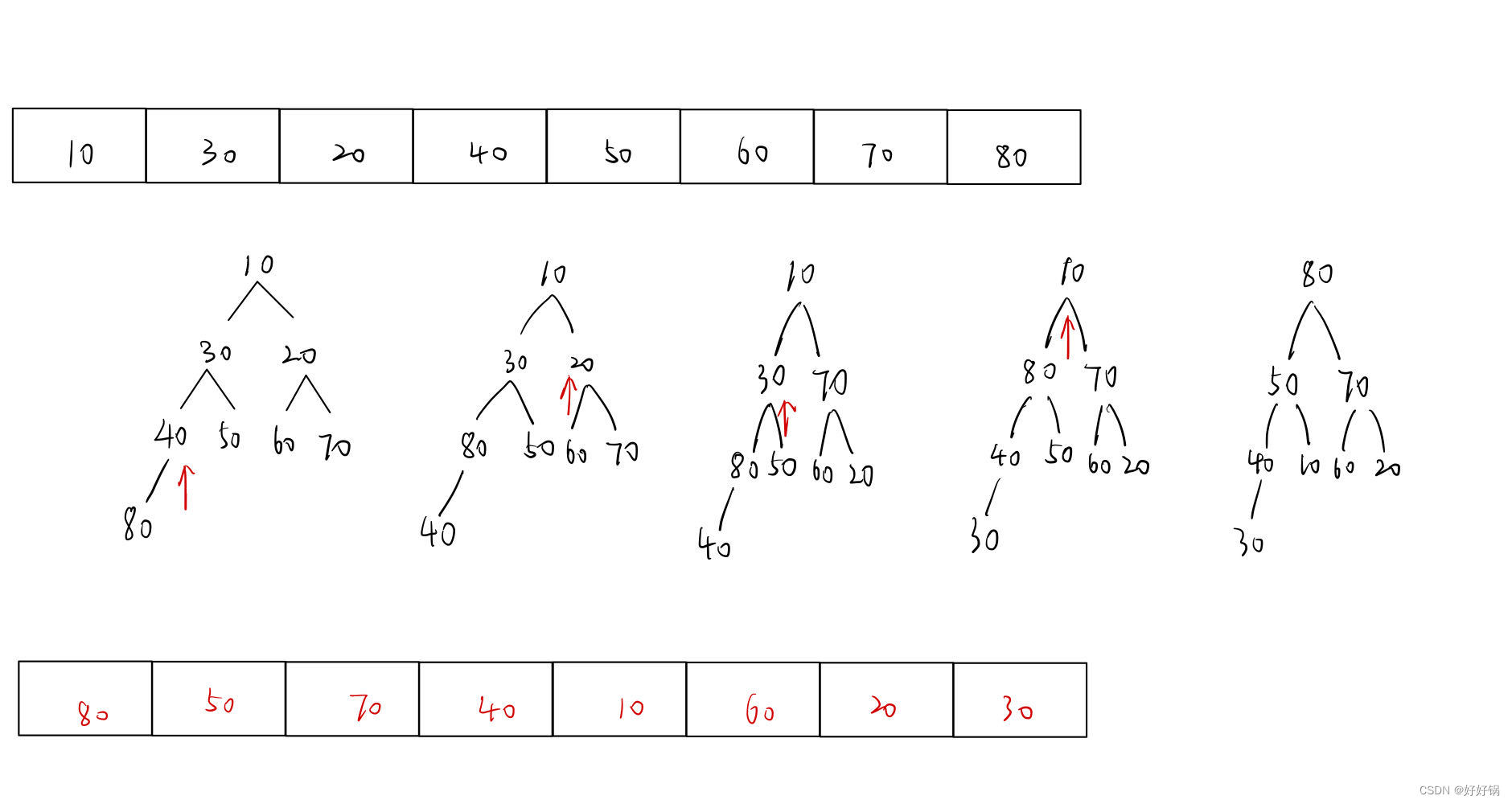
第九章:C语言数据结构与算法初阶之堆
系列文章目录 文章目录系列文章目录前言一、堆的定义二、堆的实现三、堆的接口函数1、初始化2、销毁3、插入4、删除5、判空6、元素个数四、堆排序1、建堆2、排序五、堆的应用——TOPK1、什么是TOPK问题?2、解决方法总结前言 堆就是完全二叉树。 一、堆的定义 我们…...
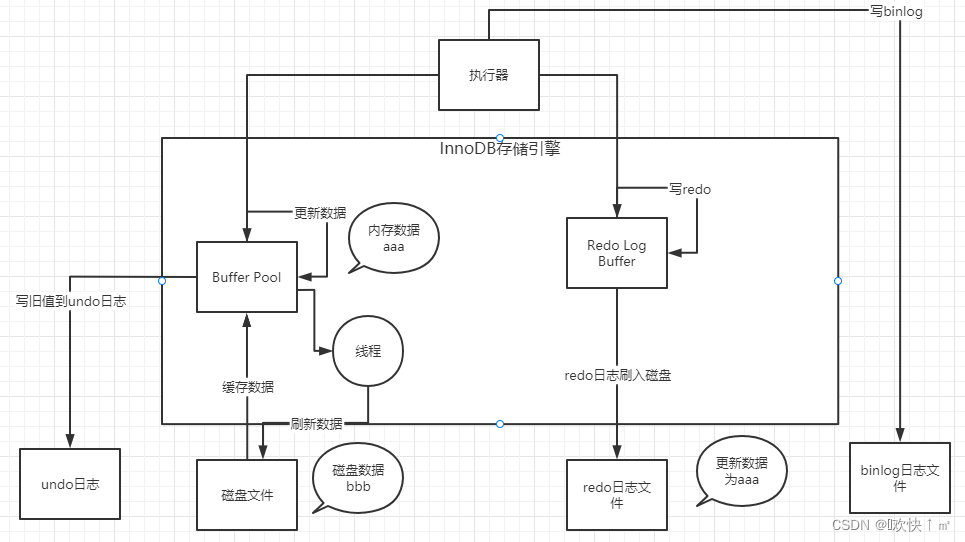
Mysql架构初识
🥲 🥸 🤌 🫀 🫁 🥷 🐻❄️🦤 🪶 🦭 🪲 🪳 🪰 🪱 🪴 🫐 🫒 🫑…...

字符串函数和内存函数
🍕博客主页:️自信不孤单 🍬文章专栏:C语言 🍚代码仓库:破浪晓梦 🍭欢迎关注:欢迎大家点赞收藏关注 字符串函数和内存函数 文章目录字符串函数和内存函数前言1. 字符串函数介绍1.1 s…...

Web3中文|GPT-4超越GPT-3.5的五大看点
A Beautiful CinderellaDwelling EagerlyFinally Gains HappinessInspiring Jealous KinLove Magically Nurtures Opulent PrinceQuietly RescuesSlipper TriumphsUniting Very WondrouslyXenial Youth Zealously这是一段描述童话故事《灰姑娘》的内容,它出自GPT-4之…...
动态矢量瓦片缓存库方案
目录 前言 二、实现步骤 1.将数据写入postgis数据库 2.将矢量瓦片数据写入缓存库 3.瓦片接口实现 4.瓦片局部更新接口实现 总结 前言 矢量瓦片作为webgis目前最优秀的数据格式,其主要特点就是解决了大批量数据在前端渲染时出现加载缓慢、卡顿的问题࿰…...

AI助手状态可视化:像素风办公室看板的设计、部署与集成指南
1. 项目概述:一个像素风的AI办公室看板如果你和我一样,日常工作中重度依赖AI助手,比如OpenClaw,那你可能也遇到过这样的困惑:当AI在后台默默执行一个长任务时,你完全不知道它进行到哪一步了。是卡住了&…...

开源金属四足机器人MEVIUS2设计与实现解析
1. MEVIUS2:开源金属四足机器人设计解析四足机器人技术近年来取得了显著进展,从实验室走向了实际应用场景。作为一名长期从事机器人系统开发的工程师,我特别关注如何降低这类先进机器人的研发门槛。MEVIUS2项目正是这一领域的突破性尝试——它…...

基于Raspberry Pi Pico的DIY宏键盘:从矩阵扫描到KMK固件实战
1. 项目概述:ClawDeck,一个为游戏玩家打造的桌面控制中心最近在逛一些开发者社区和硬件DIY论坛时,发现一个叫“ClawDeck”的项目挺有意思。项目作者是“gaminghousenursingaide761”,这个名字看起来像是一个个人开发者的ID。ClawD…...

企业团队如何利用Taotoken统一管理API密钥与下载用量报告
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业团队如何利用Taotoken统一管理API密钥与下载用量报告 在团队协作开发与使用大模型API的过程中,如何安全、高效地管…...

视频去水印工具推荐:免费视频去水印怎么弄?2026实测手机电脑好用方法全汇总
视频去水印工具推荐:免费视频去水印怎么弄?2026实测手机电脑好用方法全汇总 视频水印这件事,很多人都遇到过。从平台保存的视频自带LOGO角标,转发来的内容带着别人账号的水印,或者AI生成的视频角落挂着一串平台标识——…...

Switch游戏文件管理的终极解决方案:5步掌握NSC_BUILDER批量处理技巧
Switch游戏文件管理的终极解决方案:5步掌握NSC_BUILDER批量处理技巧 【免费下载链接】NSC_BUILDER Nintendo Switch Cleaner and Builder. A batchfile, python and html script based in hacbuild and Nuts python libraries. Designed initially to erase titleri…...

使用 TaoToken CLI 工具一键为团队配置统一的开发环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具一键为团队配置统一的开发环境 为团队统一接入大模型服务时,常会遇到配置分散、环境不一致的问…...

如何永久保存生活记忆?WeChatMsg让你的珍贵时刻永不褪色
如何永久保存生活记忆?WeChatMsg让你的珍贵时刻永不褪色 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeC…...

LinkSwift:免费网盘直链下载的终极解决方案
LinkSwift:免费网盘直链下载的终极解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅雷…...

利用Taotoken透明计费与账单追溯功能优化项目成本管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken透明计费与账单追溯功能优化项目成本管理 对于项目管理者或独立开发者而言,大模型API的调用成本常常是一个…...