火山引擎数据飞轮实践:在电商场景中,如何建设全链路数据血缘?
数据作为新型生产要素,正支撑企业的数智化转型。但企业数字化建设也存在管理成本高、数据产品使用门槛高、数据资产价值不够的问题,其原因在于业务和数据之间没有形成双向良性驱动。
结合新时代企业数字化转型需求,火山引擎基于字节跳动十余年数据驱动的实践经验,对外发布企业数智化升级新范式“数据飞轮”,帮助企业实现数据驱动。
具体来说,数据消费是数据飞轮的核心,通过一个又一个具体业务中的数据消费,在上层“业务应用轮”实现决策科学、行动敏捷,带来业务价值提升;在下层“数据资产轮”,也通过频繁的数据消费和业务收益,有的放矢建设高质量、低成本的数据资产,更好支撑业务应用。
构建扎实的数据资产轮能更好支撑企业上层数据应用。那么,在企业实践中,究竟应该如何做呢?
作为数据资产轮的支撑产品之一,火山引擎DataLeap在资产建设治理层面,能提升数据质量,实现效率提升和成本优化。本文将从电商角度出发,聚焦在数据血缘建设层面,具体介绍如何建设血缘底座、电商场景的血缘应用实践。
数据全链路血缘介绍
在电商场景中,我们建设数据全链路血缘的核心目的,是对数据从源头到终端全过程进行追踪和管理。
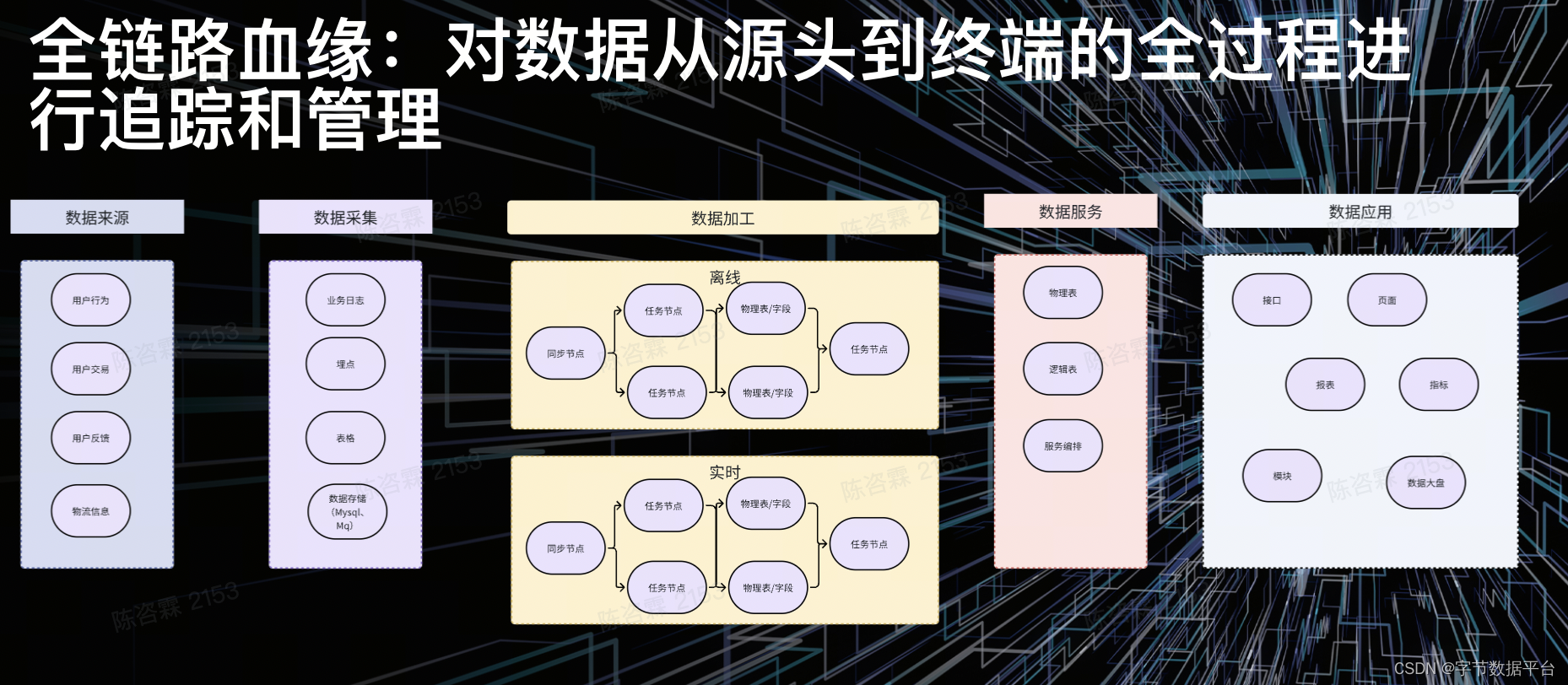
以零售行业举例,数据包括商品数据、物流信息、用户反馈等,其全流程包括:
-
通过数据采集,如业务日志、埋点、表格、存储;
-
经过ETL数据加工,包括离线和实时两种任务;
-
再到数据服务中的物理表、逻辑表,以及服务编排;
-
最后透传到数据应用,比如接口、页面、报表、指标等。
在业务发展过程中,我们常常会遇到如下问题:
首先,随着业务的快速发展,数据不断膨胀。数据量到大,但数据产生的实际价值在哪里?数据血缘则可以帮助我们更好评估数据价值,并在满足业务需求的同时,控制存储计算资源的膨胀速度。与此同时,数据血缘还能够衡量数仓建设的优劣,并且做好数仓体系化建设。
第二,如何做好数仓变更监控?在数仓的日常开发过程中,我们经常会遇到上下游变更,变更后希望能及时、准确地衡量数据变更的影响。由于数据来源变更丰富,需要通过数据血缘将数据变更及时通知下游关联方。
第三,数仓研发提效。我们希望通过数据血缘及时完成表重构,理清字段的来源以及加工口径,并且进行任务精准回溯。
最后,通过数据血缘助力指标体系化建设,保证指标一致性,避免重复开发。在指标体系化建设中,数据血缘可以帮助将新增的指标绑定到已有的指标上。
解决数据不断膨胀的问题
针对数据膨胀的问题,数据血缘可以明确数据流转路径,优化资源配置。血缘关系可以精确衡量数仓对业务的价值,实现数据治理,控制资源膨胀,并且能够精准地完成影响面评估。
帮助数仓开发提效
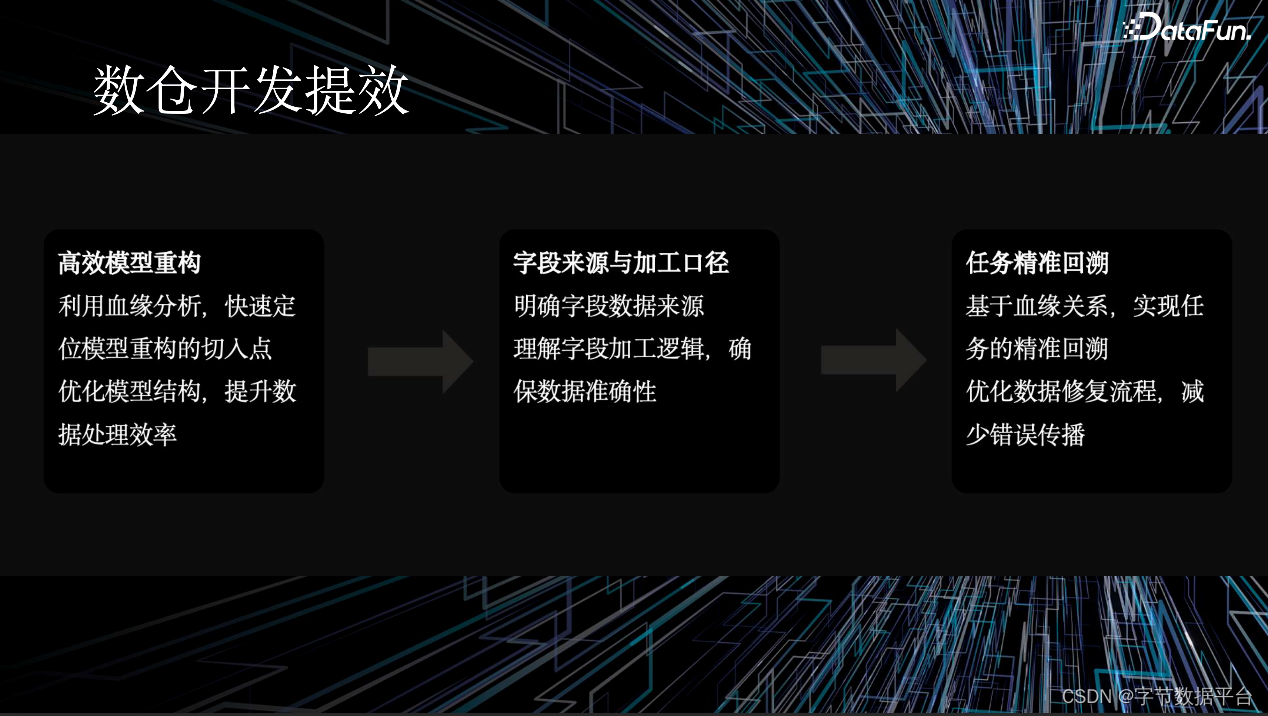
随着业务发展,我们经常面临模型重构的问题,比如一些旧表要切换到新表。数据血缘分析可以帮助我们快速定位模型重构的切入点,提升数据处理的效率。基于算子级的血缘关系,数据血缘可以实现任务的精准回溯优化,减少数据修复流程时间,减少错误传播。
保障数据一致性

在数据一致性方面,通过全链路血缘等手段,我们实现了指标从定义到生产消费的完整自动化流程,提升了指标的管理效率,减少了人为失误。通过血缘分析加解析能力,我们能识别出重复加工的字段,优化数据流程,从而减少不必要的资源消耗。
如何构建数据血缘底座
血缘底座是全链路数据血缘的基石。接下来,我将从整体架构、质量评估体系和应用层血缘三个方面来介绍血缘底座的建设。
整体架构
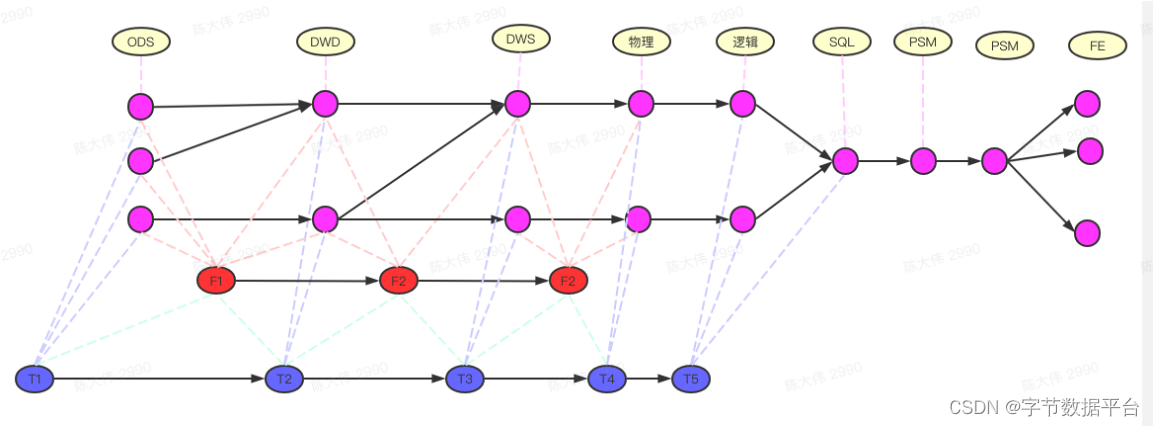
整体架构-关系图谱
如上图所示,关系图谱中有一些关键特点,如点、边、节点存储和边存储等。
-
点(Node):代表各种类型的节点,如指标、任务等
-
边(Edge):表示节点之间的血缘关系,如数据流向、任务依赖等
-
节点存储:每个节点类型对应一个或多个图中的点
-
边存储:节点间的血缘关系通过边来表示,边包含方向和类型信息
一般数仓加工链路会进行分层,如ODS贴源层、DWD明细层、DWS汇总层等,最终透传到数据产品的前端页面。
如果用传统的离线数仓来实现以上架构,且有明确关系的表模型,是非常困难的。最终,我们选择了字节自研图数据库来实现血缘数据的底层存储。
血缘质量度量体系
血缘质量是整个全链路血缘从应用到实践的最核心评测标准。
举个例子,如果某个业务要基于字段级的血缘回溯下游,但是由于血缘质量不达标,预期要回溯10个任务,最终查出来11个或者9个,出现一定误差。
在电商场景中,我们搭建了一套完整的血缘质量度量体系,从血缘解析的准确率、成功率、覆盖率、查询能力等维度来度量血缘的数据质量,评估血缘质量的健康程度,并且定期自动化检验血缘数据与实际数据流向的一致性。我们通过定期巡检机制发现bad case,并随之更新、迭代对应的血缘模块。
应用层血缘
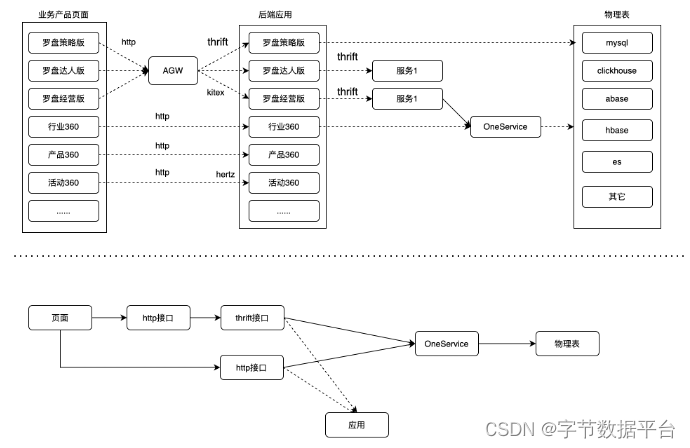
应用层调度链路

应用层数据采集方案
应用层血缘,与常规理解的数仓链路血缘不同。
对于数据链路血缘来说,我们针对异构数据源的SQL进行解析,在数据平台上维护了很多丰富的元数据,可以更好解析数仓之间的链路关系。但是对于应用层则不同,在电商场景中,我们维护了很多数据应用,如果逐一推进应用接入全链路血缘能力,成本很高。数据流转是从产品页面经过HTTP或者thrift接口请求后端服务,经过数据服务层打到数仓底表。
右图将该过程划分层级,通过低代码平台搭建前端页面、业务产品页面、数据产品页面,再通过接口的形式请求后端服务,最终映射到在one service上,形成对应的API,其底层就是刚才提到的数仓链路的血缘。

为了解决业务应用接入成本高的问题,我们实现了网关层自动参数上报,通过日志平台以及网关平台、服务平台间的合作,在前端请求接口时会自动上报URL refer参数,再通过日志采集系统把所有前端请求的日志采集下来,经过清洗,最终实现应用程序血缘的数据采集。
但在整个过程中,我们会遇到爬虫乱传参数、不传参数等问题,对血缘质量造成污染。为了解决该问题,我们通过脚本对域内的爬虫进行补全。通过自定义爬虫脚本,对全域的前端接口进行抓包,替换外部污染的数据。
电商场景的血缘应用实践
接下来重点介绍一下血缘应用在电商场景的实践,包含新旧表切换、字段口径探查、指标自动化拆解三个部分。
新旧表切换
开发人员使用IDE修改一个方法时,会改方法名、方法的入参以及方法的出参,IDE则提供代码级的替换能力。
而对于数仓研发人员来说,没有类似的能力可以做切换的操作。一般在重构中,数仓研发人员拿到要切换的表,通过人工查询,获取切换旧表影响的任务,进而手动拉群,做切换表的通知,下游的接收人收到消息后,更改任务代码,并进行数据比对,如果发现有问题需要再与上游进行沟通,如果没有问题则上线代码。

基于一站式新旧表切换功能,上述人工操作可以由平台自动完成,大幅降低了切换的工作量,提高了工作效率和质量。
通过平台能力,数仓研发人员只需要在系统中录入旧表信息,以及新旧表的映射关系,就可以自动生成切换后的代码。在生成代码、跑数之后,平台还支持与旧表的历史数据进行比对。对比结果无误的情况下,下游无需做任何调整。除此之外,平台还提供了批量切换的能力,可以同时进行多张表的切换。
对于下游切换者来说,原本由于切换收益不大,导致操作意愿不强。但现在通过平台提供的切换收益量化的能力,如SLA和稳定性提升,提升下游切换意愿。
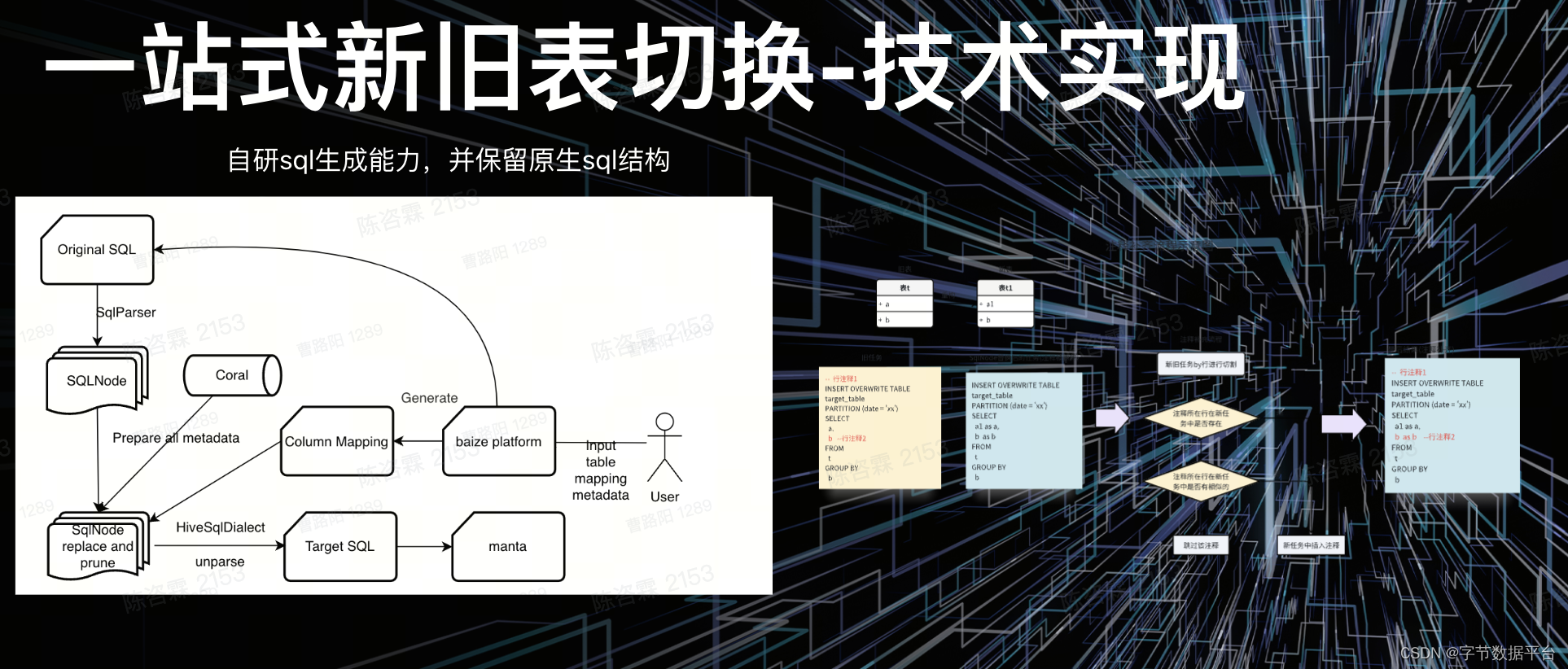
下面介绍技术实现。用户输入需要切换的旧表之后,平台通过旧表的产出任务进行解析,获取语法树文件,并基于语法树文件做裁剪、替换。基于用户输入的新旧表映射关系生成切换后的SQL,再提交到比对平台,最终完成整体比对。
在这一过程中,用户不希望原生代码遭到太多破坏,如注释被溶解,或对一些写法造成影响。针对这种情况,我们会在SQL解析前把注释的关键信息保留下来,拿到比对完成的SQL之后再做补全,最终把原始任务的SQL尽可能相似地提供出来。
字段口径探查
作为一名数仓研发人员或BI分析师,经常需要阅读其他人代码,如果代码复杂度高,对读码的专业性要求会比较高。为解决这个问题,平台提供可视化页面辅助转译。

如上图中的例子,将一段SQL转译成图的形式,可以更好帮助不写代码的角色更好理解这段SQL。
在大多数使用场景中,用户只想看到某个字段,或者某几个字段在任务中的加工逻辑。平台能力实现了在任务中裁剪出所需字段加工逻辑的能力,最终裁剪掉超90%的无关代码。原本需要从100行代码中提取出来某个字段的加工口径,现在借助平台能力,只需要阅读几行代码就可以完成需求。
此外,我们希望将整个数仓链路中分层维护的SQL进行溶解。
一个传统数仓链路有ODS层、DWD层、DWM层、APP层等等,每层都会维护一段SQL。用户需要梳理APP层的SQL里面的某个字段从ODS层哪里来的,过程比较复杂。
基于平台的能力,我们把4个任务的SQL先展开成一段大SQL,再进行内敛,最终变成从ODS层溯源到APP层的字段。平台内敛之后进行裁剪。代码的展开和收敛,是通过自研的一套语义解析引擎实现,该引擎已经申请了专利。
核心步骤如下:
-
第一步,对SQL算子进行优化,平台功能必须对算子级别SQL进行裁剪;
-
第二步,语法糖溶解,一段SQL要不断内敛,基于血缘关系找到上游表,放到替换掉这个实际的物理表名称中,在这个过程中,就会涉及到很多语法糖的溶解,在传统离线数仓里命名很多临时表,平台会进行完整的语法糖溶解;
-
第三步,基于此加上算子重写,获取关系代数,最终unparse成一段SQL返回给用户。
指标自动化拆解
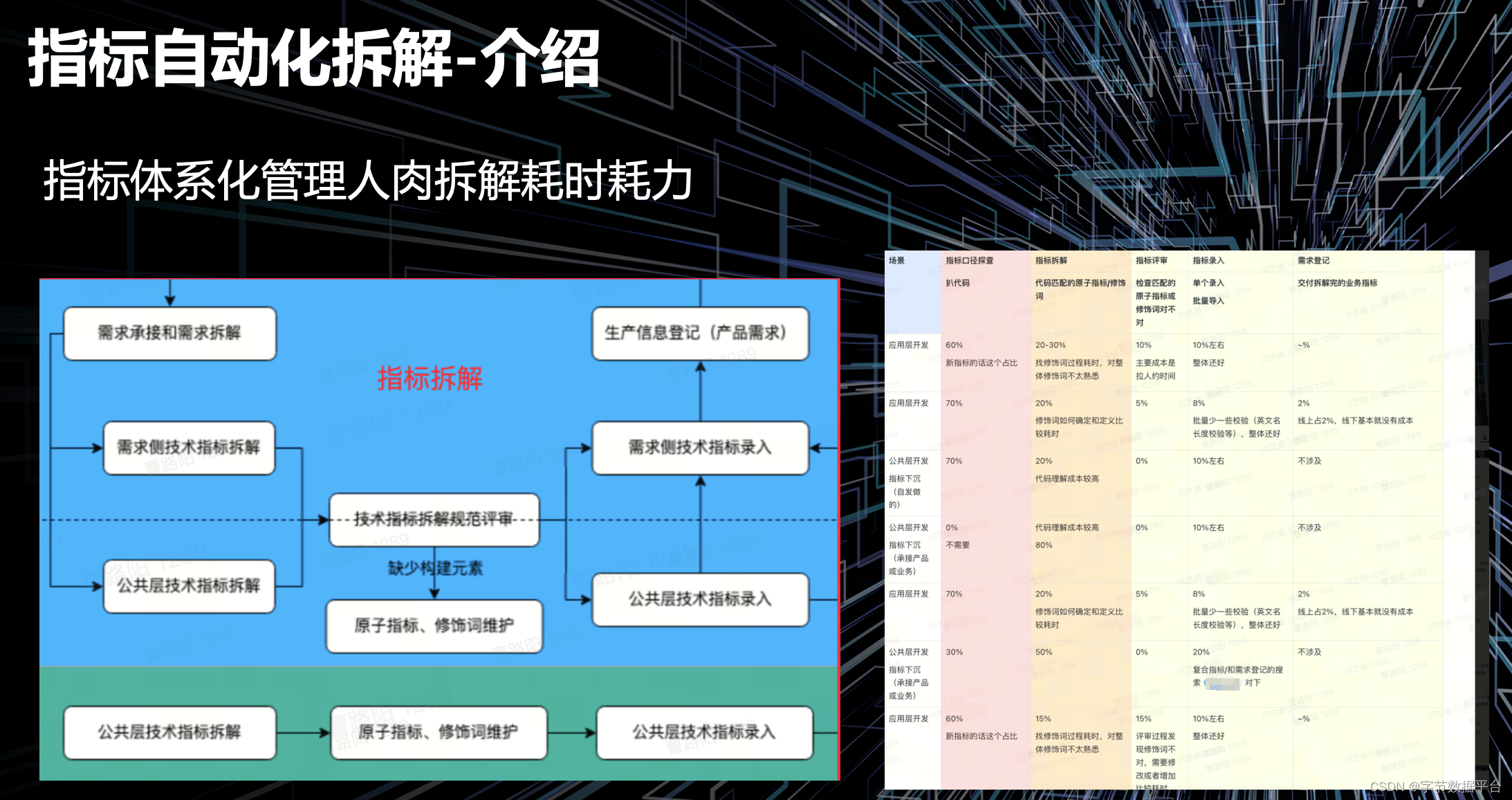
左图是传统数据指标体系化建设架构,包含配置信息、原子指标、度量、时间周期、修饰词等。每个指标种类不一样,衍生指标来源于原子指标,复合指标来源于衍生指标。
指标体系化建设的核心目的就是保证指标的一致性,避免指标重复建设。
在电商场景中,我们早期推进指标体系化建设有一个核心的步骤——指标拆解,即把字段关联到录入好的配置信息里面。如果发现绑定已有的衍生指标,则避免了重复建设的工作。
在该过程中,通过进行用户调研,我们发现,在做拆解的过程中,用户有几个核心环节,如通过字段口径了解字段真实的来源链路,同时还要看字段整体的加工逻辑,再人工用该SQL做拆解工作。最后,用户在指标平台里面维护好元信息。应用层的指标开发完成之后,再去评审最终拆解结果的质量。
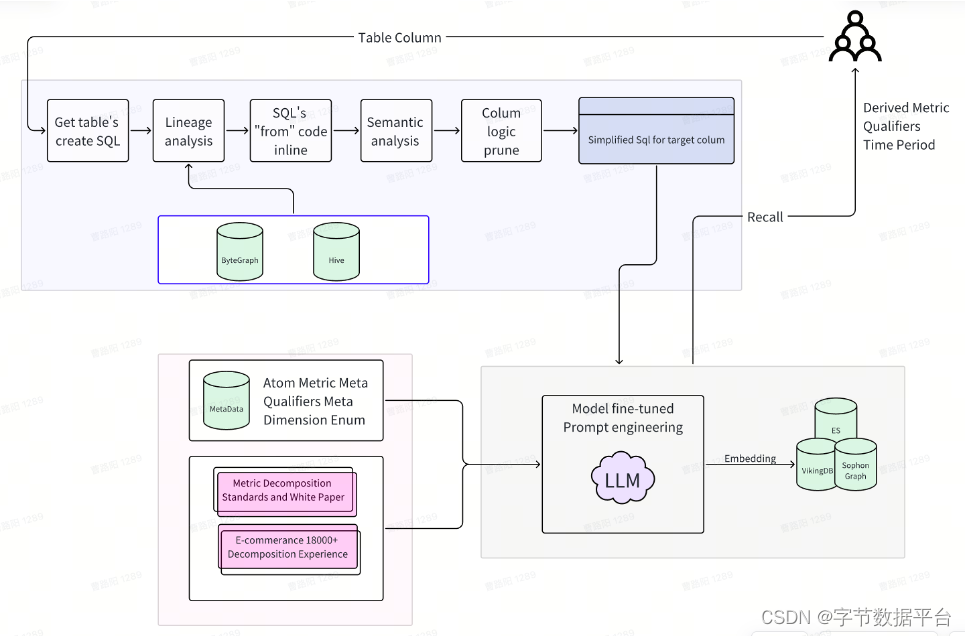
指标自动化拆解-技术实现
上图为指标自动化拆解-技术实现过程。
第一,工程能力。工程能力底层是字段口径探查的能力,将应用层的指标透传到明细数据层表,同时平台进行单指标粒度的裁剪,裁剪完成之后拿到字段应该绑定的DWD表,最终内敛到DWD表的极简SQL,过程中不需要人为查询代码完成逻辑梳理。
第二,底层数据能力。关键是必须维护好高质量的元数据。在电商场景中,我们维护了万级别的指标关系,在指标关系中再维护类似于业务过程度量的SQL逻辑,如where条件。
第三,大模型的能力。基于大模型能力,我们结合裁剪之后的SQL、待选SQL完成召回。裁剪之后的SQL,基于元数据及大模型能力,与规则方法论进行匹配,最终把标的元素判断出来。也就是说,研发人员只需要输入新开发的表,就可以知道该表是否存在重复开发的问题。
判断过程:根据拆解过程找到对应SQL,原子指标、修饰词、时间周期三个元素生成衍生指标,该衍生指标如果存在,就是存在重复开发,如果不存在,则可以在系统里绑定,供给数据应用使用。
总结与展望
数据血缘底座是提升数据管理效率和数据质量的关键。我们希望能不断提升全链路数据血缘的能力,在上文提到的新旧表切换、数仓价值评估、指标拆解等场景中,更好结合大模型等能力优化功能和用户体验,为业务提供更多价值。以上就是本次分享的内容,谢谢大家。

点击跳转火山引擎DataLeap了解详情
相关文章:
火山引擎数据飞轮实践:在电商场景中,如何建设全链路数据血缘?
数据作为新型生产要素,正支撑企业的数智化转型。但企业数字化建设也存在管理成本高、数据产品使用门槛高、数据资产价值不够的问题,其原因在于业务和数据之间没有形成双向良性驱动。 结合新时代企业数字化转型需求,火山引擎基于字节跳动十余…...

使用加密软件对企业来说有什么好处
泄密时间近年来层出不穷,一旦重要文件或数据被盗,无疑会对企业带来巨大的损失。 2024年3月,我国某高新科技企业遭境外黑客攻击,相关信息化系统及数据被加密锁定,生产经营活动被迫停止。企业生产经营活动受阻ÿ…...

STM32入门开发操作记录(二)——LED与蜂鸣器
目录 一、工程模板二、点亮主板1. 配置寄存器2. 调用库函数 三、LED1. 闪烁2. 流水灯 四、蜂鸣器 一、工程模板 参照第一篇,新建工程目录ProjectMould,将先前打包好的Start,Library和User文件^C^V过来,并在Keil5内完成器件支持包的…...

n3.平滑升级和回滚
平滑升级和回滚 1. 平滑升级流程2. 平滑升级和回滚案例 有时候我们需要对Nginx版本进行升级以满足对其功能的需求,例如添加新模块,需要新功能,而此时 Nginx又在跑着业务无法停掉,这时我们就可能选择平滑升级 1. 平滑升级流程 平…...

C#WPF DialogHost.Show 弹出对话框并返回数据
在WPF中,使用DialogHost.Show方法显示一个对话框并获取返回数据,你需要定义一个对话框,并在对话框关闭时返回数据。以下是一个简单的例子: 首先,在主窗口中添加DialogHost控件: <MaterialDesign:DialogHost x:Name="dialogHost" /> 然后,创建一个对话…...

Kafka Producer发送消息流程之分区器和数据收集器
文章目录 1. Partitioner分区器2. 自定义分区器3. RecordAccumulator数据收集器 1. Partitioner分区器 clients/src/main/java/org/apache/kafka/clients/producer/KafkaProducer.java,中doSend方法,记录了生产者将消息发送的流程,其中有一步…...
)
Codeforces Round 958 (Div. 2)
C o d e f o r c e s R o u n d 958 ( D i v . 2 ) \Huge{Codeforces Round 958 (Div. 2)} CodeforcesRound958(Div.2) 文章目录 Problems A. Split the Multiset题意思路标程 Problems B. Make Majority题意思路标程 Problems C. Increasing Sequence with Fixed OR题意思路标…...

<数据集>猫狗识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:3686张 标注数量(xml文件个数):3686 标注数量(txt文件个数):3686 标注类别数:2 标注类别名称:[cat, dog] 序号类别名称图片数框数1cat118811892dog24982498 使用标…...
Figma 中文版指南:获取和安装汉化插件
Figma是一种主流的在线团队合作设计工具,也是一种基于 Web 端的设计工具。在当今的设计时代,Figma 的使用满足了每个人的设计需求,不仅可以实现在线编辑,还可以方便日常管理,有效提高工作效率。然而,相信很…...

用c语言写一个贪吃蛇游戏
贪吃蛇游戏通常涉及到终端图形编程和简单的游戏逻辑。以下是一个基本的实现示例,包括贪吃蛇的移动、食物生成、碰撞检测等功能。 1. 贪吃蛇游戏的基本结构 贪吃蛇游戏可以分为以下几个部分: 游戏地图和终端绘制:使用二维数组表示游戏地图&am…...

计算机网络入门 --网络模型
计算机网络入门 --网络模型 1.OSI七层模型 1.1 模型概念 OSI七层模型是将计算机网络通信协议划分为七个不同层次的标准化框架,每一层都负责不同功能,并从物理连接层开始处理。OSI七层网络模型如下分别为:物理层、数据链路层、网络层、传输…...

陪玩系统小程序模式APP小程序H5系统搭建开发
随着移动互联网的营及和游戏行业的蓬轨发展,陪玩服务应远而生并迅速唱起,陪玩系统小程序作为连接游戏玩家与陪玩师的桥梁,其模式系统的搭建与开发是得尤为重要,本文将洋细凰述陪玩系统小程宗模式系统的搭建开发流程,包…...

算法训练营day72
题目:117. 软件构建 (kamacoder.com) #include<iostream> #include<unordered_map> #include<vector> #include<queue>using namespace std;int main() {int n, m;cin >> n >> m;vector<int> indegree(n, 0);unordered_…...

C语言------指针讲解(2)
目录 一、数组名的理解 二、使用指针访问数组 三、一维数组传参的本质 四、冒泡排序 五、二级指针 六、指针数组 七、指针数组模拟二维数组 一、数组名的理解 通过学习,我们知道:数组名和数组首元素的地址打印出来的结果一模一样,数组…...

大数据技术基础
一、大数据平台 1.大数据平台方案步骤: ①市场上有哪些大数据平台 ②硬件、系统、业务增长等方面 ③方案是否通过 通过后:按照一期目标投入 先虚拟环境部署联系,再实际部署 《大数据架构介绍》《Hadoop架构解析》《Hadoop集群规划》 《H…...

【文心智能体】前几天百度热搜有一条非常有趣的话题《00后疯感工牌》,看看如何通过低代码工作流方式实现图片显示
00后疯感工牌体验:https://mbd.baidu.com/ma/s/6yA90qtM 目录 前言比赛推荐工作流创建工作流入口创建工作流界面工作流界面HTTP工具卡点地方 总结推荐文章 前言 前几天百度热搜有一条非常有有趣《00后疯感工牌》。 想着通过文心智能体去一键生成00后疯感工牌是不是…...

C++20中的constinit说明符
constinit说明符断言(assert)变量具有静态初始化,即零初始化和常量初始化(zero initialization and constant initialization),否则程序格式不正确(program is ill-formed)。 constinit说明符声明具有静态或线程存储持续时间(thread storage duration)的…...

Java 中的正则表达式
转义字符由反斜杠\x组成,用于实现特殊功能当想取消这些特殊功能时可以在前面加上反斜杠\ 例如在Java中当\出现时是转义字符的一部分,具有特殊意义,前面加一个反斜可以取消其特殊意义,表示1个普通的反斜杠\,\\\\表示2个…...

华为配置蓝牙终端定位实验
个人主页:知孤云出岫 目录 配置蓝牙终端定位示例 业务需求 组网需求 数据规划 配置思路 配置注意事项 操作步骤 配置文件 配置蓝牙终端定位示例 组网图形 图1 配置蓝牙终端定位示例组网图 业务需求组网需求数据规划配置思路配置注意事项操作步骤配置文件 业…...

搭建hadoop+spark完全分布式集群环境
目录 一、集群规划 二、更改主机名 三、建立主机名和ip的映射 四、关闭防火墙(master,slave1,slave2) 五、配置ssh免密码登录 六、安装JDK 七、hadoop之hdfs安装与配置 1)解压Hadoop 2)修改hadoop-env.sh 3)修改 core-site.xml 4)修改hdfs-site.xml 5) 修改s…...

如何通过智能包装系统提升全链条的数字化与协同效率?
本段聚焦全链条数字化升级的核心路径,通过 智能包装系统实现 原材料到成品的数据共享与流程对齐。以原材料入库、生产、成品出库为主线,建立统一的数据模型、模块化接口与可追溯闭环,推动 协同优化与成本控制。结合 中科天工智能包装设备与 中…...

基于Zynq FPGA的2-FSK基带发射器设计与实现
1. 项目概述与核心思路最近在折腾一个基于Zynq的软件定义无线电(SDR)小项目,核心需求很简单:用硬件逻辑生成一个可调频率的正弦波,并通过DAC输出。这听起来像是数字信号处理的入门练习,但我的目标更具体一点…...

公域卖课佣金高、粉丝留不住?这套私域打法,完课率提升了3倍
公域卖课的两大痛点痛点一:佣金太高,利润被吃掉一大块。相信在公域卖过课的朋友都有体会。平台抽成、分销佣金、投流成本……七七八八算下来,到手的钱可能连一半都不到。你辛辛苦苦打磨的课程,大头却被别人拿走了。这感觉…...
)
CE修改器进阶:通过内存结构分析,破解‘敌我同源’的游戏逻辑(以浮点数血量为例)
CE修改器进阶:内存结构分析与游戏逻辑破解实战 游戏修改器一直是技术爱好者探索虚拟世界底层逻辑的利器。在众多工具中,Cheat Engine(简称CE)以其强大的内存扫描和调试功能脱颖而出,成为逆向工程领域的瑞士军刀。今天&…...

从理论到代码:一步步拆解单纯形法在MATLAB中的核心‘旋转运算’
从理论到代码:一步步拆解单纯形法在MATLAB中的核心‘旋转运算’ 单纯形法作为线性规划领域最经典的算法之一,其理论优雅性与计算高效性在数学优化中独树一帜。然而,当我们将教科书中的表格计算转化为编程语言实现时,往往会遇到一个…...

搜索已死?不,它刚刚重生为Agent的“天眼”
前言2026年,AI Agent的能力正以月为单位狂飙突进。写代码、跑审计、做研报……曾经需要人类全程陪跑的任务,如今八成以上已被Agent自主接管。然而,一个看似微不足道的环节,却成了整个智能链条中最脆弱的一环——搜索。你让Agent查…...

将OpenSSH集成到OpenHarmony系统镜像:从编译到system分区的完整部署流程
OpenHarmony系统镜像中集成OpenSSH的工程化实践 在物联网设备快速普及的今天,安全远程管理成为嵌入式系统开发中不可或缺的一环。作为开源鸿蒙生态的核心,OpenHarmony系统需要提供完善的远程访问能力,而OpenSSH作为行业标准的加密通信工具&am…...

Marshall 推出新款头戴式耳机 Milton ANC:音质续航兼得,售价 229 美元!
ZDNET 要点总结Milton ANC 是 Marshall 最新推出的头戴式耳机,在音质、耐用性和电池续航方面毫不妥协,售价为 229 美元。Marshall 宣布推出全新头戴式耳机——Milton ANC,它承诺在不牺牲电池续航的前提下,带来标志性的音效体验&am…...

# 040、实战项目五:多 Agent 协作系统 —— 项目经理、开发者、测试者角色模拟
从一次凌晨三点的事故说起 去年做智能客服系统重构,我犯了个低级错误——让单个Agent既写代码又自测。结果上线当天,它把“用户退款”的SQL写成了DELETE FROM orders WHERE status‘refund’,还自信满满地标注“测试通过”。凌晨三点被运维电…...

推荐几款实测有效的降重工具,要求同时对付查重系统和AIGC检测
毕业季论文两大 “生死关”—— 知网 / 维普 / 格子达等查重标红、AIGC 疑似率超标,已成为无数学生的噩梦。普通降重工具仅能降重复率,改写后仍难逃 AI 检测;AI 写作工具生成内容流畅度高,却自带明显 AI 痕迹,双检极易…...