高阶面试-mongodb
mongodb的特点,为什么使用他
nosql数据库,前端到后端到数据库,都是json,无模式,数据模型发生变更,不需要强制更新表结构,可以快速实现需求迭代。
天生分布式,高可用,处理海量高并发的数据应用。
除了CRUD,还有aggregation,可以做分析报表;有gridfs做分布式文件存储
各种致敬,索引、慢查询、explain等,无缝迁移
地理空间索引,适合移动端业务
工具多,mtools搭建集群、mongostat、mongotop等监控、mongoshake迁移
分布式高可用
涉及到 选举、复制、故障转移、数据均衡、复制延迟等
选举
需要强一致性,一般都是采用raft算法的实现,比如redis的选举、zk的选举等
流程:
各种原因触发选举startElectSelfIfEligible --> 预选举dryRun --> 选举realElection --> 投自己票voteForMyself --> 处理投票结果onVoteRequestComplete --> 处理选举获胜的结果processWinElection --> 状态变更restartHeartbeats_inlock --> 进入追赶模式catchupState --> 判断是否追上abort_inlock --> 收尾模式drainComplete
根据什么确认可以当leader?
心跳(其他节点可能率先完成选主)、任期(term)、opLog时间戳
为啥多了个预选举,防止 网络异常导致的 分区下自己投自己选了很多次term增加很多,然后网络恢复还要多一次选举的情况。
其他优化:
- 多了个chainingAllowed 链式复制,节点同步数据可以选距离自己最近的节点复制数据,怎么判断最近,心跳延时最小
- 支持投票优先级,氪金玩家体验更好
- 选举策略,可以PSS PSA,也就是arbiter等
- 脑裂的避免,primary 在选举超时时间内没收到大多数节点的应答会自动退位成secondary
复制
采用opLog同步数据,这里的oplog是一个特殊的固定集合,当主节点上的一个写操作完成后,会向oplog集合写入一条对应的日志,而备节点则通过这个oplog不断拉取到新的日志,在本地进行回放以达到数据同步的目的。由于日志会不断增加,因此oplog被设计为固定大小的集合,它本身就是一个特殊的固定集合(capped collection),当oplog的容量达到上限时,旧的日志会被滚动删除
怎么实现的?
一个环状的队列,新文档在写入时会被插入队列的末尾,如果队列已满,那么之前的文档就会被新写入的文档所覆盖
类似disraptor
备节点便可以通过轮询的方式进行拉取,这里会用到可持续追踪的游标(tailable cursor)技术
其实类似kafka的LEO同步
每个备节点都分别维护了自己的一个offset,也就是从主节点拉取的最后一条日志的optime,在执行同步时就通过这个optime向主节点的oplog集合发起查询。
每一条oplog记录都描述了一次数据的原子性变更,对于oplog来说,必须保证是幂等性的
如何实现
执行$inc操作,每次都会产生新的结果。这些非幂等的更新命令在oplog中通常会被转换为$set操作
可能问题?
如果备节点的复制不够快,就无法跟上主节点的步伐,从而产生复制延迟(replication lag)问题。
如何解决的
调整 writeConcern 和 readConcern 设置。适当降低 writeConcern 的级别可以减少写入时的延迟,但要权衡数据安全性。启用压缩,如启用 snappy 或 zlib 压缩来减少网络传输的数据量。优化 oplog 大小,确保其足够大以容纳高峰期的写操作。
在开始时,备节点仍然需要向主节点获得一份全量的数据用于建立基本快照,这个过程就称为初始化同步(initial sync)
如何实现
● 备节点记录当前的同步optime=t1(来自主节点的同步时间戳),进入STARTUP2状态。
● 从主节点上复制所有非local数据库的集合数据,同时创建这些集合上的索引。
在这个过程中,备节点会开启另外一个线程,将集合复制过程中的增量oplog(t1之后产生)也复制到本地。
● 将拉取到t1之后的增量oplog进行回放,在完成之前,节点一直处于RECOVERING状态,此时是不可读的。
● oplog回放结束后,恢复SECONDARY状态,进入正常的增量同步流程。
故障转移
自动选举,然后同步
对于业务方,副本集发生主备切换的情况下,会出现短暂的无主节点,无法接受业务写操作,
数据均衡
涉及到一个知识点chunk,数据块
每个分片的最小结构是chunk,chunk描述的是范围区间,集群在操作分片集合时,会根据分片键找到对应的chunk,并向该chunk所在的分片发起操作请求
chunk的切分方式,决定如何找到数据所在的chunk
chunk的分布状态,决定如何找到chunk所在的分片
分片策略有两种:
- 范围分片 range sharding 可以选多个字段组合成分片键
- 哈希分片 只能单个字段
分片策略选择因素
- 分片键的基数(cardinality),取值基数越大越有利于扩展。
- 分片键的取值分布应该尽可能均匀。
- 业务读写模式,尽可能分散写压力,而读操作尽可能来自一个或少量的分片。
- 分片键应该能适应大部分的业务操作。
避免广播查询,根据分片键无法满足业务查询需求,导致对所有分片做广播操作。
数据均衡的意思:
- 所有数据应该均匀的分布在不同的chunk上 由分片策略决定
- 每个分片的chunk数量尽可能的相近
如何保证每个分片的chunk数量尽可能的相近 呢?
可以手动均衡 适用于hash分片,初始的时候预分配一定数量的chunk;另一种做法通过splitAt、moveChunk命令手动切分、迁移
可以自动均衡 开启自动均衡功能 setBalancerState(true) balancer发现了不均衡状态就会自动进行chunk的搬迁以达到均衡
chunk的分裂
默认一个chunk 64MB,由chunkSize参数指定,如果数据量超了,会自动进行分裂,将chunk切分为大小相同的两块。
chunk分裂基于分片键,分片键的基数cardinality太小,会导致无法分裂出现jumbo chunk,如性别
写压力过大也可能导致分裂失败,当chunk 的文档数超过1.3xavgObjectSize导致无法迁移
自动均衡
balancer位于Primary Config Server,该节点同时控制chunk数据的搬迁流程。
具体迁移流程
- 分片shard0在持续的业务写入压力下,产生了chunk分裂
- 分片服务器通知Config Server进行元数据更新
- Config Server的自动均衡器对chunk分布进行检查,发现shard0和shard1的chunk数差异达到了阈值,向shard0下发moveChunk命令以执行chunk迁移。
- shard0执行指令,将指定数据块复制到shard1。该阶段会完成索引、chunk数据的复制,而且在整个过程中业务侧对数据的操作仍然会指向shard0;所以,在第一轮复制完毕之后,目标shard1会向shard0确认是否还存在增量更新的数据,如果存在则继续复制
- shard0完成迁移后发送通知,此时Config Server开始更新元数据库,将chunk的位置更新为目标shard1。在更新完元数据库后并确保没有关联cursor的情况下,shard0会删除被迁移的chunk副本
- Config Server通知mongos服务器更新路由表。此时,新的业务请求将被路由到shard1
迁移的阈值
不均衡状态的判断:
- chunk个数差异< 20, 阈值2
- chunk个数差异20-79, 阈值4
- chunk个数差异>80, 阈值8
数据均衡影响性能的解决方案
容易带来磁盘I/O使用率飙升,或业务时延陡增等,一个是使用SSD,将数据均衡的窗口对齐到业务的低峰期以降低影响
config数据库更新配置 setActiveWindow start stop时间为凌晨
创建索引失败MongoError: too many namespaces/collections
涉及到存储引擎
mongodb我们用的3.0,存储引擎使用的MMAPv1,采用内存映射文件管理数据,缺点是锁粒度是集合级别,并发性能受影响;缺少数据压缩,磁盘利用率低
2015年3.2版本开始wiredTiger称为默认存储引擎
storage.mmapv1.nsSize ,
mongodb mmapv1 存储引擎的 namespace size 有大小限制,默认 16M,大概 24,000 表和索引在一个 db 里
线上的 库的一个 db有 5000 左右个 collection,每个表了 里差不多有 1~10 个索引
namespace啥意思?就是mongo的collection
mongodb的OOM
背景
线上平台出现mongodb的oom,高可用架构重新选举之后选举完又OOM,mong重启达到分钟级别,多个节点被OOM后,不能很快拉起服务,对业务产生很大影响。
分析
表面看,有几个问题,1是128个G的内存,还会OOM,肯定有优化空间;2是为啥启动这么慢
通过表分析,有很多大表,其中一个巨大的表占用了110G,且有频繁的读写,原因是有很多冷数据,未做冷热分离
优化
- 删除部分历史遗留数据,如有些bak表
- mongodb的优化,mongodb3.2以后采用wiredTiger引擎,虽然不是内存数据库,但是为了提高读写效率,会最大化利用内存。修改evict的配置
db.adminCommand({setParameter: 1, wiredTigerEngineRuntimeConfig: "eviction=(threads_min=1,threads_max=8)"})原先最小线程是4,改为1,减少不必要的线程开销,减少IO抖动
深挖
mongo的内存使用
理想情况,mongodb可以提供近似内存的读写性能,wiredTiger有两级缓存,第一层是操作系统的页面缓存,第二层则是引擎提供的内部缓存
![[Pasted image 20240713071010.png]]
数据读取的流程:
- 数据库发起buffer IO读操作,由操作系统将磁盘数据页加载到文件系统的页缓存区。
- 引擎层读取页缓存区的数据,进行解压后存放到内部缓存区。
- 在内存中完成匹配查询,将结果返回给应用
如果数据已经被存储在内部缓存中,MongoDB则可以发挥最佳的读性能。稍差的情况是内部缓存中找不到,但数据仍然被存储在操作系统的页缓存中,此时需要花费一些数据解压缩的开销。为了尽可能保证业务查询的“热数据”能快速被访问,其内部缓存的默认大小达到了内存的一半,对应参数wiredTigerCacheSize指定的。
数据写入的流程:
先在内存中记录这些变更,之后通过CheckPoint机制将变化的数据写入磁盘
带来问题:可靠性
解决方案:
checkpoint检查点机制,类似RDB,建立checkpoint的时候,会在内存建立所有数据的一致性快照,是通过MVCC保证,然后持久化快照,默认1min一次,成功后内存中的修改才会真正保存。
journal日志 WAL机制,预写,顺序写,会将每个写操作的redo日志写入journal缓冲区,频繁地将日志持久化到磁盘上。一般100ms一次。如果journal日志达到100MB,或者应用程序指定journal为true,也会触发。
本质:存量(快照)+增量(journal)
实际写入的完整流程
- 应用写数据CUD
- mongo从内部缓存获取当前记录的page,如果不存在从磁盘加载 buffer IO
- wiredTiger开始执行写事务,修改的数据写入page的一个更新记录表,原来的记录保持不变
- 如果开启journal日志,写入的同时会写journal日志也就是redo log,不超过100ms将日志写磁盘
- mongo每60s执行一次checkpoint,将内存的修改真正刷盘
然后就是脏页 dirty page
需要说到缓存页的管理
page管理也是B+树,当叶子节点产生数据写入,更新记录会写入节点的一块独立区域,此时该节点被标记为脏页。其中insert和update是单独的跳表,分别存插入和修改操作,如果存在修改,读取的时候会从跳表做合并查找。
checkpoint的时候,block manager发起reconncilication过程,将内存页转换为磁盘页的格式,checkpoint线程会遍历内存中全部页并找到所有脏页进行持久化,一般用copy-onwrite保证读写分离。
对于脏页不是就地更新,而是产生新节点,每次都产生一个新的根节点,持久化完成,再淘汰不用的节点。
reconciliation的触发
- checkpoint
- 缓存的page超过最大值(存在大量修改),产生分裂,触发evict
- 缓存的脏数据比例达到阈值,触发缓存淘汰evict
缓存淘汰
wiredTiger基于LRU实现缓存的淘汰,通常由后台evict线程负责,如果内存很紧张,用户线程也会加入,读写卡顿。
淘汰策略:
![[Pasted image 20240713074054.png]]
从官网上看的
数据压缩,
- 集合采用块压缩,默认采用谷歌开源的snappy
- 索引用前缀压缩 prefix compression
- journal日志也是snappy压缩
压缩算法可以调整,storage.wiredTiger.collectionConfig.blockCompressor mongodb4.2开始支持Zstd,facebook开源的较低的CPU消耗实现更高压缩比
用内存做什么
- mongo的数据读写
- mongo连接线程
- 管理操作如创建索引、数据备份
内部缓存增大后,内存中允许驻留的脏数据也会更多,导致磁盘IO抖动问题更加明显
mongodb cursor not found
背景
使用云厂商提供的mongodb分片集群,client–>slb–>mongos,数据量大的时候报错:[AllExceptionsFilter] CaughtException: MongoError: Cursor not found (namespace: 'v7common.users', id: 3392892230983559305).
分析
游标失效了,通过slb请求mongos,策略的原因,每次查的mongos不一样,游标在一个mongos打开,后续请求路由到另一个mongos了,导致游标丢失。
优化
SLB采用会话保持,让每个客户端的会话被路由到自己对应的mongos实例
mongo的cursor
从应用层面看,游标类似一个指针,看mongodriver,是个迭代器,对于find结果进行遍历,其实是通过MongoCursor对象操作。真实的实现,做了优化,每次获取一批数据放到内存。具体细节:
- 第一次提交查询,才会携带查询条件、排序分页等参数,如果一次查询不完,通过getMore操作用cursorId进行分批拉取
- 调用next方法,其实是获取缓存的一条数据,当缓存遍历完毕自动获取下一批
- 每次拉取的条数由batchSize参数决定
- 如果没有batchSize,默认首次find返回最多101条数据,后续getMore没有限制的化,默认返回不超过16MB的数据
游标有个超时时间,默认10min,那不应该cursor not found的啊
需要了解mongos的原理
mongos查询路由,是分片集群的访问入口,从config server获取元数据并加载,然后提供访问服务将用户请求路由到对应分片。
从不同的slb过来的被认为不同的连接,导致游标失败
连接池偶发断开
背景
华为云ELB,mongo连接池偶发断开
![[Pasted image 20240713102322.png]]
一段时间后(大概一分钟)还能自动恢复
![[Pasted image 20240713102337.png]]
2021-11-16 12:46:11.938 nacos [http-nio-8089-exec-4] WARN org.mongodb.driver.connection - Got socket exception on connection [connectionId{localValue:95, serverValue:9552231}] to 172.16.3.182:7211. All connections to 172.16.3.182:7211 will be closed.
2021-11-16 12:46:11.939 nacos [http-nio-8089-exec-4] INFO org.mongodb.driver.connection - Closed connection [connectionId{localValue:95, serverValue:9552231}] to 172.16.3.182:7211 because there was a socket exception raised by this connection.
2021-11-16 12:46:11.939 nacos [http-nio-8089-exec-4] INFO org.mongodb.driver.cluster - No server chosen by ReadPreferenceServerSelector{readPreference=primary} from cluster description ClusterDescription{type=SHARDED, connectionMode=MULTIPLE, serverDescriptions=[ServerDescription{address=172.16.3.182:7211, type=UNKNOWN, state=CONNECTING}]}. Waiting for 30000 ms before timing out
2021-11-16 12:46:11.940 nacos [http-nio-8089-exec-4] INFO org.mongodb.driver.connection - Closed connection [connectionId{localValue:94, serverValue:9552230}] to 172.16.3.182:7211 because there was a socket exception raised on another connection from this pool.
![[Pasted image 20240713102409.png]]
mongo日志也有报错
![[Pasted image 20240713102424.png]]
分析
ELB导致的mongos的问题,云不是真正的高可靠,打破大厂迷信。
mongo的常用工具
mongostat
/opt/mongodb3.2.13/bin/mongostat -h 10.152.206.81 --port 7210 -u xxx -p 'xxx' --authenticationDatabase=admin --discover
![[Pasted image 20240713070357.png]]
一般用来查看QPS、内存占用、连接数等,里面vsize是虚拟内存 res是物理内存使用量
另外就是
- CRUD的速率是否有波动,超出预期
- connect 连接数是否太多
- dirty 百分比是否较高,如果持续高于10%说明磁盘IO存在瓶颈
- repl 状态是否异常,如果 RTR正常,如果REC等异常值需要修复
mongotop
``
用来查看热点表,
- 是否存在非预期的热点表,其实就是看是否有慢查询
- 热点表的操作耗时是否过高,业务高峰一般比较高一点
可以设置 -n 100 2 就是间隔2s,总共输出100次
迁移
采用 mongoshake
mongodb相关优化
mongo查询数据以后,应该使用project只返回需要使用的字段,否则在数据量、字段比较多的时候,查询效率会显著下降
索引:覆盖索引
相关文章:

高阶面试-mongodb
mongodb的特点,为什么使用他 nosql数据库,前端到后端到数据库,都是json,无模式,数据模型发生变更,不需要强制更新表结构,可以快速实现需求迭代。 天生分布式,高可用,处…...

MySQL数据库慢查询日志、SQL分析、数据库诊断
1 数据库调优维度 业务需求:勇敢地对不合理的需求说不系统架构:做架构设计的时候,应充分考虑业务的实际情况,考虑好数据库的各种选择(读写分离?高可用?实例个数?分库分表?用什么数据库?)SQL及索引:根据需求编写良…...

[短笔记] Ubuntu配置环境变量的最佳实践
结论: 不确定是否要设为系统,则先针对当前用户设,写~/.profile确定为系统级,写/etc/environment,注意无需export不推荐写在~/.bashrc(Ubuntu不推荐,理由见references) References&…...

怎样在 PostgreSQL 中优化对多表关联的连接条件选择?
🍅关注博主🎗️ 带你畅游技术世界,不错过每一次成长机会!📚领书:PostgreSQL 入门到精通.pdf 文章目录 怎样在 PostgreSQL 中优化对多表关联的连接条件选择一、理解多表关联的基本概念二、选择合适的连接条件…...
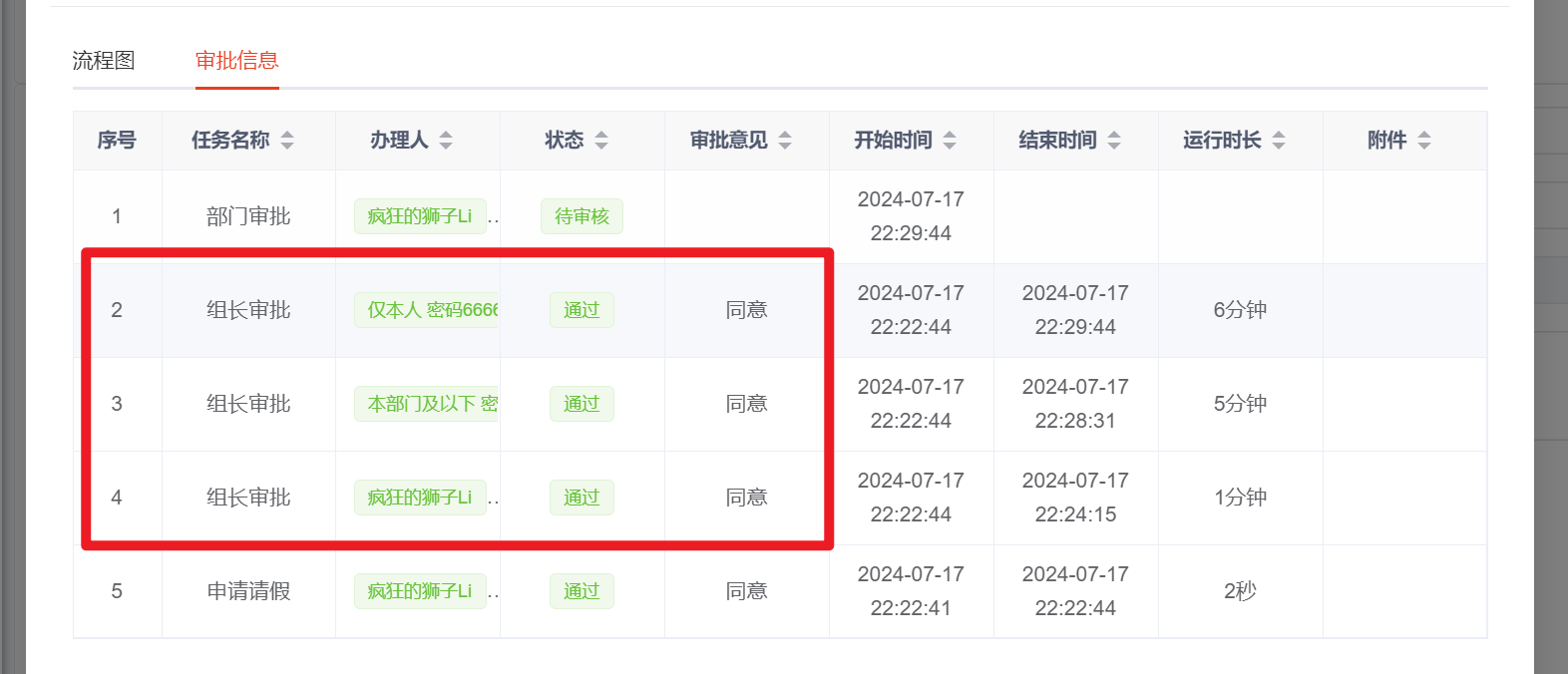
【Flowable | 第四篇】flowable工作流多任务实例节点实现会签/或签
文章目录 5.flowable工作流多任务实例节点实现会签/或签5.1会签/或签概念5.2多实例配置说明5.3会签例子5.3.1用户候选人配置5.3.2多实例配置5.3.3执行监听器配置5.3.5测试 5.flowable工作流多任务实例节点实现会签/或签 5.1会签/或签概念 我们在本篇中,将使用多任…...

解决C#读取US7ASCII字符集oracle数据库的中文乱码
👨 作者简介:大家好,我是Taro,全栈领域创作者 ✒️ 个人主页:唐璜Taro 🚀 支持我:点赞👍📝 评论 ⭐️收藏 文章目录 前言一、解决方法二、安装System.Data.OleDb连接库三…...

Linux驱动开发中设备节点、虚拟节点、逻辑节点之间的区别与关系
概述 在Linux DTS中我们可以看到各种各样的节点,每个节点都是对某一物理设备或功能抽象或具体的描述 设备节点 设备节点是对物理设备的一种具体的描述,它一般包含设备的寄存器地址、设备的类型、中断、时钟频率这些通用信息,除了这些通用信…...

【iOS】——ARC源码探究
一、ARC介绍 ARC的全称Auto Reference Counting. 也就是自动引用计数。使用MRC时开发者不得不花大量的时间在内存管理上,并且容易出现内存泄漏或者release一个已被释放的对象,导致crash。后来,Apple引入了ARC。使用ARC,开发者不再…...

ubuntu服务器安装labelimg报错记录
文章目录 报错提示查看报错原因安装报错 报错提示 按照步骤安装完labelimg后,在终端输入labelImg后,报错: (labelimg) rootinteractive59753:~# labelImg ………………Got keys from plugin meta data ("xcb") QFactoryLoader::Q…...
Transformer中Decoder的计算过程及各部分维度变化
在Transformer模型中,解码器的计算过程涉及多个步骤,主要包括自注意力机制、编码器-解码器注意力和前馈神经网络。以下是解码器的详细计算过程及数据维度变化: 1. 输入嵌入和位置编码 解码器的输入首先经过嵌入层和位置编码: I…...

QT实现滑动页面组件,多页面动态切换
这篇文章主要介绍了Qt实现界面滑动切换效果,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下。 一、简述 一个基于Qt的动态滑动页面组件。 二、 设计思路 1、自定义StackWidget类,继承自QWidget,实现一个堆叠…...

使用Python-docx库创建Word文档
哈喽,大家好,我是木头左! 简介 Python-docx是一个用于处理Microsoft Word文档的Python库。它允许用户创建、修改和提取Word文档的内容。在本文中,将详细介绍如何使用Python-docx库创建一个新的Word文档。 安装Python-docx库 要使用Python-docx库,首先需要安装它。可以使…...

C# 设计一个可变长度的数据通信协议编码和解码代码。
设计一个可变长度的数据通信协议编码和解码代码。 要有本机ID字段,远端设备ID字段,指令类型字段,数据体字段,校验字段。其中一个要求是,每次固定收发八个字节,单个数据帧超过八个字节需要分包收发。对接收的…...

【MATLAB库函数系列】MATLAB库函数pwelch之功率谱估计的详解及实现
功率谱估计 由于实际信号通常是非定常的,我们只能假设其在10ms的时间段内是定常的,并在此基础上对短的定常信号求PSD或者能谱。 窗函数的作用就是将原始的信号分割成一段段可以计算PSD和能谱的短信号,并且保证了周期结构的连续性、避免了频谱泄漏。不同的窗函数具有不同的…...

科技出海|百分点科技智慧政务解决方案亮相非洲展会
近日,华为非洲全联接大会在南非约翰内斯堡举办,吸引政府官员行业专家、思想领袖、生态伙伴等2,000多人参会,百分点科技作为华为云生态合作伙伴,重点展示了智慧政务解决方案,发表《Enable a Smarter Government with Da…...

Prometheus 云原生 - Prometheus 数据模型、Metrics 指标类型、Exporter 相关
目录 开始 Prometheus 数据类型 简单理解 时序样本 格式 和 命名要求 Metrics 指标类型 Counter 计数器 Gauge Histogram Summary Exporter 相关 概述 Exporter 类型 Exporter 规范 开始 Prometheus 数据类型 简单理解 a)安装好 Prometheus 后会暴露…...
Qt窗口程序整理汇总
到今日为止,通过一个个案例的实验,逐步熟悉了 Qt6下 窗体界面开发的,将走过的路,再次汇总整理。 Qt Splash样式的登录窗https://blog.csdn.net/castlooo/article/details/140462768 Qt实现MDI应用程序https://blog.csdn.net/cast…...

简单实现一个本地ChatGPT web服务(langchain框架)
简单实现一个本地ChatGPT 服务,用到langchain框架,fastapi,并且本地安装了ollama。 依赖安装: pip install langchain pip install langchain_community pip install langchain-cli # langchain v0.2 2024年5月最新版本 pip install bs4 pi…...
)
Elasticsearch-多边形范围查询(8.x)
目录 一、字段设计 二、数据录入 三、查询语句 四、Java代码实现 开发版本详见:Elasticsearch-经纬度查询(8.x-半径查询)_es经纬度范围查询-CSDN博客 一、字段设计 PUT /aoi_points {"mappings": {"properties": {"location": {…...

Kotlin Misk Web框架
Kotlin Misk Web框架 1 Misk 框架介绍2 Misk/SpringBoot 框架对比3 Misk 添加依赖/配置3.1 build.gradle.kts3.2 settings.gradle.kts3.3 gradle.properties 4 Misk 请求接口5 Misk 程序模块6 Misk 主服务类7 Misk 测试结果 1 Misk 框架介绍 Misk 是由 Square 公司开发的一个开…...

新手创业是注册公司好还是注册个体户好?
很多刚准备创业的朋友,最先纠结的问题就是:我到底是注册个体工商户,还是直接注册有限公司?一、先搞懂最核心的本质区别个体户属于个人经营模式,承担无限连带责任,简单说就是生意出问题,个人资产…...

不止于测试:用GStreamer打造你的树莓派低成本视频监控/图传系统
树莓派视频监控实战:用GStreamer构建低成本图传系统 树莓派搭配普通USB摄像头能做什么?大多数人可能只想到简单的视频采集测试。但如果你掌握GStreamer这个多媒体框架的进阶用法,就能将它变成一套功能完整的视频监控或无线图传系统。本文将彻…...
)
避坑指南:展锐平台Camera驱动移植中那些容易出错的配置项(以OV08A10为例)
展锐平台Camera驱动移植实战:OV08A10关键配置避坑手册 当你在展锐平台上移植OV08A10摄像头驱动时,是否遇到过这样的场景:所有配置看似正确,但摄像头就是无法正常工作?预览黑屏、图像异常或设备根本无法识别传感器——这…...

如何为 OpenClaw 配置 Taotoken 以实现高效的 Agent 工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为 OpenClaw 配置 Taotoken 以实现高效的 Agent 工作流 基础教程类,面向使用 OpenClaw 框架构建 AI Agent 的开发者…...

Vivado用户必看:中文用户名导致Vscode关联失效?手把手教你修改vivado.xml文件
Vivado与Vscode联动的终极解决方案:彻底攻克中文路径兼容性问题 在FPGA开发领域,Vivado作为Xilinx推出的旗舰级开发工具,与轻量级代码编辑器Vscode的联动已经成为提升开发效率的标准配置。然而,许多中文用户在实际操作中常常遇到…...

效率翻倍!用VSCode和SumatraPDF打造你的LaTeX论文写作‘双向传送门’
效率翻倍!用VSCode和SumatraPDF打造你的LaTeX论文写作‘双向传送门’ 学术写作从来不是一件轻松的事,尤其是当你需要处理大量公式、图表和参考文献时。传统的LaTeX写作流程往往需要在编辑器、编译器和PDF阅读器之间反复切换,这种割裂的体验让…...

GIFT高级技巧:图像组合、并行处理和性能优化的终极指南
GIFT高级技巧:图像组合、并行处理和性能优化的终极指南 【免费下载链接】gift Go Image Filtering Toolkit 项目地址: https://gitcode.com/gh_mirrors/gi/gift GIFT(Go Image Filtering Toolkit)是一个强大的Go语言图像处理库&#x…...

5步实现Windows直接安装Android应用:APK Installer完全指南
5步实现Windows直接安装Android应用:APK Installer完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过,在Windows电脑上安装…...

STFT与小波变换深度对比:时频分析工具选型与实战指南
1. 项目概述:时频分析工具箱的深度对比在信号处理这个行当里,时频分析一直是个绕不开的核心话题。无论是处理一段音频、分析机械振动信号,还是解读脑电图数据,我们面对的信号往往不是一成不变的。它们内部的频率成分会随着时间推移…...

2026 在线水印去除工具怎么选?6款实用方法对比测评
在短视频时代,去水印需求越来越普遍。无论是想要收藏喜欢的视频素材、整理图片库存,还是创作内容时需要的参考素材,高效的在线水印去除方法已经成为必需品。本文盘点了6款在线水印去除工具和方法,从处理速度、平台覆盖、易用性等维…...