ChatGPT研究分析:GPT-4做了什么
前脚刚研究了一轮GPT3.5,OpenAI很快就升级了GPT-4,整体表现有进一步提升。追赶一下潮流,研究研究GPT-4干了啥。
本文内容全部源于对OpenAI公开的技术报告的解读,通篇以PR效果为主,实际内容不多。主要强调的工作,是“Predictable Scaling”这个概念。
上一版ChatGPT的主要挑战是,因为模型的训练量极大,很难去进行优化(ChatGPT是fine-tuning的模式)。因此,OpenAI希望能够在模型训练初期,就进行优化,从而大幅提升人工调优迭代的效率。而想要进行调优,就得知道当前模型的效果如何。因此,这个问题就被转化为了:如何在模型训练初期,就能够预测最终训练完成后的实际效果。
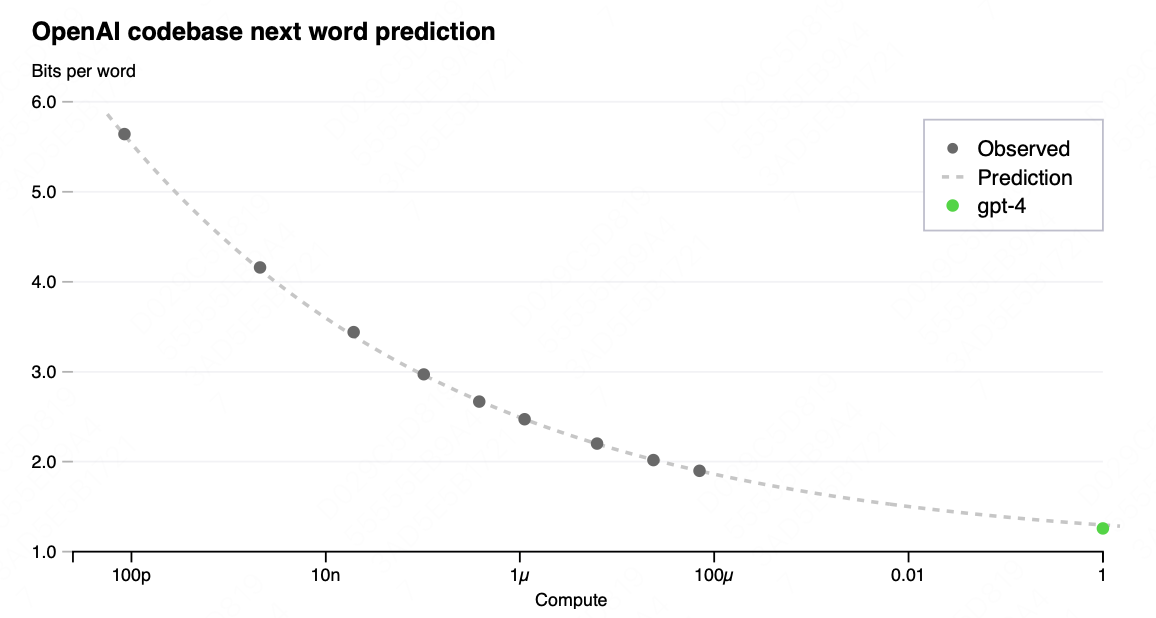
从结果来看,ChatGPT实现了,仅仅执行千分之一到万分之一的训练量,就可以大致预测模型的结果。
实现原理相对简单,就是在某一个模型的不同训练阶段进行实际效果测量,然后做函数拟合,发现符合幂等曲线。然后再基于采样值,测算一下幂等函数的相关参数,下一轮就可以只进行少量训练,就去预测最终效果了。
至于其他效果上的优化,OpenAI没有进一步解读原理,但整体应该还是基于“训练-奖励”的优化模型,去生成更针对性的奖励模型(比如增加法律、安全之类的奖励判断),以实现更优的效果。
原版内容如下:
3 Predictable Scaling
A large focus of the GPT-4 project was building a deep learning stack that scales predictably. The primary reason is that for very large training runs like GPT-4, it is not feasible to do extensive model-specific tuning. To address this, we developed infrastructure and optimization methods that have very predictable behavior across multiple scales. These improvements allowed us to reliably predict some aspects of the performance of GPT-4 from smaller models trained using 1, 000× – 10, 000× less compute.
3.1 Loss Prediction
The final loss of properly-trained large language models is thought to be well approximated by power laws in the amount of compute used to train the model [35, 36, 2, 14, 15].
To verify the scalability of our optimization infrastructure, we predicted GPT-4’s final loss on our internal codebase (not part of the training set) by fitting a scaling law with an irreducible loss term (as in Henighan et al. [15]): L(C) = aCb + c, from models trained using the same methodology but using at most 10,000x less compute than GPT-4. This prediction was made shortly after the run started, without use of any partial results. The fitted scaling law predicted GPT-4’s final loss with high accuracy (Figure 1).
3.2 Scaling of Capabilities on HumanEval
Having a sense of the capabilities of a model before training can improve decisions around alignment, safety, and deployment. In addition to predicting final loss, we developed methodology to predict more interpretable metrics of capability. One such metric is pass rate on the HumanEval dataset [37], which measures the ability to synthesize Python functions of varying complexity. We successfully predicted the pass rate on a subset of the HumanEval dataset by extrapolating from models trained with at most 1, 000× less compute (Figure 2).
For an individual problem in HumanEval, performance may occasionally worsen with scale. Despite these challenges, we find an approximate power law relationship −EP [log(pass_rate(C))] = α∗C−k
where k and α are positive constants, and P is a subset of problems in the dataset. We hypothesize that this relationship holds for all problems in this dataset. In practice, very low pass rates are difficult or impossible to estimate, so we restrict to problems P and models M such that given some large sample budget, every problem is solved at least once by every model.
We registered predictions for GPT-4’s performance on HumanEval before training completed, using only information available prior to training. All but the 15 hardest HumanEval problems were split into 6 difficulty buckets based on the performance of smaller models. The results on the 3rd easiest bucket are shown in Figure 2, showing that the resulting predictions were very accurate for this subset of HumanEval problems where we can accurately estimate log(pass_rate) for several smaller models. Predictions on the other five buckets performed almost as well, the main exception being GPT-4 underperforming our predictions on the easiest bucket.
Certain capabilities remain hard to predict. For example, the Inverse Scaling Prize [38] proposed several tasks for which model performance decreases as a function of scale. Similarly to a recent result by Wei et al. [39], we find that GPT-4 reverses this trend, as shown on one of the tasks called Hindsight Neglect [40] in Figure 3.
We believe that accurately predicting future capabilities is important for safety. Going forward we plan to refine these methods and register performance predictions across various capabilities before large model training begins, and we hope this becomes a common goal in the field.
相关文章:
ChatGPT研究分析:GPT-4做了什么
前脚刚研究了一轮GPT3.5,OpenAI很快就升级了GPT-4,整体表现有进一步提升。追赶一下潮流,研究研究GPT-4干了啥。本文内容全部源于对OpenAI公开的技术报告的解读,通篇以PR效果为主,实际内容不多。主要强调的工作…...

我为什么要写博客,写博客的意义是什么??
曾经何时我也不知道,怎样才能变成我自己所羡慕的大佬!!在一次次的CSDN阅读的过程中,结实了许多志同道合的人!!包过凉哥,擦姐……大佬,但是,很遗憾,与这些人只…...
ssm框架之spring:浅聊AOP
AOP(Aspect Oriented Programming),是一种设计思想。先看一下百度百科的解释: 在软件业,AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期间动态…...

k8s详解
一、k8s中的yaml文件 JSON格式:主要用于api接口之间信息的传递YAML格式:主要用于配置和管理,YAML是一种简洁的非标记性语言,内容格式人性化 YAML格式: 大小写敏感使用缩进代表层级关系,不支持TAB制表符缩…...
第一章操作系统引论 1.1操作系统的目标和作用)
计算机操作系统(第四版)第一章操作系统引论 1.1操作系统的目标和作用
第一章操作系统引论 1.1操作系统的目标和作用 什么是操作系统OS? 配置在计算机硬件上的第一层软件是对硬件的首次扩充。 是最重要的系统软件,其他系统软件应用软件都依赖于操作系统的支持。 操作系统主要作用? 管理计算机系统所有硬件设…...
)
git push解决办法: ! [remote rejected] master -> master (pre-receive hook declined)
项目经理远程创建了一个空项目,无任何内容,给我赋予的developer账号权限,本地改为后提交代码试了很多次都上传不上去,报错如下: ! [remote rejected] master -> master (pre-receive hook declined)先说结果&#x…...
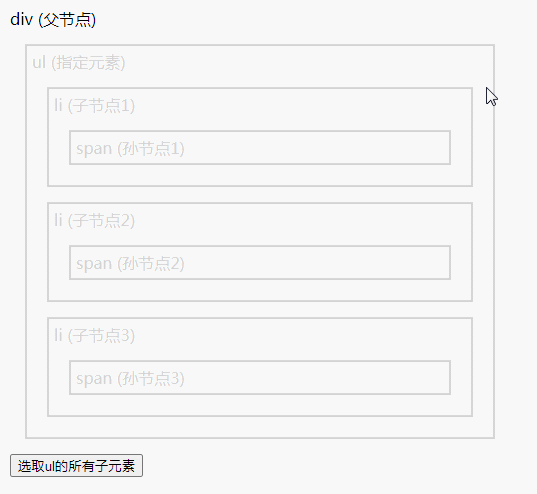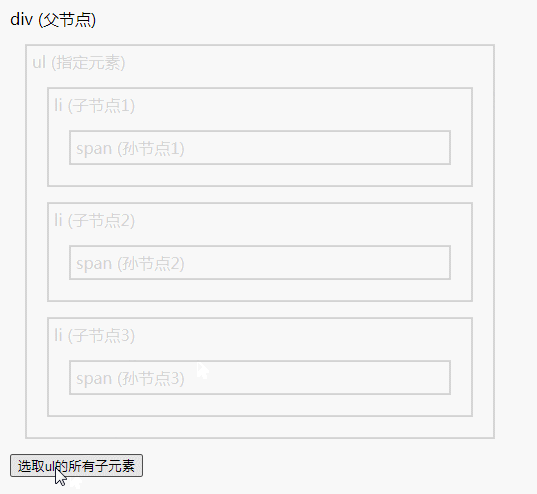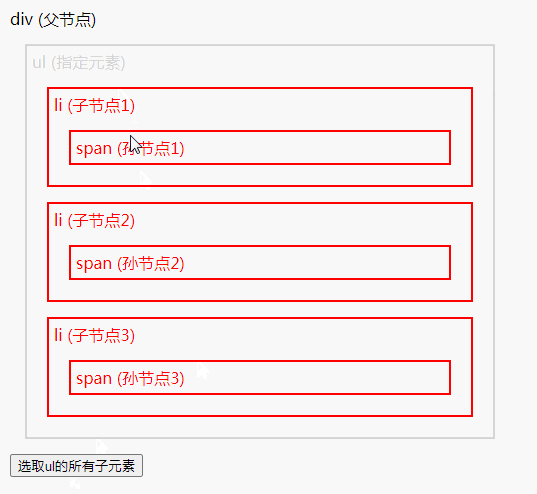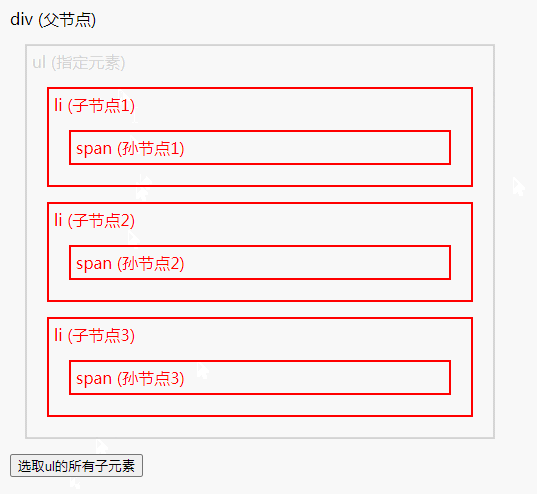
jQuery 遍历方法总结
遍历方法有:1、add(),用于把元素添加到匹配元素的集合中;2、children(),用于返回被选元素的所有直接子元素;3、closest(),用于返回被选元素的第一个祖先元素;4、contents(),用于返回…...
拦截器)
OKHttp 源码解析(二)拦截器
游戏SDK架构设计之代码实现——网络框架 OKHttp 源码解析(一) OKHttp 源码解析(二)拦截器 前言 上一篇解读了OKHttp 的基本框架源码,其中 OKHttp 发送请求的核心是调用 getResponseWithInterceptorChain 构建拦截器链…...
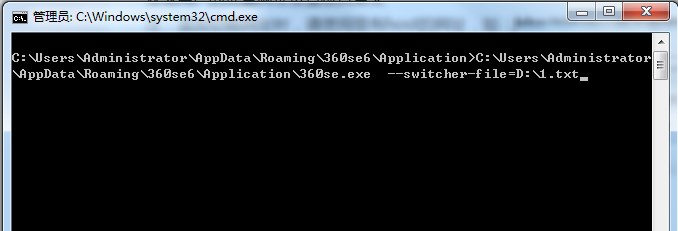
如何修改设置浏览器内核模式
优先级: 强制锁定极速模式 >手动切换(用户)>meta指定(开发者)>浏览器兼容列表(浏览器) 需要用360安全浏览器14,chromium108内核,下载地址https://bbs.360.cn/t…...

30个Python常用小技巧
1、原地交换两个数字 1 2 3 4 x, y 10, 20 print(x, y) y, x x, y print(x, y) 10 20 20 10 2、链状比较操作符 1 2 3 n 10 print(1 < n < 20) print(1 > n < 9) True False 3、使用三元操作符来实现条件赋值 [表达式为真的返回值] if [表达式] else [表达式…...

ubuntu解决中文乱码
1、查看当前系统使用的字符编码 ~$ locale LANGen_US LANGUAGEen_US: LC_CTYPE"en_US" LC_NUMERIC"en_US" LC_TIME"en_US" LC_COLLATE"en_US" LC_MONETARY"en_US" LC_MESSAGES"en_US" LC_PAPER"en_US" …...
网络安全竞赛试题——MYSQL安全测试解析(详细))
2022年全国职业院校技能大赛(中职组)网络安全竞赛试题——MYSQL安全测试解析(详细)
B-3任务三:MYSQL安全测试 *任务说明:仅能获取Server3的IP地址 1.利用渗透机场景kali中的工具确定MySQL的端口,将MySQL端口作为Flag值提交; 2.管理者曾在web界面登陆数据库,并执行了select <?php echo \<pre>\;system($_GET[\cmd\]); echo \</pre>\; ?…...

C++ map和unordered_map的区别
unordered_map 类模板和 map 类模板都是描述了这么一个对象:它是由 std::pair<const Key, value> 组成的可变长容器; 这个容器中每个元素存储两个对象,也就是 key - value 对。 1. unordered_map 在头文件上,引入 <unor…...
)
BCSP-玄子JAVA开发之JAVA数据库编程CH-04_SQL高级(二)
BCSP-玄子JAVA开发之JAVA数据库编程CH-04_SQL高级(二) 4.1 IN 4.1.1 IN 子查询 如果子查询的结果为多个值,就会导致代码报错解决方案就是使用 IN 关键字,将 替换成 IN SELECT …… FROM 表名 WHERE 字段名 IN (子查询);4.1.…...

学习java——②面向对象的三大特征
目录 面向对象的三大基本特征 封装 封装demo 继承 继承demo 多态 面向对象的三大基本特征 我们说面向对象的开发范式,其实是对现实世界的理解和抽象的方法,那么,具体如何将现实世界抽象成代码呢?这就需要运用到面向对象的三大…...
初阶数据结构 - 【单链表】
目录 前言: 1.概念 链表定义 结点结构体定义 结点的创建 2.链表的头插法 动画演示 代码实现 3.链表的尾插 动画演示 代码实现 4.链表的头删 动画演示 代码实现 5.链表的尾删 动画演示 代码实现 6.链表从中间插入结点 动画演示 代码实现 7.从单…...
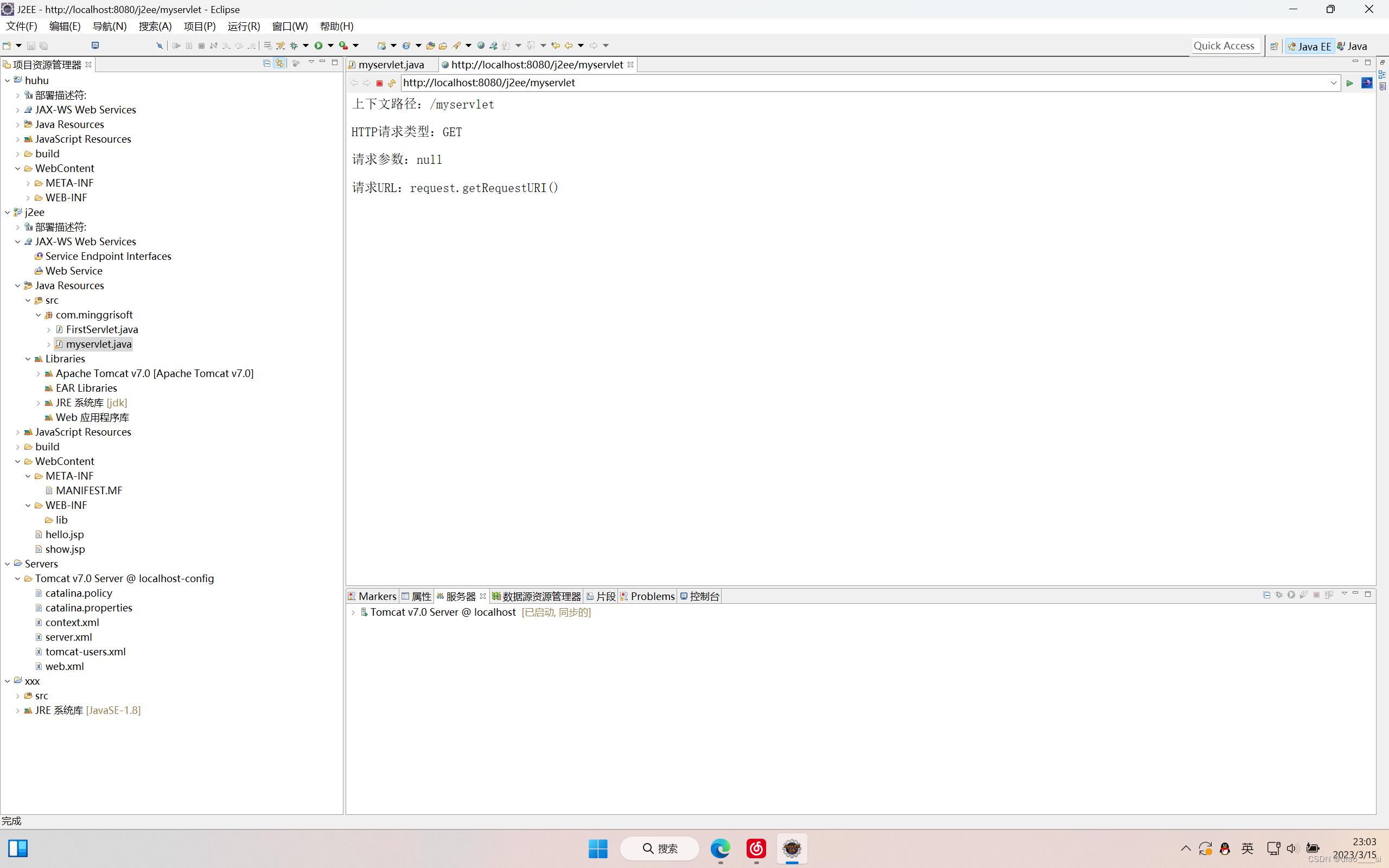
第五周作业、第一次作业(1.5个小时)、练习一
一、创建servlet的过程没有太多好说的,唯一需要注意的就是:旧版本的servlet确实需要手动配置web.xml文件,但是servlet2.5以后,servlet的配置直接在Java代码中进行注解配置。我用的版本就不再需要手动去配置web.xml文件了,所以我只…...
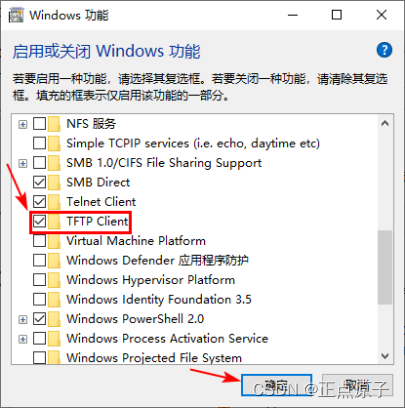
【正点原子FPGA连载】 第三十三章基于lwip的tftp server实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
第三十三章基于lwip的tftp server实验 文件传输是网络环境中的一项基本应用,其作用是将一台电子设备中的文件传输到另一台可能相距很远的电子设备中。TFTP作为TCP/IP协议族中的一个用来在客户机与服务器之间进行文件传输的协议,常用于无盘工作站、路由器…...

蓝桥冲刺31天之316
如果生活突然向你发难 躲不过那就迎面而战 所谓无坚不摧 是能享受最好的,也能承受最坏的 大不了逢山开路,遇水搭桥 若你决定灿烂,山无遮,海无拦 A:特殊日期 问题描述 对于一个日期,我们可以计算出年份的各个…...
说一个通俗易懂的PLC工程师岗位要求
你到了一家新的单位,人家接了一套新的设备,在了解设备工艺流程之后,你就能决定用什么电气元件,至少95%以上电气原件不论你用过没用过都有把握拍板使用,剩下5%,3%你可以先买来做实验,这次不能用&…...

通过审计日志追溯团队内每个API Key的详细使用记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过审计日志追溯团队内每个API Key的详细使用记录 在团队协作使用大模型API时,一个常见的管理难题是:如何…...

电子热量表设计:PIC16F913微控制器应用与热力计算
1. 电子热量表的核心原理与设计需求 在集中供暖系统中,热量表扮演着能量"会计"的角色,精确记录每户消耗的热能。其核心任务可以分解为三个关键参数的测量:进水温度、回水温度以及水流量。这三个参数通过热力学基本公式QmcpΔT相互关…...

星露谷物语模组加载器SMAPI:免费开源的游戏增强终极指南
星露谷物语模组加载器SMAPI:免费开源的游戏增强终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 星露谷物语模组加载器SMAPI是《星露谷物语》的官方模组API,为这款经典…...

零知识证明与法律科技融合:构建可验证计算驱动的自动化合约执行系统
1. 项目概述与核心价值最近在开源社区里,一个名为Sheygoodbai/vericlaw的项目引起了我的注意。乍一看这个项目名,可能会觉得有些抽象,但深入探究后,我发现它触及了当前一个非常前沿且充满潜力的交叉领域:如何利用可验证…...

微博图文视频批量采集软件用户手册
目录 系统介绍 安装与配置 功能使用说明 常见问题 日志查看 系统介绍 本系统是一款微博内容采集与媒体处理工具,主要功能包括: 采集微博内容(图文、视频) 视频裁剪与去水印 AI标题优化 文件分类保存 自动抽帧 安装与配…...
)
从HarryNull密码游戏入门CTF:手把手带你破解前10关(附完整思路与工具)
从HarryNull密码游戏入门CTF:手把手带你破解前10关(附完整思路与工具) 当你第一次接触CTF(Capture The Flag)时,可能会被各种专业术语和复杂的技术吓到。但学习安全技术最好的方式,就是从实践中…...
)
VSCode写Markdown别再只用预览了!这3个插件让你的效率翻倍(含目录生成避坑指南)
VSCode Markdown高阶玩家指南:超越预览的3个效率革命 如果你还在用VSCode的Markdown预览功能当作核心生产力工具,那么你可能只挖掘了这座金矿的10%。作为全球开发者首选的编辑器,VSCode的Markdown生态远不止于左右分屏的实时渲染。今天我们要…...

告别限速!百度网盘解析工具终极使用指南
告别限速!百度网盘解析工具终极使用指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而烦恼吗?今天我要为你介绍一个…...
)
从CI/CD到AI/CD:SITS2026定义的下一代测试流水线(附头部大厂内部迁移路径图)
更多请点击: https://intelliparadigm.com 第一章:AI研发自动化测试:SITS2026专题 AI研发流程中,测试环节正从人工验证转向模型感知驱动的闭环自动化。SITS2026(Semantic Intelligence Testing Suite 2026)…...

深度解析SOLIDWORKS在Linux平台的5大技术突破与完整部署指南
深度解析SOLIDWORKS在Linux平台的5大技术突破与完整部署指南 【免费下载链接】SOLIDWORKS-for-Linux This is a project, where I give you a way to use SOLIDWORKS on Linux! 项目地址: https://gitcode.com/gh_mirrors/so/SOLIDWORKS-for-Linux 在工程设计领域&…...