16、Python之容器:元组与列表、推导式与生成式,差之毫厘谬以千里
引言
从上一篇文章开始了对Python中容器的介绍,已经对列表的简单使用做了一些介绍,今天这篇文章,打算首先简单介绍一下元组,同时比较一下元组、列表的异同,然后就列表、元组的一些比较实用的用法,做一些补充说明。
本文的主要内容大概如下:
1、Python中元组的简单介绍
2、元组就是不可变列表?
3、关于遍历的其他方式
4、推导式与生成式的比较
Python中的tuple(元组)
在Python中提供了tuple的容器类型,可以实现不可变容器的支持。
tuple的特点主要有:
1、不可变性:元组一旦创建,不能修改、添加、删除其中的元素(需要注意不可变的严格程度)。
2、有序性:如同列表,元组也是有序的,可以通过索引访问。
3、允许重复:元组不同于set(),元素是可以重复的。
4、支持多种类型:如同列表一样,可以放入任何类型的元素。
元组的使用,除了不能增、删、改,基本是跟列表相同的。
但是,需要注意的是,不可变性的程度,是开发者需要注意到的。
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
print(zhangsan)
# 报错
zhangsan[1] = 23
执行结果:

如果改的是嵌套容器的元素呢:
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
print(zhangsan)
# 报错
# zhangsan[1] = 23
# 改变元素的内容
zhangsan[3].append('running')
print(zhangsan)执行结果:

所以,这个元组不可变的说法,需要开发者自己要有所思考、感知的。
tuple就是不可变的列表?
有些入门教材中,总是习惯于把元组称之为“不可变列表”,刚开始简单使用,其实也是无关紧要的。但是,如果要真正理解元组,这样的模糊认知其实是不够的。
首先,从语意上来说,元组,适合于用作一条记录的存储,而列表更适合一组记录的存储。所以,元组中的项数与项的顺序也有具有了语意,自然不能随意更改。
# 存储了一条记录,项依次为姓名、年龄、性别、爱好,顺序自然不能随意变更,每条记录分别以元组存储表达,多条记录则将之放入列表
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
lisi = ('李四', 23, '女', ['reading', 'singing'])
persons = [zhangsan, lisi]
print(persons)执行结果:

其次,元组是否一定能作为字典的key,这也是需要打个问号的。能作为字典key的,一定是可以哈希的。元组一定可以哈希吗?可以使用内置函数hash()来判断:
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
# 本行会抛出TypeError的异常
hash(zhangsan)执行结果:

因为元组中存储了不可哈希的元素。
那么,自然也不能作为字典的key:
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
d1 = {zhangsan: 10}执行结果:

最后,除了可以作为不可变列表使用之外,tuple相较于list还是有性能上的优势的:
1、在字面量的构建上,元组可以一次生成,并作为常量存储。列表需要逐个入栈,然后构建列表。
2、给定一个元组zs,tuple(ts)直接返回t的引用,不涉及复制。相比之下,列表ls,list(ls)则会创建zs的副本。
zs = ('张三', 18, '男', ['reading', 'basketball'])
zs2 = tuple(zs)
print(id(zs))
print(id(zs2))ls = ['李四', 23, '女', ['reading', 'singing']]
ls2 = list(ls)
print(id(ls))
print(id(ls2))执行结果:

3、在内存分配和引用存储上,元组长度固定,所以分配的内存空间刚好够用;而列表需要考虑追加元素,所以实际的内存空间会多分配一些。元组中元素的引用都存储在元组结构体中的一个数组中,而列表则把元素的引用数组存储在别处。主要是因为列表可以变长,一旦超出当前分配的空间,Python就需要重新分配引用数组来腾出空间。
关于遍历的其他方式
关于对列表和元组的遍历,其实有两个比较好用的“函数”:enumerate()和zip(),其实,不应该说是函数,严谨来说应该是类:
通过使用enumerate,可以生成带指定索引的元组格式的元素:
from faker import Faker
fk = Faker('zh_CN')names = [fk.unique.name() for _ in range(5)]
print(names)
print('='*5 + 'for names' + '='*5)
# 需要按照编号从1开始输出
# 使用for直接遍历:
for i in range(len(names)):print(f"{i + 1}: {names[i]}")
print('='*5 + 'for enumerate' + '='*5)
# 使用enumerate进行遍历:
for idx, name in enumerate(names, start=1):print(f"{idx}: {name}")执行结果:

通过使用zip,可以将两个列表进行拉链,一一组合为元组的形式。
比如,现在有两个列表,分别存放姓名和性别,需要将每个人的姓名、性别同时输出:
names = [fk.unique.name() for _ in range(5)]
genders = [fk.passport_gender() for _ in range(5)]
print('='*5 + 'for names' + '='*5)
# 使用for直接遍历:
for i in range(len(names)):print(f"{names[i]}: {genders[i]}")
print('='*5 + 'for zip' + '='*5)
# 使用zip进行遍历:
for name, gender in zip(names, genders):print(f"{name}: {gender}")执行结果:
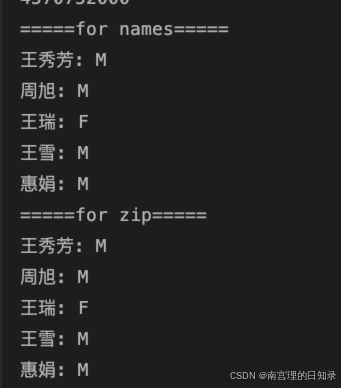
如果两个列表的长度不同呢,我们只取出能匹配上的,匹配不上的就丢弃了,使用zip,自动就可以做到了,但是普通的循环,需要我们自己处理了:
names = [fk.unique.name() for _ in range(5)]
# 性别列表比姓名多了一个
genders = [fk.passport_gender() for _ in range(6)]
print('='*5 + 'for names' + '='*5)
# 使用for直接遍历:
# 长度不同时,需要按照最短的那个来
for i in range(min(len(names), len(genders))):print(f"{names[i]}: {genders[i]}")
print('='*5 + 'for zip' + '='*5)
# 使用zip进行遍历:
for name, gender in zip(names, genders):print(f"{name}: {gender}")此外,zip结合前面提过的*号,还可以实现unzip的效果:
from faker import Faker
fk = Faker('zh_CN')name_gender_map = [(fk.unique.name(), fk.passport_gender()) for _ in range(5)]
print(name_gender_map)
names, genders = zip(*name_gender_map)
print(names)
print(genders)执行结果:

列表推导式与生成器表达式
前面文章中,已经简单介绍了列表推导式的使用,本文将介绍一种新的列表构建的方式——生成器表达式。
使用列表推导式和生成器表达式都可以快速构建一个列表对象(序列),代码编写很快,实际代码执行也会很快,甚至这种一行代码替代for循环的代码习惯之后,更加易于理解!
相较于列表推导式,生成器表达式占用的内存更少,因为生成器表达式使用迭代器协议逐个产生元素,而不是构建整个列表提供给其他构造函数。
生成器表达式的语法跟列表推导式几乎一样,只是把方括号[]换成了圆括号()。
from faker import Faker
fk = Faker('zh_CN')persons = [(fk.name(), fk.random_int(10, 150), fk.random_int(140, 200)) for _ in range(10)]
persons_new = ((fk.name(), fk.random_int(10, 150), fk.random_int(140, 200)) for _ in range(10))
print(type(persons))
print(type(persons_new))
for p in persons_new:print(p)此外,在实际代码编写时,需要注意的是:
Python会忽略[]、{}和()内部的换行。因此,列表、列表推导式、元组、字典等结构完全可以分成几行来写,无须使用续行转义符\。
总结
本文简单介绍了Python中元组的特点,同时对比了元组与列表、推导式与生成式。这些粗略看来,相差不大的概念,仔细思考之后,还是能发现很多值得注意的点,而这些可能就决定了Python代码编写的质量,以及实际运行的效率。
相关文章:
16、Python之容器:元组与列表、推导式与生成式,差之毫厘谬以千里
引言 从上一篇文章开始了对Python中容器的介绍,已经对列表的简单使用做了一些介绍,今天这篇文章,打算首先简单介绍一下元组,同时比较一下元组、列表的异同,然后就列表、元组的一些比较实用的用法,做一些补…...

HTTP协议——请求头和请求体详情
HTTP协议-请求头和请求体 请求头 请求头(Request Header)是在HTTP协议中用于描述一个HTTP请求的元数据。它是客户端发送给服务器的一部分请求信息,包含了客户端的相关配置和要求。 请求头通常包含以下几个部分: 1. 请求方法(Req…...

编程中的智慧之设计模式二
设计模式:深度解析与实战应用 在上一篇文章中,我们探讨了创建型模式、结构型模式和行为模式中的一些常用模式及其Java实现。本篇将继续深入探讨设计模式,重点介绍更多的行为模式以及架构模式在实际开发中的应用。 行为模式 责任链模式&…...

基于python的百度资讯爬虫的设计与实现
研究背景 随着互联网和信息技术的飞速发展,网络已经成为人们获取信息的主要来源之一。特别是搜索引擎,作为信息检索的核心工具,极大地改变了人们获取信息的方式。其中,百度作为中国最受欢迎的搜索引擎之一,其新闻搜索…...
用 WireShark 抓住 TCP
Wireshark 是帮助我们分析网络请求的利器,建议每个同学都装一个。我们先用 Wireshark 抓取一个完整的连接建立、发送数据、断开连接的过程。 简单的介绍一下操作流程。 1、首先打开 Wireshark,在欢迎界面会列出当前机器上的所有网口、虚机网口等可以抓取…...
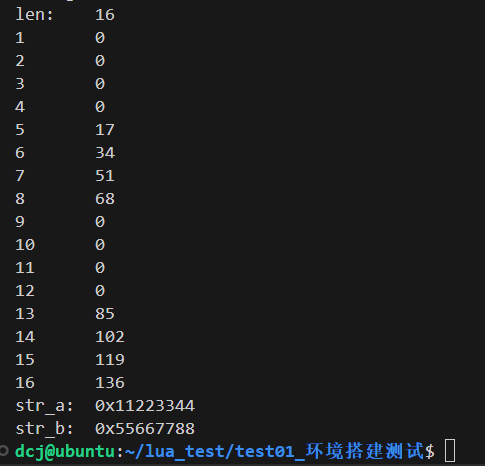
Lua基础知识入门
1 基础知识 标识符:标识符的定义和 C语言相同:字母和下划线_ 开头, 下划线_ 大写字母一般是lua保留字, 如_VERSION 全局变量:默认情况下,变量总是认为是全局的,不需要申明,给一个变…...

【机器学习实战】Datawhale夏令营2:深度学习回顾
#DataWhale夏令营 #ai夏令营 文章目录 1. 深度学习的定义1.1 深度学习&图神经网络1.2 机器学习和深度学习的关系 2. 深度学习的训练流程2.1 数学基础2.1.1 梯度下降法基本原理数学表达步骤学习率 α梯度下降的变体 2.1.2 神经网络与矩阵网络结构表示前向传播激活函数…...

开发扫地机器人系统时无法兼容手机解决方案
在开发扫地机器人系统时,遇到无法兼容手机的问题,可以从以下几个方面寻求解决方案: 一、了解兼容性问题根源 ① 操作系统差异:不同手机可能运行不同的操作系统(如iOS、Android),且即使是同一操…...

Elasticsearch 角色和权限管理
在大数据和云计算日益普及的今天,Elasticsearch 作为一款强大的开源搜索引擎和数据分析引擎,被广泛应用于日志分析、全文搜索、实时监控等领域。随着业务规模的扩大和数据敏感性的增加,对 Elasticsearch 的访问控制和权限管理也变得越来越重要…...

华为HCIP Datacom H12-821 卷42
42.填空题 如图所示,MSTP网络中SW1为总根,请将以下交换机与IST域根和主桥配对。 参考答案:主桥1468 既是IST域根又是主桥468 既不是又不是就是25 解析: 主桥1468 既是IST域根又是主桥468 既不是又不是就是25 43.填空题 网络有…...

【精品资料】物业行业BI大数据解决方案(43页PPT)
引言:物业行业BI(Business Intelligence,商业智能)大数据解决方案是专为物业管理公司设计的一套综合性数据分析与决策支持系统。该解决方案旨在通过集成、处理、分析及可视化海量数据,帮助物业企业提升运营效率、优化资…...
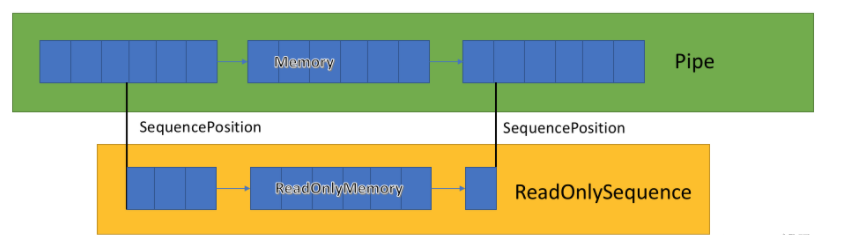
推荐一款处理TCP数据的架构--EasyTcp4Net
EasyTcp4Net是一个基于c# Pipe,ReadonlySequence的高性能Tcp通信库,旨在提供稳定,高效,可靠的tcp通讯服务。 基础的消息通讯 重试机制 超时机制 SSL加密通信支持 KeepAlive 流量背压控制 粘包和断包处理 (支持固定头处理,固定长度处理,固定字符处理) 日志支持Pipe &…...

2、电脑各部件品牌介绍 - 计算机硬件品牌系列文章
笔者是一个电脑IT达人,对于电脑硬件挺感兴趣,今天有必要讲讲关于电脑各部件的品牌问题。关于电脑硬件介绍,见博文版块:计算机硬件系列 。下面对电脑的各部件品牌等进行介绍,便于大家选购电脑的时候做参考。 1、 CPU&am…...

Git【撤销远程提交记录】
在实际开发中,你是否遇到过错误的提交了代码,想要删掉本次提交记录的情况,你可以按照如下方法实现。 1、使用 git revert 如果你想要保留历史记录,并且对远程仓库其他使用者的影响最小,你可以使用 git revert 命令。这…...

java基础学习:序列化之 - Fast serialization
在Java中,序列化是将对象的状态转换为字节流的过程,以便保存到文件、数据库或通过网络传输。Java标准库提供了java.io.Serializable接口和相应的机制来进行序列化和反序列化。然而,标准的Java序列化机制性能较低,并且生成的字节流…...

Microsoft Build 2024 推出 .NET 9:Tensor<T>、 OpenAI Collaboration和.NET Aspire
在 Microsoft Build 2024 上,.NET 9 4 发布,引入了用于深度学习的 Tensor 类型以及与 OpenAI Collaboration实现GPT4o和Assistants v2等功能。这些最新改进还带来了 .NET Aspire,简化了云原生应用开发。更新涵盖 ASP.NET Core、Blazor 和 .NE…...

【Neural signal processing and analysis zero to hero】- 2
Nonstationarities and effects of the FT course from youtube: 传送地址 why we need extinguish stationary and non-stationary signal, because most of neural signal is non-stationary. Welch’s method for smooth spectral decomposition Full FFT method y…...

好用的AI搜索引擎
1. 360AI 搜索 访问 360AI 搜索: https://www.huntagi.com/sites/1706642948656.html 360AI 搜索介绍: 360AI 搜索,新一代智能答案引擎,值得信赖的智能搜索伙伴,为复杂搜索提供专业支持,解锁更相关、更全面的答案。AI…...
十、Java集合 ★ ✔(模块18-20)【泛型、通配符、List、Set、TreeSet、自然排序和比较器排序、Collections、可变参数、Map】
day05 泛型,数据结构,List,Set 今日目标 泛型使用 数据结构 List Set 1 泛型 1.1 泛型的介绍 ★ 泛型是一种类型参数,专门用来保存类型用的 最早接触泛型是在ArrayList,这个E就是所谓的泛型了。使用ArrayList时,只要给E指定某一个类型…...

阿里云开源 Qwen2-Audio 音频聊天和预训练大型音频语言模型
Qwen2-Audio由阿里巴巴集团Qwen团队开发,它能够接受各种音频信号输入,对语音指令进行音频分析或直接文本回复。与以往复杂的层次标签不同,Qwen2-Audio通过使用自然语言提示简化了预训练过程,并扩大了数据量。 喜好儿网 Qwen2-Au…...

父子进程变量地址相同值却不同?图解Linux写时拷贝与页表机制
父子进程变量地址相同值却不同?图解Linux写时拷贝与页表机制 你是否曾在Linux环境下遇到过这样的现象:通过fork()创建的子进程与父进程打印同一个全局变量的地址时,两者的地址值完全相同,但实际读取的变量值却不同?这个…...

3步实现BERT模型轻量化部署与性能优化:基于Torch-Pruning的结构化剪枝指南
3步实现BERT模型轻量化部署与性能优化:基于Torch-Pruning的结构化剪枝指南 【免费下载链接】Torch-Pruning [CVPR 2023] Towards Any Structural Pruning; LLMs / Diffusion / Transformers / YOLOv8 / CNNs 项目地址: https://gitcode.com/gh_mirrors/to/Torch-P…...

视频格式转换革新:m4s-converter让B站缓存视频无缝播放
视频格式转换革新:m4s-converter让B站缓存视频无缝播放 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 从缓存困境到自由播放&#x…...

3分钟快速上手AdGuard浏览器扩展:开源广告拦截工具全平台安装指南
3分钟快速上手AdGuard浏览器扩展:开源广告拦截工具全平台安装指南 【免费下载链接】AdguardBrowserExtension AdGuard browser extension 项目地址: https://gitcode.com/gh_mirrors/ad/AdguardBrowserExtension AdGuard浏览器扩展是一款开源、免费的广告拦截…...

Palo Alto PAN-OS 12.1.5 VM-Series for ESXi, KVM - 基于机器学习的下一代防火墙操作系统
Palo Alto PAN-OS 12.1.5 Orion 发布 - 基于机器学习的下一代防火墙操作系统 PAN-OS 12.1 Orion delivers industry firsts including quantum readiness, unified multi-cloud protection, and more. 请访问原文链接:https://sysin.org/blog/pan-os-12/ 查看最新…...

Arduino智能小车避坑指南:从TB6612驱动到HC-05蓝牙,新手最容易搞错的5个硬件连接点
Arduino智能小车避坑实战:5个硬件连接致命细节与示波器级调试方案 刚拿到Arduino套件的新手们,总会在论坛里发出同样的灵魂拷问:"为什么我的小车要么瘫着不动,要么像醉汉一样乱撞?"这个问题背后,…...

Pylint魔法方法验证:10个技巧确保特殊方法符合Python规范的终极指南
Pylint魔法方法验证:10个技巧确保特殊方法符合Python规范的终极指南 【免费下载链接】pylint Its not just a linter that annoys you! 项目地址: https://gitcode.com/gh_mirrors/pyl/pylint Python开发者们,你是否曾为魔法方法(dund…...

Zotero插件版本兼容性问题深度解析:从冲突到解决方案
Zotero插件版本兼容性问题深度解析:从冲突到解决方案 【免费下载链接】zotero-format-metadata Linter for Zotero. An addon for Zotero to format item metadata. Shortcut to set title rich text; set journal abbreviations, university places, and item lang…...

VSCode插件离线安装的隐藏技巧:如何批量安装.vsix文件提升效率
VSCode插件离线批量安装实战指南:企业级效率提升方案 在团队协作或企业内网环境中,开发者常面临VSCode插件安装的困境——无法访问官方市场、重复下载耗时、版本管理混乱。传统单个.vsix文件安装方式在需要部署数十个插件时,效率低下到令人抓…...

扩散浓度曲线计算:从实例看 Pandat 代算与自行操作
扩散浓度曲线计算(Pandat代算或自己操作) 实例33: Al-4.06at%Mg/Al扩散偶在781K下退火36960s,Mg元素浓度随距离的变化曲线及实验数据对比如图a所示;Al-11at%Mg/Al扩散偶在773K下退火86400s,Mg元素浓度随距离的变化曲线及实验对比如图b所示&am…...